ELK日志平台
1、ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kibana三个开源工具组成,不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少。
1)Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等
2)Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。工作方式为C/S架构,Client端安装在需要收集日志的主机上,Server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch服务器。
3) Kibana也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志;
4)FileBeat是一个轻量级日志采集器,Filebeat属于Beats家族的6个成员之一,早期的ELK架构中使用Logstash收集、解析日志并且过滤日志,但是Logstash对CPU、内存、IO等资源消耗比较高,相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
5) Logstash和Elasticsearch是用Java语言编写,而Kibana使用node.js框架,在配置ELK环境要保证系统有JAVA JDK开发库;
2、ELK工作原理
1)客户端安装Logstash日志收集工具,通过logstash收集客户端APP的日志数据,将所有的日志过滤出来,存入Elasticsearch 搜索引擎里,然后通过Kibana GUI在WEB前端展示给用户,用户需要可以进行查看指定的日志内容。同时也可以加入redis通信队列:

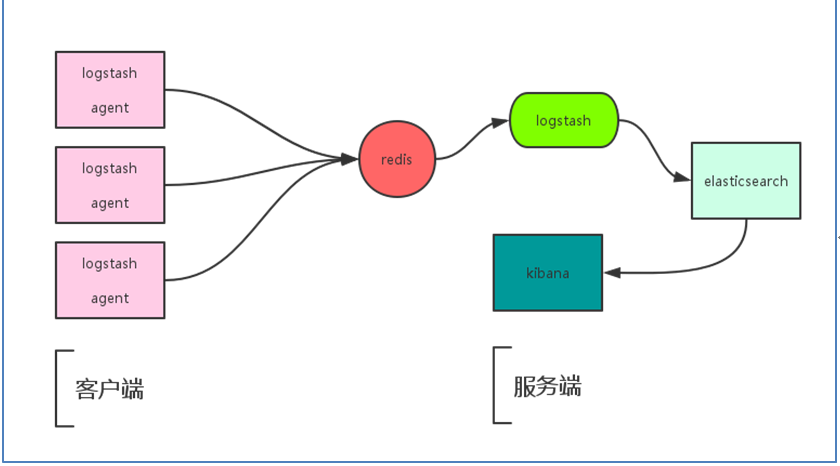
2)加入Redis队列后工作流程;
Logstash包含Index和Agent(shipper) ,Agent负责客户端监控和过滤日志,而Index负责收集日志并将日志交给ElasticSearch,ElasticSearch将日志存储本地,建立索引、提供搜索,kibana可以从ES集群中获取想要的日志信息。
3)ELFK工作流程
使用FileBeat获取Linux服务器上的日志。当启动Filebeat时,它将启动一个或多个Prospectors (检测者),查找服务器上指定的日志文件,作为日志的源头等待输出到Logstash。
Logstash从FileBeat获取日志文件。Filebeat作为Logstash的输入input将获取到的日志进行处理,Logstash将处理好的日志文件输出到Elasticsearch进行处理。
Elasticsearch得到Logstash的数据之后进行相应的搜索存储操作。将写入的数据可以被检索和聚合等以便于搜索操作,最后Kibana通过Elasticsearch提供的API将日志信息可视化的操作
ELK日志平台的更多相关文章
- elk日志平台搭建小记
最近抽出点时间,搭建了新版本的elk日志平台 elastaicsearch 和logstash,kibana和filebeat都是5.6版本的 中间使用redis做缓存,版本为3.2 使用的系统为ce ...
- Springboot项目使用aop切面保存详细日志到ELK日志平台
上一篇讲过了将Springboot项目中logback日志插入到ELK日志平台,它只是个示例.这一篇来看一下实际使用中,我们应该怎样通过aop切面,拦截所有请求日志插入到ELK日志系统.同时,由于往往 ...
- Springboot项目搭配ELK日志平台
上一篇讲过了elasticsearch和kibana的可视化组合查询,这一篇就来看看大名鼎鼎的ELK日志平台是如何搞定的. elasticsearch负责数据的存储和检索,kibana提供图形界面便于 ...
- ELK 日志平台构建
elastic中文社区 https://elasticsearch.cn/ 完整参考 ELK实时日志分析平台环境部署--完整记录 https://www.cnblogs.com/kevingrace/ ...
- 亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统.日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」 废话不多说,老司机们座好了, ...
- 学习ELK日志平台(四)
一:需求及基础: 场景: 1.开发人员不能登录线上服务器查看详细日志 2.各个系统都有日志,日志数据分散难以查找 3.日志数据量大,查询速度慢,或者数据不够实时 4.一个调用会涉及到多个系统,难以在这 ...
- 学习ELK日志平台(二)
一.ELK介绍 1.1 elasticsearch 1.1.1 elasticsearch介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索 ...
- 基于Docker的ELK日志平台搭建
1.安装Docker Docker可简单理解为一个轻量级的虚拟机.Docker对进程进行封装隔离,隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器.Docker和传统虚拟化方式的不同.传统虚拟 ...
- ELK日志平台搭建
功能: 1. 查看当天的服务器日志信息(要求:在出现警告甚至警告级别以上的都要查询)2. 能够查看服务器的所有用户的操作日志3. 能够查询nginx服务器采集的日志(kibana作图)4. 查看tom ...
随机推荐
- WPF 操作XML 读写
来自:http://blog.sina.com.cn/s/blog_633d0e170100xyc6.html XML(可扩展标记语言) 定义:用于标记电子文件使其具有结构性的标记语言,可以用来标记数 ...
- js 截取指定字符长度 为数组
str要截取的字符 n截取个数 function jiequ(str,n) { var strArr = []; for (var i = 0, l = s ...
- Oracle 更改字符集 更改后之前的中文全成乱码了
安装时采用什么字符集主要看你的需求,一般测试用的话,就用UTF8.后面可以修改, 10g:UTF8 到ZHS16GBK SHUTDOWN IMMEDIATE; STARTUP MOUNT ; ALTE ...
- 8.代理ip使用
我日常常用的两个代理: 一.风讯代理 http://www.gzkangyun.com/ 操作界面: 二.智连代理 综合感觉吧,还是智连好用一点,ip质量相对好一点,价格也便宜,不过一个ip基本上的存 ...
- Mybatis十( mybatis其他使用)
1.批量执行 public void addUser(User user); <insert id="addUser" parameterType="model.U ...
- N的多次方Python实现
N的多次方描述编写一个程序,计算输入数字N的0次方到5次方结果,并依次输出这6个结果,输出结果间用空格分隔.其中:N是一个整数或浮点数.print()函数可以同时输出多个信息,采用如下方法可以使用空格 ...
- Jenkins配置中安装插件时提示“No such plugin: cloudbees-folder”
第一次配置Jenkins时,执行下图中出现“No such plugin: cloudbees-folder”,这时应该是服务还没起完全,稍等等就好
- Redis命令操作详解
一.key pattern 查询相应的key (1)redis允许模糊查询key 有3个通配符 *.?.[] (2)randomkey:返回随机key (3)type key:返回key存储的类型 ...
- charles抓包的安装,使用说明以及常见问题解决(windows)
charles抓包的安装,使用说明以及常见问题解决(windows) https://blog.csdn.net/zhangxiang_1102/article/details/77855548
- linux crontab 保证php守护进程运行
写好php脚本.建议定期检测内存占用,核心逻辑就不写了.这个跟业务有关. if(memory_get_usage()>100*1024*1024){ exit(0);//大于100M内存退出程序 ...