Redis07——Redis到底能用在什么地方(下)
在前一篇文章中,我们已经介绍过Redis的一些实际应用。如KV缓存、分布式锁、消息队列,由于篇幅原因,并未介绍完全。接下来将继续为各位带来Redis的更多应用。
bitmat(位图)
实现
位图的基本思想是使用一个bit来表示一个映射关系,这样就能大大减小内存的使用。如一个用户一周的签到情况可以用以下方式来实现。
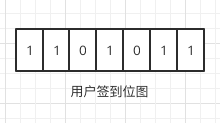
如果不用位图,而用int 来实现的话,需要7个int的空间来存储,而使用位图后,一个int空间即可表示出用户一周的签到情况了。
常用指令
- setbit:设置位图值;
127.0.0.1:6379> setbit bitmapkey 2 1 # 指定数组位
(integer) 0
127.0.0.1:6379> setbit bitmapkeyk javamd # 不指定数组位
(integer) 0
Redis位数组是自动扩展的,如果设置了超出现有内容范围的位值,将会对位数组进行自动填充零的处理。
- getbit:获取位图值;
127.0.0.1:6379> getbit bitmapkey 2 # 指定数组位
(integer) 1
127.0.0.1:6379> getbit bitmapkeyk # 不指定数组位
"javamd"
- bitcount:位图统计;
127.0.0.1:6379> bitcount key 0 0 # 第一个字符串中1的位数
(integer) 1
- bitpos:位图查找;
127.0.0.1:6379> bitpos key 0 # 第一个0的位数
(integer) 3
127.0.0.1:6379> bitpos key 1 1 1 # 从第二个字符算起,第一个1位
(integer) 3
- bitfield:位图管道处理;bitfield有三个子指令,get、set、incrby,可以对指定位片段进行操作,单个指令最多只能处理64个连续位。
应用场景:用户签到、用户画像标签、大量整数排序等场景。
HyperLogLog
原理
伯努利实验 :一次伯努利实验,抛硬币不管进行抛掷次数多少次,只要出现一个正面,就称之为为一次伯努利实验。伯努利实验存在一个关系:n = 2^(k_max) (n:伯努利实验次数,k_max: 抛掷次数最大的次数)。
比特串:hash(key) = 比特串。通过取模、前m位比特值转化为十进制等方式,确定在哪个桶内。
分桶:分桶是为了减少偶然误差性,可以理解为解决hash算法的hash冲突,分桶越多,误差越小。
Redis中HyperLogLog用了16384个桶,即2^ 14,每个桶的k_max需要6个bit来存储,最大可以表示maxbits=63,一个HyperLogLog总内存占用量为(2^14)*6/8 = 12KB。
常用指令
- pfadd:添加基数;
- pfcount:统计基础数量;
- pfmerge:合并pf基数,形成一个新的pf。
应用场景
Redis HyperLogLog 的应用有以下特点:
- 如果基数不大或数据量不大就不太适用,会有点大材小用浪费空间;
- 有一定局限性——只能统计基数数量,而没办法去知道具体的内容是什么;
- 和bitmap相比,属于两种特定统计情况,简单来说,HyperLogLog 去重比 bitmap 方便很多;
- 一般可以bitmap和HyperLogLog配合使用,bitmap标识哪些用户活跃,HyperLogLog计数。
使用场景有以下场景:
- 统计注册 IP 数;
- 统计每日访问 IP 数;
- 统计页面实时 UV 数;
- 统计在线用户数。
Bloom Filter (布隆过滤器)
Redis从4.0起,开始支持Boolm Filter这种高级数据结构。
实现
布隆过滤器实际上就是由一个大型位数组和几个不一样的的无偏hash函数组成。
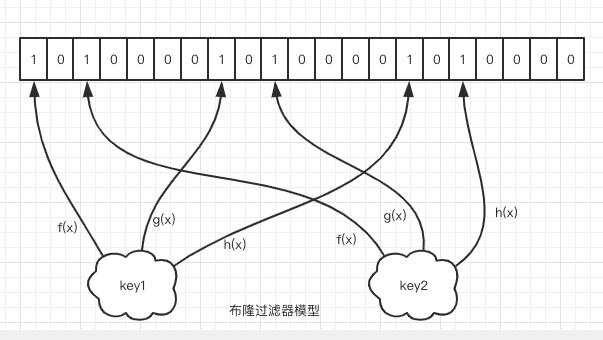
添加key步骤:
- 添加key时,会用多个hash函数对key进行hash取值;
- 然后用数组长度对hash值进行取模运算,得到对应的位置,每个hash函数都会得到一个不一样的位置;
- 同时对相应位置进行置1操作,即完成add操作。
查询key是否存在时,与add操作一致,查询对应位是否为1即可。如果有一个不为1,则说明key不存在,如果都为1,则说明key可能存在。key可能存在是因为,受数组长度影响产生的hash冲突,导致key可能存在。
建议
- 使用时不要让实际元素远大于初始化大小;
- 当实际元素开始超出初始化大小时,应该重新分配一个 size 更大的过滤器。
应用场景
布隆过滤器可以用在以下场景:
- 查询用户是否已经看过某条新闻;
- 爬虫系统中,对URL进行去重操作;
- 邮箱垃圾邮件过滤;
- 防止缓存穿透(即一直在库里查询某个不存在的key,影响数据库性能)。
Geo
在地理位置中查询附近的点时,我们可以使用Redis的Geo模块来解决这一问题。
数据库查询附近的点
当两个地理坐标相差不是很远的情况下,我们可以使用勾股定理来计算元素间的距离。
通过数据库,当给定一个坐标,查询附近的其他地理点时,我们可以先选定指定一个半径范围,然后筛选出该半径范围内所有的坐标点,对坐标点与目标点进行勾股定理算距排序。
GeoHash算法
当高并发场景,数据库筛选的方法并不合适,这时我们可以使用Redis的Geo模块来解决这一问题。
算法实现:GeoHash算法,将地球表面看做一个平面,然后划分成等分的小方格(划分越小,坐标位置精度越高),将方格转换为二位数组来表示,如00,01,02…0n,10,11,12…1n,n0,n1,n2……nn。这样每一个坐标,都能用一个整数来表示,通过这个整数,就能还原出元素的坐标。GeoHash算法再将这个整数进行base32编码。
在Redis中,经纬度用52位整数进行编码,然后放入zset中。zset的value是元素id,score是52位整数值。通过zset的score排序,就可以得到指定坐标附近的其他元素。通过score即可将整数还原成具体的坐标值。
注意事项
在使用Redids 的Geo实现附近的人需要注意,由于该结构需要较大的内存,所以建议使用单独的Redis实例,不建议做主从复制。同时可以根据数据量按地理行政级别进行拆分。
限流
在Redis中,可以根据实际情况使用以下方式实现限流。
zset
对于系统限定某个用户的某个行为在一定时间内只能发生N次的情况,可以使用zset进行限流。
实现:将用户ID与动作key当做zset的key,使用时间戳,当zset的score,value保证唯一性即可。然后根据score圈定指定时间范围内的value,这样就能实现限定某个用户的某个行为在一定时间内只能发生N次的限流需求。
应用:zset限流可以用于以下情况:
- 用户行为限流;
- 数据推送频次限流。
Redis-Cell(漏斗限流)
Redis-Cell采用的是漏斗限流,漏斗容量是有限的,同时漏斗口大小是有限的,即有一个漏水速率。通过漏斗容量,漏斗速率,漏斗剩余空间,上一次漏水时间,我们就能实现一个完整的漏斗算法。Redis中初始化Redis-Cell方法如下:
# 限制用户在60秒时间内只能回复30次(漏水速率为30次/60S)
127.0.0.1:6379>cl.throttle keykey 15 30 60 1
1) (integer) 0 # 0 表示允许,1 表示拒绝
2) (integer) 15 # 漏斗容量
3) (integer) 14 # 漏斗剩余空间
4) (integer) -1 # 如果被拒绝了,需要多长时间再试
5) (integer) 2 # 多长时间后,漏斗能完全空出来
Redis系列推荐
Redis05——Redis Cluster 如何实现分布式集群
Redis07——Redis到底能用在什么地方(下)的更多相关文章
- Redis06——Redis到底能用在什么地方(上)
之前我们介绍了一些列关于Redis的数据结构.持久化.过期&淘汰策略.集群化等知识点,感兴趣的小伙伴可以在文章的末尾查看往期内容.今天将为大家带来Redis的应用.由于本篇文章较长,所以将拆分 ...
- Redis到底该如何利用?
Redis是个好东西,经过上两个星期的研究和实践,目前正在项目里大规模的替换掉原来的本地内存cache.但是替换过程中却发现,Redis这东西高端,大气上档次,似乎不是我想象里的使用方法. 在没有深入 ...
- Redis到底该如何利用?【转自:http://www.cnblogs.com/capqueen/p/HowToUseRedis.html】
Redis是个好东西,经过上两个星期的研究和实践,目前正在项目里大规模的替换掉原来的本地内存cache.但是替换过程中却发现,Redis这东西高端,大气上档次,似乎不是我想象里的使用方法. 在没有深入 ...
- Redis、Redis+sentinel安装(Ubuntu 14.04下Redis安装及简单测试)
Ubuntu下Redis安装两种安装方式: 1.apt-get方式 步骤: 以root权限登录,切换到/usr目录下. 接下来输入命令,apt-get install redis-server,如图: ...
- Redis 数据结构与内存管理策略(下)
Redis 数据结构与内存管理策略(下) 标签: Redis Redis数据结构 Redis内存管理策略 Redis数据类型 Redis类型映射 Redis 数据类型特点与使用场景 String.Li ...
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- Redis到底该如何利用(二)?
上一篇文章里我简述了使用Keys作为Redis搜索的方式,确实感受到了社区的力量,写文章好处多.首先谢谢各位前辈的指导,我知道了拿Redis作为搜索是个错误的方向.本来这篇文章我觉得确实没必要发了,但 ...
- 搞懂Redis到底快在哪里
前言 Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,hash,list,set,zset,Bitmaps,HyperLogLog等多种数 ...
- 四个大点,搞懂 Redis 到底快在哪里
来源:https://mp.weixin.qq.com/s/4kPlBE3C6lTuSvt5mY5hUQ 前言 一. 开发语言 二. 纯内存访问 三. 单线程 四. 非阻塞多路I/O复用机制 前言 R ...
随机推荐
- 信贷建模little tricks
一.逻辑回归 概率分类模型 选取样本:对逻辑回归这种概率分类模型来说维持原来样本真实的分布还是有必要的,但是对一些树模型来说可以通过采样来平衡样本. 原来评分卡建模还有个拒绝推断,就是为了还原人群真实 ...
- 听《Sara》
Sara这首歌太好听了,虽然没有清楚具体是唱什么,但我感觉是讲一个故事,很好奇,我找到了歌词. Sara 塞拉 鲍勃迪伦 I laid on a dune, I looked at the sky, ...
- 精心收集的Hadoop学习资料
1.<Hadoop技术内幕:深入解析Hadoop Common和HDFS>下载地址:http://download.csdn.net/detail/w397090770/6643259. ...
- Esp8266和HomeKit
Summary 没有找到合适的简单解决方案,将Esp8266控制的设备连接到HomeKit.所以参照EspEasy实现 HomeKit和Esp8266连接. 连接方式: Raspberry Zero ...
- 写个匹配某段html dom代码某属性的正则匹配方法
private static string GetHtmlDomAttr(string html, string id, string attrname) { string xmatchstring ...
- pycharm中进行全局搜索
- 第一次提交本地代码到github上
上传本地项目到github: 一.SSH方式 配置ssh 进入你要上传项目中的文件夹 1)先配置ssh,输入 ssh-keygen -t rsa -C "your_email@example ...
- js类型比较
比较数据类型做比较的三种方法typeofinstanceofObject.prototype.toString.call() javascript七大类型 javascript的数据类型分为两类:原始 ...
- JXL包大解析;Java程序生成excel文件和解析excel文件内容
最近需求变化,需要把excel导入 我以前没有做过,所以我查了一些资料 和参考别人的代码 以下是多种方式: import java.io.File; import java.io.FileInputS ...
- Dungeon Master (三维BFS)
题目: You are trapped in a 3D dungeon and need to find the quickest way out! The dungeon is composed o ...