关于 word2vec 如何工作的问题
2019-09-07 22:36:21
问题描述:word2vec是如何工作的?
问题求解:
谷歌在2013年提出的word2vec是目前最常用的词嵌入模型之一。word2vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是cbow和skip gram。
cbow的目标是根据上下文来预测中心词的出现概率,skip-gram则是通过中心词来预测上下文中的单词的出现概率。

对于cbow而言,输入是上下文的one hot表示,它们共同过一个word embedding层/hidding layer层,可以得到上下文的w2v的加和,之后再过一个hidding layer + softmax layer就可以得到各个单词的出现概率,将之和truth进行交叉熵运算就可以得到它们之间的相似性,最后进行梯度回溯即可。
对于skip-gram来说,输入是中心词的one hot表示,它过一个word embedding层后得到其w2v,之后再过一个hidding layer + softmax layer就可以得到各个单词的出现概率,将之和truth进行交叉熵运算就可以得到它们之间的相似性,最后进行梯度回溯即可。
简单比较cbow 和 skip-gram,它们本质上都是语言模型,区别有两点,一个是cbow输入的是上下文的单词,输出的是中心词;skip-gram输入的是中心词,输出的是上下文的单词;第二个显著的不同是cbow的输入是批量输入的,也就是上下文的单词是整体进行输入的,但是skip-gram则是单词对进行输入,也就是一个中心词可以对应多个上下文单词,并且这多个pair是不同的训练集。
word2vec的优化策略:
- Subsampling Frequent Words 高频词汇下采样
对于高频词汇,诸如the,a等词汇,它会经常出现在各种pair对中:
1)<cat, the> 这个pair对事实上并不能提供很多的关于cat的有效信息;
2)<the, apple> 关于高频词的pair对的数目会远远多于我们实际需要的数目,这个地方产生了冗余;
为了解决这个问题,就提出了高频词汇下采样的策略。
高频词汇下采样的具体做法:对于一个window中的词汇我们以词频的概率对其中的单词进行舍弃,一旦我们舍弃了这个单词,那么这个单词就不会出现在以别的中心词为代表的上下文中(注意,自己作为中心词的时候依然会组pair)。
If we have a window size of 10, and we remove a specific instance of “the” from our text:
As we train on the remaining words, “the” will not appear in any of their context windows.
We’ll have 10 fewer training samples where “the” is the input word.
Trick:在编程实现高频词汇下采样的时候呢,还有一个trick,这里不是直接使用的词频,而是对词频进行了一定的修改,以如下的概率对某个单词进行保留,可以通过函数图像看出这个函数在词频很高的时候保留概率较低,在词频很低的时候保留概率较高。
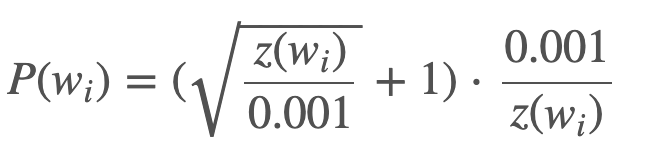
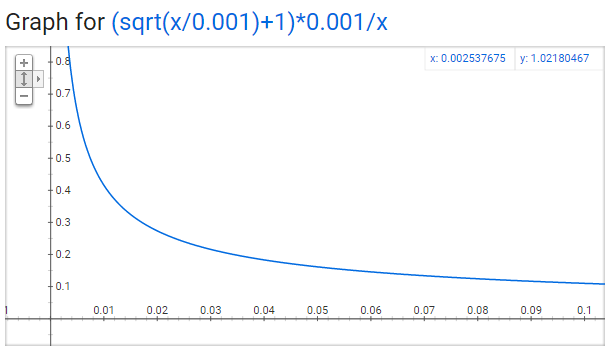
这个函数中的0.001是一个参数,名叫sample,有了这个参数我们就可以手动的去设置保留的sample的数量,如果数值取的小的话,那么实际得到的sample的数目就会少。
There is also a parameter in the code named ‘sample’ which controls how much subsampling occurs, and the default value is 0.001. Smaller values of ‘sample’ mean words are less likely to be kept.
- Negative Sampling 负采样
负采样主要解决的问题就是参数量过大,模型很难训练的。我们知道最后的输出是各个单词的概率,那么最后一个hidding layer的参数量就是 vec_size * vocab_size,而vocab_size是有可能达到10w的,如果vec_size = 400的话,那么最后的这个matrix的参数量就是4kw,这个是一个非常庞大的参数量,如何减小对这么巨大的参数量的运算呢?可以使用负采样的机制进行有效的参数控制。
采样负采样其实是真正以pair对的形式来看数据,如果说之间是一个多分类的话,那么采用负采样后就是一个二分类的问题。
<a, b1> 1
<a, b2> 1
<a, b3> 1
<a, c1> 0
<a, c2> 0
每次只对pair对进行判断,如果是正例,那么输出为1, 如果是负例,那么输出是0。采用这种方式之后,每次的参数迭代量其实就是两个w2v的大小,这样就可以大大减少参数的更新数目,起到加速模型训练的效果。
一般来说我们是进行随机采样的,采样的数目多少论文中提到如果是小的数据集,那么一般负采样的数目是5 - 20个,如果是大数据集,那么负采样的数据数目是2 - 5。这个我理解是因为如果是大数据集,那么正采样的数据量已经足够将模型学习的非常好了,所以对于负采样的要求没有那么的高。
Trick:一般来说在随机进行负采样的时候概率是以词频的概率进行抽取的,但是在实际的实现中,加上了一个幂次,实际的挑选概率的计算如下,使用这种方式进行选择可以打压高频被反复挑选到的次数,提高低频词汇被挑选到的次数。
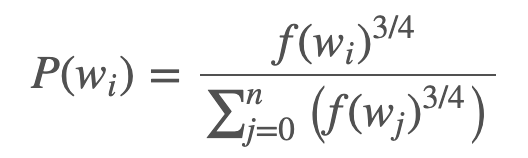
- Hierarchical Softmax 层次softmax
对于训练的参数过多的问题,使用负采样的思路是解决问题的一条途径,还有一条道路是使用层次softmax的技巧来对需要训练的参数的数目进行降低。
所谓层次softmax实际上是在构建一个哈夫曼树,这里的哈夫曼树具体来说就是对于词频较高的词汇,它的树的深度就较浅,对于词频较低的单词的它的树深度就较大,实际的样子如下图所示。
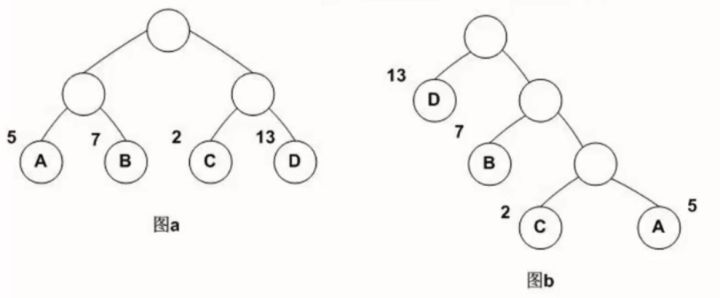
在实际训练的过程中,这里的每个节点就是一个神经元,实际上将也是将之前的多分类转成了多个二分类降低了算法回溯的时候需要更新的神经元的数目。
关于 word2vec 如何工作的问题的更多相关文章
- word2vec——高效word特征提取
继上次分享了经典统计语言模型,最近公众号中有很多做NLP朋友问到了关于word2vec的相关内容, 本文就在这里整理一下做以分享. 本文分为 概括word2vec 相关工作 模型结构 Count-ba ...
- (转)深度学习word2vec笔记之基础篇
深度学习word2vec笔记之基础篇 声明: 1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用 ...
- 重磅︱文本挖掘深度学习之word2vec的R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:2013年末,Google发布的 w ...
- 深度学习word2vec笔记之基础篇
作者为falao_beiliu. 作者:杨超链接:http://www.zhihu.com/question/21661274/answer/19331979来源:知乎著作权归作者所有.商业转载请联系 ...
- word2vec词向量训练及中文文本类似度计算
本文是讲述怎样使用word2vec的基础教程.文章比較基础,希望对你有所帮助! 官网C语言下载地址:http://word2vec.googlecode.com/svn/trunk/ 官网Python ...
- 深度学习-语言处理特征提取 Word2Vec笔记
Word2Vec的主要目的适用于词的特征提取,然后我们就可以用LSTM等神经网络对这些特征进行训练. 由于机器学习无法直接对文本信息进行有效的处理,机器学习只对数字,向量,多维数组敏感,所以在进行文本 ...
- 利用 TensorFlow 入门 Word2Vec
利用 TensorFlow 入门 Word2Vec 原创 2017-10-14 chen_h coderpai 博客地址:http://www.jianshu.com/p/4e16ae0aad25 或 ...
- 从锅炉工到AI专家(10)
RNN循环神经网络(Recurrent Neural Network) 如同word2vec中提到的,很多数据的原型,前后之间是存在关联性的.关联性的打破必然造成关键指征的丢失,从而在后续的训练和预测 ...
- word2vec是如何工作的?
如何有效的将文本向量化是自然语言处理(Natural Language Processing: NLP)领域非常重要的一个研究方向.传统的文本向量化可以用独热编码(one-hot encoding). ...
随机推荐
- hexo-next-travis-ci 构建自动化部署博客
构建效果如上面视频所示,如果浏览器不支持请戳一下链接: 自动化部署构建效果 .只要将编辑的 .md 文件推送到 github 上,博客网站就可以更新这篇文章. 其实差不多半年前也构建过一次,由于安装 ...
- 接口自动化测试平台 http://120.79.232.23
接口自动化测试平台 http://120.79.232.23 T Name Latest commit message Commit time .idea 修改自动化用例修改接口时,其他接口信息被删的 ...
- insert时出现主键冲突的处理方法
使用"insert into"语句进行数据库操作时可能遇到主键冲突,用户需要根据应用场景进行忽略或者覆盖等操作.总结下,有三种解决方案来避免出错. 测试表:CREATE TABLE ...
- Twins:眼红红 - fancybot的博客
"我最初面红.现在双眼通红" TWINS 听听歌.小时候.听得最最最多的就是TWINS的了 跳过图片 跳过歌词 眼红红 Twins 仍然怀念他 一起去学结他 一对黑眼圈 回望中三暑 ...
- 记 MySQL优化 20条
1. 为查询缓存优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的.当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一 ...
- C++走向远洋——21(项目一,三角形,类)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:sanjiaoxing.cpp * 作者:常轩 * 微信公众号: ...
- JMeter-WebService接口的测试
前言 JMeter3.2版本之后就没有SOAP/XML-RPC Request插件了,那么该如何进行webservice接口的测试呢? 今天我们来一起学习一下怎么在3.2以后版本的JMeter进行we ...
- js面试-手写代码实现new操作符的功能
我们要搞清楚new操作符到底做了一些什么事情? 1.创建一个新的对象 2.将构造函数的作用域赋给新对象(因此this指向了这个新对象) 3.执行构造函数中的代码(为这个新对象添加属性) 4.返回新对象 ...
- MySQL集群MGR架构for多主模式
本文转载自: https://www.93bok.com MGR简介 MySQL Group Replication(简称MGR)是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决 ...
- 常用css3选择器
<div class="wrapper"> <p class="test1">1</p> <p class=" ...