数据结构之B树、B+树(一)
B-树
什么是B-树?
B树是一种查找树,我们知道,这一类树(比如二叉搜索树,红黑树等等)最初生成的目的都是为了解决某种系统中,查找效率低的问题。B树也是如此,它最初启发于二叉搜索树,二叉搜索树的特点是每个非叶节点都只有两个孩子节点。然而这种做法会导致当数据量非常大时,二叉查找树的深度过深,搜索算法自根节点向下搜索时,需要访问的节点也就变的相当多。如果这些节点存储在外存储器中,每访问一个节点,相当于就是进行了一次I/O操作,随着树高度的增加,频繁的I/O操作一定会降低查询的效率。
这里有一个基本的概念,就是说我们从外存储器中读取信息的步骤,简单来分,大致有两步:
- 找到存储这个数据所对应的磁盘页面,这个过程是机械化的过程,需要依靠磁臂的转动,找到对应磁道,所以耗时长。
- 读取数据进内存,并实施运算,这是电子化的过程,相当快。
综上,对于外存储器的信息读取最大的时间消耗在于寻找磁盘页面。那么一个基本的想法就是能不能减少这种读取的次数,在一个磁盘页面上,多存储一些索引信息。B树的基本逻辑就是这个思路,它要改二叉为多叉,每个节点存储更多的指针信息,以降低I/O操作数。
因此,B树的目的:为了硬盘快速读取数据(降低IO操作次数)而设计的一种平衡的多路查找树。目前大多数据库及文件索引,都是使用B树或变形来存储实现。
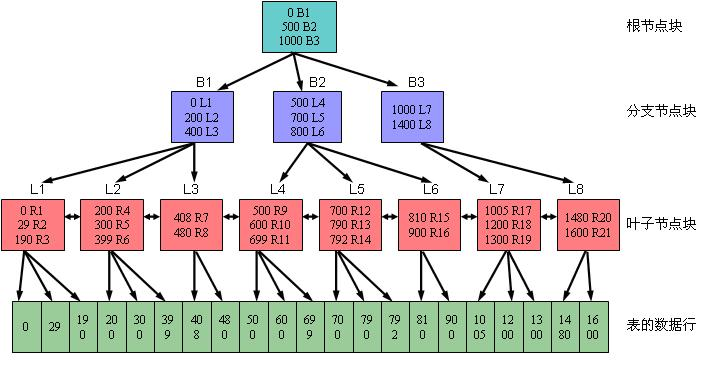
B树的定义
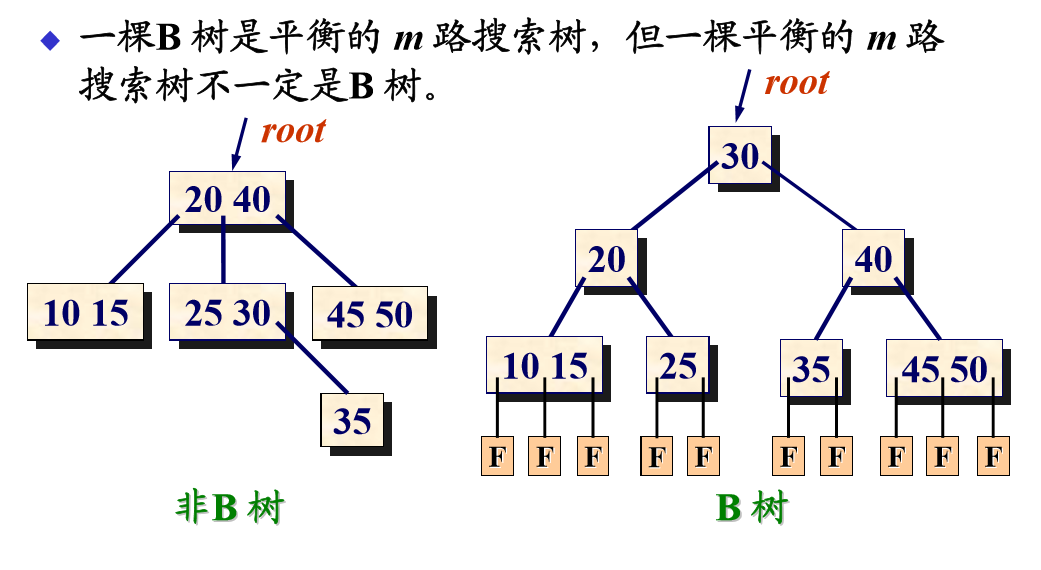
一颗m阶B-树(Balanced tree of order m)是一棵平衡的m路搜索树,它或者是空树,或者是满足以下性质的树:
- 根结点至少两个子女。
- 除根结点以外的所有结点(不包括失败结点)至少有[m/2]个子女。
- 所有失败的结点都位于同一层。
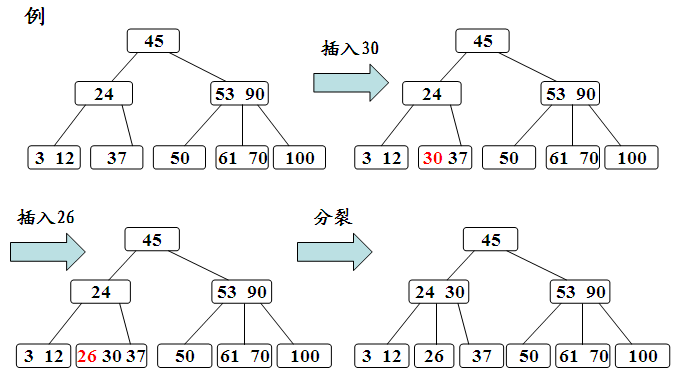
插入操作
新结点一般插在第h层,通过搜索找到对应的结点进行插入,那么根据即将插入的结点的数量又分为下面几种情况。
- 如果该结点的关键字个数没有到达m-1个,那么直接插入即可;
- 如果该结点的关键字个数已经到达了m-1个,那么根据B树的性质显然无法满足,需要将其进行分裂。分裂的规则是该结点分成两半将中间的关键字进行提升,加入到父亲结点中,但是这又可能存在父亲结点也满员的情况,则不得不向上进行回溯,甚至是要对根结点进行分裂,那么整棵树都加了一层。
其过程如下:
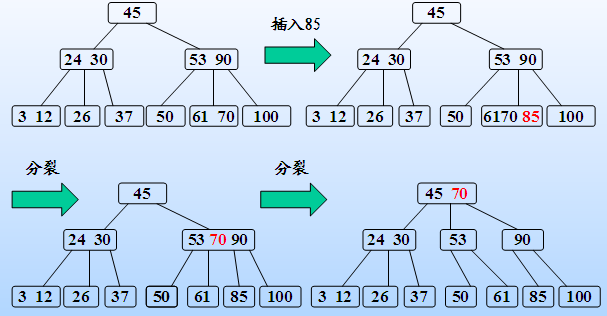
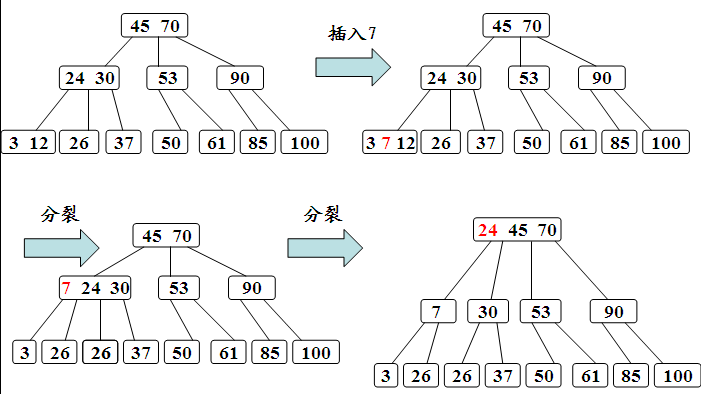
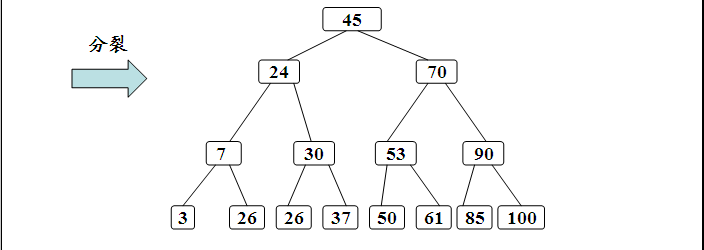
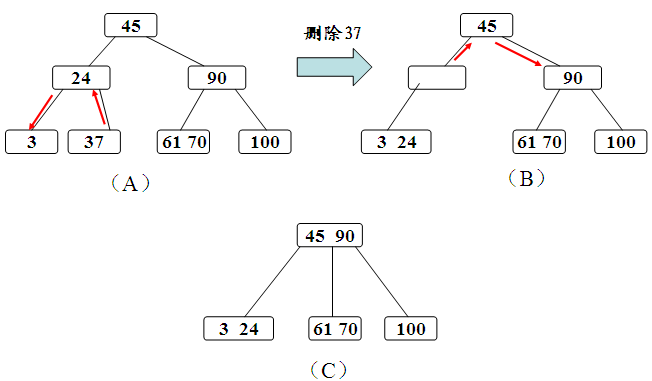
删除操作
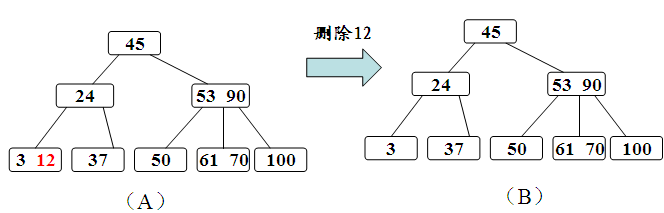
同样的,我们需要先通过搜索找到相应的值,存在则进行删除,需要考虑删除以后的情况,
- 如果该结点拥有关键字数量仍然满足B树性质,则不做任何处理;
- 如果该结点在删除关键字以后不满足B树的性质(关键字没有到达ceil(m/2)-1的数量),则需要向兄弟结点借关键字,这有分为兄弟结点的关键字数量是否足够的情况。
- 如果兄弟结点的关键字足够借给该结点,则过程为将父亲结点的关键字下移,兄弟结点的关键字上移;
- 如果兄弟结点的关键字在借出去以后也无法满足情况,即之前兄弟结点的关键字的数量为ceil(m/2)-1,借的一方的关键字数量为ceil(m/2)-2的情况,那么我们可以将该结点合并到兄弟结点中,合并之后的子结点数量少了一个,则需要将父亲结点的关键字下放,如果父亲结点不满足性质,则向上回溯;
- 其余情况参照BST中的删除。
其过程如下:

B+ 树
什么是B+树?
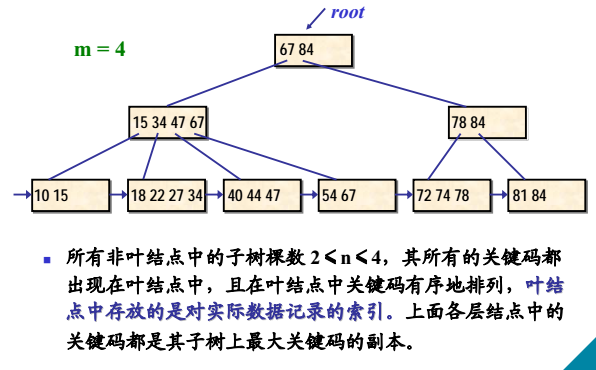
- 有n棵子树的结点中含有n个关键字,每个关键字不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的非终端结点可以看成是索引部分,结点中仅含其子树(根结点)中的最大(或最小)关键字。
通常在B+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
为什么要B+树?
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引,而B树则常用于文件索引。
B+树的定义
按 “最大关键码复写” 原则,一颗m阶B+树的结构定义如下:
- 每个结点最多有m棵子树;
- 根结点最少有1棵子树,除根结点外,其他结点至少有[m/2]棵子树;
- 有n棵子树的结点有n个关键码
- 所有叶结点在同一层,按从小到大的顺序存放全部关键码,各个叶结点顺序链接;
- 所有非叶结点可以看成叶结点的索引,结点中关键码Ki与指向子树的指针Pi构成对子树(即下一层索引块)的索引项(Ki,Pi),Ki是子树中最大的关键码。
实例:一棵4阶B+树
B+树的操作
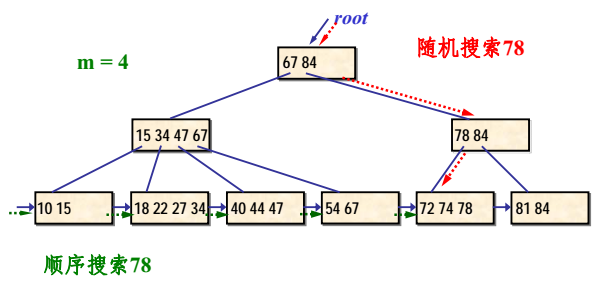
- 通常在B+树中有两个头指针:一个指向B+树的根结点,一个指向关键码最小的叶结点。
- 可对B+树进行两种搜索运算:
- 循叶结点自己拉起的链表顺序搜索
- 从根结点开始,自顶向下直至叶结点的随机搜索
- 在B+树上进行随机搜索、插入和删除的过程基本上与B树类似。只是在搜索过程中,如果非叶结点上的关键码等于给定值,搜索并不停止,而是继续沿右指针向下,一直查到叶结点上的这个关键码。
B+树的搜索示例
B+树的插入示例
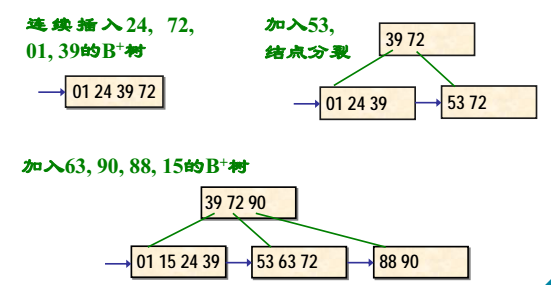
B+树的插入示例(续)
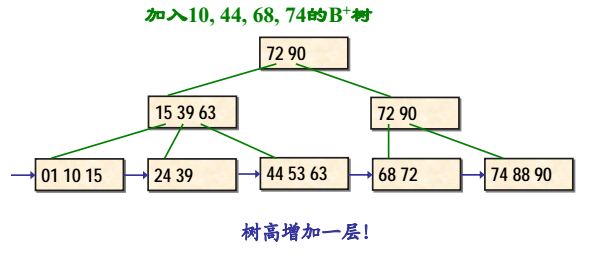
B+树的删除示例
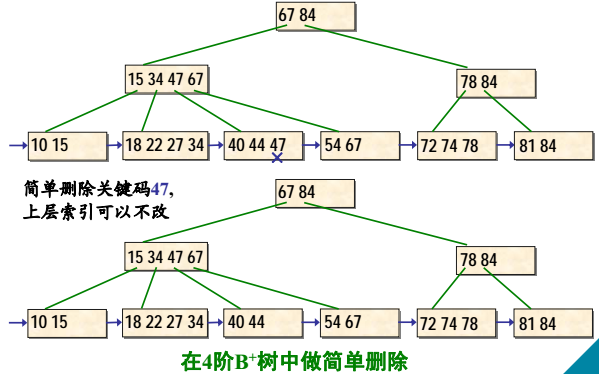
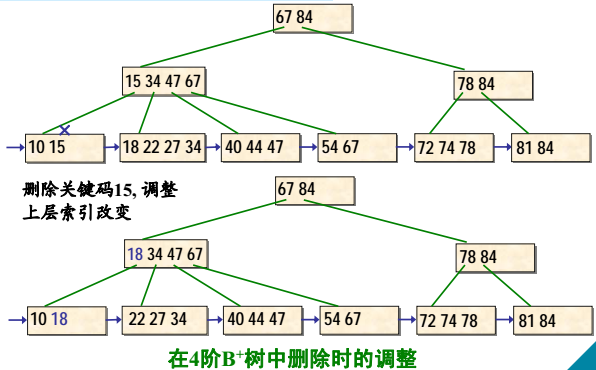
B+树的删除示例(续1)
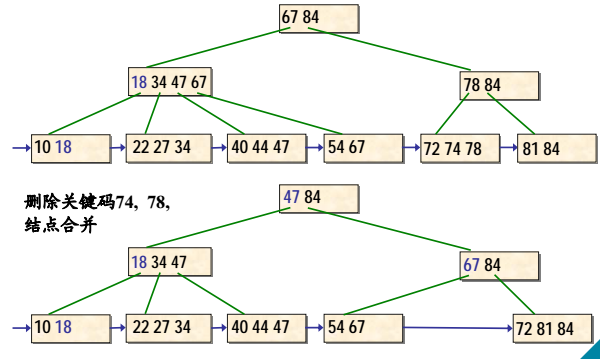
B+树的删除示例(续2)
B+树的特性
- 所有关键字都出现在叶结点的链表中,且链表中的关键字恰好是有序的;
- 搜索不可能在非叶结点命中;
- 非叶结点相当于叶结点的索引(稀疏索引),叶结点相当于是存储实际数据记录的索引(稠密索引);
- 更适合文件索引系统。
- 应用案例:Berkerly DB,SQlite,Mysql数据库。
MySQL的B-Tree索引(技术上说B+Tree)
在 MySQL 中,主要有四种类型的索引,分别为: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。我们主要分析B-Tree 索引。
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node(叶子节点) ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引。当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个Leaf Node 上面出了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息(增加了顺序访问指针),这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
下面主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式:
MyISAM索引实现:
1)主键索引:
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的原理图:
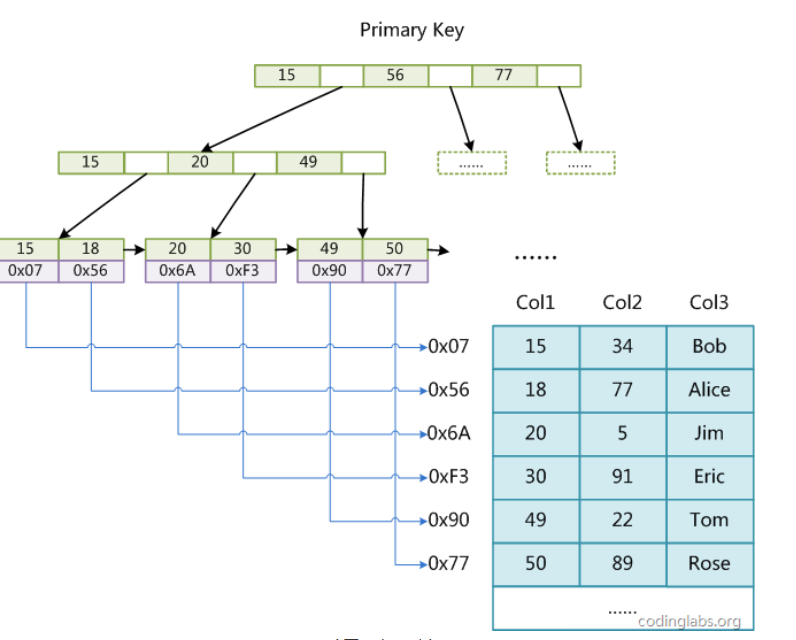
这里设表一共有三列,假设我们以Col1为主键,图myisam1是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。
2)辅助索引(Secondary key)
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
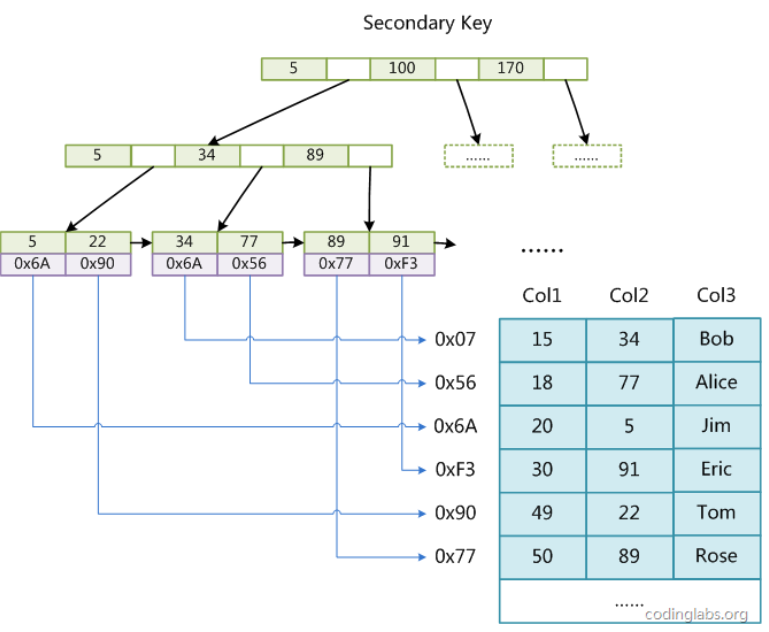
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同.
1)主键索引:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
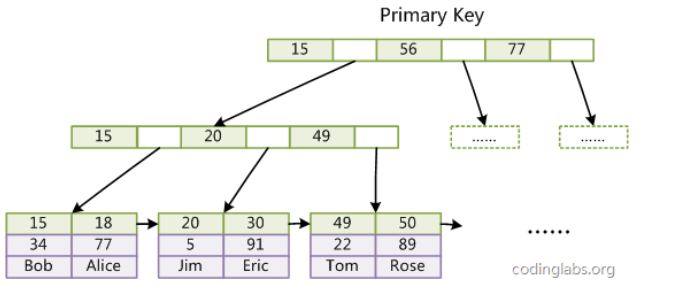
可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
2). InnoDB的辅助索引
InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
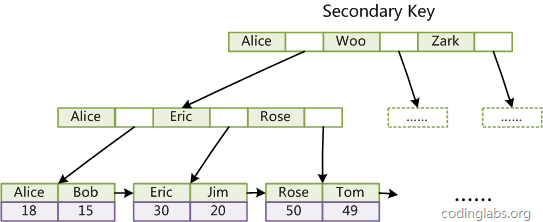
InnoDB 表是基于聚簇索引建立的。因此InnoDB 的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
InnoDB索引和MyISAM索引的区别:
- 主索引的区别:InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
- 辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
数据结构之B树、B+树(一)的更多相关文章
- 数据结构图文解析之:树的简介及二叉排序树C++模板实现.
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 【Todo】字符串相关的各种算法,以及用到的各种数据结构,包括前缀树后缀树等各种树
另开一文分析字符串相关的各种算法,以及用到的各种数据结构,包括前缀树后缀树等各种树. 先来一个汇总, 算法: 本文中提到的字符串匹配算法有:KMP, BM, Horspool, Sunday, BF, ...
- 一步一步学数据结构之1--n(通用树)
今天来看大家介绍树,树是一种非线性的数据结构,树是由n个结点组成的有限集合,如果n=0,称为空树:如果n>0,则:有一个特定的称之为根的结点,它只有直接后继,但没有直接前驱:除根以外的其他结点划 ...
- C语言数据结构基础学习笔记——B树
2-3树:是一种多路查找树,包含2结点和3结点两种结点,其所有叶子结点都在同一层次. 2结点:包含一个关键字和两个孩子(或没有孩子),其左孩子的值小于该结点,右孩子的值大于该结点. 3结点:包含两个关 ...
- 9-11-Trie树/字典树/前缀树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第9章 查找 - Trie树/字典树/前缀树(键树) ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚 ...
- 20172302 《Java软件结构与数据结构》实验二:树实验报告
课程:<Java软件结构与数据结构> 班级: 1723 姓名: 侯泽洋 学号:20172302 实验教师:王志强老师 实验日期:2018年11月5日 必修/选修: 必修 实验内容 (1)参 ...
- hdu 2527:Safe Or Unsafe(数据结构,哈夫曼树,求WPL)
Safe Or Unsafe Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- 数据结构(十一)B树
之前的二叉排序树,平衡二叉树都是基于二叉树的实现,但是在搜索过程中,效率和树的深度有关,所以就想到把二叉树改为多叉树,B树和B+树都基于多叉树的实现 多路查找树 B树 定义 应用场景 B+树 ...
- 空间划分的数据结构(网格/四叉树/八叉树/BSP树/k-d树/BVH/自定义划分)
目录 网格 (Grid) 网格的应用 四叉树/八叉树 (Quadtree/Octree) 四叉树/八叉树的应用 BSP树 (Binary Space Partitioning Tree) 判断点在平面 ...
- 19-看图理解数据结构与算法系列(Radix树)
Radix树 Radix树,即基数树,也称压缩前缀树,是一种提供key-value存储查找的数据结构.与Trie不同的是,它对Trie树进行了空间优化,只有一个子节点的中间节点将被压缩.同样的,Rad ...
随机推荐
- 关于搭建MyBatis框架(二)
由于在[关于使用Mybatis的使用说明(一)http://www.cnblogs.com/zdb292034/p/8675766.html]中存在不太完善地方,通过此片文档进行修订: 阅读指南:(1 ...
- 学习ASP.NET Core Razor 编程系列四——Asp.Net Core Razor列表模板页面
学习ASP.NET Core Razor 编程系列目录 学习ASP.NET Core Razor 编程系列一 学习ASP.NET Core Razor 编程系列二——添加一个实体 学习ASP.NET ...
- javascript原型链__proto__属性的理解
在javascript中,按照惯例,构造函数始终都应该以一个大写字母开头,而非构造函数则应该以一个小写字母开头.一个方法使用new操作符创建,例如下面代码块中的Person1(可以吧Person1看做 ...
- java排序算法之冒泡排序(Bubble Sort)
java排序算法之冒泡排序(Bubble Sort) 原理:比较两个相邻的元素,将值大的元素交换至右端. 思路:依次比较相邻的两个数,将小数放在前面,大数放在后面.即在第一趟:首先比较第1个和第2个数 ...
- 用Java语言实现简单的词法分析器
编译原理中的词法分析算是很重要的一个部分,原理比较简单,不过网上大部分都是用C语言或者C++来编写,笔者近期在学习Java,故用Java语言实现了简单的词法分析器. 要分析的代码段如下: 输出结果如下 ...
- Python 黑客相关电子资源和书籍推荐
原创 2017-06-03 玄魂工作室 玄魂工作室 继续上一次的Python编程入门的资源推荐,本次为大家推荐的是Python网络安全相关的资源和书籍. 在去年的双11送书的时候,其实送过几本Pyth ...
- Python内置函数(9)——int
英文文档: class int(x=0) class int(x, base=10) Return an integer object constructed from a number or str ...
- c#:实现动态编译,并实现动态MultiProcess功能(来自python multiprocess的想法)
由于之前一直遇到一些关于并行进行数据处理的时效果往往不好,不管是c#还是java程序都是一样,但是在Python中通过multiprocess实现同样的功能时,却发现确实可以提高程序运行的性能,及服务 ...
- flask 操作mysql的两种方式-sql操作
flask 操作mysql的两种方式-sql操作 一.用常规的sql语句操作 # coding=utf-8 # model.py import MySQLdb def get_conn(): conn ...
- www的构建技术
www的构建技术分别是: html超文本标记语言,页面的文本显示 http超文本传输协议,信息传输转移的约定 url统一资源定位符,客户端浏览超文本的地址集合