koa1.x获取原始body内容
Node版本比较老,koa1.x配合koa-body-parser,默认koa-body-parser会把请求数据转成json对象,
然而有的时候需要获取原始的内容,不要转换,看波koa-body-parser源码,找到办法。
办法一:设置请求头Content-type值为:text/plain
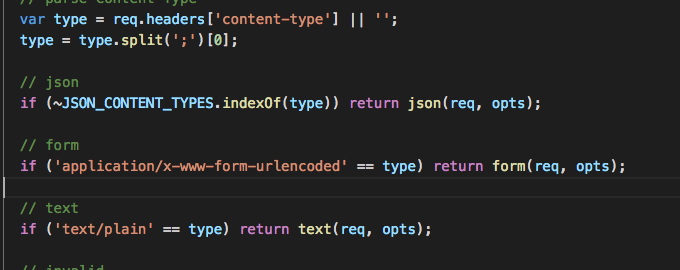
这样ctx.request.body就是一个字符串了.
缺点:要毅端加东西,想到前端的懒惰,较困难,放弃。
继续摸索源码,发现一个办法,代码:
const koa = require('koa');
const router = require('koa-router');
const bodyParser = require('koa-body-parser');
const app = new koa();
const a = new router();
function injectRawBody(rawBodyName) {
return function* (next) {
const ctx = this;
let _rawBody = yield function (done) {
let received = '';
function onData(chunk) {
received += chunk;
}
function onEnd() {
ctx.req.removeListener('data', onData);
ctx.req.removeListener('end', onEnd);
done(null, received);
}
}
ctx.request[rawBodyName] = _rawBody;
yield next;
}
}
app.use(injectRawBody('rawBody'));
app.use(bodyParser();
const server = require('http').createServer(app.callback());
app.use(a.routes());
a.post('/a', function* () {
const ctx = this;
const body = ctx.request.body;
console.log("ctx.request.body:", body);
console.log("type of ctx.request.body:", typeof body);
console.log("raw body:", Buffer.concat(ctx.request.rawBody).toString());
console.log("type of raw body:", typeof ctx.request.rawBody);
yield tt.addOrCreate.apply(ctx);
ctx.body = 'success';
});
server.listen(3000);
运行,看输出,成功把原始内容挂在ctx.request.rawBody上,但ctx.request.body却成了undefined,点解?
经过细查,发现在koa-body-parser/index.js有一句判断:
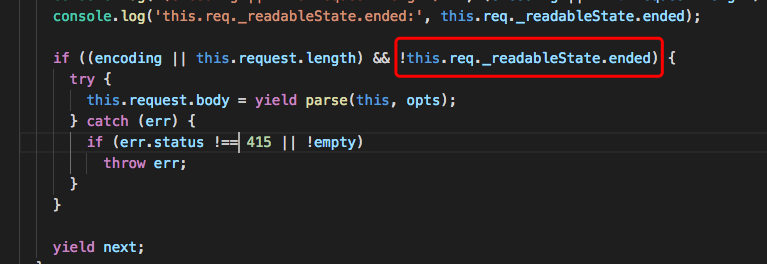
因为在上一个中间件,已经耗尽了req对象的数据,所以ended就是true,那也就不会进入之后的解析了。为了一点小私,导致依赖body的功能不能用,不行不行。
既然我放在body-parser前面不行,那我能放到后面么?像这样:
app.use(bodyParser());
app.use(injectRawBody('rawBody'));
答案是不行,因为在body-parser设置了req.once,而且即使没有设置once,body-parser只有耗尽了req对象(end事件)才会继续下一个中间件,下一个中间件不能再从已经读完的ReadableStream里重新读数据。
再细细看波源码,co、koa-body-parser、co-body、raw-body真没发现什么好方法,这几个库之间的协作太无鏠了,基本上没法hack进去。
想过伪装一个req对象,跟ctx.req有一样的接口,让koa-body-parser里操作的是这个伪装的对象,完了之后再恢复,但没试出来,暂时放弃。
束手无措之际,突然想起晚上在stackoverflow上看到有人问过同样的问题,回忆了一下其中一个回答,当时觉得没怎么样,现在想想真是可以用,代码:
const koa = require('koa');
const router = require('koa-router');
const bodyParser = require('koa-body-parser');
const app = new koa();
const a = new router();
function injectRawBody(rawBodyName) {
return function* (next) {
const ctx = this;
let received = [];
function data(chunk) {
received.push(chunk);
}
ctx.req.on('data', data);
ctx.request[rawBodyName] = received;
yield next;
}
}
app.use(injectRawBody('rawBody'));
app.use(bodyParser();
const server = require('http').createServer(app.callback());
app.use(a.routes());
a.post('/a', function* () {
const ctx = this;
//console.log(ctx.request);
const body = ctx.request.body;
console.log("ctx.request.body:", body);
console.log("type of ctx.request.body:", typeof body);
console.log("raw body:", Buffer.concat(ctx.request.rawBody).toString());
console.log("type of raw body:", typeof ctx.request.rawBody);
yield tt.addOrCreate.apply(ctx);
ctx.body = 'success';
});
server.listen(3000);
在injectRawBody中间件,绑定了data事件,接收数据。而body-parser只有在end事件发生时才会resolve,所有在injectRawBody里,获取到的是完事的数据,只是存的是buffer,使用的时候需要转换为字符串。
优点:没有body-parser那样的限制数据大小,buffer想放多少放多少,不受node堆限制;
简单,容易实现。
缺点:需要转换成字符串,不会转的还可能出现乱码。
koa1.x获取原始body内容的更多相关文章
- ASP.NET Core Web APi获取原始请求内容
前言 我们讲过ASP.NET Core Web APi路由绑定,本节我们来讲讲如何获取客户端请求过来的内容. ASP.NET Core Web APi捕获Request.Body内容 [HttpPos ...
- 《Entity Framework 6 Recipes》中文翻译系列 (45) ------ 第八章 POCO之获取原始对象与手工同步对象图和变化跟踪器
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 8-6 获取原始对象 问题 你正在使用POCO,想从数据库获取原始对象. 解决方案 ...
- paip.uapi 获取网络url内容html 的方法java php ahk c++ python总结.
paip.uapi 获取网络url内容html 的方法java php ahk c++ python总结. 各种语言总结比较,脚本php.python果然是方便.简短,实用. uapi : get_w ...
- POI教程之第二讲:创建一个时间格式的单元格,处理不同内容格式的单元格,遍历工作簿的行和列并获取单元格内容,文本提取
第二讲 1.创建一个时间格式的单元格 Workbook wb=new HSSFWorkbook(); // 定义一个新的工作簿 Sheet sheet=wb.createSheet("第一个 ...
- java分别通过httpclient和HttpURLConnection获取图片验证码内容
前面的文章,介绍了如何通过selenium+Tesseract-OCR来识别图片验证码,如果用接口来访问的话,再用selenium就闲的笨重,下面就介绍一下分别通过httpclient和HttpURL ...
- 百度编辑器ueditor获取不到内容?请把form放在table等其他元素最外面
百度编辑器ueditor获取不到内容?请把form放在table等其他元素最外面. <form name="form" method="post" act ...
- phpcms-v9 --- 如何通过{pc}标签获取全站文章内容?
1.phpcms-v9默认情况下只能根据catid获取当前栏目及子栏目下的文章,但是有时候我们需要如何通过{pc}标签来获取全站文章内容的需求,应该怎么做呢? 第一步:在content_tag.cla ...
- QWidget类中默认是忽略inputMethodEvent事件(要获取输入的内容就必须使用这个事件)
因为项目的需要以及主管的要求,准备将工程移植到Qt中,这样就可以比较容易的实现跨平台了.因为之前工程是在windows下开发的,第一个平台又是mobile所以除了底层框架之外其他的都是使用的windo ...
- spring mvc controller中获取request head内容
spring mvc controller中获取request head内容: @RequestMapping("/{mlid}/{ptn}/{name}") public Str ...
随机推荐
- 计算机基础知识 一 Basic knowledge of computers One
计算机硬件由CPU(Central Processing Unit).存储器.输入设备.输出设备组成. CPU通常由控制单元(控制器)和算数逻辑单元(运算器)组成. 运算器:负责进行算数运算和逻辑运算 ...
- idea使用actiBPM插件中文乱码
idea 安转activiti插件后,编辑流程图发现保存后中文乱码,并且idea的字符集(Settings—>Editor—>File Encodings)已经设置为UTF-8,流程图中中 ...
- idou老师教你学istio :基于角色的访问控制
istio的授权功能,也称为基于角色的访问控制(RBAC),它为istio服务网格中的服务提供命名空间级别.服务级别和方法级别的访问控制.基于角色的访问控制具有简单易用.灵活和高性能等特性.本文介绍如 ...
- Celery基本使用
Celery 什么是Celery? Celery是一种简单/高效/灵活的即插即用的分布式任务队列. Celery应用场景? 需要异步处理的任务,发邮件/发短信/上传等耗时的操作.最终到达提升用户体验的 ...
- PAT甲题题解-1091. Acute Stroke (30)-BFS
题意:给定三维数组,0表示正常,1表示有肿瘤块,肿瘤块的区域>=t才算是肿瘤,求所有肿瘤块的体积和 这道题一开始就想到了dfs或者bfs,但当时看数据量挺大的,以为会导致栈溢出,所以并没有立刻写 ...
- 《Linux内核分析》第一周——计算机是如何工作的?
杨舒雯 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 课程内容 1.诺曼依体系 ...
- 《当大数据遇见网络:大数据与SDN》
总体结构: <当大数据遇见网络:大数据与SDN> 摘要 大数据和SDN无论是对于学术界还是工业界来说都极具吸引力.传统上人们都是分别在最前沿工作中研究这两个重要的领域.然而一方面,SDN的 ...
- Beta阶段冲刺三
Beta阶段冲刺三 Task1:团队TSP 团队任务 预估时间 实际时间 完成日期 新增其他学院的爬虫 180 130 11.30 新增其他学院的数据库字段修改 180 160 12.1 新增其他学院 ...
- java 读写 excle 完整版
pom.xml <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</a ...
- Vue入门---事件与方法详解
一. vue方法实现 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> &l ...