spark1.6.1 on yarn搭建部署
注:本文是建立在hadoop已经搭建完成的基础上进行的。
Apache Spark是一个分布式计算框架,旨在简化运行于计算机集群上的并行程序的编写。该框架对资源调度,任务的提交、执行和跟踪,节点间的通信以及数据并行处理的内在底层操作都进行了抽象。它提供了一个更高级别的API用于处理分布式数据。从这方面说,它与Apache Hadoop等分布式处理框架类似。但在底层架构上,Spark与它们有所不同。
Spark起源于加利福利亚大学伯克利分校的一个研究项目。学校当时关注分布式机器学习算法的应用情况。因此,Spark从一开始便为应对迭代式应用的高性能需求而设计。在这类应用中,相同的数据会被多次访问。该设计主要靠利用数据集内存缓存以及启动任务时的低延迟和低系统开销来实现高性能。再加上其容错性、灵活的分布式数据结构和强大的函数式编程接口,Spark在各类基于机器学习和迭代分析的大规模数据处理任务上有广泛的应用,这也表明了其实用性。
Spark支持四种运行模式。
- 本地单机模式:所有Spark进程都运行在同一个Java虚拟机(Java Vitural Machine,JVM)中。
- 集群单机模式:使用Spark自己内置的任务调度框架。
- 基于Mesos:Mesos是一个流行的开源集群计算框架。
- 基于YARN:即Hadoop 2,它是一个与Hadoop关联的集群计算和资源调度框架。
spark是由Scala语言编写的,但是运行的环境是jvm,所以需要安装JDK
编译过程:Python、java、Scala编写的代码 -> scala编译器编译解释,生成class文件 -> 由jvm负责执行class文件(与java代码执行一致)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处
由于 spark是由Scala语言编写的,所以依赖Scala环境,且由Scala编写的执行代码也需要环境进行编译。
hdfs是作为spark的持久层,所以需要安装Hadoop,同时如果需要配置spark on yarn,则Hadoop需要安装yarn版本的
spark官方详细参数配置手册:http://spark.apache.org/docs/latest/configuration.html
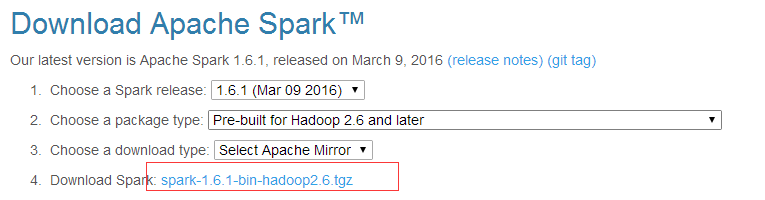
下载地址:http://spark.apache.org/downloads.html
---------------------------------------------------------------------------------------------------------
1、安装Scala
官网下载地址: http://www.scala-lang.org/download/all.html
下载后解压到指定目录,例如 /usr/local/scala
# tar -zxvf scala-2.11.8.tgz ; mv scala-2.11.8 /usr/local/scala
配置环境变量:
# vim /etc/profile
export SCALA_HOME=/usr/local/scala/
export PATH=$SCALA_HOME/bin:$PATH
2、编辑conf/spark-env.sh文件
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=dataMaster30
export SPARK_EXECUTOR_INSTANCES=3
export SPARK_EXECUTOR_CORES=3
export SPARK_EXECUTOR_MEMORY=8g
export SPARK_DRIVER_MEMORY=2g
3、编辑slaves文件
#localhost
dataSlave31
dataSlave32
dataSlave33
dataSlave34
dataSlave35
4、启动spark集群:
/usr/local/spark/sbin/start-all.sh
关闭spark集群:
/usr/local/spark/sbin/stop-all.sh
5、检测是否安装成功:
# jps (Master节点) 此时会多出现一个Master进程
1701 Master
1459 SecondaryNameNode
2242 NameNode
1907 ResourceManage
# jps (Worker节点) 此时会多出现一个Worker进程
5387 Worker
4269 DataNode
4398 NodeManager
执行以下测试命令,查看spark单机运行是否成功:
/usr/local/spark/bin/run-example SparkPi 1000
执行以下测试命令,查看spark集群运行是否成功:
cd /usr/local/spark
./bin/spark-submit --master spark://master60:7077 --class org.apache.spark.examples.SparkPi lib/spark-examples-1.6.1-hadoop2.6.0.jar 1000
如果没有报错的话,则证明spark确实部署成功。
6、查看集群状态:
http://master30:/
最后设置开机自启动:
vim /etc/rc.local
su - hadoop -c "/usr/local/hadoop/sbin/start-all.sh"
su - hadoop -c "/usr/local/spark/sbin/start-all.sh"
spark1.6.1 on yarn搭建部署的更多相关文章
- Spark1.3.1 On Yarn的集群搭建
下面给出的是spark集群搭建的环境: 操作系统:最小安装的CentOS 7(下载地址) Yarn对应的hadoop版本号:Hadoop的Cloudera公司发行版Hadoop2.6.0-CDH5.4 ...
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记 1.环境介绍 (1)操作系统RHEL6.2-64 (2)两个节点:spark1(192.168.232.147),spark2(192 ...
- 云服务器+tomcat+mysql+web项目搭建部署
云服务器+tomcat+mysql+web项目搭建部署 1.老样子,开头墨迹两句. 作为我的第二篇文章,有很多感慨,第一篇人气好低啊,有点小丧气,不过相信我还是经验少,分享的都是浅显的,所以大家可能不 ...
- Ubuntu14.04下Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
不多说,直接上干货! 写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentO ...
- Ubuntu14.04下Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)(在线或离线)
第一步: Cloudera Manager安装之Cloudera Manager安装前准备(Ubuntu14.04)(一) 第二步: Cloudera Manager安装之时间服务器和时间客户端(Ub ...
- nginx Win下实现简单的负载均衡(1)nginx搭建部署
快速目录: 一.nginx Win下实现简单的负载均衡(1)nginx搭建部署 二.nginx Win下实现简单的负载均衡(2)站点共享Session 三.nginx Win下实现简单的负载均衡(3) ...
- zabbix环境搭建部署(一)
Linux高端架构师课程 Linux实战运维国内NO.1全套视频课程 QQ咨询:397824870 > 监控报警 > zabbix环境搭建部署(一) zabbix环境搭建部署(一) 监 ...
- 企业级监控软件zabbix搭建部署之zabbix server的安装
企业级监控软件zabbix搭建部署之zabbix server的安装 zabbix线上已经应用半年多了,关于zabbix在生产环境中的使用心得,以及一些经验写下来,希望让大家少走弯路,共同学习! 环境 ...
- 企业级监控软件Zabbix搭建部署之zabbix在WEB页面中的配置
企业级监控软件zabbix搭建部署之zabbix在WEB页面中的配置 企业级监控软件zabbix搭建部署之zabbix在WEB页面中的配置 关于安装请看 http://www.linuxidc.com ...
随机推荐
- OpenSips使用说明
OpenSips使用说明 安装MYSQL 安装及初始化 下载地址:http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.17-linux-gli ...
- java.util.stream 库简介
Java Stream简介 Java SE 8 中主要的新语言特性是拉姆达表达式.可以将拉姆达表达式想作一种匿名方法:像方法一样,拉姆达表达式具有带类型的参数.主体和返回类型.但真正的亮点不是拉姆达表 ...
- 使用Mongo dump 将数据导入到hive
概述:使用dump 方式将mongo数据导出,上传到hdfs,然后在hive中建立外部表. 1. 使用mongodump 将集合导出 mongodump --host=localhost:27 ...
- 升级Android Studio到1.0.2的问题解决
当前从光网下载到的Android Studio的版本是1.0.1,升级到1.0.2大概是3M的升级包.升级很简单,点击Help--Check For Update... 可是我碰到的情况是提示:Con ...
- 更优雅的使用Git
JavaScript之禅已经发过两篇 Git 相关的文章了.一篇文章,教你学会Git :浅显易懂,如果你还不会 Git 可以先去看看.Git的奇技淫巧 :介绍了一些实用的操作.今天为大家带来第三篇,如 ...
- tp3.2 支付宝手机网站支付
手机网站支付接口,支付宝官方文档:https://b.alipay.com/signing/productSet.htm?navKey=all 第一步: 1)登陆支付宝企业账号 进入支付宝官网 ,登陆 ...
- 快速部署MySQL数据库
一.下载对应的软件版本 下载地址:http://mirrors.sohu.com/mysql/MySQL-5.6/ [root@localhost ~]# wget -q http://mirrors ...
- solr使用cursorMark做深度分页
深度分页 深度分页是指给搜索结果指定一个很大的起始位移. 普通分页在给定一个大的起始位移时效率十分低下,例如start=1000000,rows=10的查询,搜索引擎需要找到前1000010条记录然后 ...
- properties文件读取
package properties; import java.io.FileInputStream; import java.io.FileNotFoundException; import jav ...
- c++引用(修改引用的值)
当我们希望修改某个函数的返回值时,通常我们会返回这个值的引用(因为函数返回值其实是返回那个值得一份拷贝而已,所以想要修改必须使用引用): .h文件 #pragma once #include < ...