python操作MySQL与MySQL补充
python操作MySQL
python中支持操作MySQL的模块很多,最常见是pymysql,pymysql属于第三方模块,需要自行下载。
pip install pymysql
基本使用
现有如下数据:
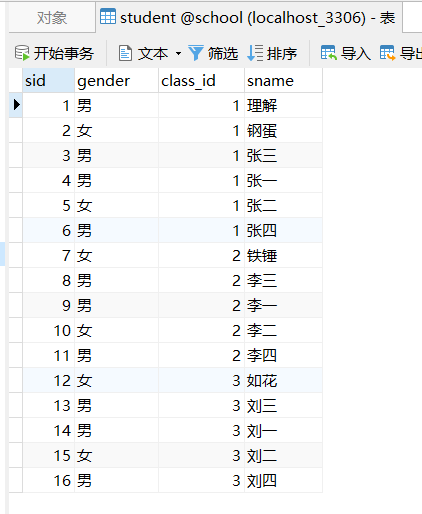
通过python代码获取数据:
# 1.导入模块import pymysql# 2.连接数据库db_obj = pymysql.connect(host='127.0.0.1', # MySQL服务端的IP地址port=3306, # MySQL默认PORT地址(端口号)user='root', # 用户名password='123456', # 密码,也可以简写passwd=database='school', # 库名称,也可以简写db=charset='utf8' # 字符编码,千万不要加杠utf-8)# 3.产生获取命令的游标对象cursor = db_obj.cursor() # 不写参数返回的是元组# 4.编写SQL语句sql = 'select * from student;'# 5.执行SQL语句affect_rows = cursor.execute(sql) # 返回的是受影响的行数print(affect_rows)# 6.获取全部结果res = cursor.fetchall()print(res)

对于游标对象,不写参数时每一个记录默认返回的是元组类型,如果想要返回其他类型,比如字典类型,可以在产出游标对象时加上参数:
cursor = db_obj.cursor(cursor=pymysql.cursors.DictCursor)

补充说明
在获取SQL语句执行的结果时,跟读取文件内容的read方法几乎一致(光标)。
- fetchall()可以获取当前光标到结尾的全部数据,并把光标移到末尾。
- fetchone()可以获取当前光标往后一个的数据,并把光标往后移动一位。
- fetchmany()可以获取当前光标往后任意个数据,并把光标往后移动相应的位数,比如fetchmany(3)就是获取三个数据。
此外,还有可以控制光标移动的方法:
- 游标对象.scroll(m, 'relative'),相对于当前位置往后移动m个单位
- 游标对象.scroll(m, 'absolute'),相对于起始位置往后移动m个单位
SQL注入问题
先看一个例子:
数据:
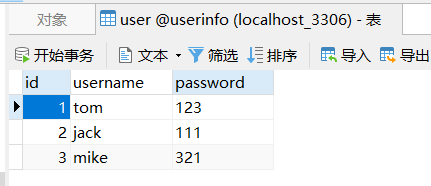
代码:
import pymysqldb_obj = pymysql.connect(host='127.0.0.1', port=3306,user='root', password='332525',db='userinfo')cursor = db_obj.cursor(cursor=pymysql.cursors.DictCursor)# 获取输入username = input('请输入用户名:')password = input('请输入密码:')sql = "select * from user where username='%s' and password='%s'" % (username, password)print(sql)cursor.execute(sql)res = cursor.fetchall()if res:print('登录成功!')else:print('用户名或密码错误')
运行后输入,tom,123,登录成功!这是没有问题的,但是如果你这么输入(只输入用户名):
请输入用户名:tom' -- abc密码:
这时还是登录成功。
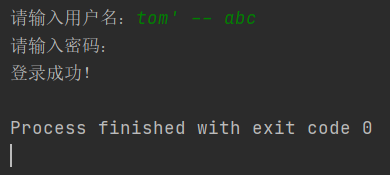
我们可以把sql语句输出看一看:
select * from user where username='tom' -- abc' and password=''
我们发现,后面的密码比对的条件被注释了,这就是典型的SQL注入问题。
解决方法
execute方法自带校验SQL注入问题,自动处理特殊符号。
把执行SQL语句这么写就行了:
# 获取输入username = input('请输入用户名:')password = input('请输入密码:')sql = "select * from user where username=%s and password=%s"res = cursor.execute(sql, (username, password))
execute还可以批量写入数据,如:
sql = 'insert into userinfo(name,password) values(%s,%s)'cursor.executemany(sql,[('tom',123),('lavin',321),('pony',333)])
二次确认
在使用刚刚所学的python代码修改数据库数据时,你会发现明明没有报错,确无法把数据库里的数据修改。
这是因为pymysql针对增、改、删三个操作,都设置了二次确认,如果不确认则不会真正影响数据库。
方法一:手动提交
cursor.execute(sql)db_obj.commit() # 手动二次确认
方法二:连接数据库时配置固定参数
db_obj = pymysql.connect(autocommit=True # 自动二次确认)
视图
视图的概念:通过SQL语句的执行得到的一张虚拟表,保存下来之后就称之为'视图'。
创建视图语法:
create view 视图名 as SQL语句
视图只能用于数据的查询,不能做增、删、改的操作,可能会影响原始数据,因为视图里面的数据是直接来源于原始表,而不是拷贝一份。
优点:如果需要频繁的使用一张虚拟表,可以考虑制作成视图,降低操作难度。
缺点:视图虽然看似很好用,但是会造成表的混乱,再使用show tables时,视图也会一并展示出来,会让人分不清这是表还是视图。
触发器
触发器概念:在对表数据进行增、删、改的具体操作下,自动触发的功能。
作用:专门针对表数据的操作,定制个性化配套功能。
| 触发器种类 | 含义 |
|---|---|
| before insert | 新增数据之前触发 |
| before update | 新增数据之前触发 |
| before delete | 删除数据之前触发 |
| after insert | 删除数据之后触发 |
| after update | 更新数据之后触发 |
| after delete | 更新数据之后触发 |
创建触发器语法:
delimiter $$ # 需要先将mysql默认的结束符由;换成$$create trigger 触发器名字 before/after insert/update/delete on 表名 for each rowbegin触发后执行的SQL语句;end $$delimiter ; # 结束之后记得再改回来,不然后面结束符就都是$$了
查看当前库中所有的触发器信息:
show triggers;
删除当前库下指定的触发器信息:
drop trigger 触发器名称;

事务
事务的概念:由数据库操作语句构成,事务可以用来维护数据库的数据的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
事务的四大特性(ACID):
- 原子性(A):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。
- 一致性(C):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
- 隔离性(I):一个数据库可以有多个事务,事务之间是互相隔离的,彼此不干扰。
- 持久性(D):事务处理结束后,对数据的修改就是永久的。
基本使用
| 使用 | 含义 |
|---|---|
| start transaction; | 开启事务 |
| rollback; | 事务回滚(返回执行事务操作之前的数据库状态) |
| commit; | 提交事务(提交后事务结束,无法回滚了) |
案例
# 创建表并添加数据create table user(id int primary key auto_increment,name char(32),balance int);insert into user(name,balance)values('jason',1000),('kevin',1000),('tank',1000);# 开启事务start transaction;# 事务内容(SQL语句)update user set balance=900 where name='jason';update user set balance=1010 where name='kevin';update user set balance=1090 where name='tank';# 事务回滚# rollback; 如果回滚了那么以上的数据都会变回原来的状态# 提交事务commit;
存储过程
存储过程相当于一个函数。
定义与调用:
无参存储过程:
delimiter $$create procedure 存储过程名()beginSQL语句;end $$delimiter ;
调用:
call 存储过程名();
有参存储过程:
delimiter $$create procedure 存储过程名(in|out|inout 参数1 参数1类型,in|out|inout 参数2 参数2类型,...)beginSQL语句;end $$delimiter ;
- in表示这个参数必须只能是传入不能被返回出去
- out表示这个参数可以被返回出去
- inout表示即可以传入也可以被返回出去
对于可以返回出去的参数,需要提前定义:
set @返回的参数=值; # 定义call 存储过程(各项参数) # 调用存储过程select @返回的参数 # 查看是否变化# 比如有存储过程create procedure p1(in m int, out res int)set @res=10; # 定义返回的参数call p1(5,@res) # 调用存储过程select @res # 查看是否变化
| 关于存储过程的SQL语句 | 作用 |
|---|---|
| show create procedure 存储过程名; | 查看存储过程具体信息 |
| show procedure status; | 查看所有存储过程 |
| drop procedure 存储过程名; | 删除存储过程 |

函数
mysql有许多内置的函数。
| 内置函数 | 作用 |
|---|---|
| Trim(字符串) | 移除字符串两边空格 |
| Trim(leading 字符 from 字符串) | 移除开头的指定字符 |
| Trim(both 字符 from 字符串) | 移除两边指定字符 |
| Trim(trailing 字符 from 字符串) | 移除末尾的指定字符 |
| LTrim(字符串) | 移除字符串左边空格 |
| RTrim(字符串) | 移除字符串右边空格 |
| Lower(字符串) | 字符串全转小写 |
| Upper(字符串) | 字符串全转大写 |
| Left(字符串,m) | 获取字符串左边m个字符 |
| Right(字符串,m) | 获取字符串右边m个字符 |
| Soundex(字符串) | 返回读音相似字符 |
| date_format(时间字符串,转成的格式) | 把时间字符串转成想要的格式 |
trim()
Examples:mysql> SELECT TRIM(' bar ');-> 'bar'mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');-> 'barxxx'mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');-> 'bar'mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');-> 'barx'
ltrim()
Examples:mysql> SELECT LTRIM(' barbar');-> 'barbar'
rtrim()
Examples:mysql> SELECT RTRIM('barbar ');-> 'barbar'
lower()
mysql> SELECT LOWER('QUADRATICALLY');-> 'quadratically'
upper()
mysql> SELECT UPPER('Hej');-> 'HEJ'
left()
Examples:mysql> SELECT LEFT('foobarbar', 5);-> 'fooba'
right()
Examples:mysql> SELECT RIGHT('foobarbar', 4);-> 'rbar'
soundex()
Examples:mysql> SELECT SOUNDEX('Hello');-> 'H400'mysql> SELECT SOUNDEX('Quadratically');-> 'Q36324'
date_format()
Examples:mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y');-> 'Sunday October 2009'mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s');-> '22:23:00'mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00',-> '%D %y %a %d %m %b %j');-> '4th 00 Thu 04 10 Oct 277'mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',-> '%H %k %I %r %T %S %w');-> '22 22 10 10:23:00 PM 22:23:00 00 6'mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V');-> '1998 52'mysql> SELECT DATE_FORMAT('2006-06-00', '%d');-> '00'
流程控制
MySQL if判断,只能放在begin·end中
if 条件 then子代码elseif 条件 then子代码else子代码end if;
MySQL while循环,只能放在begin·end中
while 条件 do子代码end while;

索引
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构:
- 主键:primary key
- 唯一键:unique key
- 索引键:index key
上面三种键前两种除了有加速查询的效果之外还有额外的约束条件,而index key没有任何约束功能只会帮你加速查询。
索引的影响:
- 在表中有大量数据的前提下,创建索引速度会很慢
- 在索引创建完毕后,对表的查询性能会大幅度提升,但是写的性能会降低,因为每次更新数据的同时也会更新索引。
索引的底层数据结构b+树
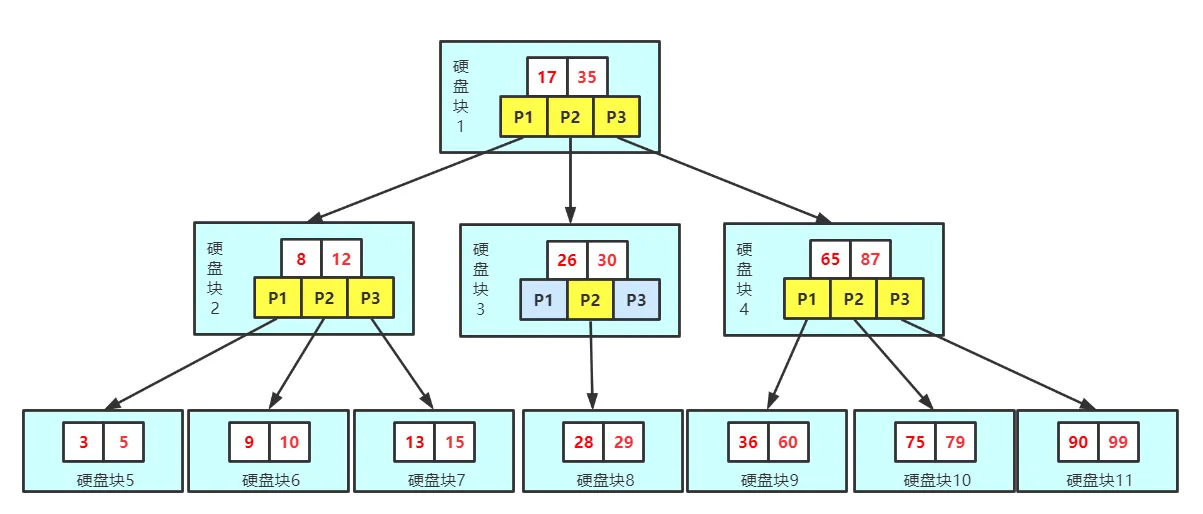
只有叶子结点存放真实数据,根和树枝节点存的仅仅是虚拟数据。
查询次数由树的层级决定,层级越低次数越少。
一个磁盘块儿的大小是一定的,那也就意味着能存的数据量是一定的。如何保证树的层级最低呢?一个磁盘块儿存放占用空间比较小的数据项。
思考我们应该给我们一张表里面的什么字段字段建立索引能够降低树的层级高度>>> 主键id字段(一个整型肯定比其他类型小)
聚集索引(primary key)
如果在表中创建了主键约束,SQL Server将自动为其产生唯一性约束。在创建主键约束时,指定了CLUSTERED关键字或干脆没有制定该关键字,SQL Sever将会自动为表生成唯一聚集索引。
辅助索引(unique key,index key)
查询数据的时候不可能都是用主键作为筛选条件,也可能会用其他字段,那么这个时候就无法利用到聚集索引的加速查询效果。就需要给其他字段建立索引,这些索引就叫辅助索引。
特点:叶子结点存放的是辅助索引字段对应的那条记录的主键的值(比如:按照name字段创建索引,那么叶子节点存放的是:{name对应的值:name所在的那条记录的主键值})
覆盖索引与非覆盖索引
覆盖索引指只在辅助索引的叶子节点中就已经找到了所有我们想要的数据,比如:
select name from user where name='jason';
非覆盖索引指查询的时候命中了索引字段,但是要查的是其他字段,所以还需要利用主键才去查找
select age from user where name='jason';
练习
使用MySQL作为数据库,编写用户名注册登录功能
点击查看代码
import pymysqldb_obj = pymysql.connect(host='127.0.0.1', port=3306,user='root', password='332525',db='userinfo')cursor = db_obj.cursor(cursor=pymysql.cursors.DictCursor)def login():username = input('请输入用户名:')password = input('请输入密码:')sql = "select * from user where username=%s and password=%s"res = cursor.execute(sql, (username, password))if res:print('登录成功!')else:print('用户名或密码错误')def register():username = input('请输入用户名:')password = input('请输入密码:')sql_select = "select * from user where username=%s"res = cursor.execute(sql_select, (username,))if res:print('用户名已存在!')returnsql_insert = "insert into user(username,password) value(%s, %s)"cursor.execute(sql_insert, (username, password))print('注册成功!')while True:print("""1.登录2.注册""")func_dict = {'1': login,'2': register,}choose = input('请输入指令:')if choose in func_dict:func_dict[choose]()else:print('指令错误!')
python操作MySQL与MySQL补充的更多相关文章
- Python操作数据库之 MySQL
Python操作数据库之MySQL 一.安装Python-MySQLdb模块 Python-MySQLdb是一个操作数据库的模块,Python 通过它对 mysql 数据实现各种操作. 如果要源码安装 ...
- python操作db2和mysql ,ibm_db
我需要提取mysql和db2的数据进行对比,所以需要用python对其都进行操作. python对mysql进行操作应该没什么问题,就是安装drive后就可以了,在上一篇中有讲安装python-mys ...
- Python学习笔记(五)之Python操作Redis、mysql、mongodb数据库
操作数据库 一.数据库 数据库类型主要有关系型数据库和菲关系型数据库. 数据库:用来存储和管理数的仓库,数据库是通过依据“数据结构”将数据格式化,以记录->表->库的关系存储.因此数据查询 ...
- python操作MongoDB、MySQL、Postgres、Sqlite、redis实例
总结:除了MongoDB.redis,其他三个数据库用python来操作其实是差不多的.所有例子都很简单,实际生产环境中的数据库操作远比这复杂得多,命令也比我例子中的多得多,我这里高级一点的用法就是批 ...
- python操作数据库(Mysql)
原文地址:https://www.cnblogs.com/R-bear/p/7022231.html python DB-API介绍 1.python标准数据库接口为 python DB-API,py ...
- 使用python操作InfluxDB
环境: CentOS6.5_x64InfluxDB版本:1.1.0Python版本 : 2.6 准备工作 启动服务器 执行如下命令: service influxdb start 示例如下: [roo ...
- 多表查询思路、navicat可视化软件、python操作MySQL、SQL注入问题以及其他补充知识
昨日内容回顾 外键字段 # 就是用来建立表与表之间的关系的字段 表关系判断 # 一对一 # 一对多 # 多对多 """通过换位思考判断""" ...
- Day12(补充) Python操作MySQL
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb ...
- python 操作 mysql基础补充
前言 本篇的主要内容为整理mysql的基础内容,分享的同时方便日后查阅,同时结合python的学习整理python操作mysql的方法以及python的ORM. 一.数据库初探 在开始mysql之前先 ...
随机推荐
- 对height 100%和inherit的总结
对height 100%和inherit的总结 欢迎大家来我的博客留言:https://sxq222.github.io/CSS%...博客主页:https://sxq222.github.io 正文 ...
- python-你好
你的程序会读入一个名字,比如John,然后输出"Hello John". 输入格式: 一行文字. 输出格式: 一行文字. 输入样例: Mary Johnson 输出样例: Hell ...
- String和int、long、double等基本数据类型的转换
学习目标: 掌握Java的基本数据类型与String的转换 学习内容: 1.转化规则 String 转 基本数据类型 基本数据类型 变量 = 包装类.Parse基本数据类型(String); // c ...
- box-shadow 阴影的高级用法,多个阴影叠加
box-shadow的这些用法你知道吗? $shadowH: ''; @for $i from 1 through 12 { $shadowH: #{$shadowH}, 0 ($i * 30px) ...
- 最长非降子序列的N*logN解法
之前讲到过求最长非降子序列的O(N^2)解法. 链接 这次在原来的基础上介绍一下N*logN解法. 该解法主要是维护一个数组minValue,minValue[i]表示最长上身子序列长度为i的数的最小 ...
- Java语言学习day17--7月23日
1.面向对象思想2.类与对象的关系3.局部变量和成员变量的关系4.封装思想5.private,this关键字6.随机点名器 ###01面向对象和面向过程的思想 * A: 面向过程与面向对象都是我们编程 ...
- 2021.08.05 P5357 康托展开模板(康托展开)
2021.08.05 P5357 康托展开模板(康托展开) P5367 [模板]康托展开 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 重点: 1.康托展开 算法学习笔记(56): ...
- Blazor Bootstrap 组件库 Toast 轻量弹窗组件介绍
轻量级 Toast 弹窗 DEMO https://www.blazor.zone/toasts 基础用法: 用户操作时,右下角给予适当的提示信息 <ToastBox class="d ...
- Delphi 类库(DLL)动态调用与静态调用示例讲解
在Delphi或者其它程序中我们经常需要调用别人写好的DLL类库,下面直接上示例代码演示如何进行动态和静态的调用方法: { ************************************** ...
- 爬虫亚马逊Bestselling类别产品数据TOP100
1 # -*- coding: utf-8 -*- 2 # @Time : 2020/9/11 16:23 3 # @Author : Chunfang 4 # @Email : 3470959534 ...