Kafka之工作流程分析
Kafka之工作流程分析
kafka核心组成
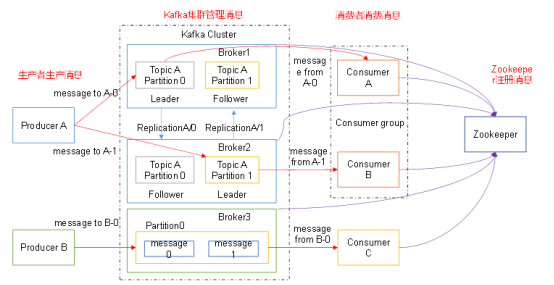
一、Kafka生产过程分析
1.1 写入方式
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
1.2 分区(Partition)
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
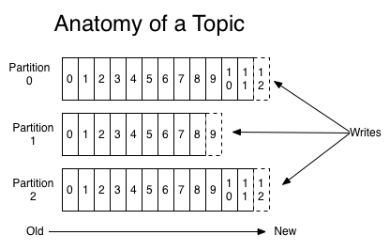
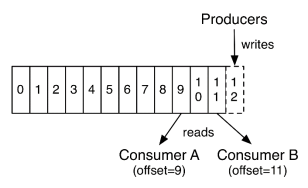
我们可以看到,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
(1)分区的原因
1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
2)可以提高并发,因为可以以Partition为单位读写了。
(2)分区的原则
1)指定了patition,则直接使用;
2)未指定patition但指定key,通过对key的value进行hash出一个patition;
3)patition和key都未指定,使用轮询选出一个patition。
DefaultPartitioner类
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
1.3 副本(Replication)
同一个partition可能会有多个replication(对应 server.properties 配置中的 default.replication.factor=N)。没有replication的情况下,一旦broker 宕机,其上所有 patition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
1.4 写入流程
producer写入消息流程如下:
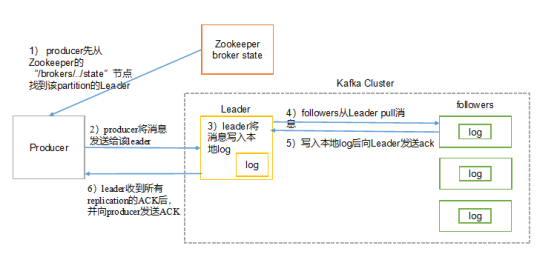
1、Broker:安装Kafka服务的那台集群就是一个broker(broker的id要全局唯一)
2、Producer:消息的生产者,负责将数据写入到broker中(push)
3、Consumer:消息的消费者,负责从kafka中读取数据(pull),老版本的消费者需要依赖zk,新版本的不需要
4、Topic:主题,相当于是数据的一个分类,不同topic存放不同的数据
5、replication:副本,数据保存多少份(保证数据不丢)
6、partition:分区,是一个物理分区,一个分区就是一个文件,一个topic可以有一到多个分区,每一个分区都有自己的副本。
7、Consumer Group:消费者组,一个topic可以有多个消费者同时消费,多个消费者如果在一个消费者组中,那么他们不能重复消费数据
二、Broker 保存消息
2.1 存储方式
物理上把topic分成一个或多个patition(对应server.properties 中的num.partitions=3配置),每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件),如下:
[hadoop1 logs]$ ll
drwxrwxr-x. 2 hadoop hadoop 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 hadoop hadoop 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 hadoop hadoop 4096 8月 6 14:37 first-2
[hadoop1 logs]$ cd first-0
[hadoop1 first-0]$ ll
-rw-rw-r--. 1 hadoop hadoop 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 hadoop hadoop 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 hadoop hadoop 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 hadoop hadoop 8 8月 6 14:37 leader-epoch-checkpoint
2.2 存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1)基于时间:log.retention.hours=168
2)基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
2.3 Zookeeper存储结构
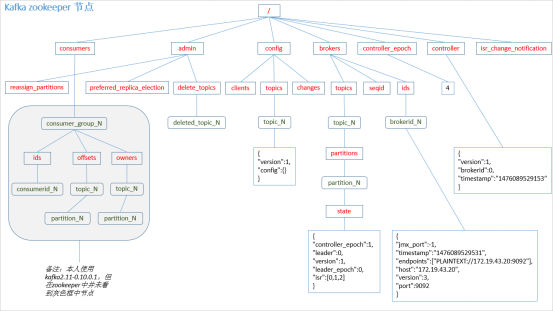
注意:producer不在zk中注册,消费者在zk中注册。
三、Kafka消费过程分析
kafka提供了两套consumer API:高级Consumer API和低级Consumer API。
3.1 高级API
1)高级API优点
高级API 写起来简单
不需要自行去管理offset,系统通过zookeeper自行管理。
不需要管理分区,副本等情况,系统自动管理。
消费者断线会自动根据上一次记录在zookeeper中的offset去接着获取数据(默认设置1分钟更新一下zookeeper中存的offset)
可以使用group来区分对同一个topic 的不同程序访问分离开来(不同的group记录不同的offset,这样不同程序读取同一个topic才不会因为offset互相影响)
2)高级API缺点
不能自行控制offset(对于某些特殊需求来说)
不能细化控制如分区、副本、zk等
3.2 低级API
1)低级 API 优点
能够让开发者自己控制offset,想从哪里读取就从哪里读取。
自行控制连接分区,对分区自定义进行负载均衡
对zookeeper的依赖性降低(如:offset不一定非要靠zk存储,自行存储offset即可,比如存在文件或者内存中)
2)低级API缺点
太过复杂,需要自行控制offset,连接哪个分区,找到分区leader 等。
3.3 消费者组
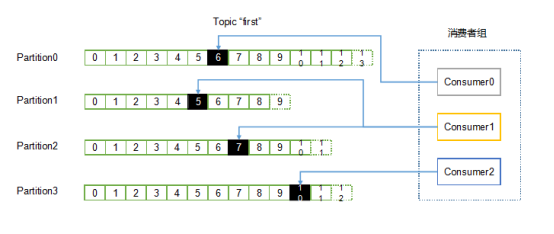
消费者是以consumer group消费者组的方式工作,由一个或者多个消费者组成一个组,共同消费一个topic。每个分区在同一时间只能由group中的一个消费者读取,但是多个group可以同时消费这个partition。在图中,有一个由三个消费者组成的group,有一个消费者读取主题中的两个分区,另外两个分别读取一个分区。某个消费者读取某个分区,也可以叫做某个消费者是某个分区的拥有者。
在这种情况下,消费者可以通过水平扩展的方式同时读取大量的消息。另外,如果一个消费者失败了,那么其他的group成员会自动负载均衡读取之前失败的消费者读取的分区。
3.4 消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适,它可简化broker的设计,consumer可自主控制消费消息的速率,同时consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,我们在我们的拉请求中有参数,允许消费者请求在等待数据到达的“长轮询”中进行阻塞(并且可选地等待到给定的字节数,以确保大的传输大小)。
3.5 消费者组案例
1)需求:测试同一个消费者组中的消费者,同一时刻只能有一个消费者消费。
2)案例实操
(1)在hadoop1、hadoop2上修改/home/bigdata/kafka/config/consumer.properties配置文件中的group.id属性为任意组名。
[hadoop2 config]$ vi consumer.properties
group.id=hadoop1
(2)在hadoop1、hadoop2上分别启动消费者
[hadoop1 kafka]$ bin/kafka-console-consumer.sh \
--zookeeper hadoop1:2181 --topic first --consumer.config config/consumer.properties
[hadoop2 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop1:2181 --topic first --consumer.config config/consumer.properties
(3)在hadoop104上启动生产者
[hadoop1 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop1:9092 --topic first
>hello world
(4)查看hadoop1和hadoop2的接收者
同一时刻只有一个消费者接收到消息。
Kafka之工作流程分析的更多相关文章
- Kafka工作流程分析
Kafka工作流程分析 生产过程分析 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘 ...
- 【转】Hostapd工作流程分析
[转]Hostapd工作流程分析 转自:http://blog.chinaunix.net/uid-30081165-id-5290531.html Hostapd是一个运行在用户态的守护进程,可以通 ...
- 第2章 rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释. 以下是本文的姊妹篇: 1.rsync(一):基本命令和用法 2.rsync(二):ino ...
- [国嵌笔记][030][U-Boot工作流程分析]
uboot工作流程分析 程序入口 1.打开顶层目录的Makefile,找到目标smdk2440_config的命令中的第三项(smdk2440) 2.进入目录board/samsung/smdk244 ...
- rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释.本文不会介绍如何使用rsync命令(见rsync基本用法),而是详细解释它如何实现高效的增 ...
- nodejs的Express框架源码分析、工作流程分析
nodejs的Express框架源码分析.工作流程分析 1.Express的编写流程 2.Express关键api的使用及其作用分析 app.use(middleware); connect pack ...
- Mysql工作流程分析
Mysql工作流程图 工作流程分析 1. 所有的用户连接请求都先发往连接管理器 2. 连接管理器 (1)一直处于侦听状态 (2)用于侦听用户请求 3. 线程管理器 (1)因为每个用户 ...
- u-boot分析(二)----工作流程分析
u-boot分析(二) 由于这两天家里有点事,所以耽误了点时间,没有按时更新,今天我首先要跟大家说说我对于u-boot分析的整体的思路,然后呢我以后的博客会按照这个内容更新,希望大家关注. 言归正传, ...
- Struts2的工作流程分析
Struts2的工作流程分析 Posted on 2011-02-22 09:32 概述 本章讲述Struts2的工作原理. 读者如果曾经学习过Struts1.x或者有过Struts1.x的开发经验, ...
随机推荐
- HTML基础标签学习
HTML基础学习 前言 HTML基础学习会由HTML基础标签学习.HTML表单学习和一张思维导图总结HTML基础三篇文章构成,文章中博主会提取出重点常用的知识和经常出现的bug,提高学习的效率,后续会 ...
- 一寸宕机一寸血,十万容器十万兵|Win10/Mac系统下基于Kubernetes(k8s)搭建Gunicorn+Flask高可用Web集群
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_185 2021年,君不言容器技术则已,欲言容器则必称Docker,毫无疑问,它是当今最流行的容器技术之一,但是当我们面对海量的镜像 ...
- Python 车主之家全系车型(包含历史停售车型)配置参数爬虫
本文仅供学习交流使用,如侵立删!demo下载见文末 车主之家全系车型(包含历史停售车型)配置参数爬虫 先上效果图 环境: win10 ,Contos7.4 python3.9.4 pycharm202 ...
- 业务可视化-让你的流程图"Run"起来(6.定时任务&Spring-Batch的集成)
前言 首先,感谢大家对上一篇文章[业务可视化-让你的流程图"Run"起来(5.SpringBoot集成&微服务编排)]的支持. 分享一下近期我对这个项目的一些改进. 在项目 ...
- React报错之React hook 'useState' cannot be called in a class component
正文从这开始~ 总览 当我们尝试在类组件中使用useState 钩子时,会产生"React hook 'useState' cannot be called in a class compo ...
- {版本发布公告}HMS Core 6.6.0来啦
分析服务 ◆ 留存分析支持¬将流失用户存为受众,开发者通过对流失人群的分层以及多维分析,在制定相关用户召回策略时将更有针对性: ◆ 原"受众分析"更名为"人群洞察&quo ...
- 线性代数 | Jordan 标准型的笔记
内容概述: 把方阵 A 的特征多项式 \(c(λ)=|λE-A|\) 展开成 \(c(λ)=\sum_ia_i\lambda^i\) 的形式,然后使用神乎其技的证明,得到 \(c(A)=O\),特征多 ...
- OpenJ_Bailian - 3424 Candies (差分约束)
题面 During the kindergarten days, flymouse was the monitor of his class. Occasionally the head-teache ...
- C#基础_VS常用快捷键
Shift+End,Shift+Home,跳转到当前代码的行尾和行首. 1.窗口快捷键 记忆诀窍: 凡跟窗口挂上钩的快捷键必有一个W(Windows): Ctrl+W,W: 浏览器窗口 (浏览橱窗用 ...
- 【unity游戏入门】2 使用代码编写Hello Unity游戏
作者 罗芭Remoo 2021年9月24日 第一章.许可证的安装 下载好Unity之后,我们还需要一个前置操作才可以进入Unity引擎----许可证. 当然不用担心,Unity是一个开放的引擎,一切以 ...