Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.连接操作Map端Join(适合处理小表+大表的情况)
no001 12.3
no002 18.8
no003 20.0
no004 50.0
no005 23.1
no006 39.0
no007 5.0
no008 6.0
orders.txt 文件内容
linghunbaiduren
yinzhengjie
alex
linhaifeng
wupeiqi
xupeicheng
changqiling
laowang
customers.txt 文件内容
1>.MapJoinMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.map; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map; /**
* 输出KeyValue
* key是组合后的数据
* value空
*
*/
public class MapJoinMapper extends Mapper<LongWritable,Text,Text,NullWritable> { Map<Integer,String> map = new HashMap<Integer, String>(); /**
*
*setup方法是在map方法之前执行,它也是map方法的初始化操作.
*
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//通过上下文,得到conf
Configuration conf = context.getConfiguration();
//通过conf获取自定义key
String file = conf.get("customer.file");
//读取customer数据
FileSystem fs = FileSystem.get(conf);
FSDataInputStream fis = fs.open(new Path(file));
InputStreamReader reader = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(reader);
String line = null;
byte[] buf = new byte[1024];
while((line = br.readLine()) != null){
String[] arr = line.split("\t");
int id = Integer.parseInt(arr[0]);
String name = arr[1];
//1 tom
//2 tomas
map.put(id,name);
}
} /**
* 通过
* oid orderno price cid
* 8 no008 6.0 1
*
* 得到
* cid cname orderno price
* 1 tom no008 6.0
*/ @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] arr = line.split("\t"); String orderno = arr[1];
String price = arr[2];
int cid = Integer.parseInt(arr[3]); String name = map.get(cid);
//拼串操作
String outKey = cid + "\t" + name + "\t" + orderno + "\t" + price + "\t";
//
context.write(new Text(outKey), NullWritable.get());
}
}
2>.MapJoinApp.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.map; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MapJoinApp { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//自定义一个变量名"customer.file",后面的文件是其具体的值,这里设置后可以在Mapper端通过get方法获取改变量的值。
conf.set("customer.file", "D:\\10.Java\\IDE\\yhinzhengjieData\\customers.txt");
conf.set("fs.defaultFS","file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(MapJoinApp.class);
job.setJobName("Map-Join");
job.setMapperClass(MapJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\orders.txt"));
Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\out");
if (fs.exists(outPath)){
fs.delete(outPath);
}
FileOutputFormat.setOutputPath(job,outPath);
job.waitForCompletion(true);
}
}
3>.验证结果是否正确

二.连接操作Reduce端Join之组合Key实现(适合处理大表+大表的情况)
no001 12.3
no002 18.8
no003 20.0
no004 50.0
no005 23.1
no006 39.0
no007 5.0
no008 6.0
orders.txt 文件内容
linghunbaiduren
yinzhengjie
alex
linhaifeng
wupeiqi
xupeicheng
changqiling
laowang
customers.txt 文件内容
以上两个文件的指定路径如下:(输入路径)
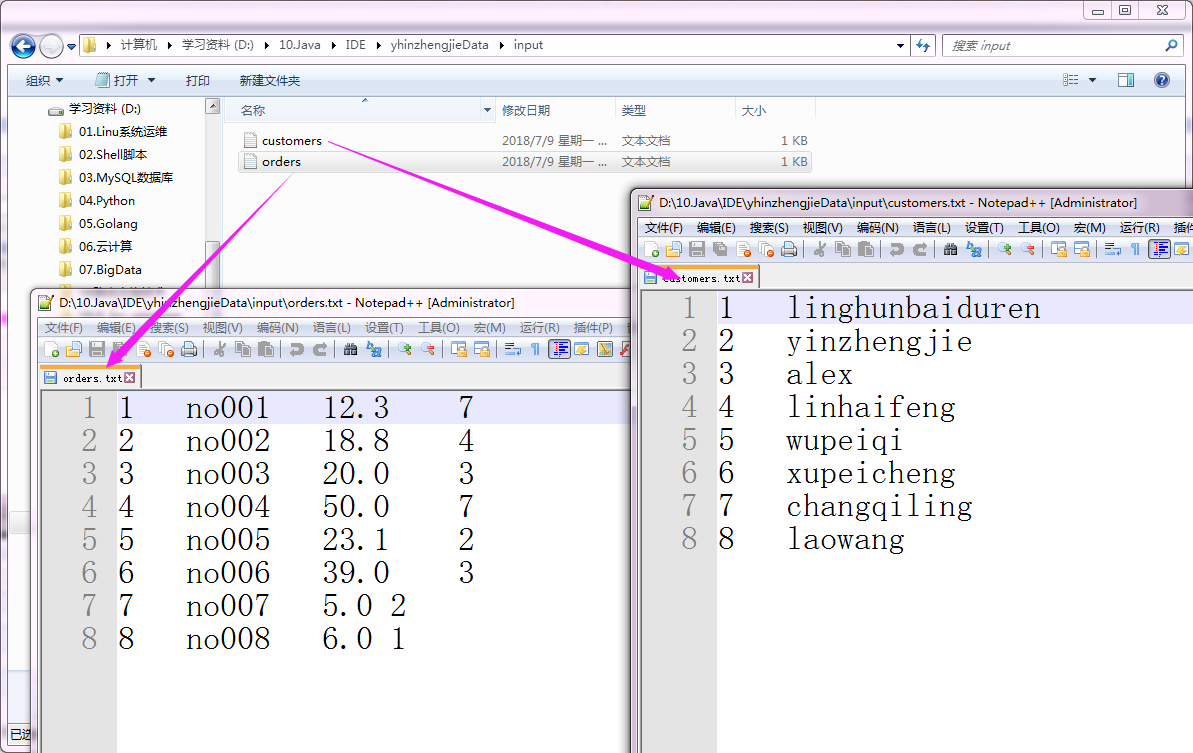
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.reduce; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; public class CompKey implements WritableComparable<CompKey> {
//定义客户id
private int cid;
//定义标识
private int flag; public int compareTo(CompKey o) {
//如果cid相等
if (this.getCid() == o.getCid()) {
//比较flag
return this.getFlag() - o.getFlag();
}
return this.getCid() - o.getCid();
} //定义序列化
public void write(DataOutput out) throws IOException {
out.writeInt(cid);
out.writeInt(flag);
} //定义反序列化
public void readFields(DataInput in) throws IOException {
cid = in.readInt();
flag = in.readInt();
} public int getCid() {
return cid;
} public void setCid(int cid) {
this.cid = cid;
} public int getFlag() {
return flag;
} public void setFlag(int flag) {
this.flag = flag;
} @Override
public String toString() {
return cid + "," + flag;
}
}
CompKey.java(组合Key实现)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.reduce; import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; public class MyGroupingComparator extends WritableComparator { public MyGroupingComparator() {
super(CompKey.class, true);
} @Override
public int compare(WritableComparable a, WritableComparable b) { CompKey ck1 = (CompKey) a;
CompKey ck2 = (CompKey) b; int cid1 = ck1.getCid();
int cid2 = ck2.getCid(); return cid1 - cid2;
}
}
MyGroupingComparator.java (分组对比器实现)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.reduce; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class ReduceJoinMapper extends Mapper<LongWritable, Text, CompKey, Text> { String fileName; @Override
protected void setup(Context context) throws IOException, InterruptedException {
//得到输入切片
InputSplit split = context.getInputSplit();
FileSplit fileSplit = (FileSplit) split; //得到切片文件名或路径
fileName = fileSplit.getPath().getName();
} @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] arr = line.split("\t"); //判断文件是否包含"customers"。
if (fileName.contains("customers")) {
int cid = Integer.parseInt(arr[0]);
CompKey ck = new CompKey();
ck.setCid(cid);
ck.setFlag(0);
context.write(ck, value);
} else {
int cid = Integer.parseInt(arr[3]);
CompKey ck = new CompKey();
ck.setCid(cid);
ck.setFlag(1);
context.write(ck, value);
}
}
}
ReduceJoinMapper.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.reduce; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException;
import java.util.Iterator; public class ReduceJoinReducer extends Reducer<CompKey, Text, Text, NullWritable> { /**
* 通过
* oid orderno price cid
* 8 no008 6.0 1
* <p>
* 得到
* cid cname orderno price
* 1 tom no008 6.0
*/
@Override
protected void reduce(CompKey key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //初始化迭代器
Iterator<Text> it = values.iterator(); //将while指针指向第一条之后
String cust = it.next().toString(); //继上一条之后读取
while(it.hasNext()){
String[] arr = it.next().toString().split("\t");
String orderno = arr[1];
String price = arr[2];
String newLine = cust.toString() + "\t" + orderno + "\t" + price;
context.write(new Text(newLine), NullWritable.get()); }
}
}
ReduceJoinReducer.java 文件内容
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.join.reduce; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class ReduceJoinApp { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(ReduceJoinApp.class);
job.setJobName("Reduce-Join");
job.setMapperClass(ReduceJoinMapper.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setGroupingComparatorClass(MyGroupingComparator.class);
//map的输出k-v
job.setMapOutputKeyClass(CompKey.class);
job.setMapOutputValueClass(Text.class); //reduce的k-v
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); //指定输入的文件路径
FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\input\\"));
//指定输出的文件路径
Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\output");
if (fs.exists(outPath)){
fs.delete(outPath);
}
FileOutputFormat.setOutputPath(job,outPath); job.setNumReduceTasks(2);
job.waitForCompletion(true);
}
}
ReduceJoinApp.java 文件内容
以上代码执行结果如下:(输出路径)
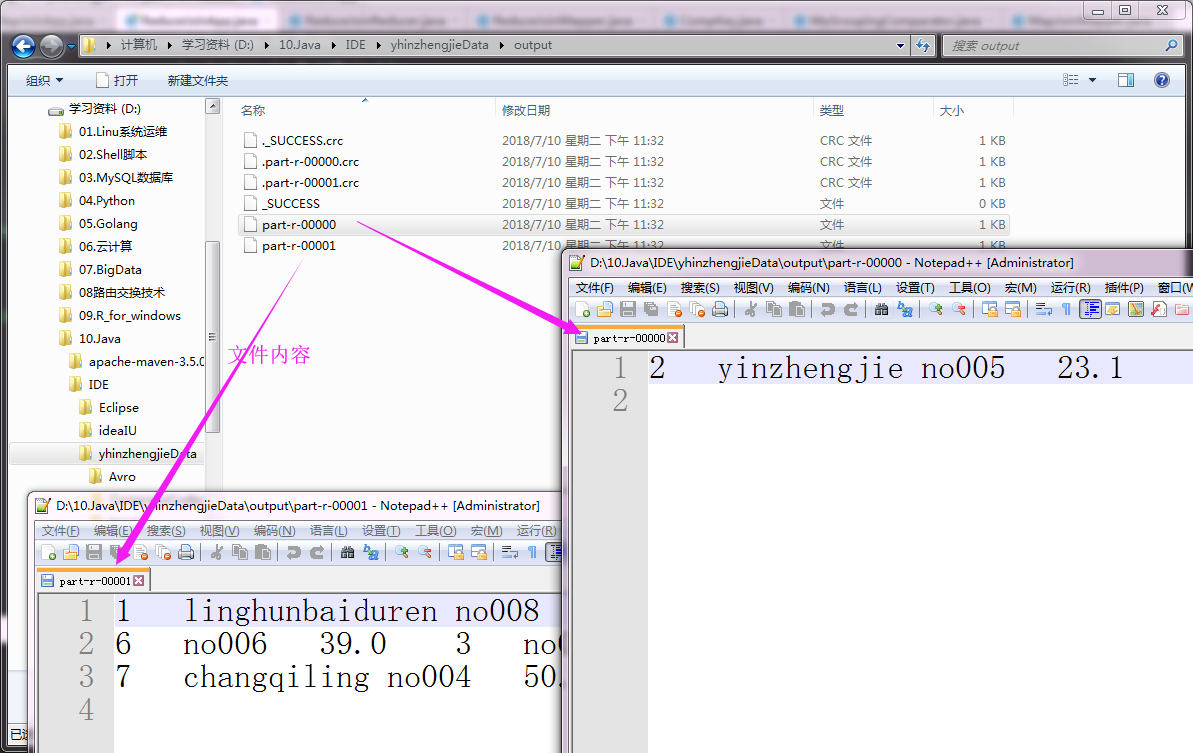
Hadoop基础-MapReduce的Join操作的更多相关文章
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-通过IO流操作HDFS
Hadoop基础-通过IO流操作HDFS 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.上传文件 /* @author :yinzhengjie Blog:http://www ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
随机推荐
- libgdx学习记录19——图片动态打包PixmapPacker
libgdx中,opengl 1.x要求图片长宽必须为2的整次幂,一般有如下解决方法 1. 将opengl 1.x改为opengl 2.0.(libgdx 1.0版本后不支持1.x,当然不存在这个问题 ...
- Elasticsearch Query DSL 整理总结(一)—— Query DSL 概要,MatchAllQuery,全文查询简述
目录 引言 概要 Query and filter context Match All Query 全文查询 Full text queries 小结 参考文档 引言 虽然之前做过 elasticse ...
- 使用Redis做分布式
一 为什么使用 Redis 在项目中使用 Redis,主要考虑两个角度:性能和并发.如果只是为了分布式锁这些其他功能,还有其他中间件 Zookpeer 等代替,并非一定要使用 Redis. 性能: 如 ...
- 真机调试傻瓜图文教程(Xcode6.4)
先准备好99刀,真机调试才带你玩. PS:万能宝十来块钱可以买个资格... Developer Apple上的设置 1.打开https://developer.apple.com/,点击Member ...
- 配置LNPM
在 Ubuntu 系统中,可以使用 apt-get 命令来搭建 LNMP环境.这种方式较编译方式安装更加简便,因此选择使用该方式来搭建环境以供学习. 安装Nginx 使用 sudo apt-get i ...
- 算法(JAVA)----两道小小课后题
LZ最近翻了翻JAVA版的数据结构与算法,无聊之下将书中的课后题一一给做了一遍,在此给出书中课后题的答案(非标准答案,是LZ的答案,猿友们可以贡献出自己更快的算法). 1.编写一个程序解决选择问题.令 ...
- Js_特效II
字号缩放 让文字大点,让更多的用户看的更清楚.(也可以把字体变为百分比来实现)<script type="text/javascript"> function doZ ...
- 用 IIS 搭建 mercurial server
mercurial server 对于代码管理工具,更多的人可能对 Git 更熟悉一些(Git太火了).其实另外一款分布式代码管理工具也被广泛的使用,它就是 mercurial.当多人协作时最好能够通 ...
- mui框架(三)
1.Ajax-get请求 // get测试请求地址 http://test.dongyixueyuan.com/link_app/get?state=index&num=0 mui.get(' ...
- 《Linux 内核分析》第五周
[李行之原创作品 转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000] <Linux内 ...