【Java】【数据库】索引为何使查询变得更快?--B+树
排序数据的二分查找
二分查找的时间复杂度是\(O(log_2n)\),明显快于暴力搜索。
索引
建立索引的数据,就是通过事先排好顺序,在查找时可以应用二分查找来提高查询效率。
所以索引应该尽可能建立在主键这样的字段上,因为主键必须唯一,所以这样生成的二叉查找树的效率是最高的。
数据库索引的原理-- B+ 树
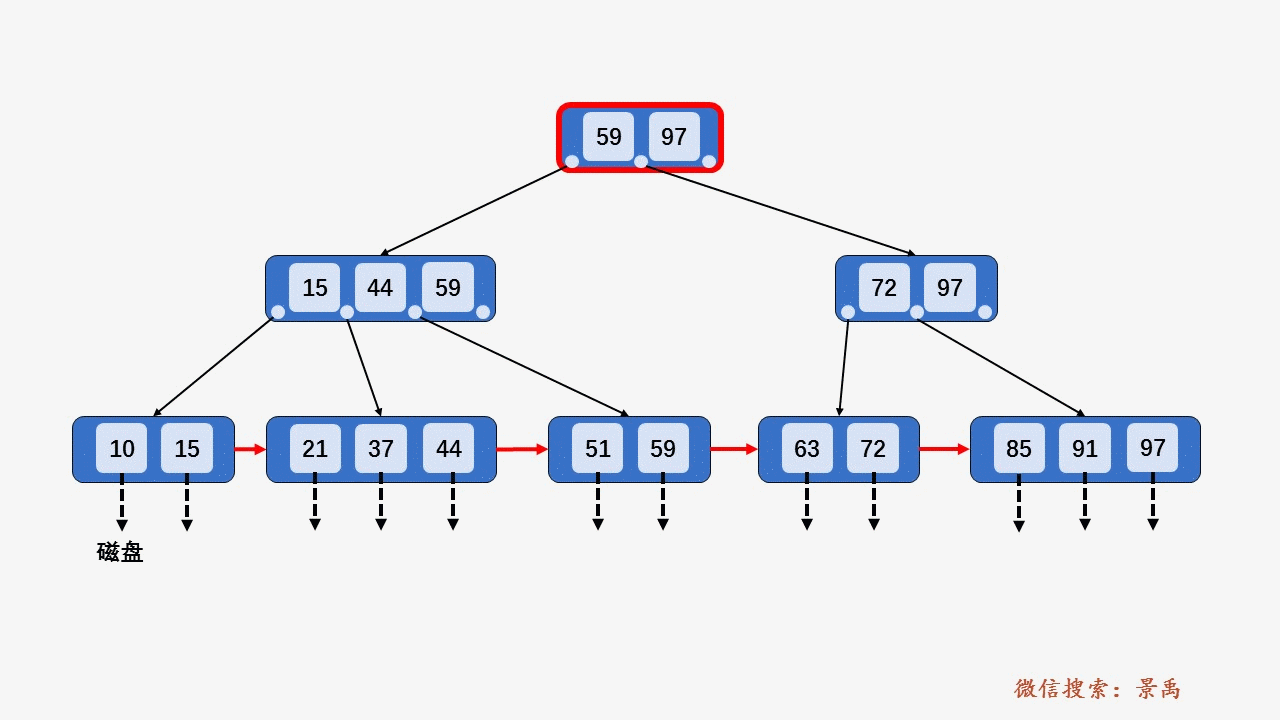
数据库用 B+ 树来实现索引
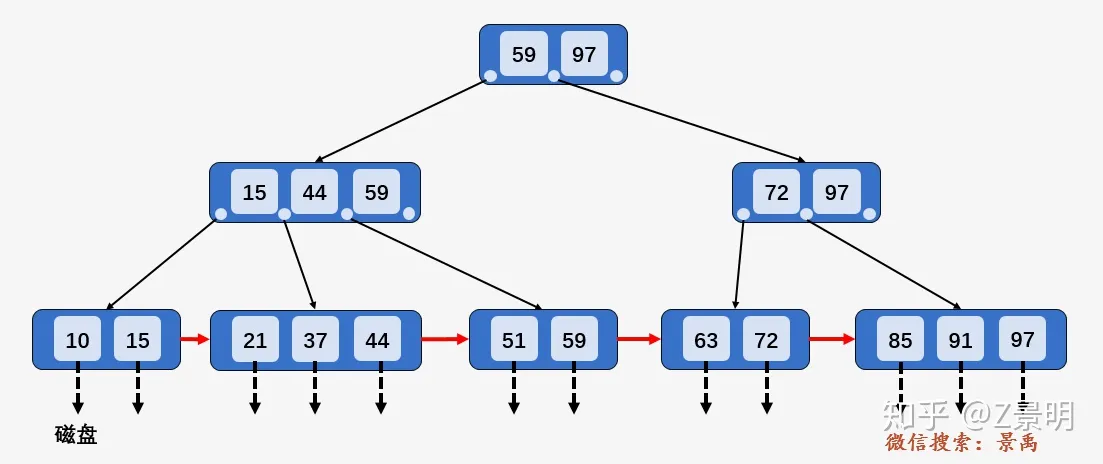
其中, 非叶子节点形如
\(<P_1,K_1,P_2,K_2,...,P_{c-1},K_{c-1},P_c>\)
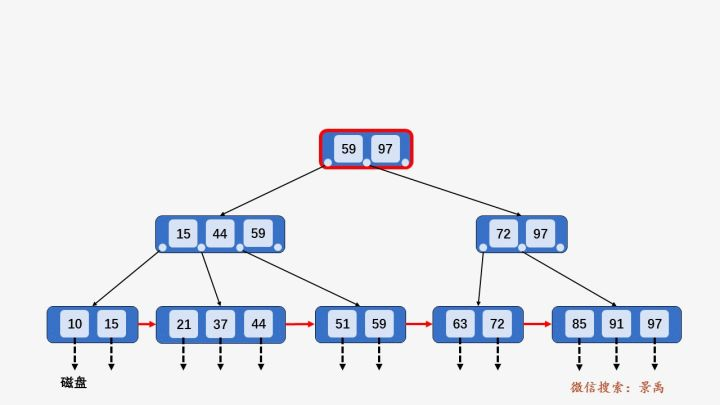
以第一层为例,\(<P_1,59,P_2,97,P_3>\).满足数据部分(\(K_i\))从小到大有序排列,且指针\(P_i\)指向的下一个节点\(X\)满足\(K_{i-1}<X<=K_i\) , 例如图中的树,59在它左边节点指向的树里,44在它左边结点指向的树里,15在它左边结点指向的树里,且都是在最右边的位置。
B+树延伸
查找操作
以上图查找\(key=59\)为例,
先访问根节点\([59,97]\), 发现\(key\)小于等于根节点中的第一个数\(59\), 于是继续访问\(59\)左边的指针指向的节点\([15,44,59]\), 发现\(key\)小于等于第三个树\(59\), 于是访问\(59\)左边的指针指向的叶子节点\([51,59]\), 遍历找到要查找的元素\(59\).
叶子节点的详细结构如下图
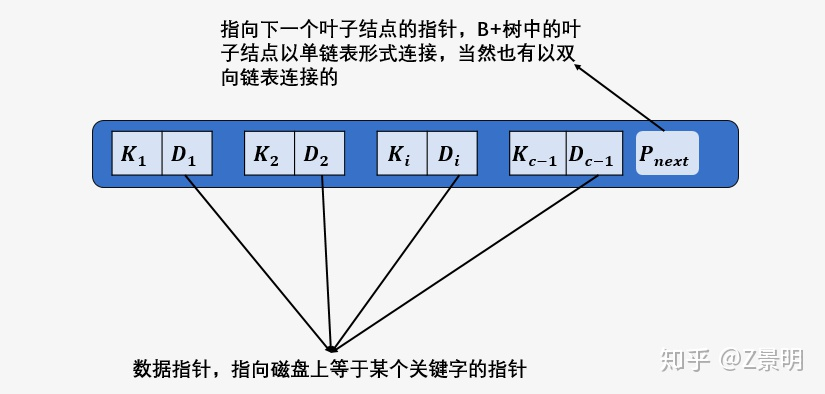
由于数据指针只在叶子节点上,所以 B+ 树所有查询所有关键字的磁盘 \(I/O\) 的次数都是树的高度。
区间查找
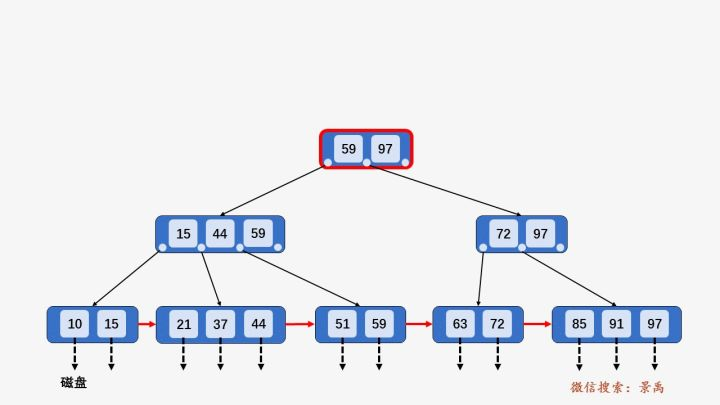
在上面的叶子节点图中,我们可以看到每个叶子节点有一个指针\(P_{next}\), 它的作用体现在区间查找的时候。
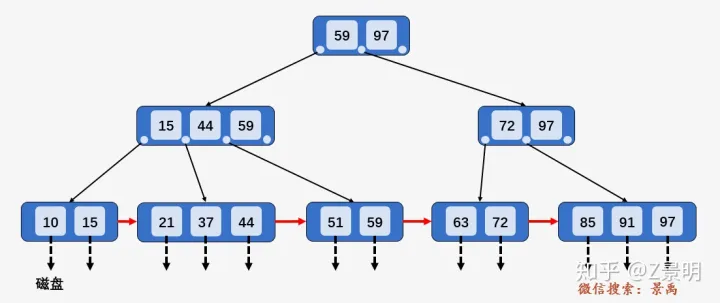
例如,需要查询\([21,63]\)之间的关键字。
- \(21<59\),访问\(59\)左边指针指向的节点\([15,44,59]\).
- \(15<21<44\), 访问\(44\)左边指针指向的叶子节点\([21,37,44]\).
- 遍历这个叶子节点找到\(21\),下面的操作就如同单链表的遍历,一直遍历到\(63\)即可.
插入操作
不细说了,这篇文章的动图能说明一切知乎文章
只把动图贴到这里
没有超出叶子结点的最大容量m
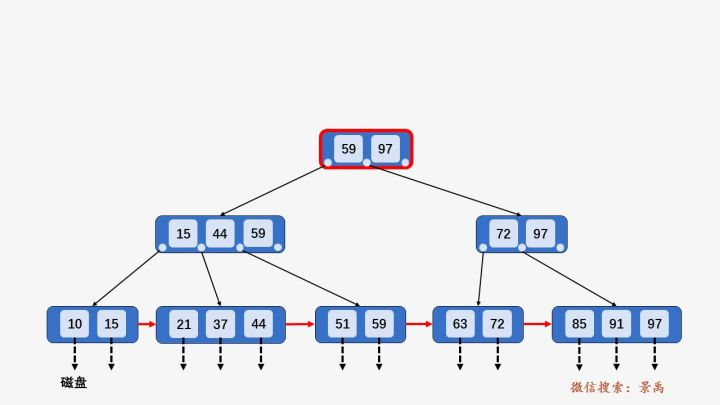
超出m,要分裂叶子节点
分裂叶子节点导致上层的节点也超出m,要分裂上层的节点
插入数值比当前最大值还大,要保证新的最大值在根节点中,需要重新调整 B+ 树
B+ 树的复杂度
查找、插入和删除等操作的时间复杂度都是\(O(logn)\)
至于这个结论怎么得出的,还是看那篇知乎文章吧,写得太好了。
【Java】【数据库】索引为何使查询变得更快?--B+树的更多相关文章
- Java数据库学习之模糊查询(like )
Java数据库学习之模糊查询(like ): 第一种方式:直接在SQL语句中进行拼接,此时需要注意的是parm在SQL语句中需要用单引号拼接起来,注意前后单引号之间不能空格 String sql = ...
- LSM树——LSM 将B+树等结构昂贵的随机IO变的更快,而代价就是读操作要处理大量的索引文件(sstable)而不是一个,另外还是一些IO被合并操作消耗。
Basic Compaction 为了保持LSM的读操作相对较快,维护并减少sstable文件的个数是很重要的,所以让我们更深入的看一下合并操作.这个过程有一点儿像一般垃圾回收算法. 当一定数量的ss ...
- 对于Java中的Loop或For-each,哪个更快
Which is Faster For Loop or For-each in Java 对于Java中的Loop或Foreach,哪个更快 通过本文,您可以了解一些集合遍历技巧. Java遍历集合有 ...
- java 数据库索引的注意事项
索引缺点 1.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行insert.update和delete.因为更新表时,不仅要保存数据,还要保存一下索引文件.2.建立索引会占用磁盘空间的 ...
- java+数据库+D3.js 实时查询人物关系图
先看下 效果 某个用户,邀请了自己的朋友 ,自己的朋友邀请了其他朋友,1 展示邀请关系,2 点击头像显示邀请人和被邀请人的关系.(网上这种资料很少, 另外很多都是从JSON文件取 数据, 这里是从数据 ...
- java数据库编程之高级查询
第三章:高级查询(-) 3.1:修改表 3.1.1:修改表 语法: Alter table <旧表名> rename [ TO] <新表名>; 例子:Alter table ` ...
- JAVA数据库处理(连接,数据查询,结果集返回)
package john import java.io.IOException; import java.util.*; public class QueryDataRow { public Hash ...
- Java数据库学习之分页查询
分页查询 limit [start],[rows] 思路: pram start 从哪一行开始 关键是从哪一行开始,需要根据查询的页数来进行换算出查询具体页数是从哪一行开始 start = (pag ...
- Python窗口学习之使窗口变得更高清
初学tkinter发现窗口并不像成熟软件那么清楚 在实例化window后加这一行代码 #使窗口更加高清 # 告诉操作系统使用程序自身的dpi适配 ctypes.windll.shcore.SetPro ...
- MongoDB 索引 explain 分析查询速度
一.索引基础索引是对数据库表中一列或多列的值进行排序的一种结构,可以让我们查询数据库变得更快.MongoDB 的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的查询优化技巧.下面是创建索引 ...
随机推荐
- Petrozavodsk Winter Training Camp 2016: Moscow SU Trinity Contest
题目列表 A.ABBA E.Elvis Presley G. Biological Software Utilities J. Burnished Security Updates A.ABBA 题意 ...
- R及R Studio下载安装教程(超详细)
R 语言是为数学研究工作者设计的一种数学编程语言,主要用于统计分析.绘图.数据挖掘. 如果你是一个计算机程序的初学者并且急切地想了解计算机的通用编程,R 语言不是一个很理想的选择,可以选择 Pytho ...
- logback.xml详解
介绍 之前博文有专门介绍过基于Log4j Appender 实现大数据平台组件日志的采集, 本篇主要对java项目中经常会接触到的logback.xml文件的配置做一个介绍和总结. logback.x ...
- Codeforces Round #804 (Div. 2) C(组合 + mex)
Codeforces Round #804 (Div. 2) C(组合 + mex) 本萌新的第一篇题解qwq 题目链接: 传送门QAQ 题意: 给定一个\(\left [0,n-1 \right ] ...
- Linux基础_4_文件夹管理
文件路径 . #表示当前目录,同./ .. #表示上级目录,同../ ../../ #表示上上级目录 / #表示根目录 注:文件名长度不超过255个字符 注:.开头为隐藏文件 切换目录 cd #默认切 ...
- 中国制霸生成器「GitHub 热点速览 v.22.42」
火遍推特的中国制霸生成器本周一开源就占据了两天的 GitHub Trending 榜,不知道你的足迹遍布了多少个省份呢?同样记录痕迹的 kanal 用了内存读写方式解决了 Rust 的消息处理问题,P ...
- 知识图谱顶会论文(ACL-2022) PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法
PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法 论文地址:Do Pre-trained Models Benefit Knowledge Graph Completion? A Reli ...
- Tesla-E380,4K eDP一键点屏神器问世
eDP屏快速点亮,EDID回读, eDP屏调试 是否为点屏的准备工作感到烦躁: 1)查找LCD模组的数据手册(常常还未必能找着) 2)在上位机软件或者单片机程序里设置一大堆的LCD屏参,这个频率,那个 ...
- 29.渲染器Renderer
什么是渲染器 渲染器就是将服务器生成的数据格式转为http请求的格式 渲染器触发及参数配置 在DRF配置参数中,可用的渲染器作为一个类的列表进行定义 但与解析器不同的是,渲染器的列表是有顺 ...
- 大文件分片上传,后端拼接保存(前端:antd;后端:.Net 5 WebAPI)
前言 对于普通业务场景而言,直接用 FormData() 将文件以入参的一个参数传给后端即可,但此方法有一个弊端就是,有个 30M 的上限. 对于动辄几百 M.几个 G 的文件上传需求,FormDat ...