Hadoop组件详解(随缘摸虾)
1.1. Hadoop组成:
Hadoop = hdfs(存储) + mapreduce(计算) + yarn(资源协调) + common(工具包) + ozone(对象存储) +
submarine(机器学习库)
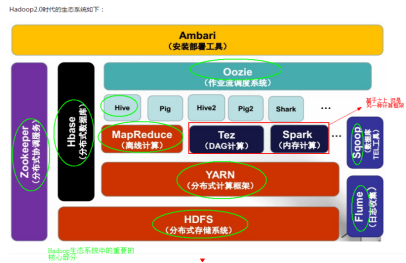
hadoop生态圈:
1.2. 分布式存储系统HDFS (Hadoop Distributed File System)
概括: 它是一个分布式存储系统, 提供高可靠性(high reliablity), 高扩展性(high scalability)和高吞吐率(High throughput)的数据存储服务。
应用: 主要用于解决大数据的存储问题。
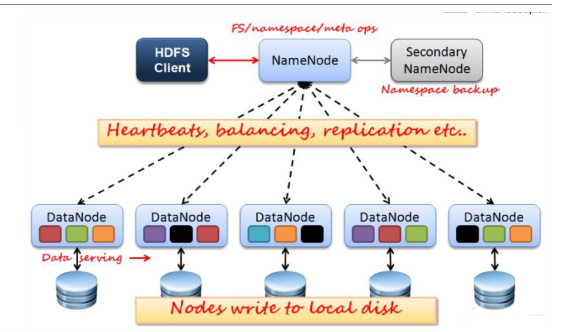
HDFS架构图:
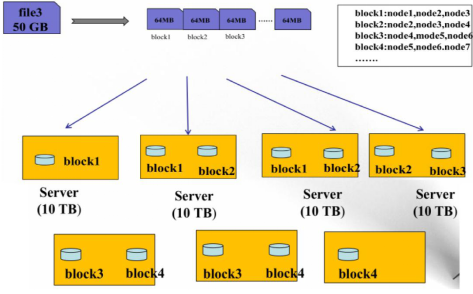
HDFS 数据存储单元(block)
文件被切分成固定大小的数据块block
(1). 默认数据块大小为128MB(hadoop 3.x为256MB),可自定义配置
(2). 若文件大小不到128MB, 则单独存储成一个block
文件存储方式
(1). 按大小被切分成若干个block, 存储到不同节点上
(2). 默认情况下每个block都有3个副本
Block大小和副本数通过Client端上传文件时设置, 文件上传成功后副本数可以变更, Block Size 不可变更
hdfs存储模型: 字节
- 文件线性切割成块(Block): 偏移量 offset (byte)
- Block 分散存储在集群节点中
- 单一文件Block大小一致, 文件与文件可以不一致
- Block可以设置副本数, 副本分散在不同节点中(副本数不要超过节点数量)
- 文件上传可以设置Block大小和副本数
- 已上传的文件Block副本数可以调整, 大小不变
- 只支持一次写入多次读取, 同一时刻只有一个写入者可以append追缴数据
名称节点NameNode(NN)
主要功能:
- 接受客户端的读/写服务
- 收集DataNode回报的Block列表信息
特性: 基于内存存储, 不会和磁盘发生交换
- 只存在内存中
- 持久化
NameNode保存metadata(元数据)信息
- 文件ownership(归属) & permission(权限)
- 文件大小, 时间
- Block列表: Block偏移量, 位置信息(不会持久化)
- Block 保存在哪个DataNode, 信息就由该DataNode启动时上报, 不保存在磁盘
NameNode持久化
- NameNode的metadate信息在启动后会叫再到内存
- metadata存储到磁盘的文件名为 “fsimage”
- Block的位置信息不会保存到 fsimage
- edits 记录对metadata的操作日志
fsimage保存了最新的metadata检查点, 类似snapshot.
editslog 保存自最新检查点后的原信息变化, 从最新检查点后, hadoop将对每个文件的操作都保存在edits中。客户端修改文件的时候, 先写到editlog, 成功后才更新内存中的metadata信息。
so: Metadata = fsimage + editslog
数据节点DataNode(DN)
- 本地磁盘目录存储数据(Block), 文件形式
- 同时存储Block的元数据(md5值)信息文件
- 启动DN进程的时候会向NameNode汇报block信息
- 通过向NN发送心跳保持与其联系(3秒一次), 如果NN 10分钟没有收到DN的心跳, 则认为其已经失效, 并拷贝其上的block到其他DN
第二个名称节点SecondaryNameNode(SNN) [hadoop2.x 被standby namenode替代]

合并流程:
首先是NN中的Fsimage和edits文件通过网络拷贝, 到达SNN服务器中, 拷贝的同时, 用户在实时操作数据, 那么NN中就会从新生成一个edits来记录用户的操作, 而另一边的SNN将拷贝过来的edits和fsimage进行合并, 合并之后替换NN中的fsimage。之后NN根据fsimage进行操作(每隔一段时间进行合并替换, 循环)。 当然新的edits与合并之后传输过来的fsimage会在下一次时间内又进行合并。
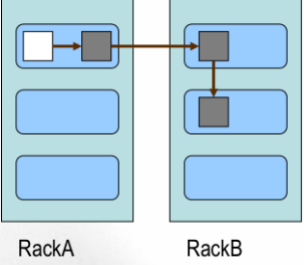
Block 的副本放置策略
- 第一个副本: 放置在上传文件的DN; 如果是集群外提交, 则随机挑选一台磁盘不太满, CPU不太忙的节点。
- 第二个副本: 放置在于第一个副本不同的机架的节点上。
- 第三个副本: 与第二个副本相同机架的不同节点。
- 更多副本: 随机节点
集群内提交:
HDFS读写流程
写文件流程图

- 客户端Client:
- 切分文件Block
- 按 Block 线性和NN获取DN列表(副本数)
- 验证DN列表后以更小的单位(packet)流式传输数据(需确保各节点可两两通信)
- Block传输结束后:
- DN向NN汇报Block信息
- DN向Client汇报完成
- Client向NN汇报完成
- 获取下一个Block存放的DN列表 ...............
- 最终Client汇报完成
- NN会在写流程更新文件状态
读文件流程图

- 客户端Client:
- 和 NN 获取一部分Block副本位置列表
- 在Block副本列表中按距离择优选取
- 和DN获取Block, 最终合并为一个文件
HDFS文件权限
与Linux文件权限类似
- r: read; w: write; x: execute
- 权限x对于文件忽略, 对于文件夹表示是否允许访问其内容
如果Linux系统用户xxx使用hadoop命令创建一个文件, 那么这个文件在HDFS中owner就是xxx。
HDFS的权限目的:组织好人做错事, 而不是阻止坏人做坏事。
HDFS相信, 你告诉我你是谁, 我就认为你是谁。
安全模式
- namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
- 一旦在内存中成功建立文件系统元数据的映射,创建一个空的编辑日志。
- 此刻namenode运行在安全模式。即namenode的文件系统对于客服端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败)。
- 在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的, 在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
- 当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中。
HDFS的优缺点
优点:
- 高容错性
- 数据自动保存多个副本
- 副本丢失后, 自动恢复
- 适合批处理
- 移动计算而非数据
- 数据位置暴露给计算框架(Block 偏移量)
- 适合大数据处理
- TB, 甚至PB级数据
- 百万规模以上的文件数量
- 10K+ 节点
- 可构建在廉价机器上
- 通过多副本提高可靠性
- 提供了容错和恢复机制
缺点
低延迟
- 支持秒级别反应, 不支持毫秒级
- 延迟与高吞吐率问题(吞吐量大但有限制于其延迟)
小文件存储
- 占用NameN大量内存
- 寻道时间超过读取时间
并发写入, 文件随机修改
- 一个文件只能有一个写者
- 仅支持append
1.3. 分布式计算框架MapReduce
MapReduce 是一个分布式计算框架(计算向数据移动), 具有易于编程,高容错性和高扩展性等优点, 运用于大规模数据集(TB, PB级别)的并行运算。
MapReduce = Map(映射) + Reduce(规约)
宏观上的流程: 输入(key, value) 数据集 --> 通过MapTask映射成一个中间数据集(key, value) --> reduce
"相同"的key为一组(打引号是因为这个相同是可以通过修改比较器(Comparator)方法自己定义的), 调用一次reduce方法, 方法内迭代这一组数据进行计算。
分布式计算
分布式计算将应用分解成许多小块, 分配给多台计算机节点进行处理, 以此来节约整体计算时间并提高计算效率。
移动计算(不移动数据)
将计算程序移动到具有数据的计算机节点之上进行计算操作, 从而减少数据通过网络IO拉取的时间。
MapReduce计算流程
Mapper
Mapper负责"分", 它把复杂的任务分解为若干个"简单的任务" 执行。
“简单的任务" 的定义:
- 数据或计算规模相对于原任务大大缩小;
- 就近计算, 即会被分配到存放了所需数据的节点进行计算
- 这些小任务可以并行计算, 彼此之间没有依赖关系
caution:Split只是一个逻辑上的块, 并不是物理上存在的, 它只存在于mapreduce任务的计算过程当中。
Map的数目是由split的个数决定的, 而split的个数是由几个因素决定, 但通常情况下, split个数和block个数一样
Reduce
Reduce的任务是对map阶段的结果进行"汇总"并输出。
ReduceTask默认个数缺省值为1, 用户也可以修改。
Reduce任务:
- Reduce 中可以包含不同的Key
相同的Key汇聚到一个Reduce中
相同的“Key” 为一组, 调用一次reduce方法
Shuffle(洗牌)
Shuffle是mapper和reducer中间的一个步骤, 它包括了:
Map 端:
- 分区
- 排序
- 合并
Reduce端:
- 拉取数据
- 排序
- 合并
1.4. 分布式资源管理框架YARN(Yet Another Resource Negotiator)
YARN负责集群资源的管理和调度, 使其他计算框架如Spark, Storm 和Flink可以在其上运行(hadoop2.0 新引入)。
Hadoop1.x架构
JobTracker
- 核心, 主
- 调度所有的作业
- 监控整个集群的资源负载
TaskTracker
- 从, 自身节点资源管理
- 和JobTracker心跳,汇报资源, 获取Task在本机上运行
Client
- 规划作业计算分部
- 提交作业资源(jar)到HDFS
- 最终提交作业到JobTracker
弊端:
- JobTracker: 负载过重, 单点故障就gg
- 资源管理与计算调度胡耦合度很高, 其他计算框架需要重复实现资源管理
- 不同框架对资源不能全局管理
Hadoop2.x架构
YARN:
核心思想: 将MRv1中JobTracker的资源管理和任务调度两个功能分开, 分别有ResourceManager和ApplicationMaster进程实现
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务, 比如任务调度、任务监控和容错等
YARN的引入, 使得多个计算框架可运行在一个集群中
每个应用程序对应一个ApplicationMaster
目前有多个计算框架可以运行在YARN上, 比如Mapreduce, Spark, Storm等
MRv2架构图:
YARN: 解耦资源与计算
- ResourceManager
- 主, 核心
- 集群节点资源管理
- NodeManager
- 与RM汇报资源
- 管理Container生命周期
- 计算框架中的角色都以Container表示
- Container: [节点 NM, CPU, MEM,I/O大小,启动命令]
- 默认NodeManager启动线程监控Cointainer大小, 超出申请资源额度, 就kill
- 支持Linux内核的Cgroup
- ResourceManager
MR:
- MR-ApplicationMaster(AM)-Container
- 作业为单位, 避免单点故障, 负载到不同的节点
- 创建Task需要和RM申请资源(Container) -Task-Conatiner
- MR-ApplicationMaster(AM)-Container
Client:
- Rm-Client: 请求资源创建 AM
- AM-Client: 与AM交互
概括:
Hadoop2.x 将MapReduce作业直接运行在YARN上而不是由JobTracker和TaskTracker构建的MRv1系统中。
- 基本功能模块
- YARN: 负责资源管理和调度
- ApplicationMaster: 负责任务切分、任务调度、任务监控和容错等
- NodeManager: 负责管理本节点的资源和任务执行情况
- 每个MapReduce作业对应一个MRAppMaster
- MRAppMaster 任务调度
- YARN将资源分配给MRAppMaster
- MRAppMaster进一步将资源分配给内部的任务
- MRAppMaster 容错
- applicationMaster失败后, 由YARN重新启动
- task任务失败后, MRAppMaster 重新申请资源, 然后启动
Hadoop组件详解(随缘摸虾)的更多相关文章
- hadoop框架详解
Hadoop框架详解 Hadoop项目主要包括以下四个模块 ◆ Hadoop Common: 为其他Hadoop模块提供基础设施 ◆ Hadoop HDFS: 一个高可靠.高吞吐量的分布式文件系统 ◆ ...
- Hadoop Pipeline详解[摘抄]
最近使用公司内部的一个框架写map reduce发现没有封装hadoop streaming这些东西,查了下pipeline相关的东西 Hadoop Pipeline详解 20. Aug / had ...
- Android中Intent组件详解
Intent是不同组件之间相互通讯的纽带,封装了不同组件之间通讯的条件.Intent本身是定义为一个类别(Class),一个Intent对象表达一个目的(Goal)或期望(Expectation),叙 ...
- Android笔记——四大组件详解与总结
android四大组件分别为activity.service.content provider.broadcast receiver. ------------------------------- ...
- vue.js基础知识篇(6):组件详解
第11章:组件详解 组件是Vue.js最推崇也最强大的功能之一,核心目标是可重用性. 我们把组件代码按照template.style.script的拆分方式,放置到对应的.vue文件中. 1.注册 V ...
- Hadoop Streaming详解
一: Hadoop Streaming详解 1.Streaming的作用 Hadoop Streaming框架,最大的好处是,让任何语言编写的map, reduce程序能够在hadoop集群上运行:m ...
- Echars 6大公共组件详解
Echars 六大组件详解 : title tooltip toolbox legend dataZoom visualMap 一.title标题详解 myTitleStyle = { color ...
- Angular6 学习笔记——组件详解之组件通讯
angular6.x系列的学习笔记记录,仍在不断完善中,学习地址: https://www.angular.cn/guide/template-syntax http://www.ngfans.net ...
- Angular6 学习笔记——组件详解之模板语法
angular6.x系列的学习笔记记录,仍在不断完善中,学习地址: https://www.angular.cn/guide/template-syntax http://www.ngfans.net ...
随机推荐
- VUE 使用axios请求第三方接口数据跨域问题解决
VUE是基于node.js,所以解决跨域问题,设置一下反向代理即可. 我这里要调用的第三方接口地址为 http://v.juhe.cn/toutiao/index?type=top&key=1 ...
- os期末复习
登记之后会发生两个变化:读者数增加(v操作).座位数减少(p操作) 注销之后会发生的变化:读者数减少(p操作).座位数增加(v操作) 必须要清楚释放的是甚麽,以及申请的是甚麽资源(在具体的题目当中) ...
- C语言数组成绩排序
#include<stdio.h> #define N 10 int main() { int s,i,j,tmp; int a[10]={78,56,38,99,81,86,39,100 ...
- IOS pin约束问题 存在间隙
今天在为自己的view添加约束 对比以前添加的约束时,发现有有两层淡红色线框一条实线和一条虚线,而以前一个demo中添加的则只有一个蓝色实线框. 今天添加的约束如图1所示: 图1 而以前添加约束如图2 ...
- Lesson 2 Spare that spider
How much of each year do spiders killing insects? Why, you may wonder, should spiders be our friends ...
- Matplotlib 基本概念
章节 Matplotlib 安装 Matplotlib 入门 Matplotlib 基本概念 Matplotlib 图形绘制 Matplotlib 多个图形 Matplotlib 其他类型图形 Mat ...
- 怎样快速高效的定义Django的序列化器
1.使用Serializer方法自己创建一个序列化器 先写一个简单的例子 class BookInfoSerializer(serializers.Serializer): ""& ...
- 开发自己的 chart【转】
Kubernetes 给我们提供了大量官方 chart,不过要部署微服务应用,还是需要开发自己的 chart,下面就来实践这个主题. 创建 chart 执行 helm create mychart 的 ...
- SpringIOC初始化过程源码跟踪及学习
Spring版本 4.3.2,ssm框架 代码过宽,可以shift + 鼠标滚轮 左右滑动查看 web.xml <!--配置获取项目的根路径,java类中使用System.getProperty ...
- Android实现三级联动下拉框下拉列表spinner
原文出处:http://www.cnblogs.com/zjjne/archive/2013/10/03/3350107.html 主要实现办法:动态加载各级下拉值的适配器 在监听本级下拉框,当本级下 ...