吴裕雄--天生自然HADOOP操作实验学习笔记:协同过滤算法
实验目的
初步认识推荐系统
学会用mapreduce实现复杂的算法
学会系统过滤算法的基本步骤
实验原理
前面我们说过了qq的好友推荐,其实推荐算法是所有机器学习算法中最重要、最基础、最复杂的算法,一个推荐系统的架构,需要综合考虑离线计算、实时计算。需要用到的技术可能还有Flume、Kafka、Redis、Storm、Spark,算法包括ALS矩阵分解、协同过滤、线性回归、余弦相似度等。
1.协同过滤
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
协同过滤又可分为评比(rating)或者群体过滤(social filtering)。协同过滤以其出色的速度和健壮性,在全球互联网领域炙手可热。
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。简单的说就是:物以类聚,人以群分。
2.协同过滤基本思想
如果两个人对相同商品的打分比较相似,我们就说这两个人比较相似,那么其中一个人买过的东西我们就可以推荐给另一个人,这是基于用户的相似度,我们称之为基于用户的协同过滤。同理,如果同一个人对两个物品打分相似,我们说这两个物品比较相似,我们就可以给购买了其中一个物品的人推荐另一个物品,这就是基于物品的协同过滤。总结来说:
基于用户的协同过滤就是:跟你喜好相似的人喜欢的东西你也很有可能喜欢
基于物品的协同过滤就是:跟你喜欢的东西类似的东西你也可能喜欢
3.协同过滤的实现思路
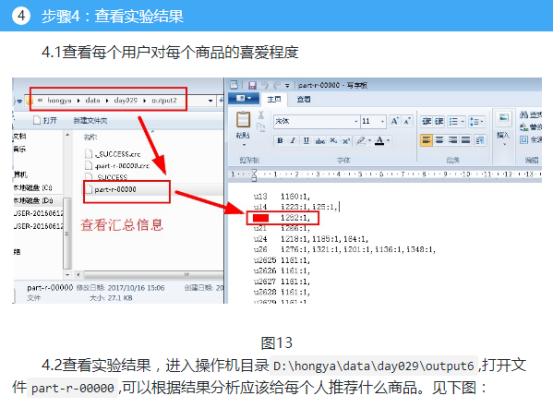
以基于物品的协同过滤为例,第一步我们就是要找到物品之间的相似性,假如我们已经找到了n个商品相互之间的相似性,量化为一个n维矩阵。第二步就是找到要推荐的用户对每个商品的喜爱程度,也就是这个用户给每个商品的打分,假设已经找到了他对n个商品的喜爱程度,量化为一个n维向量(如果不知道他对某个商品的喜爱程度,打分就是0)。第三步我们可以通过将这个相似矩阵乘以这个喜爱向量,就能得到一个新的向量,新的向量的值就代表每个商品给这个用户的推荐指数。
所以主要就是两个问题:相似矩阵、喜爱矩阵(一个用户是喜爱向量、多个用户是喜爱矩阵)。
3.1求相似矩阵
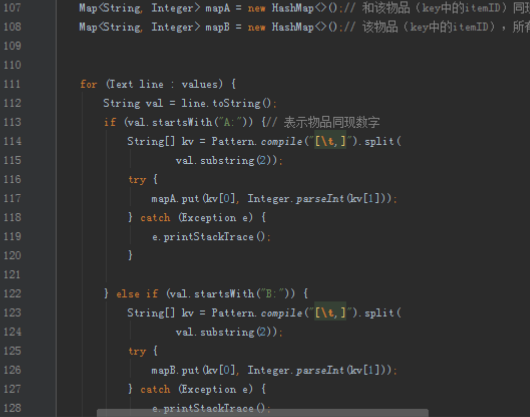
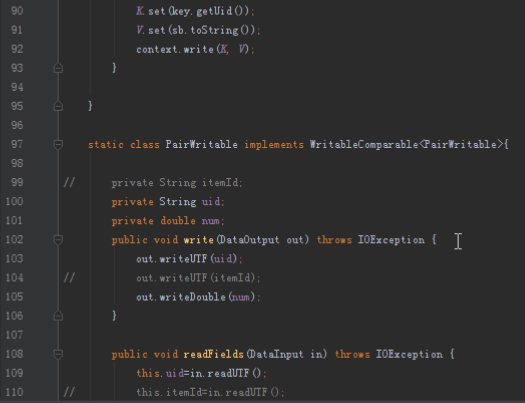
相似性的计算思路比较多,例如根据商品的内容,计算他们的余弦相似度的,这种方法大家可以自行查阅资料。我们计算在喜欢物品i的用户中有多少是喜欢物品j的,也就是同时出现的次数。当一个用户对两个物品都喜欢的时候,我们往往可以认为这两个物品可能属于同一分类。所以我们的相似矩阵就是计算一个同时出现的次数得到。
3.2计算喜爱矩阵
计算一个用户对一个商品的喜爱程度,我们可以根据这个用户的行为得到,最简单的就是买了就是1,不买就是0。实际上这样得到的数据并不能很好的反应真实情况,因为用户行为还有很多,包括浏览、收藏、加购物车、购买等。我们可以通过线性回归的方法去拟合每个行为的权重。我们为了简便,直接假设这四种行为的权重分别为1、2、3、4,也就是说如果用户购买了就说明喜爱程度是4,收藏就说明喜爱程度是2。
4.代码实现协同过滤
第一步,原始数据清洗。由于我们需要的只是一条url里面的用户id、商品id、行为。所以第一步就是过滤数据,取出关键信息。
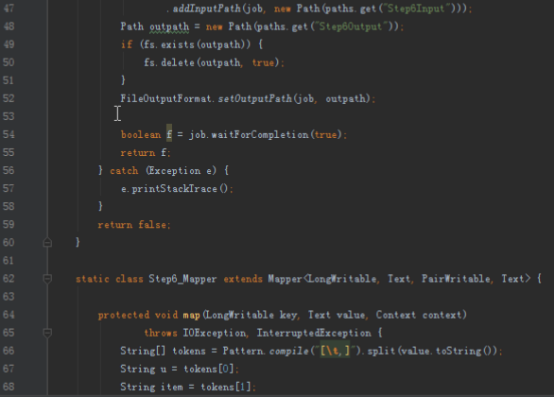
第二步,计算相似矩阵。
实验环境
1.操作系统
操作机:Windows_7
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1)最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2)首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3)其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4)最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1)插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2)在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3)匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4)资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
智能选择
丰富的导航模式
历史记录功能
JUnit的完美支持
对重构的优越支持
编码辅助
灵活的排版功能
XML的完美支持
动态语法检测
代码检查等等。
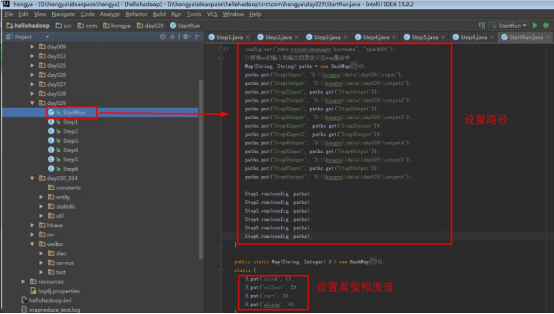
步骤2:代码分析
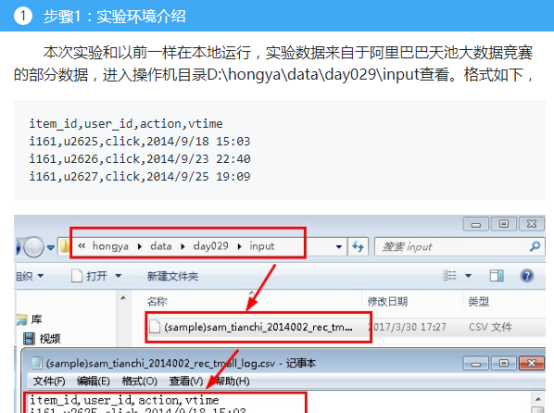
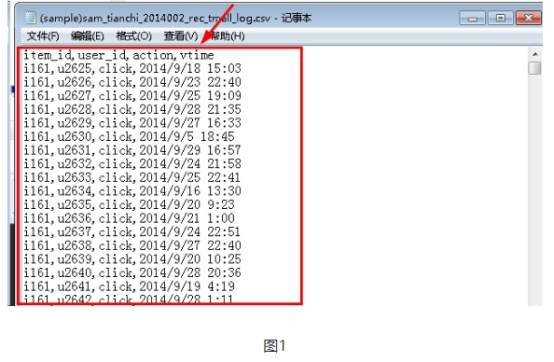
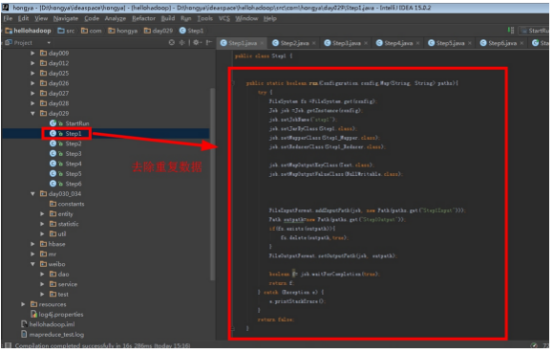
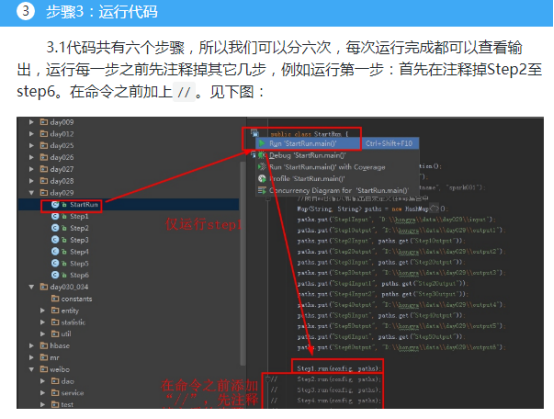
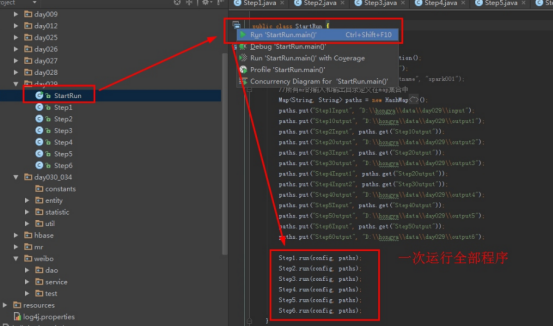
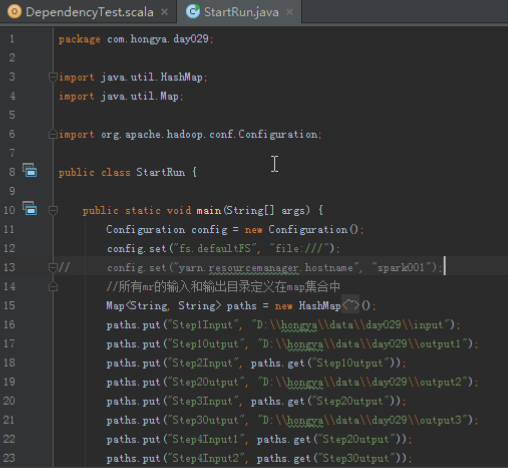
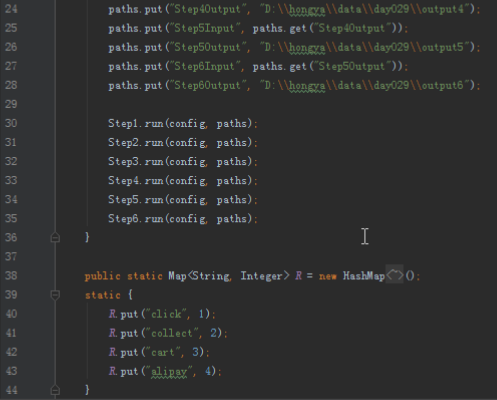
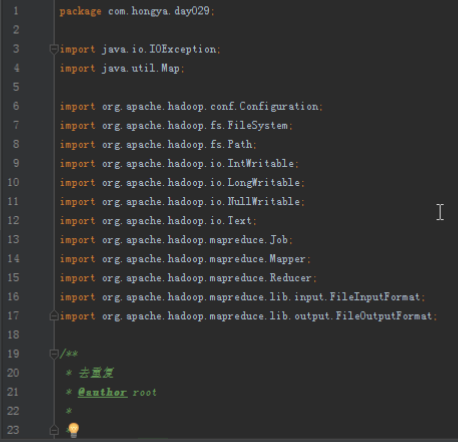
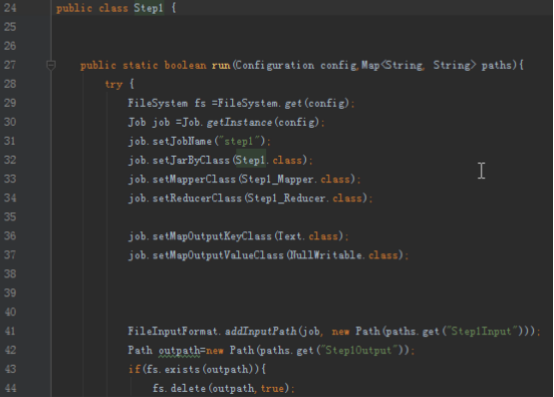
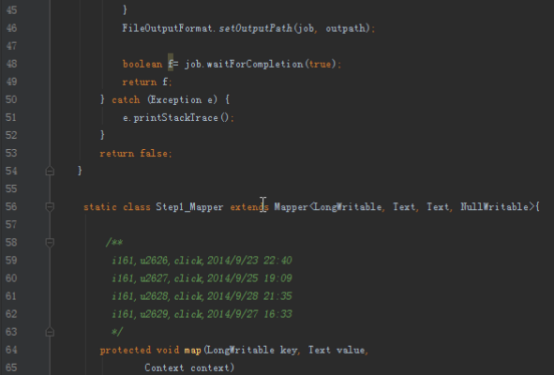
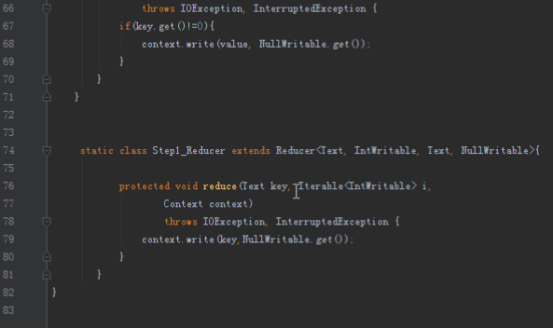
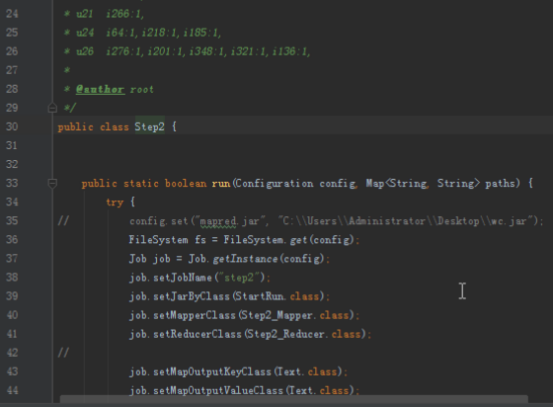
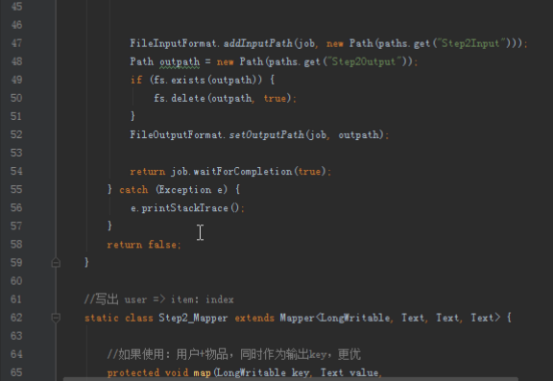
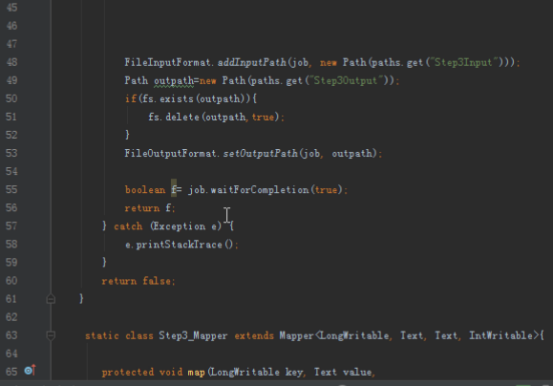
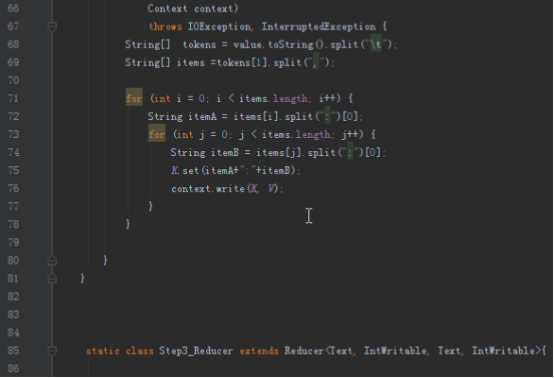
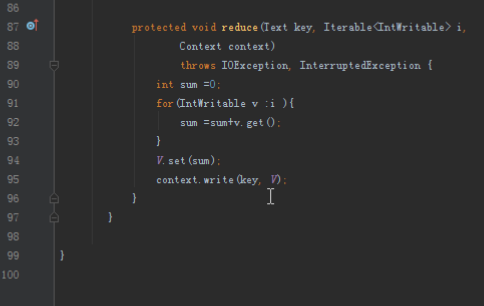
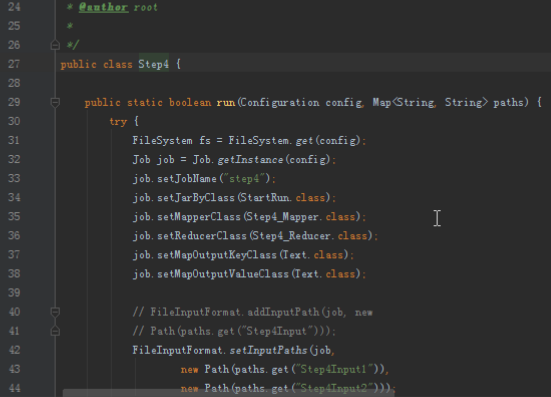
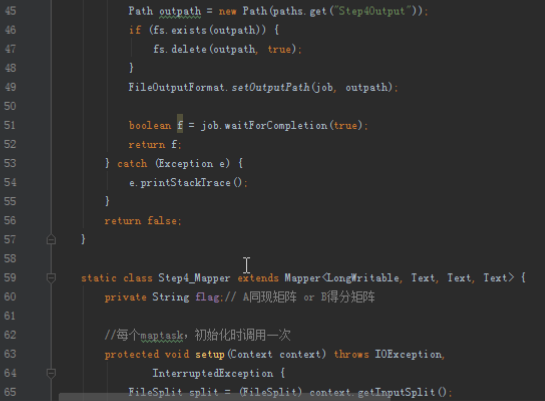
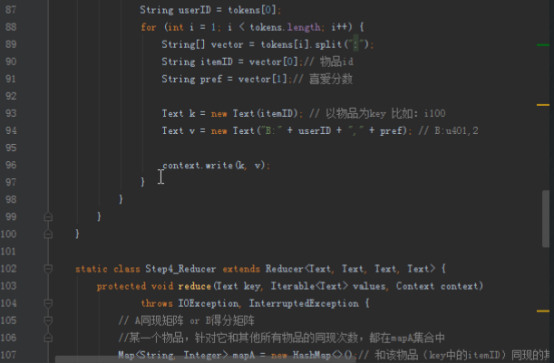
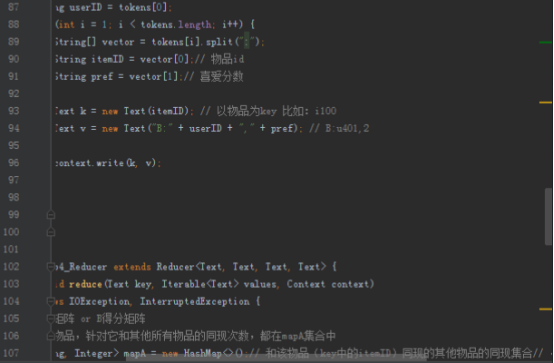
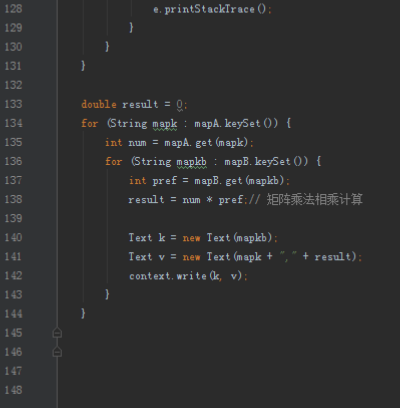
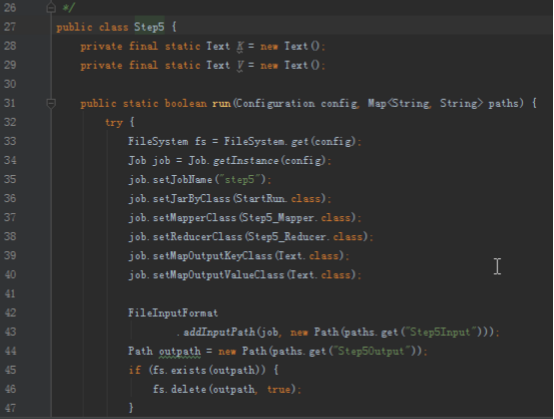
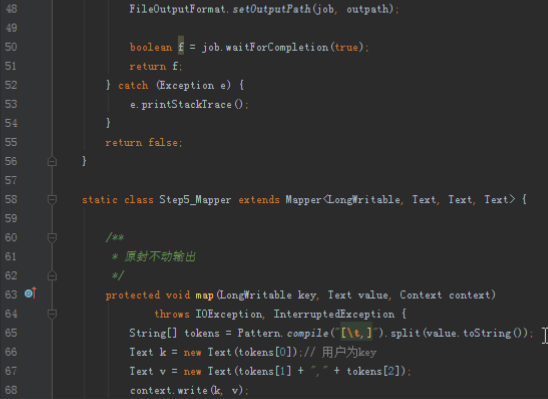
首先操作中打开桌面的IDEA,直接进入hellohadoop|com.hongya|day029下查看实验要用到的代码(其代码文目为:D:\hongya\ideaspace\hellohadoop\src\com\hongya\day029)。本次的逻辑比前几次都复杂,代码量比前几次都大,需要连续跑六个mapred,我们设计的时候尽量每一步简单。
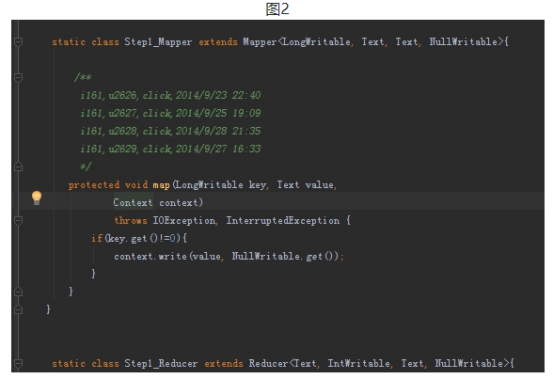
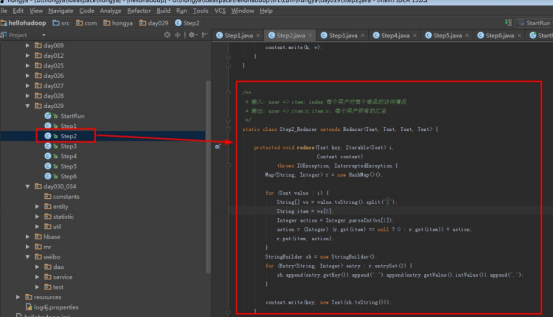
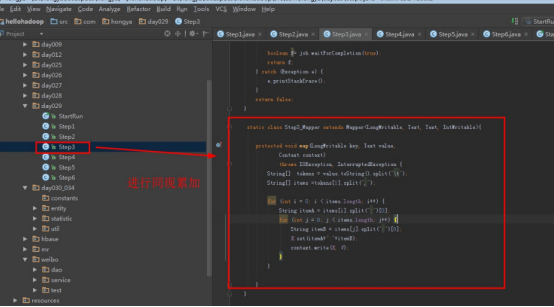
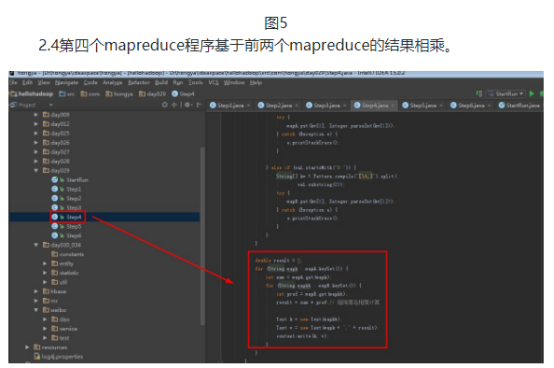
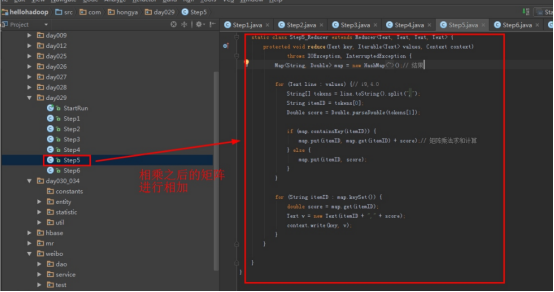
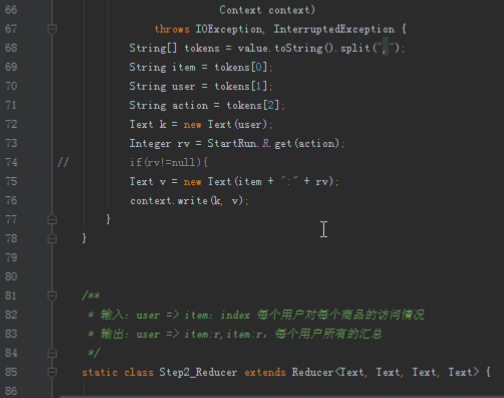
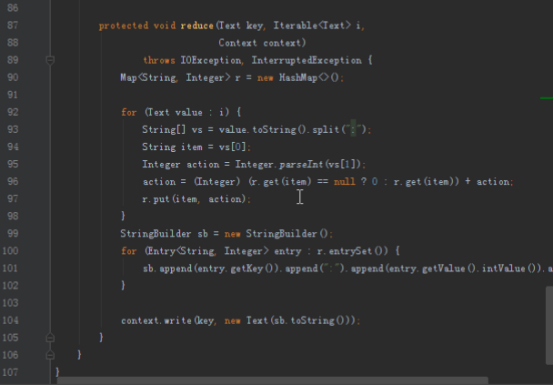
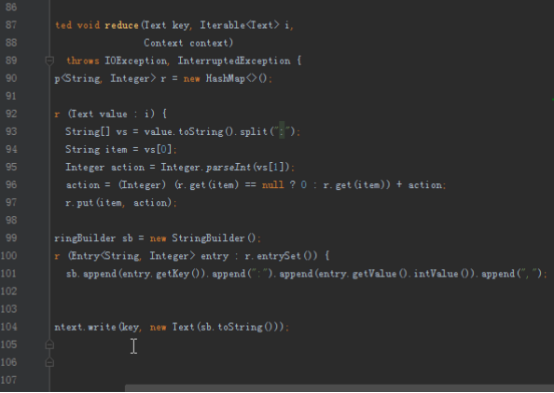
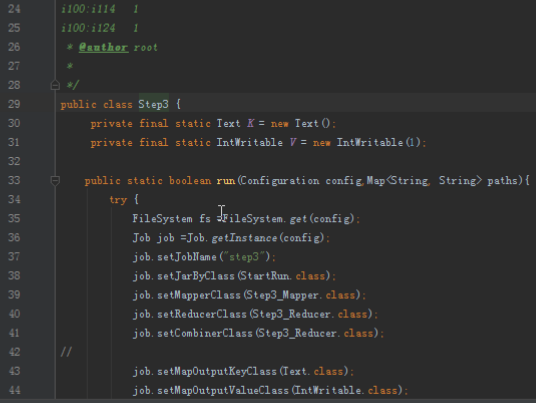
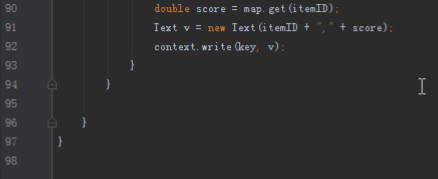
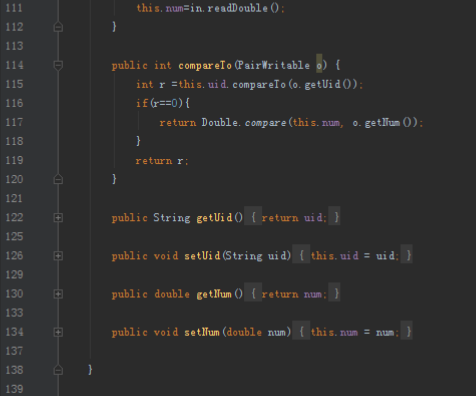
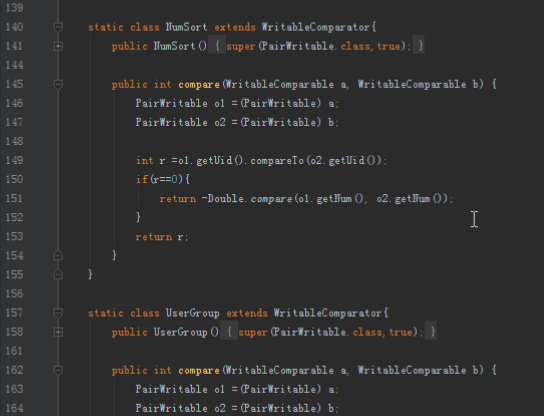
2.1第一个mapreduce程序主要是对数据清洗:
map方法直接写出,reduce方法只写出第一个。


















吴裕雄--天生自然HADOOP操作实验学习笔记:协同过滤算法的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:tf-idf算法
实验目的 通过实验了解tf-idf算法原理 通过实验了解mapreduce的更多组件 学会自定义分区,读写缓存文件 了解mapreduce程序的设计方法 实验原理 1.TF-IDF简介 TF-IDF( ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pagerank算法
实验目的 了解PageRank算法 学会用mapreduce解决实际的复杂计算问题 实验原理 1.pagerank算法简介 PageRank,即网页排名,又称网页级别.Google左侧排名或佩奇排名. ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
随机推荐
- P1432
这个题是一个很简单的等比数列. 题目大意是:初始第一步 $ n_1 = 2 $,之后的每一步都比前一步减少 98%,即满足等比数列 $ 2 + 2 \times 0.98 + 2 \times 0.9 ...
- SQLite3介绍
一.SQLite数据库简介 SQLite 是一个软件库,实现了自给自足的.无服务器的.零配置的.事务性的 SQL 数据库引擎.SQLite 是在世界上最广泛部署的 SQL 数据库引擎. DDL - 数 ...
- Win Oracle 监听文件配置参考
Win lister.ora配置参考 # listener.ora Network Configuration File: C:\app\Administrator\product\\dbhome_1 ...
- 「NOIP2013」货车运输
传送门 Luogu 解题思路 首先 \(\text{Kruskal}\) 一下,构造出一棵森林. 并查集还要用来判断连通性. 倍增 \(\text{LCA}\) 的时候顺便维护一下路径最小值即可. 细 ...
- IDEA中使用Springboot+SSM的踩坑记(一)
今天由于电脑无限蓝屏,不知怎么把我IDEA里面破解过的一些东西给搞没了,包括IDEA本体和JRebel,照着原来的方法破解连本体都开不起来了(哭死),索性下了个最新版来用,结果JRebel还是破解不得 ...
- 吴裕雄--天生自然Numpy库学习笔记:NumPy 高级索引
import numpy as np x = np.array([[1, 2], [3, 4], [5, 6]]) y = x[[0,1,2], [0,1,0]] print (y) import n ...
- 热部署简介及在eclipse安装插件JRebel进行热部署
一.热部署简介 1.热部署与热加载在应用运行的时候升级软件,无需重新启动的方式有两种,热部署和热加载.它们之间的区别是:(1).部署方式: 热部署在服务器运行时重新部署项目.热加载在运行时重新加载cl ...
- Nginx禁止使用ip访问,只允许使用域名访问
Nginx虚拟主机配置,vhosts下面有很多域名的配置: [root@external-lb01 vhosts]# pwd/data/nginx/conf/vhosts [root@external ...
- 「JSOI2014」支线剧情2
「JSOI2014」支线剧情2 传送门 不难发现原图是一个以 \(1\) 为根的有根树,所以我们考虑树形 \(\text{DP}\). 设 \(f_i\) 表示暴力地走完以 \(i\) 为根的子树的最 ...
- 入门项目数字手写体识别:使用Keras完成CNN模型搭建(重要)
摘要: 本文是通过Keras实现深度学习入门项目——数字手写体识别,整个流程介绍比较详细,适合初学者上手实践. 对于图像分类任务而言,卷积神经网络(CNN)是目前最优的网络结构,没有之一.在面部识别. ...