Redis高可用之集群配置(六)
0、Redis目录结构
5)Redis高可用之哨兵模式Sentinel配置与启动(五)
一、介绍
上篇文章中介绍了redis的主从复制,但是如果出从复制无法满足单节点故障问题,则需要引入集群部署。
在之前有看到过redis集群部署的三种方案,不过性能最高的还是redis官方推荐的redis-cluster,性能最高,其他两种我就不介绍了,主要介绍一下redis-cluster这种。
1、redis-cluster
A、采用去中心化的思想,没有中心节点的说法,它使用hash slot方式将16348个hash slot覆盖到所有节点上,对于存储的每个key值,使用CRC16(KEY)&16348=slot得到他对应的hash slot,
并在访问key的时候就去找他的hash slot在哪一个节点上,然后由当前访问节点从实际被分配了这个hash slot的节点去取数据,节点之间使用轻量协议通信 减少带宽占用 性能很高,
自动实现负载均衡与高可用,自动实现failover并且支持动态扩展,官方已经玩到可以1000个节点 实现的复杂度低。
B、其内部中也需要配置主从,并且内部也是采用哨兵模式,如果有半数节点发现某个异常节点,共同决定更改异常节点的状态,如果改节点是主节点,则对应的从节点自动顶替为主节点,当原先的主节点上线后,则会变为从节点。
如果集群中的master没有slave节点,则master挂掉后整个集群就会进入fail状态,因为集群的slot映射不完整。如果集群超过半数以上的master挂掉,无论是否有slave,集群都会进入fail状态。
C、根据官方推荐 集群部署至少要3台以上的master节点。那么接下来就开始部署吧
二、集群部署
1、环境配置
第一:准备3台服务器,每台服务器运行两个redis
| 主机说明 | 主机IP | 端口 |
| Redis |
192.168.250.129 |
7000 7001 |
| Redis | 192.168.250.130 |
7002 7003 |
| Redis |
192.168.250.131 |
7004 7005 |
2、在每一台服务器上我们添加一下配置文件
分别为:redis-7000.conf redis-7001.conf redis-7002.conf redis-7003.conf redis-7004.conf redis-7005.conf
配置文件内容为如下:其他的配置文件修改一下端口以及log文件、日志文件即可。其中中间部分cluster代表集群设置
- daemonize yes
- port
- logfile .log
- dir ./
- bind 192.168.250.129 127.0.0.1
- cluster-enabled yes
- cluster-config-file nodes_7000.conf
- cluster-node-timeout
- appendonly yes
- appendfilename aof-.aof
- appendfsync everysec
- no-appendfsync-on-rewrite yes
- auto-aof-rewrite-percentage
- auto-aof-rewrite-min-size 64mb
3、上面文件都配置好后,即可启动

4、启动后我们就可以创建集群啦
注意:
在redis5.0后 创建集群统一使用redis-cli,之前的版本使用redis-trib.rb,但是需要安装ruby软件相对复杂,相比之前的版本5.0不需要安装额外的软件,方便。具体的可以参照redis官方网站查看
https://redis.io/topics/cluster-tutorial
创建集群命令:其中 cluster-replicas 1 代表 一个master后有几个slave,1代表为1个slave节点
- ./src/redis-cli --cluster create 192.168.250.129: 192.168.250.129: 192.168.250.130: 192.168.250.130: 192.168.250.131: 192.168.250.131: --cluster-replicas
等待集群创建成功,发现 7000/7002/7004为master主节点,其他的为slave。
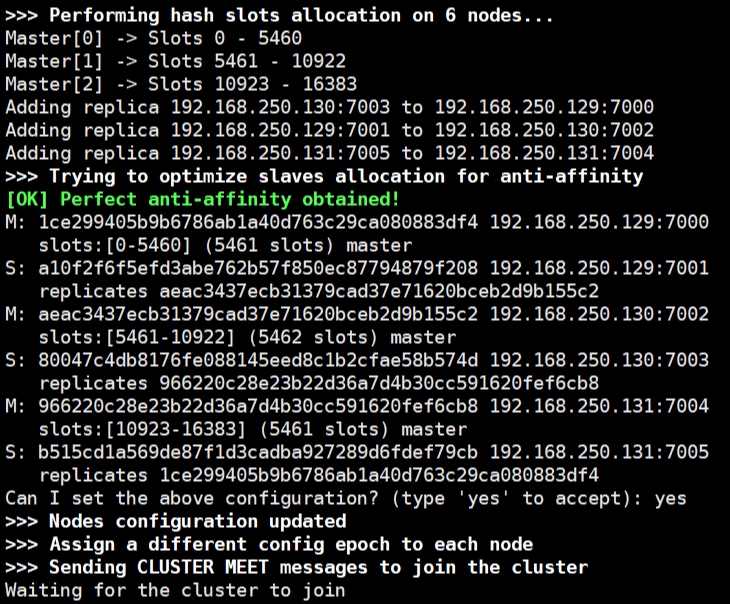
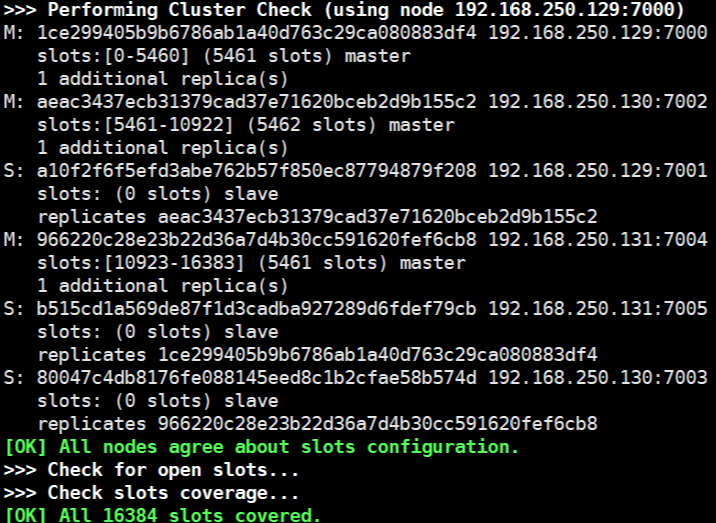
5、我们验证一下集群是否创建成功
登录redis客户端 ./src/redis-cli -c -p 7000, -c 参数代表连接到集群中
我们先看一下主从配对情况,根据node ID匹配可以得出配比。如下:红色圈出来的为标注,大家可以看看是否有对应的ID,这样我们就区分了主从节点的关系了。

验证数据匹配是否采用哈希槽的方式。大家可自行测试一下。发现我在7000客户端设置的数据,被分配到7002上了。

我们查看一下key 为 wangjing,发现定位到了7002

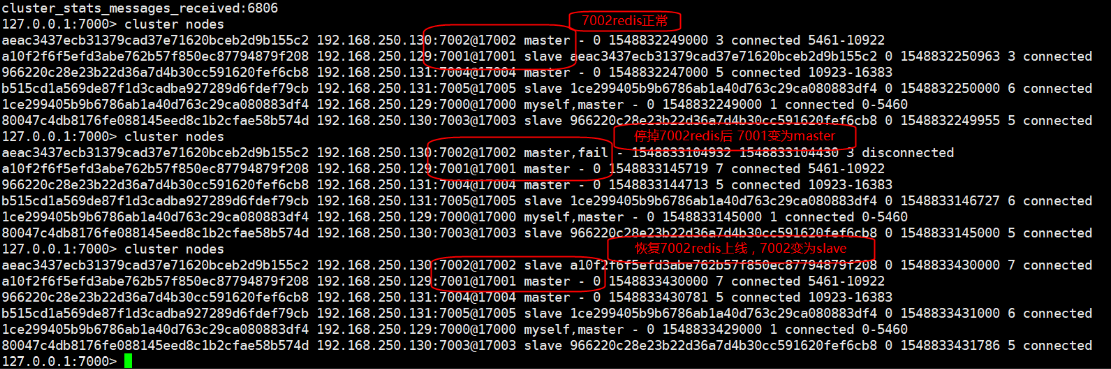
6、我们验证一下故障转移
我们从上面可以看出7002为master,7001为其从节点。我们按照如下流程进行操作
先停掉7002,发现7001转为了master节点,然后恢复7002上线,7002变为slave节点。
那么redis集群演示就到此为止吧。
后面还涉及到 集群新增节点(包括master和slave)以及删除节点,这些操作大家自行操作吧,俗话说 师父领进门修行在个人。大家加油。
大家如果有问题欢迎提问,谢谢。
asp.net core 交流群: 欢迎加群交流
如果您认为这篇文章还不错或者有所收获,您可以点击右下角的【推荐】按钮精神支持,因为这种支持是我继续写作,分享的最大动力!
微信公众号:欢迎关注 QQ技术交流群: 欢迎加群


Redis高可用之集群配置(六)的更多相关文章
- Redis高可用复制集群实现
redis简单介绍 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库.Redis 与其他 key - value 缓存产品有以下三个特点: 支持数据的持久化,可以将 ...
- redis高可用分布式集群
一,高可用 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响. 停止服务的原因可能由于网卡.路由器.机房.CPU负载过高.内存溢出.自然灾害等不可预期的原 ...
- Redis 高可用分布式集群
一,高可用 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响. 停止服务的原因可能由于网卡.路由器.机房.CPU负载过高.内存溢出.自然灾害等不可预期的原 ...
- Redis高可用及集群
目录 Redis主从复制 环境准备 主从复制命令 Redis Sentinel 功能 Redis Sentinel配置 Redis集群 Redis主从复制 使用异步复制 一个服务器可以有多个从服务器 ...
- Eureka单机高可用伪集群配置
Eureka Server高可用集群理论上来讲,因为服务消费者本地缓存了服务提供者的地址,即使Eureka Server宕机,也不会影响服务之间的调用,但是一旦新服务上线,已经缓存在本地的服务提供者不 ...
- Redis之高可用、集群、云平台搭建
原文:Redis之高可用.集群.云平台搭建 文章大纲 一.基础知识学习二.Redis常见的几种架构及优缺点总结三.Redis之Redis Sentinel(哨兵)实战四.Redis之Redis Clu ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- 搭建高可用kubernetes集群(keepalived+haproxy)
序 由于单master节点的kubernetes集群,存在master节点异常之后无法继续使用的缺陷.本文参考网管流程搭建一套多master节点负载均衡的kubernetes集群.官网给出了两种拓扑结 ...
随机推荐
- 图像处理之规则裁剪(Resize)
1 图像裁剪 在实际工作中,经常需要根据研究工作要求对图像进行裁剪(Subset Image),按照实际图像分幅裁剪的过程,可以将图像分幅裁剪分为两种类型:规则分幅裁剪(Rectangle Subse ...
- SQL Server 性能优化详解
故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性能表现不错,但随着注册用户的增多,访问速度开始变慢,一些用户开始发来邮件表示抗议,事情变得越来越糟,为了留住用户, ...
- ceilometer主要组件分析
一.Agent 主要有compute agent 和central agent,还有一些其他的agent这里暂时不分析. agent初始化时会动态加载给定namespace的pollster插件,并通 ...
- npm install --save
1. npm install:本地安装 2. npm install -g:全局安装 我们在使用 npm install 安装模块或插件时,有两种命令把它们写入到 package.json 文件中去, ...
- Spring Cloud(十四)Config 配置中心与客户端的使用与详细
前言 在上一篇 文章 中我们直接用了本应在本文中配置的Config Server,对Config也有了一个基本的认识,即 Spring Cloud Config 是一种用来动态获取Git.SVN.本地 ...
- 20155232 2016-2017-3 《Java程序设计》第8周学习总结
20155232 2016-2017-3 <Java程序设计>第8周学习总结 教材学习内容总结 第十四章NIO与NIO2 NIO使用频道来衔接数据结点,在处理数据时,NIO可以让你设定缓冲 ...
- MySQL主从复制部署
前言 MySQL的主从复制是基于二进制日志机制的,需开启二进制日志功能.在具体的配置过程中,需注意主服务器与从服务器均配置唯一ID编号,且从服务器必须设置主服务器的主机名.日志文件名.文件位置等参数. ...
- Spark笔记之累加器(Accumulator)
一.累加器简介 在Spark中如果想在Task计算的时候统计某些事件的数量,使用filter/reduce也可以,但是使用累加器是一种更方便的方式,累加器一个比较经典的应用场景是用来在Spark St ...
- 数据结构笔记之跳表(SkipList)
一.跳表简述 跳表可以看做是一个带有索引的链表,在介绍跳表之前先看一下一个普通的链表,假如当前维护了一个有序的链表: 现在要在这个链表中查找128,因为事先不知道链表中数值的分布情况,我们只能从前到后 ...
- MySQL-存储过程procedure
存储过程:是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行. 1.创建存储过程: -- 创建存储过程 delimiter // create procedure p1( ...