MySQL优化三,SQL语法
## 1.3.MySQL调优
前言:在前面的基础之上把相应的数据库表设计得很完美,建立了好用的索引,如果SQL语句中没有使用到相应索引的话,也是白搭,如何设计好一点的SQL,则是一大问题
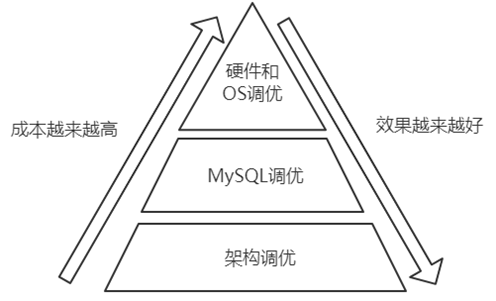
### 1.3.1.MySQL调优金字塔
### 1.3.2.查询性能优化
#### 1.3.2.1.什么是慢查询
##### **1.3.2.1.1慢查询基础-优化数据访问**
##### **1.3.2.1.2请求了不需要的数据?**
##### 1.3.2.1.3.是否在扫描额外的记录
#### 1.3.3.1慢查询配置
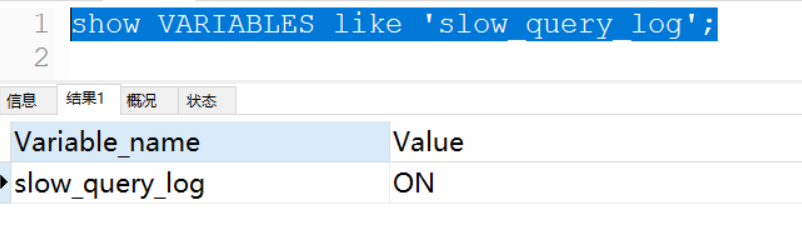
show VARIABLES like 'slow_query_log';
开启1,关闭0
set GLOBAL slow_query_log=1;
show VARIABLES like '%long_query_time%';
set global long_query_time=0;
show VARIABLES like '%log_queries_not_using_indexes%';

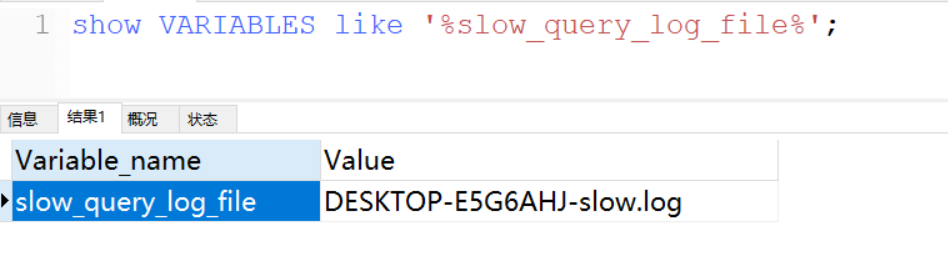
show VARIABLES like '%slow_query_log_file%';
##### 小结
### 1.3.4.Explain执行计划
#### 1.3.4.1.什么是执行计划
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
#### 1.3.4.2.执行计划的语法
#### 1.3.4.3.执行计划详解
id列:
表示执行顺序,值越大则优先级越高;值相同则从上而下执行
select_type列常见的有:
|
1
2
3
4
5
6
7
8
|
simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。 且只有一个union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表 select_type都是uniondependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为nullsubquery:除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquerydependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌select |
table列
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的<derived N>就表示这个是临时表,后边的N就是执行计划 中的id,表示结果来自于这个查询产生。如果是尖括号括起来<union M,N>,与<derived N>类似, 也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集
Type列
:表示访问类型,性能从低到高依次是:ALL->index->range->ref->eq_ref->const->system
- ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
- index:Full Index Scan(覆盖索引)index与ALL区别为index类型只遍历索引树,例如count(*)
- range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、and ,in, <、 >等的查询
- unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
- index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重
- ref:非唯一性索引扫描,等值匹配,可能有多行命中。返回匹配某个单独值的所有行。常见于使用非唯一索引和唯一索引的非唯一前缀进行的查找
- eq_ref:唯一性索引扫描,PK或者unique上的join查询。对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描的多表链接操作中
- system最快:不进行磁盘IO。当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该 查询转换为一个常量。 System为表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表, type列在这个情况通常都是all或者index
- const:使用唯一索引或者主键上的等值查询,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
- NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引
possible_keys列
表示MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
Key列:
表示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
key_len列:
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
Ref列:
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
Rows列:
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,值越大性能越差
Extra列:
包含不适合在其他列中显示但十分重要的额外信息
MySQL优化三,SQL语法的更多相关文章
- MySQL优化三(InnoDB优化)
body { font-family: Helvetica, arial, sans-serif; font-size: 14px; line-height: 1.6; padding-top: 10 ...
- 【Mysql优化三章】第一章
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/Bv5f4b8Peex/article/details/78130845 如今网上的好多mysql优化 ...
- 【原创】6. 在MYSQL++中实现SQL语法中的NULL
这次要说明的是在MYSQL++中为了实现SQL中的NULL而做出的一系列的举措.我的感觉是Null<T, B>类型通常出现在SSQLS和template Query中比较多. 1. 什么是 ...
- mysql优化之SQL语句优化
Mysql优化是一个老生常谈的问题, 优化的方向也优化很多:从架构层;从设计层;从存储层;从SQL语句层; 今天讲解一下从SQL语句层: 这个部分是程序员最容易把控的地方,也是最容易忽视的地方. 一个 ...
- MySQL优化三 表结构优化
由于MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大 ...
- MySQL优化(三):优化数据库对象
二.优化数据库对象 1.优化表的数据类型 应用设计的时候需要考虑字段的长度留有一定的冗余,但不推荐很多字段都留有大量的冗余,这样既浪费磁盘空间,也在应用操作时浪费物理内存. 在MySQL中,可以使用函 ...
- MySQL 优化 (三)
参数优化 query_cache_size (1) 简介: 查询缓存简称QC,使用查询缓冲,mysql将查询结果存放在缓冲区中,今后对于同样的select语句(区分大小写),将直接从缓冲区中读取结果. ...
- MySQL优化五 SQL优化
1.减少 IO 次数 IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然 ...
- mysql优化三
1. 为查询缓存优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的.当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一 ...
- mysql优化和sql语句优化总结
mysql性能优化 1. EXPLAIN 你的 SELECT 查询.使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的.这可以帮你分析你的查询语句或是表结构的性能瓶颈. 2. ...
随机推荐
- MySQL安装卸载、idea中Database的使用、常用的sql语句
MySQL安装卸载 MySQL安装 在下面的资源链接中下载MySQL软件压缩包(绿色版),这个版本是MySQL5.7.29的,本教程也只适用于这个绿色版的,如果下载的是安装包那就可能有些地方不一样了, ...
- v-for和router-link的共同使用
1. 错误例子 <div style="color: red" v-for="item in pressionList" :key="item. ...
- 齐博x1如何取消禁止跨城市密码登录限制
为安全起意见,只要用户绑定了手机,或者QQ登录,或者微信登录其中的一项,只要用户的IP所在城市变了,就会禁止密码登录.如下图所示 而必须选择绑定过的手机或QQ或微信其中一种方式登录.以避免密码被盗所带 ...
- 使用LEFT JOIN 统计左右存在的数据
最近做了一个数据模块的统计,统计企业收款.发票相关的数据,开始统计是比较简单,后面再拆分账套统计就有点小复杂,本文做一个简单的记录. 需求 企业表 企业表t_company有如下字段:标识id.企业名 ...
- 二、Kubernetes 概念介绍
一.Master Master指的是集群控制节点,在每个Kubernetes集群里都需要有一个Master来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它负责具体的 ...
- Day16异常1
package com.exception.demo01;public class demo01 { public static void main(String[] args) { try{new ...
- 部署owncloud连接ladp迁移数据
定期 清理日志 echo '' > /var/www/html/data/owncloud.log 查询 用户 的 ldap 语句 (|(objectclass=inetOrgPerson)(o ...
- vim-瞬间移动打发
一,常用基本命令 set rnu 显示相对行号 1.ctrl+F 将屏幕向下滚动一屏 2.ctrl+u pageUp,ctrl+d pageDown 3.行内移动:W,b在单词间移动,ge向上跳,f ...
- SpringBoot使用@Async的总结!
一些业务场景我们需要使用多线程异步执行任务,加快任务执行速度. 之前有写过一篇文章叫做: 异步编程利器:CompletableFuture 在实际工作中也更加推荐使用CompletableFuture ...
- Android网络请求(1)
Android网络请求(1) 安卓开发网络请求可谓是安卓开发的灵魂,如果你不会网络请求,那么你开发的应用软件就是一具没有灵魂的枯骨. 在安卓开发中进行网络请求和java中的网络请求有异曲同工之 ...