Yale数据库上的人脸识别
一、问题分析
1. 问题描述
在Yale数据集上完成以下工作:在给定的人脸库中,通过算法完成人脸识别,算法需要做到能判断出测试的人脸是否属于给定的数据集。如果属于,需要判断出测试的人脸属于数据集中的哪一位。否则,需要声明测试的人脸不属于数据集。
2. 数据集分析
Yale人脸数据集由耶鲁大学创建,包含15个人,每个人有不同表情、姿态和光照下的11张人脸图像,共165张图片,每张图片大小为100*100。整个数据集非常小,图片信息也较为简单。
如图1所示,数据集中人脸数据已经标定,因此这并不是传统意义上的人脸识别任务,而是一个简单的图像多分类问题。另外,每个人包含了在不同表情、光照下的人脸图像,这就要求我们提取的图像特征要具有光照不敏感性,能够很好得体现人脸的轮廓信息。
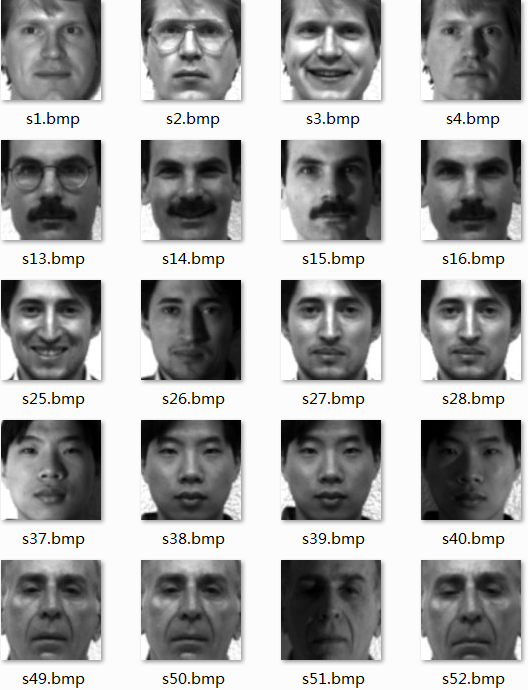
图 1 Yale数据集示例
3. 特征提取
神经网络:在图像多分类任务中,如今前沿的方法都是采用深度神经网络来学习图像数据,从而训练得到一个多分类模型,例如ResNet[1]可以在大规模数据集ImageNet上达到3.57%的top5 error。在基于海量数据的前提下,神经网络已经被证明了可以很好得提取图像特征,然而由于Yale数据集非常小,只有165张图片,因此不适用于神经网络中。
PCA: PCA[2]即主成分分析。在原始数据中,很多维度间具有较大的相关系数,PCA旨在利用降维的思想,把多指标转化为少数几个综合指标。但PCA可能会忽略贡献率小的主成分,这种成分往往可能含有对样本差异的重要信息,从而使得分类结果出现误差。
SIFT:SIFT[3]特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性,且独特性好,信息量丰富,适用于海量特征库进行快速、准确的匹配。而由于Yale数据量少,SIFT难以达到理想的效果。
HOG: HOG[4]即方向梯度直方图特征,通过计算和统计图像局部区域的梯度方向直方图来构成特征。由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光照变化都能保持很好的不变性,因此非常适用于具有不同光照情况的Yale数据集上。另外,HOG特征包含了图像边缘的梯度方向和梯度信息,能够很好得对人脸轮廓、五官信息进行表达。
综合以上分析,在本实验中我们选择了HOG来提取图像的特征信息。
4. 分类方法
常用的分类方法包括K近邻、SVM[5]、Softmax等。K近邻实现较为简单,但是在预测时计算复杂度较高,因此现在已经很少采用这个分类模型;SVM在训练时确保正样本和负样本之间的间距大于某个阈值,对于正样本尽可能给与更高的置信度,然而在多分类SVM中,负样本的得分并不具有对应的概率意义;Softmax是逻辑回归在多分类上的扩展,针对每一个类别都给出了其对应的概率得分。Softmax在训练时总是力求最大化正样本的概率,最小化其他负样本的概率,因此输出值可以用来表示样本属于每个类的概率。
在本次实验中,我们需要判定噪声集中的数据是否属于数据库,算法实现的核心思想要求模型能够输出对应每个类别的概率。而由于Softmax在类别得分上比SVM有更高的置信度,因此在本次实验中,我们采用HOG+Softmax的模型对实现人脸识别任务。
二、模型
1. HOG特征
方向梯度直方图(Histogram of Oriented Gradient, HOG),是一种用于表征图像局部梯度方向和梯度强度分布特性的描述符。在一副图像中,局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述。HOG特征对于图像几何的和光学的形变都能保持很好的不变性。
HOG特征提取分为以下几个步骤:
(1) 色彩和伽马归一化,减少光照因素的影响;
(2) 计算图像横坐标和纵坐标方向的梯度方向和梯度幅值;
(3) 利用细胞单元的梯度信息构建梯度直方图;
(4) 将每个block下的细胞单元组合起来,并对梯度直方图归一化;
(5) 收集HOG特征,将整幅图的block特征向量整合成一个特征向量。
HOG特征提取流程图如图2所示:
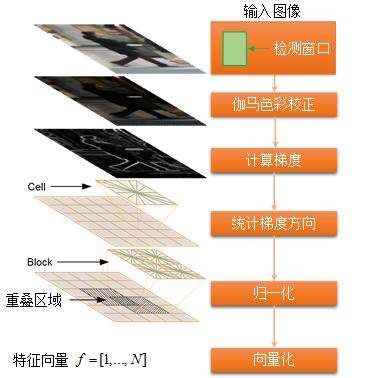
图 2 HOG特征提取流程图
2. Softmax
Softmax用于多分类过程中,当给定图像数据,以W为参数,分配给正确分类标签的Softmax函数值(归一化概率)如下:

Softmax函数的输入值是一个向量,向量中元素为任意实数的评分值,函数对其进行压缩,输出一个向量,其中每个元素值在0到1之间,可以等同于每个类对应的概率值,且所有元素之和为1,从而来进行多分类。
3. HOG+Softmax
实验中,我们采用HOG+Softmax的方法对人脸识别问题进行建模。模型如图3所示,我们首先提取人脸图像的HOG特征,再将这些HOG特征送入Softmax中进行训练。在训练完成后,对于每个输入,我们可以得到其对应的多个分类概率值,再通过判定其中的最大概率值是否小于阈值,如果小于,则判定为不属于数据集;否则,输出其对应的ground-truth。
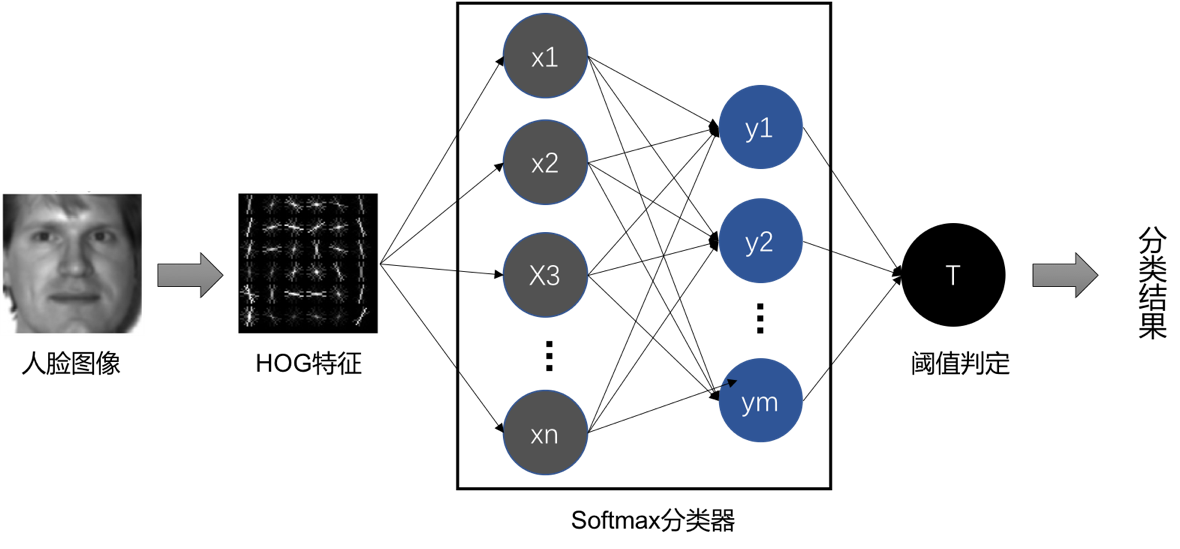
图 3 HOG+Softmax模型图
三、实验
本次实验利用python实现,主要用到的核心库包括scikit-learn、scikit-image和openCV等,特征提取和分类都是直接使用这些库去实现。实验中首先对Yale数据集进行预处理并提取HOG特征,然后利用K折交叉验证搜索模型得到符合条件的最优阈值,最后用这个模型测定在数据集和噪声集上的表现情况。实验代码已在github上开源:https://github.com/CStianya/Yale-FaceRecognition。
1. 数据集处理
我们首先利用openCV读取Yale数据库,因其命名符合一定的规范,通过简单的字符串处理后,我们可以得到每个数据对应的标签信息。Yale数据库共有165张图片,包含15个类,每个类11张图片。我们按4:1的比例将数据库划分为数据集和噪声集,其中数据集包含1-12类样本,噪声集包含13-15类样本。训练时以3:1的比例进一步将数据集划分为训练集和测试集,以确保模型的泛化能力,另外噪声集的标签在训练期间是不会出现的。
我们利用scikit-image库中的hog函数提取数据的HOG特征,cell大小是16*16,block大小为1*1,采用的归一化方式是“L2-Hys”,共有8个bins。提取到的HOG特征具有288个维度,其特征图可视化结果如图4所示:
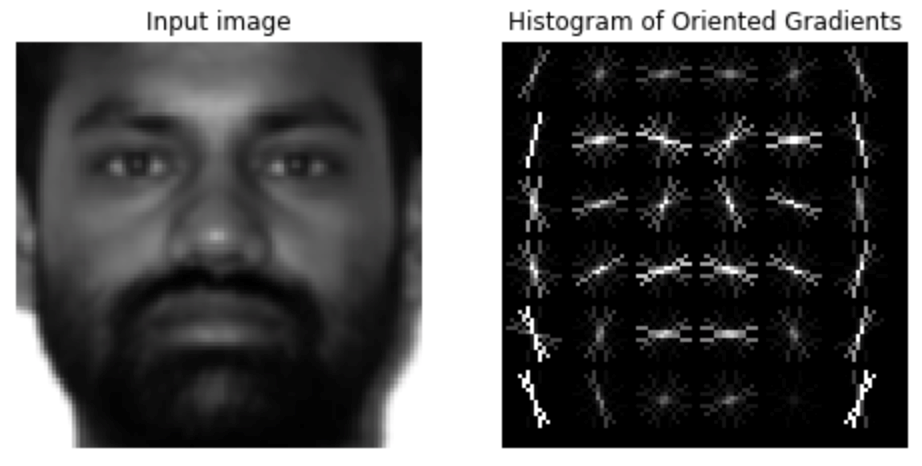
图 4 人脸图像的HOG特征图
2. 实验结果
实验中我们采用重复K折交叉训练来搜索模型的最优阈值。我们要观测的指标是模型在测试集上的ground-truth所对应的最小概率值α以及在噪声集上的最大概率值β。通过改变参数K和重复次数n的值,我们得到模型对应的α和β指标结果如表1所示。
通过表1可以发现,当K=4,n=6时,模型α指标为0.3497,β指标为0.3209,满足α>β。因此我们选择其中间值0.33作为阈值。
表 1 不同参数下模型的α指标(左)和β指标(右)
|
2 |
3 |
4 |
||||
|
1 |
0.2141 |
0.2926 |
0.2194 |
0.2886 |
0.2356 |
0.2825 |
|
2 |
0.1763 |
0.2831 |
0.1679 |
0.2938 |
0.2263 |
0.3897 |
|
3 |
0.1475 |
0.3070 |
0.1651 |
0.3181 |
0.1806 |
0.3195 |
|
4 |
0.1479 |
0.3918 |
0.1768 |
0.3704 |
0.2179 |
0.3542 |
|
5 |
0.1737 |
0.3467 |
0.1894 |
0.3044 |
0.2385 |
0.3219 |
|
6 |
0.2271 |
0.3339 |
0.3259 |
0.3261 |
0.3497 |
0.3209 |
基于上述模型以及0.33的阈值设定,我们评价了模型在测试集和噪声集上的acc_class指标和err_in指标。其中acc_class为分类的准确度,err_in为判断样本是否在数据集中的的错误率。实验结果如表2所示。
从表2中可以看出,HOG+Softmax模型可以在噪声集上达到0%的错误率,这意味着对于噪声集的所有数据,模型都能够判定其不在数据集里;另外,模型在测试集上也达到了100%的acc_class。实验结果表明HOG+Softmax模型可以很好的权衡acc_class和err_in两个指标,且在Yale数据库上同时达到了最优的表现情况。
表 2 测试集和噪声集上的acc_class和err_in表现
|
acc_class(%) |
err_in(%) |
|
|
测试集 |
100 |
0 |
|
噪声集 |
100 |
0 |
为了使实验结果更为直观、便于理解,我们利用QT库制作了一个模型demo,分别测试了模型在数据集和噪声集上的预测情况。预测结果如图5和图6所示。
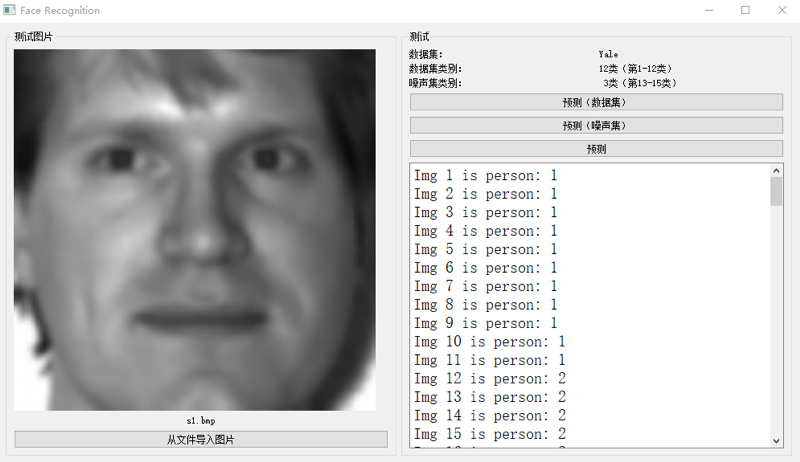
图 5 数据集上的预测情况
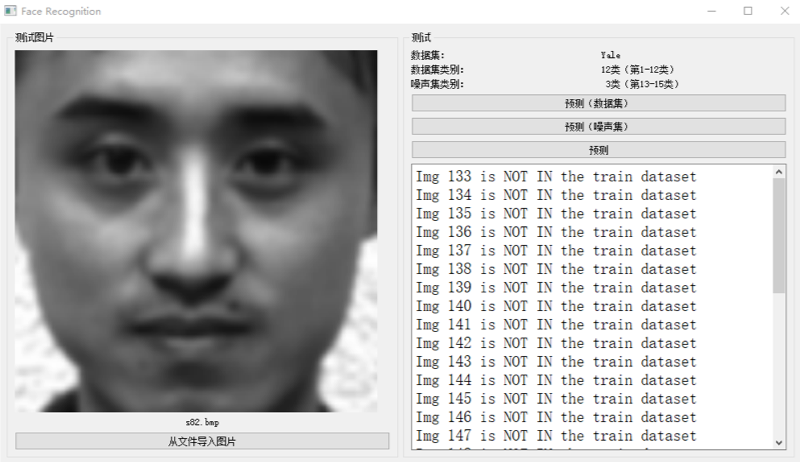
图 6 噪声集上的预测情况
四、总结
在实验中,我们采用HOG+Softmax的模型解决了Yale数据库上的人脸识别问题,在测试集和噪声集上都达到了最优的表现情况,证明了该模型的有效性和先进性。当然,模型还存在的一定的问题,实验中为了解决噪声集的判别问题,我们引入了阈值的设定,这导致每次噪声集的类别改变后,我们都需要重新搜索得到一个阈值;此外,由于Yale数据量实在太小,模型很容易就达到了100%的准确度,这也会造成过拟合问题。
总而言之,我们的模型在Yale上的人脸识别任务还是达到了非常优异的表现。这次实验也让我们的编码能力和团队协作能力得到了很大的提升。
参考文献
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, et al. Deep Residual Learning for Image Recognition[J]. 2015:770-778.
[2] Wold S, Esbensen K, Geladi P. Principal component analysis[J]. Chemometrics & Intelligent Laboratory Systems, 1987, 2(1):37-52.
[3] Lowe D G. Distinctive Image Features from Scale-Invariant Keypoints[C]// International Journal of Computer Vision. 2004:91-110.
[4] Dalal, Navneet, Triggs, et al. Histograms of Oriented Gradients for Human Detection[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2005:886-893.
[5] Adankon M M, Cheriet M. Support Vector Machine[J]. Computer Science, 2002, 1(4):1-28.
Yale数据库上的人脸识别的更多相关文章
- 在Ubuntu上实现人脸识别登录
安装Howdy: howdy项目地址 sudo add-apt-repository ppa:boltgolt/howdy sudo apt update sudo apt install howdy ...
- 使用OpenCV进行人脸识别
不断维护的地址:http://plzcoding.com/face-recognition-with-opencv/ 怎样使用OpenCV进行人脸识别 本文大部分来自OpenCV官网上的Face Re ...
- Python 3 利用 Dlib 19.7 实现摄像头人脸识别
0.引言 利用python开发,借助Dlib库捕获摄像头中的人脸,提取人脸特征,通过计算欧氏距离来和预存的人脸特征进行对比,达到人脸识别的目的: 可以自动从摄像头中抠取人脸图片存储到本地: 根据抠取的 ...
- 第三十七节、人脸检测MTCNN和人脸识别Facenet(附源码)
在说到人脸检测我们首先会想到利用Harr特征提取和Adaboost分类器进行人脸检测(有兴趣的可以去一看这篇博客第九节.人脸检测之Haar分类器),其检测效果也是不错的,但是目前人脸检测的应用场景逐渐 ...
- python中使用Opencv进行人脸识别
上一节讲到人脸检测,现在讲一下人脸识别.具体是通过程序采集图像并进行训练,并且基于这些训练的图像对人脸进行动态识别. 人脸识别前所需要的人脸库可以通过两种方式获得:1.自己从视频获取图像 2.从人 ...
- 免费人脸识别APi
今天对应一些免费的人脸识别的api 做了一下简单的对比,觉得百度开发出来的人脸识别接口还是最符合的我的要求,简单易用,容易上手. 据说百度的一些门禁也使用上了人脸识别的功能了,功能很强大,而且能识别出 ...
- OpenCV+python 人脸识别
首先给大家推荐一本书:机器学习算法原理与编程实践 本文内容全部转载于书中,相当于一个读书笔记了吧 绪论 1992年麻省理工学院通过实验对比了基于结构特征的方法与基于模版匹配的方法,发现模版匹配的方法要 ...
- 使用 HTML5, javascript, webrtc, websockets, Jetty 和 OpenCV 实现基于 Web 的人脸识别
这是一篇国外的文章,介绍如何通过 WebRTC.OpenCV 和 WebSocket 技术实现在 Web 浏览器上的人脸识别,架构在 Jetty 之上. 实现的效果包括: 还能识别眼睛 人脸识别的核心 ...
- 人脸识别FaceNet+TensorFlow
一.本文目标 利用facenet源码实现从摄像头读取视频,实时检测并识别视频中的人脸.换句话说:把facenet源码中contributed目录下的real_time_face_recognition ...
随机推荐
- JavaScript利用Date实现简单的倒计时实例
介绍 Date对象,是操作日期和时间的对象.Date对象对日期和时间的操作只能通过方法.Date在js中和Array类似,都是拥有自己的特殊方法的特殊对象. 创建 Date 对象的语法: var my ...
- python第三十九课——面向对象(二)之设计类
1.设计类class 车: #属性 颜色 = red 品牌 = "BMW" 车牌 = "沪A88888" #函数 行驶(): 停止(): 2.实例化车对象 ca ...
- CF838D Airplane Arrangements
传送门:https://www.luogu.org/problemnew/show/CF838D 这道题反正我自己想是毫无头绪,最后还是听了肖大佬的做法. 因为题中说乘客可以从前后门进来,所以我们可以 ...
- Eclipse Mars 2安装Drools6.4插件(Drools and jBPM tools)时无法安装JBoss Runtime Drools Detector
在eclipse上本地安装Drools6.4Final的时候出现两个组件无法正常安装的情况,具体组件如下: 具体的提示信息为: Cannot complete the install because ...
- [转]VS2015+OpenCV3.3 GPU模块和opencv_contrib模块的编译以及采用CMake编译opencv_contrib时提示“No extra modules found in folder”问题的解决方案
据官方说法,目前还不是太稳定的算法模块都在opencv_contrib里边,由于不稳定,所以不能在release版本里发行,只有在稳定以后才会放进release里边.但是这里边有很多我们经常要用的算法 ...
- nginx下No input file specified错误的解决
在web服务的根目录下创建 .htaccess文件,设置一下内容: RewriteEngine on RewriteCond %{REQUEST_FILENAME} !-d RewriteCond % ...
- python在输出一段话中插入多个变量,每日作业补充
%s用来插入用户输入的值name=input('请输入您的姓名:')age=input('请输入您的年龄:')sex=input('你的性别:')print('-------您好!%s------\n ...
- 2017-2018-2 20155203《网络对抗技术》 Exp7:网络欺诈防范
1.基础问题回答 (1)通常在什么场景下容易受到DNS spoof攻击 连接无线网络,和恶意攻击者处在同一局域网下. (2)在日常生活工作中如何防范以上两攻击方法 首先决不去点击浏览器都认为不安全的网 ...
- 20155310 《网络攻防》Exp4 恶意代码分析
20155310 <网络攻防>Exp4 恶意代码分析 基础问题 1.如果在工作中怀疑一台主机上有恶意代码,但只是猜想,所有想监控下系统一天天的到底在干些什么.请设计下你想监控的操作有哪些, ...
- PostgreSQL基础知识与基本操作索引页
磨砺技术珠矶,践行数据之道,追求卓越价值 返回顶级页:PostgreSQL索引页 luckyjackgao@gmail.com 本页记录所有本人所写的PostgreSQL的基础知识和基本操作相关文摘和 ...