AI技术原理|机器学习算法
摘要
- 机器学习算法分类:监督学习、半监督学习、无监督学习、强化学习
- 基本的机器学习算法:线性回归、支持向量机(SVM)、最近邻居(KNN)、逻辑回归、决策树、k平均、随机森林、朴素贝叶斯、降维、梯度增强
- 公式、图示、案例
机器学习算法分类
机器学习算法大致可以分为:
- 监督学习 | Supervised learning
- 半监督学习 | Semi-supervised learning
- 无监督学习 | Unsupervised learning
- 强化学习 | Reinforcement learning
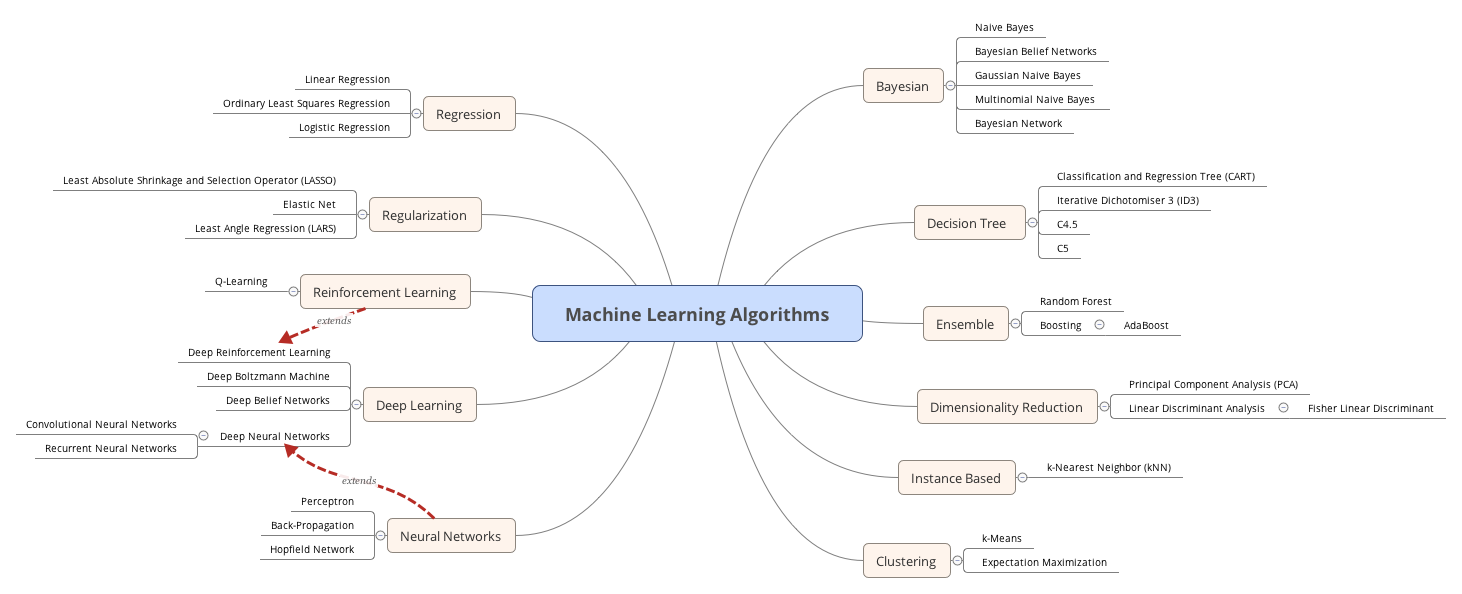 Machine-Learning-Algorithms
Machine-Learning-Algorithms
监督学习 | Supervised learning
监督学习算法基于一组示例进行预测。在监督学习训练过程中,可以由训练数据集学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。
监督学习算法要求特定的输入/输出,一个常见的例子是根据当年和前几年的销售情况估算下一年的销售额。首先需要决定 使用哪种数据作为范例。例如,文字识别应用中一个手写的字符,或一行手写文字。监督学习主要算法包括神经网络、支持向量机、最近邻居法、朴素贝叶斯法、决策树等。
- 分类(Classification):当数据被用于预测分类变量时,监督学习也被称为分类。为图像分配标签或指示器(例如狗或猫)时就是这种情况。当只有两个标签时,这称为二进制分类( binary classification)。当有两个以上的类别时,这些问题被称为多级分类(multi-class classification)。
- 回归(Regression):当我们需要预测连续值时,就变成了回归问题。
- 预测(Forecasting):根据过去和现在的数据对未来进行预测的过程。它最常用于分析趋势。
半监督学习 | Semi-supervised learning
监督学习带来的挑战是标签数据可能非常昂贵而且耗时。如果标签有限,可以使用未标记的示例来增强监督式学习。因为在这种情况下机器没有完全监督,所以我们说机器是半监督的。使用半监督学习,您可以使用带有少量标签数据的未标记示例来提高学习的准确性。
无监督学习 | Unsupervised learning
无监督学习算法没有特定的目标输出,算法将数据集分为不同的组。
在进行无监督学习时,机器会显示完全未标记的数据。它要求发现数据基础的内在模式,例如聚类结构(clustering structure),低维流形(a low-dimensional manifold)或稀疏树(sparse tree )和图(graph)。
- 聚类(Clustering):对一组数据示例进行分组,使一个组(或一个聚类)中的示例与其他组中的示例更相似(根据某些标准)。这通常用于将整个数据集分成几个组。可以在每个组中进行分析以帮助用户找到固有模式。
- 降维(Dimension reduction):减少需要考虑的变量数量。在许多应用中,原始数据具有非常高的维度特征,并且一些特征对于任务是多余的或不相关的。降维有助于找到数据内在真实的、潜在的关系。
强化学习 | Reinforcement learning
强化学习强调通过基于环境的反馈行为分析、优化以取得最佳预期。机器尝试不同的场景来发现哪些行为能产生最大的回报,而不是被告知要采取何种行动。反复试验(Trial-and-error)和延迟奖励(delayed reward)是将强化学习与其他技术区分开来的关键。
强化学习普适性强,主要基于决策进行训练,算法根据输出结果(决策)的成功或错误来训练自己,通过大量经验训练优化后的算法将能够给出较好的预测。类似有机体在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。在运筹学和控制论的语境下,强化学习被称作“近似动态规划”(approximate dynamic programming,ADP)。
机器学习算法列表
- 线性回归算法 Linear Regression
- 支持向量机算法 (Support Vector Machine,SVM)
- 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
- 逻辑回归算法 Logistic Regression
- 决策树算法 Decision Tree
- k-平均算法 K-Means
- 随机森林算法 Random Forest
- 朴素贝叶斯算法 Naive Bayes
- 降维算法 Dimensional Reduction
- 梯度增强算法 Gradient Boosting
1. 线性回归算法 Linear Regression
回归分析(Regression Analysis)是统计学的数据分析方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来预测其它变量的变化情况。
线性回归算法(Linear Regression)的建模过程就是使用数据点来寻找最佳拟合线。公式,y = mx + c,其中 y 是因变量,x 是自变量,利用给定的数据集求 m 和 c 的值。
线性回归又分为两种类型,即 简单线性回归(simple linear regression),只有 1 个自变量;*多变量回归(multiple regression),至少两组以上自变量。
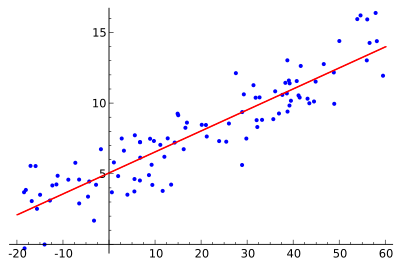
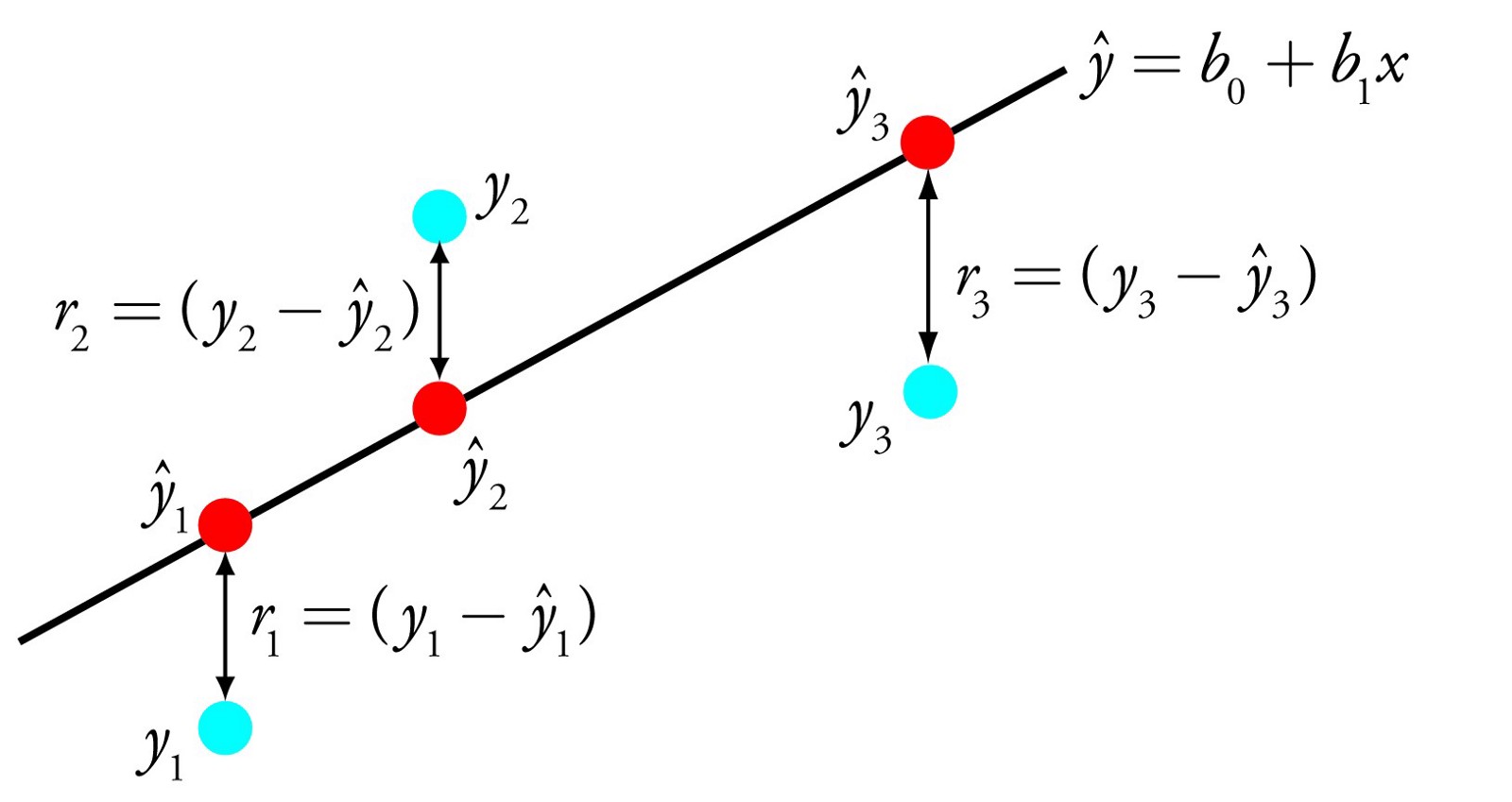
下面是一个线性回归示例:基于 Python scikit-learn 工具包描述。
|
|
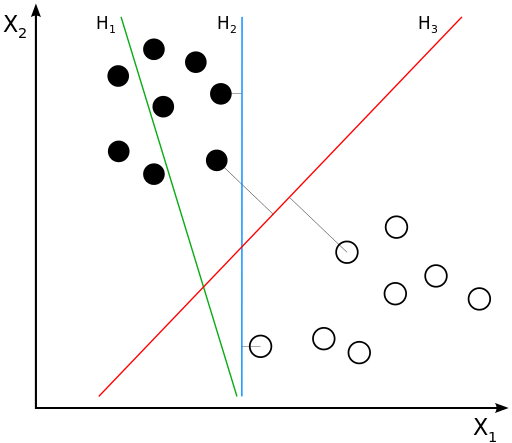
2. 支持向量机算法(Support Vector Machine,SVM)
支持向量机/网络算法(SVM)属于分类型算法。SVM模型将实例表示为空间中的点,将使用一条直线分隔数据点。需要注意的是,支持向量机需要对输入数据进行完全标记,仅直接适用于两类任务,应用将多类任务需要减少到几个二元问题。
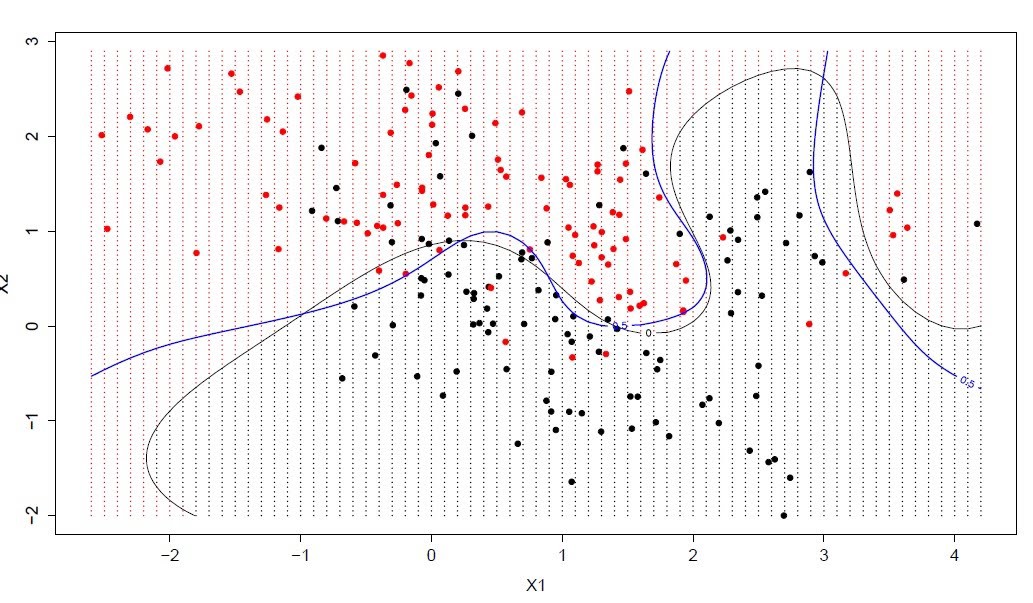
|
|
3. 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
KNN算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。用最近的邻居(k)来预测未知数据点。k 值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。
KNN 算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。
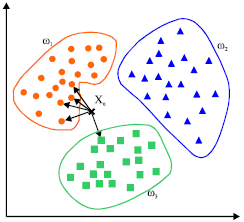
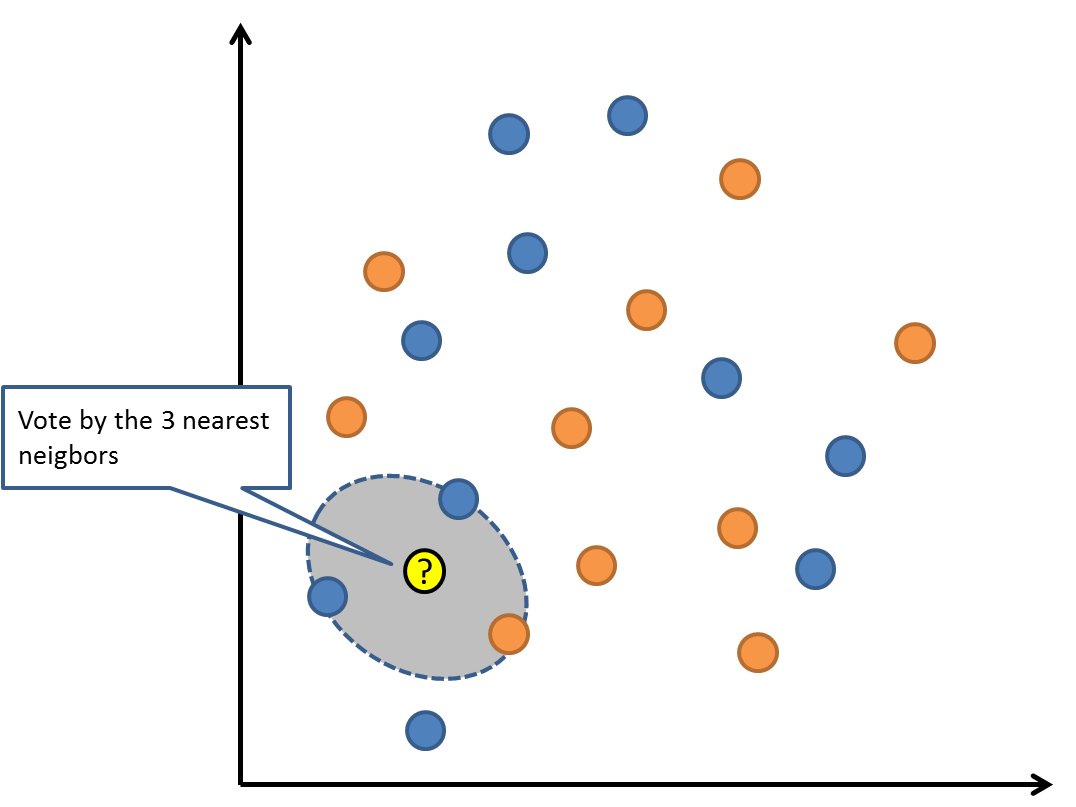
|
|
延伸:KNN 的一个缺点是依赖于整个训练数据集,学习向量量化(Learning Vector Quantization,LVQ)是一种监督学习的人神经网络算法,允许你选择训练实例。LVQ 由数据驱动,搜索距离它最近的两个神经元,对于同类神经元采取拉拢,异类神经元采取排斥,最终得到数据的分布模式。如果基于 KNN 可以获得较好的数据集分类效果,利用 LVQ 可以减少存储训练数据集存储规模。典型的学习矢量量化算法有LVQ1、LVQ2和LVQ3,尤以LVQ2的应用最为广泛。
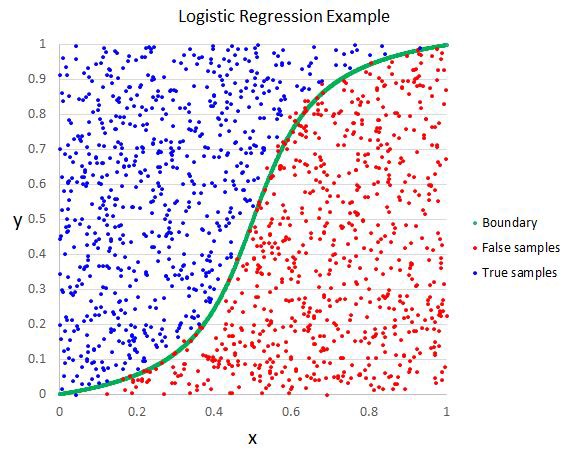
4. 逻辑回归算法 Logistic Regression
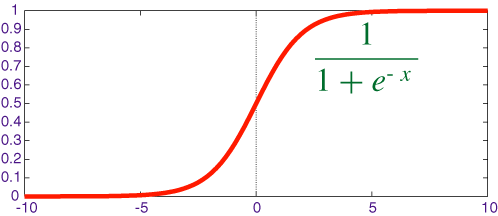
逻辑回归算法(Logistic Regression)一般用于需要明确输出的场景,如某些事件的发生(预测是否会发生降雨)。通常,逻辑回归使用某种函数将概率值压缩到某一特定范围。
例如,Sigmoid 函数(S 函数)是一种具有 S 形曲线、用于二元分类的函数。它将发生某事件的概率值转换为 0, 1 的范围表示。
Y = E ^(b0+b1 x)/(1 + E ^(b0+b1 x ))
以上是一个简单的逻辑回归方程,B0,B1是常数。这些常数值将被计算获得,以确保预测值和实际值之间的误差最小。
5. 决策树算法 Decision Tree
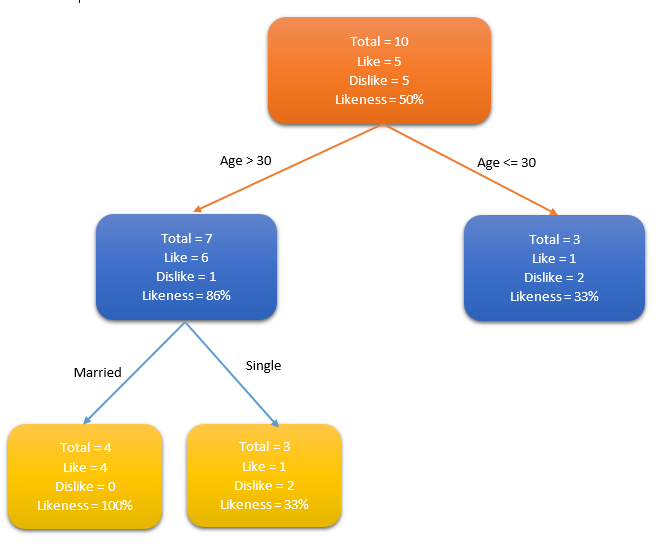
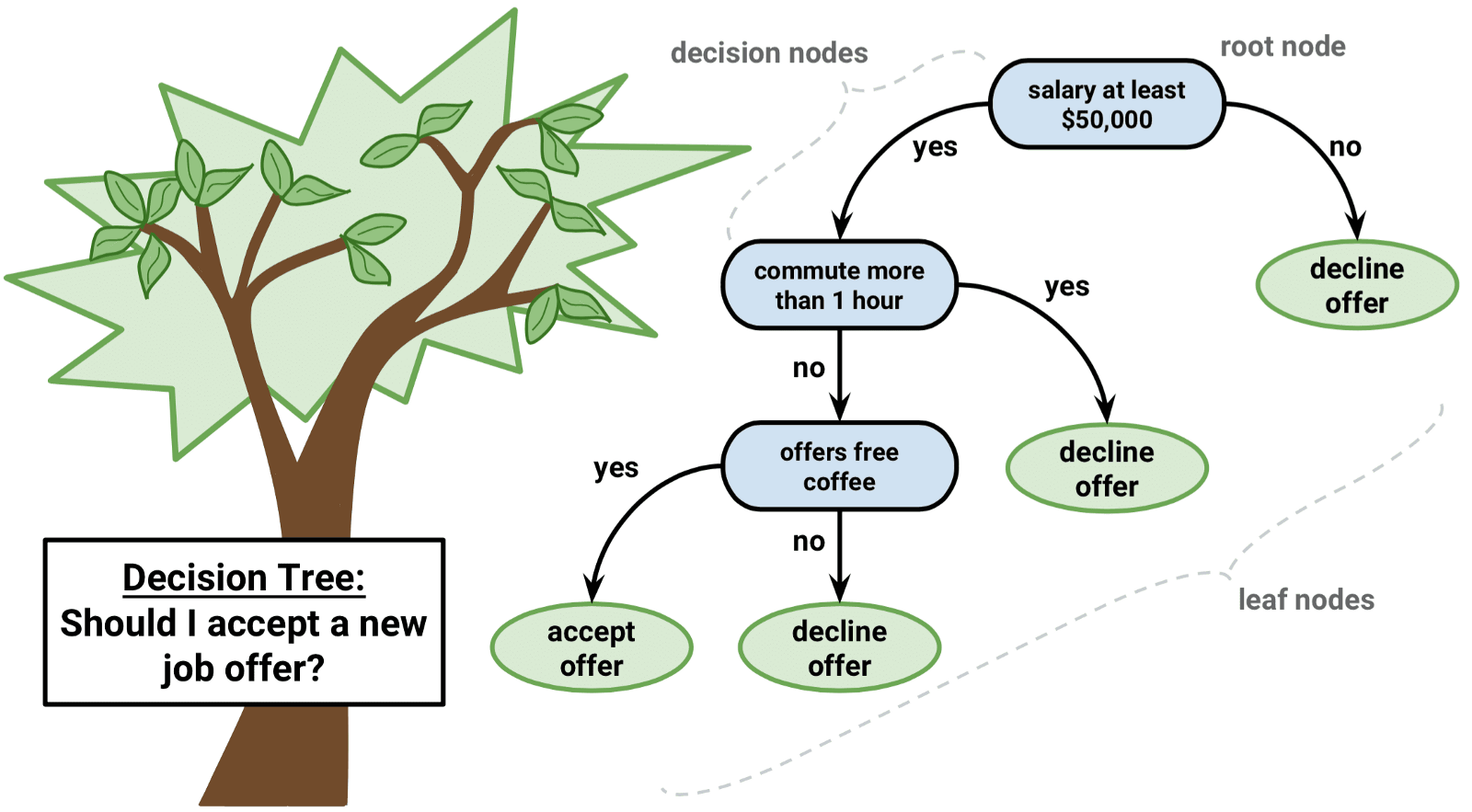
决策树(Decision tree)是一种特殊的树结构,由一个决策图和可能的结果(例如成本和风险)组成,用来辅助决策。机器学习中,决策树是一个预测模型,树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,通常该算法用于解决分类问题。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结点:通常用三角形来表示
简单决策树算法案例,确定人群中谁喜欢使用信用卡。考虑人群的年龄和婚姻状况,如果年龄在30岁或是已婚,人们更倾向于选择信用卡,反之则更少。
通过确定合适的属性来定义更多的类别,可以进一步扩展此决策树。在这个例子中,如果一个人结婚了,他超过30岁,他们更有可能拥有信用卡(100% 偏好)。测试数据用于生成决策树。
注意:对于那些各类别样本数量不一致的数据,在决策树当中信息增益的结果偏向于那些具有更多数值的特征。
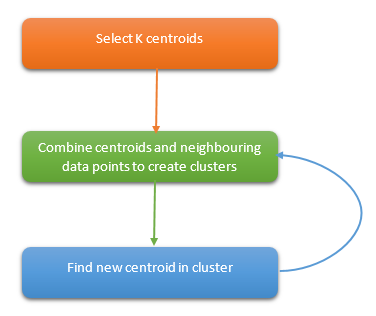
6. k-平均算法 K-Means
k-平均算法(K-Means)是一种无监督学习算法,为聚类问题提供了一种解决方案。
K-Means 算法把 n 个点(可以是样本的一次观察或一个实例)划分到 k 个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群。重复上述过程一直持续到重心不改变。
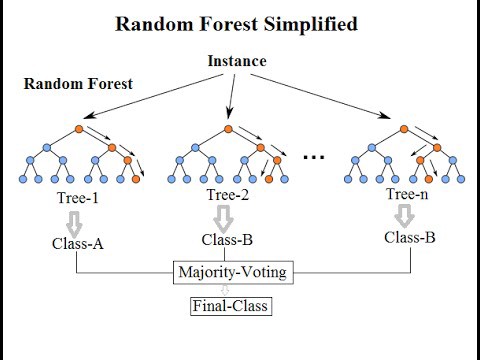
7. 随机森林算法 Random Forest
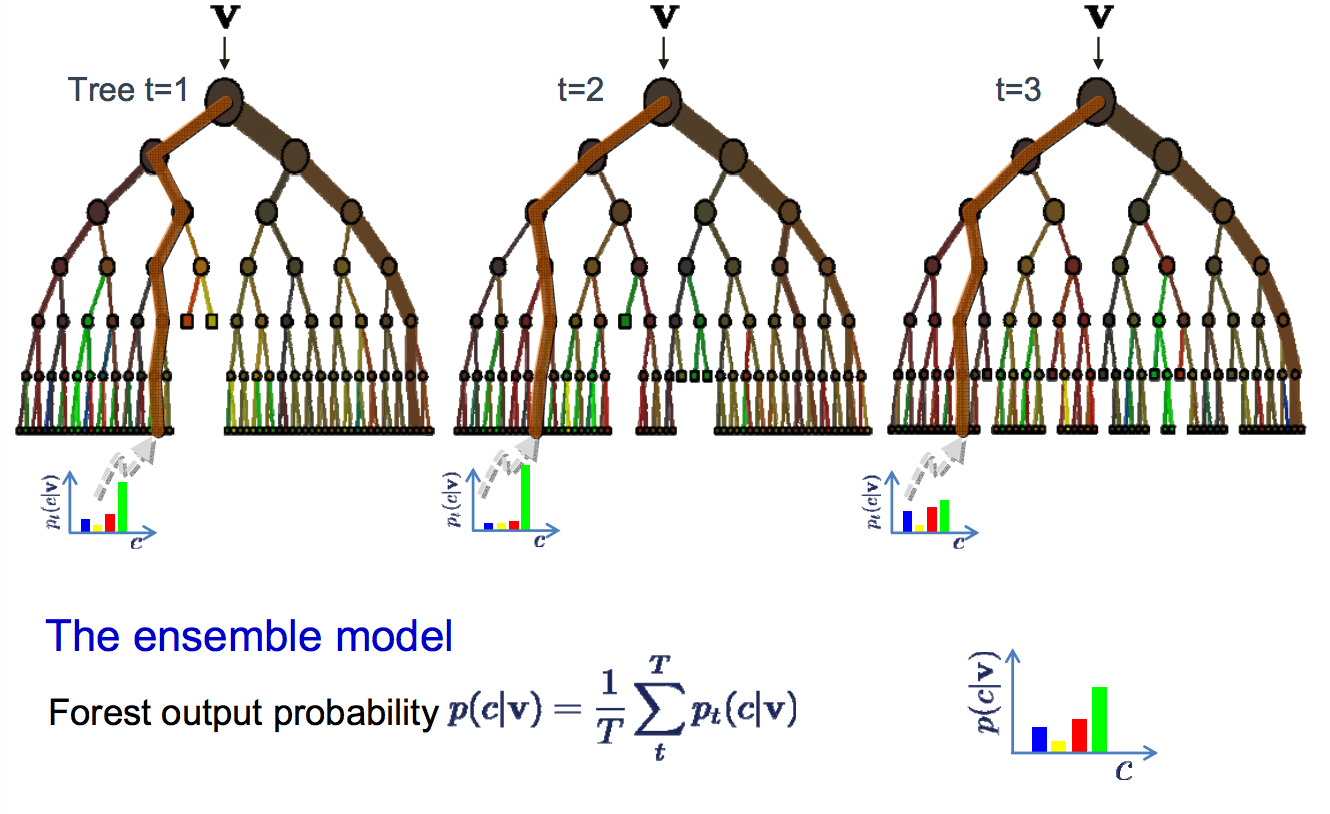
随机森林算法(Random Forest)的名称由 1995 年由贝尔实验室提出的random decision forests 而来,正如它的名字所说的那样,随机森林可以看作一个决策树的集合。
随机森林中每棵决策树估计一个分类,这个过程称为“投票(vote)”。理想情况下,我们根据每棵决策树的每个投票,选择最多投票的分类。
8. 朴素贝叶斯算法 Naive Bayes
朴素贝叶斯算法(Naive Bayes)基于概率论的贝叶斯定理,应用非常广泛,从文本分类、垃圾邮件过滤器、医疗诊断等等。朴素贝叶斯适用于特征之间的相互独立的场景,例如利用花瓣的长度和宽度来预测花的类型。“朴素”的内涵可以理解为特征和特征之间独立性强。
与朴素贝叶斯算法密切相关的一个概念是最大似然估计(Maximum likelihood estimation),历史上大部分的最大似然估计理论也都是在贝叶斯统计中得到大发展。例如,建立人口身高模型,很难有人力与物力去统计全国每个人的身高,但是可以通过采样,获取部分人的身高,然后通过最大似然估计来获取分布的均值与方差。
Naive Bayes is called naive because it assumes that each input variable is independent.
9. 降维算法 Dimensional Reduction
在机器学习和统计学领域,降维是指在限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程,并可进一步细分为特征选择和特征提取两大方法。
一些数据集可能包含许多难以处理的变量。特别是资源丰富的情况下,系统中的数据将非常详细。在这种情况下,数据集可能包含数千个变量,其中大多数变量也可能是不必要的。在这种情况下,几乎不可能确定对我们的预测影响最大的变量。此时,我们需要使用降维算法,降维的过程中也可能需要用到其他算法,例如借用随机森林,决策树来识别最重要的变量。
10. 梯度增强算法 Gradient Boosting
梯度增强算法(Gradient Boosting)使用多个弱算法来创建更强大的精确算法。它与使用单个估计量不同,而是使用多个估计量创建一个更稳定和更健壮的算法。梯度增强算法有几种:
- XGBoost — 使用线性和树算法
- LightGBM — 只使用基于树的算法
梯度增强算法的特点是精度较高。此外,LightGBM 算法具有令人难以置信的高性能。
扩展阅读
AI技术原理|机器学习算法的更多相关文章
- 【沙龙报名中】集结腾讯技术专家,共探AI技术原理与实践
| 导语 9月7日,上海市长宁区Hello coffee,云+社区邀您参加<AI技术原理与实践>沙龙活动,聚焦人工智能技术在各产业领域的应用落地,共话AI技术带来的机遇与挑战,展望未来. ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 机器学习算法-PCA降维技术
机器学习算法-PCA降维 一.引言 在实际的数据分析问题中我们遇到的问题通常有较高维数的特征,在进行实际的数据分析的时候,我们并不会将所有的特征都用于算法的训练,而是挑选出我们认为可能对目标有影响的特 ...
- IBM沃森会成为第一个被抛弃的AI技术吗?
作者|William Vorhies 译者|姚佳灵 编辑|Debra 导读:IBM 的沃森问答机(Question Answering Machine,简称 QAM),因 2011 年参加综艺节目&l ...
- 福利:42套AI技术视频免费领取
<福利:33套AI技术视频免费领取> 视频获取方式:请加机器学习和自然语言(QQ群号:436303759)群后,私信群主获取(备注上自己想要获取是视频名称),仅限本群公众号粉丝成员,多套视 ...
- Atitit 语音识别的技术原理
Atitit 语音识别的技术原理 1.1. 语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),2 1.2. 模型目前,主流的大词汇量语音识别系统多 ...
- AdaBoost原理,算法实现
前言: 当做重要决定时,大家可能综合考虑多个专家而不是一个人的意见.机器学习处理问题也是如此,这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式,前几天看了一个称作adaboost方法的介绍 ...
- 如今领占主导地位的19种AI技术!
如今领占主导地位的19种AI技术! http://blog.itpub.net/31542119/viewspace-2212797/ 深度学习的突破将人工智能带进全新阶段. 2006 年-2015 ...
- 机器学习算法实现解析——word2vec源代码解析
在阅读本文之前,建议首先阅读"简单易学的机器学习算法--word2vec的算法原理"(眼下还没公布).掌握例如以下的几个概念: 什么是统计语言模型 神经概率语言模型的网络结构 CB ...
随机推荐
- Centos 7服务器搭建MySQL(mariadb)服务
1.下载并安装MySQL yum install mariadb mariadb-server -y 2.启动MySQL systemctl start mariadb 3.对mariadb进行初始化 ...
- 20199326《Linux内核原理与分析》第十二周作业
Collabtive系统跨站请求伪造攻击实验 实验背景 CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/sessi ...
- AIX详细的VG,LV扩容步骤
需求 1.归档日志刷得太快,经常把空间挤爆. 2.Oracle数据库表空间需要扩容 解决方案 1.先做重要数据备份 2.进行文件系统扩容 步骤 1. df -g 查找出/u01 对应的VG卷 VOLU ...
- 快速部署一个Kubernetes集群
官方提供的三种部署方式 minikube Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,仅用于尝试Kubernetes或日常开发的用户使用. 部署地址:https:// ...
- springboot docker jenkins 自动化部署并上传镜像
springboot + docker + jenkins自动化部署项目,jenkins.mysql.redis都是docker运行的,并且没有使用虚拟机,就在阿里云服务器(centos7)运行 1. ...
- 3年前的一个小项目经验,分享给菜鸟兄弟们(公文收发小软件:小技能 SmallDatetime)...
为什么80%的码农都做不了架构师?>>> 这个系统中的数据库有100多M,里面当然有很多表,我的每个表里,有几个字段,都是一样的例如 CreateUserID.CreateDat ...
- mysql 5.7 MGR
最近看了一下mysql5.7的MGR集群挺不错的,有单主和多主模式,于是乎搭建测试了一下效果还不错,我指的不错是搭建和维护方面都比较简单.网上绝大多数都是单主模式,当然我这里也是,为了加深印象,特意记 ...
- Netty(五):ServerBootstrap启动流程
这篇文章主要是对ServerBootstrap启动流程做一个梳理,方便我们串联起各个类,同时也对主要的一些类有个大概的印象,方便之后逐个类的深入学习. 本篇文章不在具体贴出代码,而是对整个启动流程画了 ...
- Vue.js 条件渲染 v-if、v-show、v-else
v-if v-if 完全根据表达式的值在DOM中生成或移除一个元素.如果v-if表达式赋值为false,那么对应的元素就会从DOM中移除:否则,对应元素的一个克隆将被重新插入DOM中. 1 2 3 ...
- 安装XCode7.1后,QT5.5出现的各种问题解决方案
安装XCode7.1后,突然发现QT5.5编译不了程序了.直接在终端输入clang,竟然输出如下的信息. Agreeing to the Xcode/iOS license requires admi ...