夯实Java基础(二十三)——Java8新特征之Stream API
1、Stream简介
Java8中除了引入了好用的Lambda表达式、Date API之外,另外还有一大亮点就是Stream API了,也是最值得所有Java开发人员学习的一个知识点,因为它的功能非常的强大,尤其是和前面学习的Lambda表达式、函数式接口、方法引用共同使用的时候。
Stream流是数据渠道,用于操作数据源所生成的元素序列,即操作集合、数组等等。其中集合和stream的区别是:集合讲的是数据,而stream讲的是计算。Stream的API全部都位于java.util.stream这样一个包下,它能够帮助开发人员从更高的抽象层次上对集合进行一系列操作,就类似于使用SQL执行数据库查询。而借助java.util.stream包,我们可以简明的声明性的表达集合,数组和其他数据源上可能的并行处理。实现从外部迭代到内部迭代的改变。它含有高效的聚合操作、大批量的数据处理,同时也内置了许多运算方式,包括筛选、排序、聚合等等。简单来说,用Stream来操作集合——减少了代码量,增强了可读性,提高运行效率。
然后这里要提一下:Stream和Java IO中的stream是完全不同概念的两个东西。本文要讲解的stream是能够对集合对象进行各种串行或并发聚集操作,而Java IO流用来处理设备之间的数据传输,它们两者截然不同。
Stream的主要特点有:
1、stream本身并不存储数据,数据是存储在对应的collection(集合)里,或者在需要的时候才生成的。
2、stream不会修改数据源,总是返回新的stream。
3、stream的操作是延迟(lazy)执行的:仅当最终的结果需要的时候才会执行,即执行到终止操作为止。
2、传统方式与使用Stream简单对比
首先我们先使用以前的方法来对集合进行一些操作,代码示例如下:
public class StreamTest {
public static void main(String[] args) {
//创建集合
ArrayList<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
list.add("six");
//遍历数据,只遍历4个
for (int i = 0; i < list.size()-1; i++) {
//过滤掉字符串——two
if (!(list.get(i).contains("two"))) {
System.out.println(list.get(i));
}
}
}
}
我相信像上面这样的代码估计每个java开发人员分分钟都可实现。但如果要求再复杂一点,代码量就会大量增加,所以再通过创建一个存储数据的集合,然后对集合进行遍历,再通过特定的条件进行筛选并且将结果输出。这样的代码中或多或少会有缺点的:
1、代码量一多,维护肯定更加困难。可读性也会变差。
2、难以扩展,要修改为并行处理估计会花费很大的精力。
然后下面展示了用Stream来实现相同的功能,非常的简洁,如果需要添加其他的方法也非常的方便。注:Stream中的一些方法可能暂时不清楚,这没关系,后面都会一 一介绍它们。
//使用filter,limit,forEach方法
list.stream().filter(s->!s.contains("two")).limit(4).forEach(System.out::println);
最终两种方式的代码运行结果是一样的:
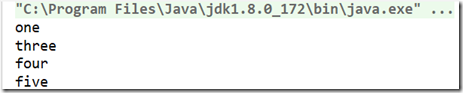
从上面使用Stream的情况下我们可以发现是Stream直接连接成了一个串,然后将stream过滤后的结果转为集合并返回输出。而至于转成哪种类型,这由JVM进行推断。整个程序的执行过程像是在叙述一件事,没有过多的中间变量,所以可以减小GC压力,提高效率。所以接下来开始探索Stream的功能吧。
3、Stream操作的三个步骤
Stream的原理是:将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上处理,包括有过滤、筛选、去重、排序、聚集等。元素在管道中经过中间操作的处理,最后由终止操作得到前面处理的结果。
所以Stream的所有操作分为这三个部分:创建对象-->中间操作-->终止操作,如下图。
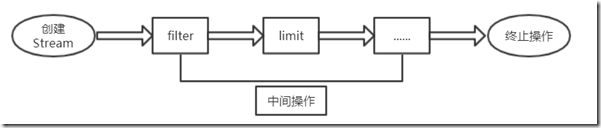
(1)、创建Stream:一个数据源(如:集合、数组),获取一个流。
(2)、中间操作:一个中间操作链,对数据源的数据进行处理。
(3)、终止操作(终端操作):一个终止操作,执行中间操作链,并产生结果。
4、创建Stream对象
①、使用Java8中被扩展的Collection接口,其中提供了两个获取流的方法:
- default Stream<E> stream() 返回一个数据流
- default Stream<E> parallelStream() 返回一个并行流
//1、方法一:通过Collection
ArrayList<String> list=new ArrayList<>();
//获取顺序流,即有顺序的获取
Stream<String> stream = list.stream();
//获取并行流,即同时取数据,无序
Stream<String> stream1 = list.parallelStream();
②、使用Java8 中Arrays的静态方法stream()获取数组流:
- public static <T> Stream<T> stream(T[] array) 返回一个流
//2、方法二:通过数组
String str[]=new String[]{"A","B","C","D","E"};
Stream<String> stream2 = Arrays.stream(str);
③、使用Stream类本身的静态方法of(),通过显式的赋来值创建一个流,它可以接受任意数量的参数:
- public static<T> Stream<T> of(T... values) 返回一个流
//3、方法三:通过Stream的静态方法of()
Stream<Integer> stream3 = Stream.of(1, 2, 3, 4, 5, 6);
④、创建无限流(迭代、生成)
- public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
- public static<T> Stream<T> generate(Supplier<T> s)
//4.、方式四:创建无限流(迭代、生成)
//迭代(需要传入一个种子,也就是起始值,然后传入一个一元操作)
Stream.iterate(2, (x) -> x * 2).limit(10).forEach(System.out::println);
//生成(无限产生对象)
Stream.generate(() -> Math.random()).limit(10).forEach(System.out::println);
以上的四种方式学习前三中即可,第四种不常用。除了上面这些额外还有其他创建Stream对象的方式,如Stream.empty():创建一个空的流、Random.ints():随机数流等等。
5、Stream中间操作
中间操作的所有操作会返回一个新的流,但它不会修改原始的数据源,并且操作是延迟执行的(lazy),意思就是在终止操作开始的时候才中间操作才真正开始执行。
中间操作主要有以下方法:filter、limit、 skip、distinct、map (mapToInt, flatMap 等)、 sorted、 peek、 parallel、 sequential、 unordered等。
为了更好地举例,我们先创建一个Student类:
public class Student {
private int id;
private String name;
private int age;
private String address;
public Student() { }
public Student(int id, String name, int age, String address) {
this.id = id;
this.name = name;
this.age = age;
this.address = address;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id == student.id &&
age == student.age &&
Objects.equals(name, student.name) &&
Objects.equals(address, student.address);
}
@Override
public int hashCode() {
return Objects.hash(id, name, age, address);
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
后面的所有测试数据用会用下面这一组数据(必要时会改):
List<Student> students= Arrays.asList(
new Student(1, "张三", 18, "北京"),
new Student(2, "李四", 19, "上海"),
new Student(3, "王五", 20, "广州"),
new Student(4, "赵六", 21, "浙江"),
new Student(5, "孙七", 22, "深圳")
);
然后开始介绍流的中间操作的方法使用:
①、filter(Predicate<? super T> predicate):筛选:接收 Lambda表达式,表示从流中过滤某些元素。
//筛选年龄大于19岁并且住在浙江的学生
students.stream().filter(s -> s.getAge() > 19).filter(s -> "浙江".equals(s.getAddress())).forEach(System.out::println);
运行结果为:

这里我们创建了五个学生对象,然后经过filter的筛选,筛选出年龄大于19岁并且家庭住址是在浙江的学生集合。
②、limit(long maxSize):截断:表示使其元素不超过给定数量。
//给定获取3个数据
students.stream().limit(3).forEach(System.out::println);
运行结果:

我们只让它截断3个,每次都是从第一个数据开始截取。
③、skip(long n):跳过:表示跳过前 n 个元素。若流中元素不足 n 个,则返回一个空流。它与 limit(n)互补。
//跳过前3个数据
students.stream().skip(3).forEach(System.out::println);
运行结果:

可以发现输出的数据恰好与limit方法互补。
④、distinct():筛选:去除流中重复的元素。
这里我将第二个数据改成和第一个一样,看结果会怎样。
public static void main(String [] args) {
List<Student> students= Arrays.asList(
new Student(1, "张三", 18, "北京"),
new Student(1, "张三", 18, "北京"),
new Student(3, "王五", 20, "广州"),
new Student(4, "赵六", 21, "浙江"),
new Student(5, "孙七", 22, "深圳")
);
//去除重复元素
students.stream().distinct().forEach(System.out::println);
}
}
运行结果:
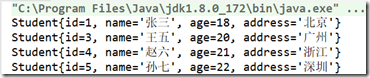
可以发现相同的元素被去除了,但是注意:distinct 需要实体中重写hashCode()和 equals()方法才可以使用。
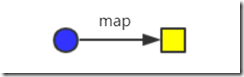
⑤、map(Function<? super T, ? extends R> mapper):映射(转换):将一种类型的流转换为另外一种类型的流。
为了便于理解我们来分析一下,map函数中需要传入一个实现Function<T,R>函数式接口的对象,而该接口的抽象方法apply接收T类型,返回是R类型,所以map也可以理解为映射关系。
//lambda表达式
students.stream().map(s->s.getName()).forEach(System.out::println);
//方法引用
students.stream().map(Student::getName).forEach(System.out::println);
运行结果:

上面的例子中将Student对象转换为了普通的String对象,获取Student对象的名字。
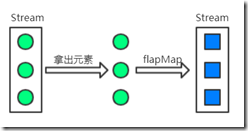
⑥、flatMap(Function<? super T, ? extends Stream<? extends R>> mapper):转换合并:将流中的每个值都转换成另一个流,然后把所有流组合成一个流并且返回。
它和map有点类似。flatMap在接收到Stream后,会将接收到的Stream中的每个元素取出来放入另一个Stream中,最后将一个包含多个元素的Stream返回。
List<Student> student1= Arrays.asList(
new Student(1, "张三", 18, "北京"),
new Student(2, "李四", 19, "上海")
); List<Student> student2= Arrays.asList(
new Student(3, "王五", 20, "广州"),
new Student(4, "赵六", 21, "浙江"),
new Student(5, "孙七", 22, "深圳")
); //lambda
Stream.of(student1,student2).flatMap(student -> student.stream()).forEach(System.out::println);
//方法引用
Stream.of(student1,student2).flatMap(List<Student>::stream).forEach(System.out::println);
//常规方法
Stream.of(student1,student2).flatMap(new Function<List<Student>, Stream<?>>() {
@Override
public Stream<?> apply(List<Student> students) {
return students.stream();
}
}).forEach(System.out::println);
运行结果都是:
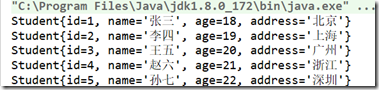
因为flatMap中最后需要将每个元素组合成一个流,所以flatMap方法形参返回了一个stream流。
如果map和flatmap还不清楚可以参考这篇博客:java8 stream流操作的flatMap(流的扁平化) 写的很清楚。
⑦、sorted():自然排序:按自然顺序排序的流元素。
这里就不用Student对象作为举例了,否则要在Student类中实现Comparable接口。
//自然排序
List<String> list = Arrays.asList("CC", "BB", "EE", "AA", "DD");
list.stream().sorted().forEach(System.out::println);
运行结果:
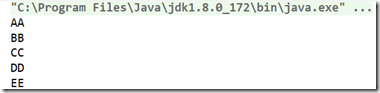
上面使用String中默认实现的接口自动完成排序。
⑧、sorted(Comparator<? super T> comparator):自定排序:按提供的比较符排序的流元素 。
//自定排序
students.stream().sorted((s1,s2)-> {
if(s1.getId()>s2.getId()){
return s1.getId().compareTo(s2.getId());
}else{
return -s1.getAge().compareTo(s2.getAge());
}
}).forEach(System.out::println);
运行结果:
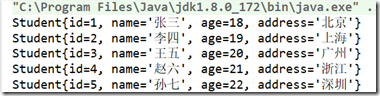
上面的代码表示为先按照id进行排序,如果id相同则按照年龄降序排序,你可以将其他id改为 1测试一下 。
。
6、Stream终止操作
终止操作主要有以下方法:forEach、 forEachOrdered、anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、count、min、 max、 reduce、 collect、toArray、iterator。下面只介绍一下常用的方法。
注意:Stream流只要进行了终止操作后,就不能再次使用了,再次使用得重新创建流。
①、void forEach(Consumer<? super T> action):遍历:接收Lambda表达式,遍历流中的所有元素。
forEach上面已经用的够多的了,这里就不说了。
②、anyMatch/allMatch/noneMatch:匹配:返回值为boolean,参数为(Predicate<? super T> predicate)。
- allMatch——检查是否匹配所有元素
- anyMatch——检查是否至少匹配一个元素
- noneMatch——检查是否没有匹配的元素
boolean b = students.stream().allMatch((s) -> s.getAge() > 20);
System.out.println("allMatch()"+"\t"+b); boolean b1 = students.stream().anyMatch((s) -> s.getAge() > 21);
System.out.println("anyMatch()"+"\t"+b1); boolean b2 = students.stream().noneMatch((s) -> s.getAge() == 22);
System.out.println("noMatch()"+"\t"+b2);
运行结果:

③、findFirst/findAny:查找:返回Optional<T>,无参数。
- findFirst——返回第一个元素
- findAny——返回当前流中的任意元素
//先按id排好序
Optional<Student> first = students.stream().sorted((s1, s2) -> s1.getId().compareTo(s2.getId())).findFirst();
System.out.println("findFirst()"+"\t"+first.get()); Optional<Student> any = students.stream().filter((s)->s.getAge()>19).findAny();
System.out.println("findAny()"+"\t"+any.get());
运行结果:

④、long count():统计:返回流中元素的个数。
//统计流中数量
long count = students.stream().count();
System.out.println("count()"+"\t"+count);
运行结果:

⑤、max/min:大小值:返回Optional<T>,无参数。
- max——返回流中最大值
- min——返回流中最小值
//获取年龄最大值
Optional<Student> max = students.stream().max((s1, s2) -> Integer.compare(s1.getAge(), s2.getAge()));
System.out.println("max()"+"\t"+max.get());
//获取年龄最小值
Optional<Student> min = students.stream().min((s1, s2) -> Integer.compare(s1.getAge(), s2.getAge()));
System.out.println("min()"+"\t"+min.get());
运行结果:

⑥、reduce:归约:可以将流中元素反复结合在一起,得到一个值。
- T reduce(T identity, BinaryOperator<T> accumulator)
- Optional<T> reduce(BinaryOperator<T> accumulator)
//累加0-10
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10); Integer sum = list.stream().reduce(0, (x, y) -> x + y);
//1、T reduce(T identity, BinaryOperator<T> accumulator);
System.out.println("reduce1--"+sum); //2、Optional<T> reduce(BinaryOperator<T> accumulator);
Optional<Integer> sum1 = list.stream().reduce(Integer::sum);
System.out.println("reduce2--"+sum1.get()); Optional<Integer> sum2 = list.stream().reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer integer1, Integer integer2) {
return Integer.sum(integer1,integer2);
}
});
System.out.println("reduce3--"+sum2.get());
运行结果:

备注:map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名。
7、Collectors的使用
Stream流与Collectors中的方法是非常好的搭档,通过组合来以更简单的方式来实现更加强大的功能,我们利用Stream中的collect方法来实现。
collect:收集:将流转换为其他形式。它接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法。
Collector接口中方法得实现决定了如何对流执行收集操作(如收集到List,Set,Map)。但是Collectors实用类提供了很多静态方法,可以方便地创建常见得收集器实例。
所以下面逐一介绍Collectors中的方法:
①、Collectors.toList():将流转换成List。
/**
* Collectors.toList():将流转换成List
*/
List<String> list = students.stream().map(student -> student.getName()).collect(Collectors.toList());
System.out.println("toList----"+list);
②、Collectors.toSet():将流转换为Set。
/**
* Collectors.toSet():将流转换成Set
*/
Set<String> set = students.stream().map(student -> student.getName()).collect(Collectors.toSet());
System.out.println("toSet----"+set);
③、Collectors.toCollection():将流转换为其他类型的集合。
/**
* Collectors.toCollection():将流转换为其他类型的集合
*/
TreeSet<String> treeSet = students.stream().map(student -> student.getName()).collect(Collectors.toCollection(TreeSet::new));
System.out.println("toCollection----"+treeSet);
④、Collectors.counting():元素个数。
/**
* Collectors.counting():元素个数
*/
Long aLong = students.stream().collect(Collectors.counting());
System.out.println("counting----"+aLong);
⑤、Collectors.averagingInt()、Collectors.averagingDouble()、Collectors.averagingLong():求平均数。
这三个方法都可以求平均数,不同之处在于传入得参数类型不同,但是返回值都为Double。
/**
* Collectors.averagingInt()
* Collectors.averagingDouble()
* Collectors.averagingLong()
* 求平均数
*/
Double aDouble = students.stream().collect(Collectors.averagingInt(student -> student.getAge()));
System.out.println("averagingInt()----"+aDouble); Double aDouble1 = students.stream().collect(Collectors.averagingDouble(student -> student.getAge()));
System.out.println("averagingDouble()----"+aDouble1); Double aDouble2 = students.stream().collect(Collectors.averagingLong(student -> student.getAge()));
System.out.println("averagingLong()----"+aDouble2);
⑥、Collectors.summingDouble()、Collectors.summingDouble()、Collectors.summingLong():求和。
这三个方法都可以求和,不同之处在于传入得参数类型不同,返回值为Integer, Double, Long。
/**
* Collectors.summingInt()
* Collectors.summingDouble()
* Collectors.summingLong()
* 求和
*/
Integer integer = students.stream().collect(Collectors.summingInt(student -> student.getAge()));
System.out.println("summingInt()----"+integer); Double aDouble3 = students.stream().collect(Collectors.summingDouble(student -> student.getAge()));
System.out.println("summingDouble()----"+aDouble3); Long aLong1 = students.stream().collect(Collectors.summingLong(student -> student.getAge()));
System.out.println("summingLong()----"+aLong1);
⑦、Collectors.maxBy():求最大值。
/**
* Collectors.maxBy():求最大值
*/
Optional<Integer> integer1 = students.stream().map(student -> student.getId()).collect(Collectors.maxBy((x, y) -> Integer.compare(x, y)));
System.out.println("maxBy()----"+integer1.get());
⑧、Collectors.minBy():求最小值。
/**
* Collectors.minBy():求最小值
*/
Optional<Integer> integer2 = students.stream().map(student -> student.getId()).collect(Collectors.minBy((x, y) -> Integer.compare(x, y)));
System.out.println("maxBy()----"+integer2.get());
⑨、Collectors.groupingBy():分组 ,返回一个map。
/**
* Collectors.groupingBy():分组 ,返回一个map
*/
Map<Integer, List<Student>> listMap = students.stream().collect(Collectors.groupingBy(Student::getId));
System.out.println(listMap);
其中Collectors.groupingBy()还可以实现多级分组,如下:
/**
* Collectors.groupingBy():多级分组 ,返回一个map
*/ //先按name分组然后得出每组的学生数量,使用重载的groupingBy方法,第二个参数是分组后的操作
Map<String, Long> stringLongMap = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.counting()));
System.out.println("groupingBy()多级分组----"+stringLongMap); //先按id分组然后再按年龄分组
Map<Integer, Map<Integer, List<Student>>> integerMapMap = students.stream().collect(Collectors.groupingBy(Student::getId, Collectors.groupingBy(Student::getAge)));
System.out.println("groupingBy()多级分组----"+integerMapMap); //遍历
Map<Integer,List<Student>> map = new HashMap<>();
Iterator<Map.Entry<Integer, Map<Integer, List<Student>>>> iterator = integerMapMap.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<Integer, Map<Integer, List<Student>>> entry = iterator.next();
System.out.println("key="+entry.getKey()+"----value="+entry.getValue());
}
⑩、Collectors.partitioningBy():分区。按true和false分成两个区。
/**
* Collectors.partitioningBy():分区,分成两个区
*/
Map<Boolean, List<Student>> listMap1 = students.stream().collect(Collectors.partitioningBy(student -> student.getAge() > 18));
System.out.println(listMap1);
⑪、Collectors.joining():拼接。按特定字符将数据拼接起来。
/**
* Collectors.joining():拼接
*/
String str = students.stream().map(student -> student.getName()).collect(Collectors.joining("---"));
System.out.println(str);
8、结束语
Java8中的Stream提供的功能非常强大,用它们来操作集合会让我们用更少的代码,更快的速度遍历出集合。而且在java.util.stream包下还有个类Collectors,它和stream是好非常好的搭档,通过组合来以更简单的方式来实现更加强大的功能。虽然上面介绍的都是Stream的一些基本操作,但是只要大家勤加练习就可以灵活使用,很快的可以运用到实际应用中。
夯实Java基础(二十三)——Java8新特征之Stream API的更多相关文章
- Java基础20:Java8新特性终极指南
更多内容请关注微信公众号[Java技术江湖] 这是一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM.SpringBoot.MySQL.分布式.中间件.集群.Linux ...
- Java8 新特性之Stream API
1. Stream 概述 Stream 是Java8中处理集合的关键抽象概念,可以对集合执行非常复杂的查找,过滤和映射数据等操作; 使用 Stream API 对集合数据进行操作,就类似于使用 SQL ...
- Java8 新特性 Lambda & Stream API
目录 Lambda & Stream API 1 Lambda表达式 1.1 为什么要使用lambda表达式 1.2 Lambda表达式语法 1.3 函数式接口 1.3.1 什么是函数式接口? ...
- 【Java8新特性】Stream API有哪些中间操作?看完你也可以吊打面试官!!
写在前面 在上一篇<[Java8新特性]面试官问我:Java8中创建Stream流有哪几种方式?>中,一名读者去面试被面试官暴虐!归根结底,那哥儿们还是对Java8的新特性不是很了解呀!那 ...
- 夯实Java基础(十三)——字符串
字符串应该是我们在Java中用的最频繁.最多的,可见字符串对于我们来说是多么的重要,所以我们非常有必要去深入的了解一下. 1.String String就代表字符串,在Java中字符串属于对象.我们刚 ...
- 夯实Java基础(二十五)——JDBC使用详解
1.JDBC介绍 JDBC的全称是Java Data Base Connectivity(Java数据库连接).是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问(例如MyS ...
- 夯实Java基础系列目录
自进入大学以来,学习的编程语言从最初的C语言.C++,到后来的Java,. NET.而在学习编程语言的同时也逐渐决定了以后自己要学习的是哪一门语言(Java).到现在为止,学习Java语言也有很长一段 ...
- 夯实Java基础系列15:Java注解简介和最佳实践
Java注解简介 注解如同标签 Java 注解概述 什么是注解? 注解的用处 注解的原理 元注解 JDK里的注解 注解处理器实战 不同类型的注解 类注解 方法注解 参数注解 变量注解 Java注解相关 ...
- 夯实Java基础系列1:Java面向对象三大特性(基础篇)
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 [https://github.com/h2pl/Java-Tutorial](https: ...
随机推荐
- Xcode 内存泄露检查出现:nil returned from a method that is expected to return a non-null value iOS 解决方案。
在 使用 Xcode 检查内存泄露时(cmd+shift+B)运行,出现了一个警告:nil returned from a method that is expected to return a no ...
- 生成SSH密钥过程
1.查看是否已经有了ssh密钥:cd ~/.ssh 如果没有密钥则不会有此文件夹,有则备份删除 2.生存密钥: $ ssh-keygen -t rsa -C "name@doumi.com& ...
- EntityFramework 插入自增ID主从表数据
原因: 数据库中的两个表是主从表关系,但是没有建外键,而表的id用的是数据库的自增整数,导致在使用EF导入主从表数据时,需要先保存主表数据,取到 主表的自增id后才能插入从表数据,这样循环之下,数据插 ...
- django+vue基础框架:django one对one格式
创建app:python manage.py startapp app01(这里的app01是指名字,可以是a或b等等) 生成迁移文件:python manage.py makemigrations ...
- PHP固定长度字符串
/** * 获取固定长度随机字符串 * @param $n * @return string * @throws Exception */ function gf_rand_str($n) { if ...
- PAT 1014 Waiting in Line (模拟)
Suppose a bank has N windows open for service. There is a yellow line in front of the windows which ...
- Servlet_001 我的第一个servlet程序
今天开启servlet学习 一.第一个Servlet程序 首先写我们的第一个servlet程序 第一步:新建我们的servlet程序(Web Project),命名为Servlet_001 第二步 : ...
- ELK日志分析系统部署
======================================================================================= 操作系统 IP地址 主机 ...
- pycharm连接数据库报错Access denied for user 'root'@'localhost' (using password:YES),以及wampserver 2/3个服务器正在运行 问题
使用mysql版本为mysql5.7,参考下列 https://blog.csdn.net/qq_32969455/article/details/79051932 https://blog.csdn ...
- 聊聊面试中常问的GC机制
GC 中文直译垃圾回收,是一种回收内存空间避免内存泄漏的机制.当 JVM 内存紧张,通过执行 GC 有效回收内存,转而分配给新对象从而实现内存的再利用. JVM GC 机制虽然无需开发主动参与,减轻不 ...