ClickHouse MergeTree引擎
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:
- 存储的数据按主键排序。
这使得您能够创建一个小型的稀疏索引来加快数据检索。
- 如果指定了 分区键 的话,可以使用分区。
在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
- 支持数据副本。
ReplicatedMergeTree 系列的表提供了数据副本功能。
- 支持数据采样。
需要的话,您可以给表设置一个采样方法。
!!! note "注意" 合并 引擎并不属于 *MergeTree 系列。
建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
子句
ENGINE - 引擎名和参数。 ENGINE = MergeTree(). MergeTree 引擎没有参数。
ORDER BY — 排序键。
可以是一组列的元组或任意的表达式。 例如: ORDER BY (CounterID, EventDate) 。
如果没有使用 PRIMARY KEY 显式指定的主键,ClickHouse 会使用排序键作为主键。
如果不需要排序,可以使用 ORDER BY tuple(). 参考 选择主键
- PARTITION BY — 分区键 ,可选项。
大多数情况下,不需要分使用区键。即使需要使用,也不需要使用比月更细粒度的分区键。分区不会加快查询(这与 ORDER BY 表达式不同)。永远也别使用过细粒度的分区键。不要使用客户端指定分区标识符或分区字段名称来对数据进行分区(而是将分区字段标识或名称作为 ORDER BY 表达式的第一列来指定分区)。
要按月分区,可以使用表达式 toYYYYMM(date_column) ,这里的 date_column 是一个 Date 类型的列。分区名的格式会是 "YYYYMM" 。
- PRIMARY KEY - 如果要 选择与排序键不同的主键,在这里指定,可选项。
默认情况下主键跟排序键(由 ORDER BY 子句指定)相同。 因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
- SAMPLE BY - 用于抽样的表达式,可选项。
如果要用抽样表达式,主键中必须包含这个表达式。例如: SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)) 。
- TTL - 指定行存储的持续时间并定义数据片段在硬盘和卷上的移动逻辑的规则列表,可选项。
表达式中必须存在至少一个 Date 或 DateTime 类型的列,比如:
TTL date + INTERVAl 1 DAY
规则的类型 DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'指定了当满足条件(到达指定时间)时所要执行的动作:移除过期的行,还是将数据片段(如果数据片段中的所有行都满足表达式的话)移动到指定的磁盘(TO DISK 'xxx') 或 卷(TO VOLUME 'xxx')。默认的规则是移除(DELETE)。可以在列表中指定多个规则,但最多只能有一个DELETE的规则。
SETTINGS — 控制 MergeTree 行为的额外参数,可选项:
index_granularity — 索引粒度。索引中相邻的『标记』间的数据行数。默认值8192 。参考数据存储。
index_granularity_bytes — 索引粒度,以字节为单位,默认值: 10Mb。如果想要仅按数据行数限制索引粒度, 请设置为0(不建议)。
min_index_granularity_bytes - 允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表。参考数据存储
enable_mixed_granularity_parts — 是否启用通过 index_granularity_bytes 控制索引粒度的大小。在19.11版本之前, 只有 index_granularity 配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes 配置能够提升ClickHouse的性能。如果您的表里有很大的行,可以开启这项配置来提升SELECT 查询的性能。
use_minimalistic_part_header_in_zookeeper — ZooKeeper中数据片段存储方式 。如果use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。更多信息参考[服务配置参数](Server Settings | ClickHouse Documentation)这章中的 设置描述 。
min_merge_bytes_to_use_direct_io — 使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse 会计算要被合并的所有数据的总存储空间。如果大小超过了 min_merge_bytes_to_use_direct_io 设置的字节数,则 ClickHouse 将使用直接 I/O 接口(O_DIRECT 选项)对磁盘读写。如果设置 min_merge_bytes_to_use_direct_io = 0 ,则会禁用直接 I/O。默认值:10 * 1024 * 1024 * 1024 字节。merge_with_ttl_timeout — TTL合并频率的最小间隔时间,单位:秒。默认值: 86400 (1 天)。
write_final_mark — 是否启用在数据片段尾部写入最终索引标记。默认值: 1(不要关闭)。
merge_max_block_size — 在块中进行合并操作时的最大行数限制。默认值:8192
storage_policy — 存储策略。 参见 使用具有多个块的设备进行数据存储.
min_bytes_for_wide_part,min_rows_for_wide_part 在数据片段中可以使用Wide格式进行存储的最小字节数/行数。您可以不设置、只设置一个,或全都设置。参考:数据存储
max_parts_in_total - 所有分区中最大块的数量(意义不明)
max_compress_block_size - 在数据压缩写入表前,未压缩数据块的最大大小。您可以在全局设置中设置该值(参见max_compress_block_size)。建表时指定该值会覆盖全局设置。
min_compress_block_size - 在数据压缩写入表前,未压缩数据块的最小大小。您可以在全局设置中设置该值(参见min_compress_block_size)。建表时指定该值会覆盖全局设置。
max_partitions_to_read - 一次查询中可访问的分区最大数。您可以在全局设置中设置该值(参见max_partitions_to_read)。
示例配置
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID) SETTINGS index_granularity=8192
在这个例子中,我们设置了按月进行分区。
同时我们设置了一个按用户 ID 哈希的抽样表达式。这使得您可以对该表中每个 CounterID 和 EventDate 的数据伪随机分布。如果您在查询时指定了 SAMPLE 子句。 ClickHouse会返回对于用户子集的一个均匀的伪随机数据采样。
数据存储
表由按主键排序的数据片段(DATA PART)组成。
当数据被插入到表中时,会创建多个数据片段并按主键的字典序排序。例如,主键是 (CounterID, Date) 时,片段中数据首先按 CounterID 排序,具有相同 CounterID 的部分按 Date 排序。
不同分区的数据会被分成不同的片段,ClickHouse 在后台合并数据片段以便更高效存储。不同分区的数据片段不会进行合并。合并机制并不保证具有相同主键的行全都合并到同一个数据片段中。
数据片段可以以 Wide 或 Compact 格式存储。在 Wide 格式下,每一列都会在文件系统中存储为单独的文件,在 Compact 格式下所有列都存储在一个文件中。Compact 格式可以提高插入量少插入频率频繁时的性能。
数据存储格式由 min_bytes_for_wide_part 和 min_rows_for_wide_part 表引擎参数控制。如果数据片段中的字节数或行数少于相应的设置值,数据片段会以 Compact 格式存储,否则会以 Wide 格式存储。
每个数据片段被逻辑的分割成颗粒(granules)。颗粒是 ClickHouse 中进行数据查询时的最小不可分割数据集。ClickHouse 不会对行或值进行拆分,所以每个颗粒总是包含整数个行。每个颗粒的第一行通过该行的主键值进行标记, ClickHouse 会为每个数据片段创建一个索引文件来存储这些标记。对于每列,无论它是否包含在主键当中,ClickHouse 都会存储类似标记。这些标记让您可以在列文件中直接找到数据。
颗粒的大小通过表引擎参数 index_granularity 和 index_granularity_bytes 控制。颗粒的行数的在 [1, index_granularity] 范围中,这取决于行的大小。如果单行的大小超过了 index_granularity_bytes 设置的值,那么一个颗粒的大小会超过 index_granularity_bytes。在这种情况下,颗粒的大小等于该行的大小。
主键的选择
主键中列的数量并没有明确的限制。依据数据结构,您可以在主键包含多些或少些列。这样可以:
改善索引的性能。
如果当前主键是 (a, b) ,在下列情况下添加另一个 c 列会提升性能:
查询会使用 c 列作为条件
很长的数据范围( index_granularity 的数倍)里 (a, b) 都是相同的值,并且这样的情况很普遍。换言之,就是加入另一列后,可以让您的查询略过很长的数据范围。
改善数据压缩。
ClickHouse 以主键排序片段数据,所以,数据的一致性越高,压缩越好。
在CollapsingMergeTree 和 SummingMergeTree 引擎里进行数据合并时会提供额外的处理逻辑。
在这种情况下,指定与主键不同的 排序键 也是有意义的。
长的主键会对插入性能和内存消耗有负面影响,但主键中额外的列并不影响 SELECT 查询的性能。
可以使用 ORDER BY tuple() 语法创建没有主键的表。在这种情况下 ClickHouse 根据数据插入的顺序存储。如果在使用 INSERT ... SELECT 时希望保持数据的排序,请设置 max_insert_threads = 1。
想要根据初始顺序进行数据查询,使用 单线程查询
选择与排序键不同的主键
Clickhouse可以做到指定一个跟排序键不一样的主键,此时排序键用于在数据片段中进行排序,主键用于在索引文件中进行标记的写入。这种情况下,主键表达式元组必须是排序键表达式元组的前缀(即主键为(a,b),排序列必须为(a,b,**))。
当使用 SummingMergeTree 和 AggregatingMergeTree 引擎时,这个特性非常有用。通常在使用这类引擎时,表里的列分两种:维度 和 度量 。典型的查询会通过任意的 GROUP BY 对度量列进行聚合并通过维度列进行过滤。由于 SummingMergeTree 和 AggregatingMergeTree 会对排序键相同的行进行聚合,所以把所有的维度放进排序键是很自然的做法。但这将导致排序键中包含大量的列,并且排序键会伴随着新添加的维度不断的更新。
在这种情况下合理的做法是,只保留少量的列在主键当中用于提升扫描效率,将维度列添加到排序键中。
对排序键进行 ALTER 是轻量级的操作,因为当一个新列同时被加入到表里和排序键里时,已存在的数据片段并不需要修改。由于旧的排序键是新排序键的前缀,并且新添加的列中没有数据,因此在表修改时的数据对于新旧的排序键来说都是有序的。
索引和分区在查询中的应用
对于 SELECT 查询,ClickHouse 分析是否可以使用索引。如果 WHERE/PREWHERE 子句具有下面这些表达式(作为完整WHERE条件的一部分或全部)则可以使用索引:进行相等/不相等的比较;对主键列或分区列进行IN运算、有固定前缀的LIKE运算(如name like 'test%')、函数运算(部分函数适用),还有对上述表达式进行逻辑运算。
因此,在索引键的一个或多个区间上快速地执行查询是可能的。下面例子中,指定标签;指定标签和日期范围;指定标签和日期;指定多个标签和日期范围等执行查询,都会非常快。
当引擎配置如下时:
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate) SETTINGS index_granularity=8192
这种情况下,这些查询:
SELECT count() FROM table WHERE EventDate = toDate(now()) AND CounterID = 34
SELECT count() FROM table WHERE EventDate = toDate(now()) AND (CounterID = 34 OR CounterID = 42)
SELECT count() FROM table WHERE ((EventDate >= toDate('2014-01-01') AND EventDate <= toDate('2014-01-31')) OR EventDate = toDate('2014-05-01')) AND CounterID IN (101500, 731962, 160656) AND (CounterID = 101500 OR EventDate != toDate('2014-05-01'))
ClickHouse 会依据主键索引剪掉不符合的数据,依据按月分区的分区键剪掉那些不包含符合数据的分区。
上文的查询显示,即使索引用于复杂表达式,因为读表操作经过优化,所以使用索引不会比完整扫描慢。
下面这个例子中,不会使用索引。
SELECT count() FROM table WHERE CounterID = 34 OR URL LIKE '%upyachka%'
要检查 ClickHouse 执行一个查询时能否使用索引,可设置 force_index_by_date 和 force_primary_key 。
使用按月分区的分区列允许只读取包含适当日期区间的数据块,这种情况下,数据块会包含很多天(最多整月)的数据。在块中,数据按主键排序,主键第一列可能不包含日期。因此,仅使用日期而没有用主键字段作为条件的查询将会导致需要读取超过这个指定日期以外的数据。
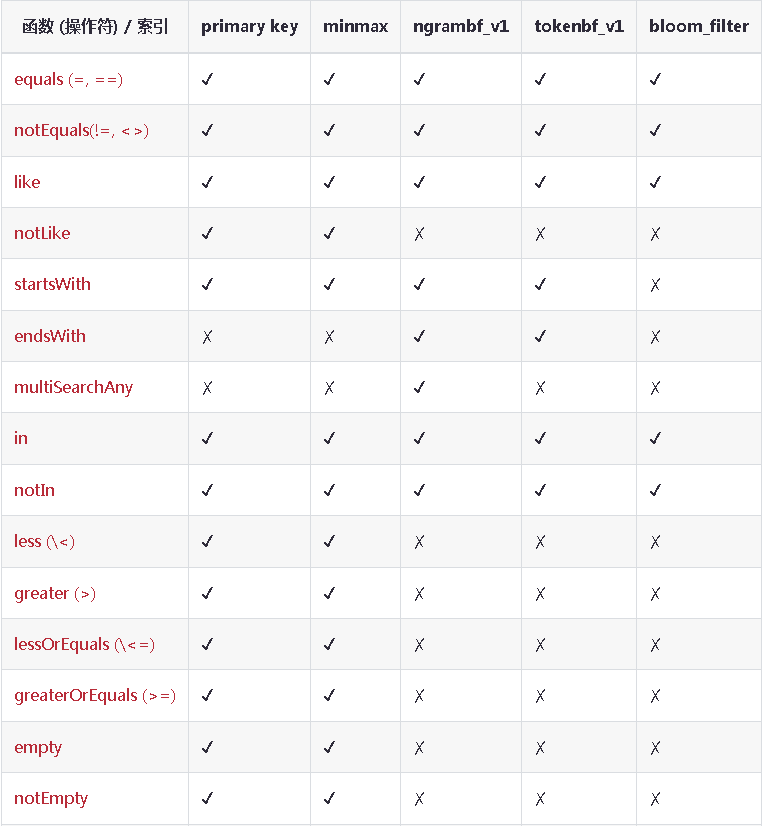
函数支持
WHERE 子句中的条件可以包含对某列数据进行运算的函数表达式,如果列是索引的一部分,ClickHouse会在执行函数时尝试使用索引。不同的函数对索引的支持是不同的。
set 索引会对所有函数生效,其他索引对函数的生效情况见下表
并发数据访问
对于表的并发访问,我们使用多版本机制。换言之,当一张表同时被读和更新时,数据从当前查询到的一组片段中读取。没有冗长的的锁。插入不会阻碍读取。
对表的读操作是自动并行的。
表 TTL
表可以设置一个用于移除过期行的表达式,以及多个用于在磁盘或卷上自动转移数据片段的表达式。当表中的行过期时,ClickHouse 会删除所有对应的行。对于数据片段的转移特性,必须所有的行都满足转移条件。
TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'][, DELETE|TO DISK 'aaa'|TO VOLUME 'bbb'] ...
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ]
TTL 规则的类型紧跟在每个 TTL 表达式后面,它会影响满足表达式时(到达指定时间时)应当执行的操作:
- DELETE - 删除过期的行(默认操作);
- TO DISK 'aaa' - 将数据片段移动到磁盘 aaa;
- TO VOLUME 'bbb' - 将数据片段移动到卷 bbb.
- GROUP BY - 聚合过期的行
使用WHERE从句,您可以指定哪些过期的行会被删除或聚合(不适用于移动)。GROUP BY表达式必须是表主键的前缀。如果某列不是GROUP BY表达式的一部分,也没有在SET从句显示引用,结果行中相应列的值是随机的(就好像使用了any函数)。
示例:
创建时指定 TTL
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb';
修改表的 TTL
ALTER TABLE example_table
MODIFY TTL d + INTERVAL 1 DAY;
创建一张表,设置一个月后数据过期,这些过期的行中日期为星期一的删除:
CREATE TABLE table_with_where
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH DELETE WHERE toDayOfWeek(d) = 1;
创建一张表,设置过期的列会被聚合。列x包含每组行中的最大值,y为最小值,d为可能任意值。
CREATE TABLE table_for_aggregation
(
d DateTime,
k1 Int,
k2 Int,
x Int,
y Int
)
ENGINE = MergeTree
ORDER BY (k1, k2)
TTL d + INTERVAL 1 MONTH GROUP BY k1, k2 SET x = max(x), y = min(y);
删除数据
ClickHouse 在数据片段合并时会删除掉过期的数据。
当ClickHouse发现数据过期时, 它将会执行一个计划外的合并。要控制这类合并的频率, 您可以设置 merge_with_ttl_timeout。如果该值被设置的太低, 它将引发大量计划外的合并,这可能会消耗大量资源。
如果在两次合并的时间间隔中执行 SELECT 查询, 则可能会得到过期的数据。为了避免这种情况,可以在 SELECT 之前使用 OPTIMIZE 。
ClickHouse MergeTree引擎的更多相关文章
- clickhouse核心引擎MergeTree子引擎
在clickhouse使用过程中,针对数据量和查询场景,MergeTree是最常用也是较为合适的表引擎.针对特定的业务,MergeTree的子引擎可以针对不同的业务而定,但都基于MergeTree引擎 ...
- Clickhouse - MergeTree原理
Clickhouse - MergeTree原理 MergeTree引擎以及隶属于MergeTree引擎族的所有引擎是Clickhouse表引擎中最重要, 最强大的引擎. MergeTree引擎族中的 ...
- UniqueMergeTree:支持实时更新删除的 ClickHouse 表引擎
UniqueMergeTree 开发的业务背景 首先,我们看一下哪些场景需要用到实时更新. 我们总结了三类场景: 第一类是业务需要对它的交易类数据进行实时分析,需要把数据流同步到 ClickHouse ...
- ClickHouse(07)ClickHouse数据库引擎解析
目录 Atomic 建表语句 特性 Table UUID RENAME TABLES DROP/DETACH TABLES EXCHANGE TABLES ReplicatedMergeTree in ...
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
目录 建表语法 数据处理策略 资料分享 参考文章 MergeTree拥有主键,但是它的主键却没有唯一键的约束.这意味着即便多行数据的主键相同,它们还是能够被正常写入.在某些使用场合,用户并不希望数据表 ...
- Clickhouse中的预聚合引擎
作者: LemonNan 原文地址: https://mp.weixin.qq.com/s/qXlmGTr4C1NjodXeM4V9pA 注: 转载需注明作者及原文地址 介绍 本文将介绍 Clickh ...
- Linux系统:Centos7下搭建ClickHouse列式存储数据库
本文源码:GitHub·点这里 || GitEE·点这里 一.ClickHouse简介 1.基础简介 Yandex开源的数据分析的数据库,名字叫做ClickHouse,适合流式或批次入库的时序数据.C ...
- ClickHouse
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告 1 安装前的准备1.1 Cent ...
- Clickhouse单机部署以及从mysql增量同步数据
背景: 随着数据量的上升,OLAP一直是被讨论的话题,虽然druid,kylin能够解决OLAP问题,但是druid,kylin也是需要和hadoop全家桶一起用的,异常的笨重,再说我也搞不定,那只能 ...
- ClickHouse学习笔记
1. 概述 ClickHouse是一个用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management Syst ...
随机推荐
- Skywalking Swck Agent注入实现分析
项目地址: GitHub - apache/skywalking-swck: Apache SkyWalking Cloud on Kubernetes 项目简介: A bridge project ...
- PHP全栈开发(八):CSS Ⅶ 表格 style
表格默认是没有边框的,因此,我们在设置表格格式的时候,首先要设置的是表格边框的样式,也就是 table{ border-style:solid; } 设置完表格表格的样式之后,可以设置表格边框的粗细程 ...
- PHP全栈开发(八):CSS Ⅰ 选择器
直到目前为止,我们把从HTML中的数据是如何通过PHP到服务器端,然后又通过PHP到数据库,然后从数据库中出来,通过PHP到HTML的整个过程通过一个案例过了一遍. 可以说,这些才刚刚开始.下面我们开 ...
- 洛谷P2341 [USACO03FALL / HAOI2006] 受欢迎的牛 G (tarjan缩点)
在本题中很明显,给你一个有向图,要用tarjan缩点. 缩点后,一头牛要受到所有牛的欢迎,那么该点的出度要为0,这是容易证明的:如果该点还有出度,比如a连向b,那么a不受到b的欢迎.所以我们要找出度为 ...
- Linux文本相关命令
Linux文本相关命令 目录 Linux文本相关命令 文本排序命令 文本去重命令 基础命令cut 文本三剑客 sed awk grep 文本排序命令 sort 常用参数: -n:以数值大小进行排序 - ...
- 从SVN导出项目出现的乱码问题
解决的方法很简单,只需要将Eclipse的编码标准设置为UTF-8即可 1.Window->Preferences->General->Workspace 面板Text file ...
- flutter系列之:把box布局用出花来
目录 简介 LimitedBox SizedBox FittedBox 总结 简介 flutter中的layout有很多,基本上看layout的名字就知道这个layout到底是做什么用的.比如说这些l ...
- Kafka之 API实战
Kafka之 API实战 一.环境准备 1)启动zk和kafka集群,在kafka集群中打开一个消费者 [hadoop1 kafka]$ bin/kafka-console-consumer.sh \ ...
- 手写自定义springboot-starter,感受框架的魅力和原理
一.前言 Springboot的自动配置原理,面试中经常问到,一直看也记不住,不如手写一个starter,加深一下记忆. 看了之后发现大部分的starter都是这个原理,实践才会记忆深刻. 核心思想: ...
- springboot+vue 实现校园二手商城(毕业设计一)
1.功能划分 2.实现的效果 2.1 登录页面 2.2 注册页面 2.3 商城首页 2.4 商品详情 2.5 购物车 2.6 订单 2.7 在线交流 2.8 公告信息 2.9 个人信息 3.后台管理界 ...