道长的算法笔记:Trie字典树
Trie模板
Trie 是一种用于实现字典序快速检索的多叉树结构,Trie 每个节点都有若干的字符指针,若在扫扫描字符串时扫到字符 \(c\),则沿着当前节点 \(c\) 字符指针走向该指针指向的节点。初始化阶段,Trie近包含一个空节点,其所有字符指针均为空。
通过数组模拟字典树,分配树节点的方式与数组模拟静态链表的方式是一样,使用一个索引变量分配节点,与模拟链表中不同的地方在于分配节点使用++idx而非idx++,这种做法相当于利用 idx=0虚设了一个根节点,也即全局声明idx已经完成了初始化。接下来,Trie 主要操作包括插入与查询两个,其核心逻辑都是自顶向下的遍历:

当要插入一个字符串 \(S\),使用指针 \(p\) 指向根节点,依次扫描\(S\)包含的每个字符\(c\)
- 如果 \(p\) 字符指针指向了空指针,则新建一个节点 \(q\),再令 \(p=q\)
- 如果 \(p\) 字符指针指向了已经存在的节点 \(q\),则令 \(p=q\)
- 如果 \(S\) 已经扫描完毕则在当前节点 \(p\) 标记一下
当要查询一个字符串 \(S\),使用指针 \(p\) 指向根节点,依次扫描 \(S\) 包含的每个字符 \(c\)
- 如果 \(p\) 字符指针指向了空指针,说明字符串不存在,结束检索
- 如果 \(p\) 字符指针指向了已经存在的节点 \(q\),则令 \(p=q\),继续检索
- 如果 \(S\) 已经扫描完毕且当前节点 \(p\) 已被标记则认为 \(S\) 存在,反之不存在,结束检索
char str[MAXN];
int son[MAXN][26], cnt[MAXN], idx = 0;
int insert(char str[]){
int p = 0;
for(int i = 0; str[i]; i++){
int u = str[i] - 'a';
if(!son[p][u]){
son[p][u] = ++idx;
}
p = son[p][u]; // 沿着新建的或已存在的节点往下移动
}
cnt[p]++;
}
int query(char str[]){
int p = 0;
for(int i = 0; str[i]; i++){
int u = str[i] - 'a';
if(!son[p][u]){
return 0;
}
p = son[p][u];
}
return cnt[p]; // 末尾标记不为零则说明字符串存在于树中
}
上述代码逻辑详见代码。如果需要删掉某个单词,只需要把插入逻辑都末端增加,改成末端字符减少即可,Trie 除了用于处理字符串的前缀问题与统计问题之外也常被用于解决最大异或对问题及其变体,但在处理数值类型的元素时,Trie 未必是在末尾进行计数,根据题目的需求,有可能会对每一位都进行计数,
最大异或对
给定的 \(N\) 个整数 \(A_1, A_2,...,A_N\) ,要在其中选出两个元素进行 XOR(异或)运算,其中序列长度范围 \(1 ≤ N ≤ 10^5\), 每个元素的数值范围 \(0≤A_i<2^{31}\),要求解出最大对异或对,本题实际是对 Trie 扩展应用,把元素视为二进制数。边插边查,查询的时候,根据贪心思想,如果同层具有相异的元素则朝着相异的方向往下遍历,否则朝着相同的方向往下遍历。
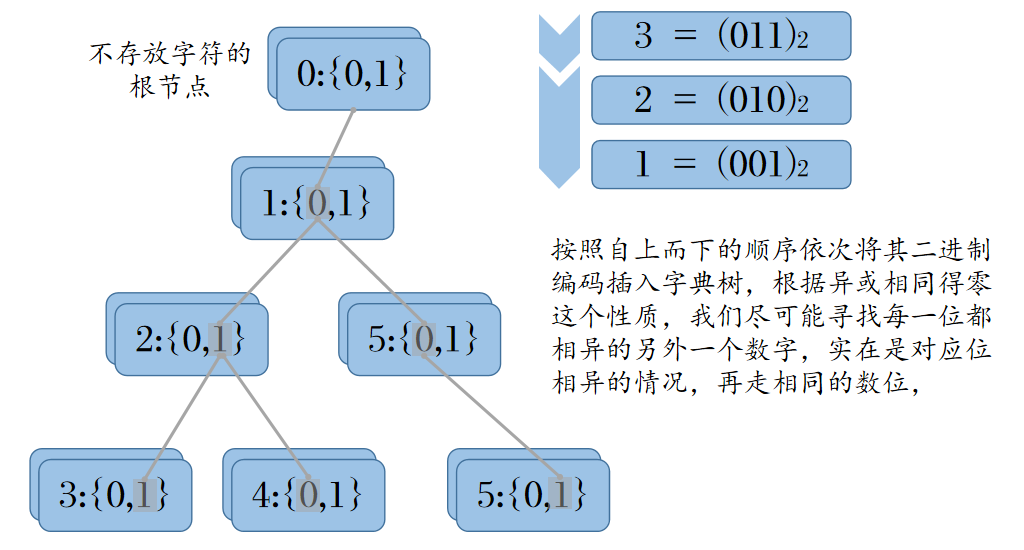
之所以能够能够边插边查,是因为异或满足交换律,\(a \oplus b = b \oplus a\),两两配对构建二元组的复杂度 \(\Theta(n^2)\),但是交换律告诉我们,在计算了 \(a \oplus b\) 之后无需再计算 \(b \oplus a\),因而实际上只需要进行 \(\Theta(\frac{1}{2}n(n+1))\),虽然复杂度的阶数不变,但在代码实现来说,相当于允许我们边插边查,无需先插再查。
#include <bits/stdc++.h>
#include <limits.h>
using namespace std;
#define MAXN 3000005
int sons[MAXN][2], cnt[MAXN], idx;
void insert(int x){
int p = 0;
for(int i = 30; i >= 0; i--){
int u = x >> i & 1;
if(!sons[p][u]){
sons[p][u] = ++idx;
}
p = sons[p][u];
}
cnt[p]++;
}
int query(int x){
int p = 0, ans = 0;
for(int i = 30; i >= 0; i--){
int u = x >> i & 1;
if(sons[p][!u]){
p = sons[p][!u];
ans = 2 * ans + !u;
}else{
p = sons[p][u];
ans = 2 * ans + u;
}
}
return ans;
}
int n, x;
int main(){
scanf("%d", &n);
int ans = 0;
for(int i = 0; i < n ; i++){
scanf("%d", &x);
insert(x);
ans = max(ans, x ^ query(x));
}
printf("%d\n",ans);
return 0;
}
其实本题的 cnt 数组根本不影响答案,因为 32bit int变量转为二进制码长度都是一样的,只要能够走到末尾的叶子节点,即可说明路径对应的数值是存在的。类似的,下面的最长异或路径(AC0146) ,cnt 数组对于答案同样是没有影响的,只有涉及删除操作的时候,cnt 数组才会影响答案,并且彼时 cnt 数组并不在末尾计数,而要对每一个数位都进行计数。
最长异或路径
最长异或路径问题能够转为最大异或对问题,最长异或路径问题中,假设任意两个不相等于的树节点 \(p\)、\(q\),根节点记作 \(r\),我们可以先算从根节点出发,分别到达 \(p\) 与 \(q\) 二者的路径,不妨将其记作,\((p,r)\) 与 \((q,r)\),然后再减掉 \(2\times(LCA(p,q),r)\),其中 \(LCA\) 代表二者的最近公共祖先。

又因为异或的运算系统里面,加减都用 \(\oplus\) 算符,简单化简可知, \((p,r)\oplus (q,r)\) 即为 \(p\) 与 \(q\) 之间连成的异或路径,因而求解最长异或路径的问题转变为找出一对 \((p,r)\)、\((q,r)\) 使得 \((p,r)\oplus (q,r)\) 最大,先对数据预处理,求出所有节点到根节点的距离,至此问题也就变为了最大异或对问题。
#include <bits/stdc++.h>
#include <limits.h>
using namespace std;
#define MAXN 5000005
int head[MAXN], val[MAXN], nxt[MAXN], wgt[MAXN], link;
int sons[MAXN][2], cnt[MAXN], idx;
int arr[MAXN];
void add_edge(int u, int v, int w){
val[link] = v;
wgt[link] = w;
nxt[link] = head[u];
head[u] = link++;
}
void dfs(int u, int parent, int sum){
arr[u] = sum;
for(int i = head[u]; ~i; i = nxt[i]){
int j = val[i];
if(j != parent){
dfs(j, u, sum ^ wgt[i]);
}
}
}
void insert(int x){
int p = 0;
for(int i = 30; i >= 0; i--){
int u = x >> i & 1;
if(!sons[p][u]){
sons[p][u] = ++idx;
}
p = sons[p][u];
}
cnt[p]++;
}
int query(int x){
int p = 0, ans = 0;
for(int i = 30; i >= 0; i--){
int u = x >> i & 1;
if(sons[p][!u]){
p = sons[p][!u];
ans = 2 * ans + !u;
}else{
p = sons[p][u];
ans = 2 * ans + u;
}
}
return ans;
}
int n, x;
int main(){
memset(head, -1, sizeof(head));
scanf("%d", &n);
int a, b, w, ans = 0;
for(int i = 0; i < n - 1; i++){
scanf("%d %d %d", &a, &b, &w);
add_edge(a, b, w);
add_edge(b, a, w);
}
dfs(0, -1, 0);
for(int i = 0; i < n ; i++){
insert(arr[i]);
}
for(int i = 0; i < n ; i++){
ans = max(ans, arr[i] ^ query(arr[i]));
}
printf("%d\n",ans);
return 0;
}
本小节提到的最近公共祖先(LCA)是一个树结构算法题中非常经典的母题,
离线最大异或和
#include <bits/stdc++.h>
#include <limits.h>
using namespace std;
#define MAXN 3500005
int sons[MAXN][2], cnt[MAXN], idx;
int prefix[MAXN];
void insert(int x, int c){
int p = 0;
for(int i = 30; i >= 0; i--){
int u = x >> i & 1;
if(!sons[p][u]){
sons[p][u] = ++idx;
}
p = sons[p][u];
cnt[p] += c;
}
}
/**
* 在一些题解中,(1)与(2)两处的!u与u 会被硬编码写成1与0,
* 这种写法是因为那些作者直接使用 query 计算两个元素异或的结果,然而,
* 注意我们更新 ans 变量的方式,我们是在使用 query 查找能跟当前元素异或最大的另一个元素!
*/
int query(int x){
int p = 0, ans = 0;
for(int i = 30; i >= 0; i--){
int u = x >> i & 1;
if(cnt[sons[p][!u]]){
p = sons[p][!u];
ans = 2 * ans + !u; // (1)
}else{
p = sons[p][u];
ans = 2 * ans + u; // (2)
}
}
return ans;
}
int n, m, x;
int main(){
scanf("%d %d", &n, &m);
int ans = 0;
for(int i = 1; i <= n ; i++){
scanf("%d", &x);
prefix[i] = prefix[i - 1] ^ x;
}
insert(0, 1);
for(int i = 1; i <= n; i++){
if(i > m){
insert(prefix[i - m - 1], -1);
}
// 先更新再插入,因为答案有可能落在[0,i],上文中我们预插了一个 0 用于处理这种情况
ans = max(ans, prefix[i] ^ query(prefix[i]));
insert(prefix[i], 1);
}
printf("%d\n",ans);
return 0;
}
在线最大异或和
待更新…
道长的算法笔记:Trie字典树的更多相关文章
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- 用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成“***”就可 ...
- 算法导论:Trie字典树
1. 概述 Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树. Trie一词来自retrieve,发音为/tr ...
- 萌新笔记——C++里创建 Trie字典树(中文词典)(一)(插入、遍历)
萌新做词典第一篇,做得不好,还请指正,谢谢大佬! 写了一个词典,用到了Trie字典树. 写这个词典的目的,一个是为了压缩一些数据,另一个是为了尝试搜索提示,就像在谷歌搜索的时候,打出某个关键字,会提示 ...
- 踹树(Trie 字典树)
Trie 字典树 ~~ 比 KMP 简单多了,无脑子选手学不会KMP,不会结论题~~ 自己懒得造图了OI WIKI 真棒 字典树大概长这么个亚子 呕吼真棒 就是将读进去的字符串根据当前的字符是什么和所 ...
- Trie字典树 动态内存
Trie字典树 #include "stdio.h" #include "iostream" #include "malloc.h" #in ...
- 标准Trie字典树学习二:Java实现方式之一
特别声明: 博文主要是学习过程中的知识整理,以便之后的查阅回顾.部分内容来源于网络(如有摘录未标注请指出).内容如有差错,也欢迎指正! 系列文章: 1. 标准Trie字典树学习一:原理解析 2.标准T ...
- 817E. Choosing The Commander trie字典树
LINK 题意:现有3种操作 加入一个值,删除一个值,询问pi^x<k的个数 思路:很像以前lightoj上写过的01异或的字典树,用字典树维护数求异或值即可 /** @Date : 2017- ...
- C++里创建 Trie字典树(中文词典)(一)(插入、遍历)
萌新做词典第一篇,做得不好,还请指正,谢谢大佬! 写了一个词典,用到了Trie字典树. 写这个词典的目的,一个是为了压缩一些数据,另一个是为了尝试搜索提示,就像在谷歌搜索的时候,打出某个关键字,会提示 ...
- 数据结构 -- Trie字典树
简介 字典树:又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种. 优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高. 性质: 1. 根节 ...
随机推荐
- Go素数筛选分析
Go素数筛选分析 1. 素数筛选介绍 学习Go语言的过程中,遇到素数筛选的问题.这是一个经典的并发编程问题,是某大佬的代码,短短几行代码就实现了素数筛选.但是自己看完原理和代码后一脸懵逼(仅此几行能实 ...
- PX01关于手机屏SPI触摸调试学习笔记
上位机工具:http://www.xk-image.com/download/blog/0002_TP调试/LcdTools20210605.rar 调试案例:http://www.xk-image. ...
- 2.asyncio快速上手
事件循环:可以理解成一个死循环,去检测并执行某些代码 import asyncio # 去生成或者获取一个事件循环 loop = asyncio.get_event_loop() # 将任务放到事 ...
- 【MySQL】02_子查询与多表查询
子查询 指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL 4.1开始引入. SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者 ...
- CSS选择器大全48式
00.CSS选择器 CSS的选择器分类如下图,其中最最常用的就是基础选择器中的三种:元素选择器.类选择器.id选择器.伪类选择器就是元素的不同行为.状态,或逻辑.然后不同的选择器组合,基于不同的组合关 ...
- CodeTON Round 3 (C.差分维护,D.容斥原理)
C. Complementary XOR 题目大意: 给你两个01串ab,问你是否可以通过一下两种操作在不超过n+5次的前提下将两个串都变为0,同时需要输出可以的操作方案 选择一个区间[l,r] 将串 ...
- JavaScript&Bootstrap
1. JS介绍 JS诞生主要是完成页面的数据验证.因此它运行在客户端,需要浏览器来执行JS代码 JS最早取名LiveScript:为了吸引更多的Java程序员,更名JavaScript JS是弱类型, ...
- 记一次HTTPClient模拟登录获取Cookie的开发历程
记一次HTTPClient模拟登录获取Cookie的开发历程 环境: springboot : 2.7 jdk: 1.8 httpClient : 4.5.13 设计方案 通过新建一个 ...
- 嵌入式-C语言基础:函数指针
定义函数地址:如果在程序中定义了一个函数,那么在编译的时候,编译系统为函数代码分配一段存储空间,这段存储空间的起始地址(也叫入口地址)称为这个函数的地址. 和数组一样,数组名代表地址,而函数名表示函数 ...
- XMind2022安装激活
1. 下载XMind2021并安装 2. 激活安装 2.1 找到需要替换文件的目录右击软件,打开文件所在的位置(默认路径:C:\Program Files\XMind),找到resources文件夹 ...