C++初探索
C++初探索
前言
C++ 和 C 的区别主要在8个方面:
- 输入和输出
- 引用
- inline函数
- 函数默认值
- 函数重载
- 模板函数
- new 和 delete
- namespace
我仅对印象不深的地方做了总结。
一、引用初探索
1.引用的定义与区别
定义:类型& 引用变量的名称 = 变量名称
'&' 不是取地址符吗,怎么又成为引用了呢?下面将常见的 '&' 做一个区分:
C中的 '&'
c = a && b; //此处 && 是 逻辑与
c = a & b; //此处的 & 是 按位与
int *p = &a; //此处的 & 是 取地址符
int &x = a; //此处的 & 是 引用
void fun(int &a); //此处的 & 也是引用
疑问:int &fun()这个是函数的引用吗?
回答:不是函数的引用,表示函数的返回值是一个引用。
2.引用的要求
- ①当定义引用时,必须初始化
//正确用法:
int a = 10;
int &x = a;
- ② 没有引用的引用(没有二级引用)
//错误用法:
int &x = a;
int &&y = x;
- ③ 没有空引用
int &x; //error:不存在空引用
3.引用与指针的区别
| 引用 | 指针 |
|---|---|
| 必须初始化 | 可以不初始化 |
| 不可为空 | 可以为空 |
| 不能更换目标 | 可以更换目标 |
| 没有二级引用 | 存在二级指针 |
1、引用必须初始化,而指针可以不初始化
int &s; //error:引用没用初始化
int *p; //right:指针不强制初始化
2、引用不可以为空,指针可以为空
int &s = NULL; //error:引用不可以为空,右值必须是已经定义过的变量名
int *p = NULL; //right:可以定义空指针。 int fun_p(int *p)
{
if(p != NULL) //因为指针可以为空,所以在输出前需要判断。
{
cout << *p << endl;
}
return *p;
} int fun_s(int &s)
{
cout << s << endl; //引用不为空,可以直接输出 return s;
}
3、引用不能改变目标,指针可以更换目标
int main()
{
int a = 20;
int b = 10; int &s = a;
int *p = &a; s = b; //引用只能指向初始化时的对象,如果改变,原先对象也跟着改变。
p = &b; //指针可以改变指向的对象,不改变原先对象。 cout << s << endl;
cout << a << endl; return 0;
}
4.常引用
我们可以能力收缩,不可能力扩展
//error:能力扩展
int a = 10;
int& b = a; //a b c都是一个东西
const int& c = a; //常引用
b += 10;
a += 100; //可以通过a b 去修改a 和 b
//c += 100; //error:不可通过 c 来修改 a 或者 b
//能力收缩
const int a = 100;
int& b = a; //不可编译成功
//a += 100; //error:a 自身不可改变
b += 100;
int a = 100;
const int& x = a; //可以编译成功
5.何时使用引用
引用可以作为函数参数
void Swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 10, y = 20;
Swap(x, y); //仅仅Swap内部交换,并不能影响到实参
}
//加上引用,对a和b的改变会影响实参
void Swap(int &a, int &b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 10, y = 20;
Swap(x, y); //仅仅Swap内部交换,并不能影响到实参
}
二、inline内联函数
1.内联函数的定义
为了解决一些频繁调用小函数消耗大量栈空间的问题,引入了inline内联函数。
inline int fun(int a ,int b)
{
return a + b;
}
2.内联函数的处理流程
处理步骤
- 将 inline 函数体复制到 inline 函数调用点处;
- 为所用 inline 函数中的局部变量分配内存空间;
- 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
int fun(int a,int b)
{
return a + b;
}
//普通调用
int main()
{
int a = 10;
int b = 20;
int c = fun(10,20);
}
//内联函数
int main()
{
int a = 10;
int b = 20;
int c = 10 + 20; //此处相当于直接展开函数
}
3.内联函数与三者的区别
3.1 与普通函数的区别
内联函数在函数的调用点直接展开代码,没有开栈和清栈的开销。普通函数有开栈和清栈的开销。
内联函数要求代码简单,不能包含复杂的结构控制语句。
若内联函数体过于复杂,编译器将自动把内联函数当成普通函数来执行。
3.2 与static函数的区别
static修饰的函数处理机制只是将函数的符号变成局部符号,函数的处理机制和普通函数相同,都有函数的开栈和清栈的开销。内联函数没有函数的开栈和清栈的开销。
inline函数是因为代码直接在调用点展开导致函数只在本文件可见。而static修饰的函数是因为函数法符号从全局符号变成局部符号导致函数本文件可见。
3.3 与宏定义的区别
inline函数的处理时机是在编译阶段处理的,有安全检查和类型检查。而宏的处理是在预编译阶段处理的。没有任何的检查机制,只是简单的文本替换。
inline函数是一种更安全的宏。
4.仅realese版本才会产生内联
代码如下:
inline int Add_Int(int x, int y)
{
return x + y;
}
int main()
{
int a = 10, b = 20;
int c = 0;
c = Add_Int(a, b);
cout << c << endl;
return 0;
}
debug版本的反汇编:仍是以函数调用的形式
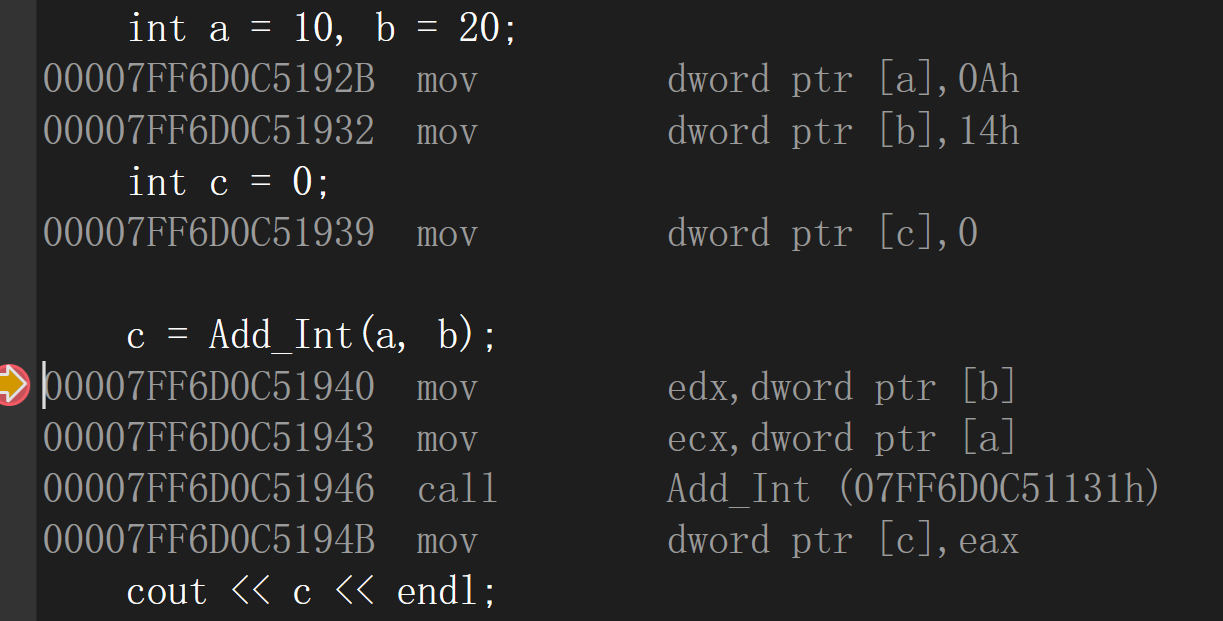
release版本的反汇编:在编译时期展开
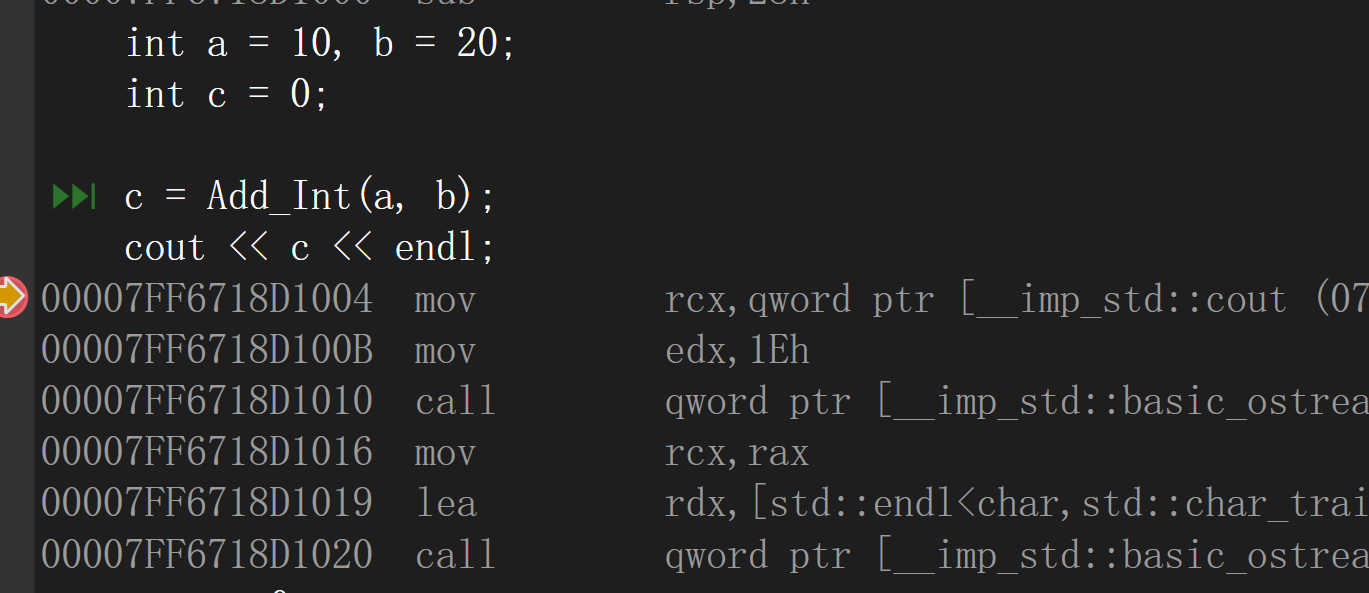
5.inline函数使用的限制
一般写在头文件中
只在release版本中生效
inline只是一个建议,是否处理由编译器决定
如果函数体内的代码比较长,使得内联将导致内存消耗代价比较高。
如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。
基于实现的,不是基于声明的
int fun(int x,int y); // 函数声明 inline int fun(int x,int y) // 函数定义
{
return x+y;
} // 定义时加inline关键字
inline void fun1(int x)
{ }
三、函数的重载
在C语言中,函数名 是 函数的唯一标识
在C++中,函数原型 是 函数的标识。
函数原型
函数原型 = 函数返回类型 + 函数名 + 形参列表(参数的类型和个数)
使用extern关键字指定为C语言编译
extern"C" int Max(int a, int b)
{
return a > b ? a : b;
}
extern"C" int fun(int a, int b)
{
return a + b;
}
int main()
{
Max(10, 20);
fun(20, 30);
return 0;
}
VS2022中
以C语言编译:函数名仍是原来的函数名
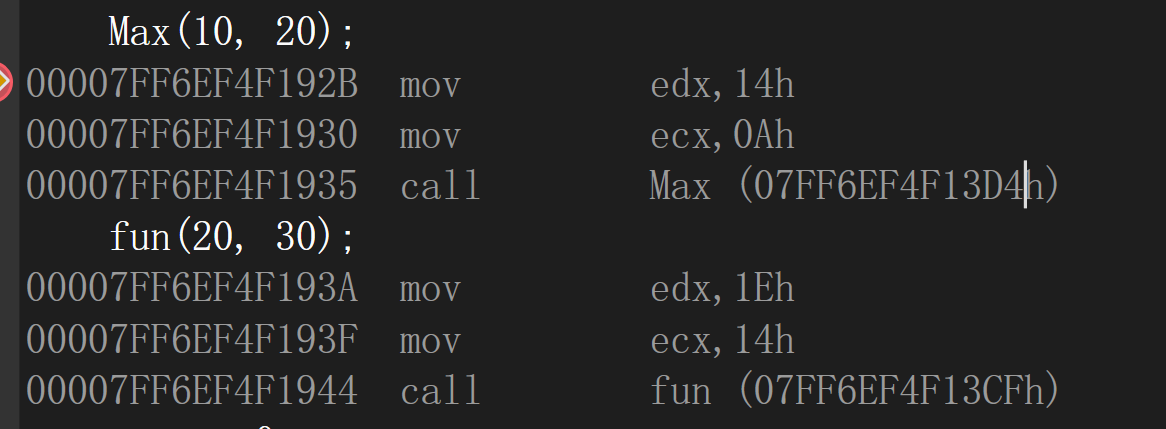
以C++编译:也是一样的情况
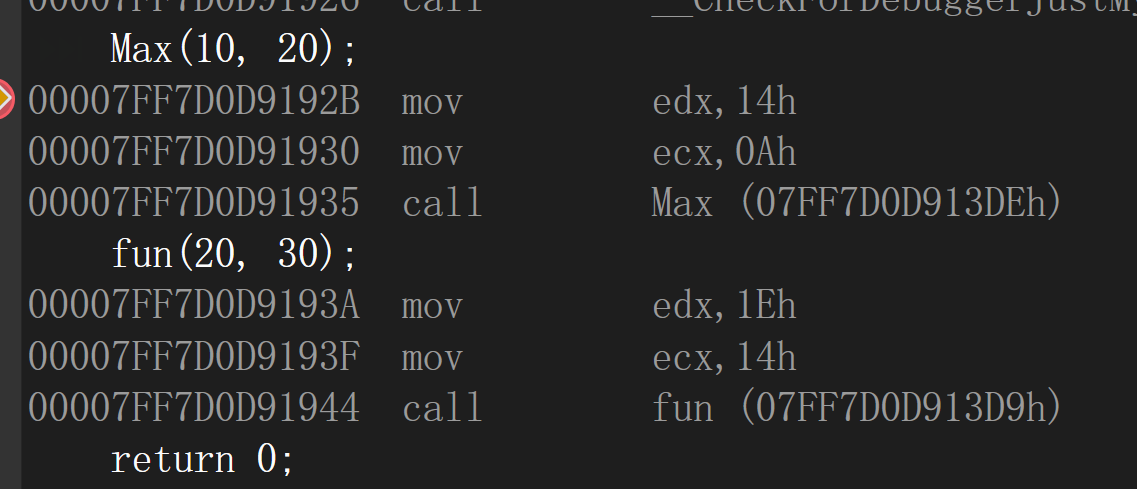
将函数的形参类型进行修改:
int Max(int a, int b)
{
return a > b ? a : b;
}
int Max(double a, int b)
{
return a > b ? a : b;
}
int main()
{
Max(10, 20); //编译正常
Max(10.00, 20); //编译正常
return 0;
}
发现函数名仍是一样,但是存放double类型的寄存器与存放int类型的寄存器不一样
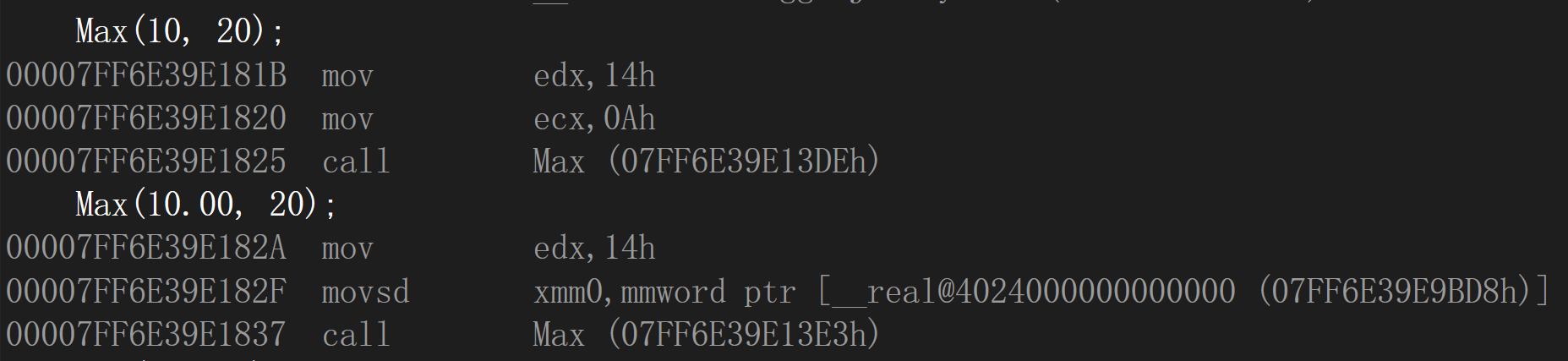
再将返回值类型也进行修改:
int Max(int a, int b)
{
return a > b ? a : b;
}
double Max(double a, int b)
{
return a > b ? a : b;
}
int fun(int a, int b)
{
return a + b;
}
int main()
{
Max(10, 20); //编译正常
Max(10.10, 20); //编译正常
return 0;
}
发现并没有任何问题,调用的也并非是同一个函数
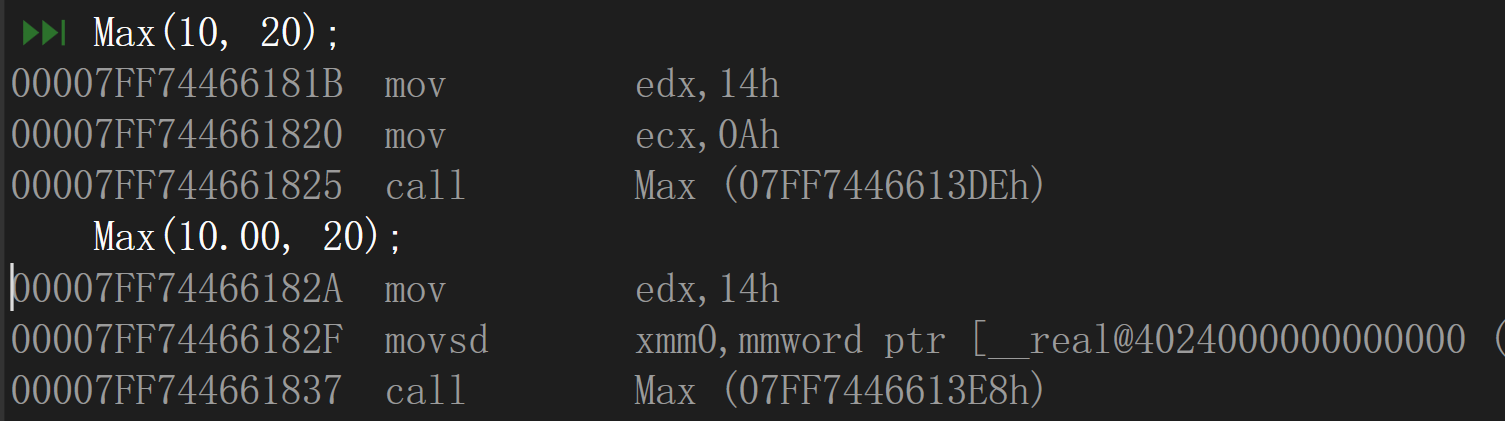
在VS2019中:
以C语言编译:函数名前加 _ ,_fun 和 _Max

以C++编译:没有下划线,与VS2022中C++编译相同
在VC6.0中:
int Max(int a, int b)
{
return a > b ? a : b;
}
double Max(double a, double b)
{
return a > b ? a : b;
}
char Max(char a, char b)
{
return a > b ? a : b;
}
int main()
{
Max(10, 20);
Max(10.0, 10.0);
Max('a','b');
return 0;
}
返回值为int 类型的Max函数:
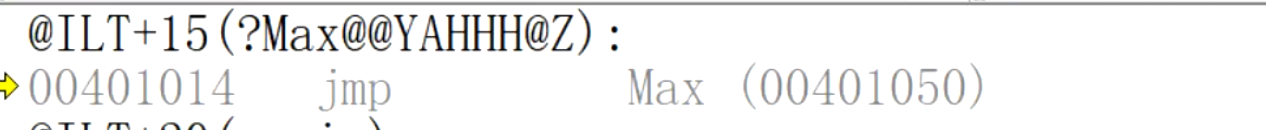
返回值为double类型的Max函数:
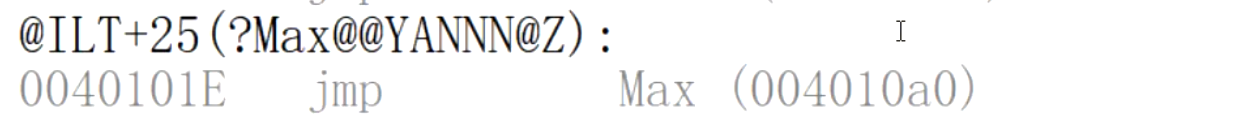
返回值为char类型的Max函数:
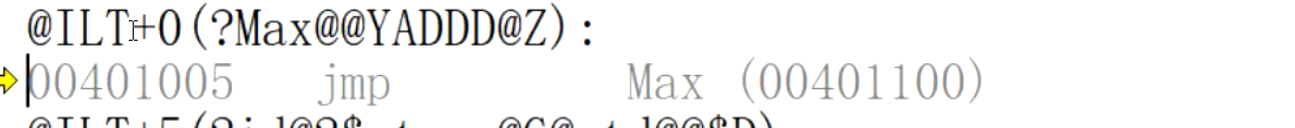
为什么函数名发生了如此大的改变?
这个就是名字粉碎技术
四、函数模板
模板的定义:
template <模板参数名>
返回类型 函数名(形式参数表)
{
//函数体
}
<模板参数表> 尖括号中不能为空,参数可以有多个,用,隔开
template<class Type>
void Swap(Type& a, Type& b)
{
Type tmp = a;
a = b;
b = tmp;
}
注意1:<>中只能以C++的方式写,不能出现如 template <struct Type>
注意2:下面调用Swap不是简单的替换(宏替换),是重命名规则
//普通类型
template <class Type> typedef int Type;
void Swap(Type &a ,Type &b) void Swap<int>(Type &a,Type &b)
{ {
Type tmp = a; Type tmp = a;
a = b; a = b;
b = tmp; b = tmp;
} }
int main()
{
int a = 10, b = 20;
Swap(a, b); //此处的调用如同右边函数
}
//指针类型
template<class Type> typedef int Type
void fun(Type p) void fun<int *>(Type p)
{ {
Type a, b; Type a, b;
} }
int main()
{
int x = 10;
int* ip = &x;
fun(ip);
return 0;
}
注意3:编译时进行重命名,非运行时。
五、new和malloc
//C语言与C++申请空间:
int main()
{
int n = 10;
//C:malloc free
int* ip = (int*)malloc(sizeof(int) * n);
//地址空间与NULl进行对比,判断是否申请失败
if (NULL == ip) exit(1);
free(ip);
ip = NULL;
//C++:new delete
ip = new int;
*ip = 100;
delete ip;
ip = NULL;
}
//new申请连续空间
int main()
{
//new申请连续空间,要释放连续空间
ip = new int[n];
//此处的delete不是把ip删除,而是将ip指向堆区的空间换给系统
delete[]ip;
}
new申请失败时候的处理:
//错误处理:
ip = new int;
if (ip == NULL) exit(1);
delete ip;
ip == NULL;
//new 如果分配内存失败,默认是抛出异常的。
//分配成功时,那么并不会执行 if (ip == NULL)
//若分配失败,也不会执行 if (ip == NULL)
//分配失败时,new 就会抛出异常跳过后面的代码。
//正确处理1:强制不抛出异常
int *ip = new (std::nothrow) int[n];
if (ip == NULL)
{
cout << "error" << endl;
}
//正确处理2:捕捉异常
try
{
int* ip = new int[SIZE];
}
catch (const bad_alloc& e)
{
return -1;
}
总结
仍遗留下很多问题:
- new和malloc的区别
- 命名空间
- 引用的深入
- const
C++初探索的更多相关文章
- dubbo框架----初探索-配置
使用框架版本 dubbo-2.5.3 spring-4.2.1.RELEASE jdk-1.8 tomcat-8.0 zookeeper-3.3.6 Dubbo与Zookeeper.SpringMVC ...
- react初探索--react + react-router + ant-design 后台管理系统配置
首先确认安装了node环境,Node >= 6. 如果对react 及 ant-design 一无所知,建议去阅读下api文档,react 可以在 codePen 在线练习. react Api ...
- Dock镜像初探索
一.安装CentOS版DockerCE 1.1 卸载旧的版本 yum remove docker \ docker-client \ docker-client-latest \ docker-com ...
- 高效动画实现原理-Jetpack Compose 初探索
一.简介 Jetpack Compose是Google推出的用于构建原生界面的新Android 工具包,它可简化并加快 Android上的界面开发.Jetpack Compose是一个声明式的UI框架 ...
- Kaggle:Home Credit Default Risk 数据探索及可视化(1)
最近博主在做个 kaggle 竞赛,有个 Kernel 的数据探索分析非常值得借鉴,博主也学习了一波操作,搬运过来借鉴,原链接如下: https://www.kaggle.com/willkoehrs ...
- [读书系列] 深度探索C++对象模型 初读
2012年底-2014年初这段时间主要用C++做手游开发,时隔3年,重新拿起<深度探索C++对象模型>这本书,感觉生疏了很多,如果按前阵子的生疏度来说,现在不借助Visual Studio ...
- Java线程池ThreadPoolExecutor初略探索
在操作系统中,线程是一个非常重要的资源,频繁创建和销毁大量线程会大大降低系统性能.Java线程池原理类似于数据库连接池,目的就是帮助我们实现线程复用,减少频繁创建和销毁线程 ThreadPoolExe ...
- Xamarin+Prism开发详解四:简单Mac OS 虚拟机安装方法与Visual Studio for Mac 初体验
Mac OS 虚拟机安装方法 最近把自己的电脑升级了一下SSD固态硬盘,总算是有容量安装Mac 虚拟机了!经过心碎的安装探索,尝试了国内外的各种安装方法,最后在youtube上找到了一个好方法. 简单 ...
- 马里奥AI实现方式探索 ——神经网络+增强学习
[TOC] 马里奥AI实现方式探索 --神经网络+增强学习 儿时我们都曾有过一个经典游戏的体验,就是马里奥(顶蘑菇^v^),这次里约奥运会闭幕式,日本作为2020年东京奥运会的东道主,安倍最后也已经典 ...
随机推荐
- Aspose.Words 操作 Word 画 EChart 图
使用 Aspose.Words 插件在 Word 画 EChart 图 使用此插件可以画出丰富的 EChart 图,API 参考 https://reference.aspose.com/words/ ...
- AI带你省钱旅游!精准预测民宿房源价格!
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
- Debian安装WPS的方法
1.防止安装失败,请尽量重启电脑,关闭系统的软件商店,因为商店的权限可能会锁住pkg的配置文件,导致无法安装wps. 2.将原机残废的WPS卸载干净,卸载方法:手动或命令行操作. sudo apt r ...
- iptables综合实验: 两个私有网络的互相通迅
环境准备: 主机A IP:192.168.0.6/24 网关改为192.168.0.8 firewallA IP:eth1 192.168.0.8/24 eth0 10.0.0.8/24 删除默认路由 ...
- PyCharm配置远程Docker环境
1. docker 配置 使用-p参数暴露一个端口用于ssh连接. docker run -itd --name wangchao_paddle --gpus all -p 8899:8888 -p ...
- scrapy 如何使用代理 以及设置超时时间
使用代理 1. 单文件spider局部使用代理 entry = 'http://xxxxx:xxxxx@http-pro.abuyun.com:xxx'.format("帐号", ...
- Oracle收集统计信息的一些思考
一.问题 Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少? 假设采样比例为10%,那么在计算单个 ...
- zephyr的GPIOTE驱动开发记录——基于nordic的NCS
简介: 本次测试了zephyr的中断驱动方式(GPIOTE),在这可以去看zephyr的官方文档对zephyr的中断定义,连接如下,Interrupts - Zephyr Project Docume ...
- AArch32/AArch64应用程序级内存模型(五)
本文主要为了记录在学习armv8的过程中的一些感悟.由于原文部分章节晦涩难懂,作者参考了网上很多优秀博主的部分章节(可能是直接摘录)并结合自己的理解重新整理了当前这个版本.文中不免有部分章节讲解很浅, ...
- C温故补缺(十五):栈帧
栈帧 概念 栈帧:也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构,每次函数的调用,都会在调用栈(call stack)上维护一个独立的栈帧(stack frame) 栈帧的内容 函数的 ...