1. GC标记-清除算法(Mark Sweep GC)
- 世界上第一个GC算法,由 JohnMcCarthy 在1960年发布。
标记-清除算法由标记阶段和清除阶段构成。
标记阶段就是把所有的活动对象都做上标记的阶段。
- 标记阶段就是“遍历对象并标记”的处理过程。
- 标记阶段经常用到深度优先搜索。
mark_pahase(){
for(r : $roots)
mark(*r)
} mark(obj){
if(obj.mark == FALSE)
obj.mark = TRUE
for(child : children(obj))
mark(*child)
}
清除阶段就是把那些没有标记的对象,也就是非活动对象回收的阶段。
- 清除阶段collector会遍历整个堆,回收没有打上标记的对象(即垃圾)。
- 内存的合并操作也是在清除阶段进行的。
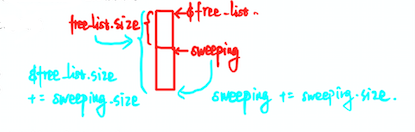
sweep_phase(){
sweeping = $heap_start
while(sweeping < $heap_end)
if(sweeping.mark == TRUE)
sweeping.mark = FALSE
else
sweeping.next = $free_list
$free_list = sweeping
sweeping += sweeping.size
}
1. 分配
分配指将回收的内存空间进行再利用。
-> 伪代码描述内存分配 new_obj(size){
chunk = pickup_chunk(size, $free_list)
if(chunk != NULL)
return chunk
else
allocation_fail() # 大招,销毁并释放全部空间
}
2. 合并
合并指将连续的小分块连在一起形成一个大分块
-> 伪代码描述合并操作 sweep_phase() {
sweeping = $heap_start
while(sweeping < $heap_end)
if(sweeping.mark == TRUE)
sweeping.mark = FALSE
else
if(sweeping == $free_list + $free_list.size)
$free_list.size += sweeping.size
else
sweeping.next = $free_list
$free_list = sweeping
sweeping += sweeping.size
}

优点
- 实现简单
- 与保守式GC算法兼容
缺点
碎片化(fragmentation)
- 使用过程中会逐渐产生被细化的分块
分配速度
- 分块不连续,每次分配都必须遍历空闲链表,以便找到足够大的分块。
- 最糟的情况就是每次分配都要遍历全部空闲链表
与写时复制技术(copy-on-write)不兼容
- 写时复制技术在重写时要将共享空间数据复制为自己的私有空间数据后,再对私有空间数据进行重写。
- 而标记-清除算法需要频繁的设置所有活动对象的头的标志位,这样就会频繁发生本不应该发生的复制,压迫到内存空间。
为了解决分配速度的问题, 人们提出了两种方法
使用多个空闲链表(multiple free-list)
类似于建立索引的方法。
为了防止空闲链表(也就是索引)的数组过大的问题,通常会给分块大小设定一个上限。
大于这个上限的按照一个空闲链表处理。
- ex.
- 设置上限为100
- 那么准备1~100及大于等于101个字的100个空闲链表就可以了。
-> 伪代码描述使用多个空闲链表的内存分配 new_obj(size){
index = size / (WORD_LENGTH / BYTE_LENGTH)
if(index <= 100)
if($free_list[index] != NULL)
chunk = $free_list[index]
return chunk
else
chunk = pickup_chunk(size, $free_list[101])
if(chunk != NULL)
return chunk allocation_fail() # 大招,销毁并释放全部空间
}
-> 伪代码描述使用多个空闲链表的内存合并 sweep_phase() {
for(i : 2...101)
$free_list[i] = NULL sweeping = $heap_start while(sweeping < $heap_end)
if(sweeping.mark == TRUE)
sweeping.mark = FALSE
else:
index = size / (WROD_LENGTH / BYTE_LENGTH)
if(index<=100)
sweeping.next = $free_list[index]
$free_list[index] = sweeping
else
sweeping.next = $free_list[101]
$free_list[101] = sweeping
sweeping += sweeping.size
}
BiBOP(Big Bag Of Pages)法
- BiBOP法是指将大小相近的对象整理成固定大小的块进行管理的做法
- 对此我们可以把堆分割成固定大小的块,让每个块只能配置同样大小的对象。
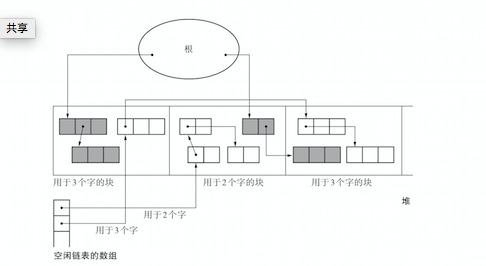 

缺点
BiBOP并不能完全消除碎片化。可能出现某一个块中活动对象过少的问题。比如在全部用于2个字的块中,只有一个活动对象
BiBOP法原本是为了消除碎片化,提高堆的使用效率而采用的方法。
但像上面这样,在多个块中分散残留着同样大小的对象,反而会降低堆的使用效率。
为了解决与写时复制不兼容的问题,则采取位图标记的方法
位图标记
位图标记的方法就是只收集各个对象的标志位并表格化,不跟对象一起管理。在标记的时候,不在对象的头里标记,而是在这个表格中的标记。
像这样集合了用于标记的位的表格称为“位图表格”。
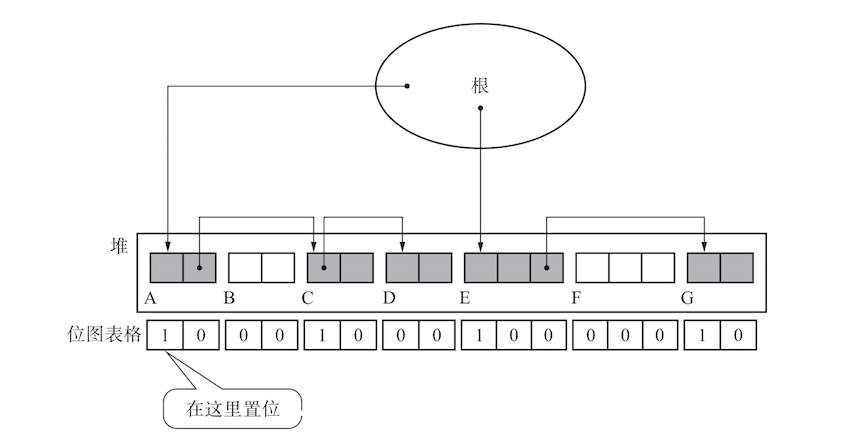 
优点
- 与写时复制技术兼容
- 清除操作更高效
注意
- 有多个堆的话,一班会为每个堆都准备一个位图表格
延迟清除法(Lazy Sweep)
延时清除法是缩减因清除操作而导致的mutator最大暂停时间的方法。在标记操作结束后,不立即进行清除操作。
-> 伪代码描述延时清除法中的分配操作
new_obj(size){
chunk = lazy_sweep(size)
if(chunk != NULL)
reutrn chunk
make_phase()
chunk = lazy_sweep(size)
if(chunk != NULL)
return chunk
allocation_fail()
}
lazy_sweep(size){
while($sweeping < $heap_end)
if($sweeping.mark == TRUE)
$sweeping.mark == FALSE
else if($sweeping.size >= size)
chunk = $sweeping
$sweeping += $sweeping.size
return chunk
$sweeping += $sweeping.size
$sweeping = $heap_start
return NULL
}
- lazy_sweep() 函数会一直遍历堆,知道找到大于等于所申请大小的分块为止。
- 在找到合适的分块时会将其返回。
- 但是在这里$sweeping 变量时全局变量。也就是说遍历的开始为止位于上一次清除操作中发现的分块的右边。
- 当lazy_sweep()函数遍历到堆的最后都没有找到分块时,会返回NULL。
- 因为延时清除法不是一下遍历整个堆,它只在分配时执行必要的遍历,所以可以压缩因清除操作而导致的mutator的暂停是时间。这就是“延时”清除操作的意思。
缺点
延时清除的效果是不均衡的
如图:
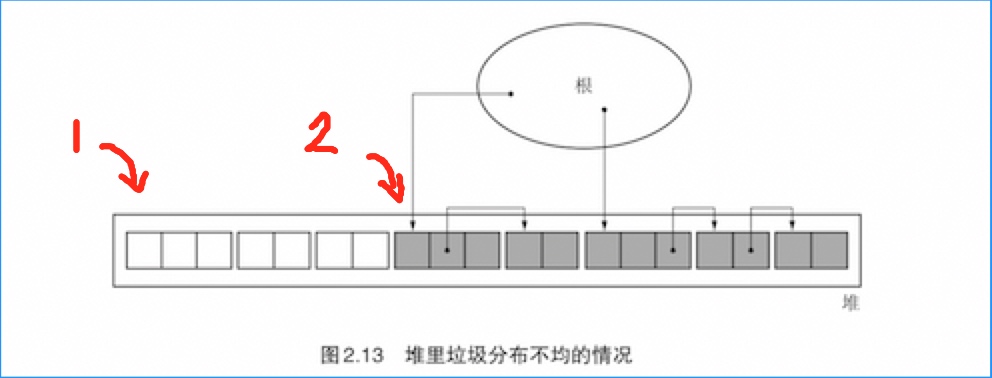 

- 如果垃圾和活动对象在堆中的分布都变成连续的,那么程序在垃圾部分(1标示的位置)能马上获得分块。而一旦程序进入活动对象周围(2标示的位置),就怎么都无法获得分块了。这样就增加了mutator的暂停时间。
1. GC标记-清除算法(Mark Sweep GC)的更多相关文章
- 《垃圾回收的算法与实现》——GC标记-清除算法
基本算法 标记-清除算法由 ==标记阶段== 和 ==清除阶段== 构成. 标记即将所有活动的对象打上标记. 清除即将那些没有标记的对象进行回收. 标记与清除 遍历GC root引用,递归标记(设置对 ...
- Java GC 标记/清除算法
1) 标记/清除算法是怎么来的? 我们在程序运行期间如果想进行垃圾回收,就必须让GC线程与程序当中的线程互相配合,才能在不影响程序运行的前提下,顺利的将垃圾进行回收. 为了达到这个目的,标记/清除算法 ...
- Mark Sweep GC
目录 标记清除算法 标记阶段 深度优先于广度优先 清除阶段 分配 First-fit.Best-fit.Worst-fit三种分配策略 合并 优点 实现简单 与保守式GC算法兼容 缺点 碎片化 分配速 ...
- Reference Counting GC (Part two :Partial Mark & Sweep)
目录 部分标记清除算法 前提 dec_ref_cnt()函数 new_obj()函数 scan_hatch_queue()函数 paint_gray()函数 scan_gray()函数 collect ...
- (转)jvm具体gc算法介绍标记整理--标记清除算法
转自:https://www.cnblogs.com/ityouknow/p/5614961.html GC算法 垃圾收集器 概述 垃圾收集 Garbage Collection 通常被称为“GC”, ...
- JVM内存管理------GC算法精解(五分钟让你彻底明白标记/清除算法)
相信不少猿友看到标题就认为LZ是标题党了,不过既然您已经被LZ忽悠进来了,那就好好的享受一顿算法大餐吧.不过LZ丑话说前面哦,这篇文章应该能让各位彻底理解标记/清除算法,不过倘若各位猿友不能在五分钟内 ...
- GC算法精解(五分钟让你彻底明白标记/清除算法)
GC算法精解(五分钟让你彻底明白标记/清除算法) 相信不少猿友看到标题就认为LZ是标题党了,不过既然您已经被LZ忽悠进来了,那就好好的享受一顿算法大餐吧.不过LZ丑话说前面哦,这篇文章应该能让各位彻底 ...
- JVM内存管理之GC算法精解(五分钟让你彻底明白标记/清除算法)
相信不少猿友看到标题就认为LZ是标题党了,不过既然您已经被LZ忽悠进来了,那就好好的享受一顿算法大餐吧.不过LZ丑话说前面哦,这篇文章应该能让各位彻底理解标记/清除算法,不过倘若各位猿友不能在五分钟内 ...
- JVM之GC算法、垃圾收集算法——标记-清除算法、复制算法、标记-整理算法、分代收集算法
标记-清除算法 此垃圾收集算法分为“标记”和“清除”两个阶段: 首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记对象,它的标记过程前面已经说过——如何判断对象是否存活/死去 死去的对象就会 ...
随机推荐
- ubuntu资料
1.VNC实现Windows远程访问Ubuntu 16.04(无需安装第三方桌面,直接使用自带远程工具) https://www.cnblogs.com/xuliangxing/p/7642650.h ...
- Java 数据脱敏 工具类
一.项目导入Apache的commons的Jar包. Jar包Maven下载地址:https://mvnrepository.com/artifact/org.apache.commons/commo ...
- WLAN配置SKC
1.关于SKC WLC支持粘滞密钥缓存(Sticky Key Caching,SKC). 通过SKC,客户端为其关联的每个AP接收并存储不同的PMKID. AP还维护发布给客户端的PMKID数据库. ...
- Mac 系统上有趣的插件
1.微信小助手:https://github.com/TKkk-iOSer/WeChatPlugin-MacOS 作用:开启消息撤回拦截,设置自动回复,远程登录Mac,微信多开,免认证登录.... 2 ...
- Mysql 连接时的 option 含义
官网文档: https://dev.mysql.com/doc/refman/5.7/en/mysql-real-connect.html
- JavaScript - __proto__和prototype,原形
参考 https://stackoverflow.com/questions/9959727/proto-vs-prototype-in-javascript 区别 构造函数中的prototype创建 ...
- CSP2019 滚粗记
目录 CSP 2019 游记 DAY 0 DAY 1 DAY 2 CSP总结 自测之后 CSP 2019 游记 坐标:GD,GZ 人物:hyf 组别:J和S 任务:划水 目标:划水 任务奖励:退役证书 ...
- c# 分页 PaginatedList<TResult>
using System; using System.Collections.Generic; using System.Linq; namespace Microestc.PaginatedList ...
- 关于java程序在运行时出现a java exception has occured时解决方法
错误截图: 出现情况原因分析: 1.环境没有配置好,配置java环境变量: 参考 检查是否正确,java javac,可以尝试重新 2.查看使用的jdk版本是否存在版本问题: 例如jdk1.7对中文的 ...
- IDEA中使用Lombok插件简化实体类的编写
版本:IDEA Community 2019.2.2 流程:安装lombok插件并安装,重启=>在pom文件中加入 <dependency> <groupId>org.p ...