分布式爬虫管理平台Crawlab安装与使用
Why,为什么需要爬虫管理平台?
以下摘自官方文档:
Crawlab主要解决的是大量爬虫管理困难的问题,例如需要监控上百个网站的参杂scrapy和selenium的项目不容易做到同时管理,而且命令行管理的成本非常高,还容易出错。
Crawlab支持任何语言和任何框架,配合任务调度、任务监控,很容易做到对成规模的爬虫项目进行有效监控管理。
项目自 2019 年 3 月份上线以来受到爬虫爱好者们和开发者们的好评,超过一半的使用者表示已经在用 Crawlab 作为公司的爬虫管理平台。
经过近数月的迭代,陆续上线了 定时任务、数据分析、可配置爬虫、SDK、消息通知、Scrapy 支持、Git 同步等功能,
将Crawlab打造得更加实用,更加全面,能够真正帮助用户解决爬虫管理困难的问题。
以下是Crawlab的一些页面:
主页
爬虫列表页
爬虫文件编辑
定时任务
消息通知
----------------
真香,想起自己以前写的大大小小的的爬虫脚本。如果早些使用crawlab来管理说不定还是能发挥余热的。
抱着对定时任务、消息通知、数据分析等功能的期待。
开始了安装及使用之旅~
安装:
系统:阿里云centos7
这里使用最简单的安装方法,docker安装。
先用docker下载crawlab镜像:
docker pull tikazyq/crawlab:latest
关于docker常用命令及简介,这篇文章写的很全:
https://blog.csdn.net/javahelpyou/article/details/104587242
还需要安装docker-compose,在安装了python3 的前提下:
pip3 install docker-compose
安装后可执行docker-compose ps验证是否安装正常。
启动crawlab:
需要先找到docker-compose.yml文件所在文件夹,shell在根目录下执行:
find -name "docker-compose.yml"
转到该文件夹直接执行:
docker-compose up
即可运行。
在浏览器中输入 http://localhost:8080就可以看到界面。
如果布置到了公网记得开放8080端口及重设密码。
这里mongodb及redis也是使用docker-compose一同安装管理。
所以建议您将数据库持久化,因为否则的话,一旦您的 Docker 容器发生意外导致关闭重启,您的数据将丢失。
至于数据持久化、mongodb及redis密码设置、数据库端口映射。等等修改配置文件docker-compose.yml即可。
可以到官方文档查看说明:
https://docs.crawlab.cn/Installation/Docker.html
使用测试:
以这个网站为例。
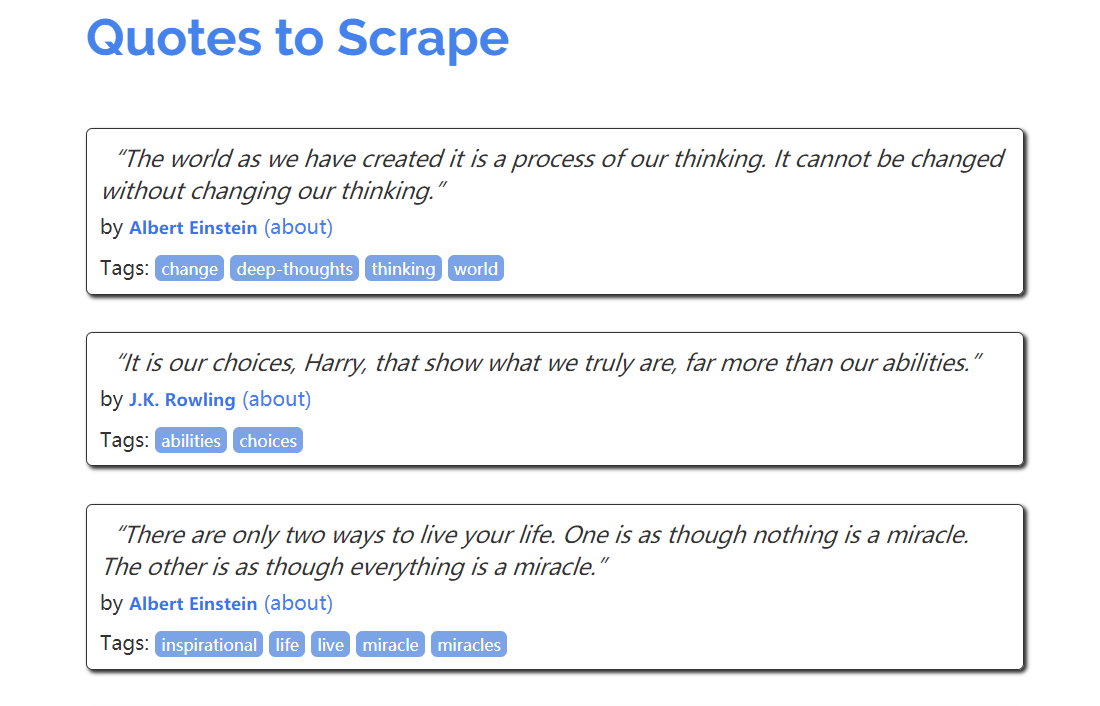
上面有一些名人名句,需要抓的是句子内容、作者及标签。
可配置爬虫(当然也能上传运行自定义的爬虫):
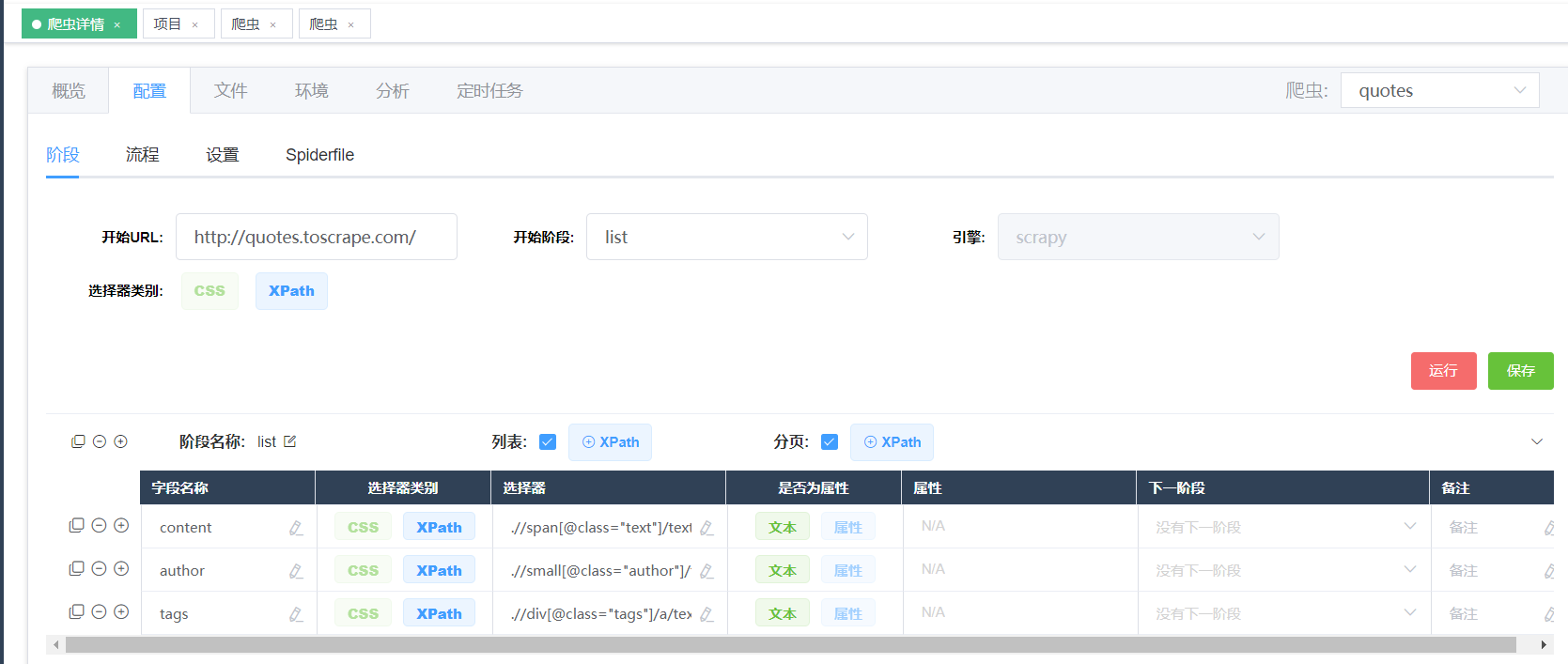
使用crawlab生成个可配置爬虫,即在web界面点几下就能生成一个爬虫。

添加爬虫后可在“配置”这里配置开始url,一些字段xpath及下一页的xpath
也可到“文件”进一步修改错漏的地方:
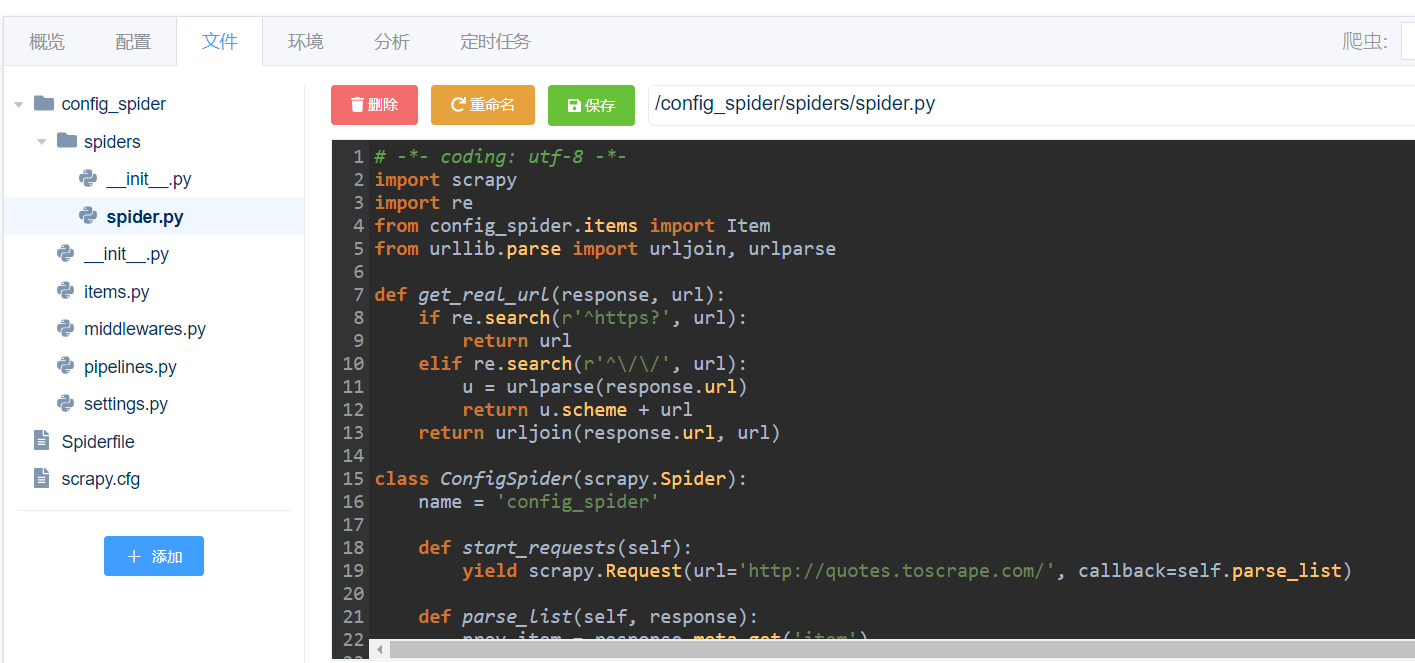
配置好后运行->查看结果
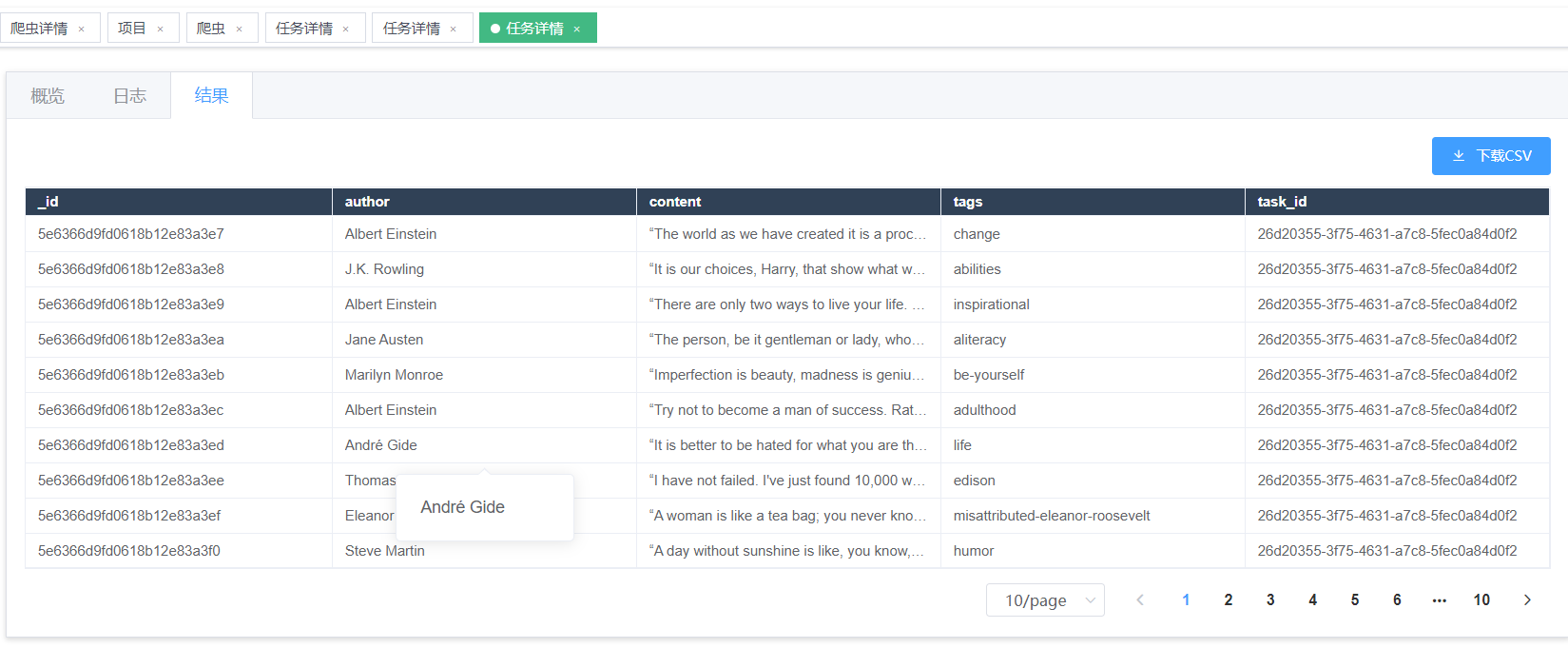
定时爬虫:
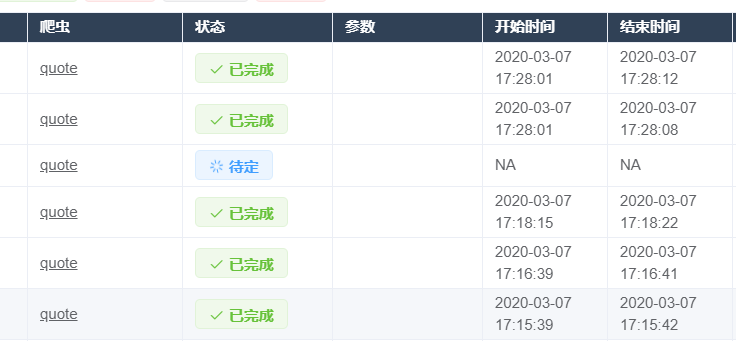
将上面设置的爬虫设置定时运行。

为了看清楚效用,设置了每分钟运行一次,它是基于linux下的crontab设置的定时任务
关于crontab的配置可参考:
https://blog.csdn.net/wade3015/article/details/90289751
ok,可以看到有在定时运行,没毛病~
感谢阅读,以上~
分布式爬虫管理平台Crawlab安装与使用的更多相关文章
- 使用Docker部署爬虫管理平台Crawlab
当前目录创建 docker-compose.yml 文件 version: '3.3' services: master: image: tikazyq/crawlab:latest containe ...
- Crawlab Lite 正式发布,更轻量的爬虫管理平台
Crawlab 是一款基于 Golang 的分布式爬虫管理平台,产品发布已经一年有余,经过开发团队的不断打磨,即将迭代到 v0.5 版本.在这期间我们为 Crawlab 加入了大量社区用户共同期望的功 ...
- 爬虫管理平台以及wordpress本地搭建
爬虫管理平台以及wordpress本地搭建 学习目标: 各爬虫管理平台了解 scrapydweb gerapy crawlab 各爬虫管理平台的本地搭建 Windows下的wordpress搭建 爬虫 ...
- 分布式缓存管理平台XXL-CACHE
<分布式缓存管理平台XXL-CACHE> 一.简介 1.1 概述 XXL-CACHE是一个分布式缓存管理平台,其核心设计目标是"让分布式缓存的接入和管理的更加的简洁和高效&quo ...
- 分布式逻辑管理平台XXL-GLUE
<分布式逻辑管理平台XXL-GLUE> 一.简介 1.1 概述 XXL-GLUE 是一个分布式环境下的 "可执行逻辑单元" 管理平台, 学习简单,扩展JVM的动态 ...
- KVM管理平台openebula安装
1.1opennebula控制台的安装 (如果要添加映像需要给200G以上给/var/lib/one,本文是共享/var/lib/one实现监控,用映像出创建虚拟机原理是从opennebula控制平台 ...
- 集中化管理平台Saltstack安装配置
salt是一个异构平台基础设置管理工具(虽然我们通常只用在Linux上),使用轻量级的通讯器ZMQ,用Python写成的批量管理工具,完全开源,遵守Apache2协议,与Puppet,Chef功能类似 ...
- Dubbo-admin管理平台的安装
1.到地址 https://github.com/alibaba/dubbo 下载dubbo源码 2.解压缩zip文件到 “ D:\技术资料\zookeeper\dubbo-master\dub ...
- KubeSphere企业级分布式多租户容器管理平台
KubeSphere企业级分布式多租户容器管理平台 KubeSphere安装部署2.1.0DEV版本
随机推荐
- python3多线程应用详解(第三卷:图解多线程中join,守护线程应用)
- C++中stoi函数
作用: 将 n 进制的字符串转化为十进制 头文件: #include <string> 用法: stoi(字符串,起始位置,n进制),将 n 进制的字符串转化为十进制 示例: stoi(s ...
- [LC] 303. Range Sum Query - Immutable
Given an integer array nums, find the sum of the elements between indices i and j (i ≤ j), inclusive ...
- apache和tomcat的关系
apache和tomcat的关系: 举个例子:apache是一辆卡车,上面可以装一些东西如html等.但是不能装水,要装水必须要有容器(桶),tomcat就是一个桶(装像JAVA这样的水),而这个桶也 ...
- 使用记事本编写html代码并运行
在使用记事本编写html代码,运行时需要将其.txt后缀改为.html双击运行即可. 有时电脑会默认的隐藏其后缀,这时需要修改一下. win7系统修改方法: 双击 我的电脑: 选择 组织: 选择 ...
- 测试误区《二》 python逻辑运算和关系运算优先级
关系运算 关系运算就是对2个对象进行比较,通过比较符判断进行比较,有6种方式. x > y 大于 x >= y 大于等于 x < y 小于 x <= y 小于等于 x = y ...
- JVM笔记(一)
<ignore_js_op> Class Loader类加载器负责加载class文件,class文件在文件开头有特定的文件标识,并且ClassLoader只负责class文件的加载,至于它 ...
- JDK1.8新特性Lambda表达式
/** * Lambda * @date 2019/8/2 10:03 */ public class Lamda { public static void main(String[] args){ ...
- Matplotlib绘图库入门(七):高效使用
原文地址: !()[http://www.bugingcode.com/blog/Matplotlib_7_Effectively_Using.html] 这是一篇关于如何高效的使用Matplotli ...
- 阿里投资Magic Leap 是美酒还是毒药?
Leap 是美酒还是毒药?" title="阿里投资Magic Leap 是美酒还是毒药?"> 土豪阿里又摊上"大事"了!但这次不是让人头痛的假 ...