netty系列之:netty中的frame解码器
简介
netty中的数据是通过ByteBuf来进行传输的,一个ByteBuf中可能包含多个有意义的数据,这些数据可以被称作frame,也就是说一个ByteBuf中可以包含多个Frame。
对于消息的接收方来说,接收到了ByteBuf,还需要从ByteBuf中解析出有用而数据,那就需要将ByteBuf中的frame进行拆分和解析。
一般来说不同的frame之间会有有些特定的分隔符,我们可以通过这些分隔符来区分frame,从而实现对数据的解析。
netty为我们提供了一些合适的frame解码器,通过使用这些frame解码器可以有效的简化我们的工作。下图是netty中常见的几个frame解码器:
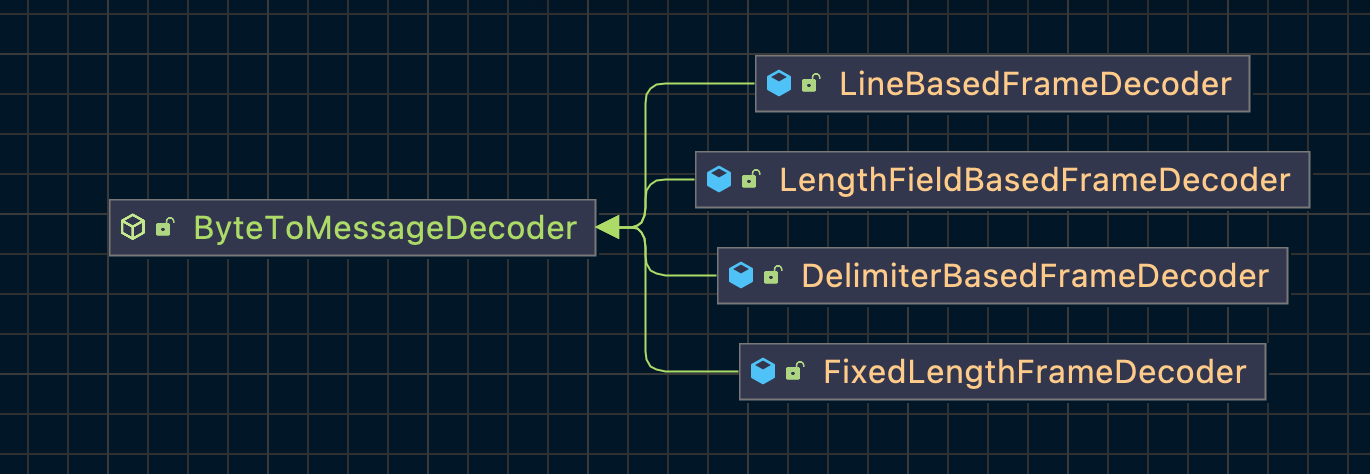
接下来我们来详细介绍一下上面几个frame解码器的使用。
LineBasedFrameDecoder
LineBasedFrameDecoder从名字上看就是按行来进行frame的区分。根据操作系统的不同,换行可以有两种换行符,分别是 "\n" 和 "\r\n" 。
LineBasedFrameDecoder的基本原理就是从ByteBuf中读取对应的字符来和"\n" 跟 "\r\n",可以了可以准确的进行字符的比较,这些frameDecoder对字符的编码也会有一定的要求,一般来说是需要UTF-8编码。因为在这样的编码中,"\n"和"\r"是以一个byte出现的,并且不会用在其他的组合编码中,所以用"\n"和"\r"来进行判断是非常安全的。
LineBasedFrameDecoder中有几个比较重要的属性,一个是maxLength的属性,用来检测接收到的消息长度,如果超出了长度限制,则会抛出TooLongFrameException异常。
还有一个stripDelimiter属性,用来判断是否需要将delimiter过滤掉。
还有一个是failFast,如果该值为true,那么不管frame是否读取完成,只要frame的长度超出了maxFrameLength,就会抛出TooLongFrameException。如果该值为false,那么TooLongFrameException会在整个frame完全读取之后再抛出。
LineBasedFrameDecoder的核心逻辑是先找到行的分隔符的位置,然后根据这个位置读取到对应的frame信息,这里来看一下找到行分隔符的findEndOfLine方法:
private int findEndOfLine(final ByteBuf buffer) {
int totalLength = buffer.readableBytes();
int i = buffer.forEachByte(buffer.readerIndex() + offset, totalLength - offset, ByteProcessor.FIND_LF);
if (i >= 0) {
offset = 0;
if (i > 0 && buffer.getByte(i - 1) == '\r') {
i--;
}
} else {
offset = totalLength;
}
return i;
}
这里使用了一个ByteBuf的forEachByte对ByteBuf进行遍历。我们要找的字符是:ByteProcessor.FIND_LF。
最后LineBasedFrameDecoder解码之后的对象还是一个ByteBuf。
DelimiterBasedFrameDecoder
上面讲的LineBasedFrameDecoder只对行分隔符有效,如果我们的frame是以其他的分隔符来分割的话LineBasedFrameDecoder就用不了了,所以netty提供了一个更加通用的DelimiterBasedFrameDecoder,这个frameDecoder可以自定义delimiter:
public class DelimiterBasedFrameDecoder extends ByteToMessageDecoder {
public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf delimiter) {
this(maxFrameLength, true, delimiter);
}
传入的delimiter是一个ByteBuf,所以delimiter可能不止一个字符。
为了解决这个问题在DelimiterBasedFrameDecoder中定义了一个ByteBuf的数组:
private final ByteBuf[] delimiters;
delimiters= delimiter.readableBytes();
这个delimiters是通过调用delimiter的readableBytes得到的。
DelimiterBasedFrameDecoder的逻辑和LineBasedFrameDecoder差不多,都是通过对比bufer中的字符来对bufer中的数据进行截取,但是DelimiterBasedFrameDecoder可以接受多个delimiters,所以它的用处会根据广泛。
FixedLengthFrameDecoder
除了进行ByteBuf中字符比较来进行frame拆分之外,还有一些其他常见的frame拆分的方法,比如根据特定的长度来区分,netty提供了一种这样的decoder叫做FixedLengthFrameDecoder。
public class FixedLengthFrameDecoder extends ByteToMessageDecoder
FixedLengthFrameDecoder也是继承自ByteToMessageDecoder,它的定义很简单,可以传入一个frame的长度:
public FixedLengthFrameDecoder(int frameLength) {
checkPositive(frameLength, "frameLength");
this.frameLength = frameLength;
}
然后调用ByteBuf的readRetainedSlice方法来读取固定长度的数据:
in.readRetainedSlice(frameLength)
最后将读取到的数据返回。
LengthFieldBasedFrameDecoder
还有一些frame中包含了特定的长度字段,这个长度字段表示ByteBuf中有多少可读的数据,这样的frame叫做LengthFieldBasedFrame。
netty中也提供了一个对应的处理decoder:
public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder
读取的逻辑很简单,首先读取长度,然后再根据长度再读取数据。为了实现这个逻辑,LengthFieldBasedFrameDecoder提供了4个字段,分别是 lengthFieldOffset,lengthFieldLength,lengthAdjustment和initialBytesToStrip。
lengthFieldOffset指定了长度字段的开始位置,lengthFieldLength定义的是长度字段的长度,lengthAdjustment是对lengthFieldLength进行调整,initialBytesToStrip表示是否需要去掉长度字段。
听起来好像不太好理解,我们举几个例子,首先是最简单的:
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
要编码的消息有个长度字段,长度字段后面就是真实的数据,0x000C是一个十六进制,表示的数据是12,也就是"HELLO, WORLD" 中字符串的长度。
这里4个属性的值是:
lengthFieldOffset = 0
lengthFieldLength = 2
lengthAdjustment = 0
initialBytesToStrip = 0
表示的是长度字段从0开始,并且长度字段占有两个字节,长度不需要调整,也不需要对字段进行调整。
再来看一个比较复杂的例子,在这个例子中4个属性值如下:
lengthFieldOffset = 1
lengthFieldLength = 2
lengthAdjustment = 1
initialBytesToStrip = 3
对应的编码数据如下所示:
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
上面的例子中长度字段是从第1个字节开始的(第0个字节是HDR1),长度字段占有2个字节,长度再调整一个字节,最终数据的开始位置就是1+2+1=4,然后再截取前3个字节的数据,得到了最后的结果。
总结
netty提供的这几个基于字符集的frame decoder基本上能够满足我们日常的工作需求了。当然,如果你传输的是一些更加复杂的对象,那么可以考虑自定义编码和解码器。自定义的逻辑步骤和上面我们讲解的保持一致就行了。
本文已收录于 http://www.flydean.com/14-5-netty-frame-decoder/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
netty系列之:netty中的frame解码器的更多相关文章
- 【读后感】Netty 系列之 Netty 高性能之道 - 相比 Mina 怎样 ?
[读后感]Netty 系列之 Netty 高性能之道 - 相比 Mina 怎样 ? 太阳火神的漂亮人生 (http://blog.csdn.net/opengl_es) 本文遵循"署名-非商 ...
- Netty 系列之 Netty 高性能之道 高性能的三个主题 Netty使得开发者能够轻松地接受大量打开的套接字 Java 序列化
Netty系列之Netty高性能之道 https://www.infoq.cn/article/netty-high-performance 李林锋 2014 年 5 月 29 日 话题:性能调优语言 ...
- netty系列之:netty中的核心解码器json
目录 简介 java中对json的支持 netty对json的解码 总结 简介 程序和程序之间的数据传输方式有很多,可以通过二进制协议来传输,比较流行的像是thrift协议或者google的proto ...
- netty系列之:netty实现http2中的流控制
目录 简介 http2中的流控制 netty对http2流控制的封装 Http2FlowController Http2LocalFlowController Http2RemoteFlowContr ...
- netty系列之:netty中各不同种类的channel详解
目录 简介 ServerChannel和它的类型 Epoll和Kqueue AbstractServerChannel ServerSocketChannel ServerDomainSocketCh ...
- 【转】Netty系列之Netty编解码框架分析
http://www.infoq.com/cn/articles/netty-codec-framework-analyse/ 1. 背景 1.1. 编解码技术 通常我们也习惯将编码(Encode)称 ...
- Netty系列之Netty编解码框架分析
1. 背景 1.1. 编解码技术 通常我们也习惯将编码(Encode)称为序列化(serialization),它将对象序列化为字节数组,用于网络传输.数据持久化或者其它用途. 反之,解码(Decod ...
- netty系列之:netty架构概述
目录 简介 netty架构图 丰富的Buffer数据机构 零拷贝 统一的API 事件驱动 其他优秀的特性 总结 简介 Netty为什么这么优秀,它在JDK本身的NIO基础上又做了什么改进呢?它的架构和 ...
- Netty 系列之 Netty 高性能之道
1. 背景 1.1. 惊人的性能数据 最近一个圈内朋友通过私信告诉我,通过使用 Netty4 + Thrift 压缩二进制编解码技术,他们实现了 10 W TPS(1 K 的复杂 POJO 对象)的跨 ...
随机推荐
- Spring Boot 多模块项目创建与配置 (转)
转载:https://www.cnblogs.com/MaxElephant/p/8205234.html 最近在负责的是一个比较复杂项目,模块很多,代码中的二级模块就有9个,部分二级模块下面还分了多 ...
- char型变量中能不能存储一个中文字符?为什么?
char型变量是用来存储Unicode编码的字符的,Unicode编码字符集中包含了汉字,因此char型变量中可以存储汉字.不过,如果某个特殊的汉字没有被包含在Unicode编码字符集中,那么,这个c ...
- SpringBoot bean映射yml中的属性举例
pom:导入配置文件处理器,配置文件进行绑定就会有提示 <dependency> <groupId>org.springframework.boot</groupId&g ...
- django CBV 及其装饰器
#urls.py from django.contrib import admin from django.urls import path, re_path from app01 import vi ...
- 学习docker(三)
一.Docker介绍 1.docker容器 docker是宿主机的一个进程,通过namespace实现了资源隔离,通过cgroup实现了资源限制, 通过写时复制技术(copy-on-write)实现了 ...
- 遇到的错误之“Cannot find module 'XXX’的错误”
一.问题: 在进行webpack打包的时候,会出现Cannot find module 'XXX'的错误,找不到某个模块的错误 二.解决方法: (1)方法1: 直接进行npm install重新打包: ...
- 【HTML5版】导出Table数据并保存为Excel
首发我的博客 http://blog.meathill.com/tech/js/export-table-data-into-a-excel-file.html 最近接到这么个需求,要把<tab ...
- webSocket原理探索
本文概述 Web Sockets的目标是在一个单独的持久连接上提供全双工.双向通信.在Javascript创建了Web Socket之后,会有一个HTTP请求发送到浏览器以发起连接.在取得服务器响应后 ...
- 富文本编辑器CKeditor的配置和图片上传,看完不后悔
CKeditor是一款富文本编辑器,本文将用极为简单的方式介绍一下它的使用和困扰大家很久的图片上传问题,要有耐心. 第一步:如何使用 1.官网下载https://ckeditor.com/ckedit ...
- oracle数据库存储过程中的select语句的位置
导读:在oracle数据库存储过程中如果用了select语句,要么使用"select into 变量"语句要么使用游标,oracle不支持单独的select语句. 先看下这个存储过 ...