Bert不完全手册8. 预训练不要停!Continue Pretraining
- paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks
- GitHub: https://github.com/allenai/dont-stop-pretraining
论文针对预训练语料和领域分布,以及任务分布之间的差异,提出了DAPT领域适应预训练(domain-adaptive pretraining)和TAPT任务适应预训练(task-adaptive pretraining)两种继续预训练方案,并在医学论文,计算机论文,新闻和商品评价4个领域上进行了测试。想法很简单就是在垂直领域上使用领域语料做继续预训练,不过算是开启了新的训练范式,从之前的pretrain+fintune,到pretrain+continue pretrain+finetune
核心要点主要有以下4个
- 和预训练差异越大的领域,领域适应继续预训练的效果提升越显著
- 任务适应预训练轻量好使,效果也不差
- 领域预训练+任务预训练效果最好,不过成本较高
- 通过KNN扩展任务语料,能逼近领域预训练的效果
DAPT
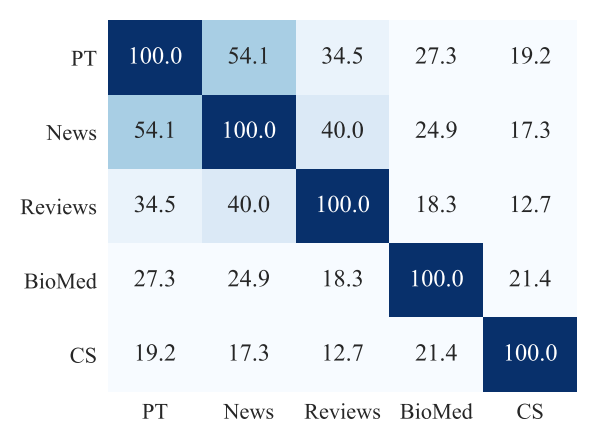
首先作者通过每个领域内的Top10K高频词的重合度,来衡量领域之间,以及领域和预训练语料的文本相似度,相似度News>Reviews>Bio>CS。我们预期DAPT的效果会和相似度相关,理论上在相似度低的领域,继续预训练应该带来更大的提升。
训练部分作者复用了Roberta的预训练方案。为了保证4个领域可比,作者通过样本采样,以及不同的batch size保证了4个领域的step相同。为了防止灾难遗忘,作者只在领域数据上继续训练了1个epoch(12.5K steps)。除了News领域,其他领域的继续预训练都带来了MLM Loss的下降。
在下游分类任务微调中,继续训练的模型效果都显著优于原始Roberta,和预训练语料差异更大的领域CS,Bio整体的效果提升更显著,如下

为了剔除更多的训练样本可能带来的效果提升,作者按以上的语料相关性,每个领域都选择了相关性最低的另一个领域的继续预训练模型(¬DAPT),对比在下游微调中的效果,部分场景有提升部分有下降,但是都显著低于对应领域的继续预训练模型,从而进一步证明继续预训练的收益来自对应领域信息的补充。
TAPT
TAPT是使用任务样本直接进行继续训练。Task Adaptive和Domain Adaptive的主要区别是,Task对应的数据集更小训练成本更低,不过因为直接使用任务数据,所以和任务的相关度更高。对应以上DAPT训练1个epoch(12.5K steps), TAPT训练100个epoch,每个epochs使用15%的Random Delete来进行样本增强。
作者对比了只使用DAPT,TAPT以及先使用DAPT+TAPT的效果:整体上DAPT+TAPT的继续预训练效果最好。其中针对更加垂直(和预训练语料相关性更小)的领域DAPT更好。感觉主要是因为领域垂直,TAPT受限于样本量能提供的领域信息不足,容易过拟和。而和预训练语料更相似的新闻领域和评论领域,TAPT的效果甚至超过DAPT,如下

作者进一步尝试了Cross Task Transfer,就是使用相同领域中任务1做继续预训练,然后在任务2上进行微调。效果显著低于使用相同任务的语料做T继续训练,这进一步说明了相同领域不同任务间的语料分布也是存在差异的,所以在部分任务上TAPT的效果要优于DAPT。
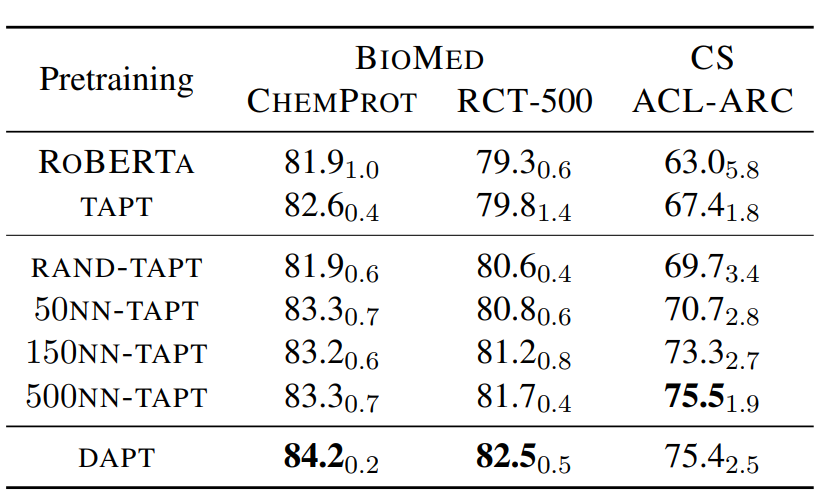
那能否在保留当前任务分布的前提下,拓展任务相关语料,解决TAPT样本量不足的问题呢?比较直观的方案就是使用文本Embedding,从相同领域的样本中,使用KNN抽取任务对应的K个相似样本来扩充任务样本。作者使用的是词袋模型VAMPIRE来计算文本表征,对比了不同参数K的效果,500KNN已经逼近DAPT。如果你有耐心>_<的话,KNN配合TAPT确实算是更优的方案,它的预训练成本显著低于DAPT,但又比TAPT的效果以及泛化性要显著更好
领域差异
说了半天继续预训练可以提高下游任务的效果,不过究竟继续预训练干了啥??这部分在作者也没有很详细的证明,所以我们只能借助相关paper来猜想一哈~
- 领域词汇/实体/ngram差异: 垂直领域和通用领域的主要差异在专属实体和短语,也就是领域知识信息。继续预训练可以提供这部分的补充信息。不过这其实也challenge了论文复用Roberta的预训练方案并一定是最优方案,可能SpanBert或者ERNIE,甚至K-Bert对应的知识增强,实体掩码方案更合适
- 整体语料差异: 除知识之外,常规的文本表达和上下文语境也存在整体差异,可以通过继续与训练来进行调整。
- 优化空间分布,提高线性可分性:在之前探测Bert Finetune对向量空间的影响中我们讨论过,微调其实是对预训练文本表征的空间分布进行了调整,使得在下游任务中空间分布更简单更加线性可分,这里猜测继续预训练其实也起到了类似的效果。
- 提高模型泛化:在下游任务微调中,模型往往只更新/依赖任务相关的局部信息,而继续预训练目标的设置使得模型能更全面的学习领域/任务相关的上下文知识,一定程度上提高模型的泛化能力,起到更优的bayesian prior的作用
案例
总结下,针对单任务模型,直接使用TAPT成本最低实用性最高,针对领域底层大模型,使用DAPT效果更好。不过使用起来具体使用哪种预训练方案,以及如何避免灾难遗忘,感觉还是要case by case的来看。一些相关的案例有
- 金融负面主体识别比赛:Rank3的方案就尝试了在任务语料上继续预训练,并且配合实体掩码相关的预训练方案来提升模型效果。
- 疫情期间民情识别比赛: 作者用比赛数据提供的任务样本,以及任务样本相关的未标注样本进行做curated tapt,平均准确率有1个点左右的提升
- 淘宝UGC情感分类:评论底层大模型,使用评论领域语料来继续预训练,用于上层的子任务
最近在复现一些比赛方案时,尝试了下在金融负面主体这个任务中引入TAPT,因为是实体相关的情感分类问题,因此在TAPT上使用了Whole Word和Entity粒度结合的MLM作为预训练目标。在使用多任务的基础上,使用TAPT进一步训练后F1进一步有0.2%个点的提升,不过这个提升只有当预训练使用全部语料的时候才显著,如果和下游微调一样保留部分数据用于测试,则不会有显著的效果提升,这里的效果对比更支持上面的提高模型泛化能力这个假设~具体实现详见ClassicSolution/fin_neg_entity
Bert不完全手册8. 预训练不要停!Continue Pretraining的更多相关文章
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 预训练中Word2vec,ELMO,GPT与BERT对比
预训练 先在某个任务(训练集A或者B)进行预先训练,即先在这个任务(训练集A或者B)学习网络参数,然后存起来以备后用.当我们在面临第三个任务时,网络可以采取相同的结构,在较浅的几层,网络参数可以直接加 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- NLP之预训练
内容是结合:https://zhuanlan.zhihu.com/p/49271699 可以直接看原文 预训练一般要从图像处理领域说起:可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预 ...
- Bert不完全手册1. 推理太慢?模型蒸馏
模型蒸馏的目标主要用于模型的线上部署,解决Bert太大,推理太慢的问题.因此用一个小模型去逼近大模型的效果,实现的方式一般是Teacher-Stuent框架,先用大模型(Teacher)去对样本进行拟 ...
- 【算法】Bert预训练源码阅读
Bert预训练源码 主要代码 地址:https://github.com/google-research/bert create_pretraning_data.py:原始文件转换为训练数据格式 to ...
随机推荐
- Lydon 分解与最小表示法
我们定义一个串是 \(\text{Lyndon}\) 串,当且仅当这个串的最小后缀就是这个串本身. 该命题等价于这个串是它的所有循环表示中字典序最小的. 引理 1:如果 \(u\) 和 \(v\) 都 ...
- C++ 模板和泛型编程(掌握Vector等容器的使用)
1. 泛型 泛型在我的理解里,就是可以泛化到多种基本的数据类型,例如整数.浮点数.字符和布尔类型以及自己定义的结构体.而容器就是提供能够填充任意类型的数据的数据结构.例如vector就很类似于pyth ...
- 攻防世界MISC—进阶区32—37
32.normal_png 得到一张png,扔进kali中binwalk 和 pngcheck一下,发现CRC报错 尝试修改图片高度,我是把height的2改为4,得到flag 33.很普通的数独 得 ...
- 线程池ThreadPoolExector核心ctl, execute, addWorker, reject源码分析
线程池核心方法execute()解析: public void execute(Runnable command) {//#1 if (command == null) throw new NullP ...
- 基于ABP实现DDD--聚合和聚合根实践
在下面的例子中涉及Repository.Issue.Label.User这4个聚合根,接下来以Issue聚合为例进行分析,其中Issue聚合是由Issue[聚合根].Comment[实体].Iss ...
- 数据类型 简单扩展(Java)
public class HelloWorld { public static void main(String[] args) { //整数拓展 进制 二进制0b 十进制 八进制0 十六进制0x i ...
- Hippo4J v1.3.1 发布,增加 Netty 监控上报、SpringCloud Hystrix 线程池监控等特性
文章首发在公众号(龙台的技术笔记),之后同步到博客园和个人网站:xiaomage.info Hippo4J v1.3.1 正式发布,本次发布增加了 Netty 上传动态线程池监控数据.适配 Hystr ...
- github碰到的问题
下载问题 自己编译一下 mvn clear mvn compile mvn package 自己编译之后的文件,然后解压即可,第一次自己傻傻的,直接用源码跑,少报错! 项目预览问题 添加1s即可 下载 ...
- Redis 5 种基本数据结构(String、List、Hash、Set、Sorted Set)详解 | JavaGuide
首发于:Redis 5 种基本数据结构详解 - JavaGuide 相关文章:Redis常见面试题总结(上) . Redis 5 种基本数据结构(String.List.Hash.Set.Sorted ...
- WPF 截图控件之画笔(八)「仿微信」
前言 接着上周写的截图控件继续更新添加 画笔. 1.WPF实现截屏「仿微信」 2.WPF 实现截屏控件之移动(二)「仿微信」 3.WPF 截图控件之伸缩(三) 「仿微信」 4.WPF 截图控件之绘制方 ...