[一起面试AI]NO.5过拟合、欠拟合与正则化是什么?
Q1 过拟合与欠拟合的区别是什么,什么是正则化
欠拟合指的是模型不能够再训练集上获得足够低的「训练误差」,往往由于特征维度过少,导致拟合的函数无法满足训练集,导致误差较大。
过拟合指的是模型训练误差与测试误差之间差距过大;具体来说就是模型在训练集上训练过度,导致泛化能力过差。
「所有为了减少测试误差的策略统称为正则化方法」,不过代价可能是增大训练误差。
Q2 解决欠拟合的方法有哪些
降低欠拟合风险主要有以下3类方法。
加入新的特征,对于深度学习来讲就可以利用因子分解机、子编码器等。
增加模型复杂度,对于线性模型来说可以增加高次项,对于深度学习来讲可以增加网络层数、神经元个数。
减小正则化项的系数,从而提高模型的学习能力。
Q3 防止过拟合的方法主要有哪些
「1.正则化」
正则化包含L1正则化、L2正则化、混合L1与L2正则化。
「L1正则化」目的是减少参数的绝对值总和,定义为:
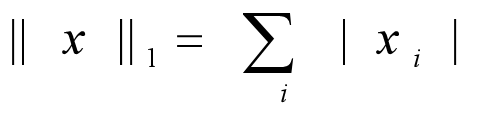
「L2正则化」目的是减少参数平方的总和,定义为:
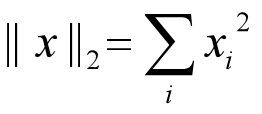
**混合L1与L2**正则化是希望能够调节L1正则化与L2正则化,定义为:
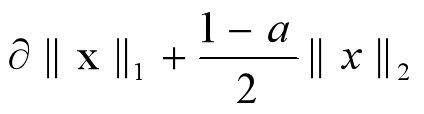
因为最优的参数值很大概率出现在「坐标轴」上,这样就会导致某一维的权重为0,产生「稀疏权重矩阵」。而L2正则化的最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。
所以由于L1正则化导致参数趋近于0,因此它常用于特征选择设置中。而机器学习中最常用的正则化方法是对权重施加「L2范数约束」。
L1正则化与L2正则化还有个「重要区别」就是L1正则化可通过假设权重w的先验分布为「拉普拉斯分布」,由最大后验概率估计导出。L2正则化可通过假设权重w的先验分布为「高斯分布」,由最大后验概率估计导出。
「2.Batch Normalization」
Batch Normalization是一种深度学习中减少泛化误差的「正则化」方法,主要是通过缓解梯度下降加速网络的训练,防止过拟合,降低了参数初始化的要求。
由于训练数据与测试数据分布不同会降低模型的泛化能力。因此,应该在开始训练前对数据进行「归一化处理」。因为神经网络每层的参数不同,每一批数据的分布也会改变,从而导致每次迭代都会去拟合不同的数据分布,增大过拟合的风险。
Batch Normalization会针对每一批数据在输入前进行归一化处理,目的是为了使得输入数据均值为0,标准差为1。这样就能将数据限制在统一的分布下。
「3.Dropout」
Dropout是避免神经网络过拟合的技巧来实现的。Dropout并不会改变网络,他会对神经元做「随机」删减,从而使得网络复杂度「降低」,有效的防止过拟合。
具体表现为:每一次迭代都删除一部分隐层单元,直至训练结束。
运用Dropout相当于训练了非常多的仅有部分隐层单元的神经网络,每个网络都会给出一个结果,随着训练的进行,大部分网络都会给出正确的结果。
「4.迭代截断」
迭代截断主要是在迭代中记录准确值,当达到最佳准确率的时候就截断训练。
「5.交叉验证」
K-flod交叉验证是把训练样本分成k份,在验证时,依次选取每一份样本作为验证集,每次实验中,使用此过程在验证集合上取得最佳性能的迭代次数,并选择恰当的参数。
hi 认识一下?
❝
微信关注公众号:「全都是码农」 (allmanong)
你将获得:
关于人工智能的所有面试问题「一网打尽」!未来还有「思维导图」哦!
回复「121」 立即获得 已整理好121本「python学习电子书」。
回复「89」 立即获得 「程序员」史诗级必读书单吐血整理「四个维度」系列89本书。
回复「167」 立即获得 「机器学习和python」学习之路史上整理「大数据技术书」从入门到进阶最全本(66本)
回复「18」 立即获得 「数据库」从入门到进阶必读18本技术书籍网盘整理电子书(珍藏版)
回复「56」 立即获得 我整理的56本「算法与数据结构」书
未来还有人工智能研究生课程笔记等等,我们一起进步呀!
❞

[一起面试AI]NO.5过拟合、欠拟合与正则化是什么?的更多相关文章
- 过拟合/欠拟合&logistic回归等总结(Ng第二课)
昨天学习完了Ng的第二课,总结如下: 过拟合:欠拟合: 参数学习算法:非参数学习算法 局部加权回归 KD tree 最小二乘 中心极限定律 感知器算法 sigmod函数 梯度下降/梯度上升 二元分类 ...
- 动手学习Pytorch(4)--过拟合欠拟合及其解决方案
过拟合.欠拟合及其解决方案 过拟合.欠拟合的概念 权重衰减 丢弃法 模型选择.过拟合和欠拟合 训练误差和泛化误差 在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差 ...
- L13过拟合欠拟合及其解决方案
过拟合.欠拟合及其解决方案 过拟合.欠拟合的概念 权重衰减 丢弃法 模型选择.过拟合和欠拟合 训练误差和泛化误差 在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差(g ...
- L7过拟合欠拟合及其解决方案
1.涉及语句 import d2lzh1981 as d2l 数据1 : d2lzh1981 链接:https://pan.baidu.com/s/1LyaZ84Q4M75GLOO-ZPvPoA 提取 ...
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- 过拟合VS欠拟合、偏差VS方差
1. 过拟合 欠拟合 过拟合:在训练集(training set)上表现好,但是在测试集上效果差,也就是说在已知的数据集合中非常好,但是在添加一些新的数据进来训练效果就会差很多,造成这样的原因是考虑影 ...
- AI - TensorFlow - 示例04:过拟合与欠拟合
过拟合与欠拟合(Overfitting and underfitting) 官网示例:https://www.tensorflow.org/tutorials/keras/overfit_and_un ...
- TensorFlow从1到2(八)过拟合和欠拟合的优化
<从锅炉工到AI专家(6)>一文中,我们把神经网络模型降维,简单的在二维空间中介绍了过拟合和欠拟合的现象和解决方法.但是因为条件所限,在该文中我们只介绍了理论,并没有实际观察现象和应对. ...
- 局部加权回归、欠拟合、过拟合(Locally Weighted Linear Regression、Underfitting、Overfitting)
欠拟合.过拟合 如下图中三个拟合模型.第一个是一个线性模型,对训练数据拟合不够好,损失函数取值较大.如图中第二个模型,如果我们在线性模型上加一个新特征项,拟合结果就会好一些.图中第三个是一个包含5阶多 ...
随机推荐
- Java Grammar(三):修饰符
简介 修饰符是用于限定类型以及类型成员申明的一种符号,从修饰对象上可以分为类修饰符,方法修饰符,变量修饰符:从功能上可以划分为访问控制修饰符和非访问修饰符.访问修饰符控制访问权限,不同的访问修饰符有不 ...
- [日志分析]Graylog2进阶 通过正则解析Nginx日志
之前分享的 [日志分析]Graylog2采集Nginx日志 主动方式 这篇文章介绍了Graylog如何通过Graylog Collector Sidecar来采集nginx日志. 由于日志是未经处理的 ...
- JAVA反射概念及使用详解(超详细)
JAVA反射概念及使用详解 一.什么是反射? 反射:框架设计的灵魂 框架:半成品软件.可以在框架的基础上进行软件开发,简化编码 反射:将类的各个组成部分封装为其他对象,这就是反射机制 好处: ...
- Spring解决循环依赖,你真的懂了吗?
导读 前几天发表的文章SpringBoot多数据源动态切换和SpringBoot整合多数据源的巨坑中,提到了一个坑就是动态数据源添加@Primary接口就会造成循环依赖异常,如下图: 这个就是典型的构 ...
- (转)协议森林07 傀儡 (UDP协议)
协议森林07 傀儡 (UDP协议) 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 我们已经讲解了物理层.连接层和网络层.最开始的 ...
- chrome DevTools 里面 css样式里面 勾上 :hover 会将鼠标移上的效果一直保持,技巧:要在鼠标上的 div上 勾 :hover
chrome DevTools 里面 css样式里面 勾上 :hover 会将鼠标移上的效果一直保持,技巧:要在鼠标上的 div上 勾 :hover
- KEIL编译出现错误“source file is not valid utf-8”
实际情况是: .h文件一直报错source file is not valid utf-8的错误, 原因就是: 文件中出现了一个中文的“:”导致的.总结就是:如出现此类错误,可能是字符不够标准.
- fastText 训练和使用
2019-09-09 16:33:11 问题描述:fastText是如何进行文本分类的. 问题求解: fastText是一种Facebook AI Research在16年开源的一个文本分类器. 其特 ...
- flume面试题
1 你是如何实现Flume数据传输的监控的使用第三方框架Ganglia实时监控Flume. 2 Flume的Source,Sink,Channel的作用?你们Source是什么类型?1.作用 (1)S ...
- 【笔记3-31】Python语言基础-列表list
列表list my_list = [1, 2, 3, 4, 5] 索引index my_list[0] 获取列表长度 len(my_list) 切片 [起始:结束:步长] my_list[1:3:2] ...