词向量模型word2vector详解
前言
记得第一次接触word2vec的时候是在研二的时候,当时看了一些介绍的博客,对word2vec的原理有了一些了解,但是对于其中的细节,推导等没有理解的透彻,后来也不知道什么原因,就将其搁置了。最近有了一些时间,准备写一个预训练语言模型的系列,所以准备先拿word2vec开刀,热热身。话不多说,开始我们今天的正题,here we go。
1、背景知识
1.1、词向量
词向量这个概念很早就已经提出来了,为什么要提出词向量这个概念呢?我们都知道,对于一段语言文字来说,计算机是不能理解人所说的语言的,所以需要一种方法,将人类的语言映射到计算机可以理解的维度。所以,我们想到的一种方法是,将词汇映射为一个向量,例如,我们已经得到了“足球"这个单词的向量为w,则在计算机中,见到向量w就知道其所代表的单词是"足球"了。
好了,假如我们现在得到了这样的一批词汇的向量了,那么这些向量该怎么用呢?
- 计算单词之间的相似度
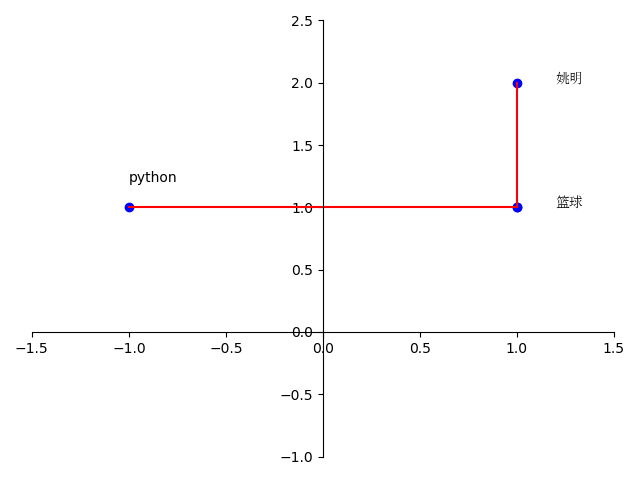
我们知道,对于向量空间中的两个点,我们可以用两个点的距离来代表两个点的远近,那既然这样的话,是不是可以用两个点所在的空间中的远近来代表两个词汇的相似程度呢。比如,对于一个二维空间来说,假设"篮球"的词向量为[1,1],"姚明"的词向量[1,2],python的词向量是[-1,1],我们发现,单词"篮球"和"姚明"的距离为1,"python"和"篮球"的距离为2,那我们可以猜测,"篮球"和"姚明"两个词的相似度较高要比"Python"和"篮球"的相似性要高。
- 可以通过加减法获得对应单词
通过词向量,我们寄希望于向量间的加减法来获得这样的性质,如vec(中国) + vec(首都) = vec(北京)
- 可以推测相关单词
如图所示,假如我们将两种语言分别进行词向量的训练,得到如下的结果,假设词向量维度为2维,由此,我们可以推断出图二的?为英文单词three。

当然,以上只是词向量的一些用法,词向量的一个重要的用法是当做神经网络的输入embedding,将一个高质量的固定好的词向量作为神经网络的输入embedding,不仅可以提高训练速度,在有些时候,也会获得不错的效果。
1.2、one-hot模型
one_hot模型是词向量的一种,也是比较早的词向量表示方法,one-hot模型将每个单词映射到一个V维向量中,其中V代表词汇的数量,v[i]为1表示是当前单词,为0表示不是当前单词。如下图所示,假设总共有3个单词,["我","爱","中国"],则one-hot模型可以表示成
我\\
爱\\
中国
\end{matrix}
\begin{bmatrix}
1 & 0 & 0\\
0 & 1& 0\\
0 & 0 & 1
\end{bmatrix}
\]
one-hot模型的优点是简单,直观,方便表示,缺点是当V变得特别大的时候,容易造成维度灾难,尤其是在大数据的时代,往往V可以达到十万到百万级别,且这种表示方法无法获取单词之间的相互关系,单词之间是相互独立的。
1.3、word2vec模型
word2vec是Google于2013年开源推出的一个用于获取word vector的工具包,它简单、高效,因此引起了很多人的关注。word2vec的理论来源于Tomas Mikolov的两篇论文[1][2],这两篇文章都提到了word2vec的两个模型,CBOW模型和skim-gram模型,但是论文并没有对模型进行详细的讲解,随后,xin rong[3] 又对两个模型的参数进行了详细的推导和详解,至此,通过这三篇文章,我们基本上可以了解word2vec的整体模型结构和原理。
word2vec主要是基于这样的思想,在一个句子中,一个词的周围若干词和这个词有较强的相关性,而其他词相关性则较差,根据这样的思想,我们构建神经网络,来对当前词和其上下文词进行模型训练,最终得到词向量。其实,word2vec的本质上是构建一个语言模型,而词向量是其一个副产物。在本篇文章中,我们不过多介绍语言模型的相关细节,有兴趣的读者可以自行搜索语言模型相关算法,n-gram,NNLM,甚至bert啊等等
word2vec主要包含两个模型,CBOW和skim-gram,CBOW主要是根据当前词的上下文词,即context来推断当前词,而skim-gram主要是根据context上下文的词来推断当前词。基本上,这两个模型都是可以用一个三层神经网络来进行描述。
CBOW模型和skim-gram模型理论上是可行的,但是在现实情况中,由于数据量较大,导致计算时间过长,例如,一般情况下训练语料中的词汇V的个数是万级别的,那么,我们构建三层神经网络时,每次需要更新的参数是V * h * V的数量,其中h为隐藏层的节点数,也可以理解为词向量的维度,所以导致训练时间过长,那么,如何减少训练时间呢?Hierarchical Softmax和Negative Sampling就是解决训练时间过长的方法
1.3.1、单个单词到单个单词的例子
本节首先介绍一个简单的一个词到一个词的简单模型,搞懂了这个模型,我们就很好理解CBOW模型和skim-gram模型了。
假定我们有这样一句话"我喜欢观看巴西足球世界杯",经过分词,我们得到,['我','喜欢','观看','巴西','足球','世界杯'],由于我们这个模型是训练一个词到一个词的模型,所以,我们对单词进行两两分组,得到[['我','喜欢'],['喜欢','观看'],['观看','巴西'],['巴西','足球'],['足球','世界杯']]。在最原始的word2vec模型中,我们将分组好的词汇分别输入到下面的模型中,进行训练。
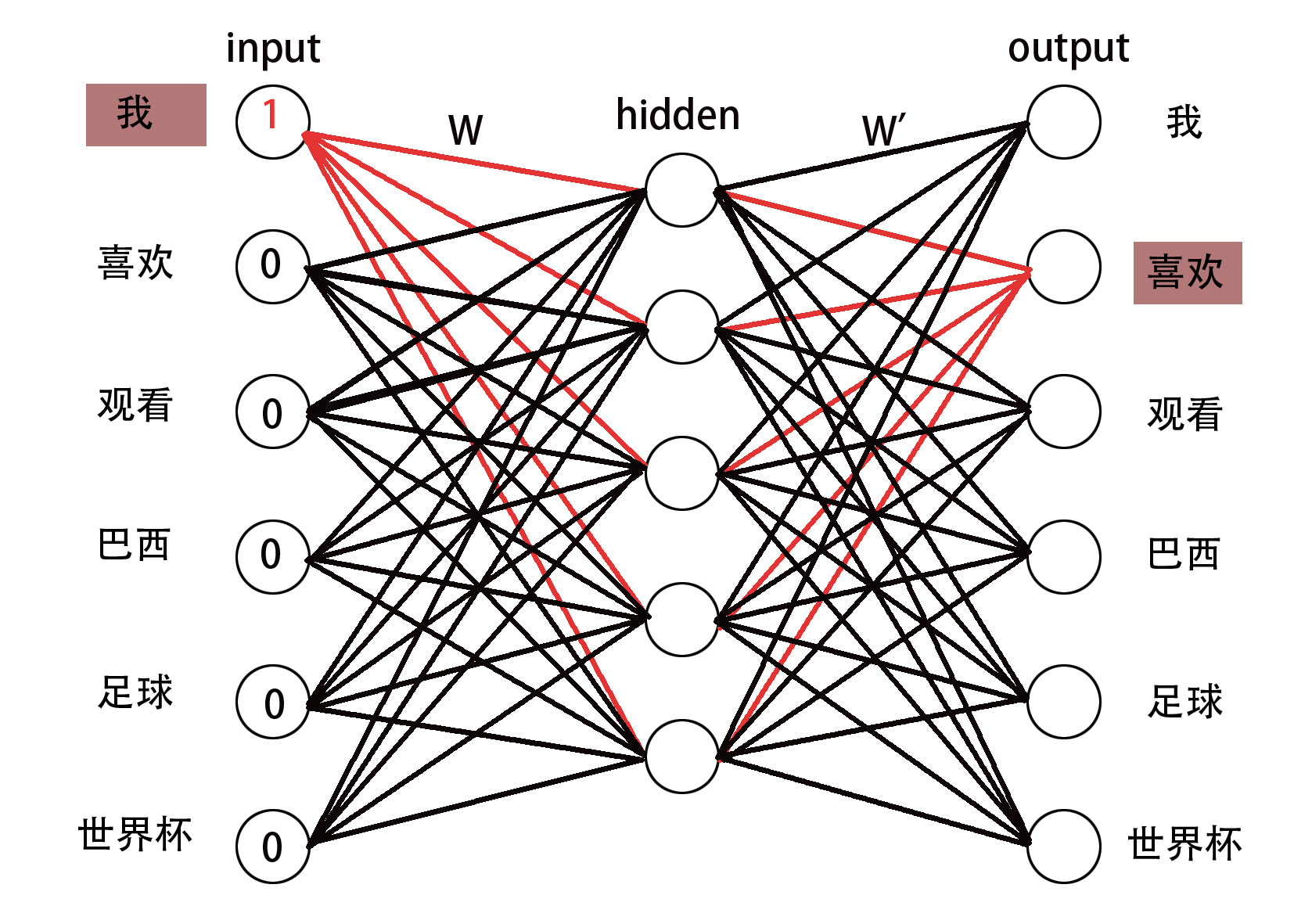
- 输入层
在第一轮训练中,我们将['我','喜欢']这两个词输入到这个模型中,在这个模型中,输入为一个one-hot向量,当我们输入'我'这个词的时候,'我'这个词所对应的节点为1,其余的为0,输入层的节点个数即为词汇数量V,我们这里的V即为6。 - 输入层->隐藏层
输入层到隐藏层是一个\(V*H\)维的向量,其中\(H\)为隐藏层节点个数,一般情况下,我们会把\(V*H\)的向量作为最终的词向量,我们把这个\(V*H\)的权值向量成为\(W\),其实隐藏层大的节点即为输入节点所对应的词向量,为啥呢,因为其他词的输入都为0,只有'我'这个词的输入为1,所以只有'我'所对应的权值会参与计算,而其他的词都不会参与计算。 - 隐藏层->输出层
隐藏层到输出层是一个\(H*V\)的权值向量\(W'\),其中输出层节点个数也是V,即我们根据计算,得到每一个输出节点的权值。 - 更新参数\(W\)和\(W'\)
接下来我们在每一轮输入的时候都需要更新权值\(W\)和\(W'\),我们用到的方法就是构建损失函数,用梯度下降方法进行更新。在这里,先用大白话解释下损失函数,在第一轮训练,即训练集['我','喜欢']输出的时候,寄希望于'喜欢'那个输出节点值最大,而其他的值都最小,有了解softmax的小伙伴就知道了,可以在输出层做一次softmax,构造相应的损失函数,以最大化'喜欢'的那个词所对应的输出节点。
1.3.2、单个单词到单个单词的推导
接下来我们扩展到一般情况。

在这里,我们假定输入层为\(X\),\(X\)的维度为\(V\),\(V\)表示词表大小,\(x_{i}\)表示第\(i\)个节点的输入值,\(W\)为输入层到隐藏层的权值向量,\(w_{ki}\)表示第\(k\)个输入节点到第\(i\)个隐藏层节点边的权值,\(h_{i}\)第\(i\)个隐藏层节点,\(W'\)表示隐藏层到输出层的权值向量,\({w'_{ij}}\)表示隐藏层第\(i\)个节点到输出层第\(j\)个节点边的权值,输出层同样是一个\(V\)维的向量,其中\(y_{j}\)表示输出层第\(j\)个节点。我们接下来将分三步走,第一步,对前向流程建模,第二步,构造损失函数,第三步,反向传播对权值进行更新
- 前向流程建模
公式(1.1)中\(W\)代表输入层到隐藏层权值向量,\(x\)表示输入的one-hot向量,\(h\)表示隐藏层向量,后面的\(W_{k,.}^{T}\)和\(V_{wI}^{T}\)表示的就是输入节点为1所对应的向量。由于输入的是一个one-hot向量,所以只有一维是1,参与计算,其他的均不参加计算
公式(1.2)中表示隐藏层到输出层,这里的\(V{'}_{w_j}^{T}\)表示的就是隐藏层到输出层节点\(j\)的权值,\(u_{j}\)表示输出层第\(j\)个节点的输出值。
公式(1.3)中是一个softmax层,我们对输出层进行softmax。
\]
= \sum_{i=1}^{H} W^{\prime}_{ij} h_{i} \tag{1.2}
\]
\]
- 构造损失函数
至此,我们就可以构建我们的损失函数了,我们需要最大化\(max y_{j^{*}}\),这个\(j^{*}\)就是我们要找的那个输出的词,拿1.3.1的例子来说就是"喜欢"这个词所对应的输出,我们对\(max y_{j^{*}}\)进行一下简化,最大化\(max y_{j^{*}}\)转化为了最小化E。
\]
- 反向传播更新参数
\]
=e_{j} \cdot h_{i} \tag{1.6}
\]
\]
= (\sum_{j=1}^{V} e_{j} \cdot w_{i j}^{\prime}) \cdot x_{k} \tag{1.8}
\]
首先,明确我们需要更新的向量,一个是\(W\),一个是\(W'\),公式(1.5),我们先对\(u_{j}\)进行求导,其中\(y_{j}\)就是输出层的输出,\({t_{j}}\)表示什么呢?他表示1或者0,当为当前词时,即我们例子中的"我"时,则为1,否则,为0。这里如果有不明白的,可以对公式(1.4)中的\(u_{j^{*}}-\log \sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right)\)求导一下就明白了。
公式(1.6)就是对\(w'_{ij}\)进行求导,第一项我们由公式(1.5)已经得出,第二项是输出单元\(u_{j}\)对\(w'_{ij}\)进行求导,其中\(u_{j} = \sum_{i=1}^{H} w'_{i j} h_{i}\)求导得到\(h_{i}\)
公式(1.7)是对\(h_{i}\)进行求导,由于\(h_{i}\)和输出层所有的节点都有关系,所以需要对输出层所有节点进行求导,对每一个输出层求导得到的是\(e_{j} \cdot w_{i j}^{\prime}\),之后对其进行累加,得到所有输出节点对\(h_{i}\)的导数,我们写成\(\mathrm{EH}_{i}\)
公式(1.8)则是对我们的输入层到隐藏层权值\(w_{ij}\)进行求导,其实,这里最后更新的权值只是输入节点即例子中"我"到隐藏层节点的权值,对于其它节点的权值,我们不进行更新。
- 最后,我们得到我们需要更新的两个权值向量
\]
\]
至此,推导完毕。
2、CBOW模型
好了,当我们理解了1.3.2中的推导之后,我们在来看CBOW模型就容易多了,其实CBOW模型就是在输入的时候没有输入一个单词,而是输入多个单词,而这多个单词就是当前单词的附近的单词,假设我们定义一个距离为1,我们要把当前单词前后距离为1的单词集合作为其context单词集合。还拿"我喜欢观看巴西足球世界杯"举例,我们最终构造的训练数据集如下:

下面这个图是CBOW的模型图
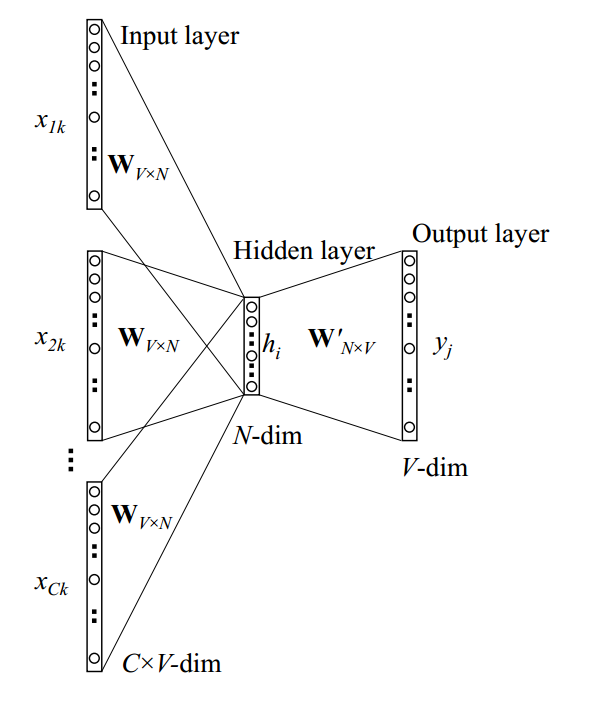
其实CBOW和我们之前在1.3.2所说的单个单词到单个单词的区别在于我们这次输入的是多个单词,所以可以叫多个单词对应单个单词。我们依然进行三步:前向网络构建,构造损失函数,更新参数权值。
- 前向网络构建
基本上CBOW和1.3.1的公式类似,区别在于输入时的单词个数,所以可以将1.3.1当成一个简化CBOW。
公式(2.1.1)中\(C\)表示上下文词汇数量,\(W\)表示输入层到隐藏层权值,\(v_{wi}\)表示第\(i\)个词汇的词向量,本质上输入层到隐藏层就是单词所对应的向量进行相加。从隐藏层到输出层和可以参见公式(1.2)和公式(1.3)。
\mathbf{h} &=\frac{1}{C} \mathbf{W}^{T}\left(\mathbf{x}_{1}+\mathbf{x}_{2}+\cdots+\mathbf{x}_{C}\right) \\
&=\frac{1}{C}\left(\mathbf{v}_{w_{1}}+\mathbf{v}_{w_{2}}+\cdots+\mathbf{v}_{w_{C}}\right)^{T}
\end{aligned} \tag{2.1}
\]
- 构造损失函数
损失函数基本上也和1.3.1一样,无非时我们的条件概率时在context为输入的情况下,输出单词的概率。
E &=-\log p\left(w_{O} | w_{I, 1}, \cdots, w_{I, C}\right) \\
&=-u_{j^{*}}+\log \sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right) \\
&=-\mathbf{v}_{w_{O}}^{\prime} T \cdot \mathbf{h}+\log \sum_{j^{\prime}=1}^{V} \exp \left(\mathbf{v}_{w_{j}}^{\prime} T^{T} \cdot \mathbf{h}\right)
\end{aligned} \tag{2.2}
\]
- 更新参数权值
基本上,我们的权值更新也和1.3.1一样,无非是在输入层的时候,我们对输入层到隐藏层权值更新求了个平均。
&\mathbf{v}_{w_{j}}^{\prime}(\text { new })=\mathbf{v}_{w_{j}}^{\prime}(\text { old })-\eta \cdot e_{j} \cdot \mathbf{h}\\
&\text { for } j=1,2, \cdots, V
\end{aligned} \tag{2.3}
\]
&\mathbf{v}_{w_{I, c}}^{(\text {new })}=\mathbf{v}_{w_{I, c}}^{(\text {old })}-\frac{1}{C} \cdot \eta \cdot \mathrm{EH}^{T}\\
&\text { for } c=1,2, \cdots, C
\end{aligned} \tag{2.4}
\]
3、skim-gram模型
skim-gram是另外一种获取词向量的方式,CBOW模型获取词向量的方式是多个词同时通过神经网络去对应当前词,而skim-gram的输入是当前词,输出的是其上下文词context,换句话说,我们要最大化输出词的节点。模型结构如下图所示:
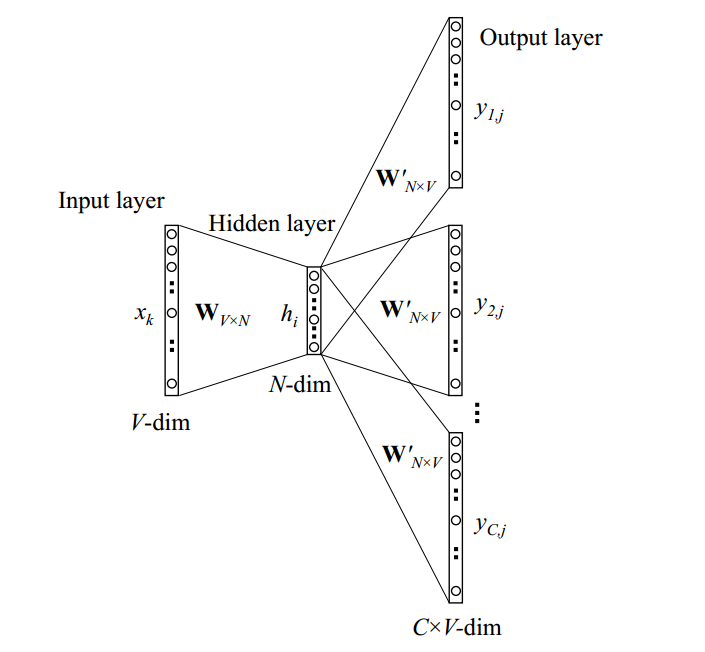
接下来,我们还是分三步走。
- 前向传播
公式(3.1)表示的是从输入层到隐藏层,有没有发现和单个单词到单个单词的第一步很相似,几乎是一样的。
公式(3.2)表示的是隐藏层到输出层,基本上也和单个单词到单个单词的类似。
公式(3.3)表示的是一层softmax,输出每一个节点的概率值,这里的C表示的就是上下文context的数量。
\]
\]
\]
- 构造损失函数
公式(3.4)是构造损失函数,这里我们最大化的不是一个节点,而是多个节点,这多个节点就是上下文context所对应的节点,比如输入的单词是"喜欢"所对应的节点,那么输出的词所对应的节点就是"我"和"观看"这两个词所对应的节点。
E &=-\log p\left(w_{O, 1}, w_{O, 2}, \cdots, w_{O, C} | w_{I}\right) \\
&=-\log \prod_{c=1}^{C} \frac{\exp \left(u_{c, j_{c}^{*}}\right)}{\sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right)} \\
&=-\sum_{c=1}^{C} u_{j_{c}^{*}}+C \cdot \log \sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right)
\end{aligned} \tag{3.4}
\]
- 反向传播
\]
\]
\]
\]
- 更新参数
基本上,更新参数和单个单词到单个单词的差不多。
\]
\]
4、Hierarchical Softmax
首先我们思考一下,上述两种模型应用在实际产品中可不可行?我们发现,每次训练,我们都需要更新大量的参数,参数的数量为 \((V * H + (H * 1) * k)\)个,其中\(V * H\)表示隐藏层到输出层的向量个数,\((H * 1) * k\)表示输入的k个单词的词向量,在单个单词到单个单词和skip-gram的场景中,k = 1,CBOW中,k = C(上下文单词的个数)。一般情况下,V的个数都是数十万级别,H通常情况下也是100维左右,那每一次参数更新,都需要更新1000万的参数,可想而知,这种参数更新的量会非常的大,所以,我们需要有一种方法来解决这种问题,要不然上述两种模型无法应用于实际的生产环境中。
解决效率问题的方法就是我们接下来要说的Hierarchical Softmax和Negative Sampling方法
4.1、CBOW中的Hierarchical Softmax
我们先来说说CBOW中的Hierarchical Softmax是什么样子的。Hierarchical Softmax的中心思想就是用一个哈夫曼树来代替隐藏层到输出层,其中叶子节点的个数维词汇V的个数,每个叶子节点都有一条唯一的从根节点到叶子节点的路径,每个内部节点也都维持着一个K维的向量,我们用以下示意图来描述一下CBOW中的Hierarchical Softmax结构。
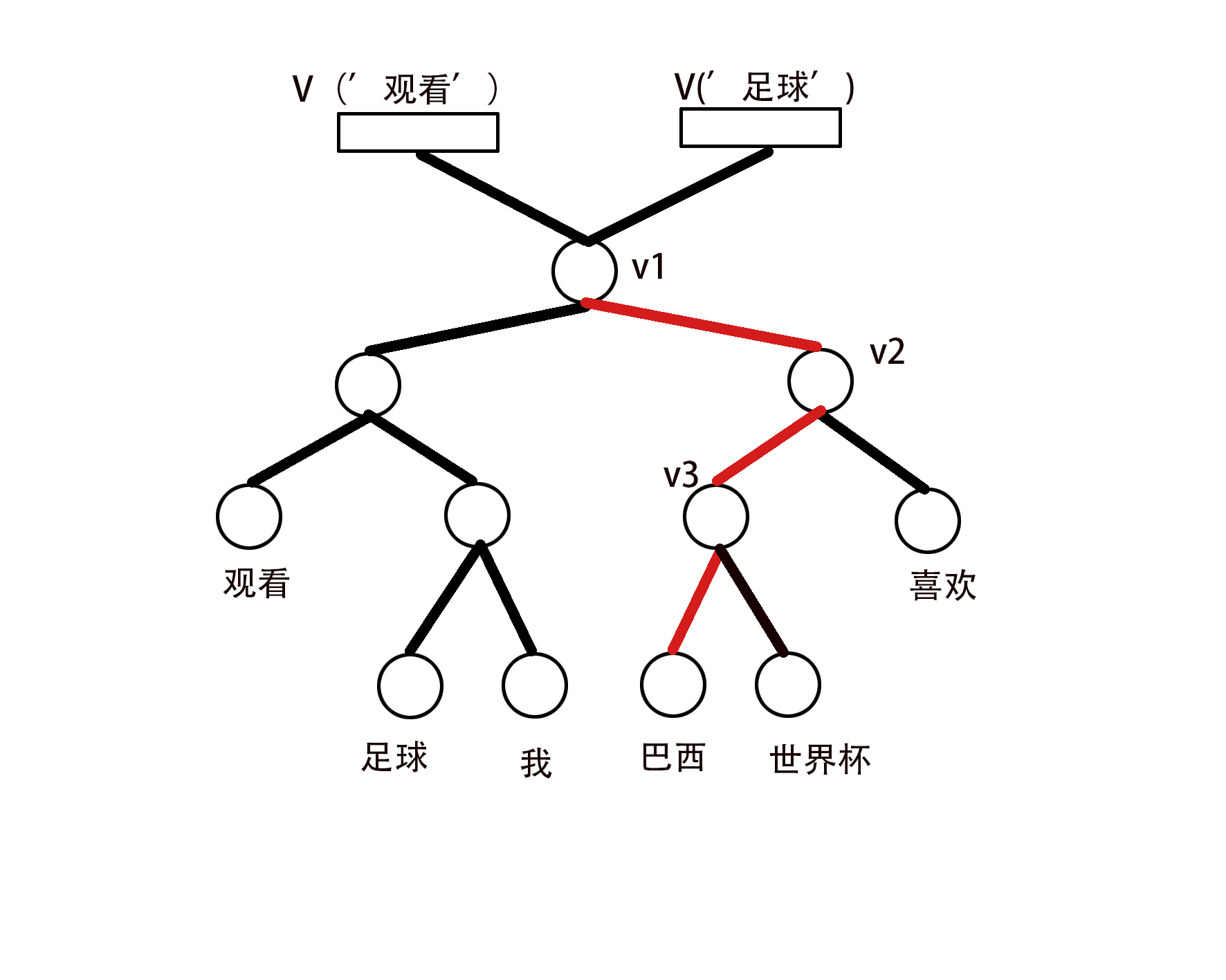
这里我们假设词汇在词表中出现的次数为count("我") = 5,count("喜欢") = 10,count("观看") = 8,count("巴西") = 6,count("足球") = 4,count("世界杯") = 7,这里我们只是做一个简单的假设,正常情况下,词表中的词汇肯定不止这些,我们这里仅仅是为了方便说明。我们这里以'巴西':['观看','足球']这组数据为例,首先,我们假定每一个单词的词向量为\(w\),假定w('巴西')代表巴西的词向量,首先,我们先将w('观看')和w('足球')词向量进行相加w('观看')+w('足球'),假设得到的是w(context),则P(w=w('巴西'))= sigmoid(1 * v1 * v(context)) * sigmoid(- 1 * v2 * v(context)) * sigmoid( - 1 * v3 * v(context)),这里我们做了个假设,在到'巴西'节点的路径上,向左表示-1,向右表示 +1,这里也可以将向右表示+1,向左表示-1。至此,这个示例的前向传播就算完成了,至此,我们继续把这种情况扩展到一般情况,进而构造模型等。
4.2、CBOW中的梯度计算
下面,我们将计算推广至一般情况,并用公式表示前向传播,并构造损失函数进行权重的更新。
- 前向传播
公式(4.1)中\(L(w)\)表示从根节点到叶子节点的的路径长度,\(\mathbf{V}_{n}^{\prime}(w, j)\)表示从根节点到叶子点中,第j个内部节点的向量,\(h\)表示上下文context向量的和,在上述例子中就是v('观看') + v('足球'),\(【n(w, j+1)=\operatorname{ch}(n(w, j))】\)这个公式表示当前节点到下一个节点是向左还是向右,向左我们就用1表示,向右我们就用-1表示。最外层我们加了一个sigmoid函数
\]
- 损失函数
\]
- 梯度计算
在公式(4.3)中我们先对\(\mathbf{v}_{j}^{\prime} \mathbf{h}\)进行求导,其中【.】表示如果当前节点向左那么为-1,否则为1,这个我们在之前解释过。\(t_{j}\)为1时表示【.】为1,为0时表示【.】为-1.
公式(4.4)表示对\(v'_{j}\)的求导,也就是我们中间节点的求导,这一步相对而言比较简单。
公式(4.5)表示对context向量的求导,也就是隐藏节点\(h\)的求导,由于从根节点到叶子节点这条路径上都有\(h\)参与的计算,所以要对哈夫曼树中的每一层都需要求导。
\frac{\partial E}{\partial \mathbf{v}_{j}^{\prime} \mathbf{h}} &=\left(\sigma\left(【.】 \mathbf{v}_{j}^{\prime T} \mathbf{h}\right)-1\right) 【.】 \\
&=\left\{\begin{array}{ll}
\sigma\left(\mathbf{v}_{j}^{\prime T} \mathbf{h}\right)-1 & (【.】=1) \\
\sigma\left(\mathbf{v}_{j}^{\prime T} \mathbf{h}\right) & (【.】=-1) \\
& =\sigma\left(\mathbf{v}_{j}^{\prime T} \mathbf{h}\right)-t_{j}
\end{array}\right.
\end{aligned} \tag{4.3}
\]
\]
\frac{\partial E}{\partial \mathbf{h}} &=\sum_{j=1}^{L(w)-1} \frac{\partial E}{\partial \mathbf{v}_{j}^{\prime} \mathbf{h}} \cdot \frac{\partial \mathbf{v}_{j}^{\prime} \mathbf{h}}{\partial \mathbf{h}} \\
&=\sum_{j=1}^{L(w)-1}\left(\sigma\left(\mathbf{v}_{j}^{\prime T} \mathbf{h}\right)-t_{j}\right) \cdot \mathbf{v}_{j}^{\prime} \\
&:=\mathrm{EH}
\end{aligned} \tag{4.5}
\]
- 参数更新
\]
&\mathbf{v}_{w_{I, c}}^{(\text {new })}=\mathbf{v}_{w_{I, c}}^{(\text {old })}-\frac{1}{C} \cdot \eta \cdot \mathrm{EH}^{T}\\
&\text { for } c=1,2, \cdots, C
\end{aligned} \tag{4.7}
\]
5、Negative Sampling
5.1、Negative Sampling计算思路
Negative Sampling也是一种加快计算速度的一种方式,但是我个人认为他跟前面的神经网络没有半毛钱关系了,基本上就是构造了一个损失函数,进而对损失函数进行求导,更新参数。说的有些笼统了,再具体点就是,我们把某个单词的上下文单词作为正例,比如以"足球"这个词举列子,我们可以把"巴西","世界杯"当作正例,再选择一批词作为负例,至于这批词怎么选,我们稍后会进行讲解,进而,我们构造目标函数,目标函数的目的就是要最大化正例在当前词的相关程度,而最小化负例在当前词的相关程度。
由于这里并不涉及神经网络,所以我们直接给出损失函数。
\]
从公式(5.1)我们可以看出,损失函数主要包括两大块,第一块就是让我们的正例最大,而第二块就是让我们的负例最小。其中,\(v'_{wo}\)表示的是我们的输出层节点,在CBOW中这个值就是我们将要找的那个节点的向量,举个例子,样本为'足球':['世界杯','巴西'],那\(v'_{wo}\)就是'足球'这个词的词向量,而\(h\)就是'世界杯'和'巴西'两个词向量的和,在skim-gram中则相反,第二个式子中\(v'_{w_{j}}\)表示的就是负例的词向量
接下来,我们对里面的参数进行求导。
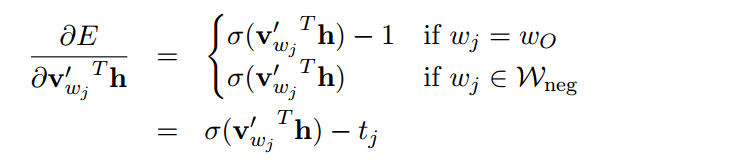
(5.2)
\]
接着我们对参数进行更新
\]
&\mathbf{v}_{w_{I, c}}^{(\text {new })}=\mathbf{v}_{w_{I, c}}^{(\text {old })}-\frac{1}{C} \cdot \eta \cdot \mathrm{EH}^{T}\\
&\text { for } c=1,2, \cdots, C
\end{aligned} \tag{5.5}
\]
5.2、Negative Sampling的方法
关于负采样,我们可以单独用一章来进行讲解,在这里可以直接借用[5]的算法。
6、后记
基本上,这些就是word2vec的全部内容,当然,里面还有很多细节的地方没有说清楚,基本上,word2vec可以理解为浅层的神经网络算法,通过一个假设,即离得最近的词相关性较高,构建神经网络,理论上这种方法没啥问题,但是由于其运行时间较长,所以才有了Hierarchical Softmax和Negative Sampling来减少训练时间。
我们最后总结一下word2vec的优缺点:
优点:
- 运行速度还是较快的,尤其是用了HS和NS之后。
- 得到的词向量可以比较好的表示word-level之间的相关性。
缺点:
- 没有考虑单词顺序之间的关系。比如"我 爱 你"和"你 爱 我"学到的词向量表示是一样的,但是其实这两者不太一样。(这块的解决办法就是加入n-gram特征,详见fasttex)
- 单词无法消岐。比如"苹果"这个词,既可以表示吃的苹果,也可以表示苹果手机。
参考文献
[1]Tomas Mikolov.(2013). Distributed Representations of Words and Phrases and their Compositionality.
[2]Tomas Mikolov.(2013). Efficient Estimation of Word Representations in Vector Space.
[3]Xin Rong.(2014). word2vec Parameter Learning Explained.
[4]如何通俗理解word2vec:https://blog.csdn.net/v_JULY_v/article/details/102708459
[5]word2vec 中的数学原理详解:https://www.cnblogs.com/peghoty/p/3857839.html
词向量模型word2vector详解的更多相关文章
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- BS模式的模型结构详解
编号:1004时间:2016年4月12日16:59:17功能:BS模式的模型结构详解 URL:http://blog.csdn.net/icerock2000/article/details/4000 ...
- 词袋模型bow和词向量模型word2vec
在自然语言处理和文本分析的问题中,词袋(Bag of Words, BOW)和词向量(Word Embedding)是两种最常用的模型.更准确地说,词向量只能表征单个词,如果要表示文本,需要做一些额外 ...
- 事件驱动模型实例详解(Java篇)
或许每个软件从业者都有从学习控制台应用程序到学习可视化编程的转变过程,控制台应用程序的优点在于可以方便的练习某个语言的语法和开发习惯(如.net和java),而可视化编程的学习又可以非常方便开发出各类 ...
- (转)Linux下select, poll和epoll IO模型的详解
Linux下select, poll和epoll IO模型的详解 原文:http://blog.csdn.net/tianmohust/article/details/6677985 一).Epoll ...
- Java内存模型(JMM)详解
在Java JVM系列文章中有朋友问为什么要JVM,Java虚拟机不是已经帮我们处理好了么?同样,学习Java内存模型也有同样的问题,为什么要学习Java内存模型.它们的答案是一致的:能够让我们更好的 ...
- 词袋模型(BOW,bag of words)和词向量模型(Word Embedding)概念介绍
例句: Jane wants to go to Shenzhen. Bob wants to go to Shanghai. 一.词袋模型 将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个 ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
- Css盒模型属性详解(margin和padding)
Css盒模型属性详解(margin和padding) 大家好,我是逆战班的一名学员,今天我来给大家分享一下关于盒模型的知识! 关于盒模型的属性详解及用法 盒模型基本属性有两个:padding和marg ...
随机推荐
- [Unity] Unity 2019.1.14f 在Terrain中使用Paint Texture的方法
1.点击Terrain中的Paint Texture按钮2.将按钮下面的下拉菜单选择paint texture3.点击Edit Terrain Layers按钮T4.点击弹出菜单的Create Lay ...
- java两数相乘基础算法
下面是别人给我的代码: package com.bootdo; public class Test { public static void main(String[] args) { System. ...
- 两个看似相同,结果不同的SQL逻辑
一朋友问我的,看着挺有意思,记录一下: 表item1,里面有上面三个字段,一共10条数据,接下来有两个相似的sql语句得到了不一样的查询结果. 表数据如下: 两条SQL及查询结果: 我的理解答: S ...
- ECMAScript 6 基础
ECMAScript 6 基础 ECMAScript 6 简介 JavaScript 三大组成部分 ECMAScript DOM BOM ECMAScript 发展历史 https://develop ...
- SpringBoot安装与配置
1.环境准备 1.1.Maven安装配置 Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件. 下载Maven可执行文件 cd /usr/local ...
- iOS 真机查看沙盒目录
iExplorer 的方法试的时候设备都无法检测到,建议放弃 启用iTunes文件共享,才能够看沙盒内的文件,只需要在plist文件中添加如下信息: <key>UIFileSharingE ...
- ios shell打包脚本 gym
#! /bin/bash project_path=$() project_config=Release output_path=~/Desktop build_scheme=YKTicketsApp ...
- iOS UITableView优化
一.Cell 复用 在可见的页面会重复绘制页面,每次刷新显示都会去创建新的 Cell,非常耗费性能. 解决方案:创建一个静态变量 reuseID,防止重复创建(提高性能),使用系统的缓存池功能. s ...
- GO gRPC教程-环境安装(一)
前言 gRPC 是一个高性能.开源和通用的 RPC 框架,面向移动和 HTTP/2 设计,带来诸如双向流.流控.头部压缩.单 TCP 连接上的多复用请求等特.这些特性使得其在移动设备上表现更好,更省电 ...
- 1089 Insert or Merge (25分)
According to Wikipedia: Insertion sort iterates, consuming one input element each repetition, and gr ...