吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同
时给出这个猜测的概率估计值。
概率论是许多机器学习算法的基础
在计算
特征值取某个值的概率时涉及了一些概率知识,在那里我们先统计特征在数据集中取某个特定值
的次数,然后除以数据集的实例总数,就得到了特征取该值的概率。
首先从一个最简单的概率分类器开始,然后给
出一些假设来学习朴素贝叶斯分类器。我们称之为“朴素”,是因为整个形式化过程只做最原始、
最简单的假设。
基于贝叶斯决策理论的分类方法

朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素负叶斯之前有必要快速了解一下贝叶
斯决策理论。
假设现在我们有一个数据集,它由两类数据组成
import matplotlib
import matplotlib.pyplot as plt from numpy import * n = 1000 #number of points to create
xcord0 = []
ycord0 = []
xcord1 = []
ycord1 = []
markers =[]
colors =[]
fw = open('E:\\testSet.txt','w')
for i in range(n):
[r0,r1] = random.standard_normal(2)
myClass = random.uniform(0,1)
if (myClass <= 0.5):
fFlyer = r0 + 9.0
tats = 1.0*r1 + fFlyer - 9.0
xcord0.append(fFlyer)
ycord0.append(tats)
else:
fFlyer = r0 + 2.0
tats = r1+fFlyer - 2.0
xcord1.append(fFlyer)
ycord1.append(tats)
#fw.write("%f\t%f\t%d\n" % (fFlyer, tats, classLabel)) fw.close()
fig = plt.figure()
ax = fig.add_subplot(111)
#ax.scatter(xcord,ycord, c=colors, s=markers)
ax.scatter(xcord0,ycord0, marker='^', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.plot([0,1], label='going up')
plt.show()
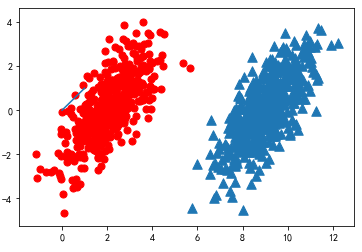

也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有
最高概率的决策。
条件概率



使用条件概率来分类


使用朴素贝叶斯进行文档分类
机器学习的一个重要应用就是文档的自动分类。在文档分类中,整 个 文 档 (如一封电子邮件)
是实例,而电子邮件中的某些元素则构成特征。虽然电子邮件是一种会不断增加的文本,但我们同
样也可以对新闻报道、用户留言、政府公文等其他任意类型的文本进行分类。我们可以观察文档中
出现的词,并把每个词的出现或者不出现作为一个特征,这样得到的特征数目就会跟词汇表中的词
目一样多。




使用Python进行文本分类

准备数据:从文本中构建词向量
将把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现在所有文
档中的所有单词,再决定将哪些词纳人词汇表或者说所要的词汇集合,然后必须要将每一篇文档
转换为词汇表上的向量。
from numpy import * def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet) def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec postingList,classVec = loadDataSet()
VocabList = createVocabList(postingList)
print(VocabList)

returnVec = setOfWords2Vec(VocabList,postingList[0])
print(returnVec)

训练算法:从词向量计算概率
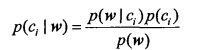


朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords)
p1Num = ones(numWords) #change to ones()
p0Denom = 2.0
p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
import matplotlib
import matplotlib.pyplot as plt from numpy import * t = arange(0.0, 0.5, 0.01)
s = sin(2*pi*t)
logS = log(s) fig = plt.figure()
ax = fig.add_subplot(211)
ax.plot(t,s)
ax.set_ylabel('f(x)')
ax.set_xlabel('x') ax = fig.add_subplot(212)
ax.plot(t,logS)
ax.set_ylabel('ln(f(x))')
ax.set_xlabel('x')
plt.show()


贝叶斯分类函数 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
这里的相乘是指对应元素
相乘,即先将两个向量中的第1个元素相乘,然后将第2个元素相乘,以此类推。接下来将词汇表
中所有词的对应值相加,然后将该值加到类别的对数概率上。最后,比较类别的概率返回大概率
对应的类别标签。
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)) testingNB()

准备数据:文档词袋模型

朴素贝叶斯词袋模型
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
吴裕雄--天生自然python机器学习:朴素贝叶斯算法的更多相关文章
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:KNN-近邻算法在手写识别系统上的应用
需要识别的数字已经使用图形处理软件,处理成具有相同的色 彩和大小® : 宽髙是32像 素 *32像素的黑白图像.尽管采用文本格式存储图像不能有效地利用内 存空间,但是为了方便理解,我们还是将图像转换为 ...
- 吴裕雄--天生自然python机器学习:K-近邻算法介绍
k-近邻算法概述 简单地说,谷近邻算法采用测量不同特征值之间的距离方法进行分类. 优 点 :精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. ...
- 吴裕雄--天生自然python机器学习:使用朴素贝叶斯过滤垃圾邮件
使用朴素贝叶斯解决一些现实生活中 的问题时,需要先从文本内容得到字符串列表,然后生成词向量. 准备数据:切分文本 测试算法:使用朴素贝叶斯进行交叉验证 文件解析及完整的垃圾邮件测试函数 def cre ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
随机推荐
- CSU2004:Finding words(含指定不相交前后缀的模式串计数)
题:http://acm.csu.edu.cn/csuoj/problemset/problem?pid=2004 题意:给定n个模式串,m个询问,每个询问是“前缀+‘*’+后缀 ”的组合的串S,输出 ...
- scala通过尾递归解析提取字段信息
一.背景 获取数据中以“|”作为字段间的分隔符,但个别字段中数据也是以“|”作为分隔符.因此,在字段提取时需要保护数据完整性. 二.实现 1.数据以“|”分隔,可以采用递归方式迭代解析.通过尾递归方式 ...
- Python笔记_第五篇_Python数据分析基础教程_文件的读写
1. 读写文件(基本) savetxt.loadtxt i2 = np.eye(2) print(i2) np.savetxt(r"C:\Users\Thomas\Desktop\eye.t ...
- F5双机冗余配置
转自:https://blog.51cto.com/dynamic/769888本文作者:CTO_LiuJinFeng 1. 配置管理接口-IP 前面文章中没提到如何配置IP,现在开始来配置. 登录- ...
- UML-架构分析-阶段
初始阶段:架构概念验证原型--->确定其可行性 细化阶段:因素表.技术备忘录.SAD(软件架构文档) 移交阶段:可能会修改SAD->确保与最终部署版本的一致性 后续进化循环:重温架构性因素 ...
- D11 列表 list 元祖 字典dict
取值 name = "alexdfg" print(name[3:5]) 取出 ex name = "alexdfg" print(name[3]) 取出e 列 ...
- 25.docker compose 简介 和 docker-compose.yml 参数介绍
1. docker compose概念 文档 https://docs.docker.com/compose/compose-file/compose-versioning 一个基于 docker ...
- Python说文解字_半成品再加工
1. 其实在编写代码的时候,根据需求和程序员的喜好,对现有类中的属性和方法进行二次加工,原先所给与的属性和方法贴合自己想要的需求.这就是我们常说的“重写”和二次封装. 2. 比如我们对现有的库list ...
- navicat for mysql连接数据库报错1251
使用Navicat for mysql 连接数据库,报如下错误 原因:数据库安装的是8.0版本,新的mysql采用了新的加密方式,导致连接失败 解决办法:数据库执行如下命令 改密码加密方式:用管理员身 ...
- epoll机制
一.参考网址 1.epoll机制:epoll_create.epoll_ctl.epoll_wait.close 2.Linux网络编程 使用epoll实现一个高性能TCP Echo服务器 3.用C写 ...