机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集
鸢尾花数据集作为入门经典数据集。Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
在三个类别中,其中有一个类别和其他两个类别是线性可分的。另外。在sklearn中已内置了此数据集。
from sklearn.datasets import load_iris #导入IRIS数据集
iris = load_iris() #特征矩阵
数据集的格式如下图所示:

1.数据集的载入
虽然在sklearn中,内置了鸢尾花数据集,但是我们用的是下载好的数据集,下面是数据集的读入,我们先通过手动的方式将数据集进行读入。
f = open(path)
x = []
y = []
for d in f:
d = d.strip()
if d:
d = d.split(',')
y.append(d[-1])
x.append(list(map(float, d[:-1])))
x = np.array(x)
y = np.array(y)
print(x)
y[y == 'Iris-setosa'] = 0
y[y == 'Iris-versicolor'] = 1
y[y == 'Iris-virginica'] = 2
print(y)
y = y.astype(dtype=np.int)
print(y)
代码的13-15中,通过判断y中的标签值,返回的是一个y大小相同的一个boolearn类型的列表,在通过这个列表进行赋值操作,非常的迅速和灵活。
读取的X数据如下:

处理后的标签的数据如下:

除了上述方式的手动读入数据,还可以通过pandas库来进行数据的读取。
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import preprocessing
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline df = pd.read_csv(path, header=0)
x = df.values[:, :-1]
y = df.values[:, -1]
print('x = \n', x)
print('y = \n', y)
le = preprocessing.LabelEncoder()
le.fit(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
print(le.classes_)
y = le.transform(y)
print('Last Version, y = \n', y)
上述代码中,pd.read_csv(path, header=0),header :指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0【第一行数据】,否则设置
为None。
sklearn.preprocessing.LabelEncoder():标准化标签,将标签值统一转换成range(标签值个数-1)范围内,例如["paris", "paris", "tokyo", "amsterdam"];里面不
同的标签数目是3个,则标准化标签之后就是0,1,2,并且根据字典排序。
le.fit(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])含义为将标签集喂给le标签处理器,y = le.transform(y)对y进行转化。
也可以使用numpy来对数据进行加载。
def iris_type(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s] data = np.loadtxt(path, dtype=float, delimiter=',', converters={4: iris_type})
使用np中的loadtxt来对数据加载,delimiter指定数据的分割符,converter为指定需要进行转换的列及对应的转换函数。
2.构建线性模型
为了后面的可视化的效果,我们在此仅选用了连两个特征构建logistic回归模型,代码如下:
x = x[:, :2]
print(x)
print(y)
x = StandardScaler().fit_transform(x)
lr = LogisticRegression() # Logistic回归模型
lr.fit(x, y.ravel()) # 根据数据[x,y],计算回归参数
StandardScaler----计算训练集的平均值和标准差,以便测试数据集使用相同的变换。即fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形
式。调用fit_transform(),其实找到了均值μ和方差σ^2,即已经找到了转换规则,把这个规则利用在训练集上,同样,可以直接将其运用到测试集上(甚至交叉验证
集)。
我们也可以使用管道的方式构建模型,并进行训练:
lr = Pipeline([('sc', StandardScaler()),
('clf', LogisticRegression()) ])
lr.fit(x, y.ravel())
LogisticRegression()的主要参数如下:
- penalty:惩罚项,str类型,可选参数为l1和l2,默认为l2。用于指定惩罚项中使用的规范。newton-cg、sag和lbfgs求解算法只支持L2规范。L1规范假设的是模型的参数满足拉普拉斯分布,L2假设的模型参数满足高斯分布。
- dual:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
- tol:停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解。
- c:正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
- fit_intercept:是否存在截距或偏差,bool类型,默认为True。
- intercept_scaling:仅在正则化项为”liblinear”,且fit_intercept设置为True时有用。float类型,默认为1。
- class_weight:用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。
- random_state:随机数种子,int类型,可选参数,默认为无,仅在正则化优化算法为sag,liblinear时有用。
- solver:优化算法选择参数,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear。solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
- saga:线性收敛的随机优化算法的的变重。
3.模型的可视化
我们可以在所选特征的范围内,从最大值到最小值构建一系列的数据,使得它能覆盖整个的特征数据范围,然后预测这些值所属的分类,并给它们所在的区域
上色,这样我们就能够清楚的看到模型每个分类的区域了,具体的代码如下所示:
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点 cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x[:, 0], x[:, 1], c=y.ravel(), edgecolors='k', s=50, cmap=cm_dark)
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.savefig('2.png')
plt.show()
np.meshgrid()函数常用于生成网格数据,多用于绘制三维图形。 mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])生成一个颜色的列表,plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) 根据颜色列表中的值,给传入的坐标进行绘图。
绘制的图片的效果如下:
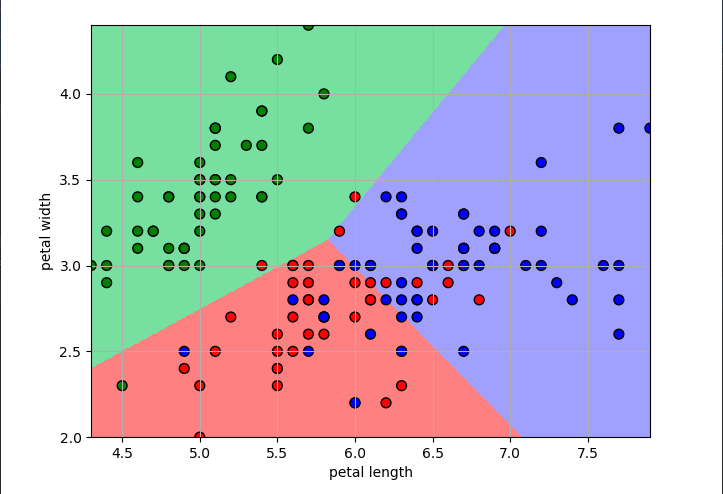
4.计算模型的准确率
由于我们使用的是两个特征进行数据集的分类,所以分类的准确率并不是高,代码如下:
y_hat = lr.predict(x)
y = y.reshape(-1)
result = y_hat == y
print(y_hat)
print(result)
acc = np.mean(result)
print('准确度: %.2f%%' % (100 * acc))
具体的准确率是多少呢?同学们可以自己动手试一下哦!

欢迎关注我的公众号,不定期分享机器学习模型原理!
机器学习——logistic回归,鸢尾花数据集预测,数据可视化的更多相关文章
- 02-15 Logistic回归(鸢尾花分类)
目录 Logistic回归(鸢尾花分类) 一.导入模块 二.获取数据 三.构建决策边界 四.训练模型 4.1 C参数与权重系数的关系 五.可视化 更新.更全的<机器学习>的更新网站,更有p ...
- 机器学习——Logistic回归
1.基于Logistic回归和Sigmoid函数的分类 2.基于最优化方法的最佳回归系数确定 2.1 梯度上升法 参考:机器学习--梯度下降算法 2.2 训练算法:使用梯度上升找到最佳参数 Logis ...
- 机器学习——Logistic回归
参考<机器学习实战> 利用Logistic回归进行分类的主要思想: 根据现有数据对分类边界线建立回归公式,以此进行分类. 分类借助的Sigmoid函数: Sigmoid函数图: Sigmo ...
- 机器学习--Logistic回归
logistic回归 很多时候我们需要基于一些样本数据去预测某个事件是否发生,如预测某事件成功与失败,某人当选总统是否成功等. 这个时候我们希望得到的结果是 bool型的,即 true or fals ...
- 机器学习-- Logistic回归 Logistic Regression
转载自:http://blog.csdn.net/linuxcumt/article/details/8572746 1.假设随Tumor Size变化,预测病人的肿瘤是恶性(malignant)还是 ...
- coursera机器学习-logistic回归,正则化
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 机器学习 Logistic 回归
Logistic regression 适用于二分分类的算法,用于估计某事物的可能性. logistic分布表达式 $ F(x) = P(X<=x)=\frac{1}{1+e^{\frac{-( ...
- 吴恩达-机器学习+Logistic回归分类方案
- 【机器学习实战】第5章 Logistic回归
第5章 Logistic回归 Logistic 回归 概述 Logistic 回归虽然名字叫回归,但是它是用来做分类的.其主要思想是: 根据现有数据对分类边界线建立回归公式,以此进行分类. 须知概念 ...
随机推荐
- ESXI的安装和部署
1. 实验拓扑图: 2. 实验要求 (1) 新建一台exsi主机,安装exsi5.5系统. 步骤: 1)新建虚拟机,导入光盘. 2)安装esxi系统 (2)在exsi主机中,配置IP地址为1 ...
- 某校高中生利用Python,巧妙获取考试成绩,看到成绩后无言以对!
Python是非常有吸引力的编程语言,学习Python的不是帅哥就是美女.为什么这么说呢?因为我和我的女朋友都是学习Python认识的,小编肯定是帅哥,不用去怀疑,而且我眼光特高. 给大伙讲一个故事, ...
- MyBatis的增删改查。
数据库的经典操作:增删改查. 在这一章我们主要说明一下简单的查询和增删改,并且对程序接口做了一些调整,以及对一些问题进行了解答. 1.调整后的结构图: 2.连接数据库文件配置分离: 一般的程序都会把连 ...
- CentOS7 通过YUM安装MySQL5.7
1.进入到要存放安装包的位置 cd /home/lnmp 2.查看系统中是否已安装 MySQL 服务,以下提供两种方式: rpm -qa | grep mysql yum list installed ...
- Jenkins使用教程
1 软件安装 1.1 运行环境 1.1.1 Maven的安装 1.1.2 Git的安装 1.1.3 Tomcat的安装 1.2 安装Jenkins 1.2.1 msi和war包安装2 ...
- hystrix基本介绍和使用(1)
一.hystrix基本介绍 Hystrix(https://github.com/Netflix/Hystrix)是Netflix(https://www.netflix.com/global)的一个 ...
- 卷积神经网络之LeNet
开局一张图,内容全靠编. 上图引用自 [卷积神经网络-进化史]从LeNet到AlexNet. 目前常用的卷积神经网络 深度学习现在是百花齐放,各种网络结构层出不穷,计划梳理下各个常用的卷积神经网络结构 ...
- k8s使用helm打包chart并上传到腾讯云TencentHub
本文只涉及Helm的Chart操作,不会对其他知识进行过多描述.至于安装这块,麻烦自行百度吧,一大堆呢. 在容器化的时代,我们很多应用都可以部署在docker,很方便,而再进一步,我们还有工具可以对d ...
- 一起学Android之Http访问
概述 在Android开发中,一般通过网络进行访问服务器端的信息(存储和检索网络中的数据),如API接口,WebService,网络图片等.今天主要讲解Http访问的常用方法,仅供学习分享使用. 涉及 ...
- Iterm2/Mac自带终端工具快速进入你想进入的虚拟机教程
一.首先我们在终端本地要写一个登录的脚本,eg: 当然首先要touch login.sh 啦,下面就是脚本文件,比较low,大神勿喷,会更炫酷写法的小伙伴可以自己参考这个思路写,不会的直接复制就好啦 ...