python爬虫-scrapy日志
1、scrapy日志介绍
Scrapy的日志系统是实现了对python内置的日志的封装

scrapy也使用python日志级别分类
logging.CRITICAL
logging.ERROE
logging.WARINING
logging.INFO
logging.DEBUG
2、如何在python中使用日志呢?
import logging
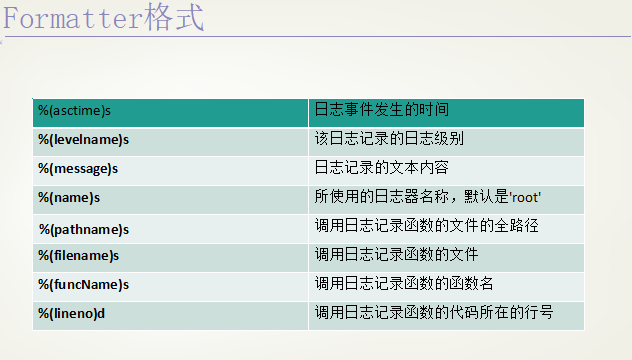
(1)日志对应的格式字符串
(2)创建一个logger
logger = logging.getLogger("%s_log" %__name__)
logger.setLevel(logging.INFO) # 设定日志等级
(3)创建一个handler,用于写入日志文件
fh = logging.FileHandler("test.log", mode="a")
fh.setLevel(logging.WARNING)
(4)定义handler的输出格式
formatter = logging.Formatter("%(asctime)s - %(filename)s [line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
(5)将对应的handler添加在logger对象中
logger.addHandle(fh)
(6)正常使用logger.log、logger.debug、logger.info、logger.warning、logger.error、logger.critical
logger.log(level, msg, *args, **kwargs)
logger.debug(msg, *args, **kwargs)
(7)还有一种简单地使用日志的方法,没有上面那么繁琐:
logging.baseConfig()参数信息如下:

import logging logging.baseConfig(filename="", filemode="", format="", datefmt="", stylefmt="", style="", level="", stream="") logging.info(msg, *args, **kw)
loggin.debug(msg, *args, **kw)
logging.warning(msg, *args, **kw)
3、如何在scrapy中配置日志呢?
在scrapy中使用日志很简单,只需在settings.py中设置LOG_FILE和LOG_LEVEL两个配置项就可以了
# 一般在使用时只会设置LOG_FILE和LOG_LEVEL两个配置项,其他配置项使用默认值 # 指定日志的输出文件
LOG_FILE
# 是否使用日志,默认为True
LOG_ENABLED
# 日志使用的编码,默认为UTF-8
LOG_ENCODING
# 日志级别,如果设置了,那么高于该级别的就会输入到指定文件中
LOG_LEVEL
# 设置日志的输出格式
LOG_FORMAT
# 设置日志的日期输出格式
LOG_DATEFORMAT
# 设置标准输出是否重定向到日志文件中,默认为False,如果设置为True,那么print("hello")就会被重定向到日志文件中
LOG_STDOUT
# 如果设置为True,只会输出根路径,不会输出组件,默认为FALSE
LOG_SHORT_NAMES
一般配置:
import logging LOG_FILE="scrapy.log" # LOG_LEVEL=logging.DEBUG|logging.INFO|logging.WARNING|logging.ERROR|logging.CRITICAL LOG_LEVEL="DEBUG"
4、如何在scrapy的组件中使用自输出日志呢?
我们在控制台下跑爬虫时出现的一系列输出都是有scrapy的日志系统在各组件中自行配置的,我们也可以在我们编写的组件中,自己输出一些日志,用于检测
控制台中输出的日志:
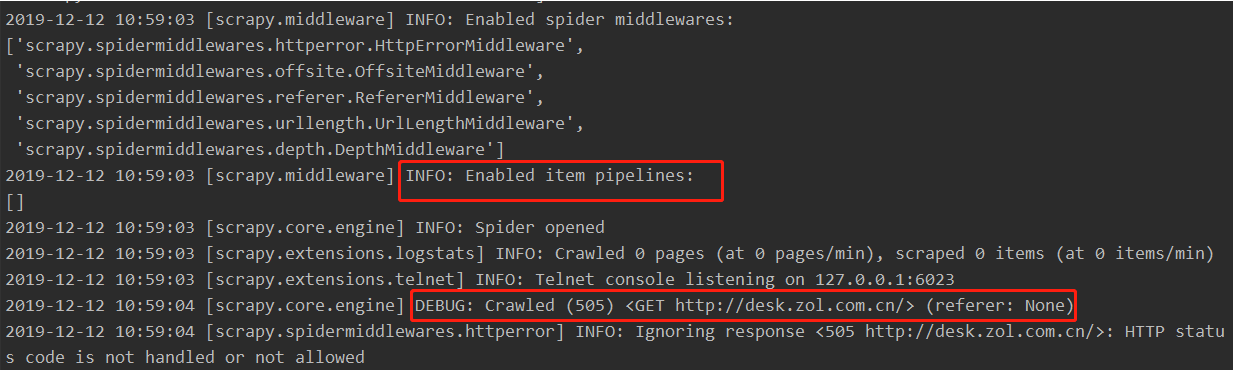
下面是从Spider类中抽出来的一个属性,在自构造的爬虫类中self.logger返回一个<class 'LoggerAdapter'>对象,而这个对象中有log、debgu、info等方法,所以我们可以在爬虫组件中使用self.logger.log()、self.logger.debug()等来输出日志,而在其它组件中,会将spider作为参数传进其他组件对象的方法中,所以我们也可以在其它组件中使用spider.logger.log()、spider.logger.debug()等在输出日志。
@property
def logger(self):
logger = logging.getLogger(self.name)
return logging.LoggerAdapter(logger, {'spider': self})
python爬虫-scrapy日志的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 安装python爬虫scrapy踩过的那些坑和编程外的思考
这些天应朋友的要求抓取某个论坛帖子的信息,网上搜索了一下开源的爬虫资料,看了许多对于开源爬虫的比较发现开源爬虫scrapy比较好用.但是以前一直用的java和php,对python不熟悉,于是花一天时 ...
- Python 爬虫-Scrapy爬虫框架
2017-07-29 17:50:29 Scrapy是一个快速功能强大的网络爬虫框架. Scrapy不是一个函数功能库,而是一个爬虫框架.爬虫框架是实现爬虫功能的一个软件结构和功能组件集合.爬虫框架是 ...
- python爬虫scrapy学习之篇二
继上篇<python之urllib2简单解析HTML页面>之后学习使用Python比较有名的爬虫scrapy.网上搜到两篇相应的文档,一篇是较早版本的中文文档Scrapy 0.24 文档, ...
随机推荐
- UI自动化(selenium+python)之元素定位的三种等待方式
前言 在UI自动化过程中,常遇到元素未找到,代码报错的情况.这种情况下,需要用等待wait. 在selenium中可以用到三种等待方式即sleep,implicitly_wait,WebDriverW ...
- PyTorch基础——预测共享单车的使用量
预处理实验数据 读取数据 下载数据 网盘链接:https://pan.baidu.com/s/1n_FtZjAswWR9rfuI6GtDhA 提取码:y4fb #导入需要使用的库 import num ...
- java作业-----方法重载
满足方法重载的条件:1.方法名相同 2.参数类型不同,参数个数不同,参数类型的顺序不同. 同时,方法的返回值不作为方法重载的判断条件.
- javascript 实现最简单的阶乘!
<script type='text/javascript'> window.onload = get(5); function get(n){ document.w ...
- tarjan通俗易懂题
洛谷2661 https://www.luogu.org/problemnew/show/P2661 分析:求缩点后成环中,环大小最小的size #include<bits/stdc++.h&g ...
- [LC] 295. Find Median from Data Stream
Median is the middle value in an ordered integer list. If the size of the list is even, there is no ...
- absorb|state|
ADJ-GRADED 极感兴趣的:专心的:全神贯注的If you are absorbed in something or someone, you are very interested in th ...
- MYSQL语句中的explain
1.使用mysql explain的原因 在我们程序员的日常写代码中,有时候会发现我们写的sql语句运行的特别慢,导致响应时间特别长,这种情况在高并发的情况下,我们的网站会直接崩溃,为什么双十一的淘宝 ...
- (转)假如没有OI By Vani
假如没有OI ...
- in与exist , not in与not exist 的区别
in和exists in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询.一直以来认为exists比in效率高的说法是不准确的. ...