Python入门-深入了解数据类型以及方法
写在开始:每一种数据类型,有对应一种功能,面对不同的问题,使用不同类型。
1.全部数据类型
1.2数值型:解决数字的计算问题
#基础的计算,求除结果,求商,求余数
print(10 / 3)
print(10 // 3)
print(10 % 3)
"""
3.3333333333333335
3
1
"""
#基础数学函数方法
abs(x) #返回数字x的绝对值,如abs(-10) 返回 10
max(序列) #求序列中的最大值
min(序列) #求序列中的最小值
pow(2, 3) #求2的3次方 #math函数用法
math.ceil() #向上取整
math.floor() #向下取整,等于int()取整
math.modf() #返回小数的整数以及小数部分。返回类型为元祖tuple
math.exp(x) #返回e的x次方
math.cmp(x, y) # 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1
math.log(x) # 返回e为底的logx对数 math.log10(x) #返回log10的x对数 math.modf(x) #返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
math.sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j
math.pi #返回数字常量pi,圆周率
math.e #返回数字常量e,即自然常数 #round函数,四舍五入
round() #该函数有bug,偶数.5不会进1,使用时注意修正
提供思路如下:
a = 5.5
b = round(a)+1 if (a-0.5) %2 ==0 else round(a)
print(b) #三角函数
acos(x) 返回x的反余弦弧度值。
asin(x) 返回x的反正弦弧度值。
atan(x) 返回x的反正切弧度值。
atan2(y, x) 返回给定的 X 及 Y 坐标值的反正切值。
cos(x) 返回x的弧度的余弦值。
hypot(x, y) 返回欧几里德范数 sqrt(x*x + y*y)。
sin(x) 返回的x弧度的正弦值。
tan(x) 返回x弧度的正切值。
degrees(x) 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0
radians(x) 将角度转换为弧度 import operator #比较两个常量的是否相等,相等返回True,否则返回False
operator.eq(2,3)
operator.eq("name","name")
1.2字符型:代码的基本类型
# 转换
eval():将str转换为有效的表达式
upper():将小写字母转换为大写
lower():大---》小
swapcase():大---》小 小----》大
capitalize():首单词的首字母大写,其他全部小写
title():每个单词的首字母大写,其他全部小写
ord(),chr() #查找
find():从左往右进行检索,返回被查找的子字符串在原字符串中第一次出现的位置,如果查找不到返回-1
rfind():从右往左进行检索
index():从左往右进行检索,返回被查找的子字符串在原字符串中第一次出现的位置,如果查找不到则直接报错
rindex():从右往左进行检索 #填充和提取
center(width[,fillchar]):用fillchar填充指定的字符串,填充之后的长度为width,原字符串居中显示
ljust(width[,fillchar]):用fillchar填充指定的字符串,填充之后的长度为width,原字符串居左显示
rjust(width[,fillchar]):用fillchar填充指定的字符串,填充之后的长度为width,原字符串居右显示
zfill(width):原字符串居右显示,剩余的字符默认用0填充
strip():去除一个指定字符串中两端指定的子字符
lstrip():去除一个指定字符串中左边指定的子字符
rstrip():去除一个指定字符串中右边指定的子字符 #合并和分割
str1 + str2:数量少推荐+法使用,数量多推荐join
join():使用指定的子字符串将列表中的元素连接【列表-----》字符串】
split():使用指定的子字符串将原字符串进行分割,得到一个列表 【字符串-----》列表】 #判断字符串的开头结尾
print(name.startswith("h")) # 判断以什么开头-->startswith
print(name.endswith("d")) # 判断以什么结尾-->endswith
print(name.endswith("r",0,9)) # 限制查询范围
注意单词中的S,很容易写漏!!!
#字符串类型判断
isalpha():一个字符串非空并字符全部是字母才返回True
isalnum():一个字符串非空并字符是字母或者数字才返回True
isupper()/islower()/istitle():和upper,lower,title有关
isdigit()/isdecimal():一个字符串非空并字符全部是数字才返回True #替换字符的两种方法
print(name.replace("hello", "hi",次数)) # 使用replace( )替换参数,可以指定替换次数
name = "hello word"
a = "abcde"
b = "我是中国人"
res = str.maketrans(a, b)
info = "dadchdjadkses"
res_info = info.translate(res)
print(res_info)
"""
国我国中h国j我国ks人s
""" #格式化输出======================================================================
格式化输出format()
format可以使用传入参数的方式赋值,还有一个%的格式化方法,与format相似,但是不能参数方式传值,不推荐使用。 name = "zhangsan"
age = 22
print("我的名字是:{} ,我今年:{}".format(name, age))
print("我的名字是:{1} ,我今年:{0}".format(age, name))
print("我的名字是:{name} ,我今年:{age}".format(age=age, name=name))
"""
我的名字是:zhangsan ,我今年:22
我的名字是:zhangsan ,我今年:22
我的名字是:zhangsan ,我今年:22
""" # format_map()的使用方式与formap相似
print("my name is :{name}, age is:{age} ".format_map({"name":"zhangsan","age":22}))
"""
my name is :zhangsan, age is:22
""" # 把字符串中的 tab 符号('\t',\n)转为空格,再输出为新字符串。通常可用于表格格式的输出
info = "name\tage\temail\nlittlefive\t22\t994263539@qq.com\njames\t33\t66622334@qq.com"
print(info.expandtabs())
"""
name age email
littlefive 22 994263539@qq.com
james 33 66622334@qq.com
""" #字符串的切片操作=================================================================
str[开始:结束:取值方向] #不推荐结束位置使用负数,造成理解难度
a = "hello word"
print(a[1])
print(a[0:6])
print(len(a))
"""
e
hello
10
"""
#切片的高级用法,字符串倒叙
print(a[::-1]) #不常用分割方法,partition,只能分割三部分,分割后生成元祖
a = "my name is tom"
print(a.partition(" "))
"""
('my', ' ', 'name is tom')
从右往左分割为,a.rpartition() #字符串编解码
res = str1.encode("utf-8")
res.decode("utf-8")
"""
参考文档:https://www.cnblogs.com/aylin/p/5452481.html
1.3列表:解决存储数据问题,按照顺序存入读取,先进先出原则,index下标是识别顺序的关键。
列表主要方法,是以下标index来进行操作。偶尔直接操作对象obj
#查询==========
list.count(obj) 查询统计某个元素,出现的次数
list.index(obj) 查询某个值第一个匹配项的索引位置,索引从0开始 #增改==========
list[index] = 值
list.append(obj) 在列表末尾添加新的对象
list.extend(seq) 在列表末尾一次性追加一整个序列(用新列表扩展原来的列表)
list.insert(index, obj) 在index位置,插入obj对象
list.reverse() 反转列表
list.sort([func]) 对原列表进行排序,会改变原列表
sorted(list) 列表排序,生成新列表,可以引用赋值
#删除==========
del listname
list.pop(值) 删除列表中最后的值,不填值则默认删除最后一个元素【有返回值】
list.remove(值) 删除列表中的某个值,默认为第一个匹配项 【无返回值,返回None】
1.4元祖:解决数据的去重问题
元祖因为不可变,所以不允许修改
#查询
print(tuple[index])
tuple3 = tuple1 + tuple2
cmp(tuple1, tuple2)
#新建 #删除
del tuple
1.5集合:解决不同数据之间的对比问题,交并补集的查询
集合可以去重,无序,每个元素必须不可变
a = {1,2,3}
print(frozenset(a)) #定义不可变集合,输出为:frozenset({1, 2, 3}) #增改操作
a.add("999") #增加单个元素
a.update({77,88}) #增加多个元素,参数只能是可迭代对象,注意字符串的传入会去重 #删除操作
a.pop() #随机删除,不需要参数
a.remove(1) #指定删除,若删除的元素不存在,会报错
a.discard("hello") #指定删除,若元素不存在,无视该方法 #交并补的查询===========================================================
a = {1,2,3,4}
b = {3,4,5,6}
#交集
print(a & b)
print(a.intersection(b))
{3, 4}
{3, 4} #并集
print(a | b)
print(a.union(b))
{1, 2, 3, 4, 5, 6}
{1, 2, 3, 4, 5, 6} #差集,注意顺序,结果会不同
print(a -b)
print(a.difference(b))
print(b -a)
print(b.difference(a))
{1, 2}
{1, 2}
{5, 6}
{5, 6} #交差补集
print(a ^ b)
print("对称差集符号:", a.symmetric_difference(b))
{1, 2, 5, 6}
{1, 2, 5, 6} #判断两个集合是否为子集或者父集
c = {1}
print(a.issuperset(b))
print(a.issuperset(c))
False
True print(a.issubset(c))
print(c.issubset(a))
False
True
1.6字典:解决成对数据的存储问题,键使用hash方法,查询速度在全部数据类型中最快
#字典的关键在于key键的信息,key键是唯一的,也是查询搜索的关键,大小写敏感 # 定义空字典
info={} 或者 info = dict() #查询,获取字典的迭代器操作
info = {"name":"tom", "age":22}
info.keys()
info.values()
info.items() 得到的是元祖类型
info[key] 通过键获取值,得不到就报错
info.get(key,value) 通过键获取值,get不到返回value,不指定value默认为None
len(info) key in info 返回布尔值 #更改增加
a[key]=[value] 已存在key则修改value值,不存在key则新增键值对
a.update(b)
dict.fromkeys(iterable, value) value值是固定的,不指定value为none
a.setdefault(key,value) 返回值为value,如果key在字典中,返回已存在的value,如果key不在字典中,返回设定的value,同时向字典新增键值对 #删除操作
del info[key]
info.clear() 只是清除元素,不会删掉
info.pop(key) 需要参数key,删除指定键值对
info.popitem() 不需要参数,默认删除最后一组键值对
2、各种数据类型间的转换
float(x ) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数 #整数转进制
x = 10
bin(x) #将数值转换为二进制数据
oct(x) #将数值转换为八进制字符串
hex(x) #将数值转换为十六进制字符串
print(bin(x))
print(oct(10))
print(hex(10))
"""
0b1010
0o12
0xa
"""
# 把指定的字符,转为整数
x = "10"
print(int(x, 2))
print(int(x, 8))
print(int(x, 10))
print(int(x, 16))
"""
2
8
10
16
"""
#获取整数转换为进制后的位数
变量.bit_length() 将数字转换为二进制,并且返回最少位二进制的位数 # 不能直接 数字.bit_length() # 字符串:简单转换
str(x) 将对象x转换为字符串
repr(x) 将对象x转换为表达式字符串,转换为输入格式
chr(x) 将一个整数转换为一个字符
ord(x) 将一个字符转换为它的整数值
name = "tom"
age = 23
print(str(age))
print(repr(name)) #原样输出
print(chr(99))
print(ord("C")) #这是大写
print(ord("c")) #这是小写
"""
23
'tom'
c
67
99
""" # 字符串:复杂转换
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
#用法一:当成简单的计算器
print(eval("3 + 8"))
print(eval("3 - 8"))
print(eval("3 * 8"))
print(eval("3 / 8"))
"""
11
-5
24
0.375
""" #用法二:当成复杂的计算器
x = 10
y = 20
a = eval("x+y",{"x":1,"y":2}) #给变量xy重新指定参数
print(a)
"""
3
""" #用法三:当成格式转换方法
a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
b = "{1: 'a', 2: 'b'}"
c = eval(a)
d = eval(b)
print(c)
print(type(c))
print(d)
print(type(d))
"""
[[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]]
<class 'list'>
{1: 'a', 2: 'b'}
<class 'dict'>
"""
# 序列间转换
tuple(s) 将序列s转换为一个元组
list(s) 将序列s转换为一个列表
set(s) 将序列s转换为一个集合
dict(s) 将序列s转换为一个字典 #字典只能传入键值对
name = "tom"
age = 22
print(dict(name=name))
print(dict(name="tom"))
"""
{'name': 'tom'}
{'name': 'tom'}
""" 参考文档:https://www.cnblogs.com/0201zcr/p/4855700.html
3、元祖,列表,字典序列间的区别
#1.元祖:tuple()
对象有序排列【3.7版本后】,通过索引读取读取,
对象不可变,可以是数字、字符串、列表、字典、其他元祖 #2.列表:list[]
对象有序排列,通过索引读取读取,
对象是可变的,可以是数字、字符串、元祖、其他列表、字典 #3.字典:dict{}
对象有序排列,通过键值(key-value)读取
键唯一且不可变(可以是数字、字符串、元祖,但不能是列表),
值是可变的,可以任意嵌套,它的值可以任意类型
4、各个序列类型的共有操作方法
求长短: len(obj)
求最值: max(obj)
min(obj)
求相加: obj1 + obj2
求复制:(obj)* 数量
求存在: 值 in obj
求迭代: for i in obj:
print(i)
求切片:obj[开始:结束:截取步长]
包头不包尾,只能取到结束符的前一位
5、可变与不可变数据类型
python的数据类型,可以分为两类,分别是可变数据类型和不可变数据类型。关于如何查看数据类型,使用type()函数。
类型是可变还是不可变怎么区分呢,需要使用之前提到的变量查看方法,id()函数,只要是内存中的数据,就一定有内存id。
不可变数据类型:当数据的值发生变化,而内存地址会变。
可变数据类型: 当数据的值发生变化,而内存地址不变。
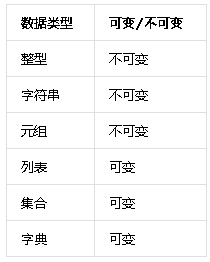
在python中数据类型有:整型,字符串,元组,集合,列表,字典。接下来我们用例子来验证查看,他们分别属于不可变数据类型还是可变数据类型!
数值型
a = 1
print(id(a))
a = 2
print(id(a))
"""
140709392295728
140709392295760
"""
# 我们可以发现,当数据发生改变后,变量的内存地址发生了改变,那么整型就是不可变数据类型。
字符串型
a = "hello"
print(id(a))
a = "word"
print(id(a))
"""
1636878268656
1636853765808
"""
# 我们可以发现,当数据发生改变后,变量的内存地址发生了改变,那么字符串就是不可变数据类型。
列表型
a = [1,2,3]
print(id(a))
a[1] = 999
print(a)
print(id(a))
"""
1636877858816
[1, 999, 3]
1636877858816
"""
# 我们可以发现,当数据发生改变后,但是内存地址没有发生了改变,那么列表就是可变数据类型。
元祖型
# 元祖本身没有修改方法,所以给元祖中放一个列表数据,改变列表来间接验证元祖是否可变
b = [1,2,3] # 定义可变列表
print(b)
a = (1,2,3,b)
print(id(a))
b[1] = 999 # 修改列表的值
print(b)
print(id(a))
"""
[1, 2, 3]
1636878338864
[1, 999, 3]
1636878338864
"""
# 我们发现,当数据发生改变后,但是列表的地址不会改变,而元组中的id地址的值也没有改变,所以也就意味着元组没有发生变化。我们就可以认为元组是不可变数据类型。
字典型
a = {'name':"tom","age":22}
print(id(a))
a["age"] = 33
print(a)
print(id(a))
"""
1636878345024
{'name': 'tom', 'age': 33}
1636878345024
"""
# 我们可以发现,当字典数据发生改变,但是内存地址没有发生了改变,那么字典就是可变数据类型
# 虽然字典是可变的,但是字典的key是不能变类型,字符串、元祖、整数等都可以都可以最为key
# 在3.6版本后,字典开始是有序的,请看评论演示:https://www.cnblogs.com/operationhome/p/9642460.html
集合型
a = {1,2,3,"name"}
print(id(a))
a.add("hello word")
print(a)
print(id(a))
"""
1636878962752
{1, 2, 3, 'name', 'hello word'}
1636878962752
"""
# 我们可以发现,虽然集合数据发生改变,但是内存地址没有发生了改变,那么集合就是可变数据类型。
所以结论是:
其他参考文档:
https://www.cnblogs.com/yanxy/archive/2010/02/27/c2p_1.html
https://www.cnblogs.com/linjiqin/p/3608541.html
https://www.cnblogs.com/linjiqin/p/3608541.html
Python入门-深入了解数据类型以及方法的更多相关文章
- Python入门篇-基础数据类型之整型(int),字符串(str),字节(bytes),列表(list)和切片(slice)
Python入门篇-基础数据类型之整型(int),字符串(str),字节(bytes),列表(list)和切片(slice) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Py ...
- python的list()列表数据类型的方法详解
一.列表 列表的特征是中括号括起来的,逗号分隔每个元素,列表中的元素可以是数字或者字符串.列表.布尔值......等等所有类型都能放到列表里面,列表里面可以嵌套列表,可以无限嵌套 字符串的特征是双引号 ...
- python 入门基础4 --数据类型及内置方法
今日目录: 零.解压赋值+for循环 一. 可变/不可变和有序/无序 二.基本数据类型及内置方法 1.整型 int 2.浮点型float 3.字符串类型 4.列表类型 三.后期补充内容 零.解压赋值+ ...
- Python 入门之基本数据类型
为什么我要学习Python这门语言呢?其实很简单,我想拓展技术面的同时,尝试更多的方向,可能最后会不了了之,谁知道呢?有可能的话,我会向爬虫和数据分析这个方向走.所以也就开始了我的Python学习之旅 ...
- Python 入门(2):数据类型
一 Number(数字) 1.1 数字类型的创建 a = 10 b = a b = 5 print(a) 10 print(b) 5 1.2 Number 类型转换 a = 5.2 b = 5 c = ...
- Python入门,基本数据类型
1.Python中的注释 单行注释:#注释内容 多行注释:三引号(单或者是双) ''' 注释内容 ''' """ 注释内容 """ 2.输入 ...
- python入门-变量与数据类型
1.命名规则 变量名只能包含字母.数字和下划线.但不能以数字打头. 变量名不能包含空格 不能与关键字冲突 变量名应尽量简短且具有描述性 2.字符串 python中引号括起的内容,其中引号可以为单引号或 ...
- Python入门 更换pip源的方法
pip国内的一些镜像 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple ...
- python的dict()字典数据类型的方法详解以及案例使用
一.之前的回顾 # int 数字 # str 字符串 # list 列表 # tuple 元组 # dict 字典 字典中最重要的方法 keys() values() items() get upd ...
随机推荐
- 【公告】淘宝 npm 域名即将切换 && npmmirror 重构升级
镜像下载.域名解析.时间同步请点击阿里云开源镜像站 前言 本文将包括两部分内容: 淘宝 npm 域名即将停止解析 npmmirror 镜像站大重构升级 原淘宝 npm 域名即将停止解析 正如在< ...
- Linux 环境部署Skywalking支持Elasticsearch
一.环境准备 1.Java JKD 1.8(建议) 2.Elasticsearch 3.Skywalking 二. 环境搭建 安装Skywalking分为两个步骤: a.安装Backend后端服务 b ...
- 生产出现oom问题,怎么排查?
生产出现oom问题,怎么排查? 1.使用dmesg命令查看系统日志 dmesg |grep -E 'kill|oom|out of memory',可以查看操作系统启动后的系统日志,这里就是查看跟 ...
- 如何进行Hibernate的性能优化?
大体上,对于HIBERNATE性能调优的主要考虑点如下: l 数据库设计调整 l HQL优化 l API的正确使用(如根据不同的业务类型选用不同的集合及查询API) l 主配置参数(日志,查询缓存,f ...
- 如何实现 Spring Boot 应用程序的安全性?
为了实现 Spring Boot 的安全性,我们使用 spring-boot-starter-security 依赖项,并且必须添加安全配置.它只需要很少的代码.配置类将必须扩展WebSecurity ...
- nginx反向代理失败,又是 fastdfs 的锅
fdfs问题记录 [root@hostcad logs]# systemctl status fdfs_trackerd.service ● fdfs_trackerd.service - LSB: ...
- 分布式HDFS的安装和启动(二)
一.分布式HDFS的安装和启动①在$HADOOP_HOME/etc/hadoop/core-site.xml文件<property> <name>fs.defaultFS< ...
- 在 Java 中,如何跳出当前的多重嵌套循环?
在最外层循环前加一个标记如 A,然后用 break A;可以跳出多重循环.(Java 中 支持带标签的 break 和 continue 语句,作用有点类似于 C 和 C++中的 goto 语 句,但 ...
- spring-boot-learning-监听事件
Springboot扩展了Spring的ApplicatoionContextEvent,提供了事件: ApplicationStartingEvent:框架启动事件 ApplicationEnvir ...
- Spring 切面可以应用五种类型的通知?
Spring 切面可以应用五种类型的通知: before:前置通知,在一个方法执行前被调用. after: 在方法执行之后调用的通知,无论方法执行是否成功. after-returning: 仅当方法 ...