学习ELK日志平台(三)
ELK(elasticsearch、logstash、kibana)
Elastic Stack是原ELK Stack在5.0版本加入Beats套件后的新称呼
解决痛点:
开发人员不能登录线上server查看详细日志;
各个系统都有日志,日志数据分散难以查找;
日志数据量大,查询速度慢,或数据不够实时;
一个调用会涉及多个系统,难以在这些系统的日志中快速定位数据;
典型应用:
http://lucene.apache.org/
大多数电商的管理后台,搜索功能(搜订单、搜用户)都用lucene;
百科:
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言);
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎;
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供,Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开源工具,就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库,人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆;
https://www.elastic.co/
elasticsearch(distributed,restful search and analytics);
kibana(visualize your data,navigate the stack);
beats(collect,parse,and ship in a lightweight fashion);
logstash(ingest,transform,enrich,and output);
es-hadoop(quickly query and get insight into ro your big data);
x-pack(security,alerting,monitoring,reporting,and graph in one pack);
elastic cloud(spin up hosted elasticsearch,kibana,and x-pack);
elastic cloud enterprise(manage a fleet of clusters on any infrastructure);
Plugins for Elastic Stack 1.x — 2.x:
shield(安全,protect your dataacross the Elastic Stack);
watcher(监控,get notifications about changes in your data);
marvel(管理,keep a pulse on the health of your Elastic Stack);
reporting(generate,schedule,and send reports of kibana visualizations);
graph(explore meaningful relationships in your data);
elasticsearch-1.7.0.tar.gz
logstash-1.5.3.tar.gz
kibana-4.1.1-linux-x64.tar.gz
日志收集系统:
scribe(facebook,C/C++);
chukwa(apache/yahoo,java);
kafka(linkedIn,scala);
flume(cloudera,java);
一、
ElasticSearch:
https://www.elastic.co/guide/en/elasticsearch/guide/current/index.html
Search in Depth(开发)
Administration,Monitoring,and Deployment(运维)
[root@test5 ~]# cat /sys/block/sda/queue/scheduler #(默认io scheduler是cfq,改为deadline或noop)
noop anticipatory deadline [cfq]
Elasticsearch是一个建立在全文搜索引擎ApacheLucene(TM)基础上的搜索引擎,可以说 Lucene是当今最先进,最高效的全功能开源搜索引擎框架;但是 Lucene 只是一个框架,要充分利用它的功能,你需要使用 JAVA,并且在你的程序中集成 Lucene,更糟的是,你需要做很多的学习了解,才能明白它是如何运行的,Lucene确实非常复杂;
Elasticsearch 使用 Lucene 作为内部引擎,但是在你使用它做全文搜索时,只需要使用统一开发好的API即可,而并不需要了解其背后复杂的Lucene的运行原理;当然Elasticsearch并不仅仅是Lucene那么简单,它不仅包括了全文搜索功能,还可以进行如下工作:分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索;实时分析的分布式搜索引擎,可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据;这么多的功能被集成到一台服务器上,你可以轻松地通过客户端或者任何你喜欢的程序语言与 ES 的 RESTful API 进行交流;
Elasticsearch 的上手是非常简单的,它附带了很多非常合理的默认值,这让初学者很好地避免一上手就要面对复杂的理论,它安装好了就可以使用了,用很小的学习成本就可以变得很有生产力;随着学习的深入,你还可以使用 Elasticsearch 更多高级的功能,整个引擎可以很灵活地进行配置,你可以根据自身需求来定制属于你自己的 Elasticsearch;
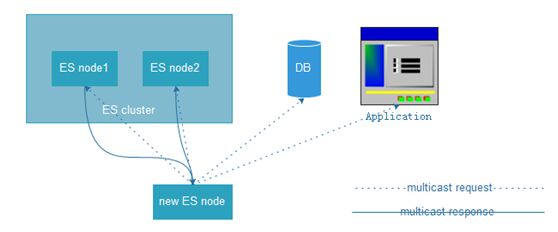
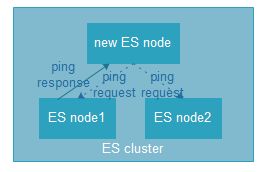
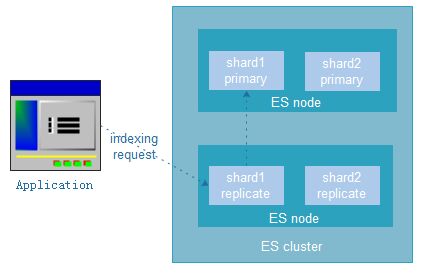
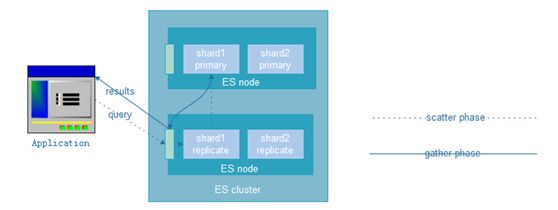
相关术语:节点、集群、文档、索引、分片、备份分片(副本);
节点&集群(节点是elasticsearch运行的实例,集群是一组有着相同cluster.name的节点,它们协同工作,互相分享数据,提供了故障转移和扩展功能,另一个node也可以是一个cluster);
文档(程序中的对象很少是单纯的键值与数值的列表,更多的时候它拥有一个复杂的结构,比如包含了日期、地理位置、对象、数组等,迟早你会把这些对象存储在数据库中,你会试图将这些丰富而又庞大的数据都放到一个由行与列组成的关系数据库中,然后你不得不根据每个字段的格式来调整数据,然后每次重建它你都要检索一遍数据,Elasticsearch是面向文档型数据库,这意味着它存储的是整个对象或者文档,它不但会存储它们,还会为他们建立索引,这样你就可以搜索他们了,你可以在 Elasticsearch 中索引、搜索、排序和过滤这些文档,不需要成行成列的数据,这将会是完全不同的一种面对数据的思考方式,这也是为什么Elasticsearch可以执行复杂的全文搜索的原因;Elasticsearch使用JSON(或称作JavaScript Object Notation)作为文档序列化的格式,JSON 已经被大多数语言支持,也成为NoSQL领域的一个标准格式,它简单、简洁、易于阅读,可把JSON想象成一个用户对象,在 Elasticsearch 中,将对象转换为 JSON 并作为索引要比在表结构中做相同的事情简单多了,几乎所有的语言都有将任意数据转换、结构化成JSON,或者将对象转换为JSON的模块,查看serialization 以及marshalling两个JSON模块,The official Elasticsearch clients也可以帮你自动结构化 JSON);
索引(在Elasticsearch中,存储数据的行为就叫做索引(indexing),但是在我们索引数据前,我们需要决定将数据存储在哪里,Elasticsearch里,文档属于一种类型(type),各种各样的类型存在于一个索引中,你也可以通过类比传统的关系数据库得到一些大致的相似之处:
关系数据库 数据库表table 行row 列(Columns)
Elasticsearch 索引 类型 文档 字段(Fields)
一个Elasticsearch集群可以包含多个索引(数据库),也就是说其中包含了很多类型(table),这些类型中包含了很多的文档(row),然后每个文档中又包含了很多的字段(column));
注:
在Elasticsearch中,索引这个词汇已经被赋予了太多意义:
索引作为名词(一个索引就类似于传统关系型数据库中的数据库,这里就是存储相关文档的的地方);
索引作为动词(为一个文档创建索引是把一个文档存储到一个索引(名词)中的过程,这样它才能被检索,这个过程非常类似于SQL中的INSERT命令,如果已经存在文档,新的文档将会覆盖旧的文档);
反向索引(在关系数据库中的某列添加一个索引,比如多路搜索树(B-Tree)索引,就可以加速数据的取回速度,Elasticsearch以及Lucene使用的是一个叫做反向索引(inverted index)的结构来实现相同的功能,通常,每个文档中的字段都被创建了索引(拥有一个反向索引),因此他们可以被搜索,如果一个字段缺失了反向索引的话,它将不能被搜索);
与elasticsearch通信,取决于是否使用java:
java API(node client;transport client):如果使用java,elasticsearch内置了两个client,可在代码中使用;node client以一个无数据node的身份加入了一个集群,换句话说,它自身没有任何数据,但是它知道什么数据在集群中的哪一个node上,它可将请求转发到正确的node上进行连接;更加轻量的传输客户端可被用来向远程集群发送请求,它并不加入集群本身,而是把请求转发到集群中的node;两个client都使用elasticsearch的传输协议,通过9300port与java客户端进行通信,集群中的各个node也是通过9300port进行通信,如果此port被禁止,那这些node将不能组成一个cluster;java的客户端的版本号必须要与elasticsearch node所用的版本号一样,否则它们之间可能无法识别);
通过HTTP向RESTful API传送json,其它语言可通过9200port与elasticsearch的RESTful API进行通信,可使用curl命令与elasticsearch通信;
elasticsearch官方提供了很多种编程语言的客户端,也有和许多社区化软件的集成插件(javascript、.NET、php、perl、python、ruby);
#curl -X <VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB(http方法,GET、PUT、POST、HEAD、DELETE);
PROTOCOL(http or https,只有在elasticsearch前面有https代理的时候可用);
HOST(elasticsearch集群中任何一个node的主机名,本地为localhost);
PORT(elasticsearch http服务的端口,默认9200);
QUERY_STRING(可选,查询请求参数,例:?pretty,可生成更加美观易读的json反馈增强可读性);
BODY(json格式编码的请求主体);
举例:
[root@test4 ~]# curl -X GET 'http://192.168.23.132:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
'
{
"count" : 1,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
}
}
注(-I不能和-d同时使用,否则Warning: You can only select one HTTP request!;-I只读取http head,-d是用post提交表单):
-I(--head,(HTTP/FTP/FILE) Fetch the HTTP-header only! HTTP-servers feature the command HEAD which this uses to get nothing but the header of a document. When used on a FTP or FILE file, curl displays the file size and last modification time only.)
-X <command>(--request <command>,(HTTP) Specifies a custom request method to use when communicating with the HTTP server. The specified request will be used instead of the method otherwise used (which defaults to GET). Read the HTTP 1.1 specification for details and explanations. Common additional HTTP requests include PUT and DELETE, but related tech-nologies like WebDAV offers PROPFIND, COPY, MOVE and more. (FTP)Specifies a custom FTP command to use instead of LIST when doing file listswith FTP. If this option is used several times, the last one will be used.)
-d <data>(--data <data>,(HTTP) Sends the specified data in a POST request to the HTTP server, in the same way that a browser does when a user has filled in an HTML form and presses the submit button. This will cause curl to pass the data to the server using the content-type application/x-www-form-urlencoded. Compare to -F/--form.)
elasticsearch安装前要有java环境
[root@test4 ~]# which java
/usr/bin/java
[root@test4 ~]# java -version
java version "1.5.0"
gij (GNU libgcj) version 4.4.7 20120313(Red Hat 4.4.7-17)
Copyright (C) 2007 Free Software Foundation,Inc.
This is free software; see the source forcopying conditions. There is NO
warranty; not even for MERCHANTABILITY orFITNESS FOR A PARTICULAR PURPOSE.
[root@test4 ~]# rpm -qa | grep java
java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
libvirt-java-0.4.9-1.el6.noarch
libvirt-java-devel-0.4.9-1.el6.noarch
java_cup-0.10k-5.el6.x86_64
[root@test4 ~]# rpm -e --nodeps java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
[root@test4 ~]# tar xf jdk-8u111-linux-x64.gz -C /usr/local/
[root@test4 ~]# vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/local/jdk1.8.0_111
export PATH=$PATH:$JAVA_HOME/bin
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@test4 ~]# . !$
. /etc/profile.d/java.sh
[root@test4 ~]# java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.111-b14, mixed mode)
[root@test4 ~]# tar xf elasticsearch-1.7.0.tar.gz -C /usr/local/
[root@test4 ~]# ln -sv /usr/local/elasticsearch-1.7.0/ /usr/local/elasticsearch
`/usr/local/elasticsearch' ->`/usr/local/elasticsearch-1.7.0/'
[root@test4 ~]# ll /usr/local/elasticsearch/ #(config/{elasticsearch.yml,logging.yml},bin/elasticsearch)
total 40
drwxr-xr-x. 2 root root 4096 Dec 15 23:18 bin
drwxr-xr-x. 2 root root 4096 Dec 15 23:18 config
drwxr-xr-x. 3 root root 4096 Dec 15 23:18 lib
-rw-rw-r--. 1 root root 11358 Mar 23 2015 LICENSE.txt
-rw-rw-r--. 1 root root 150 Jun 9 2015 NOTICE.txt
-rw-rw-r--. 1 root root 8700 Jun 9 2015 README.textile
[root@test4 ~]# vim /usr/local/elasticsearch/config/elasticsearch.yml
################################### Cluster###################################
cluster.name: elasticsearch #(LAN内的各node通过此名字标识在一个集群里,必须唯一,不能与其它集群名字相同)
#################################### Node#####################################
node.name: "test4"
node.master: true #(该node能否被选举为主node)
node.data: true #(该node能否存储数据)
#################################### Index####################################
index.number_of_shards: 5 #(分片)
index.number_of_replicas: 1 #(备份分片)
#################################### Paths####################################
path.conf: /usr/local/elasticsearch/conf/
path.data: /usr/local/elasticsearch/data/
path.work: /usr/local/elasticsearch/work/ #(临时文件)
path.logs: /usr/local/elasticsearch/logs/
path.plugins:/usr/local/elasticsearch/plugins/
################################### Memory####################################
bootstrap.mlockall: true #(锁内存,不用swap)
############################## Network AndHTTP ###############################
#network.bind_host: 192.168.0.1
#network.publish_host: 192.168.0.1
#network.host: 192.168.0.1 #(相当于network.bind_host和network.publish_host,该node与其它node交互)
#transport.tcp.port: 9300
#http.port: 9200
############################# RecoveryThrottling #############################
#indices.recovery.max_bytes_per_sec: 20mb #(设带宽)
##################################Discovery ##################################
#discovery.zen.ping.multicast.enabled:false #(多播(组播))
#discovery.zen.ping.unicast.hosts:["host1", "host2:port"] #(单播)
[root@test4 ~]#grep '^[a-z]' /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elasticsearch
node.name: "test4"
node.master: true
node.data: true
index.number_of_shards: 5
index.number_of_replicas: 1
path.conf: /usr/local/elasticsearch/conf/
path.data: /usr/local/elasticsearch/data/
path.work: /usr/local/elasticsearch/work/
path.logs: /usr/local/elasticsearch/logs/
path.plugins:/usr/local/elasticsearch/plugins/
bootstrap.mlockall: true
[root@test4 ~]# mkdir /usr/local/elasticsearch/{conf,data,work,logs,plugins}
[root@test4 ~]# /usr/local/elasticsearch-1.7.0/bin/elasticsearch -d #(可加入参数,-Xms512m -Xmx512m)
log4j:WARN No appenders could be found forlogger (node).
log4j:WARN Please initialize the log4jsystem properly.
log4j:WARN Seehttp://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[root@test4 ~]# netstat -tnulp | egrep '9200|9300'
tcp 0 0 :::9200 :::* LISTEN 7177/java
tcp 0 0 :::9300 :::* LISTEN 7177/java
[root@test4 ~]# jps -lvm
7177org.elasticsearch.bootstrap.Elasticsearch -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC-XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly-XX:+HeapDumpOnOutOfMemoryError -XX:+DisableExplicitGC -Dfile.encoding=UTF-8-Delasticsearch -Des.path.home=/usr/local/elasticsearch-1.7.0
7261 sun.tools.jps.Jps -lvm-Denv.class.path=.:/usr/local/jdk1.8.0_111/lib/dt.jar:/usr/local/jdk1.8.0_111/lib/tools.jar-Dapplication.home=/usr/local/jdk1.8.0_111 -Xms8m
安装elasticsearch-servicewrapper:
elasticsearch-servicewrapper这是对elasticsearch执行命令的包装服务,安装之后,方便elasticsearch的启动,停止等操作;
[root@test4 ~]# kill -9 7177
[root@test4 ~]# jps
7281 Jps
[root@test4 ~]# git clone https://github.com/elastic/elasticsearch-servicewrapper.git
Initialized empty Git repository in/root/elasticsearch-servicewrapper/.git/
remote: Counting objects: 184, done.
remote: Total 184 (delta 0), reused 0(delta 0), pack-reused 184
Receiving objects: 100% (184/184), 4.32 MiB| 278 KiB/s, done.
Resolving deltas: 100% (70/70), done.
[root@test4 ~]# mv elasticsearch-servicewrapper/service/ /usr/local/elasticsearch/bin/
[root@test4 ~]# /usr/local/elasticsearch/bin/service/elasticsearch --help
Unexpected command: --help
Usage:/usr/local/elasticsearch/bin/service/elasticsearch [ console | start | stop |restart | condrestart | status | install | remove | dump ]
Commands:
console Launch in the currentconsole.
start Start in thebackground as a daemon process.
stop Stop if running as adaemon or in another console.
restart Stop if running andthen start.
condrestart Restart only ifalready running.
status Query the currentstatus.
install Install to start automatically whensystem boots.
remove Uninstall.
dump Request a Java threaddump if running.
[root@test4 ~]# /usr/local/elasticsearch/bin/service/elasticsearch install #(install to startautomatically when system boots)
Detected RHEL or Fedora:
Installing the Elasticsearch daemon..
[root@test4 ~]# chkconfig --list elasticsearch
elasticsearch 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@test4 ~]# vim /usr/local/elasticsearch/bin/service/elasticsearch.conf #(通过此文件修改java环境配置等运行的一些信息,默认1024根据服务器配置更改,经验证此处至少512否则应用不能启动)
set.default.ES_HEAP_SIZE=512
[root@test4 ~]# /etc/init.d/elasticsearch start
Starting Elasticsearch...
Waiting for Elasticsearch.......
running: PID:7658
[root@test4 ~]# service elasticsearch status
Elasticsearch is running: PID:7658,Wrapper:STARTED, Java:STARTED
[root@test4 ~]# tail /usr/local/elasticsearch/logs/service.log
STATUS | wrapper | 2016/12/16 00:55:23 | --> WrapperStarted as Daemon
STATUS | wrapper | 2016/12/16 00:55:23 | Java Service WrapperCommunity Edition 64-bit 3.5.14
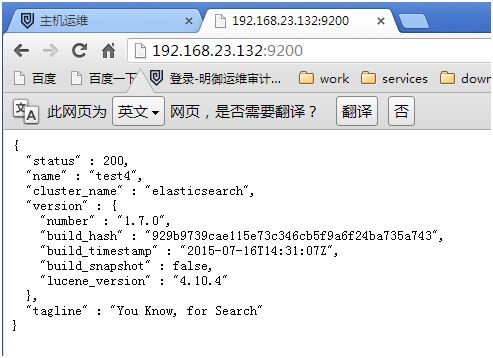
[root@test4 ~]# curl http://192.168.23.132:9200 #(200为正常)
{
"status" : 200,
"name" : "test4",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.0",
"build_hash" :"929b9739cae115e73c346cb5f9a6f24ba735a743",
"build_timestamp" : "2015-07-16T14:31:07Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
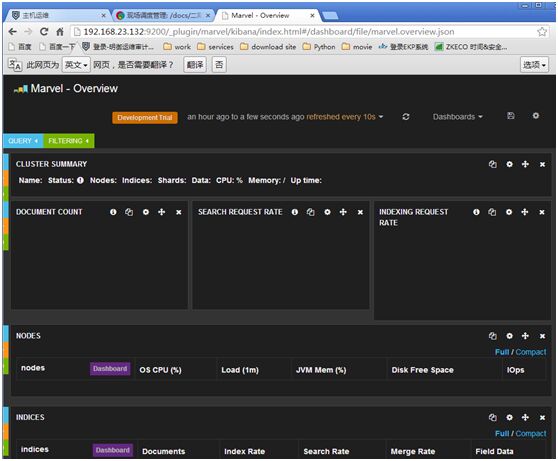
安装插件marvel:
marvel付费的监控管理工具,可使用其中的sense实现与elasticsearch友好交互;
Marvel is a management and monitoring tool for Elasticsearch which is free for development use. It comes with an interactive console called Sense which makes it very easy to talk to Elasticsearch directly from your browser. Many of the code examples in this book include a ``View in Sense'' link. When clicked, it will open up a working example of the code in the Sense console. You do not have to install Marvel,but it will make this book much more interactive by allowing you to experiment with the code samples on your local Elasticsearch cluster.
注:
You probably don't want Marvel to monitor your local cluster, so you can disable data collection with this command:
#echo 'marvel.agent.enabled: false' >> ./config/elasticsearch.yml
[root@test4 ~]# /usr/local/elasticsearch/bin/plugin -i elasticsearch/marvel/latest
-> Installingelasticsearch/marvel/latest...
Tryinghttp://download.elasticsearch.org/elasticsearch/marvel/marvel-latest.zip...
Downloading ................................................................................................................................................................................................................................................................................................DONE
Installed elasticsearch/marvel/latest into/usr/local/elasticsearch/plugins/marvel
http://192.168.23.132:9200/_plugin/marvel #(点继续试用)
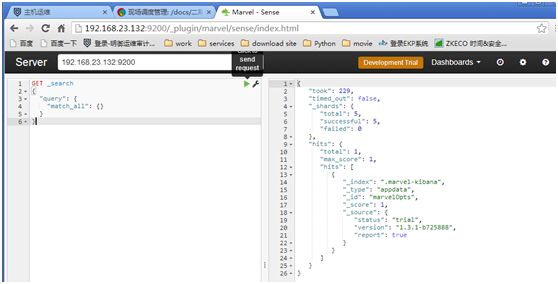
Dashboard-->Sense-->Get to work-->clickto send request
POST /index-demo/test
{
"user" : "jowin",
"message" : "hello,world"
}
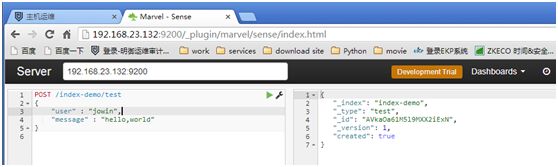
GET /index-demo/test/AVkaOa61M5l9MXX2iExN #(粘贴上一条执行结果中的"_id")
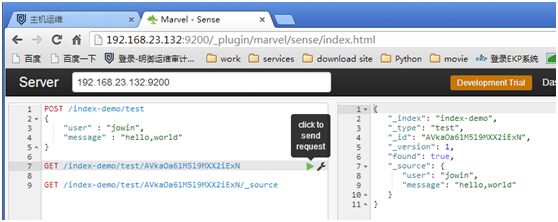
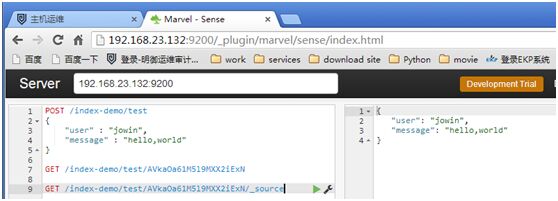
GET/index-demo/test/AVkaOa61M5l9MXX2iExN/_source #(/_source只看文档内容)
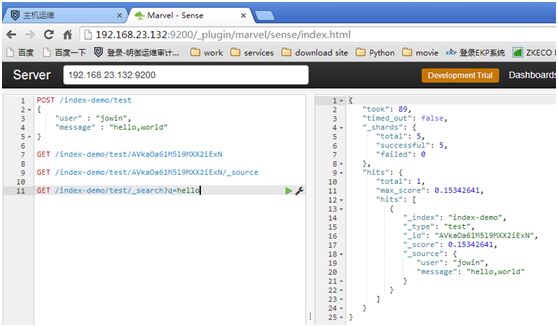
GET /index-demo/test/_search?q=hello #(全文搜索)
elasticsearch集群:
test4(192.168.23.132)
test5(192.168.23.133)
在另一node(test5)上安装elasticsearch、安装elasticsearch-servicewrapper;
test4:
[root@test4 ~]# /usr/local/elasticsearch/bin/plugin -i mobz/elasticsearch-head #(安装集群插件elasticsearch-head,管理集群)
-> Installing mobz/elasticsearch-head...
Tryinghttps://github.com/mobz/elasticsearch-head/archive/master.zip...
Downloading..........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Installed mobz/elasticsearch-head into/usr/local/elasticsearch/plugins/head
http://192.168.23.132:9200/_plugin/head/
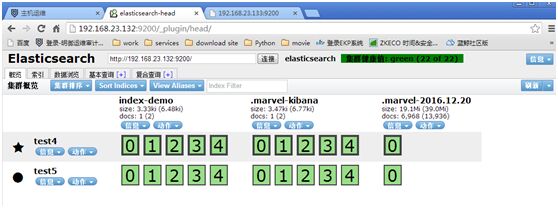
注:
.marvel-kibana为默认索引,一个索引5个分片;
集群健康值(green所有node都正常;yellow所有主分片正常,副本分片有丢失;red主分片有丢失);
[root@test4 ~]# curl-X GET 'http://192.168.23.132:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 11,
"active_shards" : 22,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0
}
二、
logstash

注:
https://www.elastic.co/guide/en/logstash/5.x/input-plugins.html #(input plugin:beats、file)
https://www.elastic.co/guide/en/logstash/5.x/output-plugins.html #(output plugins)
https://www.elastic.co/guide/en/logstash/5.x/filter-plugins.html #(filter plugins)
https://www.elastic.co/guide/en/logstash/5.x/codec-plugins.html #(codec plugins)
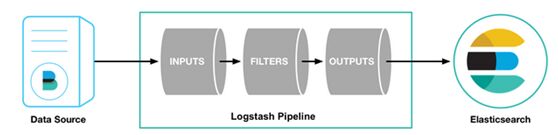
https://www.elastic.co/guide/en/logstash/5.x/configuration-file-structure.html
structure of a config file
----------------------file-start------------------------------
# This is a comment. You should usecomments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}
------------------------file-end--------------------------------
value types:
array、lists、boolean、bytes、codec、hash、number、password、path、string、comments;
array(users => [ {id=> 1, name => bob}, {id => 2, name => jane} ]);
lists(
path => [ "/var/log/messages","/var/log/*.log" ]
uris => [ "http://elastic.co","http://example.net" ]
);
boolean(ssl_enable =>true);
bytes(
my_bytes => "1113" # 1113 bytes
my_bytes => "10MiB" # 10485760 bytes
my_bytes => "100kib" # 102400bytes
my_bytes => "180 mb" #180000000 bytes
);
codec(codec =>"json");
hash(
match => {
"field1" => "value1"
"field2" => "value2"
...
}
);
number(port => 33);
password(my_password =>"password");
uri(my_uri =>"http://foo:bar@example.net");
path(my_path =>"/tmp/logstash");
string(
name => "Hello world"
name => 'It\'s a beautiful day'
);
comments(
# this is a comment
input { # comments can appear at the end ofa line, too
#...
}
);
安装logstash前要有java环境;
https://www.elastic.co/guide/en/logstash/current/installing-logstash.html#installing-logstash #(生产环境建议yum方式安装)
https://artifacts.elastic.co/downloads/logstash/logstash-5.1.1.rpm
https://download.elastic.co/logstash/logstash/packages/centos/logstash-1.5.3-1.noarch.rpm
二进制方式安装(logstash-1.5.3.tar.gz):
[root@test4 ~]# tar xf logstash-1.5.3.tar.gz -C /usr/local/
[root@test4 ~]# cd /usr/local
[root@test4 local]# ln -sv logstash-1.5.3/ logstash
`logstash' -> `logstash-1.5.3/'
[root@test4 ~]# /usr/local/logstash/bin/logstash -e 'input { stdin{} } output { stdout {} }' #(标准输入,标准输出)
hello
Logstash startup completed
2016-12-27T00:55:58.155Z test4 hello
world
2016-12-27T00:56:07.105Z test4 world
^CSIGINT received. Shutting down thepipeline. {:level=>:warn}
^CSIGINT received. Terminatingimmediately.. {:level=>:fatal}
[root@test4 ~]# /usr/local/logstash/bin/logstash -e 'input { stdin{} } output { stdout { codec => rubydebug} }' #(rubydebug)
hello
Logstash startup completed
{
"message" => "hello",
"@version" => "1",
"@timestamp" => "2016-12-27T01:29:38.988Z",
"host" => "test4"
}
^CSIGINT received. Shutting down thepipeline. {:level=>:warn}
^CSIGINT received. Terminatingimmediately.. {:level=>:fatal}
[root@test4 ~]# /usr/local/logstash/bin/logstash -e 'input { stdin {} } output { elasticsearch { host =>"192.168.23.132" protocol => "http" } }' #(输出到elasticsearch)
hello world
'[DEPRECATED] use `require 'concurrent'`instead of `require 'concurrent_ruby'`
Logstash startup completed
http://192.168.23.132:9200/_plugin/head/
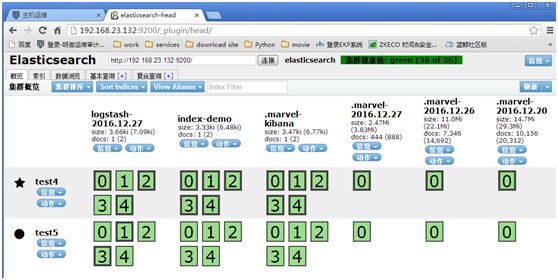
注:
粗黑框是主分片,其它是分片副本;
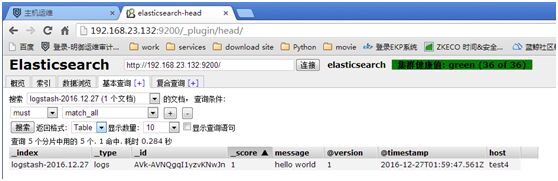
基本查询-->搜索(选logstash)-->点搜索 #(日志进了ES就可进行搜索)
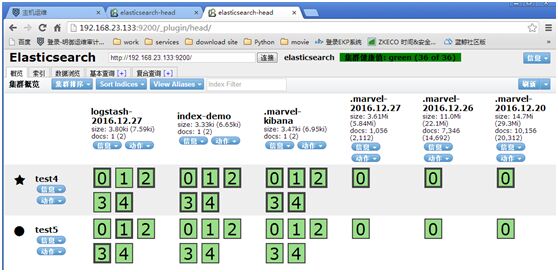
[root@test5 ~]# /usr/local/elasticsearch/bin/plugin -i mobz/elasticsearch-head #(在192.168.23.133上安装管理集群插件)
二进制方式安装(logstash-1.5.3-1.noarch.rpm):
[root@test4 ~]# rm -rf /usr/local/logstash*
[root@test4 ~]# rpm -ivh logstash-1.5.3-1.noarch.rpm
Preparing... ###########################################[100%]
1:logstash ########################################### [100%]
[root@test4 ~]# vim /etc/init.d/logstash
LS_USER=logstash
LS_GROUP=logstash
LS_HOME=/var/lib/logstash
LS_HEAP_SIZE="128m"
LS_LOG_DIR=/var/log/logstash
LS_LOG_FILE="${LS_LOG_DIR}/$name.log"
LS_CONF_DIR=/etc/logstash/conf.d
LS_OPEN_FILES=16384
LS_NICE=19
LS_OPTS=""
[root@test4 ~]# vim /etc/logstash/conf.d/logstash.conf
input {
file {
path => "/tmp/messages"
}
}
output {
file {
path =>"/tmp/%{+YYYY-MM-dd}-messages.gz"
gzip => true
}
}
[root@test4 ~]# /etc/init.d/logstash start
logstash started.
[root@test4 ~]# /etc/init.d/logstash status
logstash is running
[root@test4 ~]# cat /var/log/maillog >> /tmp/messages
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
[root@test4 ~]# ll /tmp
total 196
-rw-r--r--. 1 logstash logstash 5887 Dec 28 19:28 2016-12-29-messages.gz
drwxr-xr-x. 2 logstash logstash 4096 Dec 28 19:27 hsperfdata_logstash
drwxr-xr-x. 2 root root 4096 Dec 28 19:18 hsperfdata_root
drwxr-xr-x. 2 root root 4096 Dec 26 17:54 jna-3506402
-rw-r--r--. 1 root root 147340 Dec 28 19:28 messages
[root@test4 ~]# vim /etc/logstash/conf.d/logstash.conf
input {
file {
path =>"/tmp/messages"
}
}
output {
file {
path =>"/tmp/%{+YYYY-MM-dd}-messages.gz"
gzip => true
}
elasticsearch {
host =>"192.168.23.132"
protocol => "http"
index =>"system-messages-%{+YYYY.MM.dd}"
}
}
[root@test4 ~]# /etc/init.d/logstash restart
Killing logstash (pid 5921) with SIGTERM
Waiting logstash (pid 5921) to die...
Waiting logstash (pid 5921) to die...
logstash stopped.
logstash started.
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
http://192.168.23.132:9200/_plugin/head/
举例:
node1(test4,192.168.23.132,elasticsearch,logstash)
node2(test5,192.168.23.133,redis、elasticsearch,logstash)
前提:node1和node2是elasticsearch集群
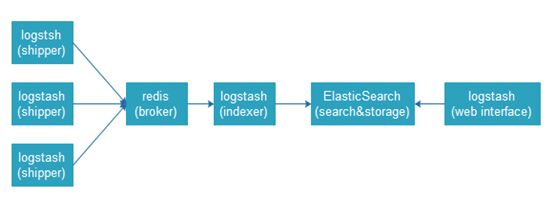
datasource-->logstash-->redis-->logstash-->elasticsearch
(1)input(file)-->logstash-->output(redis)
(2)input(redis)-->logstash-->output(elasticsearch)
注:生产上一个业务用一个redis(0-15共16个库,默认0库),例如:db0给系统日志用,db1访问日志,db2错误日志,db3给mysql日志等
(1)
在test5(node2)上:
[root@test5 ~]# yum -y install redis
[root@test5 ~]# vim /etc/redis.conf
bind 192.168.23.133
[root@test5 ~]# /etc/init.d/redis start
Starting redis-server: [ OK ]
[root@test5 ~]# redis-cli -h 192.168.23.133 -p 6379
redis 192.168.23.133:6379> info
……
redis 192.168.23.133:6379> keys *
(empty list or set)
redis 192.168.23.133:6379> select 1
OK
redis 192.168.23.133:6379[1]> keys *
(empty list or set)
在test4(node1)上:
[root@test4 ~]# vim /etc/logstash/conf.d/logstash.conf #(https://www.elastic.co/guide/en/logstash/current/plugins-inputs-redis.html)
input {
file {
path =>"/tmp/messages"
}
}
output {
redis {
data_type =>"list"
key =>"system-messages"
host =>"192.168.23.133"
port => "6379"
db => "1"
}
}
[root@test4 ~]# /etc/init.d/logstash restart
Killing logstash (pid 5986) with SIGTERM
Waiting logstash (pid 5986) to die...
Waiting logstash (pid 5986) to die...
logstash stopped.
logstash started.
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
在test5(node2)上查看:
redis 192.168.23.133:6379[1]> keys *
1) "system-messages"
redis 192.168.23.133:6379[1]> llen system-messages
(integer) 328
redis 192.168.23.133:6379[1]> lindex system-messages -1
"{\"message\":\"Dec 2819:06:17 test4 dhclient[4900]: bound to 192.168.23.132 -- renewal in 899seconds.\",\"@version\":\"1\",\"@timestamp\":\"2016-12-29T08:49:10.183Z\",\"host\":\"test4\",\"path\":\"/tmp/messages\"}"
(2)
在node2上安装logstash
[root@test5 ~]# java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.111-b14, mixed mode)
[root@test5 ~]# rpm -ivh logstash-1.5.3-1.noarch.rpm
Preparing... ########################################### [100%]
1:logstash ########################################### [100%]
[root@test5 ~]# /etc/init.d/elasticsearchstatus
Elasticsearch is running: PID:4165,Wrapper:STARTED, Java:STARTED
[root@test5 ~]# vim /etc/init.d/logstash
LS_HEAP_SIZE="128m"
[root@test5 ~]# vim /etc/logstash/conf.d/logstash.conf
input {
redis {
data_type =>"list"
key =>"system-messages"
host =>"192.168.23.133"
port => "6379"
db => "1"
}
}
output {
elasticsearch {
host =>"192.168.23.133"
protocol => "http"
index =>"system-redis-messages-%{+YYYY.MM.dd}"
}
}
[root@test5 ~]# /etc/init.d/logstash start
logstash started.
在node1上导入数据:
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
[root@test4 ~]# cat /var/log/maillog>> /tmp/messages
在node2上查看redis中数据,已被elasticsearch拿走长度0:
redis 192.168.23.133:6379[1]> llen system-messages
(integer) 0
redis 192.168.23.133:6379[1]> llen system-messages
(integer) 0
redis 192.168.23.133:6379[1]> llen system-messages
(integer) 0
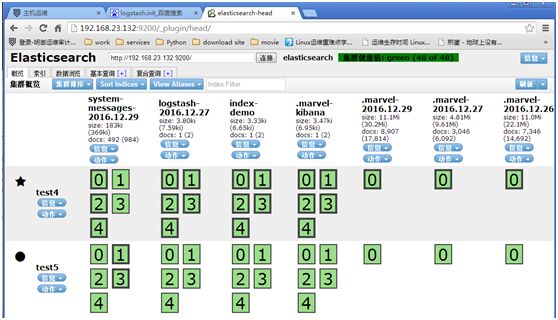
http://192.168.23.132:9200/_plugin/head/
注:
codec plugins:json
input-->decode-->filter-->encode-->output
decode、filter、encode #(codec)
系统日志syslog;
访问日志(codec => json),若json格式不完整,logstash将不会收集,意味着要丢日志,可在logstash日志中查看json解析失败,在线json解析,http://jsonlint.com/;
错误日志(codec =>multiline);
注:
codec => multiline
pattern => ".*\t.*"
运行日志(codec => json);
其它日志;
举例:
nginx记录日志用json
[root@test4 ~]# yum -y install nginx
[root@test4 ~]# cp /etc/nginx/nginx.conf.default /etc/nginx/nginx.conf
cp: overwrite `/etc/nginx/nginx.conf'? y
[root@test4 ~]# vim /etc/nginx/nginx.conf
……
http {
……
log_format logstash_json '{"@timestamp" : "$time_iso8601",'
'"host" :"$server_addr",'
'"client" :"$remote_addr",'
'"size" :$body_bytes_sent,'
'"responsetime" : $request_time,'
'"domain" :"$host",'
'"url" :"$uri",'
'"referer" :"$http_referer",'
'"agent" :"$http_user_agent",'
'"status" :"$status"}';
server {
listen 80;
server_name localhost;
……
access_log logs/access_json.log logstash_json;
……
}
……
}
[root@test4 ~]# mkdir /usr/share/nginx/logs
[root@test4 ~]# /etc/init.d/nginx configtest
nginx: the configuration file/etc/nginx/nginx.conf syntax is ok
nginx: configuration file/etc/nginx/nginx.conf test is successful
[root@test4 ~]# service nginx start
Starting nginx: [ OK ]
node1:
[root@test4 ~]# vim /etc/logstash/conf.d/logstash.conf
input {
file {
path => "/usr/share/nginx/logs/access_json.log"
codec => "json"
}
}
output {
redis {
data_type => "list"
key => "nginx-access-log"
host => "192.168.23.133"
port => "6379"
db => "2"
}
}
[root@test4 ~]# /etc/init.d/logstash restart
Killing logstash (pid 9034) with SIGTERM
Waiting logstash (pid 9034) to die...
Waiting logstash (pid 9034) to die...
Waiting logstash (pid 9034) to die...
logstash stopped.
logstash started.
node2:
[root@test5 ~]# vim /etc/logstash/conf.d/logstash.conf
input {
redis {
data_type =>"list"
key => "nginx-access-log"
host => "192.168.23.133"
port => "6379"
db => "2"
}
}
output {
elasticsearch {
host => "192.168.23.133"
protocol => "http"
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
}
[root@test5 ~]# /etc/init.d/logstash restart
Killing logstash (pid 3718) with SIGTERM
Waiting logstash (pid 3718) to die...
Waiting logstash (pid 3718) to die...
logstash stopped.
logstash started.
node1:
[root@test4 ~]# ab -n 10000 -c 100 http://192.168.23.132:80/index.html
……
[root@test4 ~]# tail -5/usr/share/nginx/logs/access_json.log
{"@timestamp" :"2017-01-03T00:32:01-08:00","host" :"192.168.23.132","client" :"192.168.23.132","size" : 0,"responsetime" :0.000,"domain" : "192.168.23.132","url" :"/index.html","referer" : "-","agent" :"ApacheBench/2.3","status" : "200"}
{"@timestamp" :"2017-01-03T00:32:01-08:00","host" :"192.168.23.132","client" :"192.168.23.132","size" : 0,"responsetime" :0.000,"domain" : "192.168.23.132","url" :"/index.html","referer" : "-","agent" :"ApacheBench/2.3","status" : "200"}
{"@timestamp" :"2017-01-03T00:32:01-08:00","host" :"192.168.23.132","client" :"192.168.23.132","size" : 0,"responsetime" :0.000,"domain" : "192.168.23.132","url" :"/index.html","referer" : "-","agent" :"ApacheBench/2.3","status" : "200"}
{"@timestamp" : "2017-01-03T00:32:01-08:00","host": "192.168.23.132","client" :"192.168.23.132","size" : 0,"responsetime" :0.000,"domain" : "192.168.23.132","url" :"/index.html","referer" : "-","agent" :"ApacheBench/2.3","status" : "200"}
{"@timestamp" :"2017-01-03T00:32:01-08:00","host" :"192.168.23.132","client" :"192.168.23.132","size" : 0,"responsetime" :0.000,"domain" : "192.168.23.132","url" :"/index.html","referer" : "-","agent" :"ApacheBench/2.3","status" : "200"}
node2(已用yum方式安装redis):
redis 192.168.23.133:6379[1]> select 2
OK
redis 192.168.23.133:6379[2]> keys *
1) "nginx-access-log"
……
redis 192.168.23.133:6379[2]> keys * #(elasticsearch取完后为空)
(empty list or set)
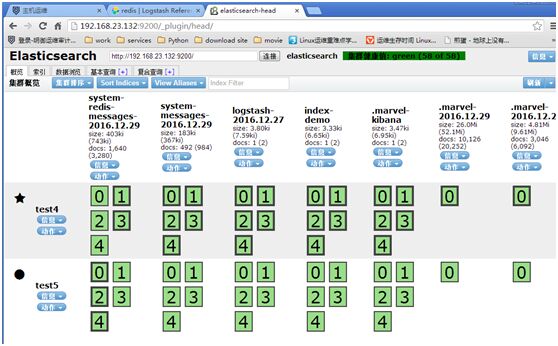
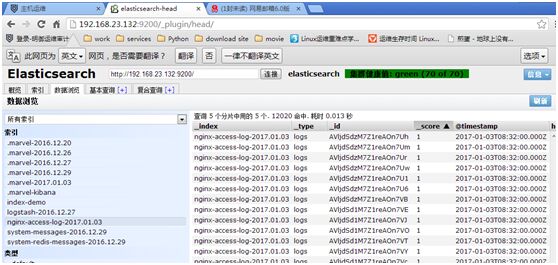
http://192.168.23.132:9200/_plugin/head/
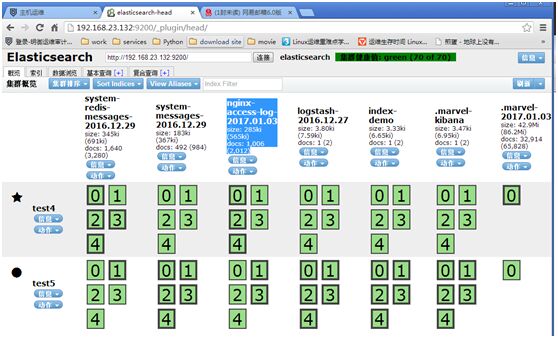
“数据浏览”中
三、
kibana,搜索elasticsearch中的数据,并可视化展现出来
kibanaV1(php);kibanaV2(ruby);kibanaV3(js);kibanaV4(jruby-->nodejs);
[root@test4 ~]# tar xf kibana-4.1.1-linux-x64.tar.gz -C /usr/local/
[root@test4 ~]# cd /usr/local
[root@test4 local]# ln -sv kibana-4.1.1-linux-x64/ kibana
`kibana' -> `kibana-4.1.1-linux-x64/'
[root@test4 local]# vim /usr/local/kibana/config/kibana.yml
elasticsearch_url: "http://192.168.23.132:9200"
[root@test4 local]# kibana/bin/kibana #(5601port,没有报错再放到后台执行)
{"name":"Kibana","hostname":"test4","pid":9687,"level":30,"msg":"Noexisting kibana indexfound","time":"2017-01-03T09:00:42.763Z","v":0}
{"name":"Kibana","hostname":"test4","pid":9687,"level":30,"msg":"Listeningon0.0.0.0:5601","time":"2017-01-03T09:00:42.850Z","v":0}
[root@test4 local]# cd
[root@test4 ~]# nohup /usr/local/kibana/bin/kibana &
[1] 9710
[root@test4 ~]# nohup: ignoring input andappending output to `nohup.out'
[root@test4 ~]# netstat -tnulp | grep :5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 9710/node
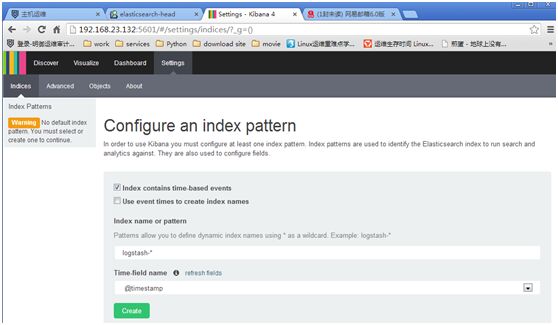
勾选index contains time-based events和use event times tocreate index names
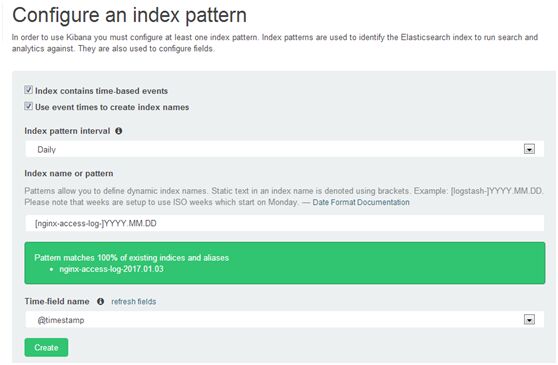
index pattern interval选daily
index name or pattern中输入[nginx-access-log-]YYYY.MM.DD会自动匹配出elasticearch中的index,如图中绿框中内容
点refresh fields,选@timestamp
点Create
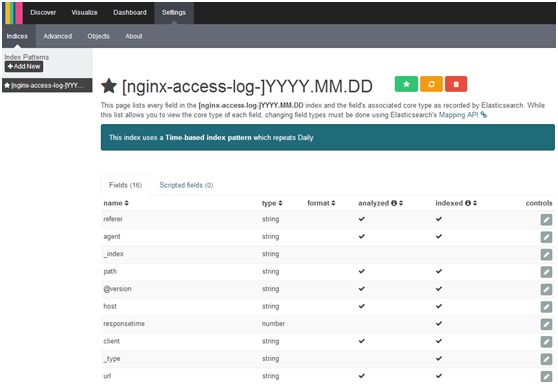
添加多个index,Settings-->Indices-->Add New,若要将某index作为默认,点绿色五角星
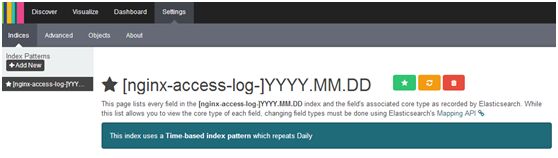
Settings-->Advanced,设置kibana各参数
discover:sampleSize,默认显示日志500行,且以倒序显示,最新的日志最先显示,为加快显示速度,可调整为50
Discover
右上角点Last 15 minutes,Quick、Relative相对、Absolute,点This month
左侧,Available Fields,依次点domain、agent、size、url,每个上都点add
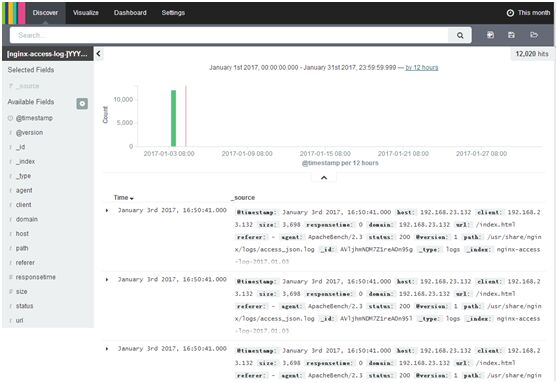
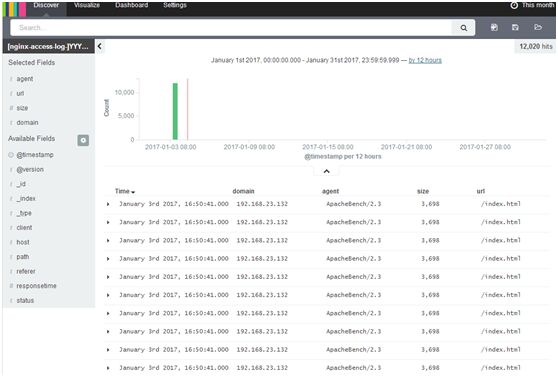
在search框内输入status:200,看搜索框的右下角,12020 hits

在search框内输入status:404,看搜索框右下角,0 hits

[root@test4 ~]# ab -n 1000 -c 10 http://192.168.23.132/nimeimei.html
redis 192.168.23.133:6379[2]> keys *
1) "nginx-access-log"
redis 192.168.23.133:6379[2]> keys *
1) "nginx-access-log"
redis 192.168.23.133:6379[2]> keys *
(empty list or set)
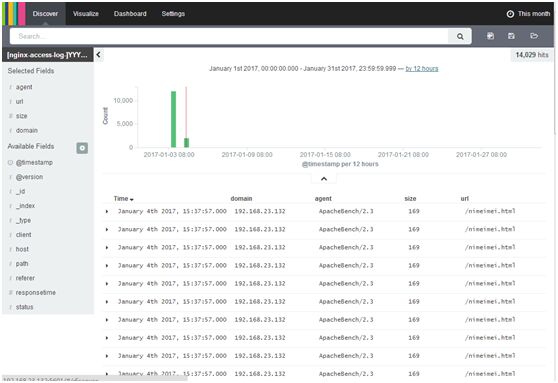
Available Fields中add进status
search框中输入,status:404
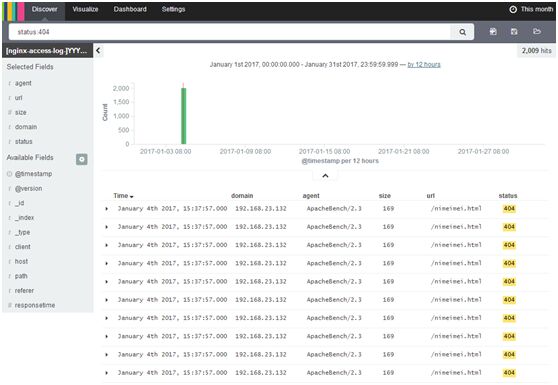
status:404 OR status:200,也可用AND、NOT、TO

status:[400 TO 499]
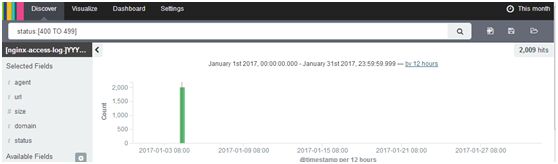
注:
status:200
status:404
status:200 OR status:404
status:[400 TO 499]
搜索框右侧第二个、第三个按钮分别为Save Search、Load Saved
Visualize:area chart, datatable, line chart, markdown widget, metric, pie chart, tile map, vertical barchart
if EXPRESSION {
……
} else if EXPRESSION {
……
} else {
……
}
举例:
input {
file {
type=> "apache"
path=> "/var/log/httpd/logs/access_log"
}
file {
type=> "php-error-log"
path=> "/var/log/php/php_errors.log"
}
}
output {
if [type] == "apache" {
redis{
host=> "192.168.23.133"
port=> "6379"
db=> "2"
data_type=> "list"
key=> "api-access-log-`HOSTNAME`"
}
}
if [type] == "php-error-log" {
redis{
host=> "192.168.23.133"
port=> "6379"
db=> "3"
data_type=> "list"
key=> "php-error-log"
}
}
if [type] == "api-run-log" {
redis{
host=> "192.168.23.133"
port=> "6379"
db=> "4"
data_type=> "list"
key=> "api-run-log"
}
}
}
注:json中不能有type字段,否则logstash不能收集到
学习ELK日志平台(三)的更多相关文章
- 学习ELK日志平台(二)
一.ELK介绍 1.1 elasticsearch 1.1.1 elasticsearch介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索 ...
- 学习ELK日志平台(四)
一:需求及基础: 场景: 1.开发人员不能登录线上服务器查看详细日志 2.各个系统都有日志,日志数据分散难以查找 3.日志数据量大,查询速度慢,或者数据不够实时 4.一个调用会涉及到多个系统,难以在这 ...
- 学习ELK日志平台(五)
ELK Stack 通常情况下: 1,开发人员是不能登录线上服务器查看日志信息 2,各个系统的日志繁多,日志数据分散难以查找 3,日志数据量较大,查询速度慢,数据不够实时性 4,一个调用会涉及到多个系 ...
- 学习ELK日志平台(一)
一.需求及基础: 场景: 1.开发人员不能登录线上服务器查看详细日志 2.各个系统都有日志,日志数据分散难以查找 3.日志数据量大,查询速度慢,或者数据不够实时 4.一个调用会涉及到多个系统,难以在这 ...
- ELK 日志平台构建
elastic中文社区 https://elasticsearch.cn/ 完整参考 ELK实时日志分析平台环境部署--完整记录 https://www.cnblogs.com/kevingrace/ ...
- elk日志平台搭建小记
最近抽出点时间,搭建了新版本的elk日志平台 elastaicsearch 和logstash,kibana和filebeat都是5.6版本的 中间使用redis做缓存,版本为3.2 使用的系统为ce ...
- Springboot项目使用aop切面保存详细日志到ELK日志平台
上一篇讲过了将Springboot项目中logback日志插入到ELK日志平台,它只是个示例.这一篇来看一下实际使用中,我们应该怎样通过aop切面,拦截所有请求日志插入到ELK日志系统.同时,由于往往 ...
- Springboot项目搭配ELK日志平台
上一篇讲过了elasticsearch和kibana的可视化组合查询,这一篇就来看看大名鼎鼎的ELK日志平台是如何搞定的. elasticsearch负责数据的存储和检索,kibana提供图形界面便于 ...
- 亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统.日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」 废话不多说,老司机们座好了, ...
随机推荐
- 开源报表工具太复杂?不如用这款免费web报表工具
随着信息系统的高速发展,报表平台逐渐成为了信息系统当中最为核心和重要的功能模块.报表工具有助于将原始数据可视化显示,使决策者或者相关人员能够一览整体的数据趋势,完整的报表解决方案会提供多样的表格数据展 ...
- Devops 开发运维高级篇之Jenkins+Docker+SpringCloud微服务持续集成——部署方案优化
Devops 开发运维高级篇之Jenkins+Docker+SpringCloud微服务持续集成--部署方案优化 之前我们做的方案部署都是只能选择一个微服务部署并只有一台生产服务器,每个微服务只有一个 ...
- IntelliJ:下载第三方库
学习自:(6条消息) IDEA中第三方软件包安装步骤_Li某人_初学者-CSDN博客 1.下载对应的软件包:以commons-logging为例 2.复制这个jar包到项目根目录下的lib目录下(li ...
- k8s-静态PV和动态PV
1.pv 简单介绍 PersistenVolume(PV):对存储资源创建和使用的抽象,使得存储作为集群中的资源管理 PV分为静态和动态,动态能够自动创建PV • PersistentVolumeCl ...
- 【转载】深入浅出SQL Server中的死锁
essay from:http://www.cnblogs.com/CareySon/archive/2012/09/19/2693555.html 简介 死锁的本质是一种僵持状态,是多个主体对于资源 ...
- 百度敏感词过滤(tp)
百度智能云网址https://cloud.baidu.com/ 1:打开网址->管理控制台->产品服务->SDK下载>内容审核->phpSDK 2:下载至php目录ser ...
- Linux下面怎么安装PHP扩展?
一般开发环境都是在windows上, 安装扩展也很容易, 直接把下载的.dll文件扔到ext下面, 改一下php.ini文件. 完事了. linux上有两种安装方法 1.编译安装 //下载文件 #wg ...
- CF594D题解
我不会数据结构/kk 我想题意应该十分清楚了. 我们知道 \(\varphi(p^k)=p^{k-1}(p-1)\),那么我们考虑将一个询问下放到右端点,然后往右移动右端点并更新每个左端点到右端点的答 ...
- pycharm实用常用快捷键
我们在实用pycharm时候,可以使用一些快捷键来帮助我们写代码. 1 alt + enter 快速导包,在需要导入包时候可以使用这个快捷键: 2 alt + 1 可以快速打开或者关闭左侧projec ...
- 解决jira配置gmail邮箱报错
具体报错: AuthenticationFailedException: 535-5.7.8 Username and Password not accepted. Learn more at 535 ...