使用Puppeteer进行数据抓取(三)——简单的示例
本文以一个示例简单的介绍一下puppeteer的用法,我们的目的是:获取我博客上的文章的前十页的所有随笔的标题和链接。由于puppeteer本身是自动化chorme,因此这里我们的步骤和手动操作浏览器差不多:
- 打开chrome,跳转到博客首页
- 获取所有博客标题信息
- 点击下一页按钮,跳转到下一页
- 重复2、3两步,直到所有信息采集完毕
获取信息
采集过程中比较麻烦的一步就是信息的采集,和传统采集html后解析的方式不同的时,由于chrome本身有完整的js引擎,因此我们采用注入一段js,利用该js采集到我们的信息,并通过puppeteer返回给应用程序的方式。由于puppete本身是采用的chrome,因此编写采集信息函数这一过程完全可以在chrome上进行。
首先用chrome打开我的博客的首页http://www.cnblogs.com/TianFang/,打开chrome devtool,获取标题的css path。然后我们可以利用chrome的snippets简单的写一个获取所有标题信息的函数:
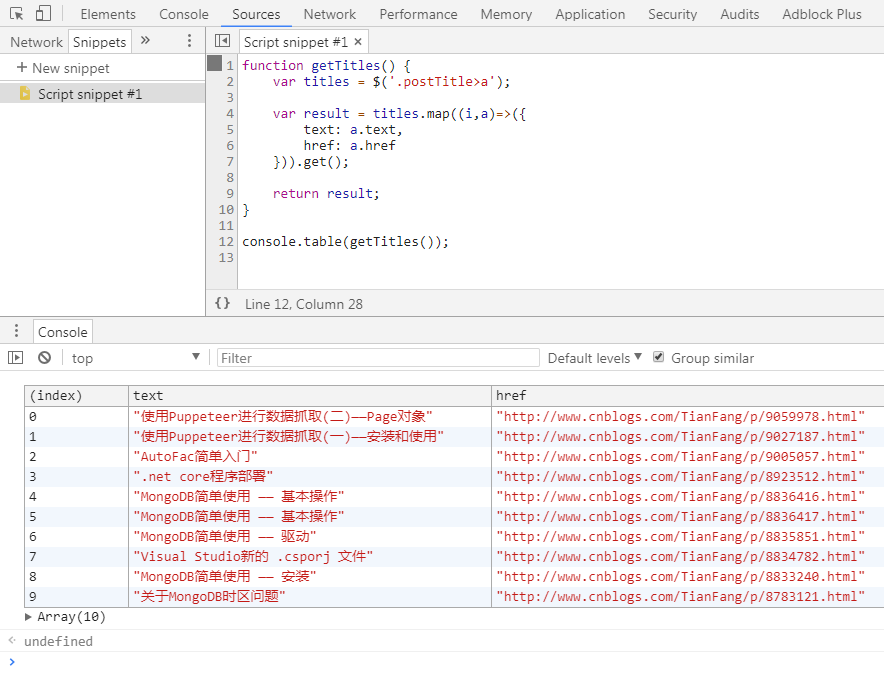
本身就蜘蛛程序而言,编写获取脚本内容的这个部分是比较繁琐的,需要不断的反复调试。但使用snippets直接编写函数大大简化了这一过程,它的主要好处有:
- 可以直接使用各种js函数,可以直接操作各种dom对象
- 利用snippets编写可以在chrome中实时调试,
- 可以实时查看生成结果
然后我们只需要将这个函数放到node中,利用puppeteer跳转到相应的页面,使用page.evaluate函数执行这个函数即可。
async function getTitles() {
var titles = $('.postTitle>a');
var result = titles.map((i, a) => ({
text: a.text,
href: a.href
})).get();
console.table(result);
return result;
}
var titles = await page.evaluate(getTitles);
console.log(titles);
一个需要注意的地方是,这个函数实际上是在chrome中执行的,puppeteer要求在chrome中执行的函数必须是异步的,因此需要加上async关键字。
页面跳转
下一步需要解决的问题就是如何跳转到下一页了。方法也比较简单:分析一下页面,找到下一页的连接,执行js模拟点击即可:
page.evaluate(async() => $(`a:contains('下一页')`)[0].click());
完整代码如下:
const puppeteer = require('puppeteer');
const chrome_exe = String.raw`${process.env["ProgramFiles(x86)"]}\Google\Chrome\Application\chrome.exe`;
const user_data_path = String.raw`${process.env.LocalAppData}\Google\Chrome\User Data\Default`;
async function run() {
const browser = await puppeteer.launch({
headless: false,
userDataDir: user_data_path,
executablePath: chrome_exe
});
const page = await browser.newPage();
page.setViewport({ width: 1600, height: 900 });
await page.goto('http://www.cnblogs.com/TianFang');
for (var i = 0; i < 10; i++) {
console.log(i);
console.log(page.url());
var titles = await page.evaluate(getTitles);
console.log(titles);
await page.evaluate(async() => $(`a:contains('下一页')`)[0].click());
await page.waitForNavigation();
await sleep(1000);
}
};
async function getTitles() {
var titles = $('.postTitle>a');
var result = titles.map((i, a) => ({
text: a.text,
href: a.href
})).get();
console.table(result);
return result;
}
async function sleep(timeout) {
return new Promise(resolve => setTimeout(resolve, timeout));
}
run();
整个过程还是非常简单的, 执行结果如下:
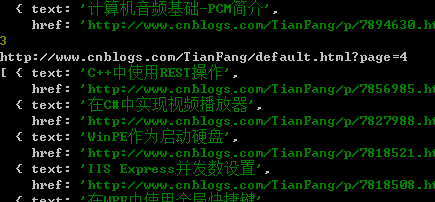
另外值得一提的是,细心的朋友可能注意到这里我们编写一个可以await的sleep函数。
async function sleep(timeout) {
return new Promise(resolve => setTimeout(resolve, timeout));
}
这个函数本身不是必须的,但在编写蜘蛛程序过程中却经常需要等待的,使用await异步等待可以大大提高代码的可读性,由于node本身没有提供可以await的sleep函数。并且这个函数非常实用,这里就自己实现了一个,记录一下,以备以后使用。
使用Puppeteer进行数据抓取(三)——简单的示例的更多相关文章
- 使用Puppeteer进行数据抓取(一)——安装和使用
Puppeteer是 Google Chrome 团队官方的Chrome 自动化工具.它本身是基于Chrome Dev Protocol协议实现的,但它提供了更高层次API封装,使用起来更加方便快捷. ...
- 使用Puppeteer进行数据抓取(二)——Page对象
page对象是puppeteer最常用的对象,它可以认为是chrome的一个tab页,主要的页面操作都是通过它进行的.Google的官方文档详细介绍了page对象的使用,这里我只是简单的小结一下. 客 ...
- 使用Puppeteer进行数据抓取(四)——图片下载
大多数情况下,图片获取并不是很困难的事情,获取图片的url,然后模拟浏览器请求即可.但是,有的时候这种方法往往无法生效,常见的情形有: 动态图片,每次获取都是一个新的,例如图片验证码,重新获取时是一个 ...
- 使用Puppeteer进行数据抓取(四)——快速调试
在我们使用chrome作为爬虫获取网页数据时,往往需如下几步. 打开chrome 导航至目标页面 等待目标页面加载完成 解析目标页面数据 保存目标页面数据 关闭chrome 我们实际的编码往往集中在第 ...
- Twitter数据抓取
说明:这里分三个系列介绍Twitter数据的非API抓取方法.有兴趣的QQ群交流: BitCrawler网络爬虫QQ群 322937592 1.Twitter数据抓取(一) 2.Twitter数据抓取 ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- 【Python入门只需20分钟】从安装到数据抓取、存储原来这么简单
基于大众对Python的大肆吹捧和赞赏,作为一名Java从业人员,我本着批判与好奇的心态买了本python方面的书<毫无障碍学Python>.仅仅看了书前面一小部分的我......决定做一 ...
- 数据抓取的艺术(三):抓取Google数据之心得
本来是想把这部分内容放到前一篇<数据抓取的艺术(二):数据抓取程序优化>之中.但是随着任务的完成,我越来越感觉到其中深深的趣味,现总结如下: (1)时间 时间是一个与抓取规模相形而 ...
- python-requests 简单实现数据抓取
安装包: requests,lxmlrequest包用于进行数据抓取,lxml用来进行数据解析对于对网页内容的处理,由于html本身并非如数据库一样为结构化的查询所见即所得,所以需要对网页的内容进行分 ...
随机推荐
- 第11月第8天 ffmpeg ffplay
static int ffplay_video_thread(void *arg) { FFPlayer *ffp = arg; VideoState *is = ffp->is; AVFram ...
- google浏览器测试时清理缓存、强制不用缓存刷新快捷键(常用、效率)
Ctrl+Shift+Del 清除Google浏览器缓存的快捷键 Ctrl+Shift+R 重新加载当前网页而不使用缓存内容
- Java初转型-SSM配置文件
文章来源:http://www.cnblogs.com/wxisme/p/4924561.html web.xml的配置 ...
- Javascript - Vue - vue对象的生命周期
vue对象的生命周期 从vue的创建到销毁会经过一系列的事件,这是vue对象的生命周期. 创建期间的生命周期函数 <div id="box"> <h3 id ...
- 针对Jigsaw勒索软件的解锁工具
针对Jigsaw勒索软件的解锁工具 据了解, 用户的计算机系统一旦感染了勒索软件Jigsaw,如果用户没有在一个小时之内支付赎金(0.4个比特币,价值约为150美金),那么恶意软件将会把系统中的上千份 ...
- Wireshark按照域名过滤
HTTP协议 http.host == "http://baidu.net" DNS协议 dns.qry.name=="www.baidu.com"
- 管中窥豹:从Page Performance看Nand Flash可靠性【转】
转自:https://blog.csdn.net/renice_ssd/article/details/53332746 如果所有的page performace在每次program时都是基本相同的, ...
- mysql-8.0.11-winx64 免安装版配置方法
mysql-8.0.11-winx64.zip 下载地址:https://dev.mysql.com/downloads/file/?id=476233 mysql-8.0.11-winx64.zi ...
- LeetCode(11):盛最多水的容器
Medium! 题目描述: 给定 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) .画 n 条垂直线,使得垂直线 i 的两个端点分别为 (i, ai) 和 (i, ...
- Codeforces 219C Color Stripe(思维+字符串)
题目链接:http://codeforces.com/problemset/problem/219/C 题目大意: 给出一个字符串,只包含k种字符,问最少修改多少个字符(不增长新的种类)能够得到一个新 ...