【Python3爬虫】你会怎么评价复仇者联盟4?
一、写在前面
最近复仇者联盟4正在热映中,很多人都去电影院观看了电影,那么对于这部电影,看过的人都是怎么评价的呢?这时候爬虫就可以派上用场了!
二、主要思路
首先打开豆瓣电影,然后进入复仇者联盟4的详情页面:https://movie.douban.com/subject/26100958/,下拉页面就可以找到这部电影的短评了:
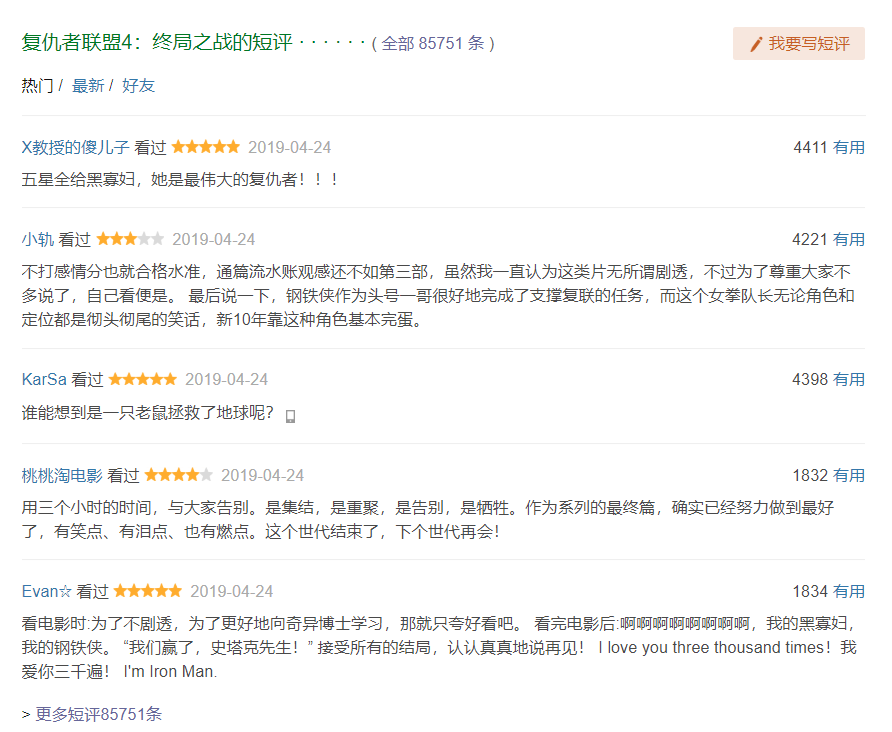
虽然它显示的短评有85751条,但是我们却没有办法获取所有的短评,在未登录的情况下只能看到200条短评,登录之后也只能得到500条短评,可是只有500条怎么够呢?所以我们得想办法得到尽量多的短评,思路为分别选择好评、一般、短评和最新,不过最新的短评只显示100条,所以我们能爬取的短评数量就是1600条。
当我们把短评爬取下来之后,可以先把短评数据保存到数据库中,然后再对这些短评进行分析。这里我选择用MongoDB数据库来保存数据,然后使用SnowNLP进行情感分析,再使用jieba分词和wordcloud生成词云。
三、主要代码
1.模拟登录
这一步是很重要的,我们需要带着登录之后的Cookie去发送请求才能得到数据,当然也可以打开浏览器登录之后复制Cookie,具体怎么做看个人喜好。登录豆瓣的url为:https://accounts.douban.com/passport/login?,抓一下包就知道怎么模拟登录了,并没有什么难度。代码如下:
def login(self):
"""
模拟登录
:return:
"""
url = "https://accounts.douban.com/j/mobile/login/basic"
data = {
"ck": "",
"name": self.username,
"password": self.password,
"remember": "false",
"ticket": ""
}
res = self.session.post(url, headers=self.headers, data=data)
print("登录成功!欢迎用户:", res.json()["payload"]["account_info"]["name"])
2.情感分析
SnowNLP是python中用来处理文本内容的,可以用来分词、标注、文本情感分析等,情感分析是简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。代码如下:
def analyze(self):
"""
情感分析
:return:
"""
result = self.col.find()
comments = []
for i in result:
comments.append(i["评论"])
sentiments_list = []
for i in comments:
s = SnowNLP(i)
sentiments_list.append(s.sentiments)
plt.hist(sentiments_list, bins=np.arange(0, 1, 0.01), facecolor="g")
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.savefig("Sentiments.png")
print("情感分析完毕,生成图片Sentiments.png")
3.生成词云
首先要用jieba对评论进行分词,然后我们要设置一些停用词,比如标点符号、“你”、“我”、“一部”、“电影”等词语,最后使用wordcloud模块生成词云图片。代码如下:
def generate(self):
"""
生成词云
:return:
"""
result = self.col.find()
comments = []
for i in result:
comments.append(i["评论"])
text = jieba.cut("\n".join(comments)) # 文本清洗,去除标点符号和长度为1的词
with open("stopwords.txt", "r", encoding='utf-8') as f:
stopwords = set(f.read().split("\n"))
stopwords.update({"一部", "一场", "电影", "小时", "分钟"})
# 使用图片
mask = np.array(Image.open("Avengers.jpg")) # 生成词云
wc = WordCloud(
mask=mask,
stopwords=stopwords,
font_path="font.ttf",
max_font_size=200,
min_font_size=20,
max_words=100,
width=1200,
height=800
)
wc.generate(' '.join(text))
wc.to_file('Avengers.png')
print("词云已生成,保存为Avengers.png。")
四、运行结果
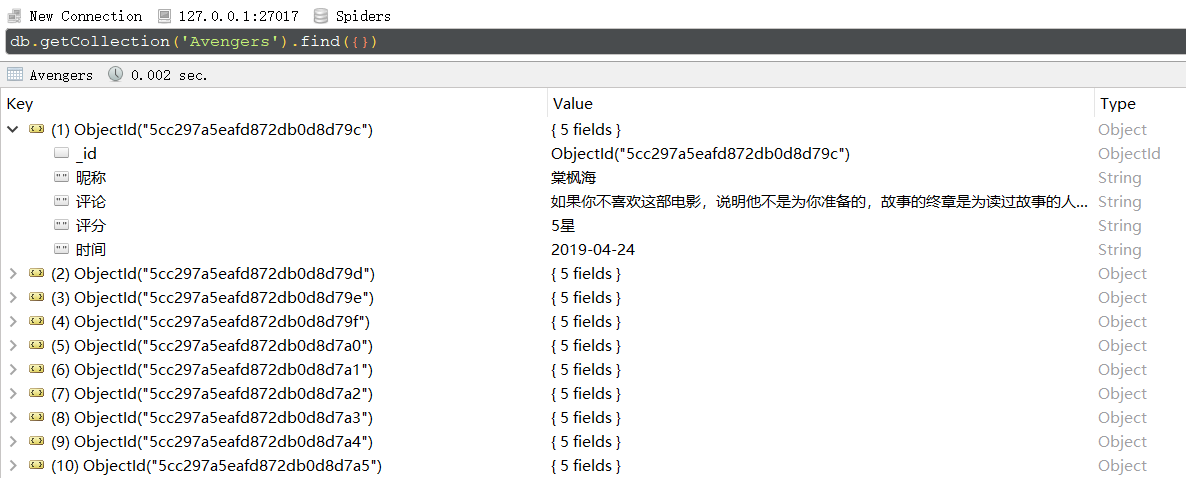
首先是进入MongoDB数据库查看数据:
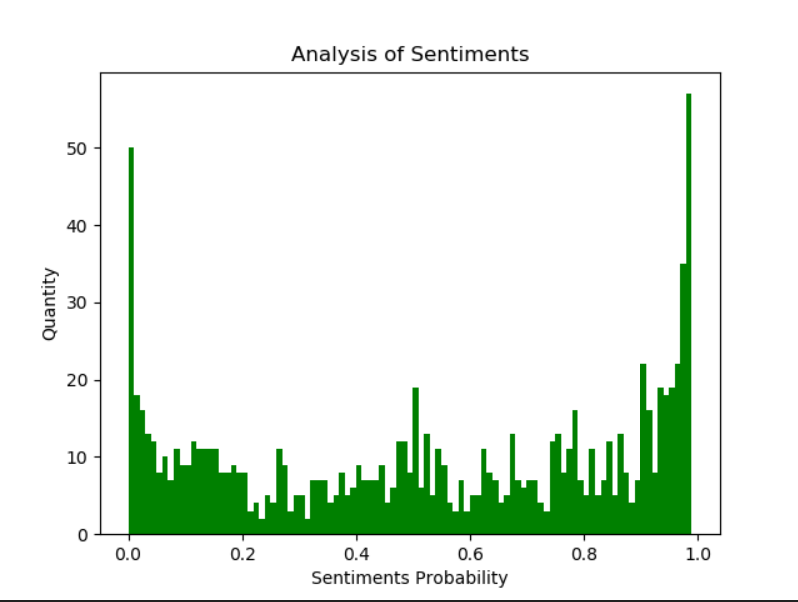
然后是使用SnowNLP进行情感分析得到的结果,可见很多人都是很喜欢复仇者联盟4的:
最后是生成的词云:

那么,对于看了电影的你,你会怎么评价这部电影呢?如果你没有看过,会不会想要买一张电影票去看看呢?
完整代码已上传到GitHub!
【Python3爬虫】你会怎么评价复仇者联盟4?的更多相关文章
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- 笔趣看小说Python3爬虫抓取
笔趣看小说Python3爬虫抓取 获取HTML信息 解析HTML信息 整合代码 获取HTML信息 # -*- coding:UTF-8 -*- import requests if __name__ ...
随机推荐
- ecshop 修改记录20150710
ecshop 修改记录20150710 1:去掉头部TITLE部分的ECSHOP演示站 Powered by ecshop 前台部分:在后台商店设置 - 商店标题修改 后者打开includes/lib ...
- es6(五):class关键字(extends,super,static)
ES5中,生成对象通过构造函数: function A(name,age){ this.name=name; this.age=age } // 在A的prototype属性上定义一个test方法,即 ...
- Heap
#include using namespace std; int heap[100010],cnt=0; void put(int x) { cnt++; heap[cnt]=x; int now= ...
- 关于前端本地压缩图片,兼容IOS/Android/PC且自动按需加载文件之lrz.bundle.js
一.介绍说明主要特点: ①在前端压缩好要上传的图片可以更快的发送给后端,因此也特别适合在移动设备上使用. ②兼容IOS/Android,修复了IOS/Android某些版本已知的BUG. ③按需加载文 ...
- DDGScreenShot—图片擦除功能
写在前面 图片擦除功能,也是运用图片的绘制功能, 将图片绘制后,拿到相应的图片.当然,有一涨底图更明显 实现代码如下 /** ** 用手势擦除图片 - imageView --传图片 - bgView ...
- php数据导出excel
/** * 导出数据为excel表格 *@param $data 一个二维数组,结构如同从数据库查出来的数组 *@param $title excel的第一行标题,一个数组,如果为空则没有标题 *@p ...
- 2018 CISCN reverse wp
2018 CISCN reverse wp 这题比赛的时候没做出来,主要是心态崩了看不下去..赛后看了下网上的wp发现不难,是自己想复杂了.这里将我的思路和exp放出来,希望大家一起交流学习. mai ...
- POI导出excel并下载(以流的形式在客户端下载,不保存文件在服务器上)
import org.apache.poi.hssf.usermodel.HSSFCell; import org.apache.poi.hssf.usermodel.HSSFCellStyle; i ...
- 启动SpringBoot的可执行jar 报错:target\spring-boot-hello-1.0-SNAPSHOT.jar中没有主清单属性
打包成功,但是在执行时报错,没有主清单属性 解决: 增加红框内的依赖: <build> <plugins> <plugin> <groupId>org. ...
- tensorflow 1.8, ubuntu 16.04, cuda 9.0, nvidia-390,安装踩坑指南。
被tensorflow 1.8, ubuntu 16.04, cuda 9.0, nvidia-390折磨了5天,终于上坑,留下指南,造福后人. 1.先把依赖搞清楚: tensorflow 1.8依赖 ...