Kafka 万亿级消息实践之资源组流量掉零故障排查分析
作者:vivo 互联网服务器团队-Luo Mingbo
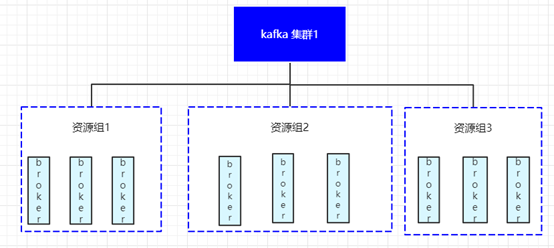
一、Kafka 集群部署架构
为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下我们 Kafka 集群的部署架构及服务接入 Kafka 集群的流程。
为了避免超大集群我们按照业务维度将整个每天负责十万亿级消息的 Kafka 集群拆分成了多个 Kafka 集群。拆分粒度太粗会导致单一集群过大,容易由于流量突变、资源隔离、限速等原因导致集群稳定性和可用性受到影响,拆分粒度太细又会因为集群太多不易维护,集群内资源较少应对突发情况的抗风险能力较弱。
由于 Kafka 数据存储和服务在同一节点上导致集群扩缩容周期较长,遇到突发流量时不能快速实现集群扩容扛住业务压力,因此我们按照业务维度和数据的重要程度及是否影响商业化等维度进行 Kafka 集群的拆分,同时在 Kafka 集群内添加一层逻辑概念“资源组”,资源组内的 Node 节点共享,资源组与资源组之间的节点资源相互隔离,确保故障发生时不会带来雪崩效应。
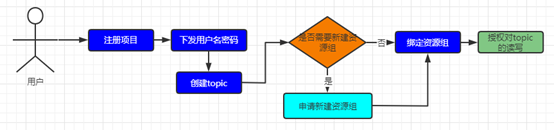
二、业务接入 Kafka 集群流程
在 Kafka 平台注册业务项目。
若项目的业务数据较为重要或直接影响商业化,用户需申请创建项目独立的资源组,若项目数据量较小且对数据的完整性要求不那么高可以直接使用集群提供的公共资源组无需申请资源组。
项目与逻辑概念资源组绑定。
创建 topic,创建 topic 时使用 Kafka 平台提供的接口进行创建,严格遵守 topic 的分区分布只能在项目绑定的资源组管理的 broker 节点上。
授权对 topic 的读写操作。
通过上述的架构部署介绍及接入流程接入介绍相信大家有很多相关知识点都与小编对齐了。
从部署架构图我们可以清晰的了解到我们这套集群部署在服务端最小的资源隔离单元为“资源组”即在同一个资源组下的多个broker节点之间会有影响,不同的资源组下的broker节点做了逻辑隔离。
上述的相关知识点对齐后我们将开启我们的故障排查之旅。
三、故障情况介绍
故障发生时,故障节点所在资源组的多个 topic 流量几乎全部掉零,生产环境我们对 Kafka 集群的磁盘指标READ、WRITE、IO.UTIL、AVG.WAIT、READ.REQ、WRITE.REQ做了告警监控,由于故障发生在凌晨,整个故障的处理过程持续实践较长,导致了业务方长时间的topic流量整体掉零对业务造成不小的影响。
四、监控指标介绍
4.1 流量监控情况
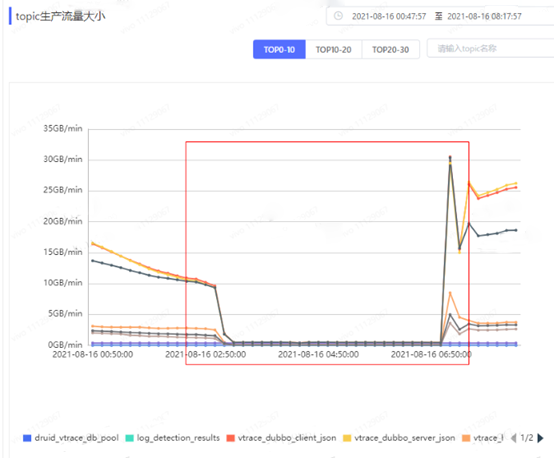
1、故障节点在故障发生时网络空闲率出现短暂的掉零情况,且与生产流量监控指标一致。一旦生产流量上升故障节点的网络空闲率就同步掉零。
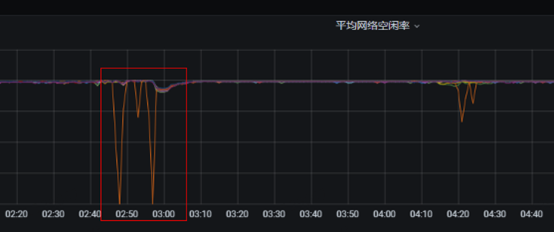
2、Grafana 监控指标中topic生产流量几乎全部掉零。
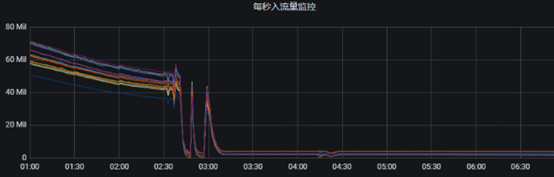
3、Kafka 平台项目监控中也体现了当前项目的多个topic生产流量指标掉零。
4.2 磁盘指标监控
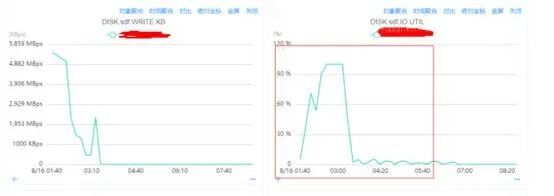
SDF 盘的IO.UTIL指标达到100%, 80%左右我们认为是服务可稳定运行的指标阈值。
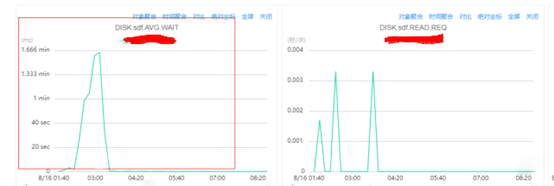
SDF 盘的AVG.WAIT指标达到分钟级等待,一般400ms左右的延迟我们认为是服务可稳定运行的阈值。
4.3 Kafka 服务端日志及系统日志情况
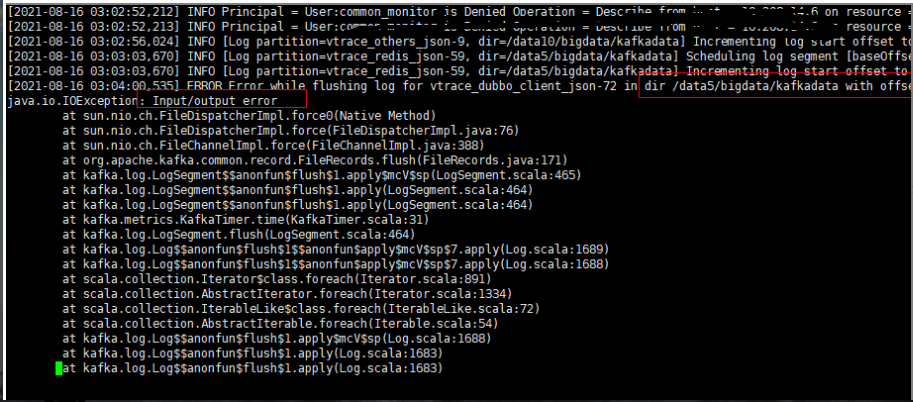
Kafka集群controller节点的日志中出现Input/Output error的错误日志。
Linux 系统日志中出现Buffer I/O error 的错误日志
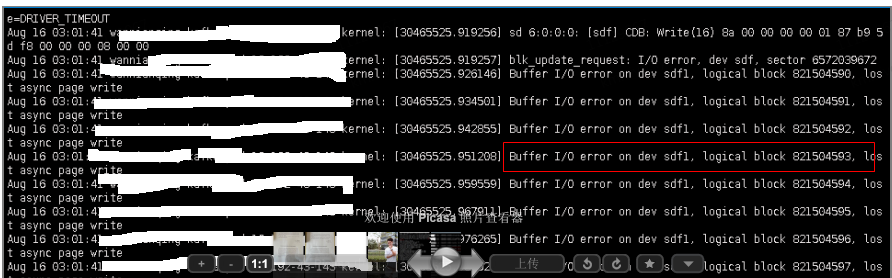
五、故障猜想及分析
从上述的指标监控中很明显的可以得出结论,故障原因是由于 Kafka broker节点的sdf盘磁盘故障导致的,只需在对应的 Kafka broker 节点上将sdf盘踢掉重启即可恢复。那这样就结束了吗 ?of course not。
对 Kafka 有一定认识的小伙伴应该都知道,创建topic时topic的分区是均匀分布到集群内的不同broker节点上的,即使内部某一台broker节点故障,其他分区应该能正常进行生产消费,如果其他分区能进行正常的生产和消费就不应该出现整个topic的流量几乎全掉零的情况。
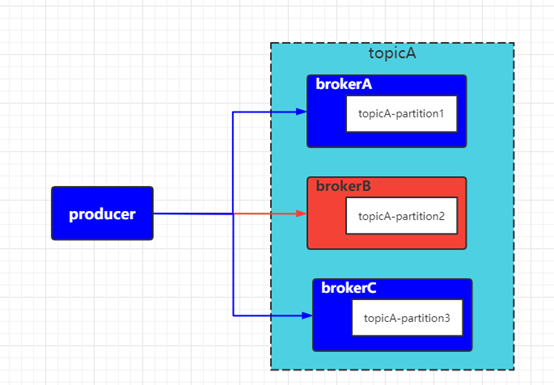
如上图所示,topicA 的三个分区分别分布在 brokerA、brokerB、brokerC三个物理主机节点上。
生产者producer向TopicA发送消息时会分别与brokerA、brokerB、brokerC三个物理主机节点建立长链接进行消息的发送,此时若 brokerB 节点发生故障无法向外部提供服务时按照我们的猜想应该不会影响到brokerA和brokerC两个节点继续向producer提供接收消息的服务。
但从监控指标的数据展示来分析当brokerB节点出现故障后topic整体流量掉零与我们的猜想大相径庭。
既然是出现类似了服务雪崩的效应导致了部分topic的整体流量几乎掉零那么我们在猜想问题发生的原因时就可以往资源隔离的方向去思考,看看在整个过程中还有哪些地方涉及到资源隔离的环节进行猜想。
Kafka 服务端我们按照资源组的方式做了 Kafka broker的逻辑隔离且从Grafana监控上可以看出有一些topic的流量并没有严重掉零的情况,那么我们暂时将分析问题的目光转移到 Kafka client端,去分析 Kafka producer的发送消息的过程是否存在有资源隔离地方没有做隔离导致了整体的雪崩效应。
六、Kafka 默认分区器的分区规则
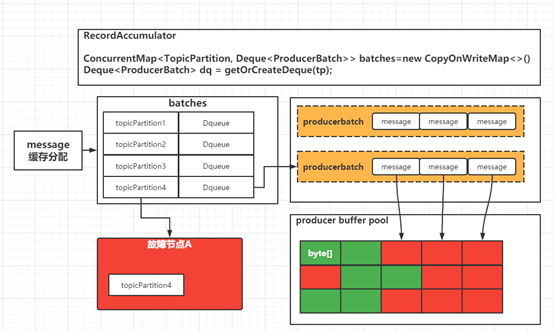
对 Kafka 生产流程流程有一定了解的同学肯定知道,Kafka 作为了大数据生态中海量数据的消息中间件,为了解决海量数据的并发问题 Kafka 在设计之初就采用了客户端缓冲消息,当消息达到一定批量时再进行批量消息的发送。
通过一次网络IO将批量的数据发送到 Kafka 服务端。关于Kafka producer客户端缓冲区的设计小编后续会单独一个篇幅进行深入的探索,鉴于篇幅问题不再此处进行详细分析。
基于此处的分析我们对一批消息发送到一个故障节点时的容错方案可以有以下猜想:
快速失败,记录故障节点信息。下次进行消息路由时只路由到健康的节点上。快速释放消息缓冲内存。
快速失败,记录故障节点信息,下次进行消息路由时当消息路由到故障节点上时直接报错,快速释放缓冲区内存。
等待超时,当次消息等待超时后,下次进行消息路由时依然会出现路由到故障节点上的情况,且每次等待超时时间后才释放占用的资源。
上述猜想中,如果是第一种情况,那么每次消息路由只路由到健康的节点上不会出现雪崩效应耗尽客户端缓冲区资源的情况;
第二种情况,当消息路由到故障节点上时,直接拒绝分配缓冲区资源也不会造成雪崩效应;
第三种情况,每次需要在一个或多个超时时间后才能将故障节点所占用的客户端缓冲区资源释放,在海量消息发送的场景下一个超时时间周期内故障节点上的消息足以将客户端缓冲区资源耗尽,导致其他可用分区无法分配客户端缓冲区资源导致出现雪崩效应。
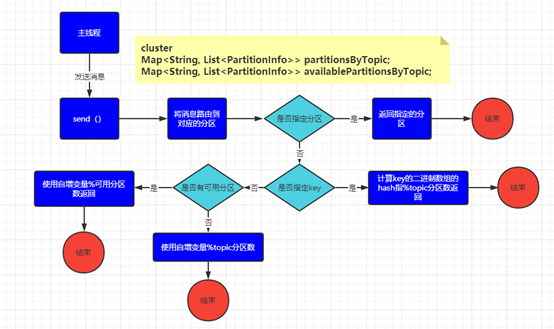
带着上述的猜想打开kafka client producer的源代码分析下defaultPartitioner的分区规则得到如下的分配逻辑:
发送消息时是否指定了分区,若指定了分区那消息就直接发往该分区无需重新路由分区。
消息是否指定了key,若消息指定了key,使用key的hash值与topic的分区数进行模运算,得出消息路由的分区号(对应第三种猜想)。
消息未指定分区也未指定key,使用自增变量与topic的可用分区进行模运算,得出消息路由的分区号(对应第一种猜想)。
七、总结
从源码中分析出若发送消息的时候指定了key,并使用的是 Kafka producer默认的分区分配器请款下会出现 Kafka producer 客户端缓冲区资源被耗尽而出现topic所有分区雪崩效应。
跟业务系统同学了解了他们的发送逻辑确实在消息发送指定了key并使用的是 Kafka producer的默认分区分配器。
问题得到论证。
八、建议
若非必要发送消息时不要指定key,否则可能会出现topic所有分区雪崩效应。
若确实需要发送消息指定key,建议不要使用Kafka producer默认的分区分配器,因为指定key的情况下使用 Kafka producer的默认分区分配器会出现雪崩效应。
九、扩展问题思考
为什么 Kafka producer提供的默认分区分配器要单独将指定key的情况采用topic所有分区进行模运算而在未指定key的采用是自增变量和可用分区进行模运算?
文章中分析的问题均为客户端缓冲区的粒度是producer实例级别的即一个producer共用一块内存缓冲区是否可以将缓冲区的粒度调整到分区级?
关于这系列的问题思考与分析,我们将在后续的文章中讲述,敬请关注。
Kafka 万亿级消息实践之资源组流量掉零故障排查分析的更多相关文章
- Kafka万亿级消息实战
一.Kafka应用 本文主要总结当Kafka集群流量达到 万亿级记录/天或者十万亿级记录/天 甚至更高后,我们需要具备哪些能力才能保障集群高可用.高可靠.高性能.高吞吐.安全的运行. 这里总结内容主 ...
- 腾讯自研万亿级消息中间件TubeMQ为什么要捐赠给Apache?
导语 | 近日,云+社区技术沙龙“腾讯开源技术”圆满落幕.本次沙龙邀请了多位腾讯技术专家围绕腾讯开源与各位开发者进行探讨,深度揭秘了腾讯开源项目TencentOS tiny.TubeMQ.Kona J ...
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- 如何基于MindSpore实现万亿级参数模型算法?
摘要:近来,增大模型规模成为了提升模型性能的主要手段.特别是NLP领域的自监督预训练语言模型,规模越来越大,从GPT3的1750亿参数,到Switch Transformer的16000亿参数,又是一 ...
- 万亿级KV存储架构与实践
一.KV 存储发展历程 我们第一代的分布式 KV 存储如下图左侧的架构所示,相信很多公司都经历过这个阶段.在客户端内做一致性哈希,在后端部署很多的 Memcached 实例,这样就实现了最基本的 KV ...
- 腾讯万亿级分布式消息中间件TubeMQ正式开源
TubeMQ是腾讯在2013年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条.较之于众多明星的开源MQ组件,T ...
- 手机QQ公众号亿级消息实时群发架构
编者按:高可用架构分享及传播在架构领域具有典型意义的文章,本文由孙子荀分享.转载请注明来自高可用架构公众号 ArchNotes. 孙子荀,2009 年在华为从事内核和分布式系统的开发工作:2011 ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- 【HBase调优】Hbase万亿级存储性能优化总结
背景:HBase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对HBase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,HBase入 ...
随机推荐
- 无需Flash实现图片裁剪——HTML5中级进阶
前言 图片裁剪上传,不仅是一个很贴合用户体验的功能,还能够统一特定图片尺寸,优化网站排版,一箭双雕. 需求就是那么简单,在浏览器里裁剪图片并上传到服务器. 我第一个想到的方法就是,将图片和裁剪参数(x ...
- Linux 0.11源码阅读笔记-内存管理
内存管理 Linux内核使用段页式内存管理方式. 内存池 物理页:物理空闲内存被划分为固定大小(4k)的页 内存池:所有空闲物理页组成内存池,以页为单位进行分配回收.并通过位图记录了每个物理页是否空闲 ...
- Java/C++实现解释器模式---机器人控制程序
某机器人控制程序包含一些简单的英文指令,其文法规则如下: expression ::= direction action distance | composite composite ::= expr ...
- Android Studio安装问题
安装问题可以参考:https://blog.csdn.net/y74364/article/details/96121530 但是gradle安装缓慢,需要FQ.有加速器FQ的可以开加速器安装,没有的 ...
- Configuration类的理解
Configuration类主要用来读取配置文件,启动Hibernate,并负责Hibernate的配置信息.一个应用程序只创建一个Configuration. 在Hibernate启动过程中,Con ...
- Jenkins 脚本命令行应用总结
Jenkins脚本命令行应用总结 测试环境 Jenkins 2.304 脚本命令行入口 Jenkins主页→系统管理→脚本命令行 遍历项目 例子:获取所有自由风格项目及相关项目信息 def proje ...
- python函数基础算法简介
一.多层语法糖本质 """ 语法糖会将紧挨着的被装饰对象名字当参数自动传入装饰器函数中""" def outter(func_name): ...
- 更改docker默认的data,metadata存储大小(实操)
为什么要更改 data,metadata呢?我们运行环境中涉及大量数据操作,数据增长有时候很快,由于之前规划不足,所以磁盘很快达到瓶颈需要进行重新部署.这就需要调整原来的一些docker配置.操作系统 ...
- 搭建MySQL集群-注意版本
系统环境采样(来自其他机器,直接copy过来的,在安装的机器上,按照步骤查看即可,当然这些还不够实际,后续补充) 检查系统内是否有其他mysql rpm -qa | grep mysql 是否存在my ...
- Thinkphp设计模式和执行流程
ThinkPHP设计模式 单例模式:数据库连接DB工厂模式:比如Db.class.php中的factory()方法适配器模式:驱动类,数据库观察者模式:Hook类 注册树模式:绑定容器外观模式:fac ...