KeeWiDB的高性能修炼之路:架构篇
数据也有冷热之分,你知道吗?
根据访问的频率的高低可将数据分为热数据和冷数据,访问频率高的则为热数据,低为冷数据。如果热、冷数据不区分,一并存储,显然不科学。将冷数据也存储在昂贵的内存中,那么你想,成本得多高呢?
有趣的是,根据我们实际的观察,目前很多使用 Redis 的业务就是这样操作的。
得益于高性能以及丰富的数据结构命令,Redis 成为目前最受欢迎的 KV 内存数据库。但随着业务数据量的爆炸增长,Redis 的内存消耗也会随之爆炸。无论客户是自建服务器还是云服务器,内存都是一个必须考虑的成本问题,它不仅贵还要持续购买。
此外 Redis 虽然提供了 AOF 和 RDB 两种方案来实现数据的持久化,但是使用不当可能会对性能造成影响甚至引发丢数据的问题。
好在,随着科技的发展,持久化硬件的发展速度也在提升,持久内存的出现进一步缩小了与内存的性能差距。或许,合理利用新型持久化技术会成为一个好的成本解决方案。
基于这一思路,为解决 Redis 可能带来的内存成本、容量限制以及持久化等一系列问题,腾讯云数据库团队推出了新一代分布式KV存储数据库 KeeWiDB。本文将详细介绍KeeWiDB 的架构设计思路、实现路径及成效。先简单总结一下 KeeWiDB 的特性:
- 友好:完全兼容 Redis 协议,原先使用 Redis 的业务无需修改任何代码便可以迁移到 KeeWiDB 上;
- 高性能低延迟:通过创新性的分级存储架构设计,单节点读写能力超过 18 万 QPS,访问延迟达到毫秒级;
- 更低的成本:内核自动区分冷热数据,冷数据存储在相对低价的 SSD 上;
- 更大的容量:节点支持 TB 级别的数据存储,集群支持 PB 级别的数据存储;
- 保证了事务的 ACID (原子性 Atomicity、一致性 Consitency、隔离性 Isolation、持久性 Durability)四大特性;
一、整体架构
KeeWiDB 的架构由代理层和服务层两个部分构成:
代理层:由多个无状态的Proxy节点组成,主要功能是负责与客户端进行交互;
服务层:由多个Server节点组成的集群,负责数据的存储以及在机器发生故障时可以自动进行故障切换。
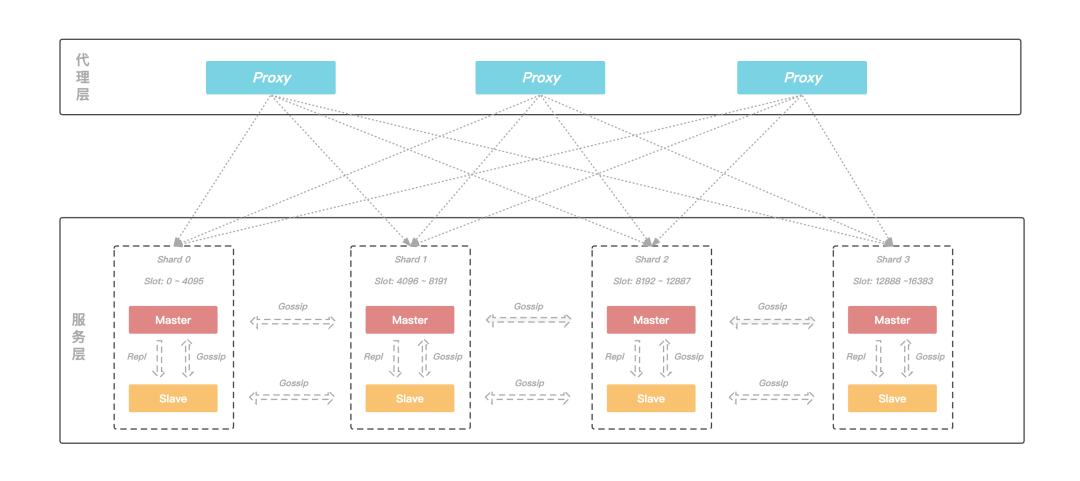
图:KeeWiDB整体架构图
代理层
客户端通过 Proxy 连接来进行访问,由于 Proxy 内部维护了后端集群的路由信息,所以 Proxy 可以将客户端的请求转发到正确的节点进行处理,从而客户端无需关心集群的路由变化,用户可以像使用 Redis 单机版一样来使用 KeeWiDB。
Proxy 的引入,还带来了诸多优势:
- 客户端直接和 Proxy 进行交互,后端集群在扩缩容场景不会影响客户端请求;
- Proxy 内部有自己的连接池和后端 KeeWiDB 进行交互,可大大减少 KeeWiDB 上的连接数量,同时有效避免业务短连接场景下反复建连断连对内核造成性能的影响;
- 支持读写分离,针对读多写少的场景,通过添加副本数量可以有效分摊 KeeWiDB 的访问压力;
- 支持命令拦截和审计功能,针对高危命令进行拦截和日志审计,大幅度提高系统的安全性;
- 由于 Proxy 是无状态的,负载较高场景下可以通过增加 Proxy 数量来缓解压力,此外我们的 Proxy 支持热升级功能,后续 Proxy 添加了新功能或者性能优化,存量 KeeWiDB 实例的 Proxy 都可以进行对客户端无感知的平滑升级;
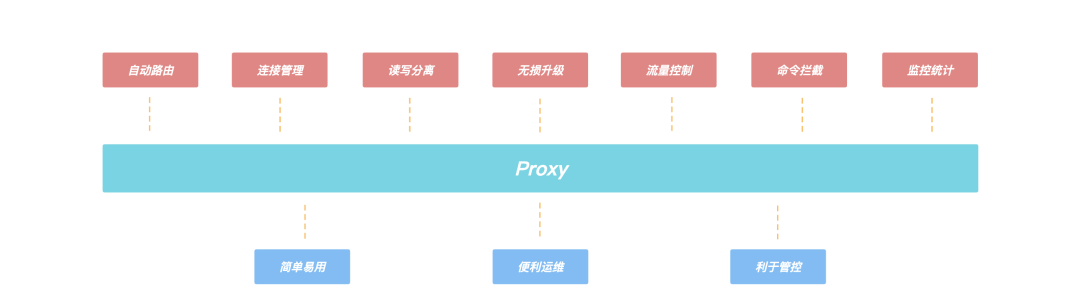
图:Proxy上的功能
服务层
KeeWiDB 的后端采用了集群的架构,这是因为集群具有高可用、可扩展性、分布式、容错等优质特性;同时,在具体的实现上参考了 Redis 的集群模式。KeeWiDB 集群同样由若干个分片构成,而每个分片上又存在若干个节点,由这些节点共同组成一主多从的高可用架构;此外每个分片的主节点负责集群中部分 Slot 的数据,并且可以通过动态修改主节点负责 Slot 区间的形式来实现横向的扩缩容,为客户提供了容量可弹性伸缩的能力。
二、Server内部模型
在 Server 内部存在一个集群管理模块,该模块通过 Gossip 协议与集群中的其他节点进行通信,获取集群的最新状态信息;另外 Server 内部存在多个工作线程,KeeWiDB 会将当前 Server 负责的 Slot 区间按一定的规则划分给各个工作线程进行处理, 并且每个工作线程都有自己独立的连接管理器,事务模块以及存储引擎等重要组件,线程之间不存在资源共享,做到了进程内部的 Shared-Nothing。正是这种 Shared-Nothing 的体系结构,减少了 KeeWiDB 进程内部线程之间由于竞争资源的等待时间,获得了良好并行处理能力以及可扩展的性能。
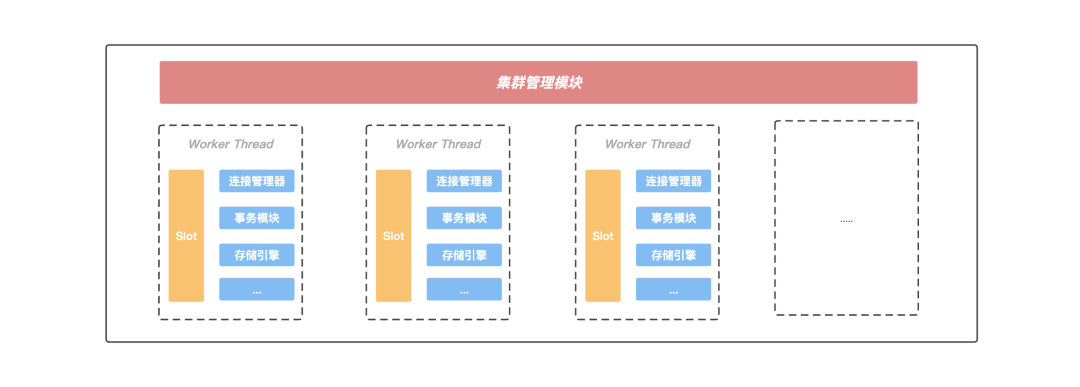
图:Server内部模块
线程模型
KeeWiDB 的设计目的,就是为了解决 Redis 的痛点问题。所以大容量,高性能以及低延迟是 KeeWiDB 追求的目标。
和数据都存放在内存中的 Redis 不同,KeeWiDB 的数据是存储在 PMem(Persistent Memory)和相对低价的 SSD 上。在用户执行读写访问请求期间 KeeWiDB 都有可能会涉及到跟硬盘的交互,所以如果还像 Redis 一样采用单进程单线程方案的话,单节点的性能肯定会大打折扣。因此,KeeWiDB 采取了单进程多线程的方案,一方面可以更好的利用整机资源来提升单节点的性能,另一方面也能降低运维门槛。
多线程方案引入的核心思想是通过提高并行度来提升单节点的吞吐量,但是在处理用户写请求期间可能会涉及到不同线程操作同一份共享资源的情况,比如存储引擎内部为了保证事务的原子性和持久性需要写 WAL,主从之间进行同步需要写 Binlog,这些日志文件在写入的过程中通常会涉及到持久化操作,相对较慢。虽然我们也采取了一系列的优化措施,例如使用组提交策略来降低持久化的频率,但是优化效果有限。
同时为了保证线程安全,在这类日志的写入期间通常都要进行加锁,这样一来,一方面虽然上层可以多线程并行的处理用户请求,但是到了写日志期间却退化成了串行执行;另一方面,申请和释放锁通常会涉及到用户态和内核态的切换,频繁的申请释放操作会给 CPU 带来额外的开销,显然会导致性能问题。

图:线程模型
正是由于进程内不同线程访问同一份共享资源需要加锁,而大量的锁冲突无法将多线程的性能发挥到极致,所以我们将节点内部负责的 Slot 区间进行进一步的拆分,每个工作线程负责特定一组 Slot 子区间的读写请求,互不冲突;此外每个工作线程都拥有自己独立的事务模块以及存储引擎等重要组件,不再跨线程共享。
通过对共享资源进行线程级别的拆分,各个线程在处理用户请求时都可以快速的获得所需要的资源,不发生等待事件,这无论是对单个请求延迟的降低还是多个请求并发的提升,都有巨大的好处;此外由于处理用户请求所需的资源都在线程内部,KeeWiDB 无需再为了线程安全而上锁,有效规避了由于频繁上锁带来的额外性能开销。
引入协程
通过上面的章节介绍,KeeWiDB 通过进程内部 Shared-Nothing 的体系结构减少了线程之间由于竞争共享资源花费的等待时间,提升了进程内部的并发度。此时我们再将视角转移到线程内部,在业务高峰时期工作线程也需要负责处理大量的客户端请求,由于每次请求操作都有可能会涉及到和磁盘的交互,此时如果再采用同步 IO 的形式和磁盘进行交互的话,由于一个客户端请求执行的 I/O 操作就会阻塞当前线程,此时后面所有的客户端请求需要排队等待处理, 显然并发度会大打折扣。
这时候也许有读者会提出按照 KeeWiDB 目前这套进程内部 Shared-Nothing 的体系结构,线程之间不存在共享资源竞争了,是不是可以通过增加线程数来缓解这个问题?想法不错,但是大量的线程引入可能会带来另外一些问题:
- 开启过多的线程会耗费大量的系统资源, 包括内存;
- 线程的上下文切换涉及到用户空间和内核空间的切换, 大量线程的上下文切换同样会给 CPU 带来额外的开销;
为了让单个线程的性能能够发挥到极致,不把时间浪费在等待磁盘 I/O 上,KeeWiDB 首先考虑的是采取异步 I/O 的方案(应用层触发 I/O 操作后立即返回,线程可以继续处理其他事件,而当 I/O 操作已经完成的时候会得到 I/O 完成的通知)。
很明显,使用异步 I/O 来编写程序性能会远远高于同步 I/O,但是异步 I/O 的缺点是编程模型复杂。我们常规的编码方式是自上而下的,但是异步 I/O 编程模型大多采用异步回调的方式。
随着项目工程的复杂度增加,由于采用异步回调编写的代码和常规编码思维相悖,尤其是回调嵌套多层的时候,不仅开发维护成本指数级上升,出错的几率以及排查问题的难度也大幅度增加。
正是由于异步 I/O 编程模型有上面提到的种种缺点, 我们经过一系列调研工作之后,决定引入协程来解决我们的痛点, 下面先来看一下cppreference中对协程的描述:
A coroutine is a function that can suspend execution to be resumed later. Coroutines are stackless: they suspend execution by returning to the caller and the data that is required to resume execution is stored separately from the stack. This allows for sequential code that executes asynchronously (e.g. to handle non-blocking I/O without explicit callbacks).
from:https://en.cppreference.com/w/cpp/language/coroutines
协程实际上就是一个可以挂起(suspend)和恢复(resume)的函数,我们可以暂停协程的执行,去做其他事情,然后在适当的时候恢复到之前暂停的位置继续执行接下来的逻辑。总而言之,协程可以让我们使用同步方式编写异步代码。
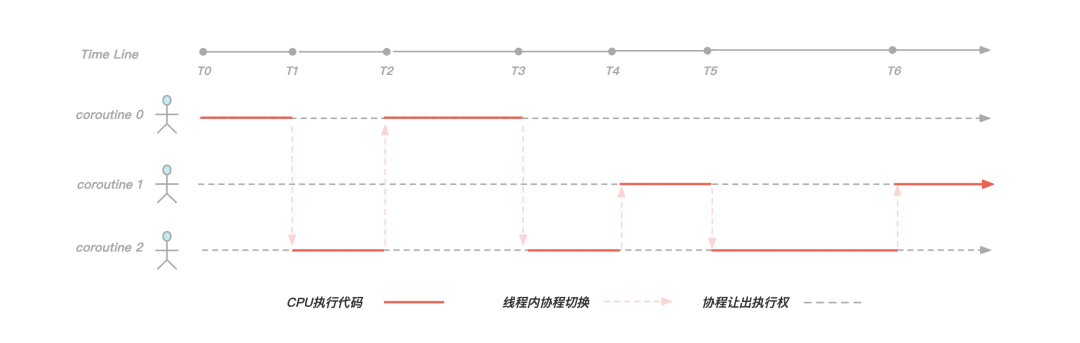
图:协程切换示意图
KeeWiDB 为每一个客户端连接都创建了一个协程,以上图为例,在工作线程内服务三个客户端连接,就创建三个协程。在[T0,T1)阶段协程0正在执行逻辑代码,但是到了T1时刻协程0发现需要执行磁盘 I/O 操作获取数据,于是让出执行权并且等待 I/O 操作完成,此时协程2获取到执行权,并且在[T1,T2)时间段内执行逻辑代码,到了T2时刻协程2让出执行权,并且此时协程0的 I/O 事件正好完成了,于是执行权又回到协程0手中继续执行。
可以看得出来,通过引入协程,我们有效解决了由于同步 I/O 操作导致线程阻塞的问题,使线程尽可能的繁忙起来,提高了线程内的并发;另外由于协程切换只涉及基本的 CPU 上下文切换,并且完全在用户空间进行,而线程切换涉及特权模式切换,需要在内核空间完成,所以协程切换比线程切换开销更小,性能更优。
三、数据存储
在文章开头有提到在持久内存出现后,进一步缩小了与内存的性能差距,持久内存是一种新的存储技术,它结合了 DRAM 的性能和字节寻址能力以及像 SSD 等传统存储设备的可持久化特性,正是这些特性使得持久内存非常有前景,并且也非常适合用于数据库系统。

图:Dram和PMem以及SSD的性能比较
通过上图可以看到,PMem(Persistent Memory)相对于 DRAM 有着更大的容量,但是相对于 SSD 有着更大的带宽和更低的读写延迟,正是因为如此,它非常适合存储引擎中的大容量Cache和高性能 WAL 日志。
前面有提到过日志文件在写入的过程中涉及到的持久化操作有可能会成为整个系统的瓶颈,我们通过将 WAL 存放在 PMem 上,日志持久化操作耗时大幅降低,提升了服务整体的性能;此外由于 PMem 的读写速度比 SSD 要快1~2个数量级,在故障恢复期间,回放 WAL 的时间也大幅度的缩短,整个系统的可用性得到了大幅度的提升。
考虑到 KeeWiDB 作为高性能低延迟的数据库,我们不仅需要做到平均延迟低,更要做到长尾延迟可控。
虽然在涉及到文件操作的场景下,利用 Page Cache 技术能够大幅提升文件的读写速度,但是由于 Page Cache 默认由操作系统调度分配,存在一定的不确定性(内核总是积极地将所有空闲内存都用作 Page Cache 和 Buffer Cache,当内存不够用时就会使用 LRU 等算法淘汰缓存页, 此时有可能造成文件读写操作有时延抖动),在一些极端场景下可能会直接影响客户实例的P99,P100。所以** KeeWiDB 采用了 Direct I/O的方式来绕过操作系统的 Page Cache 并自行维护一份应用层数据的 Cache,让磁盘的 IO 更加可控**。
使用 Page cache 能够大大加速文件的读写速度,那什么是页面缓存(Page Cache)呢?
In computing, a page cache, sometimes also called disk cache, is a transparent cache for the pages originating from a secondary storage device such as a hard disk drive (HDD) or a solid-state drive (SSD). The operating system keeps a page cache in otherwise unused portions of the main memory (RAM), resulting in quicker access to the contents of cached pages and overall performance improvements. A page cache is implemented in kernels with the paging memory management, and is mostly transparent to applications.
from:https://en.wikipedia.org/wiki/Page_cache#cite_note-1
和大多数磁盘数据库一样,KeeWiDB 将 Page 作为存储引擎磁盘管理的最小单位,将数据文件内部划分成若干个 Page,每个 Page 的大小为 4K,用于存储用户数据和一些我们存储引擎内部的元信息。从大容量低成本的角度出发,KeeWiDB 将数据文件存放在 SSD 上。
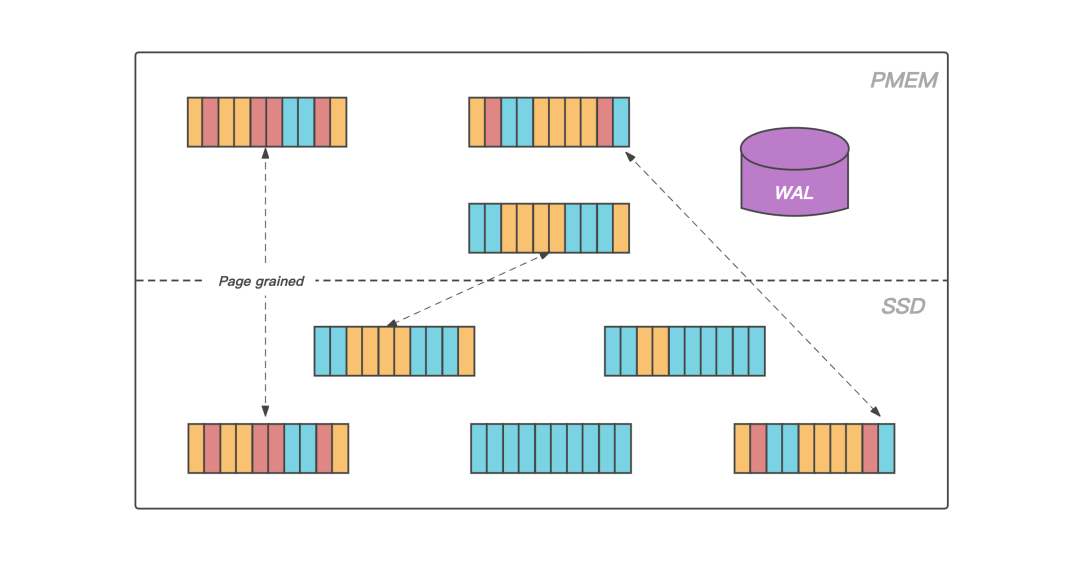
图:数据页的升温和落冷
此外,得益于 PMem 接近于 DRAM 的读写速度以及支持字节寻址的能力,KeeWiDB在 PMem 上实现了存储引擎的 Cache 模块,在服务运行期间存放业务热数据的数据页会被加载到 PMem 上,KeeWiDB 在处理用户请求期间不再直接操作 SSD 上的数据页,而是操作读写延迟更低的 PMem,使得 KeeWiDB 的性能以及吞吐量得到了进一步的提升;
同时为了能够合理高效的利用 PMem 上的空间,KeeWiDB 内部实现了高效的 LRU 淘汰算法,并且通过异步刷脏的方式,将 PMem 中长时间没有访问的数据页写回到 SSD 上的数据文件中。
四、主从同步
文章开头的架构图有提到 KeeWiDB 集群由多个分片构成,每个分片内部有多个节点,这些节点共同组成一主多从的高可用架构。和 Redis 类似,用户的请求会根据 Key 被路由到对应分片的主节点,主节点执行完后再将请求转化为 Binlog Record 写入本地的日志文件并转发给从节点,从节点通过应用日志文件完成数据的复制。
在 Redis 的 Replication 实现中,从节点每接收一个请求都立即执行,然后再继续处理下一个请求,如此往复。依赖其全内存的实现,单个请求的执行耗时非常短,从节点的回放相当于是单连接的 pipeline 写入,其回放速度足以跟上主节点的执行速度。但这种方式却不适合 KeeWiDB 这样的存储型数据库,主要原因如下:
- 存储型数据库的请求执行过程中涉及到磁盘 IO,单个请求的执行耗时本身就比较长;
- 主节点同时服务多个客户端连接,不同连接的请求并发执行,发挥了协程异步 IO 的优势,节点整体 QPS 有保障;
- 主从同步只有一个连接,由于从库顺序回放请求,无法并发,回放的 QPS 远远跟不上主节点处理用户请求的 QPS;
为了提升从节点回放的速度,避免在主库高负载写入场景下,出现从库追不上主库的问题,KeeWiDB 的 Replication 机制做了以下两点改进:
- 在从节点增加 RelayLog 作为中继,将从节点的命令接收和回放两个过程拆开,避免回放过程拖慢命令的接收速度;
- 在主节点记录 Binlog 的时候增加逻辑时钟信息,回放的时候根据逻辑时钟确定依赖关系,将互相之间没有依赖的命令一起放进回放的协程池,并发完成这批命令的回放,提升从节点整体的回放 QPS;
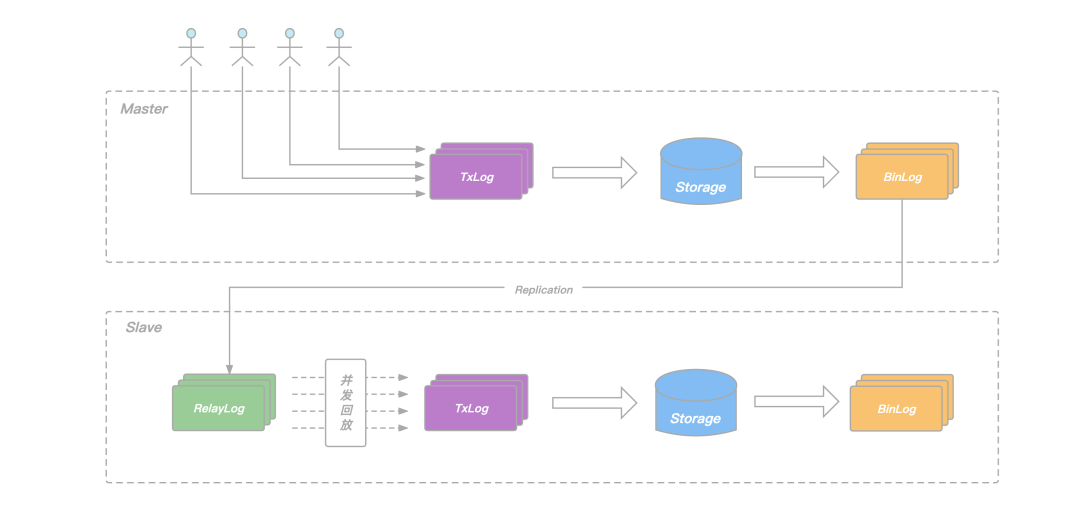
图:从库并发回放
所谓的逻辑时钟,对应到 KeeWiDB 的具体实现里,就是我们在每一条 BinLog record 中添加了 seqnum 和 parent 两个字段:
- seqnum 是主节点事务 commit 的序列号,每次有新的事务 commit,当前 seqnum 赋给当前事务,全局 seqnum 自增1;
- parent 由主节点在每个事务开始执行前的 prepare 阶段获取,记录此时已经 commit 的最大 seqnum,记为 max,说明当前事务是在 max 对应事务 commit 之后才开始执行,二者在主节点端有逻辑上的先后关系;
从节点回放 RelayLog 中的 Binlog Record 时,我们只需要简单地将它的 parent 和 seqnum 看作一个区间,简记为(P,S),如果它的(P,S)区间和当前正在回放的其它Record 的(P,S)区间有交集,说明他们在主节点端 Prepare 阶段没有冲突,可以把这条 Record 放进去一块并发地回放,反之,则这条 Record 需要阻塞等待,等待当前正在回放的这批 Binlog Record 全部结束后再继续。
通过在 Binlog 中添加 seqnum 和 parent 两个字段,我们在保证数据正确性的前提下实现了从库的并发回放,确保了主库在高负载写入场景下,从库依旧可以轻松的追上主库,为我们整个系统的高可用提供了保障。
五、总结
本篇文章先从整体架构介绍了 KeeWiDB 的各个组件,然后深入 Server 内部分析了在线程模型选择时的一些思考以及面临的挑战,最后介绍了存储引擎层面的数据文件以及相关日志在不同存储介质上的分布情况,以及 KeeWiDB 是如何解决从库回放 Binlog 低效的问题。通过本文,相信不少读者对 KeeWiDB 又有了进一步的了解。那么,在接下来的文章中我们还会深入到 KeeWiDB 自研存储引擎内部,向读者介绍 KeeWiDB 在存储引擎层面如何实现高效的数据存储和索引,敬请期待。
目前,KeeWiDB 正在公测阶段(链接:https://cloud.tencent.com/product/keewidb ),现已在内外部已经接下了不少业务,其中不乏有一些超大规模以及百万 QPS 级的业务,线上服务均稳定运行中。
后台回复“KeeWiDB”,试试看,有惊喜。
关于作者
吴显坚,腾讯云数据库高级工程师。负责过开源项目Pika的核心研发工作,对数据库、分布式存储有一定了解,现从事腾讯云Redis内核以及KeeWiDB的研发工作。
KeeWiDB的高性能修炼之路:架构篇的更多相关文章
- (转)Android项目重构之路:架构篇
去年10月底换到了新公司,做移动研发组的负责人,刚开始接手android项目时,发现该项目真的是一团糟.首先是其架构,是按功能模块进行划分的,本来按模块划分也挺好的,可是,他却分得太细,总共分为了17 ...
- MySQL性能调优与架构设计-架构篇
架构篇(1) 读书笔记 1.Scale(扩展):从数据库来看,就是让数据库能够提供更强的服务能力 ScaleOut: 是通过增加处理节点的方式来提高整体处理能力 ScaleUp: 是通过增加当前处理节 ...
- (转)Android项目重构之路:实现篇
前两篇文章Android项目重构之路:架构篇和Android项目重构之路:界面篇已经讲了我的项目开始搭建时的架构设计和界面设计,这篇就讲讲具体怎么实现的,以实现最小化可用产品(MVP)的目标,用最简单 ...
- (转)Android项目重构之路:界面篇
在前一篇文章<Android项目重构之路:架构篇>中已经简单说明了项目的架构,将项目分为了四个层级:模型层.接口层.核心层.界面层.其中,最上层的界面,是变化最频繁的一个层面,也是最复杂最 ...
- WEB架构师成长之路-架构师都要懂哪些知识 转
Web架构师究竟都要学些什么?具备哪些能力呢?先网上查查架构师的大概的定义,参见架构师修炼之道这篇文章,写的还不错,再查查公司招聘Web架构师的要求. 总结起来大概有下面几点技能要求: 一. 架构师有 ...
- 高性能高并发服务器架构设计探究——以flamigo服务器代码为例
这篇文章我们将介绍服务器的开发,并从多个方面探究如何开发一款高性能高并发的服务器程序. 所谓高性能就是服务器能流畅地处理各个客户端的连接并尽量低延迟地应答客户端的请求:所谓高并发,指的是服务器可以同时 ...
- .NET Core资料精选:架构篇
.NET 6.0 马上就要发布,高性能云原生开发框架.希望有更多的小伙伴加入大.NET阵营.这是本系列的第三篇文章:架构篇,喜欢的园友速度学起来啊. 本系列文章,主要分享一些.NET Core比较优秀 ...
- 基于.NET MVC的高性能IOC插件化架构
基于.NET MVC的高性能IOC插件化架构 最近闲下来,整理了下最近写的代码,先写写架构,后面再分享几个我自己写的插件 最近经过反复对比,IOC框架选择了Autofac,原因很简单,性能出众,这篇博 ...
- Java工程师修炼之路(校招总结)
Java工程师修炼之路(校招总结) 前言 在下本是跨专业渣考研的985渣硕一枚,经历研究生两年的学习积累,有幸于2019秋季招聘中拿到几个公司的研发岗offer,包括百度,阿里,腾讯,今日头条,网易, ...
随机推荐
- APICloud 可视化编程 - 拖拉拽实现专业级源码
低代码开发平台是无需编码 (0 代码或⽆代码) 或通过少量代码就可以快速生成应用程序的开发平台.它的强⼤之处在于,允许终端⽤户使⽤易于理解的可视化⼯具开发自己的应用程序,而不是传统的编写代码⽅式.当遇 ...
- 第四十九篇:webpack的基本使用(三) --安装和配置html-webpack-plugin插件
好家伙, 1.html-webpack-plugin的作用 讲一下为什么需要这个插件 存在问题:在点开locahost:8080之后出现的是项目的根目录,而不是网页 这时候需要再点开scr文件夹才能看 ...
- 超详细 VS Code 配置C/C++教程
写在前面 如果您使用的电脑内存 \(\leq 4 \texttt{GB}\),建议您使用Dev-C++,否则会到时内存占用爆满,体验感不佳. 网上的很多教程都不够详细,这里我把每一步.每一个操作都详细 ...
- KingbaseES 如何开启并进入数据库
关键字: KingbaseES.sys_ctl.ksql 一.数据库启动前环境检测 1.1 查看kingbase用户环境变量配置 图1-1 查看.bashrc环境变量配置 1.2 应用环境变量 [ki ...
- Linux_ps总结
ps命令用于监测进程的工作情况.进程是一直处于动态变化中,而ps命令所显示的进程工作状态时瞬间的 使用方式: ps [options] 常用参数 -A 显示所有进程 -a 显示现行终端机下的所有进程, ...
- ES6之前,JS的继承
继承的概念 谈到继承,就不得不谈到类和对象的概念. 类是抽象的,它是拥有共同的属性和行为的抽象实体. 对象是具体的,它除了拥有类共同的属性和行为之外,可能还会有一些独特的属性和行为. 打个比方: 人类 ...
- SQL语句中过滤条件放在on和where子句中的区别和联系
摘要: 介绍在多表关联SQL语句中,过滤条件放在on和where子句中的区别--inner join中没区别,外连接就不一样. 综述 蚂蚁金服的一道SQL面试题如下:SQL语句中,过滤条件放在on ...
- dotnet7 aot编译实战
0 起因 这段日子看到dotnet7-rc1发布,我对NativeAot功能比较感兴趣,如果aot成功,这意味了我们的dotnet程序在防破解的上直接指数级提高.我随手使用asp.netcore-7. ...
- centos7.2 安装MongoDB
1.配置阿里云yum仓库 #vim /etc/yum.repos.d/mongodb-org-4.0.repo [mngodb-org] name=MongoDB Repository baseurl ...
- 文心ERNIE-ViLG,你的免费插图画师
你是否想拥有一个专属画师,免费为你的优美文字插上几幅优美的插图?如今依然实现 最近AI作画确实很火,在DALL-E和Imagen崭露头角之后,ERNIE-ViLG.Stable-Diffusion(S ...