Python数据抓取_BeautifulSoup模块的使用
在数据抓取的过程中,我们往往都需要对数据进行处理
本篇文章我们主要来介绍python的HTML和XML的分析库BeautifulSoup
BeautifulSoup 的官方文档网站如下
https://www.crummy.com/software/BeautifulSoup/bs4/doc/

BeautifulSoup可以在HTML和XML的结构化文档中抽取出数据,而且还提供了各类方法,可以很方便的对文档进行搜索、抽取和修改,能极大的提高我们数据挖掘的效率
下面我们来安装BeautifulSoup
(上面我已经安装过了,所以没有显示进度条)
非常简单,无非就是pip install 加安装的包名
pip3 install bs4
下面我们开始正式来学习这个模块
首先还是提供一个目标网址
我的个人网站
http://www.susmote.com

下面我们通过requests的get方法保存这个网址内容的源代码
import requests urls = "http://www.susmote.com" resp = requests.get(urls)
resp.encoding = "utf8"
content = resp.text with open("Bs4_test.html", 'w', encoding="utf8") as f:
f.write(content)
运行起来,我们马上就能得到这个网页的源代码了
下面我们写的程序就是专门针对这个源代码利用BeautifulSoup来分析
首先我们来获取里面所有的a标签的href链接和对应的文本
代码如下
from bs4 import BeautifulSoup
with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read())
a_list = bs.find_all('a')
for a in a_list:
if a.text != "":
print(a.text.strip(), a["href"])
首先我们从BS4里面导入BeautifulSoup
然后以只读模式打开文件打开文件,我们把f.read()作为BeautifulSoup的参数,也就是将字符串初始化,把返回的对象记为bs
然后我们就可以调用BeautifulSoup的方法了,BeautifulSoup的最常用的方法就是find和find_all,可以在文档中找到符合条件的元素,区别就是找到一个,和找到所有
在这里我们使用find_all方法,他的常用形式是
元素列表 = bs.find_all(元素名称, attires = {属性名:属性值})
然后就是依次输出找到的元素,这里就不多说 了
我们在命令行运行这段代码

输出结果如下

找寻的结果太多,不一一呈现
可以看到爬取的链接其中有很多规律
例如标签链接
我们可以对代码进行稍微的更改,以获取网站所有的标签链接,也就是做一个过滤
代码如下
from bs4 import BeautifulSoup
with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read(), "lxml")
a_list = bs.find_all('a')
for a in a_list:
if a.text != "" and 'tag' in a["href"]:
print(a.text.strip(), a["href"])
大致内容没有改变,只是在输出前加了一个判定条件,以实现过滤
我们在命令行运行这个程序

结果如下

除了这样,你还可以使用很多方法达到相同的目标
使用attrs = [ 属性名 : 属性值 ] 参数
属性名我相信学过html的人一定都知道,例如"class","id"、"style"都是属性,下面我们逐步深入,利用这个来深入挖掘数据
获取我的博客网站中每篇文章的标题
经过浏览器调试,我们很容易获取到我的博客网页中标题部分的属性样式
如下图
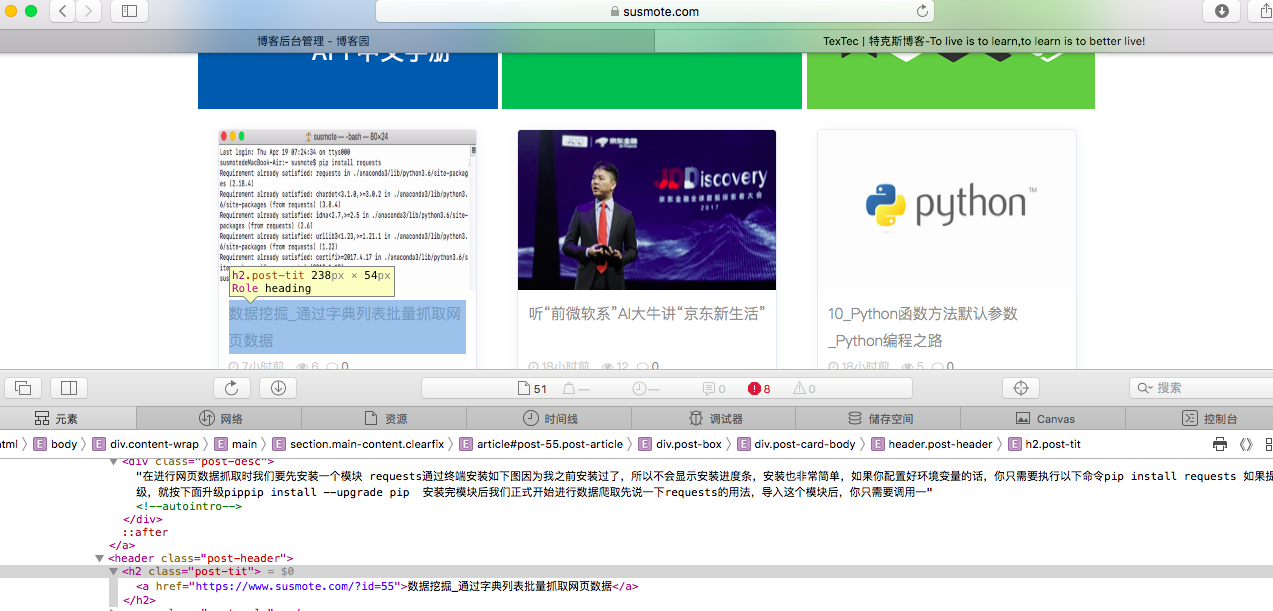
标题样式是一个<header class="post-header">
非常简单的一个属性
下面我们通过代码来实现批量获取文章标题
# coding=utf-8
__Author__ = "susmote" from bs4 import BeautifulSoup
n = 0
with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read(), "lxml")
header_list = bs.find_all('header', attrs={'class': 'post-header'})
for header in header_list:
n = int(n)
n += 1
if header.text != "":
print(str(n) + ": " + header.text.strip() + "\n")
大体上跟之前的代码没什么差别,只是在find_all方法中多加了一个参数,attrs以实现属性过滤,然后为了使结果更清晰,我加了一个n
在命令行下运行,结果如下
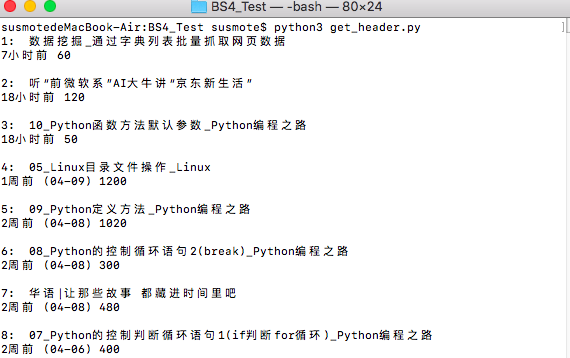
利用正则表达式来表达属性值的特征
无非就是在属性值后面加一个正则匹配的方法,我在这就不过多解释了,如果想要了解,可以自行上网百度
我的博客网站 www.susmote.com
Python数据抓取_BeautifulSoup模块的使用的更多相关文章
- python数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- Python数据抓取(1) —数据处理前的准备
(一)数据抓取概要 为什么要学会抓取网络数据? 对公司或对自己有价值的数据,80%都不在本地的数据库,它们都散落在广大的网络数据,这些数据通常都伴随着网页的形式呈现,这样的数据我们称为非结构化数据 如 ...
- Python数据抓取(2) —简单网络爬虫的撰写
(一)使用Requests存储网页 Requests 是什么?网络资源(URLs)抓取套件 优点? 改善urllib2的缺点,让使用者以最简单的方式获取网络资源 可以使用REST操作(POST,PUT ...
- Python数据抓取(3) —抓取标题、时间及链接
本次分享,jacky将跟大家分享如何将第一财经文章中的标题.时间以及链接抓取出来 (一)观察元素抓取位置 网页的原始码很复杂,我们必须找到特殊的元素做抽取,怎么找到特殊的元素呢?使用开发者工具检视每篇 ...
- 数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- 【Python入门只需20分钟】从安装到数据抓取、存储原来这么简单
基于大众对Python的大肆吹捧和赞赏,作为一名Java从业人员,我本着批判与好奇的心态买了本python方面的书<毫无障碍学Python>.仅仅看了书前面一小部分的我......决定做一 ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
随机推荐
- 功能测试很low?不能升级到高级测试工程师?
功能测试很low?不能升级到高级测试工程师? 功能测试很low?功能测试很简单?功能测试就是黑盒测试?功能测试没有技术含量?功能测试工资低?只会功能测试没有竞争力?功能测试这活初中生都可以干?功能测试 ...
- hibernate框架学习笔记5:缓存
缓存不止存在与程序中,电脑硬件乃至于生活中都存在缓存 目的:提高效率 比如IO流读写字节,如果没有缓存,读一字节写一字节,效率低下 hibernate中的一级缓存:提高操作数据库的效率 示例: 抽取的 ...
- 敏捷开发每日报告--day5
1 团队介绍 团队组成: PM:齐爽爽(258) 小组成员:马帅(248),何健(267),蔡凯峰(285) Git链接:https://github.com/WHUSE2017/C-team 2 ...
- Alpha冲刺Day4
Alpha冲刺Day4 一:站立式会议 今日安排: 我们把项目大体分为四个模块:数据管理员.企业人员.第三方机构.政府人员.完成了数据库管理员模块.因企业人员与第三方人员模块存在大量的一致性,故我们团 ...
- 新手入门 git
Git是目前世界上最先进的分布式版本控制系统 特点:高端大气上档次 什么是版本控制系统 系统自动记录文件改动 方便同事协作管理 不用自己管理一堆类似的文件了,也不需要把文件传来传去.如果想查看某次改动 ...
- 【bug清除】Surface Pro系列使用Drawboard PDF出现手写偏移、卡顿、延迟现象的解决方式
最近自己新买的New Surface Pro在使用Drawboard PDF时,出现了性能问题,即笔迹延迟偏移,卡顿的问题. 排查驱动问题之后,确认解决方案如下: 将Surface的电池调到性能模式, ...
- JAVA_SE基础——23.类的定义
黑马程序员入学blog ... java 面向对象的语言 对象:真实存在的唯一的实物. 比如:我家的狗, 类: 实际就是对某种类型事物的共性属性与行为的抽取. 抽象的概念... 比如说:车 ...
- JAVA_SE基础——10.变量的作用域
<pre name="code" class="java"> 上个月实在太忙了,从现在开始又可以静下心来写blog了. 变量的作用域指 可以使用此变 ...
- JavaScript 实现二叉树
JavaScript 实现二叉树: // JavaScript 实现二叉树 function BinaryTree () { var Node = function (key) { this.key ...
- vscode使用shell
https://stackoverflow.com/questions/42606837/how-to-use-bash-on-windows-from-visual-studio-code-inte ...