Scrapy框架学习笔记
1.Scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted,其主要对手是Tornado,异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
2.Scrapy架构图(绿线是数据流向):
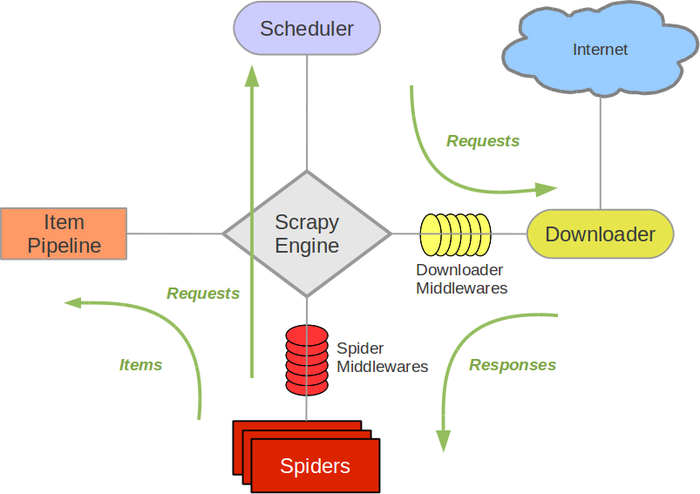
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
3. Scrapy 框架安装
Scrapy框架官方网址:https://doc.scrapy.org/
安装创建(windows)
1.pip install pypiwin32
2.pip install Scrapy (安装Scrapy框架)
注意:windows下可能需要手动安装twisted模块 如.whl: Twisted‑18.4.0‑cp35‑cp35m‑win_amd64.whl
下载地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted (下载完成以后使用 pip install 安装就可以)
3. Scrapy 项目创建
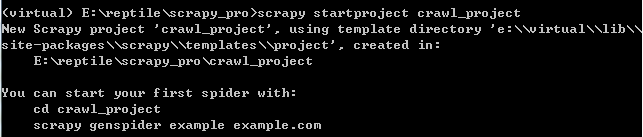
1.打开指定创建项目的位置(文件夹下),按下shift键并右击鼠标,打开cmd命令行,输入 scrapy startproject 项目名称
此时当前文件夹下会出来一个名为crawl_project的文件夹
2.使用编辑器打开刚刚创建的项目,如sublime,pychrom 结构如下:
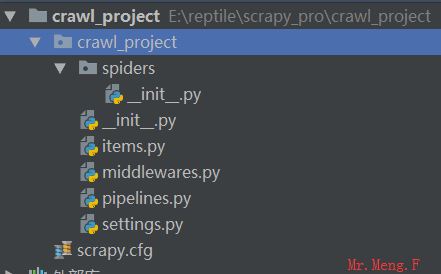
文件说明:- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
4. 使用Scrapy框架编写简单的爬虫
以爬取百度为例:
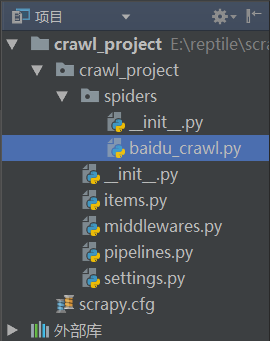
(1).在spiders文件夹下创建一个.py文件(文件名最好以爬取的网站为名)
以下为建完项目的目录:
代码如下:
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu' # 爬虫名称
allowed_domains = ['baidu.com'] # 爬虫有效域
start_urls = ['http://www.baidu.com/'] # 爬虫起始url start_url是固定属性名 # 解析函数
def parse(self, response):
# 获取响应内容
print(type(response.body))
# 文件编码必须指定
with open('baidu.html', 'w', encoding='utf-8') as f:
# 写入文件
f.write(response.body.decode('utf-8'))
(2).在与项目同级的目录下创建一个main.py的文件
文件内容如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl baidu'.split())
(3).运行main.py文件,这样就可以实现一个简单的爬虫了
或者代开命令行,输入:scrapy crawl baidu (爬虫名称是创建.py爬虫文件里属性name的值,我这里是baidu)
注意:此处应该会失败。因为每个网站都有一个robots.txt,表示网站不允许爬的网站目录。scrapy框架遵守该协议。所以需要修改Scrapy框架的配置文件
在项目目录下的 settings.py 修改一下内容:
- ROBOTSTXT_OBEY = False # 默认是True
- 命令行下重新执行 scrapy crawl baidu
Scrapy框架学习笔记的更多相关文章
- Scrapy 框架 (学习笔记-1)
环境: 1.windows 10 2.Python 3.7 3.Scrapy 1.7.3 4.mysql 5.5.53 一.Scrapy 安装 1. Scrapy:是一套基于Twisted的一部处理框 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- phalcon(费尔康)框架学习笔记
phalcon(费尔康)框架学习笔记 http://www.qixing318.com/article/phalcon-framework-to-study-notes.html 目录结构 pha ...
- Yii框架学习笔记(二)将html前端模板整合到框架中
选择Yii 2.0版本框架的7个理由 http://blog.chedushi.com/archives/8988 刚接触Yii谈一下对Yii框架的看法和感受 http://bbs.csdn.net/ ...
- JavaSE中Collection集合框架学习笔记(2)——拒绝重复内容的Set和支持队列操作的Queue
前言:俗话说“金三银四铜五”,不知道我要在这段时间找工作会不会很艰难.不管了,工作三年之后就当给自己放个暑假. 面试当中Collection(集合)是基础重点.我在网上看了几篇讲Collection的 ...
- JavaSE中Collection集合框架学习笔记(3)——遍历对象的Iterator和收集对象后的排序
前言:暑期应该开始了,因为小区对面的小学这两天早上都没有像以往那样一到七八点钟就人声喧闹.车水马龙. 前两篇文章介绍了Collection框架的主要接口和常用类,例如List.Set.Queue,和A ...
- JavaSE中Map框架学习笔记
前言:最近几天都在生病,退烧之后身体虚弱.头疼.在床上躺了几天,什么事情都干不了.接下来这段时间,要好好加快进度才好. 前面用了三篇文章的篇幅学习了Collection框架的相关内容,而Map框架相对 ...
- JavaSE中线程与并行API框架学习笔记1——线程是什么?
前言:虽然工作了三年,但是几乎没有使用到多线程之类的内容.这其实是工作与学习的矛盾.我们在公司上班,很多时候都只是在处理业务代码,很少接触底层技术. 可是你不可能一辈子都写业务代码,而且跳槽之后新单位 ...
- JavaSE中线程与并行API框架学习笔记——线程为什么会不安全?
前言:休整一个多月之后,终于开始投简历了.这段时间休息了一阵子,又病了几天,真正用来复习准备的时间其实并不多.说实话,心里不是非常有底气. 这可能是学生时代遗留的思维惯性--总想着做好万全准备才去做事 ...
随机推荐
- 历届试题 小数第n位-(同余公式+快速幂)
问题描述 我们知道,整数做除法时,有时得到有限小数,有时得到无限循环小数. 如果我们把有限小数的末尾加上无限多个0,它们就有了统一的形式. 本题的任务是:在上面的约定下,求整数除法小数点后的第n位开始 ...
- Ubuntu下面的docker开启ssh服务
选择主流的openssh-server作为服务端: root@161f67ccad50:/# apt-get install openssh-server -y Reading package lis ...
- table-cell http://www.cnblogs.com/StormSpirit/archive/2012/10/24/2736453.html
http://www.cnblogs.com/StormSpirit/archive/2012/10/24/2736453.html
- OTU(operational taxonomic units),即操作分类单元
转自http://www.dxy.cn/bbs/topic/35655953 1.OTU是什么? OTU(operational taxonomic units),即操作分类单元.通过一定的距离度量方 ...
- Process对象的其他属性:
标签(空格分隔): process join方法: 在主进程运行过程中如果想并发地执行其他的任务,我们可以开启子进程,此时主进程的任务与子进程的任务分两种情况: 情况一:在主进程的任务与子进程的任务彼 ...
- AS不能真机调试 (转)
经常遇到这种问题 现总结一下原因 打开手机的开发人员选项,允许USB调试 AS--->tools--->android-->Enable ADB Interation选项 勾上. A ...
- Django常用的模板标签
django 目前了解的各个文件的作用: manage.py: 运行服务 urls: 路由 views: 处理数据 传递给 html模板 html文件: 通过 {{变量名}}接收变量 通过 模板标 ...
- java并发:CopyOnWriteArrayList简单理解
Java集合的快速失败机制 “fail-fast” "fail-fast"是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fas ...
- postman发送json请求
简介: postman是一个很好的http模拟器,在测试rest服务时是很好用的工具,可以发送get.post.put等各种请求. 发送json的具体步骤: 1.选择post请求方式,同时将heade ...
- Shc 应用
1.说明 shc是一个加密shell脚本的工具, 它的作用是把shell脚本转换为一个可执行的二进制文件 2.安装 下载 # mget http://www.datsi.fi.upm.es/~fro ...