【JVM】垃圾回收器总结(2)——七种垃圾回收器类型
七种垃圾回收器类型

GC的约定参数
DefNew——Default New Generation
Tenured——Serial Old
ParNew——Parallel New Generation
PSYoungGen——Parallel Scavenge
ParOldGen——Parallel Old Generation
适用范围:只需要掌握Server模式,Client模式基本不会用。
操作系统:32位windows不论硬件如何默认使用Client模式。32位其他OS,2G内存同时2个CPU以上用Server模式,低于该配置是Client模式。64位只有Server模式。
七大垃圾收集器
串行GC:Serial收集器(1:1)
串行收集器是最古老的,最稳定,效率高的收集器,只使用一个线程去回收但其进行垃圾回收过程中可能会产生较长的停顿。虽然在收集垃圾的过程中需要暂停其他的工作线程,但是简单高效,对于单CPU环境来说,没有线程交互的开销可以获得最高的单线程垃圾收集效率,因此Serial垃圾回收器依然是Java虚拟机运行在Client模式下默认的新生代垃圾回收器。
开启串行收集器的JVM参数是-XX:+UseSerialGC。
开启后会使用:Serial(Young区)+ Serial Old(Old区)的收集器组合。表示新生代、老年代都会使用串行回收收集器,新生代用复制算法,老年代用标记整理算法。
显式激活垃圾回收器:
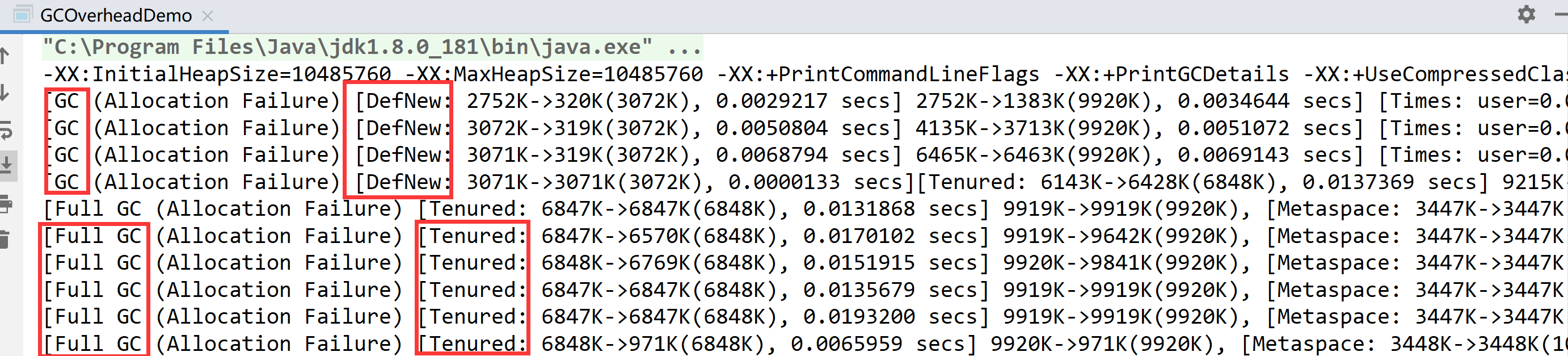
并行GC:ParNew(N:1)
使用多线程进行垃圾回收,在垃圾回收时,会暂停所有其他工作线程,直到GC结束。
ParNew时Serial收集器新生代的并行多线程版本,最常见的应用场景是配合老年代CMS GC工作,其余行为和Seria收集器完全一样,ParNew垃圾收集器在垃圾收集过程中同样要暂停所有其他的工作线程。它是很多JVM运行在Server模式下新生代的默认垃圾收集器。
开启串行收集器的JVM参数是-XX:+UseParNewGC。
启用ParNew收集器,只影响新生代的收集(新生代GC频繁),不影响老年代。开启参数后,会使用ParNew(Young区)+Serial(Old区)的收集器组合。新生代使用复制算法,老年代使用标记整理算法。

ParNew+Tenured(Serial Old)不再推荐使用:

并行回收:Parallel Scavenge(N:N)
Parallel Scavenge收集器类似ParNew,也是一个新生代垃圾收集器,使用复制算法,也是一个并行的多线程的垃圾收集器,俗称吞吐量优先收集器。相当于是串行收集器在新生代和老年代的并行化。
它重点关注可控制吞吐量,高吞吐量意味着高效利用CPU时间,它多用于在后台运算而不需要太多交互的任务。【吞吐量 = 用户代码运行时间/(用户代码运行时间+垃圾回收时间)】
自适应调节策略也是Parallel Scavenge收集器与ParNew收集器的一个重要区别。自适应调节策略就是JVM会根据当前系统的运行情况看收集性能监控信息,动态调整这些参数以提供最合适的停顿时间(-XX: MaxGCPauseMills)或最大吞吐量。
常用的JVM参数:-XX:+UseParallelGC 或者 +UseParallelOldGC(二者可以互相激活),使用Parallel Scavenge收集器。开启参数后,新生代用复制算法,老年代用复制标记整理算法。
参数-XX:+ParallelGCThread = K 表示启动K个GC线程【CPU > 8 K = 5或8 CPU < 8 K = 实际个数】
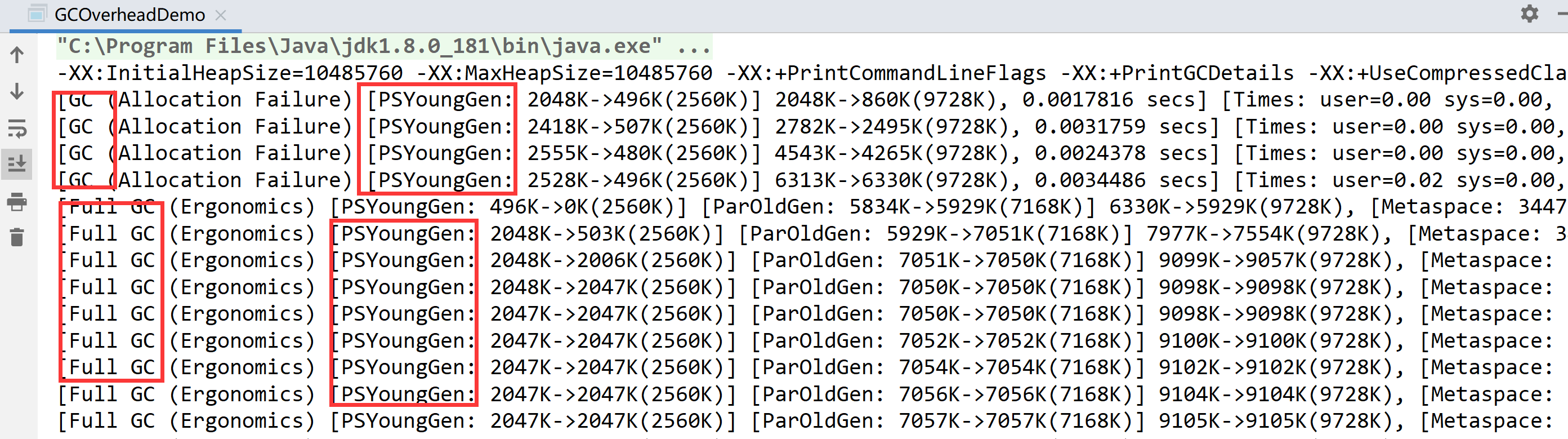
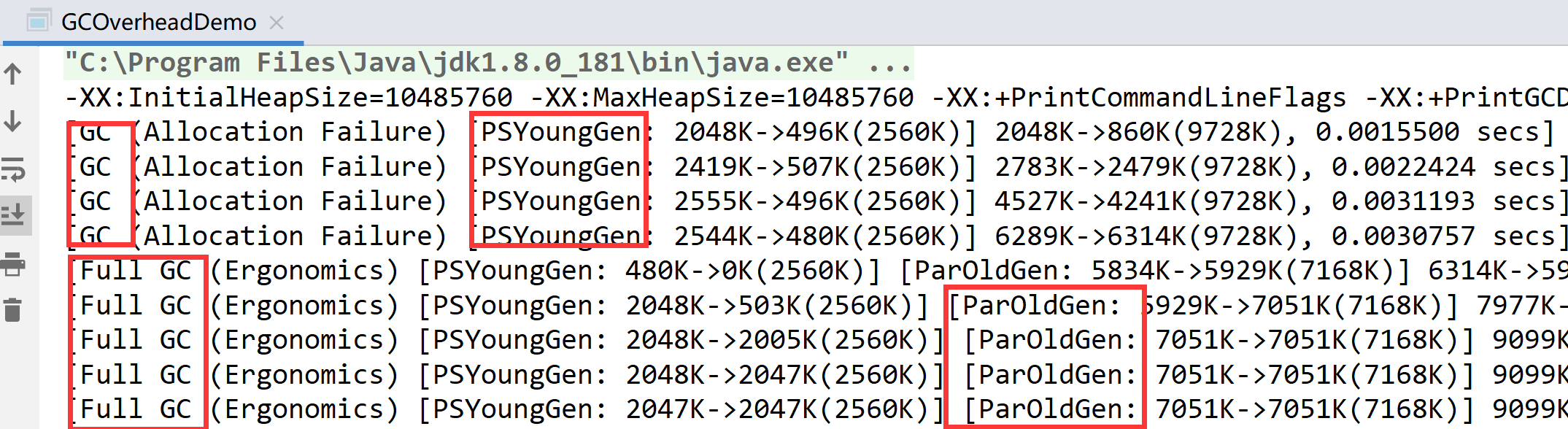
Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程的标记整理算法,在JDK1.6开始提供。
JDK1.6之前,新生代使用Parallel Scavenge收集器只能搭配老年代Serial Old收集器,只能保证新生代的吞吐量优先,无法保证整体的吞吐量。在JDK1.6之前,是Parallel Scavenge+Serial Old。
Parallel Old是为了老年代同样提供吞吐量优先的垃圾收集器,如果系统对吞吐量要求较高,JDK1.8后优先考虑新生代Parallel Scavenge和老年代 Parallel Old的搭配策列。在JDK1.8及之后,是Parallel Scavenge+Parallel Old。
JVM常用参数:-XX:+UseParallelOldGC使用Parallel Old收集器。和上一个part的截图是一致的,UseParallelGC和UseParallelOldGC可以互相激活。
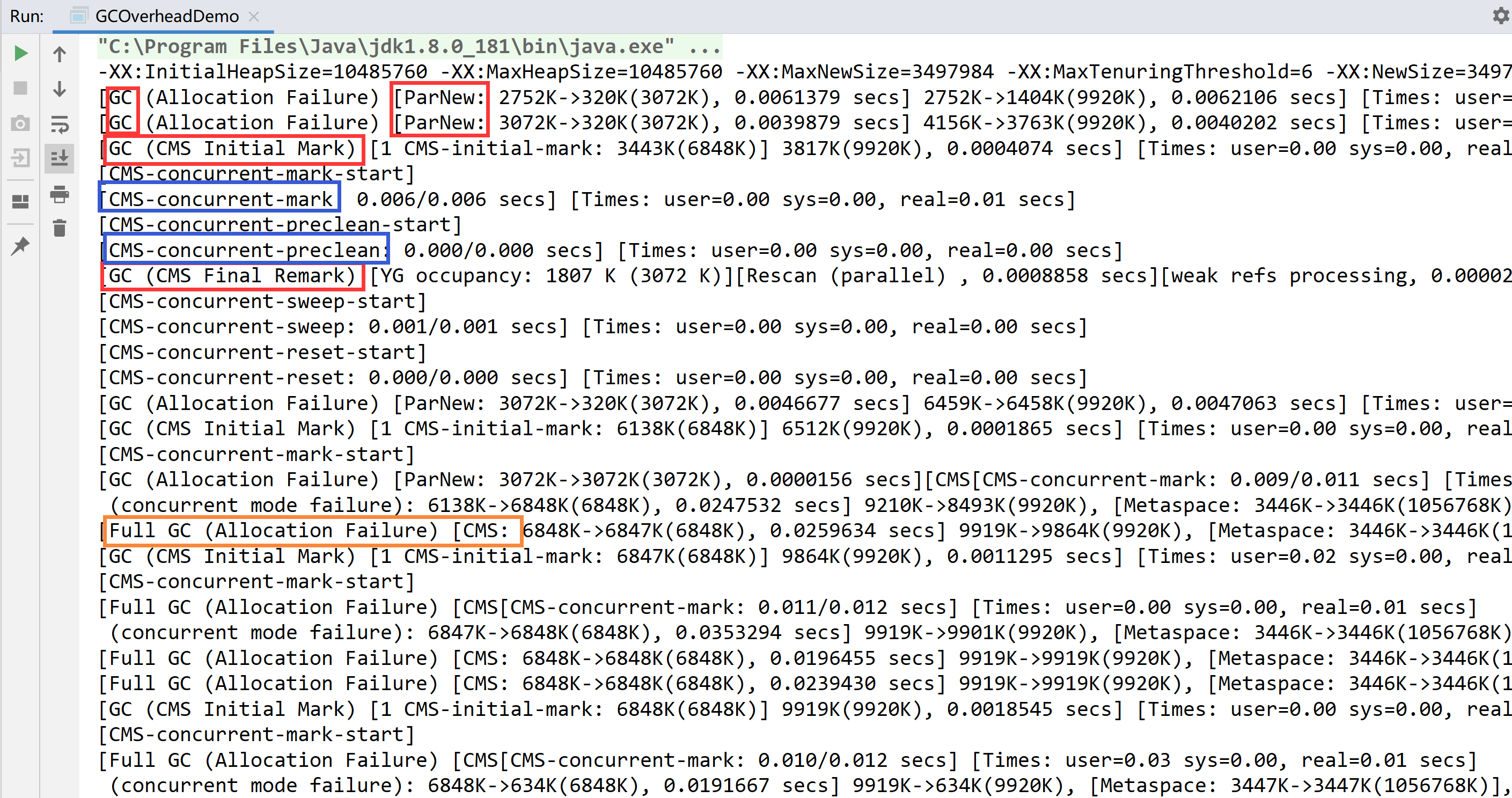
并发标记清除GC(CMS)
CMS收集器是一个以获取最短回收停顿时间为目标的收集器。适合应用在互联网站或BS系统的服务器上,因为这类场景重视服务器的响应速度,希望系统的停顿时间尽可能短。CMS适合堆内存大、CPU核数多的服务器端应用,也是G1出现之前大型应用的首选收集器。
CMS的优势是并发收集停顿少,并发是指与用户线程一起执行。
开启收集器的JVM参数:-XX:+UseConcMarkSweepGC 开启后会自动开启 -XX:+UseParNewGC

并发标记清除收集器的组合:ParNew + CMS + Serial Old(作为CMS出错的后备收集器,增强健壮性)
CMS内存回收一共有4个过程:
- 初始标记:只有标记一下GC Roots能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。
- 并发标记:进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程,主要标记过程,标记全部对象。
- 重新标记:修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程。由于并发标记时,用户线程依然运行,因此在正式清理前再做修正。
- 并发清除:清除GC Roots不可达对象,和用户线程一起工作,不需要暂停工作线程。基于标记结果,直接清理对象。由于耗时最长的并发标记和并发清除过程中,垃圾收集线程可以和用户线程一起并发工作。所以总体上说CMS收集器的内存回收和用户线程是并发执行的(初始标记和重新标记虽然要暂停,但是用时很短)。
优点:并发收集,停顿次数少。
缺点:对CPU的压力大,CMS在收集和应用线程会同时增加对堆内存的占用,也就是i说CMS必须在老年代堆内存用完之前完成GC,否则CMS会回收失败,将触发担保机制,Serial Old会以STW(Stop The World,暂停所有工作线程)的方式进行依次GC,从而造成较大的停顿时间。而且采用标记清除算法会产生内存碎片。
Serial Old收集器
Serial Old收集器是Serial垃圾收集器老年代版本,同样是单线程的收集器,使用标记整理算法。
主要运行在Client默认的JVM老年代垃圾回收器。
在Server模式下,主要有两个用途:
- 在JDK1.5之前与新生代Parallel Scavenge收集器搭配使用。(Parallel Scavenge+Serial Old)
- 作为老年代版中使用CMS收集器的后备垃圾回收方案。
G1垃圾回收器
内容较多,见【JVM】垃圾回收器总结(3)
【JVM】垃圾回收器总结(2)——七种垃圾回收器类型的更多相关文章
- Android内存管理(11)*常见JVM回收机制「Java进程内存堆分代,JVM分代回收内存,三种垃圾回收器」
参考: http://www.blogjava.net/rosen/archive/2010/05/21/321575.html 1,Java进程内存堆分代: 典型的JVM根据generation(代 ...
- Mysql表的七种引擎类型,InnoDB和MyISAM引擎对比区别总结
InnoDB和MyISAM区别总结 我用MySQL的时候用的是Navicat for MySQL(Navicat for mysql v9.0.15注册码生成器)操作库.表操作的,默认的表就是Inno ...
- JVM几种垃圾回收器介绍
整理自:http://www.cnblogs.com/lspz/p/6397649.html 一.如何回收? 1.1 垃圾收集算法: (1)标记-清除(Mark-Sweep)算法 这是最基础的算法,就 ...
- JVM基础系列第10讲:垃圾回收的几种类型
我们经常会听到许多垃圾回收的术语,例如:Minor GC.Major GC.Young GC.Old GC.Full GC.Stop-The-World 等.但这些 GC 术语到底指的是什么,它们之间 ...
- JVM性能调优(2) —— 垃圾回收器和回收策略
一.垃圾回收机制 1.为什么需要垃圾回收 Java 程序在虚拟机中运行,是会占用内存资源的,比如创建的对象.加载的类型数据等,而且内存资源都是有限的.当创建的对象不再被引用时,就需要被回收掉,释放内存 ...
- jvm七种垃圾收集器
JVM_七种垃圾收集器介绍 本文中的垃圾收集器研究背景为:HotSpot+JDK7 一.垃圾收集器概述 如上图所示,垃圾回收算法一共有7个,3个属于年轻代.三个属于年老代,G1属于横跨年轻代和年老 ...
- JVM 学习(一)反射、垃圾回收、异常处理--- 2019年4月
1.JVM 基础知识点 JVM 虚拟机包含了:自动内存管理器.垃圾回收(垃圾回收调优). 执行顺序:Java 代码 --- .class 字节码文件(加载到虚拟机中) --- Java 类放在方法区中 ...
- jvm入门及理解(六)——垃圾回收与算法
一.jvm垃圾回收要做的事情 哪些内存需要回收 什么时候回收 怎么回收 二.如何判断对象已经死亡,或者说确定为垃圾 引用计数法: 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器的值就加1: ...
- JVM实用参数(五)新生代垃圾回收
本部分,我们将关注堆(heap) 中一个主要区域,新生代(young generation).首先我们会讨论为什么调整新生代的参数会对应用的性能如此重要,接着我们将学习新生代相关的JVM参数. 单纯从 ...
随机推荐
- VA01信贷使用
1业务场景 业务在正式机中发现,当使用VA01输入客户编号回车后会报错 2解决方法 1. SE24进入CL_IM_UKM_SD_FSCM_INTEGR1 2. 双击方法IF_EX_BADI_SD_CM ...
- Qt读写xml文件
写xml <root> <element> <sub id=-1></sub> </element> </root> //添加x ...
- arangodb安装
这里仅介绍windows环境下的安装,直接官网下载安装包安装即可.安装完后进入安装目录进行配置. cd ArangoDB\\etc\\arangodb3 打开arangod.conf配置文件,修改以下 ...
- 谈谈R语言的缺点和优点
编码不友好,对中文不友好,逼着你用RStudio.Jupyter Notebook/Jupyter Lab.图标丑,每次点击感觉辣眼睛. 为节省内存,R语言计算默认有效数字为7位,比Excel的15位 ...
- 设计模式之GOF23迭代器模式
迭代器模式Iterator /** * 自定义迭代器接口 * @author 小帆敲代码 * */public interface MyIterator { void first();//游标置于第 ...
- flink进阶篇
Flink 面试--进阶篇 1.Flink是如何支持批流一体的? 2.Flink是如何做到高效的数据交换的? 3.Flink是如何做容错的? 4.Flink 分布式快照的原理是什么? 5.Flink ...
- aop面向切面编程的实现
aop主要用于日志记录,跟踪,优化和监控 下面是来自慕课网学习的一些案例,复制黏贴就完事了,注意类和方法的位置 pom添加依赖: <dependency> <groupId>o ...
- chrom浏览器总是将http请求强制转换成https请求
chrome://net-internals/#hsts 中 Delete domain security policies 输入该站点,将将该站点删除一下就OK. 其他浏览器: Chrome 浏览器 ...
- 2020年腾讯实习生C++面试题&持续更新中(2)
2020年腾讯实习生C++面试题&持续更新中(2) hello,大家好~ 我是好好学习天天,天天编程的天天,一个每天都死磕技术,及时分享的技术宅~ 昨天分享的题目不知道大家是否看过了,以后我计 ...
- Tomcat session的实现:线程安全与管理
本文所说的session是单机版本的session, 事实上在当前的互联网实践中已经不太存在这种定义了.我们主要讨论的是其安全共享的实现,只从理论上来讨论,不必太过在意实用性问题. 1. sessio ...