SIMD---SSE系列及效率对比
SSE(即Streaming SIMD Extension),是对由MMX指令集引进的SIMD模型的扩展。我们知道MMX有两个明显的缺点:
- 只能操作整数。
- 不能与浮点数同时运行(MMX使用FPU寄存器作为别名)。
而SSE则解决了这个问题,SSE引进了8个专用的浮点寄存器MMX0~MMX7。后来Intel又陆续推出了SSE2、SSE3、SSE4,这使得SSE指令系列同时拥有了浮点数学运算功能和整数运算功能,因此早先的MMX指令就显得有点多余了(虽然可是并行执行SSE、MMX指令来提高性能)。
SSE系列功能特点
SSE1
- 添加8个128位寄存器XMM0~MMX7.
- 操作4个单精度浮点数。
- 支持打包(Packed)和标量(Scaler)操作。
SSE2
- 添加整数向量运算,提升运行性能。
- 支持双精度浮点向量运算。
- 打包类型取消限制,支持8位、16位、32位、64位,包括整数和浮点数。
- 添加缓存控制指令。
- 添加浮点数到整数的转换指令
SSE3
- 寄存器内水平操作,例如打包在一个128位MMX寄存器内的2个64位整数,可以利用新指令对这两个整数进行算数运算。
- 多线程优化指令,在超线程下提高性能。
SSSE3
- 打包整形数据的运算加速。
SSE4
SSE4包含两个子集:SSE4.1和SSE4.2,并兼容以前的64位和IA-32指令集架构。值得指出的是SSE4增加了:1)STTNI(String and Text New Instructions)指令来帮助开发者处理字符搜索和比较,旨在加速对XML文件的解析;2)CRC32指令,帮助计算循环冗余校验值。
SSE效率对比
这里我们就只简单比较下这两个指令集的计算效率,其他功能就不在本次考虑范围内了。像前一篇博客一样,我们同样用对10000000个字符进行加操作来进行对比操作。这里我们全部用Intrinsics来对比,方便编写,不用考虑调用约定。
整数计算 Mmx vs Sse
因为整数操作只在SSE2中支持,所以实际上我们用的是sse2指令。
mmx代码:
void calculateUsingMmx(char* data, unsigned size)
{
assert(size % 8 == 0);
__m64 step = _mm_set_pi8(10, 10, 10, 10, 10, 10, 10, 10);
__m64* dst = reinterpret_cast<__m64*>(data);
for (unsigned i = 0; i < size; i += 8)
{
auto sum = _mm_adds_pi8(step, *dst);
*dst++ = sum;
}
_mm_empty();
}
sse代码:
void calculateUsingSseInt(char* data, unsigned size)
{
assert(size % 16 == 0);
__m128i step = _mm_set_epi8(10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10);
__m128i* dst = reinterpret_cast<__m128i*>(data);
for (unsigned i = 0; i < size; i += 16)
{
auto sum = _mm_add_epi8(step, *dst);
*dst++ = sum;
}
// no need to clear flags like mmx because SSE and FPU can be used at the same time.
}
浮点计算 Asm vs Sse
由于MMX指令集不包含浮点指令,因此我们x86浮点指令来对比,同样对10000000个flaot值进行加操作。
Asm代码:
void calculateUsingAsmFloat(float* data, unsigned count)
{
auto singleFloatBytes = sizeof(float);
auto step = 10.0;
__asm
{
push ecx
push edx
mov edx, data
mov ecx, count
fld step // fld only accept FPU or Memory
calcLoop:
fld [edx]
fadd st(0), st(1)
fstp [edx]
add edx, singleFloatBytes
dec ecx
jnz calcLoop
pop edx
pop ecx
}
}
Sse代码:
void calculateUsingSseFloat(float* data, unsigned count)
{
assert(count % 4 == 0);
assert(sizeof(float) == 4);
__m128 step = _mm_set_ps(10.0, 10.0, 10.0, 10.0);
__m128* dst = reinterpret_cast<__m128*>(data);
for (unsigned i = 0; i < count; i += 4)
{
__m128 sum = _mm_add_ps(step, *dst);
*dst++ = sum;
}
}
运行结果
SSE2的浮点计算对比x86浮点计算性能提升不是非常明显,但是也要考虑Intrinsics使用导致的略微性能缺失。上面两种计算方式的效率对比结果如下:
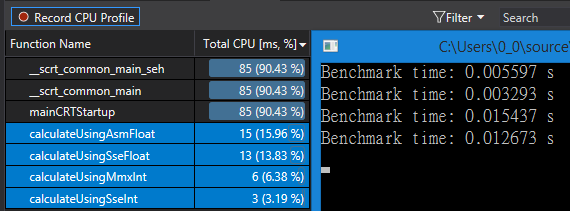
完整代码见链接。
SIMD---SSE系列及效率对比的更多相关文章
- string中Insert与Format效率对比、String与List中Contains与IndexOf的效率对比
关于string的效率,众所周知的恐怕是“+”和StringBuilder了,这些本文就不在赘述了.关于本文,请先回答以下问题(假设都是基于多次循环反复调用的情况下):1.使用Insert与Forma ...
- FileInputStream 与 BufferedInputStream 效率对比
我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3550158.html ,享受整齐的排版.有效的链接.正确的代码缩进.更好的阅读体 ...
- SSE 系列内置函数中的 shuffle 函数
SSE 系列内置函数中的 shuffle 函数 邮箱: quarrying@qq.com 博客: http://www.cnblogs.com/quarryman/ 发布时间: 2017年04月18日 ...
- java中多种写文件方式的效率对比实验
一.实验背景 最近在考虑一个问题:“如果快速地向文件中写入数据”,java提供了多种文件写入的方式,效率上各有异同,基本上可以分为如下三大类:字节流输出.字符流输出.内存文件映射输出.前两种又可以分为 ...
- golang 浮点数 取精度的效率对比
需求 浮点数取2位精度输出 实现 代码 package main import ( "time" "log" "strconv" " ...
- Snapman系统中TCC执行效率和C#执行效率对比
Snapman集合了TCC编译器可以直接编译执行C语言脚本,其脚本执行效率和C#编译程序进行效率对比,包括下面4方面: 1.函数执行效率 2.数字转换成字符串 3.字符串的叠加 4.MD5算法 这是C ...
- 查询最新记录的sql语句效率对比
在工作中,我们经常需要检索出最新条数据,能够实现该功能的sql语句很多,下面列举三个进行效率对比 本次实验的数据表中有55万条数据,以myql为例: 方式1: SELECT * FROM t_devi ...
- c#中@标志的作用 C#通过序列化实现深表复制 细说并发编程-TPL 大数据量下DataTable To List效率对比 【转载】C#工具类:实现文件操作File的工具类 异步多线程 Async .net 多线程 Thread ThreadPool Task .Net 反射学习
c#中@标志的作用 参考微软官方文档-特殊字符@,地址 https://docs.microsoft.com/zh-cn/dotnet/csharp/language-reference/toke ...
- EF 数据查询效率对比
优化的地方: 原地址:https://www.cnblogs.com/yaopengfei/p/9226328.html ①:如果仅是查询数据,并不对数据进行增.删.改操作,查询数据的时候可以取消状态 ...
随机推荐
- 在SpringBoot中配置aop
前言 aop作为spring的一个强大的功能经常被使用,aop的应用场景有很多,但是实际的应用还是需要根据实际的业务来进行实现.这里就以打印日志作为例子,在SpringBoot中配置aop 已经加入我 ...
- PCI9054 突发模式数据传输 (burst mode data transfer )
C mode target slave , 之前看PCI9054 datasheet知道这个burst mode ,也看了时序图,但是一直缺乏一个感性的认识. 今天网上买的 USB逻辑分析仪到货了,接 ...
- JavaScript获取当前日期
JavaScript获取当前日期 具体实现如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ...
- Java中的List转换成JSON报错(二)
1.错误描述 Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/loggi ...
- C# md5加密方法
public static string md5(string str, int code) { if (code == 16) //16位MD5加密(取32位加密的9~25字符) { return ...
- 【SoDiaoEditor电子病历编辑器】编辑器支持移动化
写在前面 每次写SoDiao时都是一次灵魂拷问,这么猥琐的名字,会对程序媛产生多少误导啊,我是一个正直的人,不管你信不信每个见到我的人都这么说.本次更新拖了很久,本来半个月前应该实现的,却一直拖到昨天 ...
- js中的0就是false,非0就是true及案例
在处理js代码判断真假时经常会这么写. 但fun()可能得到的是数字0,这可不是表示的没有值,但是!js中的数字0就是false,非0就是true. 于是0就被无情的当做false了. 已经被这个坑过 ...
- Python基础_函数闭包、调用、递归
这节的主要内容是函数的几个用法闭包,调用.递归. 一.函数闭包 对闭包更好的理解请看:https://www.cnblogs.com/Lin-Yi/p/7305364.html 我们来看一个简单的例子 ...
- Keras官方中文文档:keras后端Backend
所属分类:Keras Keras后端 什么是"后端" Keras是一个模型级的库,提供了快速构建深度学习网络的模块.Keras并不处理如张量乘法.卷积等底层操作.这些操作依赖于某种 ...
- js常见排序
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...