python-day4爬虫基础之正则表达式
正则表达式:(字符串匹配)
- 使用单个字符串来描述匹配一系列符合某个句法规则的字符串
- 是对字符串操作的一种逻辑公式
- 应用场景:处理文本和数据
- 正则表达式过程:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;否则,匹配失败。
首先需要导入re这个模块 import re
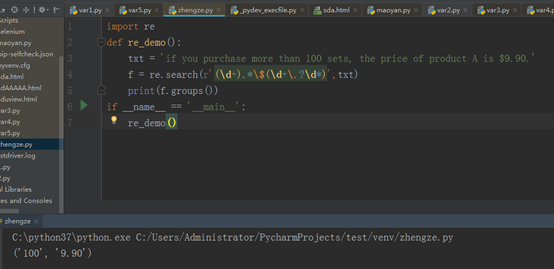
\d表示数字,+表示匹配1到多个数字
.表示匹配任意的字符
*表示0到多个所有的字符
\$ 将美元字符转义一下
\. 将点.转义 ?表示匹配0个或者1个小数点 \d 表示数字 *表示匹配0到多个数字
groups是一个方法,他可以将正则表达式里相匹配的项打印出来
re.search:搜索字符串,找到匹配的第一个字符串(搜索字符串任意位置的匹配)
re.match:从字符串开始开始匹配(只从字符串的起始位置开始匹配)

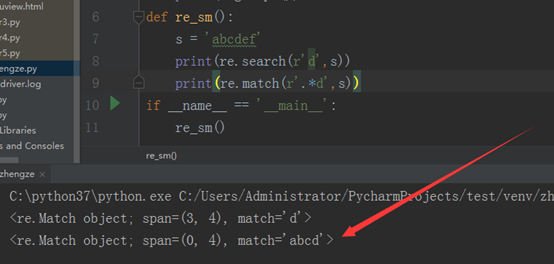
match是匹配字符串开头为‘d’的字符串,而我们给出的字符串是‘abcdef’,开头为‘a’,显然是不匹配的,所有最终的运行结果是‘None’
如果改正的话,我们可以从前边加上‘.*’,因为‘.’代表匹配任意的字符,‘*’代表0到多个字符,也就是在‘d’的前边可以有0到多个任意字符,这就可以匹配了,如下图所示:
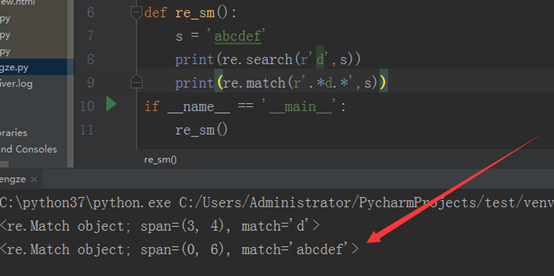
从图中可以看出,结果是abcd,后边的ef没匹配出来,同理,我们在后边也加上‘.*’,就可以得到‘abcdef’,如下图所示:
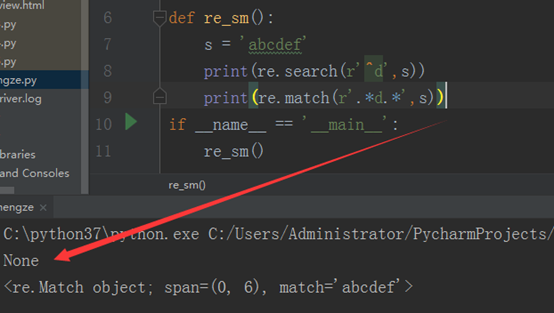
还有一种,就是我们在search那的‘d’前边加‘^’,他的意思就是严格搜索以‘d’为开头的字符串,这样的话,运行结果就不得而知了,如下:
split:使用正则表达式来分割字符串
先看程序:
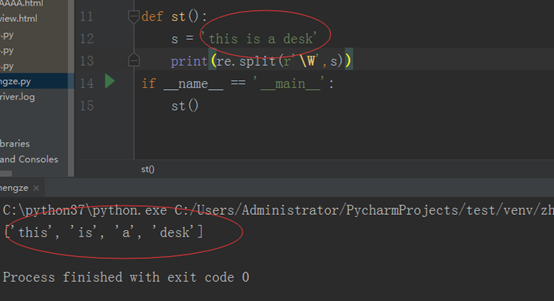
\W:任意的非字母,只要不是字母,就将其作为界限,把其分割出来的。
findall:根据正则表达式从左向右搜索匹配项,返回匹配的字符串列表。Search,是搜索到匹配的第一个,他就停下来;而findall,搜索出所有的匹配项,返回的是所有匹配项的字符串列表。
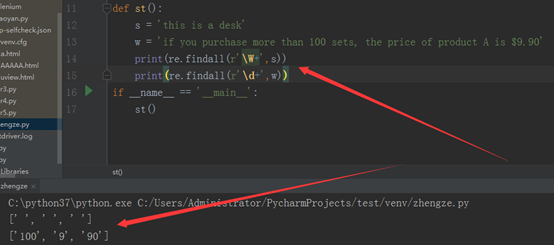
第一个print:\w+,匹配1到多个字符,等匹配完this,碰到空格,还会继续往下匹配,直到最后。
第二个print:\d+,匹配匹配1到多个数字,之所以没有打印出9.90,而是分开打印的,是因为碰到小数点以后,就继续往下寻找,自动与前一个匹配结果分开了。
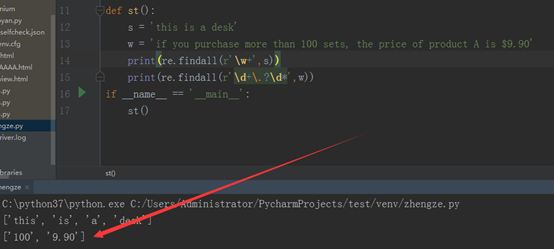
那怎么才能打印出9.90呢,我们先加一个‘\.’ , 意思是匹配小数点,然后小数点在文本中可能有,也可能没有,所以,再加一个‘?’,小数点后边可能还有数字,所以再加一个\d,再加一个*,表示可能有0个数字,也可能有多个数字。如下所示:
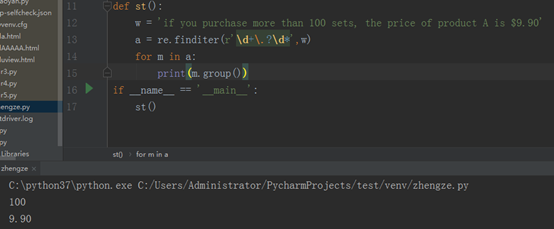
finditer:根据正则表达式从左到右搜索匹配项,返回一个迭代器迭代返回 ,迭代器里的每一个元素都是一个matchobject,你可以对matchobject进行一个操作,如下程序:
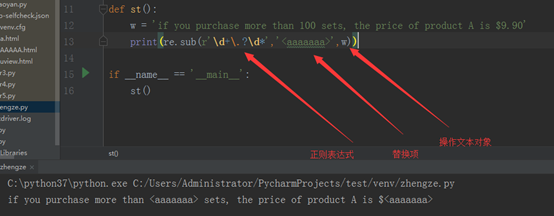
sub:字符串替换,里边有三个参数,如下:
pattern:正则表达式
repl:替换项,字符串或函数
string:待处理的字符串
程序如下所示:
以上就是今天所学,因为水平有限,可能有些地方的理解不是特别正确,还请多多指正,大家共同学习,一起进步。谢谢。
python-day4爬虫基础之正则表达式的更多相关文章
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 自学Python六 爬虫基础必不可少的正则
要想做爬虫,不可避免的要用到正则表达式,如果是简单的字符串处理,类似于split,substring等等就足够了,可是涉及到比较复杂的匹配,当然是正则的天下,不过正则好像好烦人的样子,那么如何做呢,熟 ...
- Python BeautifulSoup4 爬虫基础、多线程学习
针对 崔庆才老师 的 https://ssr1.scrape.center 的爬虫基础练习.Threading多线程库.Time库.json库.BeautifulSoup4 爬虫库.py基本语法
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- Python扫描器-爬虫基础
0x1.基础框架原理 1.1.爬虫基础 爬虫程序主要原理就是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 1.1.基础原理 1.发起HTTP请求 2 ...
- Python爬虫基础之正则表达式
一.Python正则表达式的基本使用 Python 3 使用re模块可以实现大部分的正则表达式情况. 1.re.compile(pattern, flags=0) re.compile构建匹配规则并返 ...
- Python归纳 | 爬虫基础知识
1. urllib模块库 Urllib是python内置的HTTP请求库,urllib标准库一共包含以下子包: urllib.error 由urllib.request引发的异常类 urllib.pa ...
- python开发模块基础:正则表达式
一,正则表达式 1.字符组:[0-9][a-z][A-Z] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示字符分为很多类,比如数字.字母.标点等等.假如你现在要求一个位置&q ...
- python网络爬虫之三re正则表达式模块
""" re正则表达式,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的 一些特定字符,及这些特定字符的组合,组成一个"规则字符串",然后用 ...
- 自学Python四 爬虫基础知识储备
首先,推荐两个关于python爬虫不错的博客:Python爬虫入门教程专栏 和 Python爬虫学习系列教程 .写的都非常不错,我学习到了很多东西!在此,我就我看到的学到的进行总结一下! 爬虫就是 ...
随机推荐
- 修改电脑IP地址和MAC地址
一.修改IP地址: 电脑右下角:上网的图标,点击右键,打开“网络和共享中心”, 点击“本地连接”,打开的窗口点击“属性”, 打开新窗口,找到“IPv4”,点击“属性”, 打开新窗口,修改ip,保存,关 ...
- js面试之数组的几个不low操作
1.扁平化n维数组 1.终极篇 [1,[2,3]].flat(2) //[1, 2, 3] [1,[2,3,[4,5]]].flat(3) //[1, 2, 3, 4, 5] [1,[2,3,[4,5 ...
- ESP8266 SDK开发: 外设篇-串口
串口分布 串口切换说明 1.默认所有的数据都使用串口0输出 官方提供了函数可以选择printf利用哪一个串口输出 配置printf使用串口1打印输出,波特率115200 (注:这样配置对于调试程序很有 ...
- 基于Ambari的WebUI部署HBase服务
基于Ambari的WebUI部署HBase服务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.部署Ambari服务 博主推荐阅读: https://www.cnblogs.co ...
- 51nod 1430:奇偶游戏 博弈
1430 奇偶游戏 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 160 难度:6级算法题 收藏 关注 有n个城市,第i个城市有ai个人.Daene ...
- MFC OCX 控件事件的添加和处理
1.控件的事件一般都是由对外的接口引发到,这里定一个接口先: 该接口有一个字符串参数,表示调用者将传入一个字符串,传进来后,我们将取得字符串的长度. 2.添加事件: 事件应该是属于窗口的,所以在Ctr ...
- 热衷外卖的韩国与中国,外卖APP最大的区别有哪些?
额,一向"自大"的韩国人总是想处处争先.就连在外卖方面,韩国人也说自己的"外卖民族",对外卖有着一种"痴迷".事实上,早在20多年前韩国外卖 ...
- MyBatis的初始化过程。
对于任何框架而言,在使用前都要进行一系列的初始化,MyBatis也不例外.本章将通过以下几点详细介绍MyBatis的初始化过程. 1.MyBatis的初始化做了什么 2. MyBatis基于XML配置 ...
- 对OpenSSL心脏出血漏洞的试验
1.安装OpenSSL环境 sudo apt-get install openssl sudo pip install pyopenssl(中间会提示ffi.h 没有那个文件或目录,sudo apt- ...
- SQL约束攻击
本文转载自https://blog.csdn.net/kkr3584/article/details/69223010 目前值得高兴的是,开发者在建立网站时,已经开始关注安全问题了--几乎每个开发者都 ...