Python之路(第十五篇)sys模块、json模块、pickle模块、shelve模块
一、sys模块
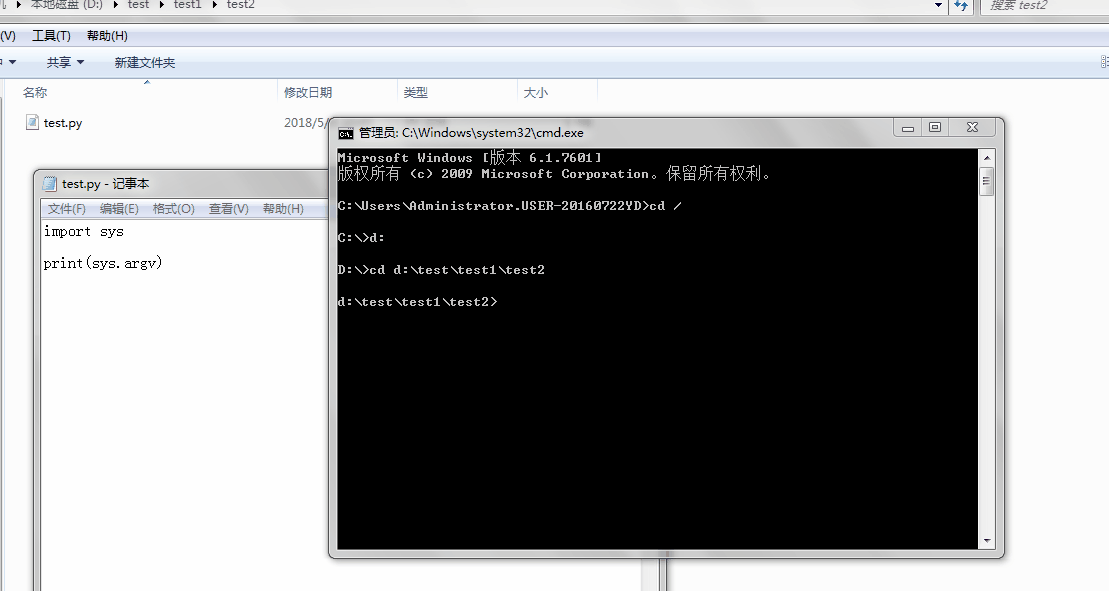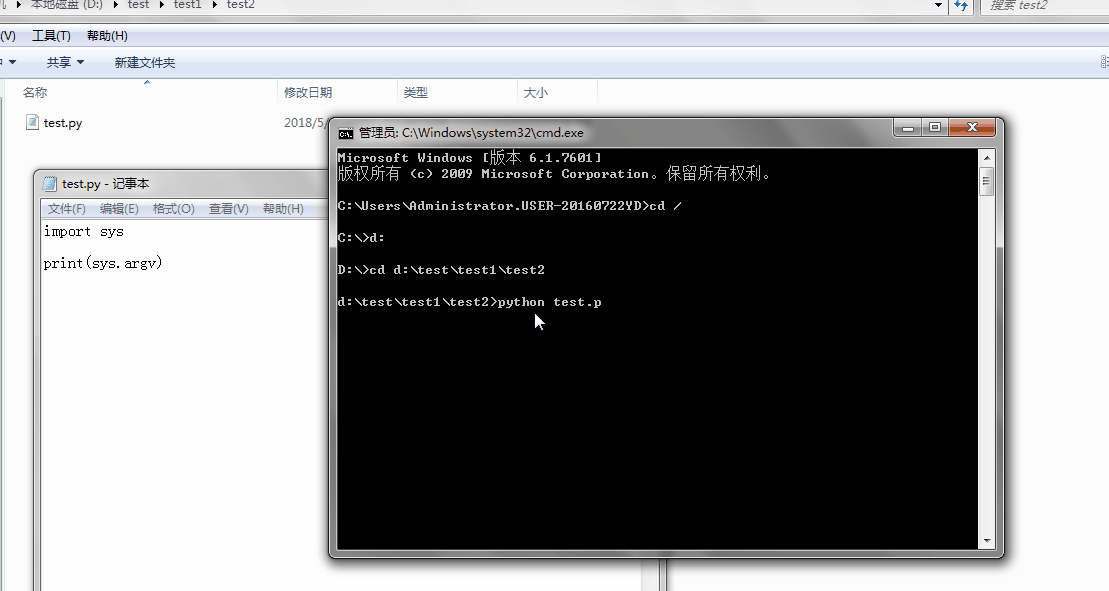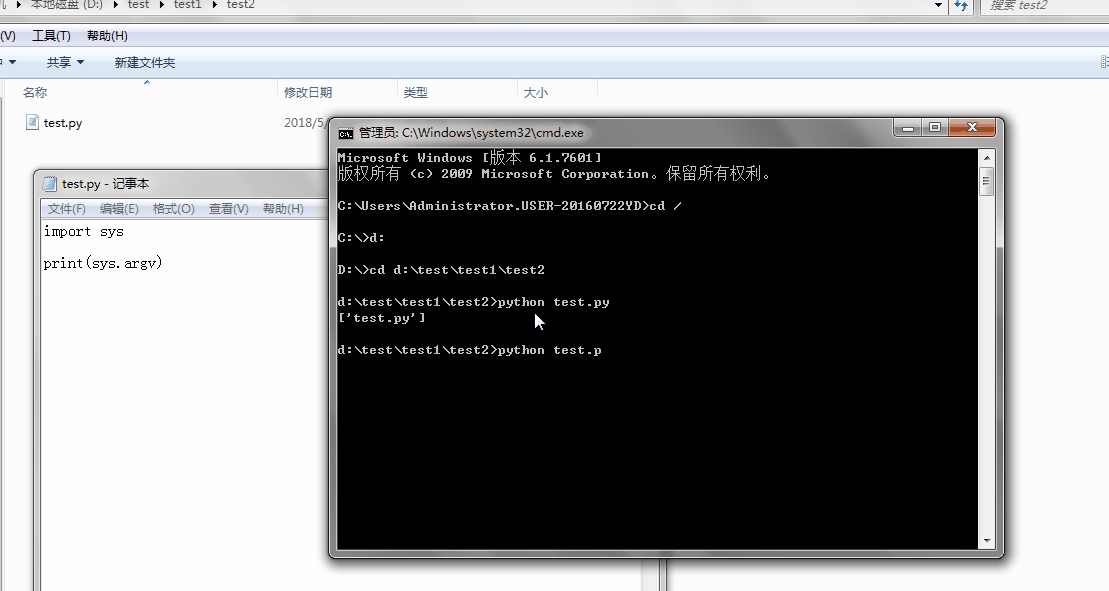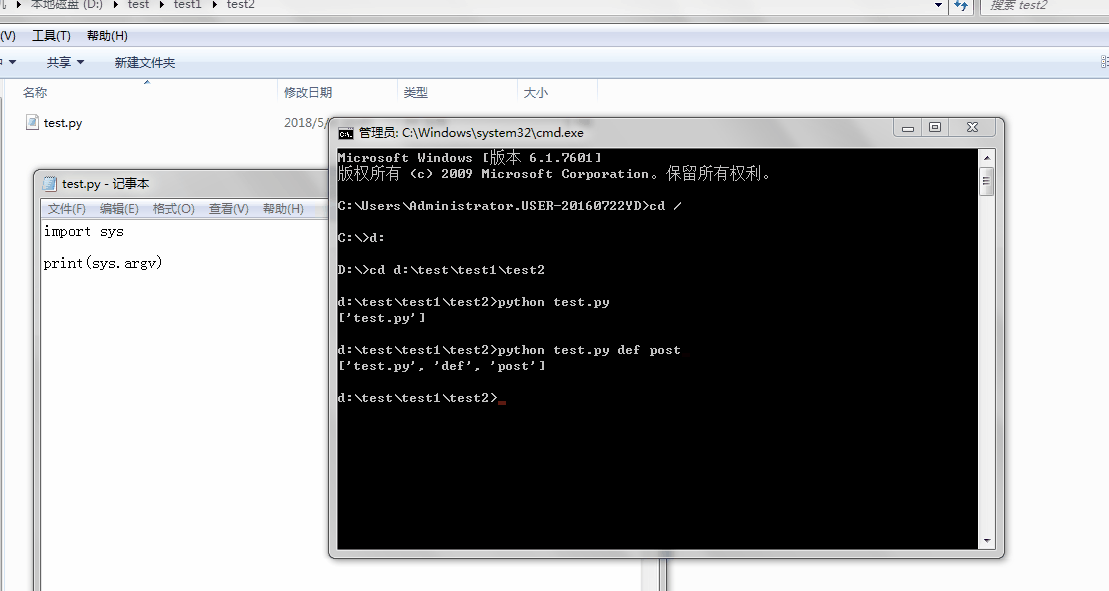
1、sys.argv
命令行参数List,第一个元素是程序本身路径
%E3%80%90day22%E3%80%91\sys.argv1.gif?lastModify=1525869572)
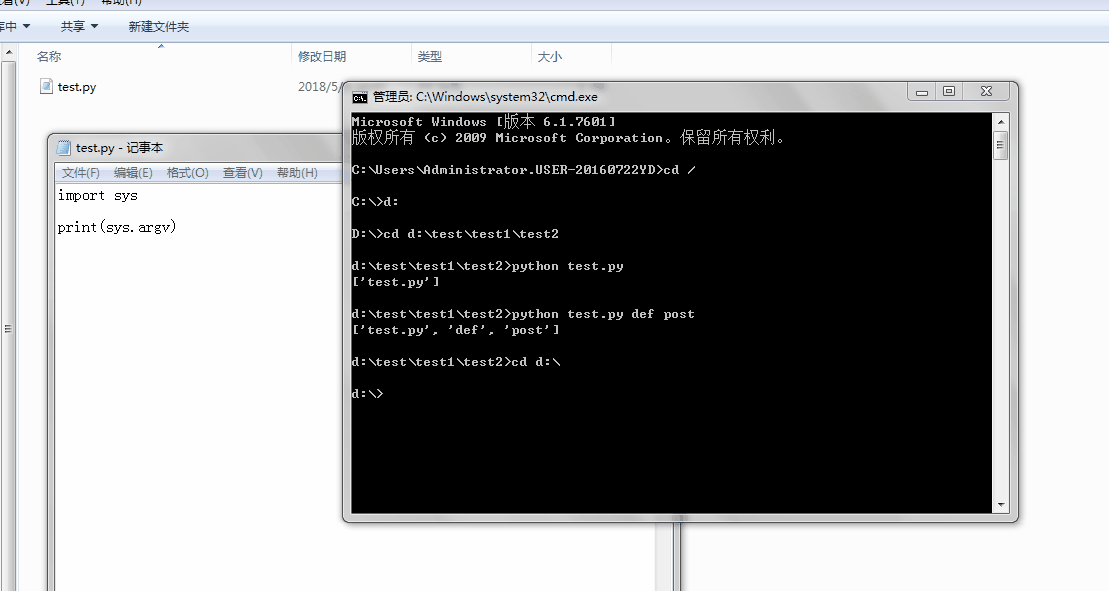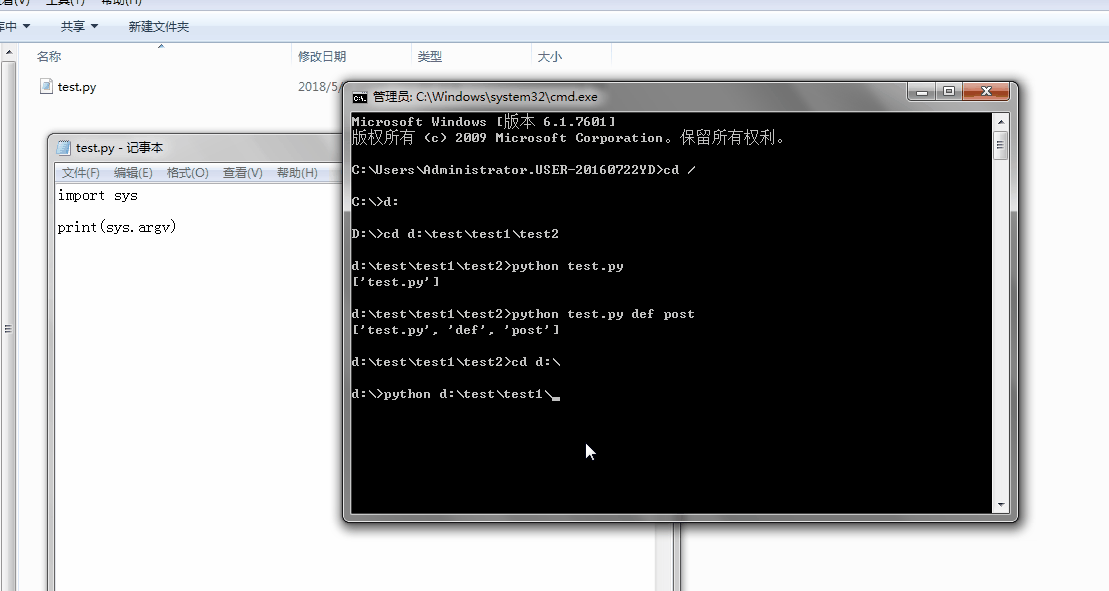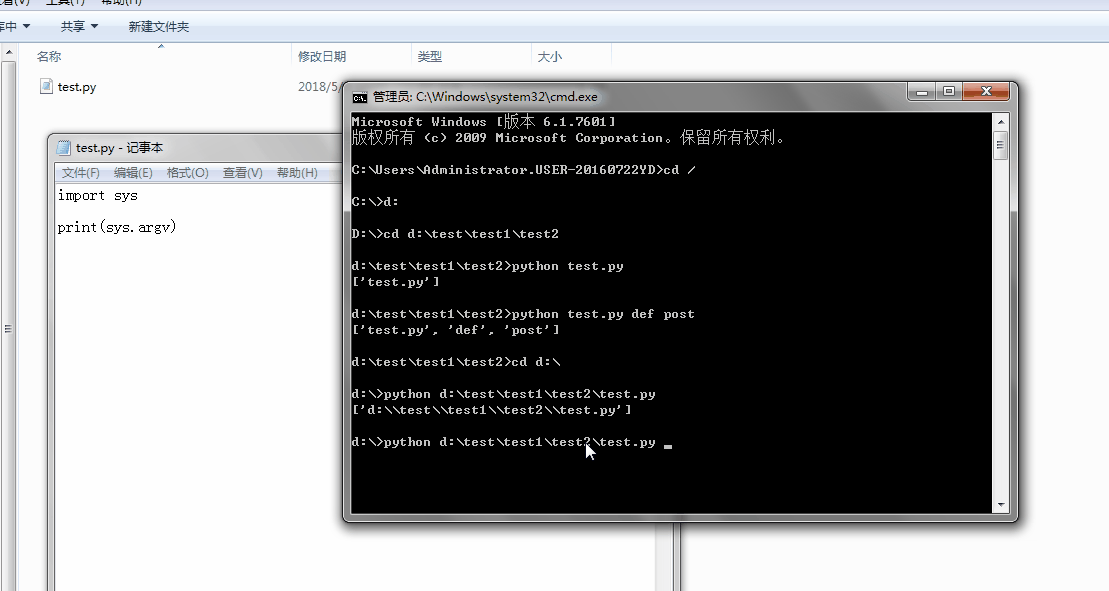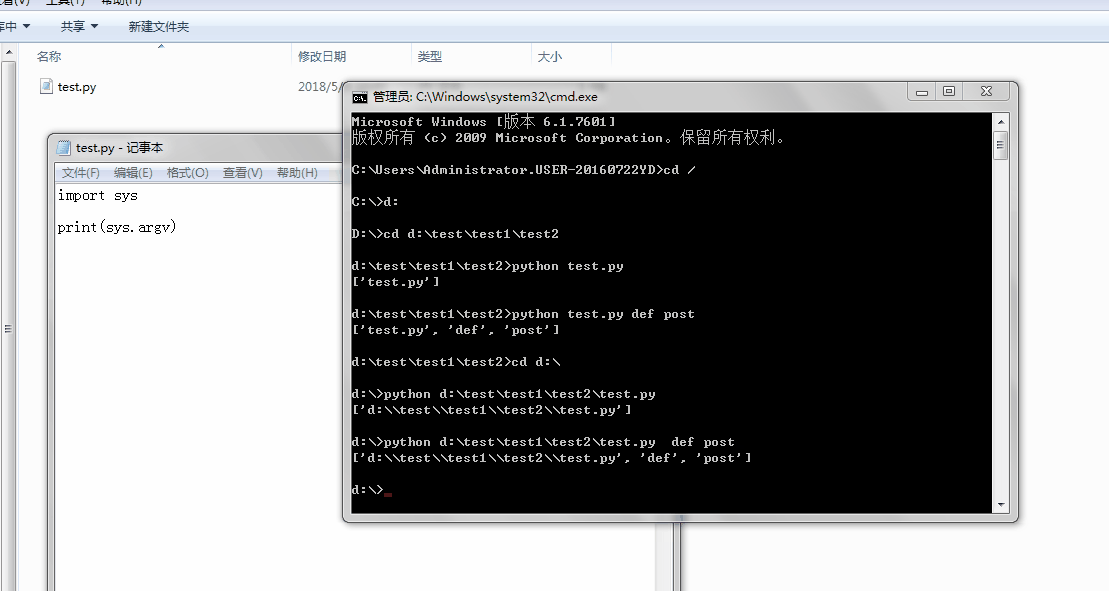
%E3%80%90day22%E3%80%91\sys.argv%202.gif?lastModify=1525869572)
2、sys.exit(n)
退出程序,正常退出时exit(0)
3、sys.version 、 sys.maxint
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
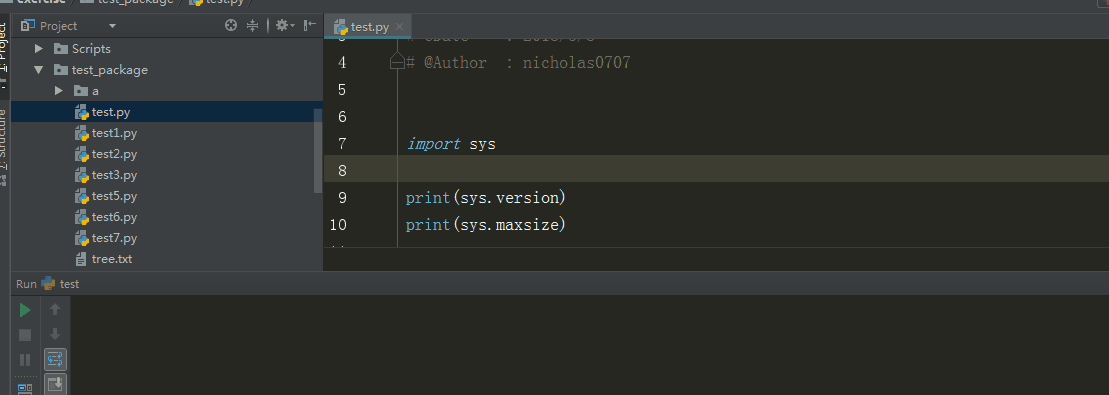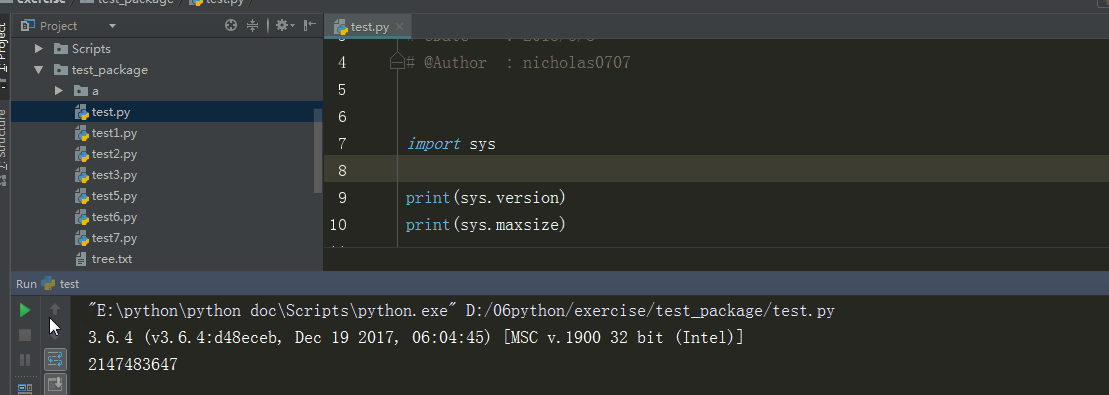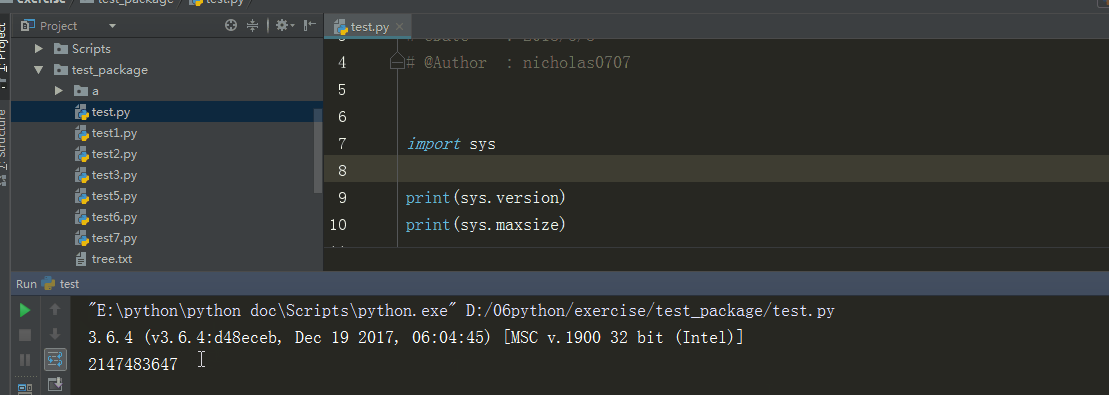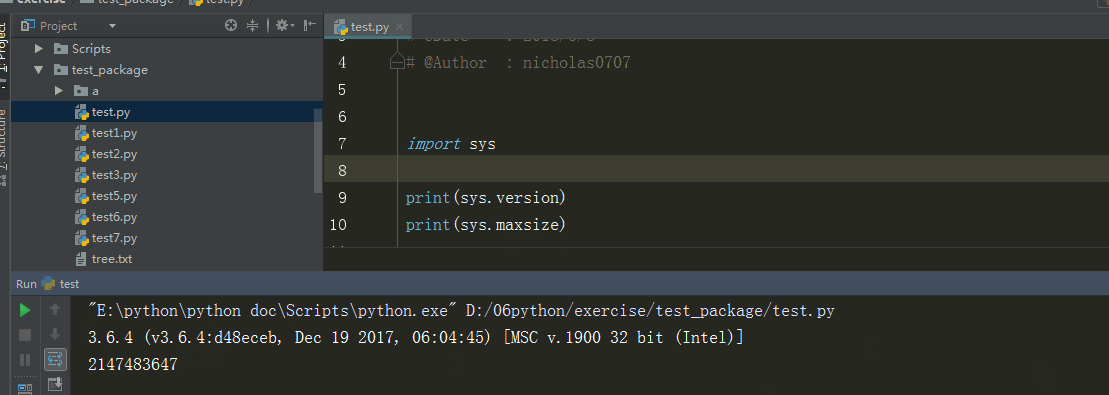
%E3%80%90day22%E3%80%91\sys.version%20%E3%80%81%20sys.maxint%20%20.gif?lastModify=1525869572)
4、sys.path
返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
%E3%80%90day22%E3%80%91\sys.path.gif?lastModify=1525869572)

分析:sys.path输出的第一个结果是程序执行文件所在的文件夹绝对路径,这里的输出结果第二个是工程文件目录,但是这个目录是pycharm自主加上的,直接用解释器执行是没有这个路径的。
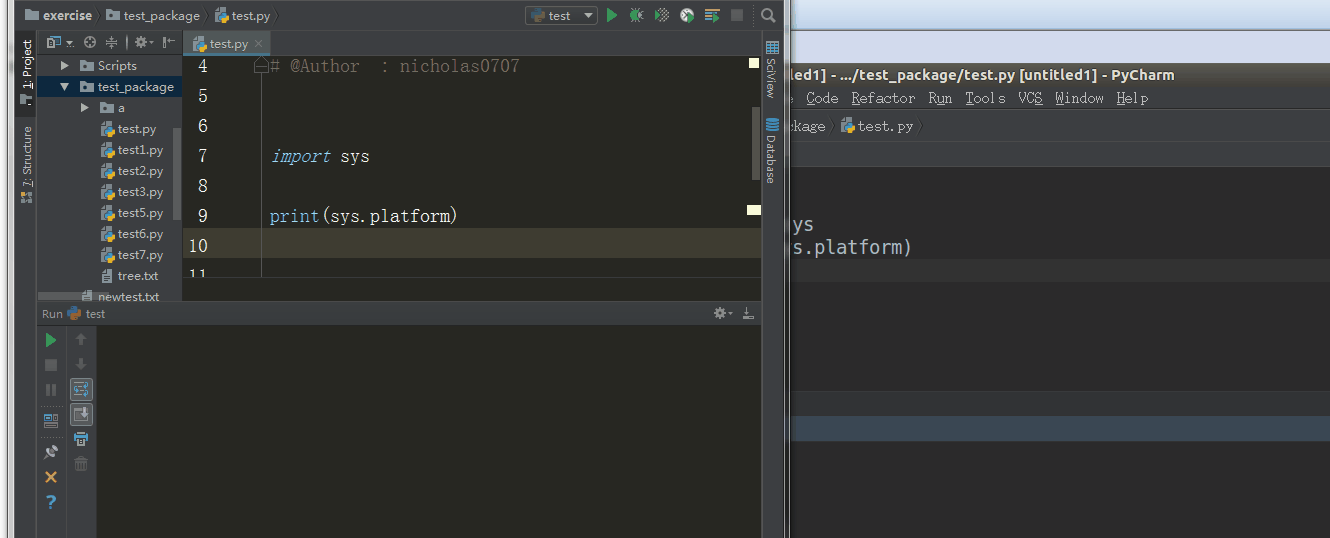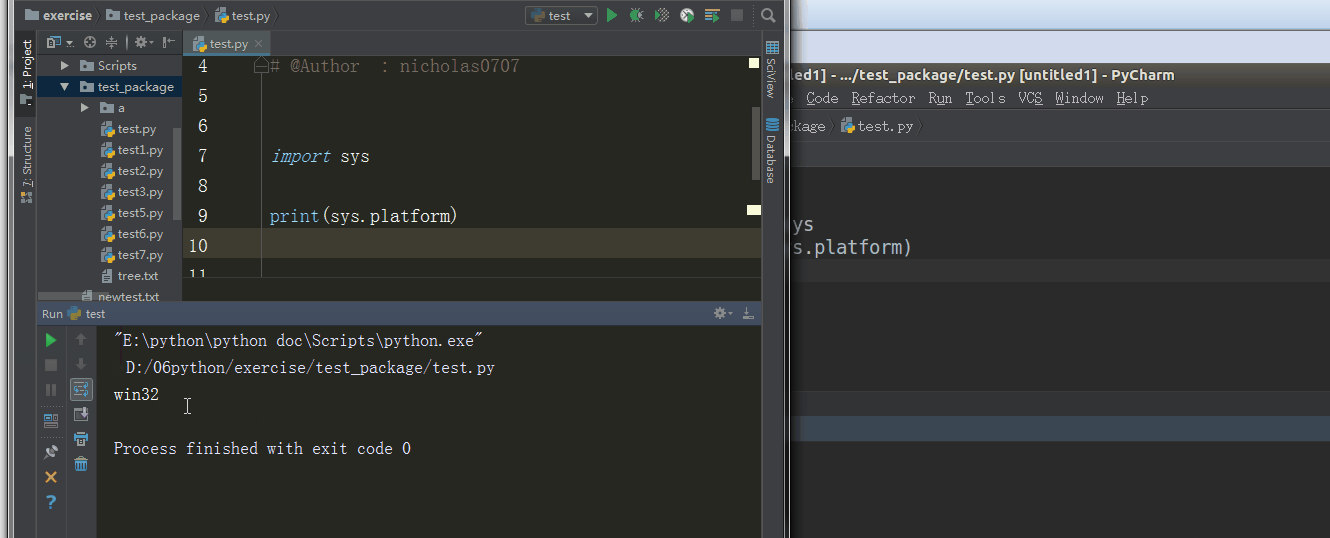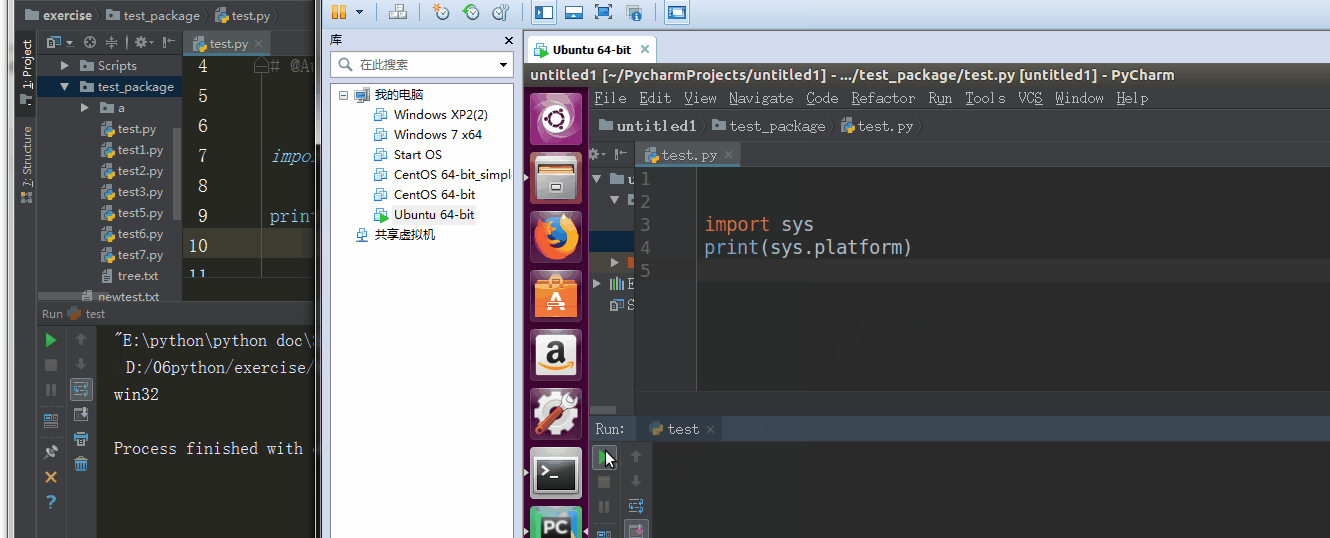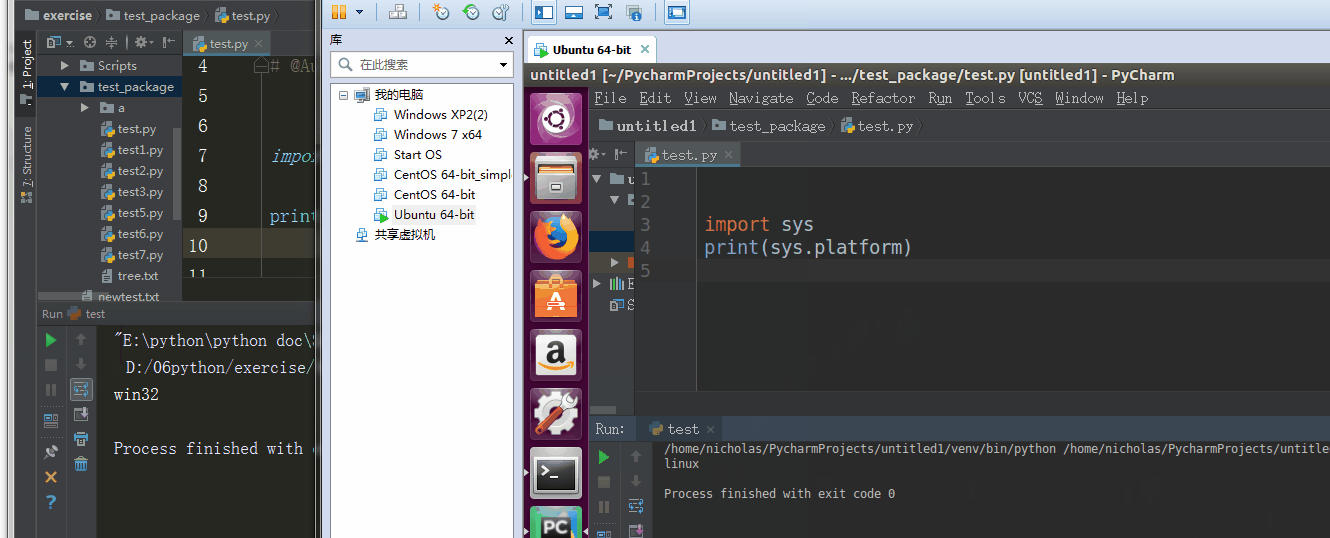
5、sys.platform
返回操作系统平台名称
%E3%80%90day22%E3%80%91\sys.platform%20%20.gif?lastModify=1525869572)
6、sys.stdout.write() 、sys.stdout.flush()
sys.stdout.write() 标准输出 , sys.stdout.write 在交互器模式下这个函数输出数据到stdout,同时还有一个返回值,就是字符串的长度。在pycharm里输出不会有字符串的长度。
sys.stdout.flush() 刷新输出

在Linux系统下,必须加入sys.stdout.flush()才能一秒输一个字符(交互器模式下)
在Windows系统下,加不加sys.stdout.flush()都能一秒输出一个字符(交互器模式下)
在pycharm里都必须加sys.stdout.flush()才能刷新输出
%E3%80%90day22%E3%80%91\sys.stdout.write.gif?lastModify=1525869572)
例子
需求:做一个简单的进度条
%E3%80%90day22%E3%80%91\%E7%AE%80%E5%8D%95%E8%BF%9B%E5%BA%A6%E6%9D%A1.gif?lastModify=1525869572)
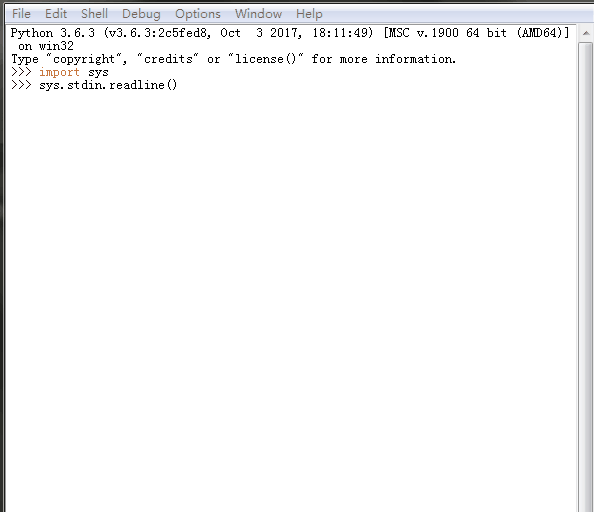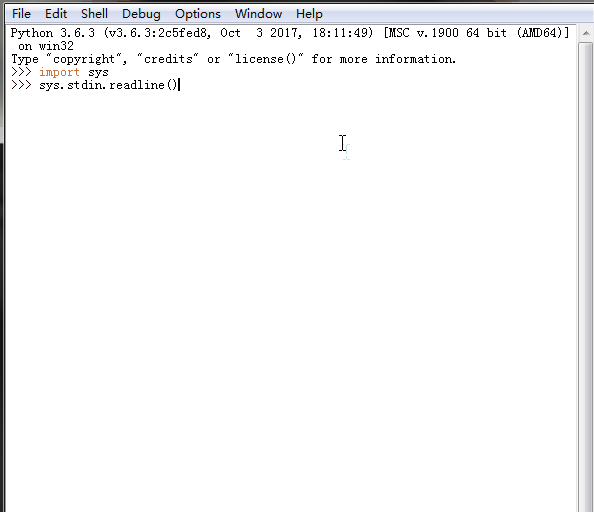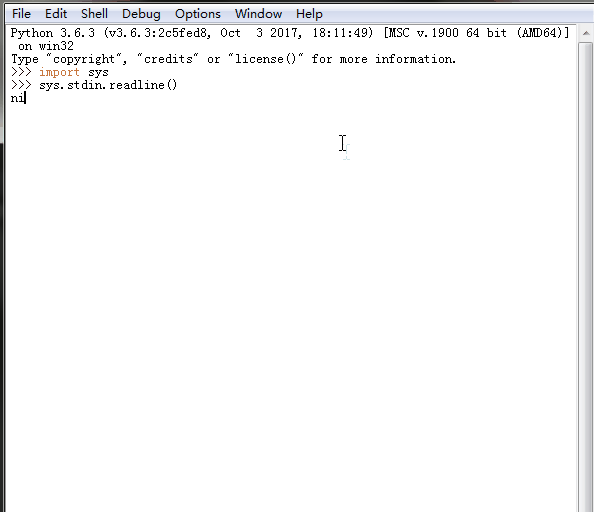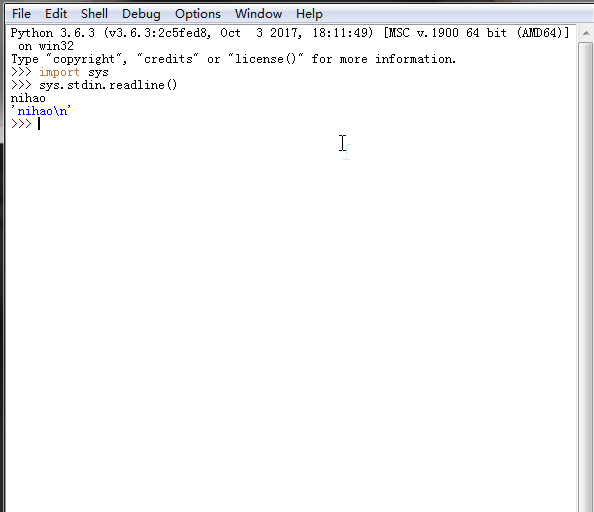
7、 sys.stdin.readline() 、sys.getrecursionlimit() 、sys.setrecursionlimit(1200)
sys.stdin.readline()[:-1] 标准输入
sys.getrecursionlimit() 获取最大递归层数
sys.setrecursionlimit(1200) 设置最大递归层数
%E3%80%90day22%E3%80%91\sys.stdin.readline.gif?lastModify=1525869572)
8、sys.getdefaultencoding() 、sys.getfilesystemencoding
sys.getdefaultencoding() 获取解释器默认编码
sys.getfilesystemencoding 获取内存数据存到文件里的默认编码
二、json模块、pickle模块
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,Python的Json模块有序列化与反序列化两个过程。即 encoding和 decoding。
encoding:把一个python对象编码转换成Json字符串。
decoding:把json格式字符串编码转换成python对象。
什么是序列化、反序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
即把python中的对象变成可存储的json字符串。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
JSON和Python内置的数据类型对应关系
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
%E3%80%90day22%E3%80%91\json%E5%92%8Cpython%E4%B9%8B%E9%97%B4%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%E7%9A%84%E5%AF%B9%E5%BA%94%E5%85%B3%E7%B3%BB.png?lastModify=1525869572)

json和python之间相互转换
%E3%80%90day22%E3%80%91\json%E5%92%8Cpython%E4%B9%8B%E9%97%B4%E7%9B%B8%E4%BA%92%E8%BD%AC%E6%8D%A2.png?lastModify=1525869572)

json的4个方法
json提供四个功能:dumps, dump, loads, load
1、dumps和dump
序列化过程
将一个python对象编码转换成Json字符串,可以存储可以网络远程传输
dumps只完成了序列化为str,将数据通过特殊的形式转换为所有程序语言都认识的字符串
dump必须传文件描述符,将序列化的str保存到文件中,将数据通过特殊的形式转换为所有程序语言都认识的字符串,并写入文件
dumps()用法
例子
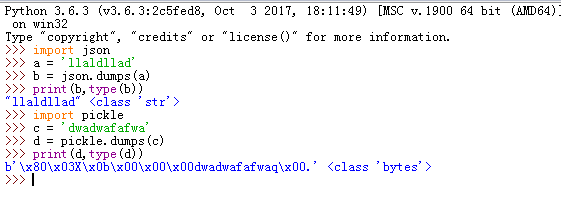
import json
dic = {"k1":"v1"}
str1= "nicholas"
data1 = json.dumps(dic)
data2 = json.dumps(str1)
print(data1)
print(data2)
print(type(data1))
print(type(data2))
输出结果

%E3%80%90day22%E3%80%91\dumps.gif?lastModify=1525869572)
dump
例子
import json
dic = {"k1":"v1"}
with open("test.json","a+") as f :
json.dump(dic,f)#传入要序列化的数据、文件描述符
输出结果
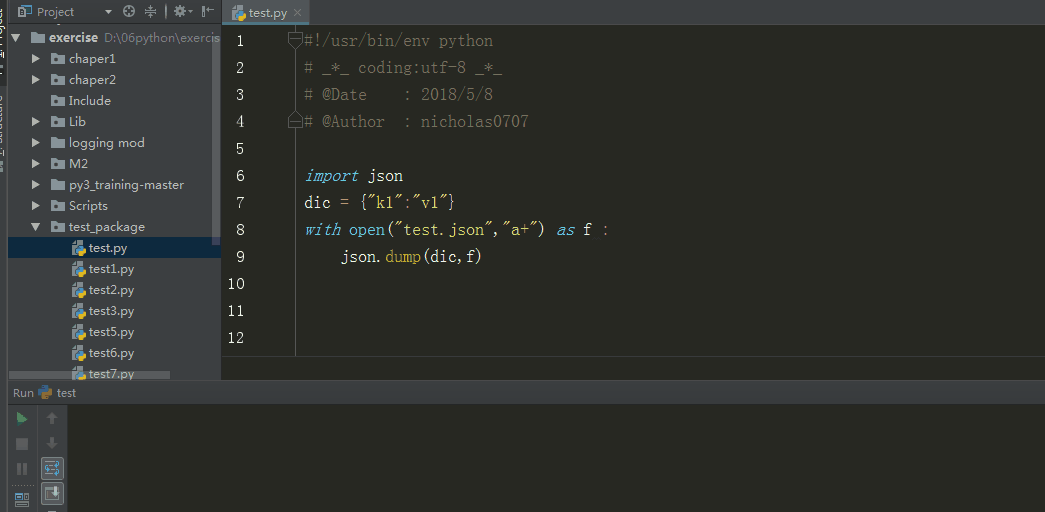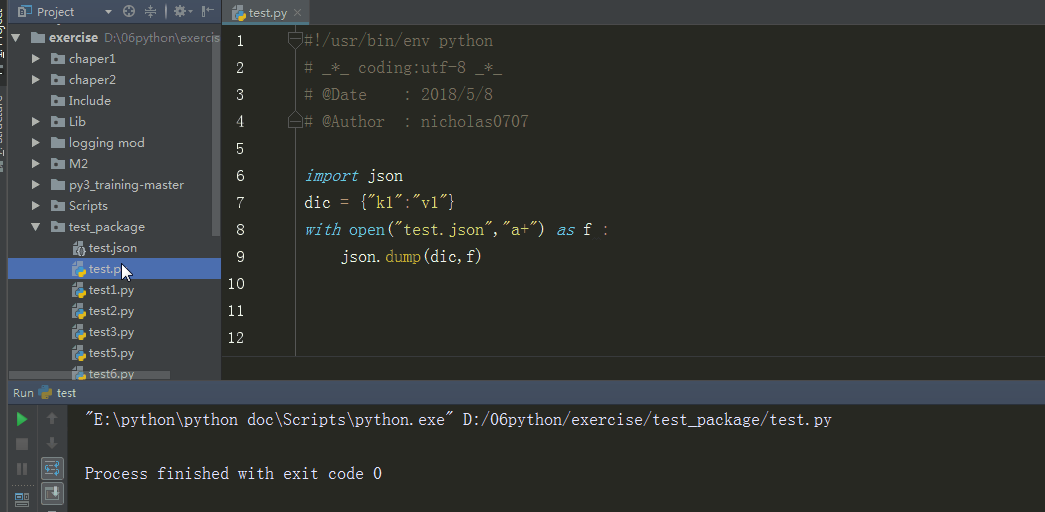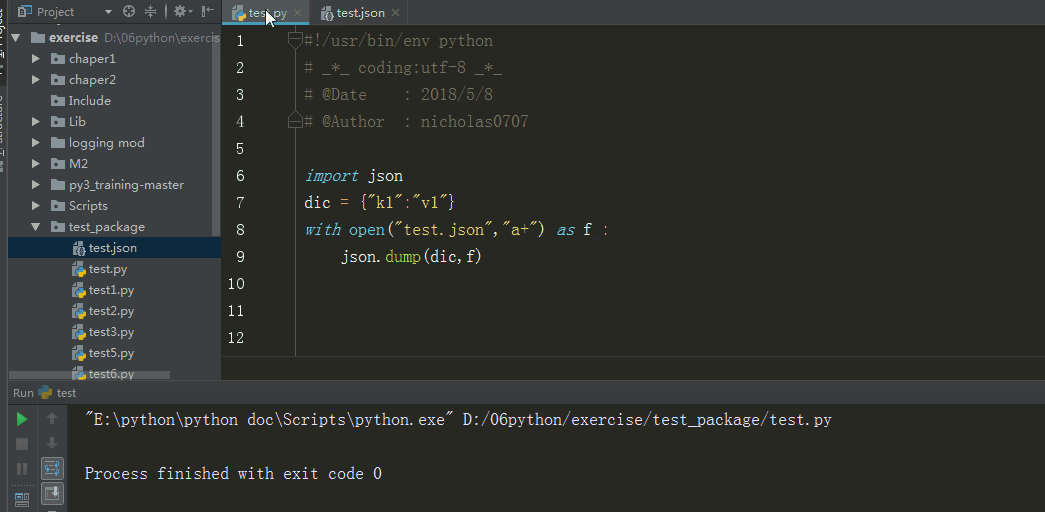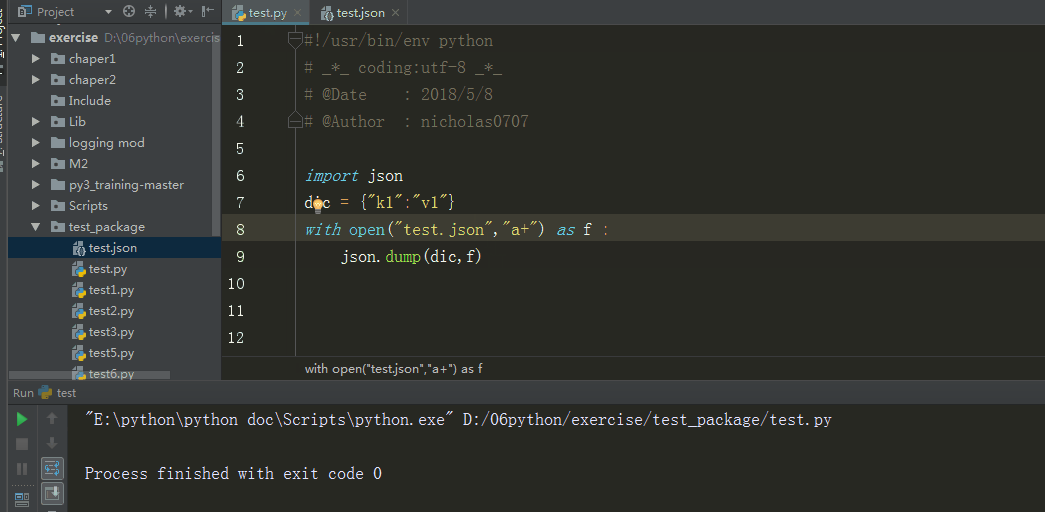
%E3%80%90day22%E3%80%91\dump.gif?lastModify=1525869572)
分析:数据通过json.dump转换为所有程序语言都认识的字符串,并写入文件
dump等价于dumps加上打开文件然后将data = json.dumps(var) 写入文件。
例子
import json
dic = {"k1":"v1"}
data = json.dumps(dic)
with open("test.json","a+") as f :
f.write(data)
2、loads 和 load
loads 只完成了反序列化,将json编码的字符串再转换为python的数据结构
load 只接收文件描述符,完成了读取文件和反序列化,数据文件中读取数据,并将json编码的字符串转换为python的数据结构
用loads例子
import json
with open("test.json") as f :
data = json.loads(f.read()) #需要加入f.read()方法读取文件数据
print(data)
print(type(data))
输出结果
{'k1': 'v1'}
<class 'dict'>
用load例子2
import json
with open("test.json") as f :
data = json.load(f) #直接加入文件描述符即可
print(data)
print(type(data))
输出结果
{'k1': 'v1'}
<class 'dict'>
pickle和python之间相互转换

Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
%E3%80%90day22%E3%80%91\pickle%E5%92%8Cpython%E4%B9%8B%E9%97%B4%E7%9B%B8%E4%BA%92%E8%BD%AC%E6%8D%A2.png?lastModify=1525869572)
picle模块 和json模块都有 dumps、dump、loads、load四种方法,而且用法一样。
不用的是json模块序列化出来的是通用格式,其它编程语言都认识,就是普通的字符串,
而picle模块序列化出来的只有python可以认识,其他编程语言不认识的,表现为乱码
注意json的序列化之后产生的格式是还是字符串,pickle序列化之后产生的格式是字节流,可以直接用于网络传输。
例子1
import pickle
dic = {"k1":"v1"}
with open("test.pickle","wb") as f: #注意这里要用二进制模式,序列化后的对象是'bytes'
data = pickle.dumps(dic)
f.write(data)
或者
import pickle
dic = {"k1":"v1"}
with open("test.pickle","wb") as f:
data = pickle.dump(dic,f)
例子2
import pickle
with open("test.pickle","rb") as f:
data = pickle.loads(f.read())
print(data)
或者
import pickle
with open("test.pickle","rb") as f:
data = pickle.load(f)
print(data)
json vs pickle比较:
JSON:
优点:跨语言、体积小
缺点:只能支持int\str\list\tuple\dict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
三、shelve 模块
shelve是封装了pickle,shelve 只能在python中用
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
序列化:保存对象至shelve文件中
例子
import shelve
f = shelve.open("test")
names = ["nicholas","jack","pony"] #python中的数据
info = {"age":[18,54,48],"some":[1,2,3]} #python中的数据
f["names"] = ["nicholas","jack","pony"] #向文件中添加内容,添加方式与给字典添加键值对类似
f["info"] = {"age":[18,54,48],"some":[1,2,3]} #向文件中添加内容,添加方式与给字典添加键值对类似
f.close() #关闭文件
输出结果
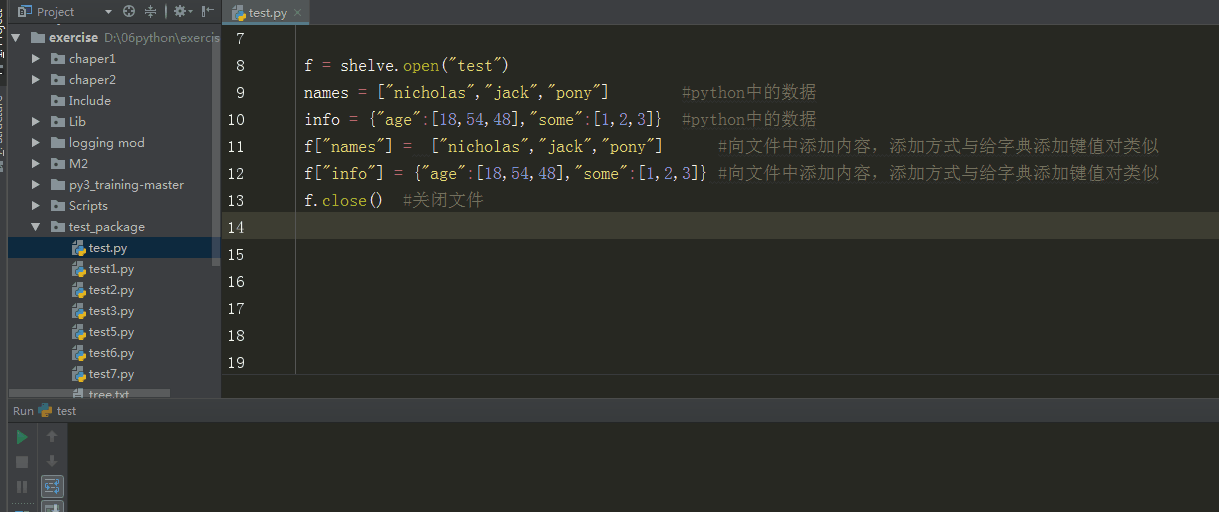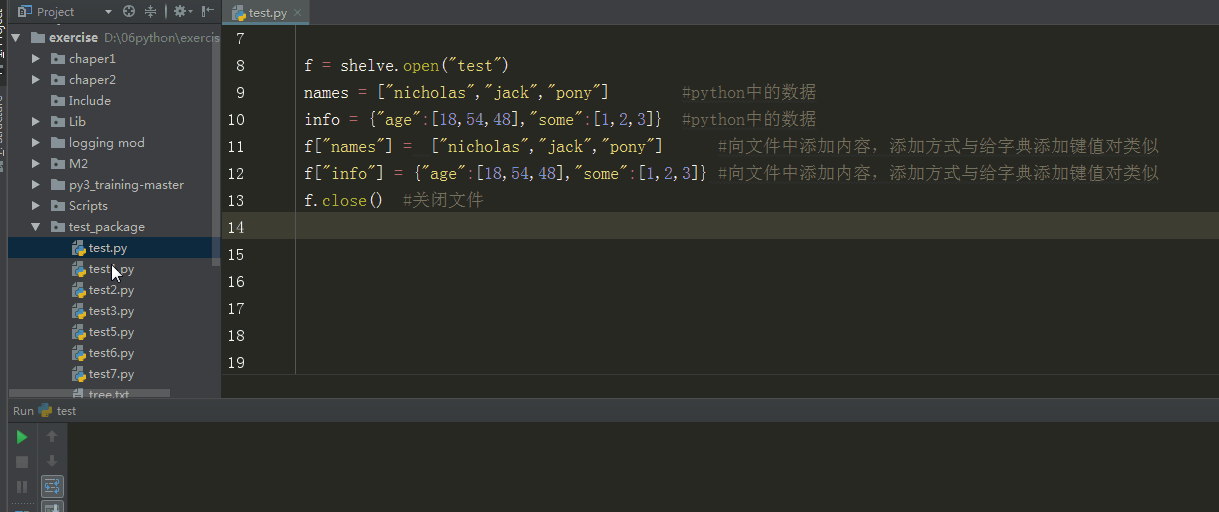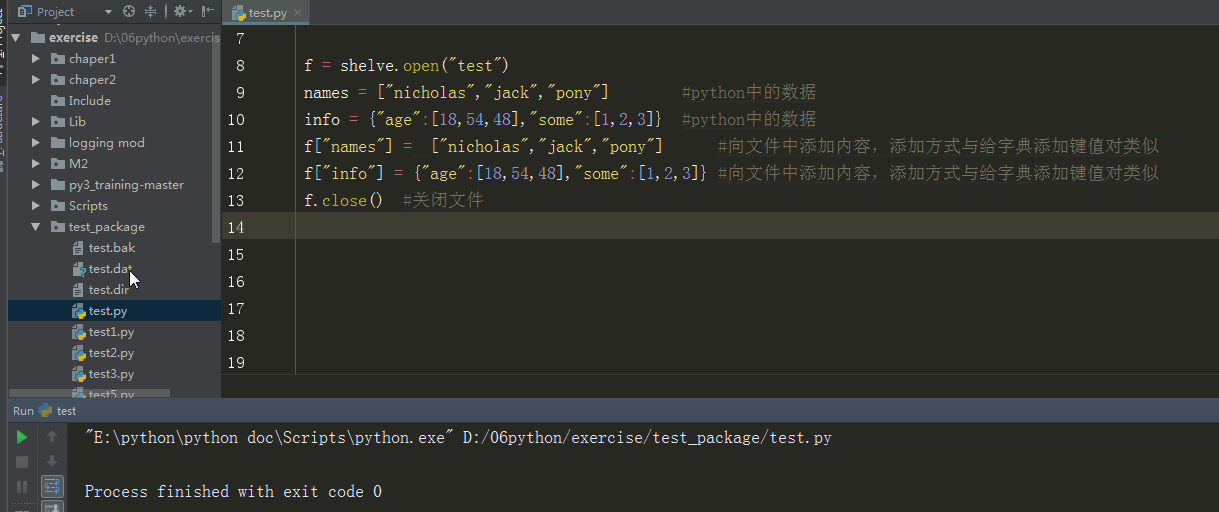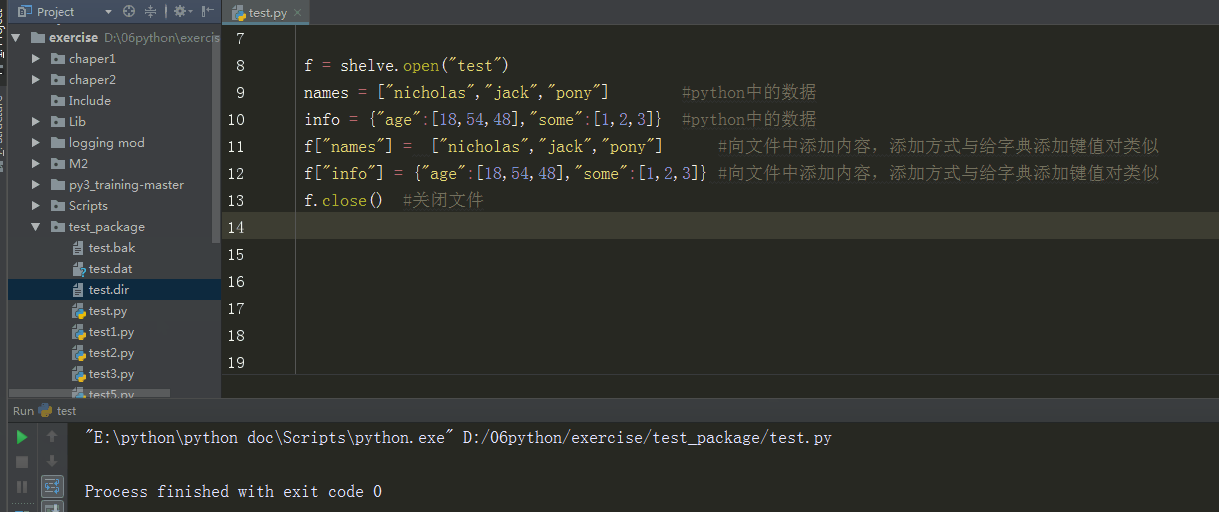
%E3%80%90day22%E3%80%91\shelve%E5%BA%8F%E5%88%97%E5%8C%96.gif?lastModify=1525869572)
分析:shelve序列化后产生3个文件
反序列化:从文件中读取对象
例子
import shelve
d = shelve.open("test")
names = d["names"] # 从文件中类似字典中获取键值的方式一样读取内容
info = d["info"]
print(names,type(names))
print(info,type(info))
d.close() #关闭文件
输出结果
%E3%80%90day22%E3%80%91\shelve%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96.gif?lastModify=1525869572)

Python之路(第十五篇)sys模块、json模块、pickle模块、shelve模块的更多相关文章
- Python之路(第二十五篇) 面向对象初级:反射、内置方法
[TOC] 一.反射 反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问.检测和修改它本身状态或行为的一种能力(自省).这一概念的提出很快引发了计算机科学领域关于应用反射性的研究.它 ...
- 第九节:os、sys、json、pickle、shelve模块
OS模块: os.getcwd()获取当前路径os.chdir()改变目录os.curdir返回当前目录os.pardir()父目录os.makedirs('a/b/c')创建多层目录os.remov ...
- Python之路【第五篇】:面向对象和相关
Python之路[第五篇]:面向对象及相关 面向对象基础 基础内容介绍详见一下两篇博文: 面向对象初级篇 面向对象进阶篇 其他相关 一.isinstance(obj, cls) 检查是否obj是否 ...
- Python之路【第五篇】:面向对象及相关
Python之路[第五篇]:面向对象及相关 面向对象基础 基础内容介绍详见一下两篇博文: 面向对象初级篇 面向对象进阶篇 其他相关 一.isinstance(obj, cls) 检查是否obj是否 ...
- Python之路(第十二篇)程序解耦、模块介绍\导入\安装、包
一.程序解耦 解耦总的一句话来说,减少依赖,抽象业务和逻辑,让各个功能实现独立. 直观理解“解耦”,就是我可以替换某个模块,对原来系统的功能不造成影响.是两个东西原来互相影响,现在让他们独立发展:核心 ...
- Python开发【第十五篇】模块的导入
的导入语句 import 语句 语法: import 模块名1 [as 模块别名] 作用: 将某模块整体导入到当前模块 示例: import math import sys,os 用法: 模块名.属性 ...
- Python之路(第十六篇)xml模块、datetime模块
一.xml模块 xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单, xml比较早,早期许多软件都是用xml,至今很多传统公司如金融行业的很多系统的接口还主要 ...
- 023--python os、sys、json、pickle、xml模块
一.os模块 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 >>> os.getcwd() 'C:\\Python36' os.chdir(&quo ...
- python模块-json、pickle、shelve
json模块 用于文件处理时其他数据类型与js字符串之间转换.在将其他数据类型转换为js字符串时(dump方法),首先将前者内部所有的单引号变为双引号,再整体加上引号(单或双)转换为js字符串:再使用 ...
随机推荐
- 去掉Android新建项目的顶部标题
[ 去掉Android新建项目的顶部标题] 使用NoActionBar的Theme即可. 参考:http://blog.csdn.net/u012246458/article/details/5299 ...
- linux上单网卡配置使用多个IP地址
准备一台红帽系列的linux(例如rhel.red hat.centos.fredora等) 方法/步骤 新建配置文件. 首先说明一下规则: 新建配置文件,配置文件名称为ifcfg-适配器名称:0-2 ...
- ORACLE 把不是SYS用户下的所有JOB删除掉
BEGIN FOR job_id in(select job,log_user,priv_user,schema_user from dba_jobs) LOOP IF(job_id.lo ...
- google翻译插件安装
来源:http://www.cnplugins.com/tools/how-to-setup-crx.html 1. 下载: 2.拖拽: 3.下一步安装 4.完成.
- 使用Fiddler远程抓包(转载)
转载自 http://www.cnblogs.com/111testing/p/6436372.html Fiddler简介以及web抓包 一.Fiddler简介 简单来说,Fiddler是一个htt ...
- CSS float清除浮动
解决高度塌陷的问题 – 清除浮动 CSS中有个讨论较多的话题就是如何清除浮动,清除浮动其实就一个目的,就是解决高度塌陷的问题.为什么会高度塌陷?什么时候会高度塌陷?塌陷原因是:元素含有浮动属性 – 破 ...
- Linux下常用的编辑文件与保存命令
打开文件: vi aaa.conf 编辑: i 编辑结束,按ESC 键 跳到命令模式,然后输入退出命令: :w (write)保存文件但不退出vi 编辑 :w! 强制保存,不退出vi 编辑 :w fi ...
- Math.random控制随机数范围
let minNum= parseInt(Math.random()*7) + 1 let maxNum= parseInt(Math.random()*83) + 1 生成7~83的随机整数
- Python compile() 函数
Python compile() 函数 Python 内置函数 描述 compile() 函数将一个字符串编译为字节代码. 语法 以下是 compile() 方法的语法: compile(sourc ...
- Android 性能测试之内存 --- 追加腾讯性能案例,安卓抓取性能扫盲帖
内存测试: 思路 目前做的是酒店APP,另下载安装几个个第三方酒店的APP以方便对比(相当于可以做竞品测试) 数据的获取来源是ADB底层命令,而且最好是不需要root权限,因为很多手机root很麻烦或 ...