flink实时数仓从入门到实战
第一章、flink实时数仓入门
一、依赖
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.dajiangtai</groupId>
<artifactId>learning-flink</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>Flink Quickstart Job</name>
<url>http://www.myorganization.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.6.2</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.10 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.bahir/flink-connector-redis -->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>protobuf-java</artifactId>
<groupId>com.google.protobuf</groupId>
</exclusion>
</exclusions>
</dependency>
<!--************************sql***************************-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-json -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-jdbc -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
<!--************************sql***************************-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.0</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<groupId>com.cloudwise.toushibao</groupId>
<artifactId>simulatedata-generator</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop2</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<configuration>
<scalaCompatVersion>2.11</scalaCompatVersion>
<scalaVersion>2.11.12</scalaVersion>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.dajiangtai.StreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<versionRange>[3.0.0,)</versionRange>
<goals>
<goal>shade</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<versionRange>[3.1,)</versionRange>
<goals>
<goal>testCompile</goal>
<goal>compile</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<!-- This profile helps to make things run out of the box in IntelliJ -->
<!-- Its adds Flink's core classes to the runtime class path. -->
<!-- Otherwise they are missing in IntelliJ, because the dependency is 'provided' -->
<profiles>
<profile>
<id>add-dependencies-for-IDEA</id>
<activation>
<property>
<name>idea.version</name>
</property>
</activation>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
</profile>
</profiles>
</project>
二、Flink DataSet API编程指南
Flink最大的亮点是实时处理部分,Flink认为批处理是流处理的特殊情况,可以通过一套引擎处理批量和流式数据,而Flink在未来也会重点投入更多的资源到批流融合中。我在Flink DataStream API编程指南中介绍了DataStream API的使用,在本文中将介绍Flink批处理计算的DataSet API的使用。通过本文你可以了解:
DataSet转换操作(Transformation)
Source与Sink的使用
广播变量的基本概念与使用Demo
分布式缓存的概念及使用Demo
DataSet API的Transformation使用Demo案例
正文开始hē hē hē hē
1、WordCount示例
在开始讲解DataSet API之前,先看一个Word Count的简单示例,来直观感受一下DataSet API的编程模型,具体代码如下:
public class WordCount {
public static void main(String[] args) throws Exception {
// 用于批处理的执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 数据源
DataSource<String> stringDataSource = env.fromElements("hello Flink What is Apache Flink");
// 转换
AggregateOperator<Tuple2<String, Integer>> wordCnt = stringDataSource
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
for (String word : split) {
out.collect(Tuple2.of(word, 1));
}
}
})
.groupBy(0)
.sum(1);
// 输出
wordCnt.print();
}
}
从上面的示例中可以看出,基本的编程模型是:
获取批处理的执行环境ExecutionEnvironment
加载数据源
转换操作
数据输出
下面会对数据源、转换操作、数据输出进行一一解读。
2、Data Source
DataSet API支持从多种数据源中将批量数据集读到Flink系统中,并转换成DataSet数据集。主要包括三种类型:分别是基于文件的、基于集合的及通用类数据源。同时在DataSet API中可以自定义实现InputFormat/RichInputFormat接口,以接入不同数据格式类型的数据源,比如CsvInputFormat、TextInputFormat等。从ExecutionEnvironment类提供的方法中可以看出支持的数据源方法,如下图所示:
1、基于文件的数据源
readTextFile(path) / TextInputFormat
解释
读取文本文件,传递文件路径参数,并将文件内容转换成DataSet类型数据集。
使用
// 读取本地文件
DataSet<String> localLines = env.readTextFile("file:///path/to/my/textfile");
// 读取HDSF文件
DataSet<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");
readTextFileWithValue(path)/ TextValueInputFormat
解释
读取文本文件内容,将文件内容转换成DataSet[StringValue]类型数据集。该方法与readTextFile(String)不同的是,其泛型是StringValue,是一种可变的String类型,通过StringValue存储文本数据可以有效降低String对象创建数量,减小垃圾回收的压力。
使用
// 读取本地文件
DataSet<StringValue> localLines = env.readTextFileWithValue("file:///some/local/file");
// 读取HDSF文件
DataSet<StringValue> hdfsLines = env.readTextFileWithValue("hdfs://host:port/file/path");
readCsvFile(path)/ CsvInputFormat
解释
创建一个CSV的reader,读取逗号分隔(或其他分隔符)的文件。可以直接转换成Tuple类型、POJOs类的DataSet。在方法中可以指定行切割符、列切割符、字段等信息。
使用
// read a CSV file with five fields, taking only two of them
// 读取一个具有5个字段的CSV文件,只取第一个和第四个字段
DataSet<Tuple2<String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.includeFields("10010")
.types(String.class, Double.class);
// 读取一个有三个字段的CSV文件,将其转为POJO类型
DataSet<Person>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.pojoType(Person.class, "name", "age", "zipcode");
readFileOfPrimitives(path, Class) / PrimitiveInputFormat
解释
读取一个原始数据类型(如String,Integer)的文件,返回一个对应的原始类型的DataSet集合
使用
DataSet<String> Data = env.readFileOfPrimitives("file:///some/local/file", String.class);
2、基于集合的数据源
fromCollection(Collection)
解释
从java的集合中创建DataSet数据集,集合中的元素数据类型相同
使用
DataSet<String> data= env.fromCollection(arrayList);
fromElements(T ...)
解释
从给定数据元素序列中创建DataSet数据集,且所有的数据对象类型必须一致
使用
DataSet<String> stringDataSource = env.fromElements("hello Flink What is Apache Flink");
generateSequence(from, to)
解释
指定from到to范围区间,然后在区间内部生成数字序列数据集,由于是并行处理的,所以最终的顺序不能保证一致。
使用
DataSet<Long> longDataSource = env.generateSequence(1, 20);
3、通用类型数据源
DataSet API中提供了Inputformat通用的数据接口,以接入不同数据源和格式类型的数据。InputFormat接口主要分为两种类型:一种是基于文件类型,在DataSet API对应readFile()方法;另外一种是基于通用数据类型的接口,例如读取RDBMS或NoSQL数据库中等,在DataSet API中对应createInput()方法。
readFile(inputFormat, path) / FileInputFormat
解释
自定义文件类型输入源,将指定格式文件读取并转成DataSet数据集
使用
env.readFile(new MyInputFormat(), "file:///some/local/file");
createInput(inputFormat) / InputFormat
解释
自定义通用型数据源,将读取的数据转换为DataSet数据集。如以下实例使用Flink内置的JDBCInputFormat,创建读取mysql数据源的JDBCInput Format,完成从mysql中读取Person表,并转换成DataSet [Row]数据集
使用
DataSet<Tuple2<String, Integer> dbData =
env.createInput(
JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://localhost/mydb")
.setQuery("select name, age from stu")
.setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO))
.finish()
);
3、Data Sink
Flink在DataSet API中的数据输出共分为三种类型。第一种是基于文件实现,对应DataSet的write()方法,实现将DataSet数据输出到文件系统中。第二种是基于通用存储介质实现,对应DataSet的output()方法,例如使用JDBCOutputFormat将数据输出到关系型数据库中。最后一种是客户端输出,直接将DataSet数据从不同的节点收集到Client,并在客户端中输出,例如DataSet的print()方法。
• writeAsText() / TextOutputFormat:以字符串的形式逐行写入元素。字符串是通过调用每个
元素的toString()方法获得的
• writeAsFormattedText() / TextOutputFormat:以字符串的形式逐行写入元素。字符串是通
过为每个元素调用用户定义的format()方法获得的。
• writeAsCsv(...) / CsvOutputFormat:将元组写入以逗号分隔的文件。行和字段分隔符是可
配置的。每个字段的值来自对象的toString()方法。
• print() / printToErr() / print(String msg) / printToErr(String msg) ()(注: 线上应用杜绝使用,
采用抽样打印或者日志的方式)
• write() / FileOutputFormat
• output()/ OutputFormat:通用的输出方法,用于不基于文件的数据接收器(如将结果存储在
数据库中)。
1、标准的数据输出方法
// 文本数据
DataSet<String> textData = // [...]
// 将数据写入本地文件
textData.writeAsText("file:///my/result/on/localFS");
// 将数据写入HDFS文件
textData.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFS");
// 写数据到本地文件,如果文件存在则覆盖
textData.writeAsText("file:///my/result/on/localFS", WriteMode.OVERWRITE);
// 将数据输出到本地的CSV文件,指定分隔符为"|"
DataSet<Tuple3<String, Integer, Double>> values = // [...]
values.writeAsCsv("file:///path/to/the/result/file", "\n", "|");
// 使用自定义的TextFormatter对象
values.writeAsFormattedText("file:///path/to/the/result/file",
new TextFormatter<Tuple2<Integer, Integer>>() {
public String format (Tuple2<Integer, Integer> value) {
return value.f1 + " - " + value.f0;
}
});
2、使用自定义的输出类型
DataSet<Tuple3<String, Integer, Double>> myResult = [...]
// 将tuple类型的数据写入关系型数据库
myResult.output(
// 创建并配置OutputFormat
JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://localhost/mydb")
.setQuery("insert into persons (name, age, height) values (?,?,?)")
.finish()
);
3、 Flink 写入数据到 ElasticSearch
依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
ElasticSearchSinkUtil 工具类
public class ElasticSearchSinkUtil {
/**
* es sink
*
* @param hosts es hosts
* @param bulkFlushMaxActions bulk flush size
* @param parallelism 并行数
* @param data 数据
* @param func
* @param <T>
*/
public static <T> void addSink(List<HttpHost> hosts, int bulkFlushMaxActions, int parallelism,
SingleOutputStreamOperator<T> data, ElasticsearchSinkFunction<T> func) {
ElasticsearchSink.Builder<T> esSinkBuilder = new ElasticsearchSink.Builder<>(hosts, func);
esSinkBuilder.setBulkFlushMaxActions(bulkFlushMaxActions);
data.addSink(esSinkBuilder.build()).setParallelism(parallelism);
}
/**
* 解析配置文件的 es hosts
*
* @param hosts
* @return
* @throws MalformedURLException
*/
public static List<HttpHost> getEsAddresses(String hosts) throws MalformedURLException {
String[] hostList = hosts.split(",");
List<HttpHost> addresses = new ArrayList<>();
for (String host : hostList) {
if (host.startsWith("http")) {
URL url = new URL(host);
addresses.add(new HttpHost(url.getHost(), url.getPort()));
} else {
String[] parts = host.split(":", 2);
if (parts.length > 1) {
addresses.add(new HttpHost(parts[0], Integer.parseInt(parts[1])));
} else {
throw new MalformedURLException("invalid elasticsearch hosts format");
}
}
}
return addresses;
}
}
Main 启动类
public class Main {
public static void main(String[] args) throws Exception {
//获取所有参数
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
//准备好环境
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
//从kafka读取数据
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
//从配置文件中读取 es 的地址
List<HttpHost> esAddresses = ElasticSearchSinkUtil.getEsAddresses(parameterTool.get(ELASTICSEARCH_HOSTS));
//从配置文件中读取 bulk flush size,代表一次批处理的数量,这个可是性能调优参数,特别提醒
int bulkSize = parameterTool.getInt(ELASTICSEARCH_BULK_FLUSH_MAX_ACTIONS, 40);
//从配置文件中读取并行 sink 数,这个也是性能调优参数,特别提醒,这样才能够更快的消费,防止 kafka 数据堆积
int sinkParallelism = parameterTool.getInt(STREAM_SINK_PARALLELISM, 5);
//自己再自带的 es sink 上一层封装了下
ElasticSearchSinkUtil.addSink(esAddresses, bulkSize, sinkParallelism, data,
(Metrics metric, RuntimeContext runtimeContext, RequestIndexer requestIndexer) -> {
requestIndexer.add(Requests.indexRequest()
.index(ZHISHENG + "_" + metric.getName()) //es 索引名
.type(ZHISHENG) //es type
.source(GsonUtil.toJSONBytes(metric), XContentType.JSON));
});
env.execute("flink learning connectors es6");
/**
DataStream<String> input = ...;
input.addSink(new ElasticsearchSink<>(
config, transportAddresses,
new ElasticsearchSinkFunction<String>() {...},
new ActionRequestFailureHandler() {
@Override
void onFailure(ActionRequest action,
Throwable failure,
int restStatusCode,
RequestIndexer indexer) throw Throwable {
if (ExceptionUtils.containsThrowable(failure, EsRejectedExecutionException.class)) {
// full queue; re-add document for indexing
indexer.add(action);
} else if (ExceptionUtils.containsThrowable(failure, ElasticsearchParseException.class)) {
// malformed document; simply drop request without failing sink
} else {
// for all other failures, fail the sink
// here the failure is simply rethrown, but users can also choose to throw custom exceptions
throw failure;
}
}
}));
**/
}
}
配置文件
kafka.brokers=localhost:9092
kafka.group.id=zhisheng-metrics-group-test
kafka.zookeeper.connect=localhost:2181
metrics.topic=zhisheng-metrics
stream.parallelism=5
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
elasticsearch.hosts=localhost:9200
elasticsearch.bulk.flush.max.actions=40
stream.sink.parallelism=5
配置优化
1、bulk.flush.backoff.enable 用来表示是否开启重试机制
2、bulk.flush.backoff.type 重试策略,有两种:EXPONENTIAL 指数型(表示多次重试之间的时间间隔按照指数方式进行增长)、CONSTANT 常数型(表示多次重试之间的时间间隔为固定常数)
3、bulk.flush.backoff.delay 进行重试的时间间隔
4、bulk.flush.backoff.retries 失败重试的次数
5、bulk.flush.max.actions: 批量写入时的最大写入条数
6、bulk.flush.max.size.mb: 批量写入时的最大数据量
7、bulk.flush.interval.ms: 批量写入的时间间隔,配置后则会按照该时间间隔严格执行,无视上面的两个批量写入配置
3、Flink 写入数据到 Kafka
依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
配置文件
kafka.brokers=xxx:9092,xxx:9092,xxx:9092
kafka.group.id=metrics-group-test
kafka.zookeeper.connect=xxx:2181
metrics.topic=xxx
stream.parallelism=5
kafka.sink.brokers=localhost:9092
kafka.sink.topic=metric-test
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
stream.sink.parallelism=5
代码:
public class Main {
public static void main(String[] args) throws Exception{
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
data.addSink(new FlinkKafkaProducer011<Metrics>(
parameterTool.get("kafka.sink.brokers"),
parameterTool.get("kafka.sink.topic"),
new MetricSchema()
)).name("flink-connectors-kafka")
.setParallelism(parameterTool.getInt("stream.sink.parallelism"));
env.execute("flink learning connectors kafka");
}
}
执行命令可以查看该 topic 的信息:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic metric-test
4、Flink 读取 Kafka 数据批量写入到 MySQL
依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
读取 kafka 数据
package com.zhisheng.connectors.mysql.utils;
import com.zhisheng.common.utils.GsonUtil;
import com.zhisheng.connectors.mysql.model.Student;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* Desc: 往kafka中写数据,可以使用这个main函数进行测试
* Created by zhisheng on 2019-02-17
* Blog: http://www.54tianzhisheng.cn/tags/Flink/
*/
public class KafkaUtil {
public static final String broker_list = "localhost:9092";
public static final String topic = "student"; //kafka topic 需要和 flink 程序用同一个 topic
public static void writeToKafka() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<String, String>(props);
for (int i = 1; i <= 100; i++) {
Student student = new Student(i, "zhisheng" + i, "password" + i, 18 + i);
ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, GsonUtil.toJson(student));
producer.send(record);
System.out.println("发送数据: " + GsonUtil.toJson(student));
Thread.sleep(10 * 1000); //发送一条数据 sleep 10s,相当于 1 分钟 6 条
}
producer.flush();
}
public static void main(String[] args) throws InterruptedException {
writeToKafka();
}
}
写入数据库
依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
MySQL工具类
package com.zhisheng.connectors.mysql.sinks;
import com.zhisheng.connectors.mysql.model.Student;
import org.apache.commons.dbcp2.BasicDataSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.List;
/**
* Desc: 数据批量 sink 数据到 mysql
* Created by zhisheng_tian on 2019-02-17
* Blog: http://www.54tianzhisheng.cn/tags/Flink/
*/
public class SinkToMySQL extends RichSinkFunction<List<Student>> {
PreparedStatement ps;
BasicDataSource dataSource;
private Connection connection;
/**
* open() 方法中建立连接,这样不用每次 invoke 的时候都要建立连接和释放连接
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
dataSource = new BasicDataSource();
connection = getConnection(dataSource);
String sql = "insert into Student(id, name, password, age) values(?, ?, ?, ?);";
ps = this.connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
super.close();
//关闭连接和释放资源
if (connection != null) {
connection.close();
}
if (ps != null) {
ps.close();
}
}
/**
* 每条数据的插入都要调用一次 invoke() 方法
*
* @param value
* @param context
* @throws Exception
*/
@Override
public void invoke(List<Student> value, Context context) throws Exception {
//遍历数据集合
for (Student student : value) {
ps.setInt(1, student.getId());
ps.setString(2, student.getName());
ps.setString(3, student.getPassword());
ps.setInt(4, student.getAge());
ps.addBatch();
}
int[] count = ps.executeBatch();//批量后执行
System.out.println("成功了插入了" + count.length + "行数据");
}
private static Connection getConnection(BasicDataSource dataSource) {
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
//注意,替换成自己本地的 mysql 数据库地址和用户名、密码
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root123456");
//设置连接池的一些参数
dataSource.setInitialSize(10);
dataSource.setMaxTotal(50);
dataSource.setMinIdle(2);
Connection con = null;
try {
con = dataSource.getConnection();
System.out.println("创建连接池:" + con);
} catch (Exception e) {
System.out.println("-----------mysql get connection has exception , msg = " + e.getMessage());
}
return con;
}
}
核心类 Main
public class Main {
public static void main(String[] args) throws Exception{
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
SingleOutputStreamOperator<Student> student = env.addSource(new FlinkKafkaConsumer011<>(
"student", //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props)).setParallelism(1)
.map(string -> GsonUtil.fromJson(string, Student.class)); //
student.timeWindowAll(Time.minutes(1)).apply(new AllWindowFunction<Student, List<Student>, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<Student> values, Collector<List<Student>> out) throws Exception {
ArrayList<Student> students = Lists.newArrayList(values);
if (students.size() > 0) {
System.out.println("1 分钟内收集到 student 的数据条数是:" + students.size());
out.collect(students);
}
}
}).addSink(new SinkToMySQL());
env.execute("flink learning connectors kafka");
}
}
5、Flink读取Kafka 数据写到 RabbitMQ
依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-rabbitmq_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
生产者
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class RabbitMQProducerUtil {
public final static String QUEUE_NAME = "zhisheng";
public static void main(String[] args) throws Exception {
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
//设置RabbitMQ相关信息
factory.setHost("localhost");
factory.setUsername("admin");
factory.setPassword("admin");
factory.setPort(5672);
//创建一个新的连接
Connection connection = factory.newConnection();
//创建一个通道
Channel channel = connection.createChannel();
// 声明一个队列
// channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//发送消息到队列中
String message = "Hello zhisheng";
//我们这里演示发送一千条数据
for (int i = 0; i < 1000; i++) {
channel.basicPublish("", QUEUE_NAME, null, (message + i).getBytes("UTF-8"));
System.out.println("Producer Send +'" + message + i);
}
//关闭通道和连接
channel.close();
connection.close();
}
}
Flink 主程序
import com.zhisheng.common.utils.ExecutionEnvUtil;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;
import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;
/**
* 从 rabbitmq 读取数据
*/
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool parameterTool = ExecutionEnvUtil.PARAMETER_TOOL;
//这些配置建议可以放在配置文件中,然后通过 parameterTool 来获取对应的参数值
final RMQConnectionConfig connectionConfig = new RMQConnectionConfig
.Builder().setHost("localhost").setVirtualHost("/")
.setPort(5672).setUserName("admin").setPassword("admin")
.build();
DataStreamSource<String> zhisheng = env.addSource(new RMQSource<>(connectionConfig,
"zhisheng",
true,
new SimpleStringSchema()))
.setParallelism(1);
zhisheng.print();
//如果想保证 exactly-once 或 at-least-once 需要把 checkpoint 开启
// env.enableCheckpointing(10000);
env.execute("flink learning connectors rabbitmq");
}
}
Sink 数据到 RabbitMQ
public class Main1 {
public static void main(String[] args) throws Exception {
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
final RMQConnectionConfig connectionConfig = new RMQConnectionConfig
.Builder().setHost("localhost").setVirtualHost("/")
.setPort(5672).setUserName("admin").setPassword("admin")
.build();
//注意,换一个新的 queue,否则也会报错
data.addSink(new RMQSink<>(connectionConfig, "zhisheng001", new MetricSchema()));
env.execute("flink learning connectors rabbitmq");
}
}
6、Flink 读取 Kafka 数据写入到 HBase
依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.5</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.8.1</version>
</dependency>
使用flink读取kafka的数据消息
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "node1:9092");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("my-test-topic", new SimpleStringSchema(), properties);
//从最早开始消费
consumer.setStartFromEarliest();
DataStream<String> stream = env.addSource(consumer);
stream.print();
//stream.map();
env.execute();
}
写入hbase
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
@Slf4j
public class HbaseProcess extends ProcessFunction<String, String> {
private static final long serialVersionUID = 1L;
private Connection connection = null;
private Table table = null;
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
try {
// 加载HBase的配置
Configuration configuration = HBaseConfiguration.create();
// 读取配置文件
configuration.addResource(new Path(ClassLoader.getSystemResource("hbase-site.xml").toURI()));
configuration.addResource(new Path(ClassLoader.getSystemResource("core-site.xml").toURI()));
connection = ConnectionFactory.createConnection(configuration);
TableName tableName = TableName.valueOf("test");
// 获取表对象
table = connection.getTable(tableName);
log.info("[HbaseSink] : open HbaseSink finished");
} catch (Exception e) {
log.error("[HbaseSink] : open HbaseSink faild {}", e);
}
}
@Override
public void close() throws Exception {
log.info("close...");
if (null != table) table.close();
if (null != connection) connection.close();
}
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
try {
log.info("[HbaseSink] value={}", value);
//row1:cf:a:aaa
String[] split = value.split(":");
// 创建一个put请求,用于添加数据或者更新数据
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn(Bytes.toBytes(split[1]), Bytes.toBytes(split[2]), Bytes.toBytes(split[3]));
table.put(put);
log.error("[HbaseSink] : put value:{} to hbase", value);
} catch (Exception e) {
log.error("", e);
}
}
}
HbaseSink类
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
@Slf4j
public class HbaseSink implements SinkFunction<String> {
@Override
public void invoke(String value, Context context) throws Exception {
Connection connection = null;
Table table = null;
try {
// 加载HBase的配置
Configuration configuration = HBaseConfiguration.create();
// 读取配置文件
configuration.addResource(new Path(ClassLoader.getSystemResource("hbase-site.xml").toURI()));
configuration.addResource(new Path(ClassLoader.getSystemResource("core-site.xml").toURI()));
connection = ConnectionFactory.createConnection(configuration);
TableName tableName = TableName.valueOf("test");
// 获取表对象
table = connection.getTable(tableName);
//row1:cf:a:aaa
String[] split = value.split(":");
// 创建一个put请求,用于添加数据或者更新数据
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn(Bytes.toBytes(split[1]), Bytes.toBytes(split[2]), Bytes.toBytes(split[3]));
table.put(put);
log.error("[HbaseSink] : put value:{} to hbase", value);
} catch (Exception e) {
log.error("", e);
} finally {
if (null != table) table.close();
if (null != connection) connection.close();
}
}
}
然后修改main方法代码,运行效果一样的。具体区别后续再分析。
// stream.print();
// stream.process(new HbaseProcess());
stream.addSink(new HbaseSink());
7、Flink 读取 Kafka 数据写入到 HDFS
依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.12</artifactId> <version>$</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId> <version>$</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId> <version>$</version>
</dependency>
消费直接存到hdfs
/*
* * Flink consumer topic data and store into hdfs.
* * @author smartloli.
* * Created by Mar 15, 2020
*/
publicclass Kafka2Hdfs { privatestatic Logger LOG = LoggerFactory.getLogger(Kafka2Hdfs.class); publicstaticvoid main(String[] args) {
if (args.length != 3) {
LOG.error("kafka(server01:9092), hdfs(hdfs://cluster01/data/),
flink(parallelism=2) must be exist."); return;
}
String bootStrapServer = args[0]; String hdfsPath = args[1]; int parallelism=Integer.parseInt(args[2]); StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(5000); env.setParallelism(parallelism); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); DataStream<String> transction = env.addSource(new FlinkKafkaConsumer010<>("test_bll_data",new SimpleStringSchema(),configByKafkaServer(bootStrapServer)));
// Storage into hdfs BucketingSink<String> sink = new BucketingSink<>(hdfsPath);
sink.setBucketer(new DateTimeBucketer<String>("yyyy-MM-dd"));
sink.setBatchSize(1024 * 1024 * 1024);
// this is 1GB sink.setBatchRolloverInterval(1000 * 60 * 60); // one hour producer a file into hdfs transction.addSink(sink);
env.execute("Kafka2Hdfs"); }
privatestatic Object configByKafkaServer(String bootStrapServer) { Properties props = new Properties(); props.setProperty("bootstrap.servers", bootStrapServer); props.setProperty("group.id", "test_bll_group"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return props; } }
8、Flink 读取 Kafka 数据写入到 Redis
依赖
dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId> <version>1.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId> <version>1.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId> <version>1.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.9_2.11</artifactId> <version>1.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.10</artifactId> <version>1.1.5</version>
</dependency>
</dependencies>
Redis工具类
packagecom.scn;
import org.apache.flink.api.common.functions.FlatMapFunction;
import
org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class FilnkCostKafka{
public static void main(String[] args)throws Exception {
final StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(1000);
Properties properties= new Properties();
properties.setProperty("bootstrap.servers", "192.168.1.20:9092");
properties.setProperty("zookeeper.connect", "192.168.1.20:2181");
properties.setProperty("group.id","test");
FlinkKafkaConsumer09<String> myConsumer=new FlinkKafkaConsumer09<String>("test",new SimpleStringSchema(),properties);
DataStream<String> stream= env.addSource(myConsumer);
DataStream<Tuple2<String,Integer>> counts= stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
//实例化Flink和Redis关联类FlinkJedisPoolConfig,设置Redis端口
FlinkJedisPoolConfig conf=new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();
//实例化RedisSink,并通过flink的addSink的方式将flink计算的结果插入到redis
counts.addSink(new RedisSink<Tuple2<String, Integer>>(conf,new RedisExampleMapper()));
env.execute("WordCount from Kafka data");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>>
{
privatestaticfinallong serialVersionUID = 1L;
public void flatMap(String value,Collector<Tuple2<String, Integer>>out){String[] tokens= value.toLowerCase().split("\\W+");
for (String token : tokens)
{
if (token.length() > 0)
{
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
//指定Redis key并将flink数据类型映射到Redis数据类型
public static final class RedisExampleMapper implements RedisMapper<Tuple2<String,Integer>>
{
public RedisCommandDescription getCommandDescription()
{
return new RedisCommandDescription(RedisCommand.HSET, "flink");
}
public String getKeyFromData(Tuple2<String, Integer> data)
{
return data.f0;
}
public String getValueFromData(Tuple2<String, Integer> data)
{ return data.f1.toString();
}
}
}
测试运行
package com.scn;
import redis.clients.jedis.Jedis;
public class RedisTest{
public static void main(String args[])
{
Jedis jedis=new Jedis("127.0.0.1");
System.out.println("Server is running: " + jedis.ping());
System.out.println("result:"+jedis.hgetAll("flink"));
} }
9、Flink 读取 Kafka 数据写入到 Flume
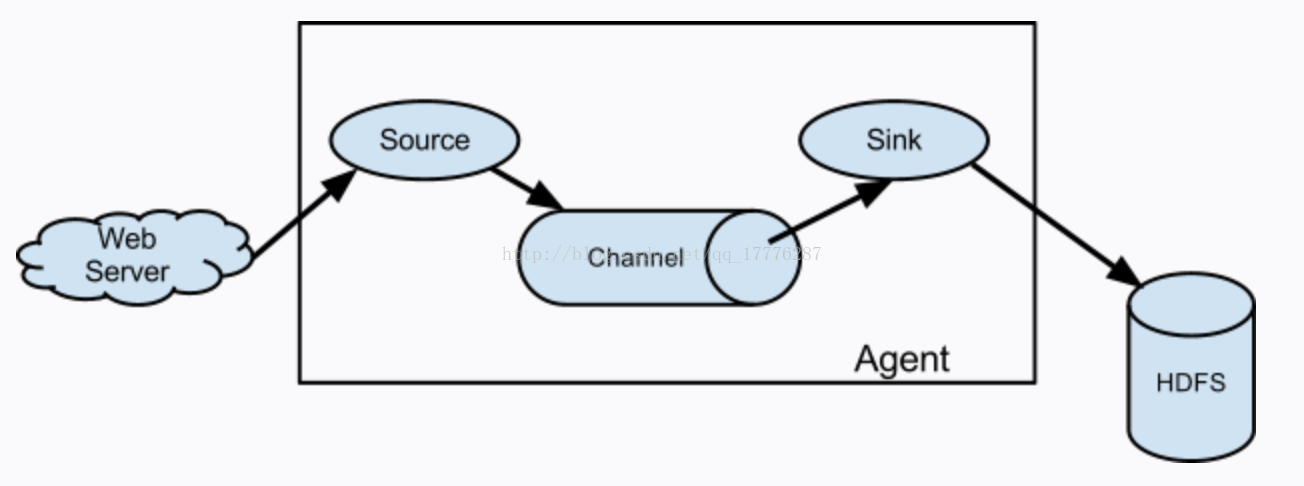
我们将多个Tomcat Server的Web服务器,或者其他的网站服务器都看你而定,没台节点上都配置了Flume Agent,用来收集本地日志目录。然后在另一台节点配置了Flume Consolidation Agent,用来收集各个Web服务器的Flume Agent的数据,然后送入Kafka Cluster。然后Kafka Cluster的数据交由Flink Cluster消费,从而将数据展示在Web前端 flume1
ZooKeeper -server host:port cmd args
#主要作用是监听文件中的新增数据,采集到数据之后,输出到avro
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听文件中的新增数据 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/data-clean/data-access.log
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 9000
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行命令
flume-ng agent --conf conf -n a1 -f 上面这个文件的位置 >/dev/null 2>&1 &
flume2同上,都是一台web服务器
flume3
#主要作用是监听目录中的新增文件,采集到数据之后,输出到kafka
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听avro
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 9000
#对于sink的配置描述 使用kafka做数据的消费
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = f-k-s
a1.sinks.k1.brokerList = 114.116.219.197:5008,114.116.220.98:5008,114.116.199.154:5008
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
#对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-ng agent --conf conf -n a1 -f 上面这个文件的位置 >/dev/null 2>&1 &
flume+kafka+flink的整合
package com.ongbo.hotAnalysis
import java.sql.Timestamp
import java.util.Properties
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
/*
*定义输入数据的样例类
*/
case class UserBehavior(userId: Long, itemId: Long, cateGoryId: Int,behavior: String, timestamp: Long)
//定义窗口聚合结果样例类
case class ItemViewCount(itemId: Long, windowEnd: Long, count: Long)
object HotItems {
def main(args: Array[String]): Unit = {
//1:创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//设置为事件事件
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//2:读取数据
/*kafka源*/
val properties = new Properties()
properties.setProperty("bootstrap.servers","114.116.219.197:5008,114.116.220.98:5008,114.116.199.154:5008")
properties.setProperty("group.id","web-consumer-group")
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset","latest")
val dataStream = env.addSource(new FlinkKafkaConsumer[String]("weblog", new SimpleStringSchema(),properties))
// val dataStream = env.readTextFile("/Users/ongbo/Maven/bin/UserBehaviorAnalysis/HotItemAnalysis/src/main/resources/UserBehavior.csv")
.map(data =>{
System.out.println("data:"+data)
val dataArray = data.split(",")
// if(dataArray(0).equals("ij"))
UserBehavior(dataArray(0).trim.toLong, dataArray(1).trim.toLong, dataArray(2).trim.toInt, dataArray(3).trim, dataArray(4).trim.toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L)
//3:transform处理数据
val processStream = dataStream
//筛选出埋点pv数据
.filter(_.behavior.equals("pv"))
//先对itemID进行分组
.keyBy(_.itemId)
//然后设置timeWindow,size为1小时,步长为5分钟的滑动窗口
.timeWindow(Time.seconds(20), Time.seconds(10))
//窗口聚合
.aggregate(new CountAgg(), new WindowResult())
.keyBy(_.windowEnd) //按照窗口分组
.process(new TopNHotItems(10))
//sink:输出数据
processStream.print("processStream::")
// dataStream.print()
//执行
env.execute("hot Items Job")
}
}
/*自定义预聚合函数*/
class CountAgg() extends AggregateFunction[UserBehavior, Long, Long]{
//累加器初始值
override def createAccumulator(): Long = 0
//每来一次就加一
override def add(in: UserBehavior, acc: Long): Long = acc+1
//
override def getResult(acc: Long): Long = acc
override def merge(acc: Long, acc1: Long): Long = acc + acc1
}
//自定义窗口函数,输出ItemViewCount
class WindowResult() extends WindowFunction[Long,ItemViewCount, Long, TimeWindow]{
override def apply(key: Long, window: TimeWindow, input: Iterable[Long], out: Collector[ItemViewCount]): Unit = {
out.collect(ItemViewCount(key,window.getEnd,input.iterator.next()))
}
}
//自定义处理函数
class TopNHotItems(topsize: Int) extends KeyedProcessFunction[Long, ItemViewCount, String] {
private var itemState: ListState[ItemViewCount] = _
override def open(parameters: Configuration): Unit = {
itemState = getRuntimeContext.getListState(new ListStateDescriptor[ItemViewCount]("item-state", classOf[ItemViewCount]))
}
override def processElement(value: ItemViewCount, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#Context, out: Collector[String]): Unit = {
//把每条数据存入状态列表
itemState.add(value)
//注册一个定时器
ctx.timerService().registerEventTimeTimer(value.windowEnd + 1)
}
//定时器触发时,对所有的数据排序,并输出结果
override def onTimer(timestamp: Long, ctx: _root_.org.apache.flink.streaming.api.functions.KeyedProcessFunction[Long, _root_.com.ongbo.hotAnalysis.ItemViewCount, _root_.scala.Predef.String]#OnTimerContext, out: _root_.org.apache.flink.util.Collector[_root_.scala.Predef.String]): Unit = {
//将所有state中的数据取出,放到一个list Buffer中
val allItems: ListBuffer[ItemViewCount] = new ListBuffer()
import scala.collection.JavaConversions._
for(item <- itemState.get()){
allItems += item
}
//按照点计量count大小排序,sortBy默认是升序,并且取前三个
val sortedItems = allItems.sortBy(_.count)(Ordering.Long.reverse).take(topsize)
//清空状态
itemState.clear()
//格式化输出排名结果
val result : StringBuilder = new StringBuilder
result.append("时间:").append(new Timestamp(timestamp - 1)).append("\n")
//输出每一个商品信息
for(i<- sortedItems.indices){
val currentItem = sortedItems(i)
result.append("No").append(i+1).append(":")
.append(" 商品ID:").append(currentItem.itemId)
.append(" 浏览量:").append(currentItem.count).append("\n")
}
result.append("============================\n")
//控制输出频率
Thread.sleep(1000)
out.collect(result.toString())
}
}
/*自定义预聚合函数计算平均数*/
class AverageAgg() extends AggregateFunction[UserBehavior, (Long,Int), Double]{
override def createAccumulator(): (Long, Int) = (0L,0)
override def add(in: UserBehavior, acc: (Long, Int)): (Long, Int) = (acc._1+in.timestamp, acc._2+1)
override def getResult(acc: (Long, Int)): Double = acc._1 /acc._2
override def merge(acc: (Long, Int), acc1: (Long, Int)): (Long, Int) = (acc._1+acc1._1, acc._2+acc1._2)
}
下面往日志目录里面写日志
543462,1715,1464116,pv,1511658000
662867,2244074,1575622,pv,1511658000
561558,3611281,965809,pv,1511658000
894923,3076029,1879194,pv,1511658000
834377,4541270,3738615,pv,1511658000
315321,942195,4339722,pv,1511658000
625915,1162383,570735,pv,1511658000
578814,176722,982926,pv,1511658000
873335,1256540,1451783,pv,1511658000
429984,4625350,2355072,pv,1511658000
866796,534083,4203730,pv,1511658000
937166,321683,2355072,pv,1511658000
156905,2901727,3001296,pv,1511658000
758810,5109495,1575622,pv,1511658000
107304,111477,4173315,pv,1511658000
452437,3255022,5099474,pv,1511658000
813974,1332724,2520771,buy,1511658000
524395,3887779,2366905,pv,1511658000
470572,3760258,1299190,pv,1511658001
543789,3110556,4558987,cart,1511658001
354759,2191348,4756105,pv,1511658001
382009,2123538,4801426,pv,1511658001
677046,1598945,4145813,pv,1511658001
946161,3021357,1506018,pv,1511658001
464646,2512167,2733371,pv,1511658001
1007641,5046581,2355072,pv,1511658001
723938,4719377,1464116,pv,1511658001
513008,3472922,401357,pv,1511658001
769215,22738,2355072,pv,1511658002
652863,4967749,1320293,pv,1511658002
801610,900305,634390,pv,1511658002
411478,3259235,2667323,pv,1511658002
431664,764155,2520377,pv,1511658002
487768,4125503,2465336,pv,1511658002
223813,4104826,2042400,pv,1511658002
672849,1822977,4801426,fav,1511658002
550127,4602135,65362,pv,1511658002
205752,1467139,171529,pv,1511658002
64419,2029769,2729260,pv,1511658002
756093,2881426,2520377,pv,1511658002
48353,4362292,583014,pv,1511658002
355509,4712764,4082778,pv,1511658003
826492,4016552,2735466,pv,1511658003
624915,2243311,2520377,pv,1511658003
682317,655740,982926,fav,1511658003
677621,1051389,4801426,pv,1511658003
422974,4649255,4818107,pv,1511658003
86512,563566,4756105,pv,1511658003
565218,2331370,3607361,pv,1511658003
232313,4182588,1730376,pv,1511658003
436966,1329977,3607361,cart,1511658003
561158,269170,2342116,fav,1511658003
344379,3318242,2920476,cart,1511658003
858204,2450718,235534,pv,1511658004
833924,3190176,1051370,pv,1511658004
992993,1900968,3794706,fav,1511658004
911930,1150136,2131531,pv,1511658004
736959,319911,4756105,pv,1511658004
82170,3588374,2465336,pv,1511658004
587599,2067643,4818107,cart,1511658004
367451,15775,4756105,pv,1511658004
428316,2478780,4284875,pv,1511658004
284910,3680091,3829657,pv,1511658004
345119,737662,4357323,pv,1511658004
551442,1762997,1879194,pv,1511658004
550384,3908776,1029459,pv,1511658004
677500,4534693,2640118,pv,1511658004
398626,2791489,1467750,pv,1511658004
118053,3545571,2433095,pv,1511658005
457401,4063698,4801426,pv,1511658005
45105,3234847,3141941,fav,1511658005
604760,2661651,3738615,pv,1511658005
905383,2064903,2939262,cart,1511658005
740788,3657484,4936889,pv,1511658005
456838,1242724,4756105,fav,1511658005
585217,215764,2640118,pv,1511658006
658185,4025021,4048584,fav,1511658006
210431,2035568,2328673,pv,1511658006
602619,1838725,2247787,pv,1511658006
860388,3797303,4357323,pv,1511658006
175334,2624960,801221,pv,1511658006
72403,4249007,1320293,pv,1511658006
307385,2551880,4050612,pv,1511658006
819283,2094785,2520377,pv,1511658006
801272,565658,1158475,pv,1511658006
344680,3224461,4789432,pv,1511658006
125206,1102775,622168,pv,1511658006
59131,1960832,154040,pv,1511658006
252339,2455388,3745824,pv,1511658006
794780,4465604,4242717,pv,1511658007
388283,4701157,1457367,pv,1511658007
416261,2101120,1299190,pv,1511658007
231758,3622677,4758477,pv,1511658007
92253,642337,4135185,pv,1511658007
297958,1762578,4801426,pv,1511658007
786771,1940649,1320293,pv,1511658007
789048,3144191,2355072,pv,1511658007
895384,1138468,1602288,pv,1511658007
578800,1324176,4135836,pv,1511658007
886777,4606952,996587,pv,1511658008
364036,2340632,2924150,pv,1511658008
783973,3935641,982926,pv,1511658008
483113,1158047,2030976,pv,1511658008
321087,3987903,149192,fav,1511658008
986762,2704613,4217906,pv,1511658008
1003495,3717164,535180,pv,1511658008
32983,1445878,2030976,pv,1511658008
580912,1837669,4263418,pv,1511658008
498371,980167,3607361,cart,1511658008
14830,3878488,3002561,pv,1511658008
457499,4796667,2355072,pv,1511658008
879381,881945,3004853,pv,1511658008
606403,1404468,781315,pv,1511658008
543832,3007018,2735466,pv,1511658009
824188,161847,4801426,pv,1511658009
750784,4727562,1286537,cart,1511658009
87479,5157294,2158079,pv,1511658009
147730,1278040,4801426,pv,1511658009
865088,3924907,411153,pv,1511658009
1006129,1993506,2939262,pv,1511658009
401750,3127850,2640118,pv,1511658009
501335,2005713,1092085,pv,1511658009
266486,1777124,4672807,cart,1511658009
23125,4680673,1756314,buy,1511658009
309473,3665543,2640118,pv,1511658009
547966,693058,2129666,pv,1511658009
599118,2771420,4159072,pv,1511658010
684544,2335709,1451814,pv,1511658010
130320,2469137,4756105,pv,1511658010
464365,1474058,3794706,pv,1511658010
522088,4170363,149192,pv,1511658010
402626,3244134,4801426,pv,1511658010
19445,2183531,4756105,pv,1511658010
44670,5140156,2131531,fav,1511658010
522815,2092266,2355072,pv,1511658010
105757,4175185,3191556,cart,1511658010
585344,1858802,267209,pv,1511658010
412009,3422566,2355072,pv,1511658010
872433,1984468,2520377,pv,1511658010
463780,3377720,745134,pv,1511658010
359932,5035793,3002561,pv,1511658011
742048,3851196,4051859,pv,1511658011
778656,559998,4874384,pv,1511658011
326402,2103118,846990,pv,1511658011
453328,2158281,2920476,pv,1511658011
362515,1892018,883960,pv,1511658011
763534,2402567,3496816,pv,1511658011
935169,55330,4339722,pv,1511658011
361299,1505783,982926,pv,1511658011
628949,4210587,903809,cart,1511658011
989894,3419383,1474371,fav,1511658012
200517,4670782,4181361,cart,1511658012
664416,2941436,1789614,pv,1511658012
348706,2605837,4163659,pv,1511658012
959846,5083345,479837,pv,1511658012
848070,988062,2342116,pv,1511658012
897594,4298799,4173315,pv,1511658012
951961,1221785,4756105,pv,1511658012
549488,2423996,4022701,pv,1511658012
524655,1925334,2033408,pv,1511658013
738256,496639,3247211,pv,1511658013
778173,1032031,784897,cart,1511658013
990673,1476503,3102419,pv,1511658013
700498,1993845,4173315,pv,1511658013
905860,2369381,1158475,pv,1511658013
893832,1153119,982926,pv,1511658013
602895,3538101,4756105,pv,1511658013
542932,1360737,903809,pv,1511658013
283950,3179868,3171095,pv,1511658013
789348,3841875,737184,pv,1511658013
756750,3534407,4129924,fav,1511658013
196825,4765909,2885642,pv,1511658013
20676,2875398,2885642,pv,1511658013
228104,2062543,2355072,pv,1511658013
773198,4200289,982926,pv,1511658014
677896,2165635,1029459,pv,1511658014
158600,3312738,1697889,fav,1511658014
287521,972793,1194737,pv,1511658014
549674,625283,3767409,pv,1511658014
631139,4364531,384755,pv,1511658014
375063,4069076,3607361,pv,1511658014
306072,1966569,285583,pv,1511658014
643526,282851,1575622,pv,1511658014
764411,4580986,982926,pv,1511658014
976200,3266415,2355072,pv,1511658014
918987,298223,1859277,pv,1511658014
18430,1882195,1080785,pv,1511658014
629115,3093045,1320293,pv,1511658014
332520,5026647,2355072,pv,1511658014
476980,2311313,4801426,pv,1511658014
157636,4858109,672001,pv,1511658015
798555,1295731,2800021,pv,1511658015
494300,4333209,3002561,cart,1511658015
122406,2059276,4801426,pv,1511658015
437344,4061918,4558987,pv,1511658015
220037,2939369,3720767,buy,1511658015
537712,2563909,3100759,pv,1511658015
520145,4465657,1320293,pv,1511658015
38574,1201477,3125533,pv,1511658015
1014253,2963034,1464116,pv,1511658015
915638,4800478,2629787,pv,1511658015
768844,2116634,4757812,pv,1511658015
74745,2231297,323851,fav,1511658015
326607,3693156,2066955,pv,1511658015
651189,4000666,886203,pv,1511658015
778396,3607696,5012555,pv,1511658016
493284,127403,359388,pv,1511658016
254349,4445002,2355072,pv,1511658016
415381,3520931,2419959,pv,1511658016
516789,18479,4145813,pv,1511658016
644777,987403,982926,pv,1511658016
317457,1546479,3776866,pv,1511658016
156905,4377552,1168596,pv,1511658016
740608,2405231,4173315,pv,1511658016
341260,5034946,4756105,pv,1511658016
806318,3525976,3299155,pv,1511658016
674989,4568242,4284875,fav,1511658016
889043,5015057,1281171,pv,1511658017
912390,2303733,2735466,pv,1511658017
393656,3569818,3738615,pv,1511658017
225763,480292,500212,pv,1511658017
334506,3722390,411153,pv,1511658017
273314,4973721,4611962,pv,1511658017
663193,2108019,2003083,pv,1511658017
1000034,800784,982926,pv,1511658018
391116,1962121,4145813,pv,1511658018
40793,4153899,1320293,pv,1511658018
280358,2654723,2520377,pv,1511658018
344240,3712088,2390349,pv,1511658018
691026,4022625,1126526,pv,1511658018
688090,1502018,1879194,pv,1511658018
947196,2259297,1406426,pv,1511658018
518479,576777,411153,pv,1511658018
789309,5136896,2981856,pv,1511658018
248568,3349768,1045172,buy,1511658018
392176,3742963,2066955,pv,1511658018
460076,79067,4145813,fav,1511658018
415381,98283,1104384,pv,1511658018
104698,2500376,4159072,pv,1511658018
854096,4858377,4145813,pv,1511658018
587129,4427761,3776866,cart,1511658019
58778,630815,2355072,pv,1511658019
250968,2335179,2355072,pv,1511658019
380976,3933325,982926,pv,1511658019
904253,1055751,471212,pv,1511658019
907231,3686874,2812445,buy,1511658019
377042,3549064,2355072,pv,1511658019
356507,3220081,578983,pv,1511658019
753856,2167638,4048584,fav,1511658019
929073,1324319,1879194,pv,1511658019
43863,918139,982926,pv,1511658019
41109,4133170,3835723,buy,1511658020
108015,4751201,411153,pv,1511658020
285636,4130380,2355072,pv,1511658020
395049,4346219,570735,cart,1511658020
949647,4427447,4756105,pv,1511658020
306072,1296281,3720767,pv,1511658020
69580,3928745,2671397,pv,1511658020
735110,40025,2974419,cart,1511658020
365717,1391888,2030976,pv,1511658020
587754,4762986,3002561,pv,1511658020
183966,1424015,4672807,pv,1511658020
874905,876411,2465336,pv,1511658020
789333,3383623,344833,pv,1511658020
323387,1699578,982926,pv,1511658021
530376,205888,5071267,pv,1511658021
770137,1031049,154040,pv,1511658021
732889,283410,3607361,pv,1511658021
170558,3144143,2465336,pv,1511658021
1004611,201201,3419760,cart,1511658021
121442,5073040,2355072,pv,1511658021
511424,1078256,440901,pv,1511658021
810879,4042749,3607361,pv,1511658021
889013,1023293,634390,pv,1511658021
641439,183845,4357323,pv,1511658021
607188,3590098,2885642,pv,1511658021
789271,5057422,245312,buy,1511658021
350999,3956368,2945933,pv,1511658021
974720,4838031,2072473,cart,1511658021
460076,2147027,1320293,fav,1511658022
956539,3937435,4801426,pv,1511658022
682283,102982,1080785,pv,1511658022
133319,2817626,4801426,pv,1511658022
82010,2788503,1216617,pv,1511658022
417933,4159217,4756105,pv,1511658022
719252,2161152,4145813,pv,1511658022
386729,4115033,3343095,pv,1511658022
460076,3268126,737184,fav,1511658022
764871,564499,2640118,pv,1511658022
599118,2335010,4159072,pv,1511658022
463780,341543,820364,pv,1511658022
377108,493618,3975787,cart,1511658022
266094,3871120,2465336,pv,1511658022
392064,4974340,4558987,pv,1511658022
858761,5042307,4357323,pv,1511658023
266992,3559268,4869428,pv,1511658023
208833,3716643,383530,pv,1511658023
244463,5059853,4145813,pv,1511658023
874809,1024295,4466876,pv,1511658023
87520,1318574,4606718,pv,1511658023
483594,1088111,2827444,pv,1511658023
29206,4448187,4756105,pv,1511658023
186556,4070367,74446,pv,1511658023
190940,833331,4604594,pv,1511658023
201971,962676,2355072,pv,1511658023
180695,1716295,2565857,pv,1511658023
670681,4511840,846990,pv,1511658024
843075,3665269,1080785,fav,1511658024
409463,4443612,1722855,pv,1511658024
145550,3900777,4993094,pv,1511658024
608599,1097682,4082778,cart,1511658024
997866,3002287,4082778,pv,1511658024
436457,1884224,4915680,pv,1511658024
517112,4526678,2520377,pv,1511658024
659269,1605934,982926,pv,1511658025
195725,5000029,4450414,pv,1511658025
563203,1849653,4298656,pv,1511658025
669210,4843772,570735,pv,1511658025
445656,2581505,3381583,pv,1511658025
16103,3494764,2640118,pv,1511658025
175769,776327,2465336,pv,1511658025
960997,2649870,4756105,pv,1511658025
995188,3017896,2355072,pv,1511658025
475656,361127,3673049,pv,1511658025
940124,176753,4411949,pv,1511658025
538101,1732433,1787510,pv,1511658025
416871,4981228,2858794,pv,1511658025
256758,3889295,3800818,pv,1511658026
511279,4601104,4868797,pv,1511658026
880462,2780737,1859277,cart,1511658026
163323,258231,1029459,pv,1511658026
425634,4018832,4159072,pv,1511658026
932384,2428269,982926,pv,1511658026
565980,2988776,3075521,pv,1511658026
551219,281111,350027,pv,1511658026
65944,4309207,3159480,pv,1511658026
118861,512107,4145813,pv,1511658026
15696,1015021,3454970,pv,1511658027
425200,2455388,3745824,pv,1511658027
55330,465280,2355072,pv,1511658027
664146,1030747,3194735,fav,1511658027
587248,1384198,634390,pv,1511658027
472221,2895550,982926,pv,1511658027
173290,416572,360294,pv,1511658027
735750,2456660,1080785,pv,1511658027
420860,1949459,1288487,pv,1511658027
248955,229653,2195789,pv,1511658027
745774,4756886,800581,pv,1511658027
179889,2041935,2520377,pv,1511658027
287035,3836534,625430,pv,1511658028
196980,3445269,3108882,pv,1511658028
550480,974291,869231,pv,1511658028
585870,291358,4174942,pv,1511658028
165889,4364728,2615163,pv,1511658028
193922,4800535,3607361,pv,1511658028
660013,1364114,4801426,pv,1511658028
813479,158169,2355072,pv,1511658028
261948,4698781,2520377,pv,1511658028
120608,131099,876318,pv,1511658029
268407,584693,3158249,pv,1511658029
411536,2563526,4663501,pv,1511658029
502196,936753,4145813,pv,1511658029
652954,1362503,4284875,pv,1511658029
70758,3011543,2926020,pv,1511658029
684074,2288156,377676,pv,1511658029
515661,680174,2355072,pv,1511658029
322508,2466347,2465336,pv,1511658030
643826,4545733,873792,pv,1511658030
447146,1436416,4331400,pv,1511658030
646259,418486,119741,pv,1511658030
288397,1926504,149192,pv,1511658030
337203,1253410,405755,pv,1511658030
219642,2704585,4148053,pv,1511658030
992351,1452966,2303546,pv,1511658030
860477,4319079,149192,pv,1511658030
680394,2772093,3720767,pv,1511658030
667912,1047955,1320293,pv,1511658030
938116,2134897,2735466,pv,1511658030
276252,3465909,1299190,pv,1511658030
1004505,4048232,145519,pv,1511658031
954492,4932087,1320293,pv,1511658031
271586,151399,578983,pv,1511658031
629913,1014006,3702593,pv,1511658031
879398,2473922,4756105,pv,1511658031
644883,4961929,1573465,pv,1511658032
62574,169041,1807416,pv,1511658032
643095,5119949,4357323,pv,1511658032
14391,2367378,2920476,pv,1511658032
840495,3013895,2926020,pv,1511658032
846863,1607283,1132429,pv,1511658032
463414,4937993,3607361,pv,1511658032
743967,491563,4244487,pv,1511658032
571930,2104387,1646753,pv,1511658032
337203,2407315,4715650,pv,1511658032
87004,3581433,690811,pv,1511658032
808466,3209415,2355072,pv,1511658032
834242,2646442,4357323,pv,1511658032
5855,1547334,1120543,pv,1511658032
861315,4512645,3361496,fav,1511658032
128765,1897815,4756105,pv,1511658033
677500,4690832,3504022,pv,1511658033
594637,3443787,3747017,pv,1511658033
958078,952967,3177877,pv,1511658033
455903,1725977,3904106,pv,1511658033
441977,177176,50601,pv,1511658033
391280,4307461,982926,pv,1511658033
873094,2044886,2355072,pv,1511658033
664177,1293088,5053508,pv,1511658034
302778,3781391,1528133,pv,1511658034
475563,4841577,1275696,cart,1511658034
208142,3139742,4756105,pv,1511658034
138026,3709805,3672452,pv,1511658034
534394,3020956,2355072,pv,1511658034
387963,1177970,2885642,pv,1511658034
334506,2951108,411153,pv,1511658034
274331,2394590,1464116,pv,1511658034
356279,829406,1102540,pv,1511658034
775853,3788823,4217906,pv,1511658034
156203,4938048,2383838,pv,1511658034
572844,1438423,2520377,pv,1511658035
987111,2263608,245312,pv,1511658035
231038,708261,1964754,fav,1511658035
81884,2437934,753984,pv,1511658035
942856,4215633,4756105,pv,1511658035
208061,2916548,4692440,pv,1511658035
495163,5100809,1879194,pv,1511658035
43237,2393443,2355072,pv,1511658036
750878,4729766,4672807,pv,1511658036
882734,4273237,1540741,pv,1511658036
400141,1714043,237446,pv,1511658036
585344,646781,267209,pv,1511658036
227633,3498188,4476428,pv,1511658036
284584,2019640,3607361,cart,1511658036
988694,3542016,982926,pv,1511658036
164332,3158500,235534,pv,1511658036
945934,2793460,3720767,pv,1511658036
691649,437087,223690,pv,1511658036
128816,2803125,3637084,pv,1511658036
715158,1448525,1842993,pv,1511658036
606841,4290041,3299155,cart,1511658037
655163,3409614,4357323,pv,1511658037
337203,1253410,405755,pv,1511658037
169609,4290998,4731191,pv,1511658037
515001,4142409,2735466,pv,1511658037
525614,4397050,3738615,pv,1511658037
48008,3043421,4239038,pv,1511658037
1015928,2849670,2735466,pv,1511658037
408783,703194,2885642,pv,1511658037
42364,3978662,611849,pv,1511658037
790128,4946853,2096639,pv,1511658038
226081,689681,4756105,pv,1511658038
774686,96790,2188684,pv,1511658038
317012,1665474,2355072,pv,1511658038
211077,990967,570735,pv,1511658038
879481,3523697,2154867,pv,1511658038
24625,5074681,2465336,pv,1511658038
638709,3848680,1575622,pv,1511658038
178232,1413610,149192,pv,1511658038
19742,4388000,200278,pv,1511658038
216011,2678565,1548278,pv,1511658038
709957,1969563,4606718,pv,1511658038
106526,856738,1080785,pv,1511658038
325562,363858,2735466,pv,1511658038
979063,2452027,4022701,pv,1511658038
451072,1035375,1320293,pv,1511658038
374336,3615843,4801426,pv,1511658038
466049,140210,1132429,pv,1511658038
38369,1780938,4357323,pv,1511658038
27948,1190005,1320293,pv,1511658038
212574,321621,4756105,pv,1511658039
793295,2941339,149192,pv,1511658039
971953,1503702,4756105,pv,1511658039
270332,1751547,4718907,pv,1511658039
261666,5141180,2355072,pv,1511658039
79249,1336042,2465336,pv,1511658039
743689,3161594,4181361,pv,1511658039
187936,1209195,4145813,pv,1511658039
954462,2653229,2448593,pv,1511658039
505372,3578525,702060,pv,1511658039
492876,2648336,35290,pv,1511658039
572164,4818203,1464116,fav,1511658039
204115,3552080,2477357,pv,1511658039
342902,679860,4756105,pv,1511658039
上面就是模拟Web日志都一条条写入了Flume,然后flume就将其导入了Kafka,然后Flink作为消费者就会去消费数据,然后利用各种窗口操作就可以了OK。

10、Flume将MySQL表数据准实时抽取到HDFS、MySQL、Kafka
软件版本号 jdk1.8、apache-flume-1.6.0-bin、kafka_2.8.0-0.8.0、zookeeper-3.4.5
集群环境安装请先测试;
参考以下作者信息,特此感谢;
①、利用Flume将MySQL表数据准实时抽取到HDFS
一、为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取从MySQL数据库增量抽取数据到HDFS,然后用HAWQ的外部表进行访问。这种方式只需要很少量的配置即可完成数据抽取任务,但缺点同样明显,那就是实时性。Sqoop使用MapReduce读写数据,而MapReduce是为了批处理场景设计的,目标是大吞吐量,并不太关心低延时问题。就像实验中所做的,每天定时增量抽取数据一次。 Flume是一个海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。Flume以流方式处理数据,可作为代理持续运行。当新的数据可用时,Flume能够立即获取数据并输出至目标,这样就可以在很大程度上解决实时性问题。 Flume是最初只是一个日志收集器,但随着flume-ng-sql-source插件的出现,使得Flume从关系数据库采集数据成为可能。下面简单介绍Flume,并详细说明如何配置Flume将MySQL表数据准实时抽取到HDFS。
二、Flume简介
Flume的概念 Flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到HDFS,简单来说flume就是收集日志的,其架构如图1所示。
Event的概念 在这里有必要先介绍一下Flume中event的相关概念:Flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,Flume再删除自己缓存的数据。 在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?Event将传输的数据进行封装,是Flume传输数据的基本单位,如果是文本文件,通常是一行记录。Event也是事务的基本单位。Event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。Event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
Flume架构介绍 Flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent。Agent本身是一个Java进程,运行在日志收集节点——所谓日志收集节点就是服务器节点。 Agent里面包含3个核心的组件:source、channel和sink,类似生产者、仓库、消费者的架构。 Source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。 Channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。 Sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、Hbase、solr、自定义。
Flume的运行机制 Flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据输入的source,一个是数据输出的sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方,例如HDFS等。注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
三、安装Hadoop和Flume
四、配置与测试
建立MySQL数据库表 建立测试表并添加数据。
use test;
create table wlslog
(id int not null,
time_stamp varchar(40),
category varchar(40),
type varchar(40),
servername varchar(40),
code varchar(40),
msg varchar(40),
primary key ( id )
);
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(1,'apr-8-2014-7:06:16-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to standby');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(2,'apr-8-2014-7:06:17-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to starting');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(3,'apr-8-2014-7:06:18-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to admin');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(4,'apr-8-2014-7:06:19-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to resuming');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(5,'apr-8-2014-7:06:20-pm-pdt','notice','weblogicserver','adminserver','bea-000361','started weblogic adminserver');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(6,'apr-8-2014-7:06:21-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to running');
insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(7,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode');
commit;
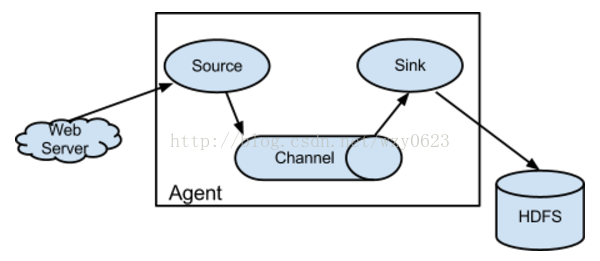
2. 建立相关目录与文件
(1)创建本地状态文件
```sh
mkdir -p /var/lib/flume
cd /var/lib/flume
touch sql-source.status
chmod -R 777 /var/lib/flume
```
(2)建立HDFS目标目录
```sh
hdfs dfs -mkdir -p /flume/mysql
hdfs dfs -chmod -R 777 /flume/mysql
```
3. 准备JAR包
从http://book2s.com/java/jar/f/flume-ng-sql-source/download-flume-ng-sql-source-1.3.7.html下载flume-ng-sql-source-1.3.7.jar文件,并复制到Flume库目录。
```sh
cp flume-ng-sql-source-1.3.7.jar /usr/hdp/current/flume-server/lib/
```
• 将MySQL JDBC驱动JAR包也复制到Flume库目录。
```sh
cp mysql-connector-java-5.1.17.jar /usr/hdp/current/flume-server/lib/mysql-connector-java.jar
```
• 将MySQL JDBC驱动JAR包也复制到Flume库目录。
```sh
cp mysql-connector-java-5.1.17.jar /usr/hdp/current/flume-server/lib/mysql-connector-java.jar
```
4. 建立HAWQ外部表
```sql
create external table ext_wlslog
(id int,
time_stamp varchar(40),
category varchar(40),
type varchar(40),
servername varchar(40),
code varchar(40),
msg varchar(40)
) location ('pxf://mycluster/flume/mysql?profile=hdfstextmulti') format 'csv' (quote=e'"');
```
5. 配置Flume
在Ambari -> Flume -> Configs -> flume.conf中配置如下属性:
```properties
agent.channels.ch1.type = memory
agent.sources.sql-source.channels = ch1
agent.channels = ch1
agent.sinks = HDFS
agent.sources = sql-source
agent.sources.sql-source.type = org.keedio.flume.source.SQLSource
agent.sources.sql-source.connection.url = jdbc:mysql://172.16.1.127:3306/test
agent.sources.sql-source.user = root
agent.sources.sql-source.password = 123456
agent.sources.sql-source.table = wlslog
agent.sources.sql-source.columns.to.select = *
agent.sources.sql-source.incremental.column.name = id
agent.sources.sql-source.incremental.value = 0
agent.sources.sql-source.run.query.delay=5000
agent.sources.sql-source.status.file.path = /var/lib/flume
agent.sources.sql-source.status.file.name = sql-source.status
agent.sinks.HDFS.channel = ch1
agent.sinks.HDFS.type = hdfs
agent.sinks.HDFS.hdfs.path = hdfs://mycluster/flume/mysql
agent.sinks.HDFS.hdfs.fileType = DataStream
agent.sinks.HDFS.hdfs.writeFormat = Text
agent.sinks.HDFS.hdfs.rollSize = 268435456
agent.sinks.HDFS.hdfs.rollInterval = 0
agent.sinks.HDFS.hdfs.rollCount = 0
```
Flume在flume.conf文件中指定Source、Channel和Sink相关的配置,各属性描述如表1所示。

6. 运行Flume代理
保存上一步的设置,然后重启Flume服务,如图2所示。
**五、方案优缺点**
利用Flume采集关系数据库表数据最大的优点是配置简单,不用编程。相比tungsten-replicator的复杂性,Flume只要在flume.conf文件中配置source、channel及sink的相关属性,已经没什么难度了。而与现在很火的canal比较,虽然不够灵活,但毕竟一行代码也不用写。再有该方案采用普通SQL轮询的方式实现,具有通用性,适用于所有关系库数据源。
这种方案的缺点与其优点一样突出,主要体现在以下几方面。
在源库上执行了查询,具有入侵性。
通过轮询的方式实现增量,只能做到准实时,而且轮询间隔越短,对源库的影响越大。
只能识别新增数据,检测不到删除与更新。
要求源库必须有用于表示增量的字段。
即便有诸多局限,但用Flume抽取关系库数据的方案还是有一定的价值,特别是在要求快速部署、简化编程,又能满足需求的应用场景,对传统的Sqoop方式也不失为一种有效的补充。
**flume自定义sink之mysql**
```java
package me; import static org.mockito.Matchers.booleanThat; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement; import org.apache.flume.Channel;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.Transaction;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink; import com.google.common.base.Preconditions; public class MySink extends AbstractSink implements Configurable {
private Connection connect;
private Statement stmt;
private String columnName;
private String url;
private String user;
private String password;
private String tableName;
// 在整个sink结束时执行一遍
@Override
public synchronized void stop() {
// TODO Auto-generated method stub
super.stop();
} // 在整个sink开始时执行一遍
@Override
public synchronized void start() {
// TODO Auto-generated method stub
super.start();
try {
connect = DriverManager.getConnection(url, user, password);
// 连接URL为 jdbc:mysql//服务器地址/数据库名 ,后面的2个参数分别是登陆用户名和密码
stmt = connect.createStatement();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} // 不断循环调用 @Override public Status process() throws EventDeliveryException { // TODO Auto-generated method stub Channel ch = getChannel(); Transaction txn = ch.getTransaction(); Event event = null; txn.begin(); while (true) { event = ch.take(); if (event != null) { break; } } try { String body = new String(event.getBody()); if (body.split(",").length == columnName.split(",").length) { String sql = "insert into " + tableName + "(" + columnName + ") values(" + body + ")"; stmt.executeUpdate(sql); txn.commit(); return Status.READY; } else { txn.rollback(); return null; } } catch (Throwable th) { txn.rollback(); if (th instanceof Error) { throw (Error) th; } else { throw new EventDeliveryException(th); } } finally { txn.close(); }
} @Override
public void configure(Context arg0) {
columnName = arg0.getString("column_name");
Preconditions.checkNotNull(columnName, "column_name must be set!!");
url = arg0.getString("url");
Preconditions.checkNotNull(url, "url must be set!!");
user = arg0.getString("user");
Preconditions.checkNotNull(user, "user must be set!!");
password = arg0.getString("password");
Preconditions.checkNotNull(password, "password must be set!!");
tableName = arg0.getString("tableName");
Preconditions.checkNotNull(tableName, "tableName must be set!!");
} }
```
agent.sources = s1
agent.channels = c1
agent.sinks = sk1 agent.sources.s1.type = netcat
agent.sources.s1.bind = localhost
agent.sources.s1.port = 5678
agent.sources.s1.channels = c1 agent.sinks.sk1.type = me.MySink
agent.sinks.sk1.url=jdbc:mysql://192.168.16.33:3306/test
agent.sinks.sk1.tableName= test.user
agent.sinks.sk1.user=root
agent.sinks.sk1.password=WoChu@123
agent.sinks.sk1.column_name=id, username, password
agent.sinks.sk1.channel = c1 agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
lihudeMacBook-Pro:~ SunAndLi$ cd hadoop-2.7.2/flume/
lihudeMacBook-Pro:flume SunAndLi$ bin/flume-ng agent -c conf -f conf/sink-mysql --name agent -Dflume.root.logger=INFO,console
需要向/usr/local/bigdata/apache-flume-1.6.0-bin/lib 放入三个jar包
flume-ng-sql-source-1.3.7.jar -->flume的mysql source 下载地址: https://github.com/keedio/flume-ng-sql-source/
mysql-connector-java-5.1.35.jar -->mysql 驱动包 应该都有吧。
flume-mysql-sink-1.0-SNAPSHOT.jar -->自定义的mysql sink参考第二个网址;打的jar包
三个jar包的下载地址: http://download.csdn.net/download/kongfanyu/10271848
重点是flume的配置文件信息如下:
agent.channels = ch1 ch2 ch3
agent.sinks = HDFS mysqlSink kfk
agent.sources = sql-source
agent.sources.sql-source.type = org.keedio.flume.source.SQLSource
agent.sources.sql-source.channels = ch1 ch2 ch3
agent.sources.sql-source.connection.url = jdbc:mysql://192.168.2.164:3306/test
agent.sources.sql-source.user = root
agent.sources.sql-source.password = root
agent.sources.sql-source.table = wlslog
agent.sources.sql-source.columns.to.select = *
agent.sources.sql-source.incremental.column.name = id
agent.sources.sql-source.incremental.value = 0
agent.sources.sql-source.run.query.delay=5000
agent.sources.sql-source.status.file.path = /var/lib/flume
agent.sources.sql-source.status.file.name = sql-source.status
#ch1
agent.channels.ch1.type = memory
agent.channels.ch1.capacity = 1000
agent.channels.ch1.transactionCapacity = 100
#ch2
agent.channels.ch2.type = memory
agent.channels.ch2.capacity = 1000
agent.channels.ch2.transactionCapacity = 100
#ch3
agent.channels.ch3.type = memory
agent.channels.ch3.capacity = 1000
agent.channels.ch3.transactionCapacity = 100
agent.sinks.HDFS.channel = ch1
agent.sinks.HDFS.type = hdfs
agent.sinks.HDFS.hdfs.path = hdfs://dbserver:9000/flume/mysql3
agent.sinks.HDFS.hdfs.fileType = DataStream
agent.sinks.HDFS.hdfs.writeFormat = Text
agent.sinks.HDFS.hdfs.rollSize = 268435456
agent.sinks.HDFS.hdfs.rollInterval = 0
agent.sinks.HDFS.hdfs.rollCount = 0
# 自定义的 mysqlSink
agent.sinks.mysqlSink.type = org.flume.mysql.sink.MysqlSink
agent.sinks.mysqlSink.url=jdbc:mysql://192.168.2.171:3306/test
agent.sinks.mysqlSink.user=root
agent.sinks.mysqlSink.password=123456
agent.sinks.mysqlSink.tableName=wlslog
agent.sinks.mysqlSink.column_name=id,time_stamp,category,type,servername,code,msg
agent.sinks.mysqlSink.channel = ch2
# 配置 kafka sink
agent.sinks.kfk.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kfk.brokerList=192.168.2.171:9092,192.168.2.172:9092,192.168.2.173:9092,192.168.2.174:9092,192.168.2.175:9092
agent.sinks.kfk.topic=mytopic
agent.sinks.kfk.requiredAcks = 1
agent.sinks.kfk.batchSize = 2
agent.sinks.kfk.channel = ch3
12、flume采集日志到HDFS中再导入到hive表中
flume介绍 Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application
简单来说是一个分布式的日志采集系统。简单易用,高容错 这次使用的是spooldir source,kafkachannnel channel, hdfs sink.,以生产方式为列使用两个fluem。 第一个flume 把数据推到kafkachannel 第二个flume把数据从kafkachannel落到hdfs中 flume1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# spooldir source
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /home/test10
#a1.sources.r1.fileHeader = true
# interceptor 拦截timestamp,简单过滤数据
a1.sources.r1.interceptors=i1 i2
a1.sources.r1.interceptors.i1.type=regex_filter
a1.sources.r1.interceptors.i1.regex=(.*)installed(.*)
a1.sources.r1.interceptors.i2.type = regex_extractor
a1.sources.r1.interceptors.i2.regex = ^(?:\\n)?(\\d\\d\\d\\d-\\d\\d-\\d\\d\\s\\d\\d:\\d\\d:\\d\\d)
a1.sources.r1.interceptors.i2.serializers = s1
a1.sources.r1.interceptors.i2.serializers.s1.type = org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer
a1.sources.r1.interceptors.i2.serializers.s1.name = timestamp
a1.sources.r1.interceptors.i2.serializers.s1.pattern = yyyy-MM-dd HH:mm:ss
# kafka memeory
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = localhost:9092
a1.channels.c1.kafka.topic = top
a1.channels.c1.kafka.consumer.group.id = top-consumer
# 老版本使用具体请看官网
#a1.channels.c1.brokerList = localhost:9092
#a1.channels.c1.zookeeperConnect = localhost:2181
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.parseAsFlumeEvent = true
flume2
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# kafka memeory
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = localhost:9092
a1.channels.c1.kafka.topic = top
a1.channels.c1.kafka.consumer.group.id = top-consumer
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.parseAsFlumeEvent = true
# sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/xzc/logss8/ds=%Y%m%d
a1.sinks.k1.hdfs.fileType = DataStream
#a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.batchSize = 10
a1.sinks.k1.channel = c1
启动flume1
$ flume-ng agent –conf conf –conf-file fllume1 –name a1 -Dflume.root.logger=INFO.console
启动flume2
$ flume-ng agent –conf conf –conf-file fllume1 –name a1 -Dflume.root.logger=INFO.console
导入HIve表
首先建立hive的外部表
create external table if not exists soft(
time string,
status string,
version string
)
partitioned by (ds string)
row format delimited fields terminated by ’ ’
lines terminated by ‘\n’
stored as textfile
location ‘/user/xzc/logss8/’;
导入数据,partition必须跟文件目录保持一致
& alter table soft add partition (ds = ‘20180806’)
查询数据
$ select * from soft
14、flume采集下沉到kafka再上传到hdfs
1、消费者:负责将数据放到本地路径暂存
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Collections;
import java.util.Properties; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; public class ConsumerDemo {
private static KafkaConsumer<String, String> consumer;
private static Properties props;
//static静态代码块,在main之前先执行
static {
props = new Properties();
//消费者kafka地址
props.put("bootstrap.servers", "hdp-2:9092");
//key反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//组
props.put("group.id", "yangk");
} /**
* 从kafka中获取数据(SpringBoot也集成了kafka)
*/
private static void ConsumerMessage() {
//允许自动提交位移
props.put("enable.auto.commit", true);
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Collections.singleton("first_kafka")); //使用轮询拉取数据--消费完成之后会根据设置时长来清除消息,被消费过的消息,如果想再次被消费,可以根据偏移量(offset)来获取
try {
File file = new File("F:/xiu.txt");
//建文件输出流
FileOutputStream fos = new FileOutputStream(file);
while (true) {
//从kafka中读到了数据放在records中
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> r : records) { String a = r.topic()+ r.offset()+ r.key()+ r.value() + "\r\n";
//将数据写到F:/xiu.txt
fos.write(a.getBytes()); System.out.printf("topic = %s, offset = %s, key = %s, value = %s", r.topic(), r.offset(),
r.key(), r.value() + "\n"); }
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
consumer.close();
}
} public static void main(String[] args) {
//调用接收消息的方法
ConsumerMessage(); }
}
2、从本地临时路径上传到hdfs
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.net.URI;
import java.net.URISyntaxException;
import java.util.TimerTask; public class UploadData extends TimerTask{ public void run() { URI uri = null;
try {
uri = new URI("hdfs://hdp-1:9000"); Configuration conf = new Configuration();
conf.set("dfs.replication", "2");//name,value 副本个数
conf.set("dfs.blocksize", "64m");//块的大小
String user = "root"; FileSystem fs = FileSystem.get(uri,conf,user);
Path src = new Path("F:/xiu.txt");//本地临时路径文件
Path dst = new Path("/hello_kafka.txt");//上传到hdfs的目标文件
fs.copyFromLocalFile(src,dst);
} catch (Exception e) {
e.printStackTrace();
} }
}
3、设置定时器
import java.util.Timer;
public class TimerDemo {
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new UploadData(),0,4*1000);//测试为了方便4s钟重新加载一次UploalData类
}
}
15、Flume读取日志数据写入Kafka
一、Flume配置 flume要求1.6以上版本
flume-conf.properties文件配置内容,sinks的输出作为kafka的product
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/flume/nginx.log
# Describe the sink
#a1.sinks.k1.type = logger
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = mytopic
a1.sinks.k1.brokerList = 192.168.209.121:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume启动
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
二、Kafka消费者
package com.lyz.flume.kafka; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties; import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties; /**
* 消费Flume的数据
* @author liuyazhuang
*/
public class KafkaConsumer { private final ConsumerConnector consumer; public KafkaConsumer() {
Properties props = new Properties();
//zookeeper 配置
props.put("zookeeper.connect", "192.168.209.121:2181"); //group 代表一个消费组
props.put("group.id", "consumer-group"); //zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
//序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder"); ConsumerConfig config = new ConsumerConfig(props); consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
} public void execute() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put("mytopic", new Integer(1)); StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties()); Map<String, List<KafkaStream<String, String>>> consumerMap =
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get("mytopic").get(0);
ConsumerIterator<String, String> it = stream.iterator();
while (it.hasNext())
System.out.println(it.next().message());
} public static void main(String[] args) {
new KafkaConsumer().execute();
}
}
三、启动命令
#启动Zookeeper server:
bin/zookeeper-server-start.sh config/zookeeper.properties &
#启动Kafka server:
bin/kafka-server-start.sh config/server.properties &
#运行producer:
bin/kafka-console-producer.sh --broker-list 192.168.209.121:9092 --topic mytopic
#运行consumer:
bin/kafka-console-consumer.sh --zookeeper 192.168.209.121:2181 --topic mytopic --from-beginning
16、flume同步mysql数据至kafka
一、前言:
现在需要经mysql的数据定时同步到kafka,一开始用的canal但是不知道为啥没成功,启动起来了但就是数据过去不,查看log也不报错,所以转到flume。发现flume挺好用的,而且灵活。
二、同步原理:
Flume原理就不多介绍了,文章一大把,我说一下,连接sql的原理。我调的是网上的开源插件,看了一下log日志,特意分享一下原理,有错误的希望指出,大家交流。其实就是source每隔一段时间(自定义)执行一遍sql,来查询数据库,将查询到的数据sink到kafka。如果数据量大的话,建议查询mysql从库。
三、部署
1、版本说明:
flume:1.9.0
mysql:不限
2、下载flume:apache-flume-1.9.0-bin.tar.gz
下载插件:flume-ng-sql-source-json-1.0.jar
下载数据库连接jar包
apache flume打包下载:flume-mysql.zip
cloudera CDH flume版本下载:cloudera-flume-mysql.zip
注:如果flume版本是CDH的,导入原生的flume-ng-sql-source-json-1.0.jar,Flume在读取mysql的时候会报错:
java.lang.NoSuchMethodError: org.apache.flume.Context.getSubProperties(Ljava/lang/String;)Lcom/google/common/collect/ImmutableMap;所以根据自己的需求下载。
2、安装Flume
1)将文件上传到linux服务器,我上传到/root目录下了。
2)创建文件夹
mkdir /home/install/
3)解压flume
tar -zxvf apache-flume-1.9.0-bin.tar.gz
4)将下载的插件和mysql的jar包导入lib目录下
mv /root/flume-ng-sql-source-json-1.0.jar /home/install/apache-flume-1.9.0-bin/lib
mv /root/mysql-connector-java.jar /home/install/apache-flume-1.9.0-bin/lib
4)创建flume的properties文件(/home/install/apache-flume-1.9.0-bin/conf)
cp /home/install/apache-flume-1.9.0-bin/conf/flume-conf.properties.template /home/install/apache-flume-1.9.0-bin/conf/flume-conf.properties
5)配置flume-conf.properties文件:
agent.sources = s1
agent.channels = c1
agent.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
agent.sources.s1.type = org.keedio.flume.source.SQLSource
agent.sources.s1.hibernate.connection.url = jdbc:mysql://192.168.26.234:3306/test
# Hibernate Database connection properties
agent.sources.s1.hibernate.connection.user = root
agent.sources.s1.hibernate.connection.password = xloVR91vQ7bRMXcW
agent.sources.s1.hibernate.connection.autocommit = true
agent.sources.s1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
agent.sources.s1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
agent.sources.s1.run.query.delay=5000 #查询间隔
agent.sources.s1.status.file.path = /home/install/apache-flume-1.9.0-bin/status
agent.sources.s1.status.file.name = sqlSource.status
# Custom query
agent.sources.s1.start.from = 0
agent.sources.s1.custom.query = select `id`, `name`, "666" as tt from test1
#where id > $@$ order by id asc 根据id增量查询
#where id > $@$ order by id asc
agent.sources.s1.batch.size = 1000
agent.sources.s1.max.rows = 1000
agent.sources.s1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
agent.sources.s1.hibernate.c3p0.min_size=1
agent.sources.s1.hibernate.c3p0.max_size=10
################################################################
agent.channels.c1.type = memory
agent.channels.c1.capacity = 10000
agent.channels.c1.transactionCapacity = 10000
agent.channels.c1.byteCapacityBufferPercentage = 20
agent.channels.c1.byteCapacity = 800000
################################################################
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#kafka的topic用来存储查询到的数据
agent.sinks.k1.topic = test-flume
agent.sinks.k1.brokerList = 192.168.6.201:9092,192.168.6.202:9092,192.168.6.203:9092
agent.sinks.k1.requiredAcks = 1
agent.sinks.k1.batchSize = 20
agent.sinks.k1.channel = c1
agent.sinks.k1.channel = c1
agent.sources.s1.channels=c1
6)创建kafak topic
略过:自行查看网上教程
7)启动flume
进入flume安装目录:cd /home/install/apache-flume-1.9.0-bin
启动:bin/flume-ng agent -n agent -c conf -f conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
8)安装配置结束,可自行测试。
4、DataSet转换
转换(transformations)将一个DataSet转成另外一个DataSet,Flink提供了非常丰富的转换操作符。具体使用如下:
1、Map
一进一出
DataSource<String> source = env.fromElements("I", "like", "flink");
source.map(new MapFunction<String, String>() {
@Override
// 将数据转为大写
public String map(String value) throws Exception {
return value.toUpperCase();
}
}).print();
2、FlatMap
输入一个元素,产生0个、1个或多个元素
stringDataSource
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
for (String word : split) {
out.collect(Tuple2.of(word, 1));
}
}
})
.groupBy(0)
.sum(1);
3、MapPartition
功能和Map函数相似,只是MapPartition操作是在DataSet中基于分区对数据进行处理,函数调用中会按照分区将数据通过Iteator的形式传入,每个分区中的元素数与并行度有关,并返回任意数量的结果值。
source.mapPartition(new MapPartitionFunction<String, Long>() {
@Override
public void mapPartition(Iterable<String> values, Collector<Long> out) throws Exception {
long c = 0;
for (String value : values) {
c++;
}
//输出每个分区元素个数
out.collect(c);
}
}).print();
4、Filter
过滤数据,如果返回true则保留数据,如果返回false则过滤掉
DataSource<Long> source = env.fromElements(1L, 2L, 3L,4L,5L);
source.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value % 2 == 0;
}
}).print();
5、Project
仅能用在Tuple类型的数据集,投影操作,选取Tuple数据的字段的子集
DataSource<Tuple3<Long, Integer, String>> source = env.fromElements(
Tuple3.of(1L, 20, "tom"),
Tuple3.of(2L, 25, "jack"),
Tuple3.of(3L, 22, "bob"));
// 去第一个和第三个元素
source.project(0, 2).print();
6、Reduce
通过两两合并,将数据集中的元素合并成一个元素,可以在整个数据集上使用,也可以在分组之后的数据集上使用。
DataSource<Tuple2<String, Integer>> source = env.fromElements(
Tuple2.of("Flink", 1),
Tuple2.of("Flink", 1),
Tuple2.of("Hadoop", 1),
Tuple2.of("Spark", 1),
Tuple2.of("Flink", 1));
source
.groupBy(0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}).print();
7、ReduceGroup
将数据集中的元素合并成一个元素,可以在整个数据集上使用,也可以在分组之后的数据集上使用。reduce函数的输入值是一个分组元素的Iterable。
DataSource<Tuple2<String, Long>> source = env.fromElements(
Tuple2.of("Flink", 1L),
Tuple2.of("Flink", 1L),
Tuple2.of("Hadoop", 1L),
Tuple2.of("Spark", 1L),
Tuple2.of("Flink", 1L));
source
.groupBy(0)
.reduceGroup(new GroupReduceFunction<Tuple2<String,Long>, Tuple2<String,Long>>() {
@Override
public void reduce(Iterable<Tuple2<String, Long>> values, Collector<Tuple2<String, Long>> out) throws Exception {
Long sum = 0L;
String word = "";
for(Tuple2<String, Long> value:values){
sum += value.f1;
word = value.f0;
}
out.collect(Tuple2.of(word,sum));
}
}).print();
8、Aggregate
通过Aggregate Function将一组元素值合并成单个值,可以在整个DataSet数据集上使用,也可以在分组之后的数据集上使用。仅仅用在Tuple类型的数据集上,主要包括Sum,Min,Max函数
DataSource<Tuple2<String, Long>> source = env.fromElements(
Tuple2.of("Flink", 1L),
Tuple2.of("Flink", 1L),
Tuple2.of("Hadoop", 1L),
Tuple2.of("Spark", 1L),
Tuple2.of("Flink", 1L));
source
.groupBy(0)
.aggregate(SUM,1)// 按第2个值求和
.print();
9、Distinct
DataSet数据集元素去重
DataSource<Tuple> source = env.fromElements(Tuple1.of("Flink"),Tuple1.of("Flink"),Tuple1.of("hadoop"));
source.distinct(0).print();// 按照tuple的第一个字段去重
// 结果:
(Flink)
(hadoop)
10、Join
默认的join是产生一个Tuple2数据类型的DataSet,关联的key可以通过key表达式、Key-selector函数、字段位置以及CaseClass字段指定。对于两个Tuple类型的数据集可以通过字段位置进行关联,左边数据集的字段通过where方法指定,右边数据集的字段通过equalTo()方法指定。比如:
DataSource<Tuple2<Integer,String>> source1 = env.fromElements(
Tuple2.of(1,"jack"),
Tuple2.of(2,"tom"),
Tuple2.of(3,"Bob"));
DataSource<Tuple2<String, Integer>> source2 = env.fromElements(
Tuple2.of("order1", 1),
Tuple2.of("order2", 2),
Tuple2.of("order3", 3));
source1.join(source2).where(0).equalTo(1).print();
可以在关联的过程中指定自定义Join Funciton, Funciton的入参为左边数据集中的数据元素和右边数据集的中的数据元素所组成的元祖,并返回一个经过计算处理后的数据。如:
// 用户id,购买商品名称,购买商品数量
DataSource<Tuple3<Integer,String,Integer>> source1 = env.fromElements(
Tuple3.of(1,"item1",2),
Tuple3.of(2,"item2",3),
Tuple3.of(3,"item3",4));
//商品名称与商品单价
DataSource<Tuple2<String, Integer>> source2 = env.fromElements(
Tuple2.of("item1", 10),
Tuple2.of("item2", 20),
Tuple2.of("item3", 15));
source1.join(source2)
.where(1)
.equalTo(0)
.with(new JoinFunction<Tuple3<Integer,String,Integer>, Tuple2<String,Integer>, Tuple3<Integer,String,Double>>() {
// 用户每种商品购物总金额
@Override
public Tuple3<Integer, String, Double> join(Tuple3<Integer, String, Integer> first, Tuple2<String, Integer> second) throws Exception {
return Tuple3.of(first.f0,first.f1,first.f2 * second.f1.doubleValue());
}
}).print();
为了能够更好地引导Flink底层去正确地处理数据集,可以在DataSet数据集关联中,通过Size Hint标记数据集的大小,Flink可以根据用户给定的hint(提示)调整计算策略,例如可以使用joinWithTiny或joinWithHuge提示第二个数据集的大小。示例如下:
DataSet<Tuple2<Integer, String>> input1 = // [...]
DataSet<Tuple2<Integer, String>> input2 = // [...]
DataSet<Tuple2<Tuple2<Integer, String>, Tuple2<Integer, String>>>
result1 =
// 提示第二个数据集为小数据集
input1.joinWithTiny(input2)
.where(0)
.equalTo(0);
DataSet<Tuple2<Tuple2<Integer, String>, Tuple2<Integer, String>>>
result2 =
// h提示第二个数据集为大数据集
input1.joinWithHuge(input2)
.where(0)
.equalTo(0);
Flink的runtime可以使用多种方式执行join。在不同的情况下,每种可能的方式都会胜过其他方式。系统会尝试自动选择一种合理的方法,但是允许用户手动选择一种策略, 可以让Flink更加灵活且高效地执行Join操作。
DataSet<SomeType> input1 = // [...]
DataSet<AnotherType> input2 = // [...]
// 广播第一个输入并从中构建一个哈希表,第二个输入将对其进行探测,适用于第一个数据集非常小的场景
DataSet<Tuple2<SomeType, AnotherType> result =
input1.join(input2, JoinHint.BROADCAST_HASH_FIRST)
.where("id").equalTo("key");
// 广播第二个输入并从中构建一个哈希表,第一个输入将对其进行探测,适用于第二个数据集非常小的场景
DataSet<Tuple2<SomeType, AnotherType> result =
input1.join(input2, JoinHint.BROADCAST_HASH_SECOND)
.where("id").equalTo("key");
// 将两个数据集重新分区,并将第一个数据集转换成哈希表,适用于第一个数据集比第二个数据集小,但两个数据集都比较大的场景
DataSet<Tuple2<SomeType, AnotherType> result =
input1.join(input2, JoinHint.REPARTITION_HASH_FIRST)
.where("id").equalTo("key");
// 将两个数据集重新分区,并将第二个数据集转换成哈希表,适用于第二个数据集比第一个数据集小,但两个数据集都比较大的场景
DataSet<Tuple2<SomeType, AnotherType> result =
input1.join(input2, JoinHint.REPARTITION_HASH_SECOND)
.where("id").equalTo("key");
// 将两个数据集重新分区,并将每个分区排序,适用于两个数据集都已经排好序的场景
DataSet<Tuple2<SomeType, AnotherType> result =
input1.join(input2, JoinHint.REPARTITION_SORT_MERGE)
.where("id").equalTo("key");
// 相当于不指定,有系统自行处理
DataSet<Tuple2<SomeType, AnotherType> result =
input1.join(input2, JoinHint.OPTIMIZER_CHOOSES)
.where("id").equalTo("key");
11、OuterJoin
OuterJoin对两个数据集进行外关联,包含left、right、full outer join三种关联方式,分别对应DataSet API中的leftOuterJoin、rightOuterJoin以及fullOuterJoin方法。注意外连接仅适用于Java 和 Scala DataSet API.
使用方式几乎和join类似:
//左外连接
source1.leftOuterJoin(source2).where(1).equalTo(0);
//右外链接
source1.rightOuterJoin(source2).where(1).equalTo(0);
此外,外连接也提供了相应的关联算法提示,可以跟据左右数据集的分布情况选择合适的优化策略,提升数据处理的效率。下面代码可以参考上面join的解释。
DataSet<SomeType> input1 = // [...]
DataSet<AnotherType> input2 = // [...]
DataSet<Tuple2<SomeType, AnotherType> result1 =
input1.leftOuterJoin(input2, JoinHint.REPARTITION_SORT_MERGE)
.where("id").equalTo("key");
DataSet<Tuple2<SomeType, AnotherType> result2 =
input1.rightOuterJoin(input2, JoinHint.BROADCAST_HASH_FIRST)
.where("id").equalTo("key");
对于外连接的关联算法,与join有所不同。每种外连接只支持部分算法。如下:
LeftOuterJoin支持:
OPTIMIZER_CHOOSES
REPARTITION_SORT_MERGE
OPTIMIZER_CHOOSES
BROADCAST_HASH_FIRST
REPARTITION_HASH_FIRST
REPARTITION_SORT_MERGE
OPTIMIZER_CHOOSES
BROADCAST_HASH_SECOND
REPARTITION_HASH_SECOND
REPARTITION_SORT_MERGE
RightOuterJoin支持:
FullOuterJoin支持:
12、CoGroup
CoGroup是对分组之后的DataSet进行join操作,将两个DataSet数据集合并在一起,会先各自对每个DataSet按照key进行分组,然后将分组之后的DataSet传输到用户定义的CoGroupFunction,将两个数据集根据相同的Key记录组合在一起,相同Key的记录会存放在一个Group中,如果指定key仅在一个数据集中有记录,则co-groupFunction会将这个Group与空的Group关联。
// 用户id,购买商品名称,购买商品数量
DataSource<Tuple3<Integer,String,Integer>> source1 = env.fromElements(
Tuple3.of(1,"item1",2),
Tuple3.of(2,"item2",3),
Tuple3.of(3,"item2",4));
//商品名称与商品单价
DataSource<Tuple2<String, Integer>> source2 = env.fromElements(
Tuple2.of("item1", 10),
Tuple2.of("item2", 20),
Tuple2.of("item3", 15));
source1.coGroup(source2)
.where(1)
.equalTo(0)
.with(new CoGroupFunction<Tuple3<Integer,String,Integer>, Tuple2<String,Integer>, Tuple2<String,Double>>() {
// 每个Iterable存储的是分好组的数据,即相同key的数据组织在一起
@Override
public void coGroup(Iterable<Tuple3<Integer, String, Integer>> first, Iterable<Tuple2<String, Integer>> second, Collector<Tuple2<String, Double>> out) throws Exception {
//存储每种商品购买数量
int sum = 0;
for(Tuple3<Integer, String, Integer> val1:first){
sum += val1.f2;
}
// 每种商品数量 * 商品单价
for(Tuple2<String, Integer> val2:second){
out.collect(Tuple2.of(val2.f0,sum * val2.f1.doubleValue()));
}
}
}).print();
13、Cross
将两个数据集合并成一个数据集,返回被连接的两个数据集所有数据行的笛卡儿积,返回的数据行数等于第一个数据集中符合查询条件的数据行数乘以第二个数据集中符合查询条件的数据行数。Cross操作可以通过应用Cross Funciton将关联的数据集合并成目标格式的数据集,如果不指定Cross Funciton则返回Tuple2类型的数据集。Cross操作是计算密集型的算子,建议在使用时加上算法提示,比如crossWithTiny() and crossWithHuge().
//[id,x,y],坐标值
DataSet<Tuple3<Integer, Integer, Integer>> coords1 = env.fromElements(
Tuple3.of(1, 20, 18),
Tuple3.of(2, 15, 20),
Tuple3.of(3, 25, 10));
DataSet<Tuple3<Integer, Integer, Integer>> coords2 = env.fromElements(
Tuple3.of(1, 20, 18),
Tuple3.of(2, 15, 20),
Tuple3.of(3, 25, 10));
// 求任意两点之间的欧氏距离
coords1.cross(coords2)
.with(new CrossFunction<Tuple3<Integer, Integer, Integer>, Tuple3<Integer, Integer, Integer>, Tuple3<Integer, Integer, Double>>() {
@Override
public Tuple3<Integer, Integer, Double> cross(Tuple3<Integer, Integer, Integer> val1, Tuple3<Integer, Integer, Integer> val2) throws Exception {
// 计算欧式距离
double dist = sqrt(pow(val1.f1 - val2.f1, 2) + pow(val1.f2 - val2.f2, 2));
// 返回两点之间的欧式距离
return Tuple3.of(val1.f0,val2.f0,dist);
}
}).print();
14、Union
合并两个DataSet数据集,两个数据集的数据元素格式必须相同,多个数据集可以连续合并.
DataSet<Tuple2<String, Integer>> vals1 = env.fromElements(
Tuple2.of("jack",20),
Tuple2.of("Tom",21));
DataSet<Tuple2<String, Integer>> vals2 = env.fromElements(
Tuple2.of("Robin",25),
Tuple2.of("Bob",30));
DataSet<Tuple2<String, Integer>> vals3 = env.fromElements(
Tuple2.of("Jasper",24),
Tuple2.of("jarry",21));
DataSet<Tuple2<String, Integer>> unioned = vals1
.union(vals2)
.union(vals3);
unioned.print();
15、Rebalance
对数据集中的数据进行平均分布,使得每个分区上的数据量相同,减轻数据倾斜造成的影响,注意仅仅是Map-like类型的算子(比如map,flatMap)才可以用在Rebalance算子之后。
DataSet<String> in = // [...]
// rebalance DataSet,然后使用map算子.
DataSet<Tuple2<String, String>> out = in.rebalance()
.map(new Mapper());
16、Hash-Partition
根据给定的Key进行Hash分区,key相同的数据会被放入同一个分区内。可以使用通过元素的位置、元素的名称或者key selector函数指定key。
DataSet<Tuple2<String, Integer>> in = // [...]
// 根据第一个值进行hash分区,然后使用 MapPartition转换操作.
DataSet<Tuple2<String, String>> out = in.partitionByHash(0)
.mapPartition(new PartitionMapper());
17、Range-Partition
根据给定的Key进行Range分区,key相同的数据会被放入同一个分区内。可以使用通过元素的位置、元素的名称或者key selector函数指定key。
DataSet<Tuple2<String, Integer>> in = // [...]
// 根据第一个值进行Range分区,然后使用 MapPartition转换操作.
DataSet<Tuple2<String, String>> out = in.partitionByRange(0)
.mapPartition(new PartitionMapper());
18、Custom Partitioning
除了上面的分区外,还支持自定义分区函数。
DataSet<Tuple2<String,Integer>> in = // [...]
DataSet<Integer> result = in.partitionCustom(partitioner, key)
.mapPartition(new PartitionMapper());
19、Sort Partition
在本地对DataSet数据集中的所有分区根据指定字段进行重排序,排序方式通过Order.ASCENDING以及Order.DESCENDING关键字指定。支持指定多个字段进行分区排序,如下:
DataSet<Tuple2<String, Integer>> in = // [...]
// 按照第一个字段升序排列,第二个字段降序排列.
DataSet<Tuple2<String, String>> out = in.sortPartition(1, Order.ASCENDING)
.sortPartition(0, Order.DESCENDING)
.mapPartition(new PartitionMapper());
20、First-n
返回数据集的n条随机结果,可以应用于常规类型数据集、Grouped类型数据集以及排序数据集上。
DataSet<Tuple2<String, Integer>> in = // [...]
// 返回数据集中的任意5个元素
DataSet<Tuple2<String, Integer>> out1 = in.first(5);
//返回每个分组内的任意两个元素
DataSet<Tuple2<String, Integer>> out2 = in.groupBy(0)
.first(2);
// 返回每个分组内的前三个元素
// 分组后的数据集按照第二个字段进行升序排序
DataSet<Tuple2<String, Integer>> out3 = in.groupBy(0)
.sortGroup(1, Order.ASCENDING)
.first(3);
21、MinBy / MaxBy
从数据集中返回指定字段或组合对应最小或最大的记录,如果选择的字段具有多个相同值,则在集合中随机选择一条记录返回。
DataSet<Tuple2<String, Integer>> source = env.fromElements(
Tuple2.of("jack",20),
Tuple2.of("Tom",21),
Tuple2.of("Robin",25),
Tuple2.of("Bob",30));
// 按照第2个元素比较,找出第二个元素为最小值的那个tuple
// 在整个DataSet上使用minBy
ReduceOperator<Tuple2<String, Integer>> tuple2Reduce = source.minBy(1);
tuple2Reduce.print();// 返回(jack,20)
// 也可以在分组的DataSet上使用minBy
source.groupBy(0) // 按照第一个字段进行分组
.minBy(1) // 找出每个分组内的按照第二个元素为最小值的那个tuple
.print();
5、广播变量
1、基本概念
广播变量是分布式计算框架中经常会用到的一种数据共享方式。其主要作用是将小数据集采用网络传输的方式,在每台机器上维护一个只读的缓存变量,所在的计算节点实例均可以在本地内存中直接读取被广播的数据集,这样能够避免在数据计算过程中多次通过远程的方式从其他节点中读取小数据集,从而提升整体任务的计算性能。
广播变量可以理解为一个公共的共享变量,可以把DataSet广播出去,这样不同的task都可以读取该数据,广播的数据只会在每个节点上存一份。如果不使用广播变量,则会在每个节点上的task中都要复制一份dataset数据集,导致浪费内存。
使用广播变量的基本步骤如下:
//第一步创建需要广播的数据集
DataSet<Integer> toBroadcast = env.fromElements(1, 2, 3);
DataSet<String> data = env.fromElements("a", "b");
data.map(new RichMapFunction<String, String>() {
@Override
public void open(Configuration parameters) throws Exception {
// 第三步访问集合形式的广播变量数据集
Collection<Integer> broadcastSet = getRuntimeContext().getBroadcastVariable("broadcastSetName");
}
@Override
public String map(String value) throws Exception {
...
}
}).withBroadcastSet(toBroadcast, "broadcastSetName"); // 第二步广播数据集
从上面的代码可以看出,DataSet API支持在RichFunction接口中通过RuntimeContext读取到广播变量。
首先在RichFunction中实现Open()方法,然后调用getRuntimeContext()方法获取应用的RuntimeContext,接着调用getBroadcastVariable()方法通过广播名称获取广播变量。同时Flink直接通过collect操作将数据集转换为本地Collection。需要注意的是,Collection对象的数据类型必须和定义的数据集的类型保持一致,否则会出现类型转换问题。
注意事项:
由于广播变量的内容是保存在每个节点的内存中,所以广播变量数据集不易过大。
广播变量初始化之后,不支持修改,这样方能保证每个节点的数据都是一样的。
如果多个算子都要使用一份数据集,那么需要在多个算子的后面分别注册广播变量。
只能在批处理中使用广播变量。
2、使用Demo
public class BroadcastExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList<Tuple2<Integer,String>> RawBroadCastData = new ArrayList<>();
RawBroadCastData.add(new Tuple2<>(1,"jack"));
RawBroadCastData.add(new Tuple2<>(2,"tom"));
RawBroadCastData.add(new Tuple2<>(3,"Bob"));
// 模拟数据源,[userId,userName]
DataSource<Tuple2<Integer, String>> userInfoBroadCastData = env.fromCollection(RawBroadCastData);
ArrayList<Tuple2<Integer,Double>> rawUserAount = new ArrayList<>();
rawUserAount.add(new Tuple2<>(1,1000.00));
rawUserAount.add(new Tuple2<>(2,500.20));
rawUserAount.add(new Tuple2<>(3,800.50));
// 处理数据:用户id,用户购买金额 ,[UserId,amount]
DataSet<Tuple2<Integer, Double>> userAmount = env.fromCollection(rawUserAount);
// 转换为map集合类型的DataSet
DataSet<HashMap<Integer, String>> userInfoBroadCast = userInfoBroadCastData.map(new MapFunction<Tuple2<Integer, String>, HashMap<Integer, String>>() {
@Override
public HashMap<Integer, String> map(Tuple2<Integer, String> value) throws Exception {
HashMap<Integer, String> userInfo = new HashMap<>();
userInfo.put(value.f0, value.f1);
return userInfo;
}
});
DataSet<String> result = userAmount.map(new RichMapFunction<Tuple2<Integer, Double>, String>() {
// 存放广播变量返回的list集合数据
List<HashMap<String, String>> broadCastList = new ArrayList<>();
// 存放广播变量的值
HashMap<String, String> allMap = new HashMap<>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//获取广播数据,返回的是一个list集合
this.broadCastList = getRuntimeContext().getBroadcastVariable("userInfo");
for (HashMap<String, String> value : broadCastList) {
allMap.putAll(value);
}
}
@Override
public String map(Tuple2<Integer, Double> value) throws Exception {
String userName = allMap.get(value.f0);
return "用户id: " + value.f0 + " | "+ "用户名: " + userName + " | " + "购买金额: " + value.f1;
}
}).withBroadcastSet(userInfoBroadCast, "userInfo");
result.print();
}
}
6、分布式缓存
1、基本概念
Flink提供了一个分布式缓存(distributed cache),类似于Hadoop,以使文件在本地可被用户函数的并行实例访问。分布式缓存的工作机制是为程序注册一个文件或目录(本地或者远程文件系统,如HDFS等),通过ExecutionEnvironment注册一个缓存文件,并起一个别名。当程序执行的时候,Flink会自动把注册的文件或目录复制到所有TaskManager节点的本地文件系统,用户可以通过注册是起的别名来查找文件或目录,然后在TaskManager节点的本地文件系统访问该文件。
分布式缓存的使用步骤:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 注册一个HDFS文件
env.registerCachedFile("hdfs:///path/to/your/file", "hdfsFile")
// 注册一个本地文件
env.registerCachedFile("file:///path/to/exec/file", "localExecFile", true)
// 访问数据
getRuntimeContext().getDistributedCache().getFile("hdfsFile");
获取缓存文件的方式和广播变量相似,也是实现RichFunction接口,并通过RichFunction接口获得RuntimeContext对象,然后通过RuntimeContext提供的接口获取对应的本地缓存文件。
2、使用Demo
public class DistributeCacheExample {
public static void main(String[] args) throws Exception {
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
/**
* 注册一个本地文件
* 文件内容为:
* 1,"jack"
* 2,"tom"
* 3,"Bob"
*/
env.registerCachedFile("file:///E://userinfo.txt", "localFileUserInfo", true);
ArrayList<Tuple2<Integer,Double>> rawUserAount = new ArrayList<>();
rawUserAount.add(new Tuple2<>(1,1000.00));
rawUserAount.add(new Tuple2<>(2,500.20));
rawUserAount.add(new Tuple2<>(3,800.50));
// 处理数据:用户id,用户购买金额 ,[UserId,amount]
DataSet<Tuple2<Integer, Double>> userAmount = env.fromCollection(rawUserAount);
DataSet<String> result= userAmount.map(new RichMapFunction<Tuple2<Integer, Double>, String>() {
// 保存缓存数据
HashMap<String, String> allMap = new HashMap<String, String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 获取分布式缓存的数据
File userInfoFile = getRuntimeContext().getDistributedCache().getFile("localFileUserInfo");
List<String> userInfo = FileUtils.readLines(userInfoFile);
for (String value : userInfo) {
String[] split = value.split(",");
allMap.put(split[0], split[1]);
}
}
@Override
public String map(Tuple2<Integer, Double> value) throws Exception {
String userName = allMap.get(value.f0);
return "用户id: " + value.f0 + " | " + "用户名: " + userName + " | " + "购买金额: " + value.f1;
}
});
result.print();
}
}
7、小结
本文主要讲解了Flink DataSet API的基本使用。首先介绍了一个DataSet API的WordCount案例,接着介绍了DataSet API的数据源与Sink操作,以及基本的使用。然后对每一个转换操作进行了详细的解释,并给出了具体的使用案例。最后讲解了广播变量和分布式缓存的概念,并就如何使用这两种高级功能,提供了完整的Demo案例。
8、优化
1、广播变量
跟DataStream中的Broadcast State有些许类似
广播变量允许您将数据集提供给的operator所有并行实例,该数据集将作为集合在operator中进行访问。
注意:由于广播变量的内容保存在每个节点的内存中,因此它不应该太大。
package com.dajiangtai.batch.API;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
/**
* 广播变量的使用
*
* @author dajiangtai
* @create 2019-07-29-13:43
*/
public class BroadcastDemo {
public static void main(String[] args) throws Exception {
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//准备需要广播的数据
ArrayList<Tuple2<String,String>> broadCastData = new ArrayList<>();
broadCastData.add(new Tuple2<>("101","jack"));
broadCastData.add(new Tuple2<>("102","tom"));
broadCastData.add(new Tuple2<>("103","john"));
//读取数据源
DataSet<Tuple2<String, String>> tuple2broadCastData = env.fromCollection(broadCastData);
//数据集转换为map类型
DataSet<HashMap<String, String>> toBroadCast = tuple2broadCastData.map(new MapFunction<Tuple2<String, String>, HashMap<String, String>>() {
@Override
public HashMap<String, String> map(Tuple2<String, String> value) throws Exception {
HashMap<String, String> map = new HashMap<>();
map.put(value.f0, value.f1);
return map;
}
});
//准备处理数据
ArrayList<Tuple2<String,Integer>> operatorData = new ArrayList<>();
operatorData.add(new Tuple2<>("101",2000000));
operatorData.add(new Tuple2<>("102",190000));
operatorData.add(new Tuple2<>("103",1000000));
//读取处理数据
DataSet<Tuple2<String, Integer>> tuple2DataSource = env.fromCollection(operatorData);
DataSet<String> result = tuple2DataSource.map(new RichMapFunction<Tuple2<String, Integer>, String>() {
List<HashMap<String, String>> broadCastMap = new ArrayList<HashMap<String, String>>();
HashMap<String, String> allMap = new HashMap<String, String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//获取广播数据
this.broadCastMap = getRuntimeContext().getBroadcastVariable("broadCastName");
for (HashMap map : broadCastMap) {
allMap.putAll(map);
}
}
@Override
public String map(Tuple2<String, Integer> tuple2) throws Exception {
String name = allMap.get(tuple2.f0);
return name + "," + tuple2.f1;
}
}).withBroadcastSet(toBroadCast, "broadCastName");
result.print();
}
}
2、分布式缓存
Flink提供了类似于Apache Hadoop的分布式缓存,可以让并行用户函数实例本地化的访问文件。此功能可用
于共享包含静态外部数据(如字典或机器学习的回归模型)的文件。
工作方式如下:程序将本地或远程文件系统(如HDFS或S3)的文件或目录作为缓存文件注册到
ExecutionEnvironment中的特定名称下。当程序执行时,Flink自动将文件或目录复制到所有worker的本地文
件系统。用户函数可以查找指定名称下的文件或目录,并从worker的本地文件系统访问它
代码:
package com.dajiangtai.batch.API;
import org.apache.commons.io.FileUtils;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import java.io.File;
import java.lang.reflect.Executable;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
/**
* 分布式缓存
*
* @author dajiangtai
* @create 2019-07-29-14:16
*/
public class DistributeCacheDemo {
public static void main(String[] args) throws Exception {
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//注册一个本地可执行文件,用户基本数据
env.registerCachedFile("file:///E:\\user.txt","localFile",true);
//准备用户游戏充值数据
ArrayList<Tuple2<String,Integer>> data = new ArrayList<>();
data.add(new Tuple2<>("101",2000000));
data.add(new Tuple2<>("102",190000));
data.add(new Tuple2<>("103",1090000));
//读取数据源
DataSet<Tuple2<String, Integer>> tuple2DataSource = env.fromCollection(data);
DataSet<String> result = tuple2DataSource.map(new RichMapFunction<Tuple2<String, Integer>, String>() {
HashMap<String,String> allMap = new HashMap<String,String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
File localFile = getRuntimeContext().getDistributedCache().getFile("localFile");
List<String> lines = FileUtils.readLines(localFile);
for (String line:lines){
String[] split = line.split(",");
allMap.put(split[0],split[1]);
}
}
@Override
public String map(Tuple2<String, Integer> t) throws Exception {
String name = allMap.get(t.f0);
return name+","+t.f1;
}
});
result.print();
}
}
3、参数传递
参数传递-Constructor方式
• 可以使用constructor或withParameters(Configuration)方法将参数传递给函
数。参数被序列化为函数对象的一部分,并传送到所有并行任务实例。
参数传递-withParameters方式
参数传递-ExecutionConfig方式(全局参数)
代码:
package com.dajiangtai.batch.API;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichFilterFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FilterOperator;
import org.apache.flink.configuration.Configuration;
/**
* 参数传递
*
* @author dajiangtai
* @create 2019-07-29-14:37
*/
public class ParameterDemo {
public static void main(String[] args) throws Exception {
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取数据
DataSet<Integer> data = env.fromElements(1, 2, 3, 4, 5);
/**
* 构造方法传递参数(Constructor)
*/
//DataSet<Integer> filter = data.filter(new MyFilter(3));
//filter.print();
/**
* Configuration传递参数(withParameters)
*/
// Configuration conf = new Configuration();
// conf.setInteger("limit",3);
//
// DataSet<Integer> filter = data.filter(new RichFilterFunction<Integer>() {
// private int limit;
//
// @Override
// public void open(Configuration parameters) throws Exception {
// limit = parameters.getInteger("limit",0);
// }
//
// @Override
// public boolean filter(Integer value) throws Exception {
// return value>limit;
// }
// }).withParameters(conf);
// filter.print();
//ExecutionConfig方式(全局参数)
Configuration conf = new Configuration();
conf.setInteger("limit",3);
env.getConfig().setGlobalJobParameters(conf);
DataSet<Integer> filter = data.filter(new RichFilterFunction<Integer>() {
private int limit ;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ExecutionConfig.GlobalJobParameters globalJobParameters = getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
Configuration globalConf = (Configuration) globalJobParameters;
limit = globalConf.getInteger("limit",0);
}
@Override
public boolean filter(Integer value) throws Exception {
return value>limit;
}
});
filter.print();
}
// public static class MyFilter implements FilterFunction<Integer>{
// private int limit = 0;
//
// public MyFilter(int limit){
// this.limit = limit;
// }
//
// @Override
// public boolean filter(Integer value) throws Exception {
// return value>limit;
// }
// }
}
4、Flink DataSet 容错
重启策略-固定延时
重启策略-失败率
批处理容错
• 批处理(DataSet API)容错是基于失败重试实现的。
• Flink支持不同的重启策略,这些策略控制在出现故障时如何重新启动job
代码:
package com.dajiangtai.batch.FaultTolerance;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import java.util.concurrent.TimeUnit;
/**
* 批处理容错
*
* @author dajiangtai
* @create 2019-07-29-15:20
*/
public class FaultToleranceDemo {
public static void main(String[] args) throws Exception {
//获取一个运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
// 3,
// Time.of(10, TimeUnit.SECONDS)
// ));
env.setRestartStrategy(RestartStrategies.failureRateRestart(
2,
Time.of(1,TimeUnit.HOURS),
Time.of(10,TimeUnit.SECONDS)
));
//读取数据
DataSet<String> data = env.fromElements("1","2","","4","5");
data.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String s) throws Exception {
return Integer.parseInt(s);
}
}).print();
}
}
三、Flink DataStream API编程指南
Flink DataStream API主要分为三个部分,分别为Source、Transformation以及Sink,其中Source是数据源,Flink内置了很多数据源,比如最常用的Kafka。Transformation是具体的转换操作,主要是用户定义的处理数据的逻辑,比如Map,FlatMap等。Sink(数据汇)是数据的输出,可以把处理之后的数据输出到存储设备上,Flink内置了许多的Sink,比如Kafka,HDFS等。另外除了Flink内置的Source和Sink外,用户可以实现自定义的Source与Sink。考虑到内置的Source与Sink使用起来比较简单且方便,所以,关于内置的Source与Sink的使用方式不在本文的讨论范围之内,本文会先从自定义Source开始说起,然后详细描述一些常见算子的使用方式,最后会实现一个自定义的Sink。
1、数据源
Flink内部实现了比较常用的数据源,比如基于文件的,基于Socket的,基于集合的等等,如果这些都不能满足需求,用户可以自定义数据源,下面将会以MySQL为例,实现一个自定义的数据源。本文的所有操作将使用该数据源,具体代码如下:
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/4/14
* @Time: 17:34
* note: RichParallelSourceFunction与SourceContext必须加泛型
*/
public class MysqlSource extends RichParallelSourceFunction<UserBehavior> {
public Connection conn;
public PreparedStatement pps;
private String driver;
private String url;
private String user;
private String pass;
/**
* 该方法只会在最开始的时候被调用一次
* 此方法用于实现获取连接
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
//初始化数据库连接参数
Properties properties = new Properties();
URL fileUrl = TestProperties.class.getClassLoader().getResource("mysql.ini");
FileInputStream inputStream = new FileInputStream(new File(fileUrl.toURI()));
properties.load(inputStream);
inputStream.close();
driver = properties.getProperty("driver");
url = properties.getProperty("url");
user = properties.getProperty("user");
pass = properties.getProperty("pass");
//获取数据连接
conn = getConection();
String scanSQL = "SELECT * FROM user_behavior_log";
pps = conn.prepareStatement(scanSQL);
}
@Override
public void run(SourceContext<UserBehavior> ctx) throws Exception {
ResultSet resultSet = pps.executeQuery();
while (resultSet.next()) {
ctx.collect(UserBehavior.of(
resultSet.getLong("user_id"),
resultSet.getLong("item_id"),
resultSet.getInt("cat_id"),
resultSet.getInt("merchant_id"),
resultSet.getInt("brand_id"),
resultSet.getString("action"),
resultSet.getString("gender"),
resultSet.getLong("timestamp")));
}
}
@Override
public void cancel() {
}
/**
* 实现关闭连接
*/
@Override
public void close() {
if (pps != null) {
try {
pps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 获取数据库连接
*
* @return
* @throws SQLException
*/
public Connection getConection() throws IOException {
Connection connnection = null;
try {
//加载驱动
Class.forName(driver);
//获取连接
connnection = DriverManager.getConnection(
url,
user,
pass);
} catch (Exception e) {
e.printStackTrace();
}
return connnection;
}
}
首先继承RichParallelSourceFunction,实现继承的方法,主要包括open()方法、run()方法及close方法。上述的
RichParallelSourceFunction是支持设置多并行度的,关于RichParallelSourceFunction与RichSourceFunction的区别,前者支持用户设置多并行度,后者不支持通过setParallelism()方法设置并行度,默认的并行度为1,否则会报如下错误:bashException in thread "main" java.lang.IllegalArgumentException: The maximum parallelism of non parallel operator must be 1.
另外,RichParallelSourceFunction提供了额外的open()方法与close()方法,如果定义Source时需要获取链接,那么可以在open()方法中进行初始化,然后在close()方法中关闭资源链接,关于Rich***Function与普通Function的区别,下文会详细解释,在这里先有个印象。上述的代码中的配置信息是通过配置文件传递的,由于篇幅限制,我会把本文的代码放置在github,见文末github地址。
2、基本转换
Flink提供了大量的算子操作供用户使用,常见的算子主要包括以下几种,注意:本文不讨论关于基于时间与窗口的算子,这些内容会在《Flink基于时间与窗口的算子》中进行详细介绍。
说明:本文的操作是基于上文自定义的MySQL Source,对应的数据解释如下:
userId; // 用户ID
itemId; // 商品ID
catId; // 商品类目ID
merchantId; // 卖家ID
brandId; // 品牌ID
action; // 用户行为, 包括("pv", "buy", "cart", "fav")
gender; // 性别
timestamp; // 行为发生的时间戳,单位秒
1、Map
解释
DataStream → DataStream 的转换,输入一个元素,返回一个元素,如下操作:
SingleOutputStreamOperator<String> userBehaviorMap = userBehavior.map(new RichMapFunction<UserBehavior, String>() {
@Override
public String map(UserBehavior value) throws Exception {
String action = "";
switch (value.action) {
case "pv":
action = "浏览";
case "cart":
action = "加购";
case "fav":
action = "收藏";
case "buy":
action = "购买";
}
return action;
}
});
示意图
将雨滴形状转换成相对应的圆形形状的map操作
2、flatMap
解释
DataStream → DataStream,输入一个元素,返回零个、一个或多个元素。事实上,flatMap算子可以看做是filter与map的泛化,即它能够实现这两种操作。flatMap算子对应的FlatMapFunction定义了flatMap方法,可以通过向collector对象传递数据的方式返回0个,1个或者多个事件作为结果。如下操作:
SingleOutputStreamOperator<UserBehavior> userBehaviorflatMap = userBehavior.flatMap(new RichFlatMapFunction<UserBehavior, UserBehavior>() {
@Override
public void flatMap(UserBehavior value, Collector<UserBehavior> out) throws Exception {
if (value.gender.equals("女")) {
out.collect(value);
}
}
});
示意图
将黄色的雨滴过滤掉,将蓝色雨滴转为圆形,保留绿色雨滴
3、Filter
解释
DataStream → DataStream,过滤算子,对数据进行判断,符合条件即返回true的数据会被保留,否则被过滤。如下:
SingleOutputStreamOperator<UserBehavior> userBehaviorFilter = userBehavior.filter(new RichFilterFunction<UserBehavior>() {
@Override
public boolean filter(UserBehavior value) throws Exception {
return value.action.equals("buy");//保留购买行为的数据
}
});
示意图
将红色与绿色雨滴过滤掉,保留蓝色雨滴。
4、keyBy
解释
DataStream→KeyedStream,从逻辑上将流划分为不相交的分区。具有相同键的所有记录都分配给同一分区。在内部,keyBy()是通过哈希分区实现的。 定义键值有3中方式: (1)使用字段位置,如keyBy(1),此方式是针对元组数据类型,比如tuple,使用元组相应元素的位置来定义键值; (2)字段表达式,用于元组、POJO以及样例类; (3)键值选择器,即keySelector,可以从输入事件中提取键值
SingleOutputStreamOperator<Tuple2<String, Integer>> userBehaviorkeyBy = userBehavior.map(new RichMapFunction<UserBehavior, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(UserBehavior value) throws Exception {
return Tuple2.of(value.action.toString(), 1);
}
}).keyBy(0) // scala元组编号从1开始,java元组编号是从0开始
.sum(1); //滚动聚合
示意图
基于形状对事件进行分区的keyBy操作
5、Reduce
解释
KeyedStream → DataStream,对数据进行滚动聚合操作,结合当前元素和上一次Reduce返回的值进行聚合,然后返回一个新的值.将一个ReduceFunction应用在一个keyedStream上,每到来一个事件都会与当前reduce的结果进行聚合, 产生一个新的DataStream,该算子不会改变数据类型,因此输入流与输出流的类型永远保持一致。
SingleOutputStreamOperator<Tuple2<String, Integer>> userBehaviorReduce = userBehavior.map(new RichMapFunction<UserBehavior, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(UserBehavior value) throws Exception {
return Tuple2.of(value.action.toString(), 1);
}
}).keyBy(0) // scala元组编号从1开始,java元组编号是从0开始
.reduce(new RichReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0,value1.f1 + value2.f1);//滚动聚合,功能与sum类似
}
});
示意图
6、Aggregations(滚动聚合)
KeyedStream → DataStream,Aggregations(滚动聚合),滚动聚合转换作用于KeyedStream流上,生成一个包含聚合结果(比如sum求和,min最小值)的DataStream,滚动聚合的转换会为每个流过该算子的key值保存一个聚合结果, 当有新的元素流过该算子时,会根据之前的结果值和当前的元素值,更新相应的结果值
sum():滚动聚合流过该算子的指定字段的和;
min():滚动计算流过该算子的指定字段的最小值
max():滚动计算流过该算子的指定字段的最大值
minBy():滚动计算当目前为止流过该算子的最小值,返回该值对应的事件;
maxBy():滚动计算当目前为止流过该算子的最大值,返回该值对应的事件;
7、union
解释
DataStream* → DataStream,将多条流合并,新的的流会包括所有流的数据,值得注意的是,两个流的数据类型必须一致,另外,来自两条流的事件会以FIFO(先进先出)的方式合并,所以并不能保证两条流的顺序,此外,union算子不会对数据去重,每个输入事件都会被发送到下游算子。
userBehaviorkeyBy.union(userBehaviorReduce).print();//将两条流union在一起,可以支持多条流(大于2)的union
示意图
8、connect
解释
DataStream,DataStream → ConnectedStreams,将两个流的事件进行组合,返回一个ConnectedStreams对象,两个流的数据类型可以不一致,ConnectedStreams对象提供了类似于map(),flatMap()功能的算子,如CoMapFunction与CoFlatMapFunction分别表示map()与flatMap算子,这两个算子会分别作用于两条流,注意:CoMapFunction 或CoFlatMapFunction被调用的时候并不能控制事件的顺序只要有事件流过该算子,该算子就会被调用。
ConnectedStreams<UserBehavior, Tuple2<String, Integer>> behaviorConnectedStreams = userBehaviorFilter.connect(userBehaviorkeyBy);
SingleOutputStreamOperator<Tuple3<String, String, Integer>> behaviorConnectedStreamsmap = behaviorConnectedStreams.map(new RichCoMapFunction<UserBehavior, Tuple2<String, Integer>, Tuple3<String, String, Integer>>() {
@Override
public Tuple3<String, String, Integer> map1(UserBehavior value1) throws Exception {
return Tuple3.of("first", value1.action, 1);
}
@Override
public Tuple3<String, String, Integer> map2(Tuple2<String, Integer> value2) throws Exception {
return Tuple3.of("second", value2.f0, value2.f1);
}
});
9、split
解释
DataStream → SplitStream,将流分割成两条或多条流,与union相反。分割之后的流与输入流的数据类型一致, 对于每个到来的事件可以被路由到0个、1个或多个输出流中。可以实现过滤与复制事件的功能,DataStream.split()接收一个OutputSelector函数,用来定义分流的规则,即将满足不同条件的流分配到用户命名的一个输出。
SplitStream<UserBehavior> userBehaviorSplitStream = userBehavior.split(new OutputSelector<UserBehavior>() {
@Override
public Iterable<String> select(UserBehavior value) {
ArrayList<String> userBehaviors = new ArrayList<String>();
if (value.action.equals("buy")) {
userBehaviors.add("buy");
} else {
userBehaviors.add("other");
}
return userBehaviors;
}
});
userBehaviorSplitStream.select("buy").print();
示意图
3、Sink
Flink提供了许多内置的Sink,比如writeASText,print,HDFS,Kaka等等,下面将基于MySQL实现一个自定义的Sink,可以与自定义的MysqlSource进行对比,具体如下:
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/4/16
* @Time: 22:53
*
*/
public class MysqlSink extends RichSinkFunction<UserBehavior> {
PreparedStatement pps;
public Connection conn;
private String driver;
private String url;
private String user;
private String pass;
/**
* 在open() 方法初始化连接
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
//初始化数据库连接参数
Properties properties = new Properties();
URL fileUrl = TestProperties.class.getClassLoader().getResource("mysql.ini");
FileInputStream inputStream = new FileInputStream(new File(fileUrl.toURI()));
properties.load(inputStream);
inputStream.close();
driver = properties.getProperty("driver");
url = properties.getProperty("url");
user = properties.getProperty("user");
pass = properties.getProperty("pass");
//获取数据连接
conn = getConnection();
String insertSql = "insert into user_behavior values(?, ?, ?, ?,?, ?, ?, ?);";
pps = conn.prepareStatement(insertSql);
}
/**
* 实现关闭连接
*/
@Override
public void close() {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (pps != null) {
try {
pps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 调用invoke() 方法,进行数据插入
*
* @param value
* @param context
* @throws Exception
*/
@Override
public void invoke(UserBehavior value, Context context) throws Exception {
pps.setLong(1, value.userId);
pps.setLong(2, value.itemId);
pps.setInt(3, value.catId);
pps.setInt(4, value.merchantId);
pps.setInt(5, value.brandId);
pps.setString(6, value.action);
pps.setString(7, value.gender);
pps.setLong(8, value.timestamp);
pps.executeUpdate();
}
/**
* 获取数据库连接
*
* @return
* @throws SQLException
*/
public Connection getConnection() throws IOException {
Connection connnection = null;
try {
//加载驱动
Class.forName(driver);
//获取连接
connnection = DriverManager.getConnection(
url,
user,
pass);
} catch (Exception e) {
e.printStackTrace();
}
return connnection;
}
}
4、关于RichFunction
细心的读者可以发现,在前文的算子操作案例中,使用的都是RichFunction,因为在很多时候需要在函数处理数据之前先进行一些初始化操作,或者获取函数的上下文信息,DataStream API提供了一类RichFunction,与普通的函数相比,该函数提供了许多额外的功能。
使用RichFunction的时候,可以实现两个额外的方法:
open(),是初始化方法,会在每个人物首次调用转换方法(比如map)前调用一次。通常用于进行一次的设置工作,注意Configuration参数只在DataSet API中使用,而并没有在DataStream API中使用,因此在使用DataStream API时,可以将其忽略。
close(),函数的终止方法 ,会在每个任务最后一次调用转换方法后调用一次,通常用于资源释放等操作。
此外用户还可以通过getRuntimeContext()方法访问函数的上下文信息(RuntimeContext),例如函数的并行度,函数所在subtask的编号以及执行函数的任务名称,同时也可以访问分区状态。
5、总结
本文首先实现了自定义MySQL Source,然后基于MySql 的Source进行了一系列的算子操作,并对常见的算子操作进行详细剖析,最后实现了一个自定义MySQL Sink,并对RichFunction进行了解释。
6、Process Function详解
link的时间与watermarks详解这篇文章中,阐述了Flink的时间与水位线的相关内容。你可能不禁要发问,该如何访问时间戳和水位线呢?首先通过普通的DataStream API是无法访问的,需要借助Flink提供的一个底层的API——Process Function。Process Function不仅能够访问时间戳与水位线,而且还可以注册在将来的某个特定时间触发的计时器(timers)。除此之外,还可以将数据通过Side Outputs发送到多个输出流中。这样以来,可以实现数据分流的功能,同时也是处理迟到数据的一种方式。下面我们将从源码入手,结合具体的使用案例来说明该如何使用Process Function。
1、简介
Flink提供了很多Process Function,每种Process Function都有各自的功能,这些Process Function主要包括:
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessJoinFunction
ProcessWindowFunction
ProcessAllWindowFunction
BaseBroadcastProcessFunction
KeyedBroadcastProcessFunction
BroadcastProcessFunction
继承关系图如下:
从上面的继承关系中可以看出,都实现了RichFunction接口,所以支持使用open()、close()、getRuntimeContext()等方法的调用。从名字上可以看出,这些函数都有不同的适用场景,但是基本的功能是类似的,下面会以KeyedProcessFunction为例来讨论这些函数的通用功能。
2、源码
3、KeyedProcessFunction
/**
* 处理KeyedStream流的低级API函数
* 对于输入流中的每个元素都会触发调用processElement方法.该方法会产生0个或多个输出.
* 其实现类可以通过Context访问数据的时间戳和计时器(timers).当计时器(timers)触发时,会回调onTimer方法.
* onTimer方法会产生0个或者多个输出,并且会注册一个未来的计时器.
*
* 注意:如果要访问keyed state和计时器(timers),必须在KeyedStream上使用KeyedProcessFunction.
* 另外,KeyedProcessFunction的父类AbstractRichFunction实现了RichFunction接口,所以,可以使用
* open(),close()及getRuntimeContext()方法.
*
* @param <K> key的类型
* @param <I> 输入元素的数据类型
* @param <O> 输出元素的数据类型
*/
@PublicEvolving
public abstract class KeyedProcessFunction<K, I, O> extends AbstractRichFunction {
private static final long serialVersionUID = 1L;
/**
* 处理输入流中的每个元素
* 该方法会输出0个或者多个输出,类似于FlatMap的功能
* 除此之外,该方法还可以更新内部状态或者设置计时器(timer)
* @param value 输入元素
* @param ctx Context,可以访问输入元素的时间戳,并其可以获取一个时间服务器(TimerService),用于注册计时器(timers)并查询时间
* Context只有在processElement被调用期间有效.
* @param out 返回的结果值
* @throws Exception
*/
public abstract void processElement(I value, Context ctx, Collector<O> out) throws Exception;
/**
* 是一个回调函数,当在TimerService中注册的计时器(timers)被触发时,会回调该函数
* @param timestamp 触发计时器(timers)的时间戳
* @param ctx OnTimerContext,允许访问时间戳,TimeDomain枚举类提供了两种时间类型:
* EVENT_TIME与PROCESSING_TIME
* 并其可以获取一个时间服务器(TimerService),用于注册计时器(timers)并查询时间
* OnTimerContext只有在onTimer方法被调用期间有效
* @param out 结果输出
* @throws Exception
*/
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out) throws Exception {}
/**
* 仅仅在processElement()方法或者onTimer方法被调用期间有效
*/
public abstract class Context {
/**
* 当前被处理元素的时间戳,或者是触发计时器(timers)时的时间戳
* 该值可能为null,比如当程序中设置的时间语义为:TimeCharacteristic#ProcessingTime
* @return
*/
public abstract Long timestamp();
/**
* 访问时间和注册的计时器(timers)
* @return
*/
public abstract TimerService timerService();
/**
* 将元素输出到side output (侧输出)
* @param outputTag 侧输出的标记
* @param value 输出的记录
* @param <X>
*/
public abstract <X> void output(OutputTag<X> outputTag, X value);
/**
* 获取被处理元素的key
* @return
*/
public abstract K getCurrentKey();
}
/**
* 当onTimer方法被调用时,才可以使用OnTimerContext
*/
public abstract class OnTimerContext extends Context {
/**
* 触发计时器(timers)的时间类型,包括两种:EVENT_TIME与PROCESSING_TIME
* @return
*/
public abstract TimeDomain timeDomain();
/**
* 获取触发计时器(timer)元素的key
* @return
*/
@Override
public abstract K getCurrentKey();
}
}
上面的源码中,主要有两个方法,分析如下:
processElement(I value, Context ctx, Collector<O> out)
该方法会对流中的每条记录都调用一次,输出0个或者多个元素,类似于FlatMap的功能,通过Collector将结果发出。除此之外,该函数有一个Context 参数,用户可以通过Context 访问时间戳、当前记录的key值以及TimerService(关于TimerService,下面会详细解释)。另外还可以使用output方法将数据发送到side output,实现分流或者处理迟到数据的功能。
onTimer(long timestamp, OnTimerContext ctx, Collector<O> out)
该方法是一个回调函数,当在TimerService中注册的计时器(timers)被触发时,会回调该函数。其中@param timestamp参数表示触发计时器(timers)的时间戳,Collector可以将记录发出。细心的你可能会发现,这两个方法都有一个上下文参数,上面的方法传递的是Context 参数,onTimer方法传递的是OnTimerContext参数,这两个参数对象可以实现相似的功能。OnTimerContext还可以返回触发计时器的时间域(EVENT_TIME与PROCESSING_TIME)。
4、TimerService
在KeyedProcessFunction源码中,使用TimerService来访问时间和计时器,下面来看一下源码:
@PublicEvolving
public interface TimerService {
String UNSUPPORTED_REGISTER_TIMER_MSG = "Setting timers is only supported on a keyed streams.";
String UNSUPPORTED_DELETE_TIMER_MSG = "Deleting timers is only supported on a keyed streams.";
// 返回当前的处理时间
long currentProcessingTime();
// 返回当前event-time水位线(watermark)
long currentWatermark();
/**
* 注册一个计时器(timers),当processing time的时间等于该计时器时钟时会被调用
* @param time
*/
void registerProcessingTimeTimer(long time);
/**
* 注册一个计时器(timers),当event time的水位线(watermark)到达该时间时会被触发
* @param time
*/
void registerEventTimeTimer(long time);
/**
* 根据给定的触发时间(trigger time)来删除processing-time计时器
* 如果这个timer不存在,那么该方法不会起作用,
* 即该计时器(timer)之前已经被注册了,并且没有过时
*
* @param time
*/
void deleteProcessingTimeTimer(long time);
/**
* 根据给定的触发时间(trigger time)来删除event-time 计时器
* 如果这个timer不存在,那么该方法不会起作用,
* 即该计时器(timer)之前已经被注册了,并且没有过时
* @param time
*/
void deleteEventTimeTimer(long time);
}
TimerService提供了以下几种方法:
currentProcessingTime()
返回当前的处理时间
currentWatermark()
返回当前event-time水位线(watermark)时间戳
registerProcessingTimeTimer(long time)
针对当前key,注册一个processing time计时器(timers),当processing time的时间等于该计时器时钟时会被调用
registerEventTimeTimer(long time)
针对当前key,注册一个event time计时器(timers),当水位线时间戳大于等于该计时器时钟时会被调用
deleteProcessingTimeTimer(long time)
针对当前key,删除一个之前注册过的processing time计时器(timers),如果这个timer不存在,那么该方法不会起作用
deleteEventTimeTimer(long time)
针对当前key,删除一个之前注册过的event time计时器(timers),如果这个timer不存在,那么该方法不会起作用
当计时器触发时,会回调onTimer()函数,系统对于ProcessElement()方法和onTimer()方法的调用是同步的
注意:上面的源码中有两个Error 信息,这就说明计时器只能在keyed streams上使用,常见的用途是在某些key值不在使用后清除keyed state,或者实现一些基于时间的自定义窗口逻辑。如果要在一个非KeyedStream上使用计时器,可以使用KeySelector返回一个固定的分区值(比如返回一个常数),这样所有的数据只会发送到一个分区。
5、使用案例
下面将使用Process Function的side output功能进行分流处理,具体代码如下:
public class ProcessFunctionExample {
// 定义side output标签
static final OutputTag<UserBehaviors> buyTags = new OutputTag<UserBehaviors>("buy") {
};
static final OutputTag<UserBehaviors> cartTags = new OutputTag<UserBehaviors>("cart") {
};
static final OutputTag<UserBehaviors> favTags = new OutputTag<UserBehaviors>("fav") {
};
static class SplitStreamFunction extends ProcessFunction<UserBehaviors, UserBehaviors> {
@Override
public void processElement(UserBehaviors value, Context ctx, Collector<UserBehaviors> out) throws Exception {
switch (value.behavior) {
case "buy":
ctx.output(buyTags, value);
break;
case "cart":
ctx.output(cartTags, value);
break;
case "fav":
ctx.output(favTags, value);
break;
default:
out.collect(value);
}
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
SingleOutputStreamOperator<UserBehaviors> splitStream = env.fromElements(
new UserBehaviors(1L, "buy", "iphone"),
new UserBehaviors(1L, "cart", "huawei"),
new UserBehaviors(1L, "buy", "logi"),
new UserBehaviors(1L, "fav", "oppo"),
new UserBehaviors(2L, "buy", "huawei"),
new UserBehaviors(2L, "buy", "onemore"),
new UserBehaviors(2L, "fav", "iphone")).process(new SplitStreamFunction());
//获取分流之后购买行为的数据
splitStream.getSideOutput(buyTags).print("data_buy");
//获取分流之后加购行为的数据
splitStream.getSideOutput(cartTags).print("data_cart");
//获取分流之后收藏行为的数据
splitStream.getSideOutput(favTags).print("data_fav");
env.execute("ProcessFunctionExample");
}
}
7、总结
本文首先介绍了Flink提供的几种底层Process Function API,这些API可以访问时间戳和水位线,同时支持注册一个计时器,进行调用回调函数onTimer()。接着从源码的角度解读了这些API的共同部分,详细解释了每个方法的具体含义和使用方式。最后,给出了一个Process Function常见使用场景案例,使用其实现分流处理。除此之外,用户还可以使用这些函数,通过注册计时器,在回调函数中定义处理逻辑,使用非常的灵活。
四、Flink的Window全面解析
窗口是流式计算中非常常用的算子之一,通过窗口可以将无限流切分成有限流,然后在每个窗口之上使用计算函数,可以实现非常灵活的操作。Flink提供了丰富的窗口操作,除此之外,用户还可以根据自己的处理场景自定义窗口。通过本文,你可以了解到:
窗口的基本概念和简单使用
内置Window Assigners的分类、源码及使用
Window Function的分类及使用
窗口的组成部分及生命周期源码解读
完整的窗口使用Demo案例
1、Quick Start
1、是什么
Window(窗口)是处理无界流的核心算子,Window可以将数据流分为固定大小的”桶(buckets)”(即通过按照固定时间或长度将数据流切分成不同的窗口),在每一个窗口上,用户可以使用一些计算函数对窗口内的数据进行处理,从而得到一定时间范围内的统计结果。比如统计每隔5分钟输出最近一小时内点击量最多的前 N 个商品,这样就可以使用一个小时的时间窗口将数据限定在固定时间范围内,然后可以对该范围内的有界数据执行聚合处理。
根据作用的数据流(DataStream、KeyedStream),Window可以分为两种:Keyed Windows与Non-Keyed Windows。其中Keyed Windows是在KeyedStream上使用window(…)操作,产生一个WindowedStream。Non-Keyed Windows是在DataStream上使用windowAll(…)操作,产生一个AllWindowedStream。具体的转换关系如下图所示。注意:一般不推荐使用AllWindowedStream,因为在普通流上进行窗口操作,会将所有分区的流都汇集到单个的Task中,即并行度为1,从而会影响性能。
2、如何用
上面我们介绍了什么是窗口,那么该如何使用窗口呢?具体如下面的代码片段:
2、Keyed Windows
stream
.keyBy(...) // keyedStream上使用window
.window(...) // 必选: 指定窗口分配器( window assigner)
[.trigger(...)] // 可选: 指定触发器(trigger),如果不指定,则使用默认值
[.evictor(...)] // 可选: 指定清除器(evictor),如果不指定,则没有
[.allowedLateness(...)] // 可选: 指定是否延迟处理数据,如果不指定,默认使用0
[.sideOutputLateData(...)] // 可选: 配置side output,如果不指定,则没有
.reduce/aggregate/fold/apply() // 必选: 指定窗口计算函数
[.getSideOutput(...)] // 可选: 从side output中获取数据
3、Non-Keyed Windows
stream
.windowAll(...) // 必选: 指定窗口分配器( window assigner)
[.trigger(...)] // 可选: 指定触发器(trigger),如果不指定,则使用默认值
[.evictor(...)] // 可选: 指定清除器(evictor),如果不指定,则没有
[.allowedLateness(...)] // 可选: 指定是否延迟处理数据,如果不指定,默认使用0
[.sideOutputLateData(...)] // 可选: 配置side output,如果不指定,则没有
.reduce/aggregate/fold/apply() // 必选: 指定窗口计算函数
[.getSideOutput(...)] // 可选: 从side output中获取数据
4、简写window操作
上面的代码片段中,要在keyedStream上使用window(…)或者在DataStream上使用windowAll(…),需要传入一个window assigner的参数,关于window assigner下文会进行详细解释。如下面代码片段:
// -------------------------------------------
// Keyed Windows
// -------------------------------------------
stream
.keyBy(id)
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // 5S的滚动窗口
.reduce(MyReduceFunction)
// -------------------------------------------
// Non-Keyed Windows
// -------------------------------------------
stream
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))) // 5S的滚动窗口
.reduce(MyReduceFunction)
上面的代码可以简写为:
// -------------------------------------------
// Keyed Windows
// -------------------------------------------
stream
.keyBy(id)
.timeWindow(Time.seconds(5)) // 5S的滚动窗口
.reduce(MyReduceFunction)
// -------------------------------------------
// Non-Keyed Windows
// -------------------------------------------
stream
.timeWindowAll(Time.seconds(5)) // 5S的滚动窗口
.reduce(MyReduceFunction)
关于上面的简写,以KeyedStream为例,对于看一下具体的KeyedStream源码片段,可以看出底层调用的还是非简写时的代码。关于timeWindowAll()的代码也是一样的,可以参考DataStream源码,这里不再赘述。
//会根据用户的使用的时间类型,调用不同的内置window Assigner
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(TumblingProcessingTimeWindows.of(size));
} else {
return window(TumblingEventTimeWindows.of(size));
}
}
5、Window Assigners
1、分类
WindowAssigner负责将输入的数据分配到一个或多个窗口,Flink内置了许多WindowAssigner,这些WindowAssigner可以满足大部分的使用场景。比如tumbling windows, sliding windows, session windows , global windows。如果这些内置的WindowAssigner不能满足你的需求,可以通过继承WindowAssigner类实现自定义的WindowAssigner。
上面的WindowAssigner是基于时间的(time-based windows),除此之外,Flink还提供了基于数量的窗口(count-based windows),即根据窗口的元素数量定义窗口大小,这种情况下,如果数据存在乱序,将导致窗口计算结果不确定。本文重点介绍基于时间的窗口使用,由于篇幅有限,关于基于数量的窗口将不做讨论。
2、使用介绍
下面将会对Flink内置的四种基于时间的windowassigner,进行一一分析。
3、Tumbling Windows
图解
Tumbling Windows(滚动窗口)是将数据分配到确定的窗口中,根据固定时间或大小进行切分,每个窗口有固定的大小且窗口之间不存在重叠(如下图所示)。这种比较简单,适用于按照周期统计某一指标的场景。
关于时间的选择,可以使用Event Time或者Processing Time,分别对应的window assigner为:TumblingEventTimeWindows、TumblingProcessingTimeWindows。用户可以使用window assigner的of(size)方法指定时间间隔,其中时间单位可以是Time.milliseconds(x)、Time.seconds(x)或Time.minutes(x)等。
使用
// 使用EventTime
datastream
.keyBy(id)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new MyProcessFunction())
// 使用processing-time
datastream
.keyBy(id)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.process(new MyProcessFunction())
4、Sliding Windows
图解
Sliding Windows(滑动窗口)在滚动窗口之上加了一个滑动窗口的时间,这种类型的窗口是会存在窗口重叠的(如下图所示)。滚动窗口是按照窗口固定的时间大小向前滚动,而滑动窗口是根据设定的滑动时间向前滑动。窗口之间的重叠部分的大小取决于窗口大小与滑动的时间大小,当滑动时间小于窗口时间大小时便会出现重叠。当滑动时间大于窗口时间大小时,会出现窗口不连续的情况,导致数据可能不属于任何一个窗口。当两者相等时,其功能就和滚动窗口相同了。滑动窗口的使用场景是:用户根据设定的统计周期来计算指定窗口时间大小的指标,比如每隔5分钟输出最近一小时内点击量最多的前 N 个商品。
关于时间的选择,可以使用Event Time或者Processing Time,分别对应的window assigner为:SlidingEventTimeWindows、SlidingProcessingTimeWindows。用户可以使用window assigner的of(size)方法指定时间间隔,其中时间单位可以是Time.milliseconds(x)、Time.seconds(x)或Time.minutes(x)等。
使用
// 使用EventTime
datastream
.keyBy(id)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.process(new MyProcessFunction())
// 使用processing-time
datastream
.keyBy(id)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.process(new MyProcessFunction())
5、Session Windows
图解
Session Windows(会话窗口)主要是将某段时间内活跃度较高的数据聚合成一个窗口进行计算,窗口的触发的条件是Session Gap,是指在规定的时间内如果没有数据活跃接入,则认为窗口结束,然后触发窗口计算结果。需要注意的是如果数据一直不间断地进入窗口,也会导致窗口始终不触发的情况。与滑动窗口、滚动窗口不同的是,Session Windows不需要有固定窗口大小(window size)和滑动时间(slide time),只需要定义session gap,来规定不活跃数据的时间上限即可。如下图所示。Session Windows窗口类型比较适合非连续型数据处理或周期性产生数据的场景,根据用户在线上某段时间内的活跃度对用户行为数据进行统计。
关于时间的选择,可以使用Event Time或者Processing Time,分别对应的window assigner为:EventTimeSessionWindows和ProcessTimeSessionWindows。用户可以使用window assigner的withGap()方法指定时间间隔,其中时间单位可以是Time.milliseconds(x)、Time.seconds(x)或Time.minutes(x)等。
使用
// 使用EventTime
datastream
.keyBy(id)
.window((EventTimeSessionWindows.withGap(Time.minutes(15)))
.process(new MyProcessFunction())
// 使用processing-time
datastream
.keyBy(id)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(15)))
.process(new MyProcessFunction())
注意:由于session window的开始时间与结束时间取决于接收的数据。windowassigner不会立即分配所有的元素到正确的窗口,SessionWindow会为每个接收的元素初始化一个以该元素的时间戳为开始时间的窗口,使用session gap作为窗口大小,然后再合并重叠部分的窗口。所以, session window 操作需要指定用于合并的 Trigger和 Window Function,比如ReduceFunction, AggregateFunction, or ProcessWindowFunction。
6、Global Windows
图解
Global Windows(全局窗口)将所有相同的key的数据分配到单个窗口中计算结果,窗口没有起始和结束时间,窗口需要借助于Triger来触发计算,如果不对Global Windows指定Triger,窗口是不会触发计算的。因此,使用Global Windows需要非常慎重,用户需要非常明确自己在整个窗口中统计出的结果是什么,并指定对应的触发器,同时还需要有指定相应的数据清理机制,否则数据将一直留在内存中。
使用
datastream
.keyBy(id)
.window(GlobalWindows.create())
.process(new MyProcessFunction())
6、Window Functions
1、分类
Flink提供了两大类窗口函数,分别为增量聚合函数和全量窗口函数。其中增量聚合函数的性能要比全量窗口函数高,因为增量聚合窗口是基于中间结果状态计算最终结果的,即窗口中只维护一个中间结果状态,不要缓存所有的窗口数据。相反,对于全量窗口函数而言,需要对所以进入该窗口的数据进行缓存,等到窗口触发时才会遍历窗口内所有数据,进行结果计算。如果窗口数据量比较大或者窗口时间较长,就会耗费很多的资源缓存数据,从而导致性能下降。
增量聚合函数
包括:ReduceFunction、AggregateFunction和FoldFunction
全量窗口函数
包括:ProcessWindowFunction
2、使用介绍
3、ReduceFunction
输入两个相同类型的数据元素按照指定的计算方法进行聚合,然后输出类型相同的一个结果元素。要求输入元素的数据类型与输出元素的数据类型必须一致。实现的效果是使用上一次的结果值与当前值进行聚合。具体使用案例如下:
public class ReduceFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 模拟数据源
SingleOutputStreamOperator<Tuple3<Long, Integer, Long>> input = env.fromElements(
Tuple3.of(1L, 10, 1588491228L),
Tuple3.of(1L, 15, 1588491229L),
Tuple3.of(1L, 20, 1588491238L),
Tuple3.of(1L, 25, 1588491248L),
Tuple3.of(2L, 10, 1588491258L),
Tuple3.of(2L, 30, 1588491268L),
Tuple3.of(2L, 20, 1588491278L)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Integer, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Integer, Long> element) {
return element.f2 * 1000;
}
});
input
.map(new MapFunction<Tuple3<Long, Integer, Long>, Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> map(Tuple3<Long, Integer, Long> value) {
return Tuple2.of(value.f0, value.f1);
}
})
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> reduce(Tuple2<Long, Integer> value1, Tuple2<Long, Integer> value2) throws Exception {
// 根据第一个元素分组,求第二个元素的累计和
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}).print();
env.execute("ReduceFunctionExample");
}
}
4、AggregateFunction
与ReduceFunction相似,AggregateFunction也是基于中间状态计算结果的增量计算函数,相比ReduceFunction,AggregateFunction在窗口计算上更加灵活,但是实现稍微复杂,需要实现AggregateFunction接口,重写四个方法。其最大的优势就是中间结果的数据类型和最终的结果类型不依赖于输入的数据类型。关于AggregateFunction的源码,如下所示:
/**
* @param <IN> 输入元素的数据类型
* @param <ACC> 中间聚合结果的数据类型
* @param <OUT> 最终聚合结果的数据类型
*/@PublicEvolvingpublic interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
/**
* 创建一个新的累加器
*/
ACC createAccumulator();
/**
* 将新的数据与累加器进行聚合,返回一个新的累加器
*/
ACC add(IN value, ACC accumulator);
/**
从累加器中计算最终结果并返回
*/
OUT getResult(ACC accumulator);
/**
* 合并两个累加器并返回结果
*/
ACC merge(ACC a, ACC b);}
具体使用代码案例如下:
public class AggregateFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 模拟数据源
SingleOutputStreamOperator<Tuple3<Long, Integer, Long>> input = env.fromElements(
Tuple3.of(1L, 10, 1588491228L),
Tuple3.of(1L, 15, 1588491229L),
Tuple3.of(1L, 20, 1588491238L),
Tuple3.of(1L, 25, 1588491248L),
Tuple3.of(2L, 10, 1588491258L),
Tuple3.of(2L, 30, 1588491268L),
Tuple3.of(2L, 20, 1588491278L)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Integer, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Integer, Long> element) {
return element.f2 * 1000;
}
});
input.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new MyAggregateFunction()).print();
env.execute("AggregateFunctionExample");
}
private static class MyAggregateFunction implements AggregateFunction<Tuple3<Long, Integer, Long>,Tuple2<Long,Integer>,Tuple2<Long,Integer>> {
/**
* 创建一个累加器,初始化值
* @return
*/
@Override
public Tuple2<Long, Integer> createAccumulator() {
return Tuple2.of(0L,0);
}
/**
*
* @param value 输入的元素值
* @param accumulator 中间结果值
* @return
*/
@Override
public Tuple2<Long, Integer> add(Tuple3<Long, Integer, Long> value, Tuple2<Long, Integer> accumulator) {
return Tuple2.of(value.f0,value.f1 + accumulator.f1);
}
/**
* 获取计算结果值
* @param accumulator
* @return
*/
@Override
public Tuple2<Long, Integer> getResult(Tuple2<Long, Integer> accumulator) {
return Tuple2.of(accumulator.f0,accumulator.f1);
}
/**
* 合并中间结果值
* @param a 中间结果值a
* @param b 中间结果值b
* @return
*/
@Override
public Tuple2<Long, Integer> merge(Tuple2<Long, Integer> a, Tuple2<Long, Integer> b) {
return Tuple2.of(a.f0,a.f1 + b.f1);
}
}
}
5、FoldFunction
FoldFunction定义了如何将窗口中的输入元素与外部的元素合并的逻辑,该接口已标记过时,建议用户使用AggregateFunction来替换使用FoldFunction。
public class FoldFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 模拟数据源
SingleOutputStreamOperator<Tuple3<Long, Integer, Long>> input = env.fromElements(
Tuple3.of(1L, 10, 1588491228L),
Tuple3.of(1L, 15, 1588491229L),
Tuple3.of(1L, 20, 1588491238L),
Tuple3.of(1L, 25, 1588491248L),
Tuple3.of(2L, 10, 1588491258L),
Tuple3.of(2L, 30, 1588491268L),
Tuple3.of(2L, 20, 1588491278L)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Integer, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Integer, Long> element) {
return element.f2 * 1000;
}
});
input.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.fold("用户",new FoldFunction<Tuple3<Long, Integer, Long>,String>() {
@Override
public String fold(String accumulator, Tuple3<Long, Integer, Long> value) throws Exception {
// 为第一个元素的值拼接一个"用户"字符串,进行输出
return accumulator + value.f0 ;
}
}).print();
env.execute("FoldFunctionExample");
}
}
6、ProcessWindowFunction
前面提到的ReduceFunction和AggregateFunction都是基于中间状态实现增量计算的窗口函数。有些时候需要使用整个窗口的所有数据进行计算,比如求中位数和众数。另外,ProcessWindowFunction的Context对象可以访问窗口的一些元数据信息,比如窗口结束时间、水位线等。ProcessWindowsFunction能够更加灵活地支持基于窗口全部数据元素的结果计算。
在系统内部,由ProcessWindowFunction处理的窗口会将所有已分配的数据存储到ListState中,通过将数据收集起来且提供对于窗口的元数据及其他一些特性的访问和使用,应用场景比ReduceFunction和AggregateFunction更加广泛。关于ProcessWindowFunction抽象类的源码,如下所示:
/**
* @param <IN> 输入的数据类型
* @param <OUT> 输出的数据类型
* @param <KEY> key的数据类型
* @param <W> window的类型
*/@PublicEvolvingpublic abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> extends AbstractRichFunction {
private static final long serialVersionUID = 1L;
/**
* 计算窗口数据,输出0个或多个元素
* @param key 窗口的key
* @param context 窗口的上下文
* @param elements 窗口内的所有元素
* @param out 输出元素的collector对象
* @throws Exception
*/
public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;
/**
* 当窗口被销毁时,删除状态
* @param context
* @throws Exception
*/
public void clear(Context context) throws Exception {}
//context可以访问窗口的元数据信息.
public abstract class Context implements java.io.Serializable {
//返回当前被计算的窗口
public abstract W window();
// 返回当前processing time.
public abstract long currentProcessingTime();
// 返回当前event-time 水位线.
public abstract long currentWatermark();
//每个key和每个window的状态访问器
public abstract KeyedStateStore windowState();
// 每个key的global state的状态访问器.
public abstract KeyedStateStore globalState();
/**
* 向side output输出数据
* @param outputTag the {@code OutputTag} side output 输出的标识.
* @param value 输出的数据.
*/
public abstract <X> void output(OutputTag<X> outputTag, X value);
}}
具体的使用案例如下:
public class ProcessWindowFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 模拟数据源
SingleOutputStreamOperator<Tuple3<Long, Integer, Long>> input = env.fromElements(
Tuple3.of(1L, 10, 1588491228L),
Tuple3.of(1L, 15, 1588491229L),
Tuple3.of(1L, 20, 1588491238L),
Tuple3.of(1L, 25, 1588491248L),
Tuple3.of(2L, 10, 1588491258L),
Tuple3.of(2L, 30, 1588491268L),
Tuple3.of(2L, 20, 1588491278L)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Integer, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Integer, Long> element) {
return element.f2 * 1000;
}
});
input.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new MyProcessWindowFunction())
.print();
}
private static class MyProcessWindowFunction extends ProcessWindowFunction<Tuple3<Long, Integer, Long>,Tuple3<Long,String,Integer>,Long,TimeWindow> {
@Override
public void process(
Long aLong,
Context context,
Iterable<Tuple3<Long, Integer, Long>> elements,
Collector<Tuple3<Long, String, Integer>> out) throws Exception {
int count = 0;
for (Tuple3<Long, Integer, Long> in: elements) {
count++;
}
// 统计每个窗口数据个数,加上窗口输出
out.collect(Tuple3.of(aLong,"" + context.window(),count));
}
}
}
7、增量聚合函数和ProcessWindowFunction整合
ProcessWindowFunction提供了很强大的功能,但是唯一的缺点就是需要更大的状态存储数据。在很多时候,增量聚合的使用是非常频繁的,那么如何实现既支持增量聚合又支持访问窗口元数据的操作呢?可以将ReduceFunction和AggregateFunction与ProcessWindowFunction整合在一起使用。通过这种组合方式,分配给窗口的元素会立即被执行计算,当窗口触发时,会把聚合的结果传给ProcessWindowFunction,这样ProcessWindowFunction的process方法的Iterable参数被就只有一个值,即增量聚合的结果。
ReduceFunction与ProcessWindowFunction组合
public class ReduceProcessWindowFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 模拟数据源
SingleOutputStreamOperator<Tuple3<Long, Integer, Long>> input = env.fromElements(
Tuple3.of(1L, 10, 1588491228L),
Tuple3.of(1L, 15, 1588491229L),
Tuple3.of(1L, 20, 1588491238L),
Tuple3.of(1L, 25, 1588491248L),
Tuple3.of(2L, 10, 1588491258L),
Tuple3.of(2L, 30, 1588491268L),
Tuple3.of(2L, 20, 1588491278L)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Integer, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Integer, Long> element) {
return element.f2 * 1000;
}
});
input.map(new MapFunction<Tuple3<Long, Integer, Long>, Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> map(Tuple3<Long, Integer, Long> value) {
return Tuple2.of(value.f0, value.f1);
}
})
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new MyReduceFunction(),new MyProcessWindowFunction())
.print();
env.execute("ProcessWindowFunctionExample");
}
private static class MyReduceFunction implements ReduceFunction<Tuple2<Long, Integer>> {
@Override
public Tuple2<Long, Integer> reduce(Tuple2<Long, Integer> value1, Tuple2<Long, Integer> value2) throws Exception {
//增量求和
return Tuple2.of(value1.f0,value1.f1 + value2.f1);
}
}
private static class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<Long,Integer>,Tuple3<Long,Integer,String>,Long,TimeWindow> {
@Override
public void process(Long aLong, Context ctx, Iterable<Tuple2<Long, Integer>> elements, Collector<Tuple3<Long, Integer, String>> out) throws Exception {
// 将求和之后的结果附带窗口结束时间一起输出
out.collect(Tuple3.of(aLong,elements.iterator().next().f1,"window_end" + ctx.window().getEnd()));
}
}
AggregateFunction与ProcessWindowFunction组合
public class AggregateProcessWindowFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 模拟数据源
SingleOutputStreamOperator<Tuple3<Long, Integer, Long>> input = env.fromElements(
Tuple3.of(1L, 10, 1588491228L),
Tuple3.of(1L, 15, 1588491229L),
Tuple3.of(1L, 20, 1588491238L),
Tuple3.of(1L, 25, 1588491248L),
Tuple3.of(2L, 10, 1588491258L),
Tuple3.of(2L, 30, 1588491268L),
Tuple3.of(2L, 20, 1588491278L))
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Integer, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Integer, Long> element) {
return element.f2 * 1000;
}
});
input.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new MyAggregateFunction(),new MyProcessWindowFunction())
.print();
env.execute("AggregateFunctionExample");
}
private static class MyAggregateFunction implements AggregateFunction<Tuple3<Long, Integer, Long>, Tuple2<Long, Integer>, Tuple2<Long, Integer>> {
/**
* 创建一个累加器,初始化值
*
* @return
*/
@Override
public Tuple2<Long, Integer> createAccumulator() {
return Tuple2.of(0L, 0);
}
/**
* @param value 输入的元素值
* @param accumulator 中间结果值
* @return
*/
@Override
public Tuple2<Long, Integer> add(Tuple3<Long, Integer, Long> value, Tuple2<Long, Integer> accumulator) {
return Tuple2.of(value.f0, value.f1 + accumulator.f1);
}
/**
* 获取计算结果值
*
* @param accumulator
* @return
*/
@Override
public Tuple2<Long, Integer> getResult(Tuple2<Long, Integer> accumulator) {
return Tuple2.of(accumulator.f0, accumulator.f1);
}
/**
* 合并中间结果值
*
* @param a 中间结果值a
* @param b 中间结果值b
* @return
*/
@Override
public Tuple2<Long, Integer> merge(Tuple2<Long, Integer> a, Tuple2<Long, Integer> b) {
return Tuple2.of(a.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<Long,Integer>,Tuple3<Long,Integer,String>,Long,TimeWindow> {
@Override
public void process(Long aLong, Context ctx, Iterable<Tuple2<Long, Integer>> elements, Collector<Tuple3<Long, Integer, String>> out) throws Exception {
// 将求和之后的结果附带窗口结束时间一起输出
out.collect(Tuple3.of(aLong,elements.iterator().next().f1,"window_end" + ctx.window().getEnd()));
}
}
}
7、window 生命周期解读
1、生命周期图解
窗口从创建到执行窗口计算再到被清除,需要经过一系列的过程,这个过程就是窗口的生命周期。
首先,当一个元素进入窗口算子之前,会由WindowAssigner分配该元素进入哪个或哪几个窗口,如果窗口不存在,则创建窗口。
其次,数据进入了窗口,这时要看有没有使用增量聚合函数,如果使用了增量聚合函数ReduceFunction或AggregateFunction,新加入窗口的元素会立即触发增量计算,计算的结果作为窗口的内容。如果没有使用增量聚合函数,则会将进入窗口的数据存储到ListState状态中,进一步等待窗口触发时,遍历窗口元素进行聚合计算。
然后,每个元素在进入窗口之后会传递至该窗口的触发器,触发器决定了窗口何时被执行计算及何时需要清除自身和保存的内容。触发器可以根据已分配的元素或注册的计时器来决定某些特定时刻执行窗口计算或清除窗口内容。
最后,触发器成功触发之后的操作取决于使用的窗口函数,如果使用的是增量聚合函数,如ReduceFunction或AggregateFunction,则会直接输出聚合的结果。如果只包含一个全量窗口函数,如ProcessWindowFunction,则会作用窗口的所有元素,执行计算,输出结果。如果组合使用了ReduceFunction和ProcessWindowFunction,即组合使用了增量聚合窗口函数和全量窗口函数,全量窗口函数会作用于增量聚合函数的聚合值,然后再输出最终的结果。
情况1:仅使用增量聚合窗口函数
情况2:仅使用全量窗口函数
情况3:组合使用增量聚合窗口函数与全量窗口函数
2、分配器(Window Assigners)
WindowAssigner的作用是将输入的元素分配到一个或多个窗口,当WindowAssigner将第一个元素分配到窗口时,就会创建该窗口,所以一个窗口一旦被创建,窗口中必然至少有一个元素。Flink内置了很多WindowAssigners,本文主要讨论基于时间的WindowAssigners,这些分配器都继承了WindowAssigner抽象类。关于常用的分配器,上文已经做了详细解释。下面先来看一下继承关系图:
接下来,将会对WindowAssigner抽象类的源码进行分析,具体代码如下:
/**
* WindowAssigner分配一个元素到0个或多个窗口
* 在一个窗口算子内部,元素是按照key进行分组的(使用KeyedStream),
* 相同key和window的元素集合称之为一个pane(格子)
* @param <T> 要分配元素的数据类型
* @param <W> window的类型:TimeWindow、GlobalWindow
*/@PublicEvolvingpublic abstract class WindowAssigner<T, W extends Window> implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 返回一个向其分配元素的窗口集合
* @param element 待分配的元素
* @param timestamp 元素的时间戳
* @param context WindowAssignerContext对象
* @return
*/
public abstract Collection<W> assignWindows(T element, long timestamp, WindowAssignerContext context);
/**
* 返回一个与该WindowAssigner相关的默认trigger(触发器)
* @param env 执行环境
* @return
*/
public abstract Trigger<T, W> getDefaultTrigger(StreamExecutionEnvironment env);
/**
* 返回一个窗口序列化器
* @param executionConfig
* @return
*/
public abstract TypeSerializer<W> getWindowSerializer(ExecutionConfig executionConfig);
/**
* 如果元素是基于event time分配到窗口的,则返回true
* @return
*/
public abstract boolean isEventTime();
/**
* 该Context允许访问当前的处理时间processing time
*/
public abstract static class WindowAssignerContext {
/**
* 返回当前的处理时间
*/
public abstract long getCurrentProcessingTime();
}}
8、触发器(Triggers)
数据接入窗口后,窗口是否触发WindowFunciton计算,取决于窗口是否满足触发条件。Triggers就是决定窗口何时触发计算并输出结果的条件,Triggers可以根据时间或者具体的数据条件进行触发,比如进入窗口元素的个数或者进入窗口的某些特定的元素值等。前面讨论的内置WindowAssigner都有各自默认的触发器,当使用的是Processing Time时,则当处理时间超过窗口结束时间时会被触发。当使用Event Time时,当水位线超过窗口结束时间时会被触发。
Flink在内部提供很多内置的触发器,常用的主要有EventTimeTrigger、ProcessTimeTrigger以及CountTrigger等。每种每种触发器都对应于不同的Window Assigner,例如Event Time类型的Windows对应的触发器是EventTimeTrigger,其基本原理是判断当前的Watermark是否超过窗口的EndTime,如果超过则触发对窗口内数据的计算,反之不触发计算。关于上面分析的内置WindowAssigner的默认trigger,可以从各自的源码中看到,具体罗列如下:
关于这些内置的Trigger的具体解释如下:
这些Trigger都继承了Trigger抽象类,具体的继承关系,如下图:
关于抽象类Trigger的源码解释如下:
/**
* @param <T> 元素的数据类型
* @param <W> Window的类型
*/@PublicEvolvingpublic abstract class Trigger<T, W extends Window> implements Serializable {
private static final long serialVersionUID = -4104633972991191369L;
/**
* 每个元素被分配到窗口时都会调用该方法,返回一个TriggerResult枚举
* 该枚举包含很多触发的类型:CONTINUE、FIRE_AND_PURGE、FIRE、PURGE
*
* @param element 进入窗口的元素
* @param timestamp 进入窗口元素的时间戳
* @param window 窗口
* @param ctx 上下文对象,可以注册计时器(timer)回调函数
* @return
* @throws Exception
*/
public abstract TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception;
/**
* 当使用TriggerContext注册的processing-time计时器被触发时,会调用该方法
*
* @param time 触发计时器的时间戳
* @param window 计时器触发的window
* @param ctx 上下文对象,可以注册计时器(timer)回调函数
* @return
* @throws Exception
*/
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception;
/**
* 当使用TriggerContext注册的event-time计时器被触发时,会调用该方法
*
* @param time 触发计时器的时间戳
* @param window 计时器触发的window
* @param ctx 上下文对象,可以注册计时器(timer)回调函数
* @return
* @throws Exception
*/
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception;
/**
* 如果触发器支持合并触发器状态,将返回true
*
* @return
*/
public boolean canMerge() {
return false;
}
/**
* 当多个窗口被合并成一个窗口时,会调用该方法
*
* @param window 合并之后的window
* @param ctx 上下文对象,可以注册计时器回调函数,也可以访问状态
* @throws Exception
*/
public void onMerge(W window, OnMergeContext ctx) throws Exception {
throw new UnsupportedOperationException("This trigger does not support merging.");
}
/**
* 清除所有Trigger持有的窗口状态
* 当窗口被销毁时,调用该方法
*
* @param window
* @param ctx
* @throws Exception
*/
public abstract void clear(W window, TriggerContext ctx) throws Exception;
/**
* Context对象,传给Trigger的方法参数中,用于注册计时器回调函数和处理状态
*/
public interface TriggerContext {
// 返回当前处理时间
long getCurrentProcessingTime();
MetricGroup getMetricGroup();
// 返回当前水位线时间戳
long getCurrentWatermark();
// 注册一个processing-time的计时器
void registerProcessingTimeTimer(long time);
// 注册一个EventTime计时器
void registerEventTimeTimer(long time);
// 删除一个processing-time的计时器
void deleteProcessingTimeTimer(long time);
// 删除一个EventTime计时器
void deleteEventTimeTimer(long time);
/**
* 提取状态当前Trigger的窗口和Key的状态
*/
<S extends State> S getPartitionedState(StateDescriptor<S, ?> stateDescriptor);
// 与getPartitionedState功能相同,该方法已被标记过时
@Deprecated
<S extends Serializable> ValueState<S> getKeyValueState(String name, Class<S> stateType, S defaultState);
// 同getPartitionedState功能,该方法已被标记过时
@Deprecated
<S extends Serializable> ValueState<S> getKeyValueState(String name, TypeInformation<S> stateType, S defaultState);
}
// TriggerContext的扩展
public interface OnMergeContext extends TriggerContext {
// 合并每个window的状态,状态必须支持合并
<S extends MergingState<?, ?>> void mergePartitionedState(StateDescriptor<S, ?> stateDescriptor);
}}
上面的源码可以看出,每当触发器调用时,会产生一个TriggerResult对象,该对象是一个枚举类,其包括的属性决定了作用在窗口上的操作是什么。总共有四种行为:CONTINUE、FIRE_AND_PURGE、FIRE、PURGE,关于每种类型的具体含义,我们先看一下TriggerResult源码:
/**
* 触发器方法的结果类型,决定在窗口上执行什么操作,比如是否调用window function
* 或者是否需要销毁窗口
* 注意:如果一个Trigger返回的是FIRE或者FIRE_AND_PURGE,但是窗口中没有任何元素,则窗口函数不会被调用
*/public enum TriggerResult {
// 什么都不做,当前不触发计算,继续等待
CONTINUE(false, false),
// 执行 window function,输出结果,之后清除所有状态
FIRE_AND_PURGE(true, true),
// 执行 window function,输出结果,窗口不会被清除,数据继续保留
FIRE(true, false),
// 清除窗口内部数据,但不触发计算
PURGE(false, true);}
9、清除器(Evictors)
Evictors是一个可选的组件,其主要作用是对进入WindowFuction前后的数据进行清除处理。Flink内置了三种Evictors:分别为CountEvictor、DeltaEvictor、TimeEvitor。如果用户不指定Evictors,也不会有默认值。
CountEvictor:保持在窗口中具有固定数量的元素,将超过指定窗口元素数量的数据在窗口计算前剔除;
DeltaEvictor:通过定义DeltaFunction和指定threshold,并计算Windows中的元素与最新元素之间的Delta大小,如果超过threshold则将当前数据元素剔除;
TimeEvictor:通过指定时间间隔,将当前窗口中最新元素的时间减去Interval,然后将小于该结果的数据全部剔除,其本质是将具有最新时间的数据选择出来,删除过时的数据。
Evictors继承关系图如下:
关于Evictors接口的源码,如下:
/**
* 在WindowFunction计算之前或者之后进行清除窗口元素
* @param <T> 元素的数据类型
* @param <W> 窗口类型
*/@PublicEvolvingpublic interface Evictor<T, W extends Window> extends Serializable {
/**
* 选择性剔除元素,在windowing function之前调用
* @param elements 窗口中的元素
* @param size 窗口中元素个数
* @param window 窗口
* @param evictorContext
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* 选择性剔除元素,在windowing function之后调用
* @param elements 窗口中的元素.
* @param size 窗口中元素个数.
* @param window 窗口
* @param evictorContext
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
// 传递给Evictor方法参数的值
interface EvictorContext {
// 返回当前processing time
long getCurrentProcessingTime();
MetricGroup getMetricGroup();
// 返回当前的水位线时间戳
long getCurrentWatermark();
}}
10、小结
本文首先给出了窗口使用的快速入门,介绍了窗口的基本概念、分类及简单使用。然后对Flink内置的Window Assigner进行了一一解读,并给出了图解与使用的代码片段。接着对Flink的Window Function进行介绍,包括窗口函数的分类及详细使用案例。最后分析了Window生命周期所涉及的组件,并对每个组件的源码进行分析。
五、Flink的状态后端(State Backends)
当使用checkpoint时,状态(state)会被持久化到checkpoint上,以防止数据的丢失并确保发生故障时能够完全恢复。状态是通过什么方式在哪里持久化,取决于使用的状态后端。
1、可用的状态后端
MemoryStateBackend
FsStateBackend
FsStateBackend
注意:如果什么都不配置,系统默认的是MemoryStateBackend
2、MemoryStateBackend
MemoryStateBackend 是将状态维护在 Java 堆上的一个内部状态后端。键值状态和窗口算子使用哈希表来存储数据(values)和定时器(timers)。当应用程序 checkpoint 时,此后端会在将状态发给 JobManager 之前快照下状态,JobManager 也将状态存储在 Java 堆上。默认情况下,MemoryStateBackend 配置成支持异步快照。异步快照可以避免阻塞数据流的处理,从而避免反压的发生。当然,使用 new MemoryStateBackend(MAX_MEM_STATE_SIZE, false)也可以禁用该特点。
缺点:
默认情况下,每一个状态的大小限制为 5 MB。可以通过 MemoryStateBackend 的构造函数增加这个大小。状态大小受到 akka 帧大小的限制(maxStateSize <= akka.framesize 默认 10 M),所以无论怎么调整状态大小配置,都不能大于 akka 的帧大小。也可以通过 akka.framesize 调整 akka 帧大小。
状态的总大小不能超过 JobManager 的内存。
推荐使用的场景:
本地测试、几乎无状态的作业,比如 ETL、JobManager 不容易挂,或挂掉影响不大的情况。
不推荐在生产场景使用。
3、FsStateBackend
FsStateBackend`需要配置的主要是文件系统,如 URL(类型,地址,路径)。比如可以是:`“hdfs://namenode:40010/flink/checkpoints”` 或`“s3://flink/checkpoints”
当选择使用 FsStateBackend时,正在进行的数据会被存在TaskManager的内存中。在checkpoint时,此后端会将状态快照写入配置的文件系统和目录的文件中,同时会在JobManager的内存中(在高可用场景下会存在 Zookeeper 中)存储极少的元数据。容量限制上,单 TaskManager 上 State 总量不超过它的内存,总大小不超过配置的文件系统容量。
默认情况下,FsStateBackend 配置成提供异步快照,以避免在状态 checkpoint 时阻塞数据流的处理。该特性可以实例化 FsStateBackend 时传入false的布尔标志来禁用掉,例如:new FsStateBackend(path, false)
推荐使用的场景:
处理大状态,长窗口,或大键值状态的有状态处理任务, 例如分钟级窗口聚合或 join。
适合用于高可用方案(需要开启HA的作业)。
可以在生产环境中使用
4、RocksDBStateBackend
RocksDBStateBackend 的配置也需要一个文件系统(类型,地址,路径),如下所示:“hdfs://namenode:40010/flink/checkpoints” 或“s3://flink/checkpoints”RocksDB 是一种嵌入式的本地数据库。RocksDBStateBackend 将处理中的数据使用 RocksDB 存储在本地磁盘上。在 checkpoint 时,整个 RocksDB 数据库会被存储到配置的文件系统中,或者在超大状态作业时可以将增量的数据存储到配置的文件系统中。同时 Flink 会将极少的元数据存储在 JobManager 的内存中,或者在 Zookeeper 中(对于高可用的情况)。RocksDB 默认也是配置成异步快照的模式。
RocksDB是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意RocksDB不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。不过RocksDB支持增量的 Checkpoint,也是目前唯一增量 Checkpoint 的 Backend,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单Key最大2G,总大小不超过配置的文件系统容量即可。
缺点:
RocksDB支持的单key和单value的大小最大为每个 2^31 字节。这是因为 RocksDB 的 JNI API 是基于byte[]的。
对于使用具有合并操作的状态的应用程序,例如 ListState,随着时间可能会累积到超过 2^31 字节大小,这将会导致在接下来的查询中失败。
推荐使用的场景:
最适合用于处理大状态,长窗口,或大键值状态的有状态处理任务。
非常适合用于高可用方案。
最好是对状态读写性能要求不高的作业
5、总结
那如何选择状态的类型和存储方式?结合前面的内容,可以看到,首先是要分析清楚业务场景;比如想要做什么,状态到底大不大。比较各个方案的利弊,选择根据需求合适的状态类型和存储方式即可。
六、Flink内部Exactly Once三板斧:状态、状态后端与检查点
Flink是一个分布式的流处理引擎,而流处理的其中一个特点就是7X24。那么,如何保障Flink作业的持续运行呢?Flink的内部会将应用状态(state)存储到本地内存或者嵌入式的kv数据库(RocksDB)中,由于采用的是分布式架构,Flink需要对本地生成的状态进行持久化存储,以避免因应用或者节点机器故障等原因导致数据的丢失,Flink是通过checkpoint(检查点)的方式将状态写入到远程的持久化存储,从而就可以实现不同语义的结果保障。通过本文,你可以了解到什么是Flink的状态,Flink的状态是怎么存储的,Flink可选择的状态后端(statebackend)有哪些,什么是全局一致性检查点,Flink内部如何通过检查点实现Exactly Once的结果保障。另外,本文内容较长,建议关注加收藏。
1、什么是状态
1、引子
关于什么是状态,我们先不做过多的分析。首先看一个代码案例,其中案例1是Spark的WordCount代码,案例2是Flink的WorkCount代码。
案例1:Spark WC
object WordCount {
def main(args:Array[String]){
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()}}
输入:
C:\WINDOWS\system32>nc -lp 9999
hello spark
hello spark
输出:
案例2:Flink WC
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStreamSource<String> streamSource = env.socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String,Integer>> words = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String,Integer>> out) throws Exception {
String[] splits = value.split("\\s");
for (String word : splits) {
out.collect(Tuple2.of(word, 1));
}
}
});
words.keyBy(0).sum(1).print();
env.execute("WC");
}}
输入:
C:\WINDOWS\system32>nc -lp 9999
hello Flink
hello Flink
输出:
从上面的两个例子可以看出,在使用Spark进行词频统计时,当前的统计结果不受历史统计结果的影响,只计算接收的当前数据的结果,这个就可以理解为无状态的计算。再来看一下Flink的例子,可以看出当第二次词频统计时,把第一次的结果值也统计在了一起,即Flink把上一次的计算结果保存在了状态里,第二次计算的时候会先拿到上一次的结果状态,然后结合新到来的数据再进行计算,这就可以理解成有状态的计算,如下图所示。
2、状态的类别
Flink提供了两种基本类型的状态:分别是 Keyed State和Operator State。根据不同的状态管理方式,每种状态又有两种存在形式,分别为:managed(托管状态)和raw(原生状态)。具体如下表格所示。需要注意的是,由于Flink推荐使用managed state,所以下文主要讨论managed state,对于raw state,本文不会做过多的讨论。
3、managed state & raw state区别
4、Keyed State & Operator State
5、Keyed State
Keyed State只能由作用在KeyedStream上面的函数使用,该状态与某个key进行绑定,即每一个key对应一个state。Keyed State按照key进行维护和访问的,Flink会为每一个Key都维护一个状态实例,该状态实例总是位于处理该key记录的算子任务上,因此同一个key的记录可以访问到一样的状态。如下图所示,可以通过在一条流上使用keyBy()方法来生成一个KeyedStream。Flink提供了很多种keyed state,具体如下:
ValueState<T>
用于保存类型为T的单个值。用户可以通过ValueState.value()来获取该状态值,通过ValueState.update()来更新该状态。使用ValueStateDescriptor来获取状态句柄。
ListState<T>
用于保存类型为T的元素列表,即key的状态值是一个列表。用户可以使用ListState.add()或者ListState.addAll()将新元素添加到列表中,通过ListState.get()访问状态元素,该方法会返回一个可遍历所有元素的Iterable<T>对象,注意ListState不支持删除单个元素,但是用户可以使用update(List<T> values)来更新整个列表。使用 ListStateDescriptor来获取状态句柄。
ReducingState<T>
调用add()方法添加值时,会立即返回一个使用ReduceFunction聚合后的值,用户可以使用ReducingState.get()来获取该状态值。使用 ReducingStateDescriptor来获取状态句柄。
AggregatingState<IN, OUT>
与ReducingState<T>类似,不同的是它使用的是AggregateFunction来聚合内部的值,AggregatingState.get()方法会计算最终的结果并将其返回。使用 AggregatingStateDescriptor来获取状态句柄
MapState<UK, UV>
用于保存一组key、value的映射,类似于java的Map集合。用户可以通过get(UK key)方法获取key对应的状态,可以通过put(UK k,UV value)方法添加一个键值,可以通过remove(UK key)删除给定key的值,可以通过contains(UK key)判断是否存在对应的key。使用 MapStateDescriptor来获取状态句柄。
FoldingState<T, ACC>
在Flink 1.4的版本中标记过时,在未来的版本中会被移除,使用AggregatingState进行代替。
值得注意的是,上面的状态原语都支持通过State.clear()方法来进行清除状态。另外,上述的状态原语仅用于与状态进行交互,真正的状态是存储在状态后端(后面会介绍状态后端)的,通过该状态原语相当于持有了状态的句柄(handle)。
6、keyed State使用案例
下面给出一个MapState的使用案例,关于ValueState的使用情况可以参考官网,具体如下:
public class MapStateExample {
//统计每个用户每种行为的个数
public static class UserBehaviorCnt extends RichFlatMapFunction<Tuple3<Long, String, String>, Tuple3<Long, String, Integer>> {
//定义一个MapState句柄
private transient MapState<String, Integer> behaviorCntState;
// 初始化状态
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
MapStateDescriptor<String, Integer> userBehaviorMapStateDesc = new MapStateDescriptor<>(
"userBehavior", // 状态描述符的名称
TypeInformation.of(new TypeHint<String>() {}), // MapState状态的key的数据类型
TypeInformation.of(new TypeHint<Integer>() {}) // MapState状态的value的数据类型
);
behaviorCntState = getRuntimeContext().getMapState(userBehaviorMapStateDesc); // 获取状态
}
@Override
public void flatMap(Tuple3<Long, String, String> value, Collector<Tuple3<Long, String, Integer>> out) throws Exception {
Integer behaviorCnt = 1;
// 如果当前状态包括该行为,则+1
if (behaviorCntState.contains(value.f1)) {
behaviorCnt = behaviorCntState.get(value.f1) + 1;
}
// 更新状态
behaviorCntState.put(value.f1, behaviorCnt);
out.collect(Tuple3.of(value.f0, value.f1, behaviorCnt));
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
DataStreamSource<Tuple3<Long, String, String>> userBehaviors = env.fromElements(
Tuple3.of(1L, "buy", "iphone"),
Tuple3.of(1L, "cart", "huawei"),
Tuple3.of(1L, "buy", "logi"),
Tuple3.of(1L, "fav", "oppo"),
Tuple3.of(2L, "buy", "huawei"),
Tuple3.of(2L, "buy", "onemore"),
Tuple3.of(2L, "fav", "iphone"));
userBehaviors
.keyBy(0)
.flatMap(new UserBehaviorCnt())
.print();
env.execute("MapStateExample");
}}
结果输出:
7、状态的生命周期管理(TTL)
对于任何类型Keyed State都可以设定状态的生命周期(TTL),即状态的存活时间,以确保能够在规定时间内及时地清理状态数据。如果配置了状态的TTL,那么当状态过期时,存储的状态会被清除。状态生命周期功能可以通过StateTtlConfig配置,然后将StateTtlConfig配置传入StateDescriptor中的enableTimeToLive方法中即可。代码示例如下:
StateTtlConfig ttlConfig = StateTtlConfig
// 指定TTL时长为10S
.newBuilder(Time.seconds(10))
// 只对创建和写入操作有效
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 不返回过期的数据
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
// 初始化状态
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
MapStateDescriptor<String, Integer> userBehaviorMapStateDesc = new MapStateDescriptor<>(
"userBehavior", // 状态描述符的名称
TypeInformation.of(new TypeHint<String>() {}), // MapState状态的key的数据类型
TypeInformation.of(new TypeHint<Integer>() {}) // MapState状态的value的数据类型
);
// 设置stateTtlConfig
userBehaviorMapStateDesc.enableTimeToLive(ttlConfig);
behaviorCntState = getRuntimeContext().getMapState(userBehaviorMapStateDesc); // 获取状态
}
在StateTtlConfig创建时,newBuilder方法是必须要指定的,newBuilder中设定过期时间的参数。对于其他参数都是可选的或使用默认值。其中setUpdateType方法中传入的类型有三种:
public enum UpdateType {
//禁用TTL,永远不会过期
Disabled,
// 创建和写入时更新TTL
OnCreateAndWrite,
// 与OnCreateAndWrite类似,但是在读操作时也会更新TTL
OnReadAndWrite
}
值得注意的是,过期的状态数据根据UpdateType参数进行配置,只有被写入或者读取的时间才会更新TTL,也就是说如果某个状态指标一直不被使用或者更新,则永远不会触发对该状态数据的清理操作,这种情况可能会导致系统中的状态数据越来越大。目前用户可以使用StateTtlConfig.cleanupFullSnapshot设定当触发State Snapshot的时候清理状态数据,但是改配置不适合用于RocksDB做增量Checkpointing的操作。
上面的StateTtlConfig创建时,可以指定setStateVisibility,用于状态的可见性配置,根据过期数据是否被清理来确定是否返回状态数据。
/**
* 是否返回过期的数据
*/
public enum StateVisibility {
//如果数据没有被清理,就可以返回
ReturnExpiredIfNotCleanedUp,
//永远不返回过期的数据,默认值
NeverReturnExpired
}
8、Operator State
Operator State的作用于是某个算子任务,这意味着所有在同一个并行任务之内的记录都能访问到相同的状态 。算子状态不能通过其他任务访问,无论该任务是相同的算子。如下图所示。
Operator State是一种non-keyed state,与并行的操作算子实例相关联,例如在Kafka Connector中,每个Kafka消费端算子实例都对应到Kafka的一个分区中,维护Topic分区和Offsets偏移量作为算子的Operator State。在Flink中可以实现ListCheckpointed<T extends Serializable>接口或者CheckpointedFunction 接口来实现一个Operator State。
首先,我们先看一下这两个接口的具体实现,然后再给出这两种接口的具体使用案例。先看一下ListCheckpointed接口的源码,如下:
public interface ListCheckpointed<T extends Serializable> {
/**
* 获取某个算子实例的当前状态,该状态包括该算子实例之前被调用时的所有结果
* 以列表的形式返回一个函数状态的快照
* Flink触发生成检查点时调用该方法
* @param checkpointId checkpoint的ID,是一个唯一的、单调递增的值
* @param timestamp Job Manager触发checkpoint时的时间戳
* @return 返回一个operator state list,如果为null时,返回空list
* @throws Exception
*/
List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
/**
* 初始化函数状态时调用,可能是在作业启动时或者故障恢复时
* 根据提供的列表恢复函数状态
* 注意:当实现该方法时,需要在RichFunction#open()方法之前调用该方法
* @param state 被恢复算子实例的state列表 ,可能为空
* @throws Exception
*/
void restoreState(List<T> state) throws Exception;}
使用Operator ListState时,在进行扩缩容时,重分布的策略(状态恢复的模式)如下图所示:
上面的重分布策略为Even-split Redistribution,即每个算子实例中含有部分状态元素的List列表,整个状态数据是所有List列表的合集。当触发restore/redistribution动作时,通过将状态数据平均分配成与算子并行度相同数量的List列表,每个task实例中有一个List,其可以为空或者含有多个元素。
我们再来看一下CheckpointedFunction接口,源码如下:
public interface CheckpointedFunction {
/**
* 会在生成检查点之前调用
* 该方法的目的是确保检查点开始之前所有状态对象都已经更新完毕
* @param context 使用FunctionSnapshotContext作为参数
* 从FunctionSnapshotContext可以获取checkpoint的元数据信息,
* 比如checkpoint编号,JobManager在初始化checkpoint时的时间戳
* @throws Exception
*/
void snapshotState(FunctionSnapshotContext context) throws Exception;
/**
* 在创建checkpointedFunction的并行实例时被调用,
* 在应用启动或者故障重启时触发该方法的调用
* @param context 传入FunctionInitializationContext对象,
* 可以使用该对象访问OperatorStateStore和 KeyedStateStore对象,
* 这两个对象可以获取状态的句柄,即通过Flink runtime来注册函数状态并返回state对象
* 比如:ValueState、ListState等
* @throws Exception
*/
void initializeState(FunctionInitializationContext context) throws Exception;}
CheckpointedFunction接口是用于指定有状态函数的最底层的接口,该接口提供了用于注册和维护keyed state 与operator state的hook(即可以同时使用keyed state 和operator state),另外也是唯一支持使用list union state。关于Union List State,使用的是Flink为Operator state提供的另一种重分布的策略:Union Redistribution,即每个算子实例中含有所有状态元素的List列表,当触发restore/redistribution动作时,每个算子都能够获取到完整的状态元素列表。具体如下图所示:
9、ListCheckpointed
ListCheckpointed接口和CheckpointedFunction接口相比在灵活性上相对弱一些,只能支持List类型的状态,并且在数据恢复的时候仅支持even-redistribution策略。该接口不像Flink提供的Keyed State(比如Value State、ListState)那样直接在状态后端(state backend)注册,需要将operator state实现为成员变量,然后通过接口提供的回调函数与状态后端进行交互。使用代码案例如下
public class ListCheckpointedExample {
private static class UserBehaviorCnt extends RichFlatMapFunction<Tuple3<Long, String, String>, Tuple2<String, Long>> implements ListCheckpointed<Long> {
private Long userBuyBehaviorCnt = 0L;
@Override
public void flatMap(Tuple3<Long, String, String> value, Collector<Tuple2<String, Long>> out) throws Exception {
if(value.f1.equals("buy")){
userBuyBehaviorCnt ++;
out.collect(Tuple2.of("buy",userBuyBehaviorCnt));
}
}
@Override
public List<Long> snapshotState(long checkpointId, long timestamp) throws Exception {
//返回单个元素的List集合,该集合元素是用户购买行为的数量
return Collections.singletonList(userBuyBehaviorCnt);
}
@Override
public void restoreState(List<Long> state) throws Exception {
// 在进行扩缩容之后,进行状态恢复,需要把其他subtask的状态加在一起
for (Long cnt : state) {
userBuyBehaviorCnt += 1;
}
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
DataStreamSource<Tuple3<Long, String, String>> userBehaviors = env.fromElements(
Tuple3.of(1L, "buy", "iphone"),
Tuple3.of(1L, "cart", "huawei"),
Tuple3.of(1L, "buy", "logi"),
Tuple3.of(1L, "fav", "oppo"),
Tuple3.of(2L, "buy", "huawei"),
Tuple3.of(2L, "buy", "onemore"),
Tuple3.of(2L, "fav", "iphone"));
userBehaviors
.flatMap(new UserBehaviorCnt())
.print();
env.execute("ListCheckpointedExample");
}
}
10、CheckpointedFunction
CheckpointedFunction接口提供了更加丰富的操作,比如支持Union list state,可以访问keyedState,关于重分布策略,如果使用Even-split Redistribution策略,则通过context. getListState(descriptor)获取Operator State;如果使用UnionRedistribution策略,则通过context. getUnionList State(descriptor)来获取。使用案例如下:
public class CheckpointFunctionExample {
private static class UserBehaviorCnt implements CheckpointedFunction, FlatMapFunction<Tuple3<Long, String, String>, Tuple3<Long, Long, Long>> {
// 统计每个operator实例的用户行为数量的本地变量
private Long opUserBehaviorCnt = 0L;
// 每个key的state,存储key对应的相关状态
private ValueState<Long> keyedCntState;
// 定义operator state,存储算子的状态
private ListState<Long> opCntState;
@Override
public void flatMap(Tuple3<Long, String, String> value, Collector<Tuple3<Long, Long, Long>> out) throws Exception {
if (value.f1.equals("buy")) {
// 更新算子状态本地变量值
opUserBehaviorCnt += 1;
Long keyedCount = keyedCntState.value();
// 更新keyedstate的状态 ,判断状态是否为null,否则空指针异常
keyedCntState.update(keyedCount == null ? 1L : keyedCount + 1 );
// 结果输出
out.collect(Tuple3.of(value.f0, keyedCntState.value(), opUserBehaviorCnt));
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// 使用opUserBehaviorCnt本地变量更新operator state
opCntState.clear();
opCntState.add(opUserBehaviorCnt);
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// 通过KeyedStateStore,定义keyedState的StateDescriptor描述符
ValueStateDescriptor valueStateDescriptor = new ValueStateDescriptor("keyedCnt", TypeInformation.of(new TypeHint<Long>() {
}));
// 通过OperatorStateStore,定义OperatorState的StateDescriptor描述符
ListStateDescriptor opStateDescriptor = new ListStateDescriptor("opCnt", TypeInformation.of(new TypeHint<Long>() {
}));
// 初始化keyed state状态值
keyedCntState = context.getKeyedStateStore().getState(valueStateDescriptor);
// 初始化operator state状态
opCntState = context.getOperatorStateStore().getListState(opStateDescriptor);
// 初始化本地变量operator state
for (Long state : opCntState.get()) {
opUserBehaviorCnt += state;
}
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
DataStreamSource<Tuple3<Long, String, String>> userBehaviors = env.fromElements(
Tuple3.of(1L, "buy", "iphone"),
Tuple3.of(1L, "cart", "huawei"),
Tuple3.of(1L, "buy", "logi"),
Tuple3.of(1L, "fav", "oppo"),
Tuple3.of(2L, "buy", "huawei"),
Tuple3.of(2L, "buy", "onemore"),
Tuple3.of(2L, "fav", "iphone"));
userBehaviors
.keyBy(0)
.flatMap(new UserBehaviorCnt())
.print();
env.execute("CheckpointFunctionExample");
}
}
11、什么是状态后端
上面使用的状态都需要存储到状态后端(StateBackend),然后在checkpoint触发时,将状态持久化到外部存储系统。Flink提供了三种类型的状态后端,分别是基于内存的状态后端(MemoryStateBackend、基于文件系统的状态后端(FsStateBackend)以及基于RockDB作为存储介质的RocksDB StateBackend。这三种类型的StateBackend都能够有效地存储Flink流式计算过程中产生的状态数据,在默认情况下Flink使用的是MemoryStateBackend,区别见下表。下面分别对每种状态后端的特点进行说明。
12、状态后端的类别
MemoryStateBackend
MemoryStateBackend将状态数据全部存储在JVM堆内存中,包括用户在使用DataStream API中创建的Key/Value State,窗口中缓存的状态数据,以及触发器等数据。MemoryStateBackend具有非常快速和高效的特点,但也具有非常多的限制,最主要的就是内存的容量限制,一旦存储的状态数据过多就会导致系统内存溢出等问题,从而影响整个应用的正常运行。同时如果机器出现问题,整个主机内存中的状态数据都会丢失,进而无法恢复任务中的状态数据。因此从数据安全的角度建议用户尽可能地避免在生产环境中使用MemoryStateBackend。Flink将MemoryStateBackend作为默认状态后端。
MemoryStateBackend比较适合用于测试环境中,并用于本地调试和验证,不建议在生产环境中使用。但如果应用状态数据量不是很大,例如使用了大量的非状态计算算子,也可以在生产环境中使MemoryStateBackend.
FsStateBackend
FsStateBackend是基于文件系统的一种状态后端,这里的文件系统可以是本地文件系统,也可以是HDFS分布式文件系统。创建FsStateBackend的构造函数如下:
FsStateBackend(Path checkpointDataUri, boolean asynchronousSnapshots)
其中path如果为本地路径,其格式为“file:///data/flink/checkpoints”,如果path为HDFS路径,其格式为“hdfs://nameservice/flink/checkpoints”。FsStateBackend中第二个Boolean类型的参数指定是否以同步的方式进行状态数据记录,默认采用异步的方式将状态数据同步到文件系统中,异步方式能够尽可能避免在Checkpoint的过程中影响流式计算任务。如果用户想采用同步的方式进行状态数据的检查点数据,则将第二个参数指定为True即可。
相比于MemoryStateBackend, FsStateBackend更适合任务状态非常大的情况,例如应用中含有时间范围非常长的窗口计算,或Key/value State状态数据量非常大的场景,这时系统内存不足以支撑状态数据的存储。同时FsStateBackend最大的好处是相对比较稳定,在checkpoint时,将状态持久化到像HDFS分布式文件系统中,能最大程度保证状态数据的安全性。
RocksDBStateBackend
与前面的状态后端不同,RocksDBStateBackend需要单独引入相关的依赖包。RocksDB 是一个 key/value 的内存存储系统,类似于HBase,是一种内存磁盘混合的 LSM DB。当写数据时会先写进write buffer(类似于HBase的memstore),然后在flush到磁盘文件,当读取数据时会现在block cache(类似于HBase的block cache),所以速度会很快。
RocksDBStateBackend在性能上要比FsStateBackend高一些,主要是因为借助于RocksDB存储了最新热数据,然后通过异步的方式再同步到文件系统中,但RocksDBStateBackend和MemoryStateBackend相比性能就会较弱一些。
需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。不过 RocksDB 支持增量的 Checkpoint,也是目前唯一增量 Checkpoint 的 Backend,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。对于超大状态的作业,例如天级窗口聚合等场景下可以使会用该状态后端。
13、配置状态后端
Flink默认使用的状态后端是MemoryStateBackend,所以不需要显示配置。对于其他的状态后端,都需要进行显性配置。在Flink中包含了两种级别的StateBackend配置:一种是在程序中进行配置,该配置只对当前应用有效;另外一种是通过 flink-conf.yaml进行全局配置,一旦配置就会对整个Flink集群上的所有应用有效。
应用级别配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
如果使用RocksDBStateBackend则需要单独引入rockdb依赖库,如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope></dependency>
使用方式与FsStateBackend类似,如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints"));
集群级别配置
具体的配置项在flink-conf.yaml文件中,如下代码所示,参数state.backend指明StateBackend类型,state.checkpoints.dir配置具体的状态存储路径,代码中使用filesystem作为StateBackend,然后指定相应的HDFS文件路径作为state的checkpoint文件夹。
# 使用filesystem存储
state.backend: filesystem
# checkpoint存储路径
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
如果想用RocksDBStateBackend配置集群级别的状态后端,可以使用下面的配置:
# 操作RocksDBStateBackend的线程数量,默认值为1
state.backend.rocksdb.checkpoint.transfer.thread.num: 1# 指定RocksDB存储状态数据的本地文件路径
state.backend.rocksdb.localdir: /var/rockdb/checkpoints
# 用于指定定时器服务的工厂类实现类,默认为“HEAP”,也可以指定为“RocksDB”
state.backend.rocksdb.timer-service.factory: HEAP
14、什么是Checkpoint(检查点)
上面讲解了Flink的状态以及状态后端,状态是存储在状态后端。为了保证state容错,Flink提供了处理故障的措施,这种措施称之为checkpoint(一致性检查点)。checkpoint是Flink实现容错的核心功能,主要是周期性地触发checkpoint,将state生成快照持久化到外部存储系统(比如HDFS)。这样一来,如果Flink程序出现故障,那么就可以从上一次checkpoint中进行状态恢复,从而提供容错保障。另外,通过checkpoint机制,Flink可以实现Exactly-once语义(Flink内部的Exactly-once,关于端到端的exactly_once,Flink是通过两阶段提交协议实现的)。下面将会详细分析Flink的checkpoint机制。
15、检查点的生成
如上图,输入流是用户行为数据,包括购买(buy)和加入购物车(cart)两种,每种行为数据都有一个偏移量,统计每种行为的个数。
第一步:JobManager checkpoint coordinator 触发checkpoint。
第二步:假设当消费到[cart,3]这条数据时,触发了checkpoint。那么此时数据源会把消费的偏移量3写入持久化存储。
第三步:当写入结束后,source会将state handle(状态存储路径)反馈给JobManager的checkpoint coordinator。
第四步:接着算子count buy与count cart也会进行同样的步骤
第五步:等所有的算子都完成了上述步骤之后,即当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件,那么整个checkpoint也就完成了,如果中间有一个不成功,那么本次checkpoin就宣告失败。
16、检查点的恢复
通过上面的分析,或许你已经对Flink的checkpoint有了初步的认识。那么接下来,我们看一下是如何从检查点恢复的。
任务失败
重启作业
恢复检查点
继续处理数据
上述过程具体总结如下:
第一步:重启作业
第二步:从上一次检查点恢复状态数据
第三步:继续处理新的数据
17、Flink内部Exactly-Once实现
Flink提供了精确一次的处理语义,精确一次的处理语义可以理解为:数据可能会重复计算,但是结果状态只有一个。Flink通过Checkpoint机制实现了精确一次的处理语义,Flink在触发Checkpoint时会向Source端插入checkpoint barrier,checkpoint barriers是从source端插入的,并且会向下游算子进行传递。checkpoint barriers携带一个checkpoint ID,用于标识属于哪一个checkpoint,checkpoint barriers将流逻辑是哪个分为了两部分。对于双流的情况,通过barrier对齐的方式实现精确一次的处理语义。
关于什么是checkpoint barrier,可以看一下CheckpointBarrier类的源码描述,如下:
/**
* Checkpoint barriers用来在数据流中实现checkpoint对齐的.
* Checkpoint barrier由JobManager的checkpoint coordinator插入到Source中,
* Source会把barrier广播发送到下游算子,当一个算子接收到了其中一个输入流的Checkpoint barrier时,
* 它就会知道已经处理完了本次checkpoint与上次checkpoint之间的数据.
*
* 一旦某个算子接收到了所有输入流的checkpoint barrier时,
* 意味着该算子的已经处理完了截止到当前checkpoint的数据,
* 可以触发checkpoint,并将barrier向下游传递
*
* 根据用户选择的处理语义,在checkpoint完成之前会缓存后一次checkpoint的数据,
* 直到本次checkpoint完成(exactly once)
*
* checkpoint barrier的id是严格单调递增的
*
*/
public class CheckpointBarrier extends RuntimeEvent {...}
可以看出checkpoint barrier主要功能是实现checkpoint对齐的,从而可以实现Exactly-Once处理语义。
下面将会对checkpoint过程进行分解,具体如下:
图1,包括两个流,每个任务都会消费一条用户行为数据(包括购买(buy)和加购(cart)),数字代表该数据的偏移量,count buy任务统计购买行为的个数,coun cart统计加购行为的个数。
图2,触发checkpoint,JobManager会向每个数据源发送一个新的checkpoint编号,以此来启动检查点生成流程。
图3,当Source任务收到消息后,会停止发出数据,然后利用状态后端触发生成本地状态检查点,并把该checkpoint barrier以及checkpoint id广播至所有传出的数据流分区。状态后端会在checkpoint完成之后通知任务,随后任务会向Job Manager发送确认消息。在将checkpoint barrier发出之后,Source任务恢复正常工作。
图4,Source任务发出的checkpoint barrier会发送到与之相连的下游算子任务,当任务收到一个新的checkpoint barrier时,会继续等待其他输入分区的checkpoint barrier到来,这个过程称之为barrier 对齐,checkpoint barrier到来之前会把到来的数据线缓存起来。
图5,任务收齐了全部输入分区的checkpoint barrier之后,会通知状态后端开始生成checkpoint,同时会把checkpoint barrier广播至下游算子。
图6,任务在发出checkpoint barrier之后,开始处理因barrier对齐产生的缓存数据,在缓存的数据处理完之后,就会继续处理输入流数据。
图7,最终checkpoint barrier会被传送到sink端,sink任务接收到checkpoint barrier之后,会向其他算子任务一样,将自身的状态写入checkpoint,之后向Job Manager发送确认消息。Job Manager接收到所有任务返回的确认消息之后,就会将此次检查点标记为完成。
18、使用案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// checkpoint的时间间隔,如果状态比较大,可以适当调大该值
env.enableCheckpointing(1000);
// 配置处理语义,默认是exactly-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两个checkpoint之间的最小时间间隔,防止因checkpoint时间过长,导致总结
本文首先从Flink的状态入手,通过Spark的WordCount和Flink的Work Count进行说明什么是状态。接着对状态的分类以及状态的使用进行了详细说明。然后对Flink提供的三种状态后端进行讨论,并给出了状态后端的使用说明。最后,以图解加文字的形式详细解释了Flink的checkpoint机制,并给出了使用Checkpoint时的程序配置。checkpoint积压
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// checkpoint执行的上限时间,如果超过该阈值,则会中断checkpoint
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 最大并行执行的检查点数量,默认为1,可以指定多个,从而同时出发多个checkpoint,提升效率
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 设定周期性外部检查点,将状态数据持久化到外部系统中,
// 使用该方式不会在任务正常停止的过程中清理掉检查点数据
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
19、总结
本文首先从Flink的状态入手,通过Spark的WordCount和Flink的Work Count进行说明什么是状态。接着对状态的分类以及状态的使用进行了详细说明。然后对Flink提供的三种状态后端进行讨论,并给出了状态后端的使用说明。最后,以图解加文字的形式详细解释了Flink的checkpoint机制,并给出了使用Checkpoint时的程序配置。
七、Flink的时间与watermarks详解
当我们在使用Flink的时候,避免不了要和时间(time)、水位线(watermarks)打交道,理解这些概念是开发分布式流处理应用的基础。那么Flink支持哪些时间语义?Flink是如何处理乱序事件的?什么是水位线?水位线是如何生成的?水位线的传播方式是什么?让我们带着这些问题来开始本文的内容。
1、时间语义
1、基本概念
时间是Flink等流处理中最重要的概念之一,在 Flink 中 Time 可以分为三种:Event-Time,Processing-Time 以及 Ingestion-Time,如下图所示:
Event Time
事件时间,事件(Event)本身的时间,即数据流中事件实际发生的时间,通常使用事件发生时的时间戳来描述,这些事件的时间戳通常在进入流处理应用之前就已经存在了,事件时间反映了事件真实的发生时间。所以,基于事件时间的计算操作,其结果是具有确定性的,无论数据流的处理速度如何、事件到达算子的顺序是否会乱,最终生成的结果都是一样的。
Ingestion Time
摄入时间,事件进入Flink的时间,即将每一个事件在数据源算子的处理时间作为事件时间的时间戳,并自动生成水位线(watermarks,关于watermarks下文会详细分析)。
Ingestion Time从概念上讲介于Event Time和Processing Time之间。与Processing Time相比 ,它的性能消耗更多一些,但结果却更可预测。由于 Ingestion Time使用稳定的时间戳(在数据源处分配了一次),因此对记录的不同窗口操作将引用相同的时间戳,而在Processing Time中每个窗口算子都可以将记录分配给不同的窗口。
与Event Time相比,Ingestion Time无法处理任何乱序事件或迟到的数据,即无法提供确定的结果,但是程序不必指定如何生成水位线。在内部,Ingestion Time与Event Time非常相似,但是可以实现自动分配时间戳和自动生成水位线的功能。
Processing Time
处理时间,根据处理机器的系统时钟决定数据流当前的时间,即事件被处理时当前系统的时间。还以窗口算子为例(关于window,下文会详细分析),基于处理时间的窗口操作是以机器时间来进行触发的,由于数据到达窗口的速率不同,所以窗口算子中使用处理时间会导致不确定的结果。在使用处理时间时,无需等待水位线的到来后进行触发窗口,所以可以提供较低的延迟。
2、对比
经过上面的分析,应该对Flink的时间语义有了大致的了解。不知道你会不会有这样一个疑问:既然事件时间已经能够解决所有的问题了,那为何还要用处理时间呢?其实处理时间有其特定的使用场景,处理时间由于不用考虑事件的延迟与乱序,所以其处理数据的延迟较低。因此如果一些应用比较重视处理速度而非准确性,那么就可以使用处理时间,比如要实时监控仪表盘。总之,虽然处理时间的延迟较低,但是其结果具有不确定性,事件时间虽然有延迟,但是能够保证处理的结果具有准确性,并且可以处理延迟甚至无序的数据。
3、使用
上一小结讲述了三种时间语义的基本概念,接下来将从代码层面讲解在程序中该如何配置这三种时间语义。首先来看一段代码:
/** The time characteristic that is used if none other is set. */
private static final TimeCharacteristic DEFAULT_TIME_CHARACTERISTIC = TimeCharacteristic.ProcessingTime;
//省略的代码
/** The time characteristic used by the data streams. */
private TimeCharacteristic timeCharacteristic = DEFAULT_TIME_CHARACTERISTIC;
上述两行代码摘自StreamExecutionEnvironment类,可以看出,Flink在流处理程序中默认的时间语义是Processing Time,那么该如何修改默认的时间语义呢?很简单,再来看一段代码,下面的代码片段同样来自于StreamExecutionEnvironment类:
/**
* 如果使用Processing Time或者Event Time,默认的水位线间隔时间是200毫秒
* 可以通过ExecutionConfig#setAutoWatermarkInterval(long)设置
* @param characteristic The time characteristic.
*/
@PublicEvolving
public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
getConfig().setAutoWatermarkInterval(0);
} else {
getConfig().setAutoWatermarkInterval(200);
}
}
上述的方法可以配置不同的时间语义,参数TimeCharacteristic是一个枚举类,包括ProcessingTime,IngestionTime,EventTime三个元素。具体使用方式如下:
//env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
2、watermarks
在解释watermarks(水位线)之前,先看一个我们身边发生的真实案例。高考,是大家非常熟悉的场景。如果把高考的考试安排简单地看作是一个流处理应用,那么,每一个考试科目的开始时间到结束时间就是一个窗口,每个考生可以理解成一条记录,考生到达考场的时间可以理解成记录的时间戳,而考试可以理解成某种算子操作。大家都知道,高考考试在开考后15分钟是不允许进场的,这个规定可以理解成一个水位线,比如,上午第一场语文考试,开考时间是9:30,允许在9:45之前进入考场,那么9:45这个时间可以理解成一个水位线。在开考之前,有的同学喜欢提前到考场,有的同学喜欢卡点到考场。假设有个同学叫考必胜,ta是卡着时间点到的考场,但是早上由于吃了不干净的东西,突然感觉肚子不适,无奈之下在厕所里耽误了16分钟,那么按照规定,此时考必胜是不能够进入考场的,因为此时已经默认所有考生都已经在考场了,此时考试也已经触发,那么考必胜就可以理解为迟到的事件。以上就是对窗口、事件时间以及水位线的简单理解,下面开始详细解释什么水位线。
1、基本概念
在上一节中,详细讲解了Flink提供的三种时间语义,在讲解这三种时间语义的时候,提到了一个名词---水位线,那么究竟什么是水位线呢?先来看一个例子,假如要每5分钟统计一次过去1个小时内的热门商品的topN,这是一个典型的滑动窗口操作,那么基于事件时间的窗口该在什么时候出发计算呢?换句话说,我们要等多久才能够确定已经接收到了特定时间点之前的所有事件,另一方面,由于网络延迟等原因,会产生乱序的数据,在进行窗口操作时,不能够无限期的等待下去,需要一个机制来告诉窗口在某个特定时间来触发window计算,即认为小于等于该时间点的数据都已经到来了。这个机制就是watermark(水位线),可以用来处理乱序事件。
水位线是一个全局的进度指标,表示可以确定不会再有延迟的事件到来的某个时间点。从本质上讲,水位线提供了一个逻辑时钟,用来通知系统当前的事件时间。比如,当一个算子接收到了W(T)时刻的水位线,就可以大胆的认为不会再接收到任何时间戳小于或等于W(T)的事件了。水位线对于基于事件时间的窗口和处理乱序数据是非常关键的,算子一旦接收到了某个水位线,就相当于接到一支穿云箭的信号:所有特定时间区间的数据都已集结完毕,可以进行窗口触发计算。
既然已经说了,事件是会存在乱序的,那这个乱序的程度究竟有多大呢,这个就不太好确定了,总之总会有些迟到的事件慢慢悠悠的到来。所以,水位线其实是一种在准确性与延迟之间的权衡,如果水位线设置的非常苛刻,即不允许有掉队的数据出现,虽然准确性提高了,但这在无形之中增加了数据处理的延迟。反之,如果水位线设置的非常激进,即允许有迟到的数据发生,那么虽然降低了数据处理的延迟,但数据的准确性会较低。
所以,水位线是中庸之道,过犹不及。在很多现实应用中,系统无法获取足够多的信息来确定完美的水位线,那么该怎么办呢?Flink提供了某些机制来处理那些可能晚于水位线的迟到时间,用户可以根据应用的需求不同,可以将这些漏网之鱼(迟到的数据)舍弃掉,或者写入日志,或者利用他们修正之前的结果。
上面说到没有完美的水位线,可能还是很抽象。接下来,我们再看一幅图,从图中可以很直观地观察真实的水位线与理想中的完美水位线之间的关系,如下图:
上图的浅灰色直虚线表示理想的水位线,深灰色的弯曲虚线表示现实中的水位线,黑色直线表示两者之间的偏差。在理想状态下,这种偏差为0,因为总是在时间发生时就会立即处理,即事件的真实时间与处理事件的时间是一致的。比如,12:01产生的事件刚好在12:01时被处理,12:02产生的事件刚好在12:02时被处理。但是现实总会有迟到的数据产生,比如网络延迟的原因,所以真实的情况会像深灰色的弯曲虚线表示的那样,即12:01产生的数据可能会在12:01之后被处理,12:02产生的数据在12:02时被处理,12:03时产生的数据会被在12:03之后处理。这种动态的偏差在分布式处理系统中是非常常见的。
2、水位线图解
在上一小节,通过语言描述对水位线的概念进行了详细解读,在本小节会通过图解的方式解析水位线的含义,这样更能加深对水位线的理解。如下图所示:
如上图,矩形表示一条记录,三角表示该条记录的时间戳(真实发生时间),圆圈表示水位线。可以看到上面的数据是乱序的,比如当算子接收到为2的水位线时,就可以认为时间戳小于等于2的数据都已经到来了,此时可以触发计算。同理,接收到为5的水位线时,就可以认为时间戳小于或等于5的数据都已经到来了,此时可以触发计算。
可以看出水位线是单调递增的,并且和记录的时间戳存在联系,一个时间戳为T的水位线表示接下来所有记录的时间戳一定都会大于T。
3、水位线的传播
现在,或许你已经对水位线是什么有了一个初步的认识,接下来将会介绍水位线是怎么在Flink内部传播的。关于水位线的传播策略可以归纳为3点:
首先,水位线是以广播的形式在算子之间进行传播
Long.MAX_VALUE表示事件时间的结束,即未来不会有数据到来了
单个分区的输入取最大值,多个分区的输入取最小值
关于Long.MAX_VALUE的解释,先看一段代码,如下:
/**
* 当一个source关闭时,会输出一个Long.MAX_VALUE的水位线,当一个算子接收到该水位线时,
* 相当于接收到一个信号:未来不会再有数据输入了
*/
@PublicEvolving
public final class Watermark extends StreamElement {
//表示事件时间的结束
public static final Watermark MAX_WATERMARK = new Watermark(Long.MAX_VALUE);
//省略的代码
}
关于另外两条策略的解释,可以从下图中得到:
如上图,一个任务会为它的每个分区都维护一个分区水位线(partition watermark),当收到每个分区传来的水位线时,任务首先会让当前分区水位线的值与接收的水位线值相比较,如果新接收的水位线值大于当前分区水位线值,则会将对应的分区水位线值更新为较大的水位线值(如上图中的2步骤),接着,任务会把事件时钟调整为当前分区水位线值的最小值,如上图步骤2 ,由于当前分区水位线的最小值为3,所以将事件时间时钟更新为3,然后将值为3的水位线广播到下游任务。步骤3与步骤4的处理逻辑同上。
同时我们可以注意到这种设计其实有一个局限,具体体现在没有对分区(partition)是否来自于不同的流进行区分,比如对于两条流或多条流的Union或Connect操作,同样是按照全部分区水位线中最小值来更新事件时间时钟,这就导致所有的输入记录都会按照基于同一个事件时间时钟来处理,这种一刀切的做法对于同一个流的不同分区而言是无可厚非的,但是对于多条流而言,强制使用一个时钟进行同步会对整个集群带来较大的性能开销,比如当两个流的水位线相差很大是,其中的一个流要等待最慢的那条流,而较快的流的记录会在状态中缓存,直到事件时间时钟到达允许处理它们的那个时间点。
4、水位线的生成方式
通常情况下,在接收到数据源之后应该马上为其生成水位线,即越靠近数据源越好。Flink提供两种方式生成水位线,其中一种方式为在数据源完成的,即利用SourceFunction在应用读入数据流的时候分配时间戳与水位线。另一种方式是通过实现接口的自定义函数,该方式又包括两种实现方式:一种为周期性生成水位线,即实现AssignerWithPeriodicWatermarks接口,另一种为定点生成水位线,即实AssignerWithPunctuatedWatermarks接口。具体如下图所示:
5、数据源方式
该方式主要是实现自定义数据源,数据源分配时间戳和水位线主要是通过内部的SourceContext对象实现的,先看一下SourceFunction的源码,如下:
public interface SourceFunction<T> extends Function, Serializable {
void cancel();
interface SourceContext<T> {
void collect(T element);
/**
* 用于输出记录并附属一个与之关联的时间戳
*/
@PublicEvolving
void collectWithTimestamp(T element, long timestamp);
/**
* 用于输出传入的水位线
*/
@PublicEvolving
void emitWatermark(Watermark mark);
/**
* 将自身标记为空闲状态
* 某个某个分区不在产生数据,会阻碍全局水位线前进,
* 因为收不到新的记录,意味着不会发出新的水位线,
* 根据水位线的传播策略,会导致整个应用都停止工作
* Flink提供一种机制,将数据源函数暂时标记为空闲,
* 在空闲状态下,Flink水位线的传播机制会忽略掉空闲的数据流分区
*/
@PublicEvolving
void markAsTemporarilyIdle();
Object getCheckpointLock();
void close();
}
}
从上面对的代码可以看出,通过SourceContext对象的方法可以实现时间戳与水位线的分配。
6、自定义函数的方式
使用自定义函数的方式分配时间戳,只需要调用assignTimestampsAndWatermarks()方法,传入一个实现AssignerWithPeriodicWatermarks或者AssignerWithPunctuatedWatermarks接口的分配器即可,如下代码所示:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<UserBehavior> userBehavior = env
.addSource(new MysqlSource())
.assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks());
周期分配器(AssignerWithPeriodicWatermarks)
该分配器是实现了一个AssignerWithPeriodicWatermarks的用户自定义函数,通过重写extractTimestamp()方法来提取时间戳,提取出来的时间戳会附加在各自的记录上,查询得到的水位线会注入到数据流中。
周期性的生成水位线是指以固定的时间间隔来发出水位线并推进事件时间的前进,关于默认的时间间隔在上文中也有提到,根据选择的时间语义确定默认的时间间隔,如果使用Processing Time或者Event Time,默认的水位线间隔时间是200毫秒,当然用户也可以自己设定时间间隔,关于如何设定,先看一段代码,代码来自于ExecutionConfig类:
/**
* 设置生成水位线的时间间隔
* 注:自动生成watermarks的时间间隔不能是负数
*/
@PublicEvolving
public ExecutionConfig setAutoWatermarkInterval(long interval) {
Preconditions.checkArgument(interval >= 0, "Auto watermark interval must not be negative.");
this.autoWatermarkInterval = interval;
return this;
}
所以,如果要调整默认的200毫秒的间隔,可以调用setAutoWatermarkInterval()方法,具体使用如下:
//每3秒生成一次水位线
env.getConfig().setAutoWatermarkInterval(3000);
上面指定了每隔3秒生成一次水位线,即每隔3秒会自动向流里注入一个水位线,在代码层面,Flink会每隔3秒钟调用一次AssignerWithPeriodicWatermarks的getCurrentWatermark()方法,每次调用该方法时,如果得到的值不为空并且大于上一个水位线的时间戳,那么就会向流中注入一个新的水位线。这项检查可以有效地保证了事件时间的递增的特性,一旦检查失败也就不会生成水位线。下面给出一个实现周期分配水位线的例子:
public class MyTimestampsAndWatermarks implements AssignerWithPeriodicWatermarks<UserBehavior> {
// 定义1分钟的容忍间隔时间,即允许数据的最大乱序时间
private long maxOutofOrderness = 60 * 1000;
// 观察到的最大时间戳
private long currentMaxTs = Long.MIN_VALUE;
@Nullable
@Override
public Watermark getCurrentWatermark() {
// 生成具有1分钟容忍度的水位线
return new Watermark(currentMaxTs - maxOutofOrderness);
}
@Override
public long extractTimestamp(UserBehavior element, long previousElementTimestamp) {
//获取当前记录的时间戳
long currentTs = element.timestamp;
// 更新最大的时间戳
currentMaxTs = Math.max(currentMaxTs, currentTs);
// 返回记录的时间戳
return currentTs;
}
}
通过查看TimestampAssignerd 继承关系可以发现(继承关系如下图),除此之外,Flink还提供了两种内置的水位线分配器,分别为:AscendingTimestampExtractor和BoundedOutOfOrdernessTimestampExtractor两个抽象类。
关于AscendingTimestampExtractor,一般是在数据集的时间戳是单调递增的且没有乱序时使用,该方法使用当前的时间戳生成水位线,使用方式如下:
SingleOutputStreamOperator<UserBehavior> userBehavior = env
.addSource(new MysqlSource())
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<UserBehavior>() {
@Override
public long extractAscendingTimestamp(UserBehavior element) {
return element.timestamp*1000;
}
});
关于BoundedOutOfOrdernessTimestampExtractor,是在数据集中存在乱序数据的情况下使用,即数据有延迟(任意新到来的元素与已经到来的时间戳最大的元素之间的时间差),这种方式可以接收一个表示最大预期延迟参数,具体如下:
SingleOutputStreamOperator<UserBehavior> userBehavior = env
.addSource(new MysqlSource())
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<UserBehavior>(Time.seconds(10)) {
@Override
public long extractTimestamp(UserBehavior element) {
return element.timestamp*1000;
}
} );
上述的代码接收了一个10秒钟延迟的参数,这10秒钟意味着如果当前元素的事件时间与到达的元素的最大时间戳的差值在10秒之内,那么该元素会被处理,如果差值超过10秒,表示其本应该参与的计算,已经完成了,Flink称之为迟到的数据,Flink提供了不同的策略来处理这些迟到的数据。
定点水位线分配器(AssignerWithPunctuatedWatermarks)
该方式是基于某些事件(指示系统进度的特殊元祖或标记)触发水位线的生成与发送,基于特定的事件向流中注入一个水位线,流中的每一个元素都有机会判断是否生成一个水位线,如果得到的水位线不为空并且大于之前的水位线,就生成水位线并注入流中。
实现AssignerWithPunctuatedWatermarks接口,重写checkAndGetNextWatermark()方法,该方法会在针对每个事件的extractTimestamp()方法后立即调用,以此来决定是否生成一个新的水位线,如果该方法返回一个非空并且大于之前值的水位线,就会将这个新的水位线发出。
下面将会实现一个简单的定点水位线分配器
public class MyPunctuatedAssigner implements AssignerWithPunctuatedWatermarks<UserBehavior> {
// 定义1分钟的容忍间隔时间,即允许数据的最大乱序时间
private long maxOutofOrderness = 60 * 1000;
@Nullable
@Override
public Watermark checkAndGetNextWatermark(UserBehavior element, long extractedTimestamp) {
// 如果读取数据的用户行为是购买,就生成水位线
if(element.action.equals("buy")){
return new Watermark(extractedTimestamp - maxOutofOrderness);
}else{
// 不发出水位线
return null;
}
}
@Override
public long extractTimestamp(UserBehavior element, long previousElementTimestamp) {
return element.timestamp;
}
}
7、迟到的数据
上文已经说过,现实中很难生成一个完美的水位线,水位线就是在延迟与准确性之前做的一种权衡。那么,如果生成的水位线过于紧迫,即水位线可能会大于后来数据的时间戳,这就意味着数据有延迟,关于延迟数据的处理,Flink提供了一些机制,具体如下:
直接将迟到的数据丢弃
将迟到的数据输出到单独的数据流中,即使用sideOutputLateData(new OutputTag<>())实现侧输出
根据迟到的事件更新并发出结果
由于篇幅限制,关于迟到数据的具体处理在本文先不做太多的讨论,在后续的文章中会对其详细进行说明。
8、总结
本文从Flink的时间语义开始说起,详细介绍了三种时间语义的概念、特点及使用方式,接着对Flink处理乱序数据的一种机制---水位线进行详细说明,主要描述了水位线的基本概念,传播方式、生成方式,并对其中的细节部分进行了图解,可以加深对水位线的理解。最后,简单说明了一下Flink对于迟到数据的处理方式。
八、Flink1.10集成Hive快速入门
Hive 是大数据领域最早出现的 SQL 引擎,发展至今有着丰富的功能和广泛的用户基础。之后出现的 SQL 引擎,如 Spark SQL、Impala 等,都在一定程度上提供了与 Hive 集成的功能,从而方便用户使用现有的数据仓库、进行作业迁移等。
Flink从1.9开始支持集成Hive,不过1.9版本为beta版,不推荐在生产环境中使用。在最新版Flink1.10版本,标志着对 Blink的整合宣告完成,达到了对 Hive 的生产级别集成,Hive作为数据仓库系统的绝对核心,承担着绝大多数的离线数据ETL计算和数据管理,期待Flink未来对Hive的完美支持。
而 HiveCatalog 会与一个 Hive Metastore 的实例连接,提供元数据持久化的能力。要使用 Flink 与 Hive 进行交互,用户需要配置一个 HiveCatalog,并通过 HiveCatalog 访问 Hive 中的元数据。
1、添加依赖
要与Hive集成,需要在Flink的lib目录下添加额外的依赖jar包,以使集成在Table API程序或SQL Client中的SQL中起作用。或者,可以将这些依赖项放在文件夹中,并分别使用Table API程序或SQL Client 的-C 或-l选项将它们添加到classpath中。本文使用第一种方式,即将jar包直接复制到$FLINK_HOME/lib目录下。本文使用的Hive版本为2.3.4(对于不同版本的Hive,可以参照官网选择不同的jar包依赖),总共需要3个jar包,如下:
flink-connector-hive_2.11-1.10.0.jar
flink-shaded-hadoop-2-uber-2.7.5-8.0.jar
hive-exec-2.3.4.jar
其中hive-exec-2.3.4.jar在hive的lib文件夹下,另外两个需要自行下载,下载地址:flink-connector-hive_2.11-1.10.0.jar
[https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.11/1.10.0/]
flink-shaded-hadoop-2-uber-2.7.5-8.0.jar
[https://maven.aliyun.com/mvn/search]
切莫拔剑四顾心茫然,话不多说,直接上代码。
2、构建程序
3、添加Maven依赖
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
4、实例代码
package com.flink.sql.hiveintegration;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/3/31
* @Time: 13:22
*
*/
public class FlinkHiveIntegration {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inBatchMode() // Batch模式,默认为StreamingMode
.build();
//使用StreamingMode
/* EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inStreamingMode() // StreamingMode
.build();*/
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive"; // Catalog名称,定义一个唯一的名称表示
String defaultDatabase = "qfbap_ods"; // 默认数据库名称
String hiveConfDir = "/opt/modules/apache-hive-2.3.4-bin/conf"; // hive-site.xml路径
String version = "2.3.4"; // Hive版本号
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
// 创建数据库,目前不支持创建hive表
String createDbSql = "CREATE DATABASE IF NOT EXISTS myhive.test123";
tableEnv.sqlUpdate(createDbSql);
}
}
5、Flink SQL Client集成Hive
Flink的表和SQL API可以处理用SQL语言编写的查询,但是这些查询需要嵌入到用Java或Scala编写的程序中。此外,这些程序在提交到集群之前需要与构建工具打包。这或多或少地限制了Java/Scala程序员对Flink的使用。
SQL客户端旨在提供一种简单的方式,无需一行Java或Scala代码,即可将表程序编写、调试和提交到Flink集群。Flink SQL客户端CLI允许通过命令行的形式运行分布式程序。使用Flink SQL cli访问Hive,需要配置sql-client-defaults.yaml文件。
6、sql-client-defaults.yaml配置
目前 HiveTableSink 不支持流式写入(未实现 AppendStreamTableSink)。需要将执行模式改成 batch 模式,否则会报如下错误:
org.apache.flink.table.api.TableException: Stream Tables can only be emitted by AppendStreamTableSink, RetractStreamTableSink, or UpsertStreamTableSink.
需要修改的配置内容如下:
#...省略的配置项...
#==============================================================================
# Catalogs
#==============================================================================
# 配置catalogs,可以配置多个.
catalogs: # empty list
- name: myhive
type: hive
hive-conf-dir: /opt/modules/apache-hive-2.3.4-bin/conf
hive-version: 2.3.4
default-database: qfbap_ods
#...省略的配置项...
#==============================================================================
# Execution properties
#==============================================================================
# Properties that change the fundamental execution behavior of a table program.
execution:
# select the implementation responsible for planning table programs
# possible values are 'blink' (used by default) or 'old'
planner: blink
# 'batch' or 'streaming' execution
type: batch
7、启动Flink SQL Cli
bin/sql-client.sh embedded
在启动之前,确保Hive的metastore已经开启了,否则会报Failed to create Hive Metastore client异常。启动成功,如下图:
启动之后,就可以在此Cli下执行SQL命令访问Hive的表了,基本的操作如下:
-- 命令行帮助
Flink SQL> help
-- 查看当前会话的catalog,其中myhive为自己配置的,default_catalog为默认的
Flink SQL> show catalogs;
default_catalog
myhive
-- 使用catalog
Flink SQL> use catalog myhive;
-- 查看当前catalog的数据库
Flink SQL> show databases;
-- 创建数据库
Flink SQL> create database testdb;
-- 删除数据库
Flink SQL> drop database testdb;
-- 创建表
Flink SQL> create table tbl(id int,name string);
-- 删除表
Flink SQL> drop table tbl;
-- 查询表
Flink SQL> select * from code_city;
-- 插入数据
Flink SQL> insert overwrite code_city select id,city,province,event_time from code_city_delta ;
Flink SQL> INSERT into code_city values(1,'南京','江苏','');
8、小结
本文以最新版本的Flink为例,对Flink集成Hive进行了实操。首先通过代码的方式与Hive进行集成,然后介绍了如何使用Flink SQL 客户端访问Hive,并对其中会遇到的坑进行了描述,最后给出了Flink SQL Cli的详细使用。相信在未来的版本中Flink SQL会越来越完善,期待Flink未来对Hive的完美支持。
六、基于Canal与Flink实现数据实时增量同步(一)
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
1、准备
1、常见的binlog命令
# 是否启用binlog日志
show variables like 'log_bin';
# 查看binlog类型
show global variables like 'binlog_format';
# 查看详细的日志配置信息
show global variables like '%log%';
# mysql数据存储目录
show variables like '%dir%';
# 查看binlog的目录
show global variables like "%log_bin%";
# 查看当前服务器使用的biglog文件及大小
show binary logs;
# 查看最新一个binlog日志文件名称和Position
show master status;
2、配置MySQL的binlog
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
3、授权
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
2、部署canal
1、安装canal
下载:点此下载
解压缩
[kms@kms-1 softwares]$ tar -xzvf canal.deployer-1.1.4.tar.gz -C /opt/modules/canal/
目录结构
drwxr-xr-x 2 root root 4096 Mar 5 14:19 bin
drwxr-xr-x 5 root root 4096 Mar 5 13:54 conf
drwxr-xr-x 2 root root 4096 Mar 5 13:04 lib
drwxrwxrwx 4 root root 4096 Mar 5 14:19 logs
2、配置修改
修改conf/example/instance.properties,修改内容如下:
## mysql serverId
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = kms-1.apache.com:3306
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
# mq config,kafka topic名称
canal.mq.topic=test
修改conf/canal.properties,修改内容如下:
# 配置zookeeper地址
canal.zkServers =kms-2:2181,kms-3:2181,kms-4:2181
# 可选项: tcp(默认), kafka, RocketMQ,
canal.serverMode = kafka
# 配置kafka地址
canal.mq.servers = kms-2:9092,kms-3:9092,kms-4:9092
3、启动canal
sh bin/startup.sh
4、关闭canal
sh bin/stop.sh
3、部署Canal Admin(可选)
canal-admin设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
1、要求
canal-admin的限定依赖:
MySQL,用于存储配置和节点等相关数据
canal版本,要求>=1.1.4 (需要依赖canal-server提供面向admin的动态运维管理接口)
2、安装canal-admin
下载
点此下载
解压缩
[kms@kms-1 softwares]$ tar -xzvf canal.admin-1.1.4.tar.gz -C /opt/modules/canal-admin/
目录结构
drwxrwxr-x 2 kms kms 4096 Mar 6 11:25 bin
drwxrwxr-x 3 kms kms 4096 Mar 6 11:25 conf
drwxrwxr-x 2 kms kms 4096 Mar 6 11:25 lib
drwxrwxr-x 2 kms kms 4096 Sep 2 2019 logs
配置修改
vi conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: kms-1:3306
database: canal_manager
username: canal
password: canal
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
初始化原数据库
mysql -uroot -p
# 导入初始化SQL
#注:(1)初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化
# (2)canal_manager.sql默认会在conf目录下
> mysql> source /opt/modules/canal-admin/conf/canal_manager.sql
启动canal-admin
sh bin/startup.sh
访问
可以通过 http://kms-1:8089/ 访问,默认密码:admin/123456
canal-server端配置
使用canal_local.properties的配置覆盖canal.properties,将下面配置内容配置在canal_local.properties文件里面,就可以了。
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
启动canal-serve
sh bin/startup.sh local
注意:先启canal-server,然后再启动canal-admin,之后登陆canal-admin就可以添加serve和instance了。
3、启动kafka控制台消费者测试
bin/kafka-console-consumer.sh --bootstrap-server kms-2:9092,kms-3:9092,kms-4:9092 --topic test --from-beginning
此时MySQL数据表若有变化,会将row类型的log写进Kakfa,具体格式为JSON:
insert操作
{
"data":[
{
"id":"338",
"city":"成都",
"province":"四川省"
}
],
"database":"qfbap_ods",
"es":1583394964000,
"id":2,
"isDdl":false,
"mysqlType":{
"id":"int(11)",
"city":"varchar(256)",
"province":"varchar(256)"
},
"old":null,
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":4,
"city":12,
"province":12
},
"table":"code_city",
"ts":1583394964361,
"type":"INSERT"
}
update操作
{
"data":[
{
"id":"338",
"city":"绵阳市",
"province":"四川省"
}
],
"database":"qfbap_ods",
"es":1583395177000,
"id":3,
"isDdl":false,
"mysqlType":{
"id":"int(11)",
"city":"varchar(256)",
"province":"varchar(256)"
},
"old":[
{
"city":"成都"
}
],
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":4,
"city":12,
"province":12
},
"table":"code_city",
"ts":1583395177408,
"type":"UPDATE"
}
delete操作
{
"data":[
{
"id":"338",
"city":"绵阳市",
"province":"四川省"
}
],
"database":"qfbap_ods",
"es":1583395333000,
"id":4,
"isDdl":false,
"mysqlType":{
"id":"int(11)",
"city":"varchar(256)",
"province":"varchar(256)"
},
"old":null,
"pkNames":[
"id"
],
"sql":"",
"sqlType":{
"id":4,
"city":12,
"province":12
},
"table":"code_city",
"ts":1583395333208,
"type":"DELETE"
}
4、JSON日志格式解释
data:最新的数据,为JSON数组,如果是插入则表示最新插入的数据,如果是更新,则表示更新后的最新数据,如果是删除,则表示被删除的数据
database:数据库名称
es:事件时间,13位的时间戳
id:事件操作的序列号,1,2,3…
isDdl:是否是DDL操作
mysqlType:字段类型
old:旧数据
pkNames:主键名称
sql:SQL语句
sqlType:是经过canal转换处理的,比如unsigned int会被转化为Long,unsigned long会被转换为BigDecimal
table:表名
ts:日志时间
type:操作类型,比如DELETE,UPDATE,INSERT
5、小结
本文首先介绍了MySQL binlog日志的配置以及Canal的搭建,然后描述了通过canal数据传输到Kafka的配置,最后对canal解析之后的JSON数据进行了详细解释。本文是基于Canal与Flink实现数据实时增量同步的第一篇,在下一篇介绍如何使用Flink实现实时增量数据同步。
七、基于Canal与Flink实现数据实时增量同步(二)
本文主要从Binlog实时采集和离线处理Binlog还原业务数据两个方面,来介绍如何实现DB数据准确、高效地进入Hive数仓。
1、背景
在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据。在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据(DB)两类。对于业务DB数据来说,从MySQL等关系型数据库的业务数据进行采集,然后导入到Hive中,是进行数据仓库生产的重要环节。如何准确、高效地把MySQL数据同步到Hive中?一般常用的解决方案是批量取数并Load:直连MySQL去Select表中的数据,然后存到本地文件作为中间存储,最后把文件Load到Hive表中。这种方案的优点是实现简单,但是随着业务的发展,缺点也逐渐暴露出来:
性能瓶颈:随着业务规模的增长,Select From MySQL -> Save to Localfile -> Load to Hive这种数据流花费的时间越来越长,无法满足下游数仓生产的时间要求。 直接从MySQL中Select大量数据,对MySQL的影响非常大,容易造成慢查询,影响业务线上的正常服务。 由于Hive本身的语法不支持更新、删除等SQL原语(高版本Hive支持,但是需要分桶+ORC存储格式),对于MySQL中发生Update/Delete的数据无法很好地进行支持。 为了彻底解决这些问题,我们逐步转向CDC (Change Data Capture) + Merge的技术方案,即实时Binlog采集 + 离线处理Binlog还原业务数据这样一套解决方案。Binlog是MySQL的二进制日志,记录了MySQL中发生的所有数据变更,MySQL集群自身的主从同步就是基于Binlog做的。
2、实现思路
首先,采用Flink负责把Kafka上的Binlog数据拉取到HDFS上。
然后,对每张ODS表,首先需要一次性制作快照(Snapshot),把MySQL里的存量数据读取到Hive上,这一过程底层采用直连MySQL去Select数据的方式,可以使用Sqoop进行一次性全量导入。
最后,对每张ODS表,每天基于存量数据和当天增量产生的Binlog做Merge,从而还原出业务数据。
Binlog是流式产生的,通过对Binlog的实时采集,把部分数据处理需求由每天一次的批处理分摊到实时流上。无论从性能上还是对MySQL的访问压力上,都会有明显地改善。Binlog本身记录了数据变更的类型(Insert/Update/Delete),通过一些语义方面的处理,完全能够做到精准的数据还原。
3、实现方案
1、Flink处理Kafka的binlog日志
使用kafka source,对读取的数据进行JSON解析,将解析的字段拼接成字符串,符合Hive的schema格式,具体代码如下:
package com.etl.kafka2hdfs;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.RollingPolicy;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Map;
import java.util.Properties;
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/3/27
* @Time: 12:52
* */
public class HdfsSink {
public static void main(String[] args) throws Exception {
String fieldDelimiter = ",";
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// checkpoint
env.enableCheckpointing(10_000);
//env.setStateBackend((StateBackend) new FsStateBackend("file:///E://checkpoint"));
env.setStateBackend((StateBackend) new FsStateBackend("hdfs://kms-1:8020/checkpoint"));
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);
// source
Properties props = new Properties();
props.setProperty("bootstrap.servers", "kms-2:9092,kms-3:9092,kms-4:9092");
// only required for Kafka 0.8
props.setProperty("zookeeper.connect", "kms-2:2181,kms-3:2181,kms-4:2181");
props.setProperty("group.id", "test123");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"qfbap_ods.code_city", new SimpleStringSchema(), props);
consumer.setStartFromEarliest();
DataStream<String> stream = env.addSource(consumer);
// transform
SingleOutputStreamOperator<String> cityDS = stream
.filter(new FilterFunction<String>() {
// 过滤掉DDL操作
@Override
public boolean filter(String jsonVal) throws Exception {
JSONObject record = JSON.parseObject(jsonVal, Feature.OrderedField);
return record.getString("isDdl").equals("false");
}
})
.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
StringBuilder fieldsBuilder = new StringBuilder();
// 解析JSON数据
JSONObject record = JSON.parseObject(value, Feature.OrderedField);
// 获取最新的字段值
JSONArray data = record.getJSONArray("data");
// 遍历,字段值的JSON数组,只有一个元素
for (int i = 0; i < data.size(); i++) {
// 获取到JSON数组的第i个元素
JSONObject obj = data.getJSONObject(i);
if (obj != null) {
fieldsBuilder.append(record.getLong("id")); // 序号id
fieldsBuilder.append(fieldDelimiter); // 字段分隔符
fieldsBuilder.append(record.getLong("es")); //业务时间戳
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(record.getLong("ts")); // 日志时间戳
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(record.getString("type")); // 操作类型
for (Map.Entry<String, Object> entry : obj.entrySet()) {
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(entry.getValue()); // 表字段数据
}
}
}
return fieldsBuilder.toString();
}
});
//cityDS.print();
//stream.print();
// sink
// 以下条件满足其中之一就会滚动生成新的文件
RollingPolicy<String, String> rollingPolicy = DefaultRollingPolicy.create()
.withRolloverInterval(60L * 1000L) //滚动写入新文件的时间,默认60s。根据具体情况调节
.withMaxPartSize(1024 * 1024 * 128L) //设置每个文件的最大大小 ,默认是128M,这里设置为128M
.withInactivityInterval(60L * 1000L) //默认60秒,未写入数据处于不活跃状态超时会滚动新文件
.build();
StreamingFileSink<String> sink = StreamingFileSink
//.forRowFormat(new Path("file:///E://binlog_db/city"), new SimpleStringEncoder<String>())
.forRowFormat(new Path("hdfs://kms-1:8020/binlog_db/code_city_delta"), new SimpleStringEncoder<String>())
.withBucketAssigner(new EventTimeBucketAssigner())
.withRollingPolicy(rollingPolicy)
.withBucketCheckInterval(1000) // 桶检查间隔,这里设置1S
.build();
cityDS.addSink(sink);
env.execute();
}
}
对于Flink Sink到HDFS,StreamingFileSink 替代了先前的 BucketingSink,用来将上游数据存储到 HDFS 的不同目录中。它的核心逻辑是分桶,默认的分桶方式是 DateTimeBucketAssigner,即按照处理时间分桶。处理时间指的是消息到达 Flink 程序的时间,这点并不符合我们的需求。因此,我们需要自己编写代码将事件时间从消息体中解析出来,按规则生成分桶的名称,具体代码如下:
package com.etl.kafka2hdfs;
import org.apache.flink.core.io.SimpleVersionedSerializer;
import org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.SimpleVersionedStringSerializer;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @Created with IntelliJ IDEA.
* @author : jmx
* @Date: 2020/3/27
* @Time: 12:49
* */
public class EventTimeBucketAssigner implements BucketAssigner<String, String> {
@Override
public String getBucketId(String element, Context context) {
String partitionValue;
try {
partitionValue = getPartitionValue(element);
} catch (Exception e) {
partitionValue = "00000000";
}
return "dt=" + partitionValue;//分区目录名称
}
@Override
public SimpleVersionedSerializer<String> getSerializer() {
return SimpleVersionedStringSerializer.INSTANCE;
}
private String getPartitionValue(String element) throws Exception {
// 取出最后拼接字符串的es字段值,该值为业务时间
long eventTime = Long.parseLong(element.split(",")[1]);
Date eventDate = new Date(eventTime);
return new SimpleDateFormat("yyyyMMdd").format(eventDate);
}
2、离线还原MySQL数据
经过上述步骤,即可将Binlog日志记录写入到HDFS的对应的分区中,接下来就需要根据增量的数据和存量的数据还原最新的数据。Hive 表保存在 HDFS 上,该文件系统不支持修改,因此我们需要一些额外工作来写入数据变更。常用的方式包括:JOIN、Hive 事务、或改用 HBase、kudu。
如昨日的存量数据code_city,今日增量的数据为code_city_delta,可以通过 FULL OUTER JOIN,将存量和增量数据合并成一张最新的数据表,并作为明天的存量数据:
INSERT OVERWRITE TABLE code_city
SELECT
COALESCE( t2.id, t1.id ) AS id,
COALESCE ( t2.city, t1.city ) AS city,
COALESCE ( t2.province, t1.province ) AS province,
COALESCE ( t2.event_time, t1.event_time ) AS event_time
FROM
code_city t1
FULL OUTER JOIN (
SELECT
id,
city,
province,
event_time
FROM
(-- 取最后一条状态数据
SELECT
id,
city,
province,
dml_type,
event_time,
row_number ( ) over ( PARTITION BY id ORDER BY event_time DESC ) AS rank
FROM
code_city_delta
WHERE
dt = '20200324' -- 分区数据
) temp
WHERE
rank = 1
) t2 ON t1.id = t2.id;
3、小结
本文主要从Binlog流式采集和基于Binlog的ODS数据还原两方面,介绍了通过Flink实现实时的ETL,此外还可以将binlog日志写入kudu、HBase等支持事务操作的NoSQL中,这样就可以省去数据表还原的步骤。
第二章、flink实时数仓实战
一、依赖
二、数据建模
1、mysql数据建模
1、商品表
CREATE TABLE test.dajiangtai_goods (
goodsId INT(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
goodsName varchar(50) NOT NULL COMMENT '商品名称',
sellingPrice DECIMAL(11,2) DEFAULT 0.00 NOT NULL COMMENT '售价',
goodsStock INT(11) DEFAULT 0 NOT NULL COMMENT '商品总库存',
appraiseNum INT(11) DEFAULT 0 NOT NULL COMMENT '评价数',
CONSTRAINT dajiangtai_goods_PK PRIMARY KEY (goodsId)
)ENGINE=InnoDB DEFAULT CHARSET=utf8
2、订单表
CREATE TABLE test.dajiangtai_orders (
orderId int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
orderNo varchar(50) NOT NULL COMMENT '订单号',
userId int(11) NOT NULL COMMENT '用户ID',
goodId int(11) NOT NULL COMMENT '商品ID',
goodsMoney decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '商品总金额',
realTotalMoney decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '实际订单总金额',
payFrom int(11) NOT NULL DEFAULT '0' COMMENT '支付来源(1:支付宝,2:微信)',
province varchar(50) NOT NULL COMMENT '省份',
createTime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`orderId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
3、flow表
2、hbase数据建模
1、商品表
2、订单表
三、MySQL和Hbase配置(GlobalConfig)
package com.dajiangtai.batch.dbus.config;
import java.io.Serializable;
/**
* 在生产上一般通过配置中心来管理
*/
public class GlobalConfig implements Serializable {
/**
* 数据库driver class
*/
public static final String DRIVER_CLASS = "com.mysql.jdbc.Driver";
/**
* 数据库jdbc url
*/
public static final String DB_URL = "jdbc:mysql://192.168.20.211:3306/test?useUnicode=true&characterEncoding=utf8";
/**
* 数据库user name
*/
public static final String USER_MAME = "canal";
/**
* 数据库password
*/
public static final String PASSWORD = "canal";
/**
* 批量提交size
*/
public static final int BATCH_SIZE = 2;
//HBase相关配置
public static final String HBASE_ZOOKEEPER_QUORUM = "master,slave1,slave2";
public static final String HBASE_ZOOKEEPER_PROPERTY_CLIENTPORT = "2181";
public static final String ZOOKEEPER_ZNODE_PARENT = "/hbase";
}
四、工具类
1、JdbcUtil类
package com.dajiangtai.batch.dbus.utils;
import com.dajiangtai.batch.dbus.config.GlobalConfig;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* jdbc通用的方法
* @Date: 2019/3/4 下午6:00
*
*/
public class JdbcUtil {
//url
private static String url = GlobalConfig.DB_URL;
//user
private static String user = GlobalConfig.USER_MAME;
//password
private static String password = GlobalConfig.PASSWORD;
//驱动程序类
private static String driverClass = GlobalConfig.DRIVER_CLASS;
/**
* 只注册一次,静态代码块
*/
static{
try {
Class.forName(driverClass);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
* 获取连接方法
*/
public static Connection getConnection(){
try {
Connection conn = DriverManager.getConnection(url, user, password);
return conn;
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
/**
* 释放资源的方法
*/
public static void close(Statement stmt,Connection conn){
if(stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
/**
* 释放资源的方法
*/
public static void close(ResultSet rs,Statement stmt,Connection conn){
if(rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
public static void main(String[] args) {
System.out.println(JdbcUtil.getConnection());
}
}
2、Md5Utils类
package com.dajiangtai.batch.dbus.utils;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class Md5Utils {
public static String getMD5String(String str) {
try {
MessageDigest instance = MessageDigest.getInstance("MD5");
byte[] digest = instance.digest(str.getBytes(StandardCharsets.UTF_8));
StringBuffer sb = new StringBuffer();
for (byte by : digest) {
// 获取字节的低八位有效值
int i = by & 0xff;
// 将整数转为16进制
String hexString = Integer.toHexString(i);
if (hexString.length() < 2) {
// 如果是1位的话,补0
hexString = "0" + hexString;
}
sb.append(hexString);
}
return sb.toString();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
return null;
}
}
}
五、数据模拟产生
1、商品数据模拟产生
package com.dajiangtai.batch.dbus.simulator;
import com.dajiangtai.batch.dbus.config.GlobalConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.io.jdbc.JDBCOutputFormat;
import org.apache.flink.api.java.tuple.Tuple5;
import org.apache.flink.types.Row;
import java.math.BigDecimal;
import java.sql.Types;
/**
* 商品数据模拟产生
*
* @author dajiangtai
* @create 2019-07-30-15:03
*/
public class GoodsSimulator {
public static void main(String[] args) throws Exception {
//获取执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//准备测试数据
DataSet<Tuple5<Integer,String, BigDecimal,Integer,Integer>> inputs=env.fromElements(
Tuple5.of(1,"Apple iPhone X (A1865)",BigDecimal.valueOf(6319.00),10000,34564),
Tuple5.of(2,"vivo iQOO",BigDecimal.valueOf(3298.00),20000,3433),
Tuple5.of(3,"AppleMQHV2CH/A",BigDecimal.valueOf(2749.00),2000,342221),
Tuple5.of(4,"AppleApple Watch",BigDecimal.valueOf(2099.00),5587,22111),
Tuple5.of(5,"灏忕背8",BigDecimal.valueOf(2299.00),10000,1298)
);
//数据转换
DataSet<Row> goods = inputs.map(new MapFunction<Tuple5<Integer, String, BigDecimal, Integer, Integer>, Row>() {
@Override
public Row map(Tuple5<Integer, String, BigDecimal, Integer, Integer> value) throws Exception {
return Row.of(value.f0,value.f1,value.f2,value.f3,value.f4);
}
});
goods.output(JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername(GlobalConfig.DRIVER_CLASS)
.setDBUrl(GlobalConfig.DB_URL)
.setUsername(GlobalConfig.USER_MAME)
.setPassword(GlobalConfig.PASSWORD)
.setBatchInterval(GlobalConfig.BATCH_SIZE)
.setQuery("insert into dajiangtai_goods (goodsId ,goodsName ,sellingPrice ,goodsStock ,appraiseNum ) values (?,?,?,?,?)")
.setSqlTypes(new int[] {Types.INTEGER,Types.VARCHAR,Types.DECIMAL,Types.INTEGER,Types.INTEGER})
.finish()
);
env.execute("GoodsSimulator");
}
}
2、订单数据模拟产生
package com.dajiangtai.batch.dbus.simulator;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.alibaba.google.common.collect.ImmutableMap;
import com.cloudwise.sdg.dic.DicInitializer;
import com.cloudwise.sdg.template.TemplateAnalyzer;
import com.dajiangtai.batch.dbus.config.GlobalConfig;
import com.dajiangtai.batch.dbus.model.Orders;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSink;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.types.Row;
import java.util.Map;
/**
* 订单数据模拟生成
*
* @author dajiangtai
* @create 2019-07-30-15:24
*/
public class OrdersSimulator {
public static final Map<String,String> PROVINCE_MAP= new ImmutableMap
.Builder<String, String>()
.put("1","北京")
.put("2","上海")
.put("3","天津")
.put("4","重庆")
.put("5","黑龙江")
.put("6","吉林")
.put("7","辽宁")
.put("8","内蒙古")
.put("9","河北")
.put("10","新疆")
.put("11","甘肃")
.put("12","青海")
.put("13","陕西")
.put("14","宁夏")
.put("15","河南")
.put("16","山东")
.put("17","山西")
.put("18","安徽")
.put("19","湖北")
.put("20","湖南")
.put("21","江苏")
.put("22","四川")
.put("23","贵州")
.put("24","云南")
.put("25","广西")
.put("26","西藏")
.put("27","浙江")
.put("28","江西")
.put("29","广东")
.put("30","福建")
.put("31","台湾")
.put("32","海南")
.put("33","香港")
.put("34","澳门")
.build();
private static final String[] FIELD_NAMES = new String[]{
"orderNo",
"userId",
"goodId",
"goodsMoney",
"realTotalMoney",
"payFrom",
"province"
};
private static final TypeInformation[] FIELD_TYPES = new TypeInformation[]{
BasicTypeInfo.STRING_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.BIG_DEC_TYPE_INFO,
BasicTypeInfo.BIG_DEC_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO
};
private static final RowTypeInfo ROW_TYPE = new RowTypeInfo(FIELD_TYPES,FIELD_NAMES);
public static void main(String[] args) throws Exception {
//获取执行环境
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
JDBCAppendTableSink sink = JDBCAppendTableSink.builder()
.setDrivername(GlobalConfig.DRIVER_CLASS)
.setDBUrl(GlobalConfig.DB_URL)
.setUsername(GlobalConfig.USER_MAME)
.setPassword(GlobalConfig.PASSWORD)
.setBatchSize(GlobalConfig.BATCH_SIZE)
.setQuery("insert into dajiangtai_orders (orderNo,userId ,goodId ,goodsMoney ,realTotalMoney ,payFrom ,province) values (?,?,?,?,?,?,?)")
.setParameterTypes(new TypeInformation[]{
BasicTypeInfo.STRING_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.BIG_DEC_TYPE_INFO,
BasicTypeInfo.BIG_DEC_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO
}).build();
//模拟生成Orders
DataStream<Row> orders = sEnv.addSource(new RichParallelSourceFunction<Row>() {
//定义状态标识位
private volatile boolean isRunning = true;
private TemplateAnalyzer ordersTplAnalyzer;
private Orders orders;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//加载数据字典
DicInitializer.init();
//编辑模板
String ordersTpl = "{\"orderNo\":\"$Dic{orderNo}\",\"userId\":$Dic{userId},\"goodId\":$Dic{goodId},\"goodsMoney\":" +
"$Dic{goodsMoney},\"realTotalMoney\":$Dic{realTotalMoney},\"payFrom\":$Dic{payFrom},\"province\":$Dic{province}}";
//创建模板分词器
ordersTplAnalyzer = new TemplateAnalyzer("orders", ordersTpl);
}
@Override
public void close() throws Exception {
super.close();
}
@Override
public void run(SourceContext<Row> sc) throws Exception {
while (isRunning) {
orders = JSON.parseObject(ordersTplAnalyzer.analyse(), new TypeReference<Orders>() {
});
sc.collect(Row.of(
orders.getOrderNo(),
orders.getUserId(),
orders.getGoodId(),
orders.getGoodsMoney(),
orders.getRealTotalMoney(),
orders.getPayFrom(),
PROVINCE_MAP.get(orders.getProvince())
));
long sleep = (long) (Math.random() * 2000);
Thread.sleep(sleep);
}
}
@Override
public void cancel() {
isRunning = false;
}
}, ROW_TYPE);
//orders.print();
sink.emitDataStream(orders);
sEnv.execute();
}
}
六、全量拉取模块
package com.dajiangtai.batch.dbus.fullpuller;
import com.dajiangtai.batch.dbus.config.GlobalConfig;
import com.dajiangtai.batch.dbus.utils.JdbcUtil;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.hadoop.mapreduce.HadoopOutputFormat;
import org.apache.flink.api.java.io.jdbc.JDBCInputFormat;
import org.apache.flink.api.java.io.jdbc.split.NumericBetweenParametersProvider;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.configuration.ConfigConstants;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.types.Row;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* 全量拉取
*
* @author dajiangtai
* @create 2019-07-30-16:51
*/
public class FullPullerAPP {
public static final boolean isparallelism = true;
public static final String SPLIT_FIELD = "goodsId";
public static final RowTypeInfo ROW_TYPE_INFO = new RowTypeInfo(
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO,
BasicTypeInfo.BIG_DEC_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO,
BasicTypeInfo.INT_TYPE_INFO
);
public static void main(String[] args) throws Exception {
//获取实现环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取商品表
JDBCInputFormat.JDBCInputFormatBuilder jdbcInputFormatBuilder = JDBCInputFormat.buildJDBCInputFormat()
.setDrivername(GlobalConfig.DRIVER_CLASS)
.setDBUrl(GlobalConfig.DB_URL)
.setUsername(GlobalConfig.USER_MAME)
.setPassword(GlobalConfig.PASSWORD)
.setQuery("select * from dajiangtai_goods")
.setRowTypeInfo(ROW_TYPE_INFO);
if(isparallelism){
int fetchSize = 2;
Boundary boundary = boundaryQuery(SPLIT_FIELD);
jdbcInputFormatBuilder.setQuery("select * from dajiangtai_goods where "+SPLIT_FIELD+" between ? and ?")
.setParametersProvider(new NumericBetweenParametersProvider(fetchSize,boundary.min,boundary.max));
}
//读取MySQL数据
DataSource<Row> source = env.createInput(jdbcInputFormatBuilder.finish());
//生成HBase输出数据
DataSet<Tuple2<Text, Mutation>> hbaseResult =convertMysqlToHBase(source);
//数据输出到HBase
org.apache.hadoop.conf.Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","master,slave1,slave2");
conf.set("hbase.zookeeper.property.clientPort","2181");
conf.set("zookeeper.znode.parent","/hbase");
conf.set(TableOutputFormat.OUTPUT_TABLE,"learing_flink:dajiangtai_goods");
conf.set("mapreduce.output.fileoutputformat.outputdir","/tmp");
//new 一个job实例
Job job = Job.getInstance(conf);
hbaseResult.output(new HadoopOutputFormat<Text, Mutation>(new TableOutputFormat<>(),job));
env.execute("FullPullerAPP");
}
public static DataSet<Tuple2<Text,Mutation>> convertMysqlToHBase(DataSet<Row> ds){
return ds.map(new RichMapFunction<Row, Tuple2<Text, Mutation>>() {
private transient Tuple2<Text,Mutation> resultTp ;
private byte[] cf = "F".getBytes(ConfigConstants.DEFAULT_CHARSET);
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
resultTp = new Tuple2<>();
}
@Override
public Tuple2<Text, Mutation> map(Row row) throws Exception {
resultTp.f0 = new Text(row.getField(0).toString());
Put put = new Put(row.getField(0).toString().getBytes(ConfigConstants.DEFAULT_CHARSET));
if(null != row.getField(1)){
put.addColumn(cf, Bytes.toBytes("goodsName"),Bytes.toBytes(row.getField(1).toString())) ;
}
put.addColumn(cf, Bytes.toBytes("sellingPrice"),Bytes.toBytes(row.getField(2).toString())) ;
put.addColumn(cf, Bytes.toBytes("goodsStock"),Bytes.toBytes(row.getField(3).toString())) ;
put.addColumn(cf, Bytes.toBytes("appraiseNum"),Bytes.toBytes(row.getField(4).toString())) ;
resultTp.f1 = put;
return resultTp;
}
});
}
public static Boundary boundaryQuery(String splitField) throws Exception{
String sql = "select min("+splitField+") , max("+splitField+") from dajiangtai_goods";
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
int min = 0;
int max = 0;
try {
connection = JdbcUtil.getConnection();
statement = connection.createStatement();
resultSet = statement.executeQuery(sql);
while (resultSet.next()){
min = resultSet.getInt(1);
max = resultSet.getInt(2);
System.out.println(min+"------------------"+max);
}
}finally {
JdbcUtil.close(resultSet,statement,connection);
}
return Boundary.of(min,max);
}
public static class Boundary{
private int min;
private int max;
public Boundary(int min ,int max){
this.min = min;
this.max = max;
}
public static Boundary of(int min ,int max){
return new Boundary(min,max);
}
}
}
七、增量实时同步模块
1、枚举类
1、CodeEnum
1、FlowStatusEnum
package com.dajiangtai.batch.dbus.enums;
import lombok.Getter;
@Getter
public enum FlowStatusEnum implements CodeEnum {
/**
* 初始状态(新添加)
*/
FLOWSTATUS_INIT(0, "初始状态"),
/**
* 就绪状态,初始采集后,可以将状态改为就绪状态
*/
FLOWSTATUS_READY(1, "就绪状态"),
/**
* 运行状态(增量采集正在运行)
*/
FLOWSTATUS_RUNNING(2, "运行状态");
private Integer code;
private String message;
FlowStatusEnum(Integer code, String message) {
this.code = code;
this.message = message;
}
}
2、HBaseStorageModeEnum
package com.dajiangtai.batch.dbus.enums;
import lombok.Getter;
@Getter
public enum HBaseStorageModeEnum implements CodeEnum{
/**
* STRING
*/
STRING(0, "STRING"),
/**
* NATIVE
*/
NATIVE(1, "NATIVE"),
/**
* PHOENIX
*/
PHOENIX(2, "PHOENIX");
private Integer code;
private String message;
HBaseStorageModeEnum(Integer code, String message) {
this.code = code;
this.message = message;
}
}
2、模型类
1、Flow
package com.dajiangtai.batch.dbus.model;
import com.dajiangtai.batch.dbus.enums.FlowStatusEnum;
import com.dajiangtai.batch.dbus.enums.HBaseStorageModeEnum;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
/**
* 每张表一个Flow
*/
//
//{
// mode: STRING # HBase中的存储类型, 默认统一存为String, 可选: #PHOENIX #NATIVE #STRING
// # NATIVE: 以java类型为主, PHOENIX: 将类型转换为Phoenix对应的类型
// destination: example # 对应 canal destination/MQ topic 名称
// database: mytest # 数据库名/schema名
// table: person # 表名
// hbaseTable: MYTEST.PERSON # HBase表名
// family: CF # 默认统一Column Family名称
// uppercaseQualifier: true # 字段名转大写, 默认为true
// commitBatch: 3000 # 批量提交的大小, ETL中用到
// #rowKey: id,type # 复合字段rowKey不能和columns中的rowKey并存
// # 复合rowKey会以 '|' 分隔
// columns: # 字段映射, 如果不配置将自动映射所有字段,
// # 并取第一个字段为rowKey, HBase字段名以mysql字段名为主
// id: ROWKE
// name: CF:NAME
// email: EMAIL # 如果column family为默认CF, 则可以省略
// type: # 如果HBase字段和mysql字段名一致, 则可以省略
// c_time:
// birthday:
//}
@Data
@ToString
public class Flow implements Serializable {
private Integer flowId;
/**
* HBase中的存储类型, 默认统一存为String,
*/
private int mode= HBaseStorageModeEnum.STRING.getCode();
/**
* 数据库名/schema名
*/
private String databaseName;
/**
* mysql表名
*/
private String tableName;
/**
* hbase表名
*/
private String hbaseTable;
/**
* 默认统一Column Family名称
*/
private String family;
/**
* 字段名转大写, 默认为true
*/
private boolean uppercaseQualifier=true;
/**
* 批量提交的大小, ETL中用到
*/
private int commitBatch;
/**
* 组成rowkey的字段名,必须用逗号分隔
*/
private String rowKey;
/**
* 状态
*/
private int status= FlowStatusEnum.FLOWSTATUS_INIT.getCode();
}
2、Orders
package com.dajiangtai.batch.dbus.model;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
import java.math.BigDecimal;
import java.sql.Timestamp;
@Data
@ToString
public class Orders implements Serializable {
private Integer orderId;
private String orderNo;
private Integer userId;
private Integer goodId;
private BigDecimal goodsMoney;
private BigDecimal realTotalMoney;
private Integer payFrom;
private String province;
private Timestamp createTime;
}
3、数据源类
1、FlowSoure
package com.dajiangtai.batch.dbus.source;
import com.dajiangtai.batch.dbus.model.Flow;
import com.dajiangtai.batch.dbus.utils.JdbcUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* 配置流
*
* @author dajiangtai
* @create 2019-07-31-11:24
*/
@Slf4j
public class FlowSoure extends RichSourceFunction<Flow> {
private static final long serialVersionUID = 3519222623348229907L;
//状态位
private volatile boolean isRunning = true;
private String query = "select * from test.dbus_flow";
private Flow flow=new Flow();
@Override
public void run(SourceContext<Flow> ctx) throws Exception {
//定时读取数据库的flow表,生成FLow数据
while (isRunning) {
Connection conn=null;
Statement stmt=null;
ResultSet rs=null;
try{
conn= JdbcUtil.getConnection();
stmt=conn.createStatement();
rs=stmt.executeQuery(query);
while (rs.next()) {
flow.setFlowId(rs.getInt("flowId"));
flow.setMode(rs.getInt("mode"));
flow.setDatabaseName(rs.getString("databaseName"));
flow.setTableName(rs.getString("tableName"));
flow.setHbaseTable(rs.getString("hbaseTable"));
flow.setFamily(rs.getString("family"));
flow.setUppercaseQualifier(rs.getBoolean("uppercaseQualifier"));
flow.setCommitBatch(rs.getInt("commitBatch"));
flow.setStatus(rs.getInt("status"));
flow.setRowKey(rs.getString("rowKey"));
log.info("load flow: "+flow.toString());
ctx.collect(flow);
}
}finally {
JdbcUtil.close(rs,stmt,conn);
}
//隔一段时间读取,可以使用更新的配置生效
Thread.sleep(60*1000L);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
4、序列化类
1、FlatMessageSchema
package com.dajiangtai.batch.dbus.schema;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.alibaba.otter.canal.protocol.FlatMessage;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
public class FlatMessageSchema implements DeserializationSchema<FlatMessage>, SerializationSchema<FlatMessage> {
@Override
public FlatMessage deserialize(byte[] message) throws IOException {
return JSON.parseObject(new String(message), new TypeReference<FlatMessage>() {});
}
@Override
public boolean isEndOfStream(FlatMessage nextElement) {
return false;
}
@Override
public byte[] serialize(FlatMessage element) {
return element.toString().getBytes(StandardCharsets.UTF_8);
}
@Override
public TypeInformation<FlatMessage> getProducedType() {
return TypeInformation.of(new TypeHint<FlatMessage>() {});
}
}
5、落地类
1、HBase操作对象类
package com.dajiangtai.batch.dbus.sink;
import lombok.ToString;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
/**
* HBase操作对象类
*
* @version 1.0.0
*/
@ToString
public class HRow implements Serializable {
private byte[] rowKey;
private List<HCell> cells = new ArrayList<>();
public HRow(){
}
public HRow(byte[] rowKey){
this.rowKey = rowKey;
}
public byte[] getRowKey() {
return rowKey;
}
public void setRowKey(byte[] rowKey) {
this.rowKey = rowKey;
}
public List<HCell> getCells() {
return cells;
}
public void setCells(List<HCell> cells) {
this.cells = cells;
}
public void addCell(String family, String qualifier, byte[] value) {
HCell hCell = new HCell(family, qualifier, value);
cells.add(hCell);
}
public static class HCell {
private String family;
private String qualifier;
private byte[] value;
public HCell(){
}
public HCell(String family, String qualifier, byte[] value){
this.family = family;
this.qualifier = qualifier;
this.value = value;
}
public String getFamily() {
return family;
}
public void setFamily(String family) {
this.family = family;
}
public String getQualifier() {
return qualifier;
}
public void setQualifier(String qualifier) {
this.qualifier = qualifier;
}
public byte[] getValue() {
return value;
}
public void setValue(byte[] value) {
this.value = value;
}
}
}
2、HbaseTemplate增删改查类
package com.dajiangtai.batch.dbus.sink;
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
@Slf4j
public class HbaseTemplate implements Serializable {
private Configuration hbaseConfig; // hbase配置对象
private Connection conn; // hbase连接
public HbaseTemplate(Configuration hbaseConfig){
this.hbaseConfig = hbaseConfig;
initConn();
}
private void initConn() {
try {
this.conn = ConnectionFactory.createConnection(hbaseConfig);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public Connection getConnection() {
if (conn == null || conn.isAborted() || conn.isClosed()) {
initConn();
}
return conn;
}
public boolean tableExists(String tableName) {
try (HBaseAdmin admin = (HBaseAdmin) getConnection().getAdmin()) {
return admin.tableExists(TableName.valueOf(tableName));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void createTable(String tableName, String... familyNames) {
try (HBaseAdmin admin = (HBaseAdmin) getConnection().getAdmin()) {
HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(tableName));
// 添加列簇
if (familyNames != null) {
for (String familyName : familyNames) {
HColumnDescriptor hcd = new HColumnDescriptor(familyName);
desc.addFamily(hcd);
}
}
admin.createTable(desc);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void disableTable(String tableName) {
try (HBaseAdmin admin = (HBaseAdmin) getConnection().getAdmin()) {
admin.disableTable(tableName);
} catch (IOException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
public void deleteTable(String tableName) {
try (HBaseAdmin admin = (HBaseAdmin) getConnection().getAdmin()) {
if (admin.isTableEnabled(tableName)) {
disableTable(tableName);
}
admin.deleteTable(tableName);
} catch (IOException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
/**
* 插入一行数据
*
* @param tableName 表名
* @param hRow 行数据对象
* @return 是否成功
*/
public Boolean put(String tableName, HRow hRow) {
boolean flag = false;
try {
HTable table = (HTable) getConnection().getTable(TableName.valueOf(tableName));
Put put = new Put(hRow.getRowKey());
for (HRow.HCell hCell : hRow.getCells()) {
put.addColumn(Bytes.toBytes(hCell.getFamily()), Bytes.toBytes(hCell.getQualifier()), hCell.getValue());
}
table.put(put);
flag = true;
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
return flag;
}
/**
* 批量插入
*
* @param tableName 表名
* @param rows 行数据对象集合
* @return 是否成功
*/
public Boolean puts(String tableName, List<HRow> rows) {
boolean flag = false;
try {
HTable table = (HTable) getConnection().getTable(TableName.valueOf(tableName));
List<Put> puts = new ArrayList<>();
System.out.println(tableName+"------------------------------------------------");
for (HRow hRow : rows) {
Put put = new Put(hRow.getRowKey());
for (HRow.HCell hCell : hRow.getCells()) {
put.addColumn(Bytes.toBytes(hCell.getFamily()),
Bytes.toBytes(hCell.getQualifier()),
hCell.getValue());
}
puts.add(put);
}
if (!puts.isEmpty()) {
table.put(puts);
}
flag = true;
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
return flag;
}
/**
* 批量删除数据
*
* @param tableName 表名
* @param rowKeys rowKey集合
* @return 是否成功
*/
public Boolean deletes(String tableName, Set<byte[]> rowKeys) {
boolean flag = false;
try {
HTable table = (HTable) getConnection().getTable(TableName.valueOf(tableName));
List<Delete> deletes = new ArrayList<>();
for (byte[] rowKey : rowKeys) {
Delete delete = new Delete(rowKey);
deletes.add(delete);
}
if (!deletes.isEmpty()) {
table.delete(deletes);
}
flag = true;
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
}
return flag;
}
public void close() throws IOException {
if (conn != null) {
conn.close();
}
}
}
3、HBase同步操作业务
package com.dajiangtai.batch.dbus.sink;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.alibaba.otter.canal.protocol.FlatMessage;
import com.dajiangtai.batch.dbus.model.Flow;
import com.dajiangtai.batch.dbus.utils.Md5Utils;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.Serializable;
import java.util.*;
/**
* HBase同步操作业务
*/
@Slf4j
public class HbaseSyncService implements Serializable {
private HbaseTemplate hbaseTemplate; // HBase操作模板
public HbaseSyncService(HbaseTemplate hbaseTemplate){
this.hbaseTemplate = hbaseTemplate;
}
public void sync(Flow flow, FlatMessage dml) {
if (flow != null) {
String type = dml.getType();
if (type != null && type.equalsIgnoreCase("INSERT")) {
insert(flow, dml);
} else if (type != null && type.equalsIgnoreCase("UPDATE")) {
// update(flow, dml);
} else if (type != null && type.equalsIgnoreCase("DELETE")) {
// delete(flow, dml);
}
if (log.isDebugEnabled()) {
log.debug("DML: {}", JSON.toJSONString(dml, SerializerFeature.WriteMapNullValue));
}
}
}
// public void sync(Flow flow, Row row) {
// if (row != null) {
//
// }
// }
/**
* 插入操作
*
* @param flow 配置项
* @param dml DML数据
*/
private void insert(Flow flow, FlatMessage dml) {
List<Map<String, String>> data = dml.getData();
if (data == null || data.isEmpty()) {
return;
}
int i = 1;
boolean complete = false;
List<HRow> rows = new ArrayList<>();
for (Map<String, String> r : data) {
HRow hRow = new HRow();
// 拼接复合rowKey
if (flow.getRowKey() != null) {
String[] rowKeyColumns = flow.getRowKey().trim().split(",");
String rowKeyVale = getRowKey(rowKeyColumns, r);
hRow.setRowKey(Bytes.toBytes(rowKeyVale));
}
convertData2Row(flow, hRow, r);
if (hRow.getRowKey() == null) {
throw new RuntimeException("empty rowKey: " + hRow.toString()+",Flow: "+flow.toString());
}
rows.add(hRow);
complete = false;
if (i % flow.getCommitBatch() == 0 && !rows.isEmpty()) {
hbaseTemplate.puts(flow.getHbaseTable(), rows);
rows.clear();
complete = true;
}
i++;
}
if (!complete && !rows.isEmpty()) {
hbaseTemplate.puts(flow.getHbaseTable(), rows);
}
}
/**
* 获取复合字段作为rowKey的拼接
*
* @param rowKeyColumns 复合rowK对应的字段
* @param data 数据
* @return
*/
private static String getRowKey(String[] rowKeyColumns, Map<String, String> data) {
StringBuilder rowKeyValue = new StringBuilder();
for (String rowKeyColumnName : rowKeyColumns) {
Object obj = data.get(rowKeyColumnName);
if (obj != null) {
rowKeyValue.append(obj.toString());
}
rowKeyValue.append("|");
}
int len = rowKeyValue.length();
if (len > 0) {
rowKeyValue.delete(len - 1, len);
}
//可自行扩展支持多种rowkey生成策略,这里写死为md5前缀
return Md5Utils.getMD5String(rowKeyValue.toString()).substring(0, 8) + "_" + rowKeyValue.toString();
}
/**
* 将Map数据转换为HRow行数据
*
* @param flow hbase映射配置
* @param hRow 行对象
* @param data Map数据
*/
private static void convertData2Row(Flow flow, HRow hRow, Map<String, String> data) {
String familyName = flow.getFamily();
for (Map.Entry<String, String> entry : data.entrySet()) {
if (entry.getValue() != null) {
byte[] bytes = Bytes.toBytes(entry.getValue().toString());
String qualifier = entry.getKey();
if (flow.isUppercaseQualifier()) {
qualifier = qualifier.toUpperCase();
}
hRow.addCell(familyName, qualifier, bytes);
}
}
}
}
4、HbaseSyncSink落地
package com.dajiangtai.batch.dbus.sink;
import com.alibaba.otter.canal.protocol.FlatMessage;
import com.dajiangtai.batch.dbus.model.Flow;
import com.dajiangtai.batch.dbus.config.GlobalConfig;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
@Slf4j
public class HbaseSyncSink extends RichSinkFunction<Tuple2<FlatMessage,Flow>> {
private HbaseSyncService hbaseSyncService;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
org.apache.hadoop.conf.Configuration hbaseConfig = HBaseConfiguration.create();
hbaseConfig.set("hbase.zookeeper.quorum", GlobalConfig.HBASE_ZOOKEEPER_QUORUM);
hbaseConfig.set("hbase.zookeeper.property.clientPort", GlobalConfig.HBASE_ZOOKEEPER_PROPERTY_CLIENTPORT);
hbaseConfig.set("zookeeper.znode.parent", GlobalConfig.ZOOKEEPER_ZNODE_PARENT);
HbaseTemplate hbaseTemplate = new HbaseTemplate(hbaseConfig);
hbaseSyncService = new HbaseSyncService(hbaseTemplate);
}
@Override
public void close() throws Exception {
super.close();
}
@Override
public void invoke(Tuple2<FlatMessage, Flow> value, Context context) throws Exception {
hbaseSyncService.sync(value.f1, value.f0);
}
}
6、增量同步类
1、IncrementSyncApp
package com.dajiangtai.batch.dbus.incrementssync;
import com.alibaba.otter.canal.protocol.FlatMessage;
import com.dajiangtai.batch.dbus.function.DbusProcessFunction;
import com.dajiangtai.batch.dbus.model.Flow;
import com.dajiangtai.batch.dbus.schema.FlatMessageSchema;
import com.dajiangtai.batch.dbus.sink.HbaseSyncSink;
import com.dajiangtai.batch.dbus.source.FlowSoure;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import java.util.Properties;
/**
* 实时增量同步模块
*
* @author dajiangtai
* @create 2019-07-31-11:04
*/
public class IncrementSyncApp {
public static final MapStateDescriptor<String, Flow> flowStateDescriptor =
new MapStateDescriptor<String, Flow>("flowBroadCastState", BasicTypeInfo.STRING_TYPE_INFO, TypeInformation.of(new TypeHint<Flow>() {
}));
public static void main(String[] args) throws Exception {
//获取执行环境
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("zookeeper.connect", "master:2181");
props.put("group.id", "group1");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
props.put("flink.partition-discovery.interval-millis","30000");
//消费kafka数据
FlinkKafkaConsumer010<FlatMessage> myConsumer = new FlinkKafkaConsumer010<>("test", new FlatMessageSchema(), props);
DataStream<FlatMessage> message = sEnv.addSource(myConsumer);
//同库,同表数据进入同一个分组,一个分区
KeyedStream<FlatMessage, String> keyedMessage = message.keyBy(new KeySelector<FlatMessage, String>() {
@Override
public String getKey(FlatMessage value) throws Exception {
return value.getDatabase() + value.getTable();
}
});
//读取配置流
BroadcastStream<Flow> broadcast = sEnv.addSource(new FlowSoure()).broadcast(flowStateDescriptor);
//连接数据流和配置流
DataStream<Tuple2<FlatMessage,Flow>> connectedStream = keyedMessage.connect(broadcast)
.process(new DbusProcessFunction())
.setParallelism(1);
connectedStream.addSink(new HbaseSyncSink());
sEnv.execute("IncrementSyncApp");
}
}
7、状态容错
1、DbusProcessFunction
package com.dajiangtai.batch.dbus.function;
import com.alibaba.otter.canal.protocol.FlatMessage;
import com.dajiangtai.batch.dbus.enums.FlowStatusEnum;
import com.dajiangtai.batch.dbus.model.Flow;
import com.dajiangtai.batch.dbus.incrementssync.IncrementSyncApp;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction;
import org.apache.flink.util.Collector;
/**
* 处理方法
*
* @author dajiangtai
* @create 2019-07-31-11:45
*/
public class DbusProcessFunction extends KeyedBroadcastProcessFunction<String, FlatMessage,Flow, Tuple2<FlatMessage, Flow>> {
@Override
public void processElement(FlatMessage value, ReadOnlyContext ctx, Collector<Tuple2<FlatMessage, Flow>> out) throws Exception {
//获取配置流
Flow flow = ctx.getBroadcastState(IncrementSyncApp.flowStateDescriptor).get(value.getDatabase() + value.getTable());
if(null != flow && flow.getStatus() == FlowStatusEnum.FLOWSTATUS_RUNNING.getCode()){
out.collect(Tuple2.of(value,flow));
}
}
@Override
public void processBroadcastElement(Flow flow, Context ctx, Collector<Tuple2<FlatMessage, Flow>> out) throws Exception {
//获取state 状态
BroadcastState<String, Flow> broadcastState = ctx.getBroadcastState(IncrementSyncApp.flowStateDescriptor);
//更新state
broadcastState.put(flow.getDatabaseName()+flow.getTableName(),flow);
}
}
flink实时数仓从入门到实战的更多相关文章
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- HBase实战 | 知乎实时数仓架构演进
https://mp.weixin.qq.com/s/hx-q13QteNvtXRpNsE5Y0A 作者 | 知乎数据工程团队编辑 | VincentAI 前线导读:“数据智能” (Data Inte ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- Clickhouse实时数仓建设
1.概述 Clickhouse是一个开源的列式存储数据库,其主要场景用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告.今天,笔者就为大家介绍如何使用Clickhouse来构建实 ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
随机推荐
- 母牛的故事(hdu2018)——笔记待完善
思考:这道题考验的是罗辑思维,这个网址http://blog.csdn.net/sxhelijian/article/details/42609353的罗辑思维值得学习 #include<std ...
- 实验6、Python-OpenCV宽度测量
一. 题目描述 测量所给图片的高度,即上下边缘间的距离. 思路: 将图片进行阈值操作得到二值化图片. 截取只包含上下边框的部分,以便于后续的轮廓提取 轮廓检测 得到结果 二. 实现过程 1.用于给图片 ...
- 编译安装路由器用的Privoxy 3.0.28(华硕RT-AC88U,原版梅林384.15)
编译安装路由器用的Privoxy 3.0.28(华硕RT-AC88U,原版梅林384.15) Privoxy有什么特殊之处? 支持和SOCKS/HTTP代理的级联.这个功能轻松将SOCKS转为HTTP ...
- 关于 Git 拉取GitLab工程报错:Repository not found的问题
[root@localhost xscan]# git pull fatal: repository 'http://gitlab.***.com/***.git/' not found 原因1: 可 ...
- Python的元类简单介绍
* 类型 和类 在Python中,一切都是对象.类也是对象.所以一个类必须有一个类型 注意: 1.type Python3中所有的类都是通过type来创建出来的 2.object:Python3中所有 ...
- 剑指Offer之链表中倒数第k个结点
题目描述 输入一个链表,输出该链表中倒数第k个结点. 思路:首先计算出链表的长度,再计算出倒数第k个是正数第几个,找到该结点即可. public ListNode FindKthToTail(Li ...
- [python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标 ...
- MySQL不香吗,清华架构师告诉你为什么还要有noSQL?
强烈推荐观看: 阿里P8架构师谈(数据库系列):NoSQL使用场景和选型比较,以及与SQL的区别_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com noSQL的大概 ...
- 【asp.net core 系列】3 视图以及视图与控制器
0.前言 在之前的几篇中,我们大概介绍了如何创建一个asp.net core mvc项目以及http请求如何被路由转交给对应的执行单元.这一篇我们将介绍一下控制器与视图直接的关系. 1. 视图 这里的 ...
- 使用turtle库画国际象棋棋盘
import turtle n = 60 # 每行间隔,小格子边长 x = -300 # x初始值 y = -300 # x初始值 def main(): turtle.speed(11) turtl ...