聚类算法——DBSCAN算法原理及公式
聚类的定义
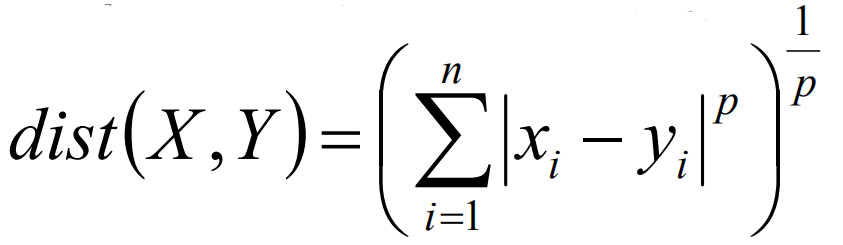
在上述的计算中,当p=1时,则是计算绝对值距离,通常叫做曼哈顿距离,当p=2时,表述的是欧式距离。
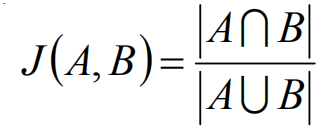
杰卡德相关系数主要用于描述集合之间的相似度,在目标检测中,iou的计算就和此公式相类似
余弦相似度
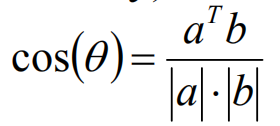
余弦相似度通过夹角的余弦来描述相似性
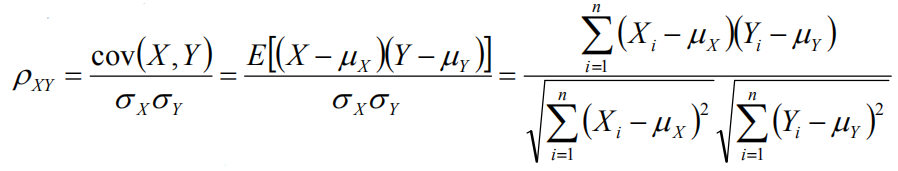
相对熵(K-L距离)
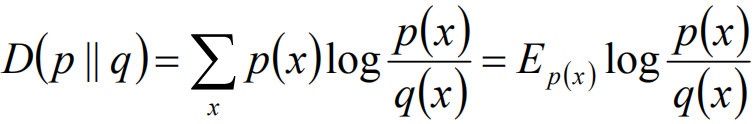
相对熵的相似度是不对称的相似度,D(p||q)不一定等于D(q||p)。
聚类的基本思想
给定一个有N个对象的数据集,划分聚类的技术将构造数据的K个划分,每个划分代表一个簇,K<=n。也就是说,聚类将数据划分为k个簇,而且这k个划分满足下列条件:
每个簇至少包含一个对象,每一个对象属于且仅属于一个簇。
具体的步骤为,对于给定的k,算法首先给出一个初始的划分方法。以后通过反复迭代的方法改变划分,使得每一次改进之后的划分方案都较前一次更好。
密度聚类
密度聚类方法的指导思想是,只要一个区域中的点的密度大于某个阈值,就把它加到与之相近的聚类中去。这类算法能够克服基于距离的算法只能发现“类圆形”的聚类的缺点,可以发现任意形状的聚类,且对噪声数据不敏感。但计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
DBSCAN算法
DBSCAN是一个比较有代表性的基于密度聚类的聚类算法,它对簇的定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有噪声的数据中发现任意形状的聚类。
DBSCAN相关定义
对象的ε-邻域:给定对象在半径ε内的区域。
核心对象:对于给定的数据m,如果一个对象的ε-邻域至少包含有m个对象,则成为该对象的核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε-邻域内,而q是一个核心对象,则对象p从对象q出发是直接密度可达的。
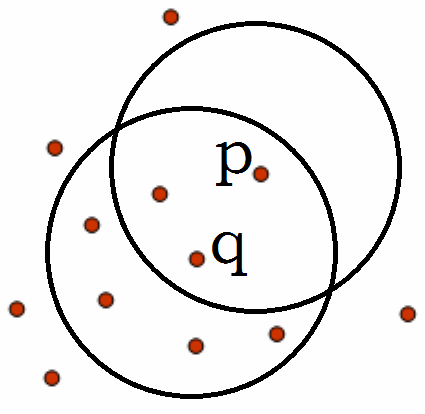
密度可达:如果存在一个对象链p1p2···pn,p1=q,pn=p,对pi属于D,pi+1是从pi关于ε和m直接密度可达的,则对象p是从对象q关于ε和m密度可达的。
密度相连:如果对象集合D中存在一个对象o,使得对象p和q是从o关于ε和m密度可达的,那么对象p和q是关于ε和m密度相连的。
簇:一个基于密度的簇是最大的密度相连对象的集合。
噪声:不包含在任何簇中的对象称为噪声。
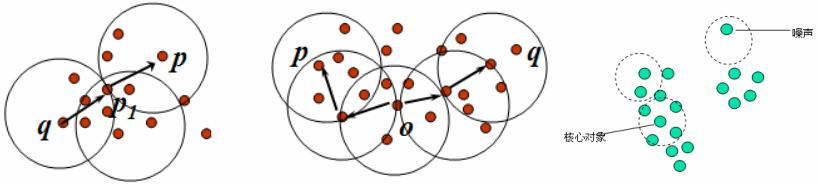
DBSCAN通过检查数据集中的每个对象的ε-邻域来寻找聚类,如果一个点p的ε-邻域包含对于m个对象,则创建一个p作为核心对象的新簇。然后,DBSCAN反复地寻找这些核心对象直接密度可达的对象,这个过程可能涉及密度可达簇的合并。当没有新的点可以被添加到任何簇时,该过程结束。算法的中ε和m是根据先验知识来给出的。
聚类算法——DBSCAN算法原理及公式的更多相关文章
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
- 机器学习--聚类系列--DBSCAN算法
DBSCAN算法 基本概念:(Density-Based Spatial Clustering of Applications with Noise) 核心对象:若某个点的密度达到算法设定的阈值则其为 ...
- 聚类之dbscan算法
简要的说明: dbscan为一个密度聚类算法,无需指定聚类个数. python的简单实例: # coding:utf-8 from sklearn.cluster import DBSCAN impo ...
- 【转】常用聚类算法(一) DBSCAN算法
原文链接:http://www.cnblogs.com/chaosimple/p/3164775.html#undefined 1.DBSCAN简介 DBSCAN(Density-Based Spat ...
- 常用聚类算法(一) DBSCAN算法
1.DBSCAN简介 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 【原创】大叔算法分享(5)聚类算法DBSCAN
一 简介 DBSCAN:Density-based spatial clustering of applications with noise is a data clustering algorit ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
随机推荐
- 2019-2020-1 20199325《Linux内核原理与分析》第一周作业
1.显示一句话welcome !/bin/bash script4-1.sht var1="welcome to use Shell script" echo $var1 pwd ...
- Spring5参考指南:事件Event
文章目录 基于继承的Event 基于注解的Event 异步侦听器 Spring提供了很方便的事件的处理机制,包括事件类ApplicationEvent和事件监听类ApplicationListener ...
- 曹工力荐:调试 jdk 中 rt.jar 包部分的源码(可自由增加注释,修改代码并debug)
背景 大家知道,jdk安装的目录下,一般会有个src.zip包,这个包基本对应了rt.jar这个包.rt.jar这个包里面,就放了jdk中,jdk采用java实现的那部分类库代码,比如java.lan ...
- springboot docker jenkins 自动化部署并上传镜像
springboot + docker + jenkins自动化部署项目,jenkins.mysql.redis都是docker运行的,并且没有使用虚拟机,就在阿里云服务器(centos7)运行 1. ...
- 【linux三剑客】sed命令
sed - stream editor for filtering and transforming text sed 流编辑器 strem edition,实现对文件的增删改替换查是Linux中第二 ...
- 标准库shutil
shutil模块是高级的 文件.文件夹.压缩包 处理模块. 下面是关于其中各种方法的使用介绍: 1.shutil.copyfileobj(fsrc, fdst[, length])将文件内容拷贝到另一 ...
- 15.Why lambda forms in python does not have statements?
Why lambda forms in python does not have statements? A lambda form in python does not have statement ...
- 定了,这个vue.js开源项目,面试时,一定会考问
因为现在的网店,都是用的商城系统, 而实体店都是入座后,扫码打开网上商城进行选购(餐饮,超市等),所以,vue.js迅速开发网上购物商城系统成为了香饽饽, 本人开源2020年4月开发的购物商城系统, ...
- NodeJs mysql 开启事务
如题:node后台使用mysql数据库,并使用事务来管理数据库操作. 这里主要讲一个事务的封装并写了一个INSERT 插入操作. code: 基础code: db.config.js const my ...
- 图论--最短路--Floyd(含路径输出)
#include<bits/stdc++.h> using namespace std; #define INF 0x3f3f3f3f #define maxn 1005 int D[ma ...