Re:从零开始的领域驱动设计
领域驱动的火爆程度不用我赘述,但是即便其如此得耳熟能详,但大多数人对其的认识,还只是停留在知道它的缩写是DDD,知道它是一种软件思想,或者知道它和微服务有千丝万缕的关系。Eric Evans对DDD的诠释是那么地惜字如金,而我所认识的领域驱动设计的专家又都是行业中的资深前辈,他们擅长于对软件设计进行高屋建瓴的论述,如果没有丰富的互联网从业经验,是不能从他们的分享中获取太多的营养的,可以用曲高和寡来形容。1000个互联网从业者,100个懂微服务,10个人懂领域驱动设计。
可能有很多和我一样的读者,在得知DDD如此火爆之后,尝试去读了开山之作《领域驱动设计——软件核心复杂性应对之道》,翻看了几张之后,晦涩的语句,不明所以的专业术语,加上翻译导致的语句流畅性,可以说观看体验并不是很好,特别是对于开发经验不是很多的读者。我总结了一下,为何这本书难以理解:
1. 没有阅读软件设计丛书的习惯,更多人偏向于阅读偏应用层面的书籍,“talk is cheap,show me the code”往往更符合大多数人的习惯。
2. 没有太多的开发经验支撑。没有踩过坑,就不会意识到设计的重要性,无法产生共情。
3. 年代有些久远,这本书写于2004年,书中很多软件设计的反例,在当时是非常流行的,但是在现在已经基本绝迹了。
大师之所以为大师,是因为其能跨越时代的限制,预见未来的问题,这也是为什么DDD在十几年前就被提出,却在微服务逐渐流行的现阶段才被大家重视。
诚然如标题所示,本文是领域驱动设计的一个入门文章,或者更多的是一个个人理解的笔记,笔者也正在学习DDD的路上,可能会有很多的疏漏。如有理解有偏颇的地方,还望各位指摘。
认识领域驱动设计的意义
领域驱动设计并不会绝对地提高项目的开发效率。
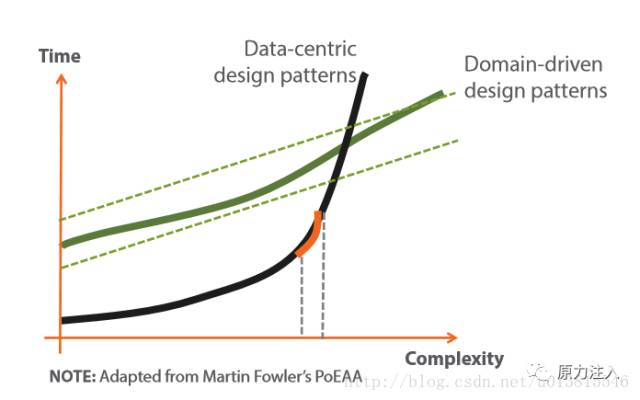
图1:复杂性与开发周期关系
遵循领域驱动设计的规范使得项目初期的开发甚至不如不使用它来的快,原因有很多,程序员的素质,代码的规范,限界上下文的划分…甚至需求修改后导致需要重新建模。但是遵循领域驱动设计的规范,在项目越来越复杂之后,可以不至于让项目僵死。这也是为什么很多系统不断迭代着,最终就黄了。书名的副标题“软件核心复杂性应对之道”正是阐释了这一点。
模式: smart ui是个反模式
可能很多读者还不知道smart ui是什么,但是在这本书写作期间,这种设计风格是非常流行的。在与一位领域驱动设计方面的资深专家的交谈中,他如下感慨到软件发展的历史:
2003年时,正是delphi,vb一类的smart ui程序大行其道,Java在那个年代,还在使用jsp来完成大量的业务逻辑操作,4000行的jsp是常见的事;2005年spring hibernate替换了EJB,社区一片欢呼,所有人开始拥护action,service,dao这样的贫血模型(充血模型,贫血模型会在下文论述);2007年,Rails兴起,有人发现了Rails的activeRecord是涨血模型,引起了一片混战;直到现在的2017年,微服务成为主流系统架构。
在现在这个年代,不懂个MVC分层,都不好意思说自己是搞java的,也不会有人在jsp里面写业务代码了
(可以说模板技术freemarker,thymeleaf已经取代jsp了),
但是在那个年代,还没有现在这么普遍地强调分层架构的重要性。
这个章节其实并不重要,因为mvc一类的分层架构已经是大多数java初学者的“起点”了,大多数DDD的文章都不会赘述这一点,我这里列出来是为了让大家知晓这篇文章的时代局限性,在后续章节的理解中,也需要抱有这样的逻辑:这本书写于2004年。
模式: Entity与Value Object
我在不了解DDD时,就对这两个术语早有耳闻。entity又被称为reference object,我们通常所说的Java bean在领域中通常可以分为这两类,(可别把value object和常用于前台展示的view object,vo混为一谈)
entity的要义在于生命周期和标识,value object的要义在于无标识,通常情况下,entity在通俗意义上可以理解为数据库的实体,(不过不严谨),value object则一般作为一个单独的类,构成entity的一个属性。
举两个例子来加深对entity和value object的理解。
例1:以电商微服务系统中的商品模块,订单模块为例。将整个电商系统划分出商品和订单两个限界上下文(Bound Context)应该是没有争议的。如果是传统的单体应用,我们可以如何设计这两个模块的实体类呢?
会不会是这样?
class Product{
String id;//主键
String skuId;//唯一识别号
String productName;
Bigdecimal price;
Category category;//分类
List<Specification> specifications;//规格
...
}
class Order{
String id;//主键
String orderNo;//订单号
List<OrderItem> orderItems;//订单明细
BigDecimal orderAmount;//总金额
...
}
class OrderItem{
String id;
Product product;//关联商品
BigDecimal snapshotPrice;//下单时的价格
}
看似好像没问题,考虑到了订单要保存下单时候的价格(当然,这是常识)但这么设计却存在诸多的问题。
在分布式系统中,商品和订单这两个模块必然不在同一个模块,也就意味着不在同一个网段中。
上述的类设计中直接将Product的列表存储到了Order中,也就是一对多的外键关联。这会导致,每次访问订单的商品列表,都需要发起n次远程调用。
反思我们的设计,其实我们发现,订单BC(Bounded Context,限界上下文)的Product和商品BC(Bounded Context,限界上下文)的Product其实并不是同一个entity,在商品模块中,我们更关注商品的规格,种类,实时价格,这最直接地反映了我们想要买什么的欲望。而当生成订单后,我们只关心这个商品买的时候价格是多少,不会关心这个商品之后的价格变动,还有他的名称,仅仅是方便我们在订单的商品列表中定位这个商品。
如何改造就变得明了了
class OrderItem{
String id;
String productId;//只记录一个id用于必要的时候发起command操作
String skuId;
String productName;
...
BigDecimal snapshotPrice;//下单时的价格
}
是的,我们做了一定的冗余,这使得即使商品模块的商品,名称发生了微调,也不会被订单模块知晓。这么做也有它的业务含义,用户会声称:我买的时候他的确就叫这个名字。记录productId和skuId的用意不是为了查询操作,而是方便申请售后一类的命令操作(command)。
在这个例子中,Order 和 Product都是entity,而OrderItem则是value object(想想之前的定义,OrderItem作为一个类,的确是描述了Order这个entity的一个属性集合)。关于标识,我的理解是有两层含义,第一个是作为数据本身存储于数据库,主键id是一个标识,第二是作为领域对象本身,orderNo是一个标识,对于人而言,身份证是一个标识。而OrderItem中的productId,id不能称之为标识,因为整个OrderItem对象是依托于Order存在的,Order不存在,则OrderItem没有意义。
例子2: 汽车和轮胎的关系是entity和value object吗?
这个例子其实是一个陷阱题,因为他没有交代BC(Bounded Context,限界上下文),场景不足以判断。对于用户领域而言,的确可以成立,汽车报废之后,很少有人会关心轮胎。
轮胎和发动机,雨刮器,座椅地位一样,只是构成汽车的一些部件,和用户最紧密相关的,只有汽车这个entity,轮胎只是描述这个汽车的属性(value object);
场景切换到汽修厂,无论是汽车,还是轮胎,都是汽修厂密切关心的,每个轮胎都有自己的编号,一辆车报废了,可以安置到其他车上,这里,他们都是entity。
这个例子是在说明这么一个道理,同样的事物,在不同的领域中,会有不同的地位。

图2:《领域驱动设计》Value Object模式的示例
在单体应用中,可能会有人指出,这直接违背了数据库范式,但是领域驱动设计的思想正如他的名字那样,不是基于数据库的,而是基于领域的。
微服务使得数据库发生了隔离,这样的设计思想可以更好的指导我们优化数据库。
模式: Repository
哲学家分析自然规律得出规范,框架编写者根据规范制定框架。有些框架,可能大家一直在用,但是却不懂其中蕴含的哲学。
——来自于笔者的口胡记得在刚刚接触mvc模式,常常用DAO层表示持久化层,在JPA+springdata中,抽象出了各式各样的xxxRepository,与DDD的Repository模式同名并不是巧合,
jpa所表现出的正是一个充血模型(如果你遵循正确的使用方式的话),可以说是领域驱动设计的一个最佳实践。
开宗明义,在Martin Fowler理论中,有四种领域模型:
1. 失血模型
2. 贫血模型
3. 充血模型
4. 胀血模型
详细的概念区别不赘述了,可以参见专门讲解4种模型的博客。他们在数据库开发中分别有不同的实现,用一个修改用户名的例子来分析。
class User{
String id;
String name;
Integer age;
}
失血模型:
跳过,可以理解为所有的操作都是直接操作数据库,在smart ui中可能会出现这样的情况。
贫血模型:
class UserDao {
@Autowired
JdbcTemplate jdbcTemplate;
public void updateName(String name,String id){
jdbcTemplate.excute("update user u set u.name = ? where id=?",name,id);
}
}
class UserService{
@Autowired
UserDao userDao;
void updateName(String name,String id){
userDao.updateName(name,id);
}
}
贫血模型中,dao是一类sql的集合,在项目中的表现就是写了一堆sql脚本,与之对应的service层,则是作为Transaction Script的入口。
观察仔细的话,会发现整个过程中user对象都没出现过。
充血模型:
interface UserRepository extends JpaRepository<User,String>{
//springdata-jpa自动扩展出save findOne findAll方法
}
class UserService{
@Autowoird
UserRepository userRepository;
void updateName(String name,String id){
User user = userRepository.findOne(id);
user.setName(name);
userRepository.save(user);
}
}
充血模型中,整个修改操作是“隐性”的,对内存中user对象的修改直接影响到了数据库最终的结果,不需要关心数据库操作,只需要关注领域对象user本身。Repository模式就是在于此,屏蔽了数据库的实现。与贫血模型中user对象恰恰相反,整个流程没有出现sql语句。
涨血模型:
没有具体的实现,可以这么理解:
void updateName(String name,String id){
User user = new User(id);
user.setName(name);
user.save();
}
我们在Repository模式中重点关注充血模型。
为什么前面说:如果你遵循正确的使用方式的话,springdata才是对DDD的最佳实践呢?
因为有的使用者会写出下面的代码:
interface UserRepository extends JpaRepository<User,String>{
@Query("update user set name=? where id=?")
@Modifying(clearAutomatically = true)
@Transactional
void updateName(String name,String id);
}
历史的车轮在滚滚倒退。本节只关注模型本身,不讨论使用中的一些并发问题,再来聊聊其他的一些最佳实践。
interface UserRepository extends JpaRepository<User,String>{
User findById();//√ 然后已经存在findOne了,只是为了做个对比
User findBy身份证号();//可以接受
User findBy名称();//×
List<权限> find权限ByUserId();//×
}
理论上,一个Repository需要且仅需要包含三类方法loadBy标识,findAll,save(一般findAll()就包含了分页,排序等多个方法,算作一类方法)。
标识的含义和前文中entity的标识是同一个含义,在我个人的理解中,身份证可以作为一个用户的标识(这取决于你的设计,同样的逻辑还有订单中有业务含义的订单编号,保单中的投保单号等等),在数据库中,id也可以作为标识。findBy名称为什么不值得推崇,因为name并不是User的标识,名字可能会重复,只有在特定的现场场景中,名字才能具体对应到人。
那应该如何完成“根据姓名查找可能的用户”这一需求呢?最方便的改造是使用Criteria,Predicate来完成视图的查询,哪怕只有一个非标识条件。
在更完善的CQRS架构中,视图的查询则应该交由专门的View层去做,可以是数据库,可以是ES。
findByUserId不值得推崇则是因为他违背了聚合根模式(下文会介绍),
User的Repository只应该返回User对象。
软件设计初期,你是不是还在犹豫:是应该先设计数据库呢,还是应该设计实体呢?在Domain-Driven的指导下,你应当放弃Data-Driven。
模式 聚合和聚合根
难住我的还有英文单词,初识这个概念时,忍不住发问:Aggregate是个啥。文中使用聚合的概念,来描述对象之间的关联,采用合适的聚合策略,可以避免一个很长,很深的对象引用路径。对划分模块也有很大的指导意义。
在微服务中我们常说划分服务模块,在领域驱动设计中,我们常说划分限界上下文。在面向对象的世界里,用抽象来封装模型中的引用,聚合就是指一组相关对象的集合,我们把它作为数据修改的单元。每个聚合都有一个聚合根(root)和一个边界(boundary)。边界定义了聚合内部有什么,而根则是一个特定的entity,两个聚合之间,只允许维护根引用,只能通过根引用去向深入引用其他引用变量。
例子还是沿用电商系统中的订单和商品模块。在聚合模式中,订单不能够直接关联到商品的规格信息,如果一定要查询,则应该通过订单关联到的商品,由商品去访问商品规格。在这个例子中,订单和商品分别是两个边界,而订单模块中的订单entity和商品模块中的商品entity就是分别是各自模块的root。遵循这个原则,可以使我们模块关系不那么的盘根错节,这也是众多领域驱动文章中不断强调的划分限界上下文是第一要义。
模式 包结构
微服务有诸多的模块,而每个模块并不一定是那么的单一职责,比模块更细的分层,便是包的分层。
我在阅读中,隐隐觉得这其中蕴含着一层哲学,但是几乎没有文章尝试解读它。
领域驱动设计将其单独作为了一个模式进行了论述,篇幅不小。重点就是论述了一个思想:包结构应当具有高内聚性。
这次以一个真实的案例来介绍一下对高内聚的包结构的理解,项目使用maven多module搭建。
我曾经开发过一个短信邮件平台模块,它在整个微服务系统中有两个职责,
一:负责为其他模块提供短信邮件发送的远程调用接口,
二:有一个后台页面,可以让管理员自定义发送短信,并且可以浏览全部的一,二两种类型发送的短信邮件记录。
在设计包结构之前,先是设计微服务模块。

api层定义了一系列的接口和接口依赖的一些java bean,model层也就是我们的领域层。
这两个模块都会打成jar包,外部服务依赖api,api则由app模块使用rpc框架实现远程调用。
admin和app连接同一个数据源,可以查询出短信邮件记录,admin需要自定义发送短信也是通过rpc调用。
简单介绍完了这个项目后,重点来分析下需求,来看看如何构建包结构。
mvc分层天然将controller,service,model,config层分割开,这符合DDD所推崇的分层架构模式
(这个模式在原文中有描述,但我觉得和现在耳熟能详的分层结构没有太大的出入,所以没有放到本文中介绍),
而我们的业务需求也将短信和邮件这两个领域拆分开了。
那么,
到底是mvc应该包含业务包结构呢?
还是说业务包结构包含mvc呢?
mvc高于业务分层
//不够好的分层
sinosoftgz.message.admin
config
CommonConfig.java
service
CommonService.java
mail
MailTemplateService.java
MailMessageService.java
sms
SmsTemplateService.java
SmsMessageService.java
web
IndexController.java
mail
MailTemplateController.java
MailMessageController.java
sms
SmsTemplateController.java
SmsMessageController.java
MessageAdminApp.java业务分层包含mvc
//高内聚的分层
sinosoftgz.message.admin
config
CommonConfig.java
service
CommonService.java
web
IndexController.java
config
MailConfig.java
service
MailTemplateService.java
MailMessageService.java
web
MailTemplateController.java
MailMessageController.java
sms
config
Smsconfig.java
service
SmsTemplateService.java
SmsMessageService.java
web
SmsTemplateController.java
SmsMessageController.java
MessageAdminApp.java
业务并不是特别复杂,但应该可以发现第二种(业务分层包含mvc)的包结构,才是一种高内聚的包结构。
第一种分层会让人有一种将各个业务模块(如mail和sms)的service和controller隔离开了的感觉,当模块更多,每个模块的内容更多,这个“隔得很远”的不适感会逐渐侵蚀你的开发速度。
一种更加低内聚的反例是不用包分层,仅仅依赖前缀区分,由于在项目开发中真的发现同事写出了这样的代码,我觉得还是有必要拿出来说一说:
//反例
sinosoftgz.message.admin
config
CommonConfig.java
MailConfig.java
Smsconfig.java
service
CommonService.java
MailTemplateService.java
MailMessageService.java
SmsTemplateService.java
SmsMessageService.java
web
IndexController.java
MailTemplateController.java
MailMessageController.java
SmsTemplateController.java
SmsMessageController.java
MessageAdminApp.java这样的设计会导致web包越来越庞大,逐渐变得臃肿,使项目僵化,项目经理为何一看到代码就头疼,
规范的高内聚的包结构,遵循业务>mvc的原则,可以知道我们的项目庞大却有条理。
其他模式
《领域驱动设计》这本书介绍了众多的模式,上面只是介绍了一部分重要的模式,后续我会结合各个模式,尽量采用最佳实践+浅析设计的方式来解读。
微服务之于领域驱动设计的一点思考
技术架构诚然重要,但不可忽视领域拆解和业务架构,《领域驱动设计》中的诸多失败,成功案例的总结,是支撑其理论知识的基础,最终汇聚成众多的模式。在火爆的微服务架构潮流下,我也逐渐意识到微服务不仅仅是技术的堆砌,更是一种设计,一门艺术。我的本科论文本想就微服务架构进行论述,奈何功底不够,最后只能改写成一篇分布式网站设计相关的文章,虽然是一个失败的过程,但让我加深了对微服务的认识。如今结合领域驱动设计,更加让我确定,技术方案始终有代替方案,决定微服务的不是框架的选择,不仅仅是restful或者rpc的接口设计风格的抉择,而更应该关注拆解,领域,限界上下文,聚合根等等一系列事物,这便是我所理解的领域驱动设计对微服务架构的指导意义。
https://mp.weixin.qq.com/s?__biz=MzI0OTIzOTMzMA==&mid=2247483947&idx=1&sn=b6b5b0c76ddf678ab361f76c5a805ef9&chksm=e995c066dee249708b192e70fcdae56ed820fe3156458ece546a16a4ae73a9270332591bf784&mpshare=1&scene=2&srcid=0729GtSlD9MY4PY5fEASD46g&from=timeline#rd
Re:从零开始的领域驱动设计的更多相关文章
- C#进阶系列——DDD领域驱动设计初探(一):聚合
前言:又有差不多半个月没写点什么了,感觉这样很对不起自己似的.今天看到一篇博文里面写道:越是忙人越有时间写博客.呵呵,似乎有点道理,博主为了证明自己也是忙人,这不就来学习下DDD这么一个听上去高大上的 ...
- C#进阶系列——DDD领域驱动设计初探(四):WCF搭建
前言:前面三篇分享了下DDD里面的两个主要特性:聚合和仓储.领域层的搭建基本完成,当然还涉及到领域事件和领域服务的部分,后面再项目搭建的过程中慢慢引入,博主的思路是先将整个架构走通,然后一步一步来添加 ...
- DDD领域驱动设计初探
DDD领域驱动设计初探1 前言:又有差不多半个月没写点什么了,感觉这样很对不起自己似的.今天看到一篇博文里面写道:越是忙人越有时间写博客.呵呵,似乎有点道理,博主为了证明自己也是忙人,这不就来学习下D ...
- DDD领域驱动设计初探(四):WCF搭建
前言:前面三篇分享了下DDD里面的两个主要特性:聚合和仓储.领域层的搭建基本完成,当然还涉及到领域事件和领域服务的部分,后面再项目搭建的过程中慢慢引入,博主的思路是先将整个架构走通,然后一步一步来添加 ...
- DDD领域驱动设计初探(一):聚合
前言:又有差不多半个月没写点什么了,感觉这样很对不起自己似的.今天看到一篇博文里面写道:越是忙人越有时间写博客.呵呵,似乎有点道理,博主为了证明自己也是忙人,这不就来学习下DDD这么一个听上去高大上的 ...
- 浅谈我对DDD领域驱动设计的理解
从遇到问题开始 当人们要做一个软件系统时,一般总是因为遇到了什么问题,然后希望通过一个软件系统来解决. 比如,我是一家企业,然后我觉得我现在线下销售自己的产品还不够,我希望能够在线上也能销售自己的产品 ...
- DDD 领域驱动设计-看我如何应对业务需求变化,愚蠢的应对?
写在前面 阅读目录: 具体业务场景 业务需求变化 "愚蠢"的应对 消息列表实现 消息详情页实现 消息发送.回复.销毁等实现 回到原点的一些思考 业务需求变化,领域模型变化了吗? 对 ...
- DDD 领域驱动设计-商品建模之路
最近在做电商业务中,有关商品业务改版的一些东西,后端的架构设计采用现在很流行的微服务,有关微服务的简单概念: 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成.系统中的各个微服务可被独 ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(3)
上一篇:<DDD 领域驱动设计-谈谈 Repository.IUnitOfWork 和 IDbContext 的实践(2)> 这篇文章主要是对 DDD.Sample 框架增加 Transa ...
随机推荐
- PS图层混合算法之三(滤色, 叠加, 柔光, 强光)
滤色模式: 作用结果和正片叠底刚好相反,它是将两个颜色的互补色的像素值相乘,然后除以255得到的最终色的像素值.通常执行滤色模式后的颜色都较浅.任何颜色和黑色执行滤色,原色不受影响;任何颜色和白色执行 ...
- 10个精选的颜色选择器Javascript脚本及其jQuery插件
Color picker即颜色选择器使我们在web开发中可能经常用到的组件,今天我们特意精选了10个超酷的颜色选择器实现,其中包括了javascript脚本 实现及其传说中的jQuery插件实现 ...
- mahout系列之---谱聚类
1.构造亲和矩阵W 2.构造度矩阵D 3.拉普拉斯矩阵L 4.计算L矩阵的第二小特征值(谱)对应的特征向量Fiedler 向量 5.以Fiedler向量作为kmean聚类的初始中心,用kmeans聚类 ...
- JNI技术简介-android学习之旅(92)
分为5步 !!!注意本地方法是java中的方法,本地函数指的是c语言中的对应函数 1.在java类中声明本地方法 2.使用javah命令,生成包含jni本地函数原型的头文件 3. 实现jni本地函数 ...
- leetCode(62)-Reverse Integer
题目: Reverse digits of an integer. Example1: x = 123, return 321 Example2: x = -123, return -321 clic ...
- Testng基本问题
Testng testng.xml suite属性说明: suite verbose="4" 命令行信息打印等级 1~5 parallel 是否多线程并发运行测试:可选值(fals ...
- JavaScript怎么把对象里的数据整合进另外一个数组里
https://blog.csdn.net/qq_26222859/article/details/70331833 var json1 = [ {"guoshui":[ 3000 ...
- es6(五):class关键字(extends,super,static)
ES5中,生成对象通过构造函数: function A(name,age){ this.name=name; this.age=age } // 在A的prototype属性上定义一个test方法,即 ...
- 微信公众号网页授权登录--JAVA
网上搜资料时,网友都说官方文档太垃圾了不易看懂,如何如何的.现在个人整理了一个通俗易懂易上手的,希望可以帮助到刚接触微信接口的你. 请看流程图!看懂图,就懂了一半了: 其实整体流程大体只需三步:用户点 ...
- Java面向对象进阶篇(包装类,不可变类)
一. Java 8的包装类 Java中的8种基本数据类型不支持面向对象的变成机制,也不具备对象的特性:没有成员变量,方法可以调用.为此,Java为这8 种基本数据类型分别提供了对应的 包装类(Byte ...