POI生成word文档完整案例及讲解
一,网上的API讲解
其实POI的生成Word文档的规则就是先把获取到的数据转成xml格式的数据,然后通过xpath解析表单式的应用取值,判断等等,然后在把取到的值放到word文档中,最后在输出来。
1.1,参考一
1、poi之word文档结构介绍之正文段落
一个文档包含多个段落,一个段落包含多个Runs,一个Runs包含多个Run,Run是文档的最小单元
获取所有段落:List<XWPFParagraph> paragraphs = word.getParagraphs();
获取一个段落中的所有Runs:List<XWPFRun> xwpfRuns = xwpfParagraph.getRuns();
获取一个Runs中的一个Run:XWPFRun run = xwpfRuns.get(index);
2、poi之word文档结构介绍之正文表格
一个文档包含多个表格,一个表格包含多行,一行包含多列(格),每一格的内容相当于一个完整的文档
获取所有表格:List<XWPFTable> xwpfTables = doc.getTables();
获取一个表格中的所有行:List<XWPFTableRow> xwpfTableRows = xwpfTable.getRows();
获取一行中的所有列:List<XWPFTableCell> xwpfTableCells = xwpfTableRow.getTableCells();
获取一格里的内容:List<XWPFParagraph> paragraphs = xwpfTableCell.getParagraphs();
之后和正文段落一样
注:
- 表格的一格相当于一个完整的docx文档,只是没有页眉和页脚。里面可以有表格,使用xwpfTableCell.getTables()获取,and so on
- 在poi文档中段落和表格是完全分开的,如果在两个段落中有一个表格,在poi中是没办法确定表格在段落中间的。(当然除非你本来知道了,这句是废话)。只有文档的格式固定,才能正确的得到文档的结构
3、poi之word文档结构介绍之页眉:
一个文档可以有多个页眉(不知道怎么会有多个页眉。。。),页眉里面可以包含段落和表格
获取文档的页眉:List<XWPFHeader> headerList = doc.getHeaderList();
获取页眉里的所有段落:List<XWPFParagraph> paras = header.getParagraphs();
获取页眉里的所有表格:List<XWPFTable> tables = header.getTables();
之后就一样了
4、poi之word文档结构介绍之页脚:
页脚和页眉基本类似,可以获取表示页数的角标
1.2,参考二
POI操作Word简介
POI读写Excel功能强大、操作简单。但是POI操作时,一般只用它读取word文档,POI只能能够创建简单的word文档,相对而言POI操作时的功能太少。
(2)POI创建Word文档的简单示例
XWPFDocument doc = new XWPFDocument();// 创建Word文件XWPFParagraph p = doc.createParagraph();// 新建一个段落p.setAlignment(ParagraphAlignment.CENTER);// 设置段落的对齐方式p.setBorderBottom(Borders.DOUBLE);//设置下边框p.setBorderTop(Borders.DOUBLE);//设置上边框p.setBorderRight(Borders.DOUBLE);//设置右边框p.setBorderLeft(Borders.DOUBLE);//设置左边框XWPFRun r = p.createRun();//创建段落文本r.setText("POI创建的Word段落文本");r.setBold(true);//设置为粗体r.setColor("FF0000");//设置颜色p = doc.createParagraph();// 新建一个段落r = p.createRun();r.setText("POI读写Excel功能强大、操作简单。");XWPFTable table= doc.createTable(3, 3);//创建一个表格table.getRow(0).getCell(0).setText("表格1");table.getRow(1).getCell(1).setText("表格2");table.getRow(2).getCell(2).setText("表格3");FileOutputStream out = newFileOutputStream("d:\\POI\\sample.doc");doc.write(out);out.close();

(3)POI读取Word文档里的文字
FileInputStream stream = newFileInputStream("d:\\POI\\sample.doc");XWPFDocument doc = new XWPFDocument(stream);// 创建Word文件for(XWPFParagraph p : doc.getParagraphs())//遍历段落{System.out.print(p.getParagraphText());}for(XWPFTable table : doc.getTables())//遍历表格{for(XWPFTableRow row : table.getRows()){for(XWPFTableCell cell : row.getTableCells()){System.out.print(cell.getText());}}
1.3,参考三,分段混乱
题:在操作POI替换world时发现getRuns将我们预设的${product}自动切换成了
${product, }]
${product }
成了两个部分- 1
- 2
- 3

解决方法一。(未尝试)
强制把List中的内容合并成一个字符串,替换内容后,把段落中的XWPFRun全部remove掉,然后新建一个含有替换后内容的XPWFRun,并赋给当前段落。
解决方法二.
请用复制粘贴把你的${product}添加进world文档里面即可解决,不要手打 目前发现复制粘贴是没有问题的,感觉像是poi的一个bug不知道立贴为证。
注意:${这里尽量不要存中文,否在还出现上面情况}
二,项目应用
2.1,判断生成word的条件
private boolean getXpathRes(String json,String xpathRule){
boolean isTrue = false;
try {
JSONObject obj = getGoodJson(json, json.replaceAll("\n", "").replaceAll("\"null\"", "\"\"").replaceAll(":null,", ":\"\",").replaceAll(" \"", "\""));
XMLSerializer serializer = new XMLSerializer();
String xml = serializer.write(obj,"UTF-8");
log.info("测试用的,记得删除"+xml);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setValidating(false);
DocumentBuilder db;
db = dbf.newDocumentBuilder();
StringReader stringReader = new StringReader(xml);
InputSource inputSource = new InputSource(stringReader);
Document doc;
doc = db.parse(inputSource);
XPathFactory factory = XPathFactory.newInstance();
XPath xpath = factory.newXPath();
isTrue = (Boolean) xpath.evaluate(xpathRule, doc,XPathConstants.BOOLEAN);
} catch (Exception e) {
log.info("合同解析生成XML报错:"+e.getMessage());
}finally{
return isTrue;
}
// return true;
}

2.1.1,下面就是根据从数据库中取到值,判断规则,和json数据做对比的,就是json数据中有没有数据库中要的值。判断规则是xpath的规则运算符。
JSONObject obj = getGoodJson(json, json.replaceAll("\n", "").replaceAll("\"null\"", "\"\"").replaceAll(":null,", ":\"\",").replaceAll(" \"", "\""));
XMLSerializer serializer = new XMLSerializer();
String xml = serializer.write(obj,"UTF-8");
--把json格式的数据以xml的格式输出
首先得到:得到 DOM 解析器的工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
然后从 DOM 工厂获得 DOM 解析器
dbf.setValidating(false);默认是false
DocumentBuilder db;
db = dbf.newDocumentBuilder();
当你有一组应用程序接口(API)只允许用Writer或Reader作为输入,但你又想使用String,这时可以用StringWriter或StringReader。
当读入文件时也一样。可以用StringReader代替Reader来哄骗API,而不必非得从某种形式的文件中读入。StringReader的构造器要求一个String参数。例如:xmlReader.parse(new InputSource(new StringReader(xmlStr)));
StringReader stringReader = new StringReader(xml);
--- 把符合xml的String转成document对象被java程序解读
StringReader stringReader = new StringReader(xml);
InputSource inputSource = new InputSource(stringReader);
Document doc;
doc = db.parse(inputSource);
--用xpath解析
--生成xpath对象
XPathFactory factory = XPathFactory.newInstance();
XPath xpath = factory.newXPath();
在 Java 中计算 XPath 表达式时,第二个参数指定需要的返回类型。有五种可能,都在javax.xml.xpath.XPathConstants 类中命名了常量:
XPathConstants.NODESET
XPathConstants.BOOLEAN
XPathConstants.NUMBER
XPathConstants.STRING
XPathConstants.NODE 获取节点 node.getTextContent() 获得节点的内容
xpathRule:数据库中存储的
//industrySubType!='20' and //industrySubType!='21' and //industrySubType!='22' and //industrySubType!='23' and //industrySubType!='26' and //industrySubType!='27' and //industrySubType!='28' and //industrySubType!='29' and //industrySubType!='30' and //industrySubType!='148' and //industrySubType!='31' and //industrySubType!='32' and //industrySubType!='37' and //industrySubType!='38' and //industrySubType!='39' and //industrySubType!='11' and //industrySubType!='12' and //industrySubType!='13' and //industrySubType!='14' and //industrySubType!='15' and //industrySubType!='16'
//标示节点中的所有的xml节点
doc就是经过一系列处理,把json数据转化成document对象,并且能被xpath解读的对象:
XPathConstants.BOOLEAN:是返回值,有这个数据就返回true,没有就是false
isTrue = (Boolean) xpath.evaluate(xpathRule, doc,XPathConstants.BOOLEAN);
这里需要见xpath的解析规则
2.2,获取模板之后,开始获取里面的参数,这个参数是在数据库中配置的。
private List<Map<String,Object>> getTemplateParam(List<String> templatNameList,
String workOrderId, String productCode,String contractNum,long merchantCode,boolean isMainFlag) throws Exception
{
log.info("======获取模板原始参数开始===获得的模板有templatNameList=="+templatNameList.toString()+"======");
List<EcontractTemplateParamsqlAdvanced> aTemplateParamSqlList = new ArrayList<EcontractTemplateParamsqlAdvanced>();
List<Map<String,Object>> aTemplateParamList = new ArrayList<Map<String,Object>>();
List<EcontractTemplateParamAdvanced> orginParamList = new ArrayList<EcontractTemplateParamAdvanced>();
Map<String, Object> rsMap = null;
Map<String,Object> queryTemplateParamSql = new HashMap<String,Object>();
Map<String,Object> queryOriginParam = new HashMap<String,Object>();
//获取每个模板的参数
for(String templateName : templatNameList)
{
log.info("======获取模板原始参数中===获得的模板有templatNameList=="+templatNameList.toString()+"==成功获取到模板文档====");
queryOriginParam.put("templateName", templateName.split(",")[0]);
//aTemplateParamSqlList = econtractTemplateParamsqlAdvancedService.queryEcontractTemplateParamsqlAdvancedByMap(queryTemplateParamSql);
//获取每个模板需要替换的参数
orginParamList = econtractTemplateParamAdvancedService.queryEcontractTemplateParamAdvancedByMap(queryOriginParam);
Map<String,String> searchMap = new HashMap<String,String>();
searchMap.put("orderId", templateName.split(",")[1]);
WorkorderDetail workOrderDeatil = workorderDetailService.findWorkorderDetailByMap(searchMap);
String json = workOrderDeatil.getProductParam();
String jsonStr = json.replaceAll("\n", "").replaceAll("\"null\"", "\"\"").replaceAll(":null,", ":\"\",").replaceAll(" \"", "\"");
rsMap = new HashMap<String,Object>();
Map<String, Object> res = getGoodJsonMap(json, jsonStr);
String xpath="";
for(EcontractTemplateParamAdvanced paramAdvancde:orginParamList){
xpath = paramAdvancde.getMethodParam();
if(res.get(paramAdvancde.getFieldName())==null){
//新添加一个实现方式,是先判断是否满足前提条件,如果满足再查询数据,不满足就直接返回/
boolean judgeSuccess = false;//判断前提条件是否成立,false-不成立,true-成立
if(!StringUtils.isEmpty(xpath)&&xpath.indexOf("@&@")!=-1 || !StringUtils.isEmpty(xpath)&&xpath.indexOf("@&&@")!=-1){//存在这个符号,表示需要判断前提条件,@&@,前提条件,需要取的值的字段,单位
// String[] methodParamArray = xpath.split(",");
String[] methodParamArray = null;
if(!StringUtils.isEmpty(xpath)&&xpath.indexOf("@&&@")!=-1){//@&&@,前提条件中存在特殊符号
methodParamArray = xpath.split(";");
}else{
methodParamArray = xpath.split(",");
}
if(getXpathRes(json,methodParamArray[1])){
judgeSuccess = true;//需要判断前提条件
}else{
String unit = methodParamArray[methodParamArray.length-1];
if("null".equals(unit)){//没有单位,在最后是单位
rsMap.put(paramAdvancde.getFieldName(),"/");
}else if("instalmentsUnitToShow".equals(unit)){//分期付款特殊处理
rsMap.put(paramAdvancde.getFieldName(),getInstalmentsUnit(methodParamArray));
}else if("hasNotUnit".equals(unit)){//针对单笔最高和单笔最低
rsMap.put(paramAdvancde.getFieldName(),"");
}else{//有单位
rsMap.put(paramAdvancde.getFieldName(),"/"+unit);
}
}
}else{//不需要判断前提条件
judgeSuccess = true;
}
// 此xpath表达式是用来做逻辑判断的
if(!StringUtils.isEmpty(xpath) && xpath.indexOf("=")!=-1 && judgeSuccess && xpath.indexOf("@&@")==-1 && xpath.indexOf("@&&@")==-1){//有=号并且不存在@&@,因为前提条件中会有=号
//快易花商户合同里不再是黑白框 应该是√和X 订单中各期商户补贴=0或空值时,为X,费率为/; 非空时,为√,费率取对应的值
if(xpath.indexOf("xx=xx")!=-1){//快易花中需要用替换的
if(getXpathRes(json,xpath)){
rsMap.put(paramAdvancde.getFieldName(),"√");
}else{
rsMap.put(paramAdvancde.getFieldName(),"×");
}
}else{//其他合同还是打■或□,快易花合同中部分也需要用■或□
if(getXpathRes(json,xpath)){
rsMap.put(paramAdvancde.getFieldName(),"■");
}else{
rsMap.put(paramAdvancde.getFieldName(),"□");
}
}
}else if(!StringUtils.isEmpty(xpath)&& (xpath.indexOf("=")==-1 || xpath.indexOf("@&@")!=-1 || xpath.indexOf("@&&@")!=-1)&&judgeSuccess){//没有=号或者有@&@符号的规则也需要走以下逻辑
//如果call_method为空,则直接利用xpath进行取值替换
String str =getXpathValue(json,paramAdvancde.getMethodParam());
if(StringUtils.isEmpty(paramAdvancde.getCallMethod())){
rsMap.put(paramAdvancde.getFieldName(),str);
}else{
// 用来判断机具类型的,固定POS、移动POS、快刷、POS附件
// JSONObject obj = (JSONObject) JSONSerializer.toJSON(jsonStr);
JSONObject obj = getGoodJson(json, jsonStr);
JSONArray productListJsonArray = obj.getJSONArray("productList");
JSONArray PriSinBillCustomDataStr=null;
JSONArray PubSinBankCustomDataStr=null;
JSONArray PriBatchBankCustomDataStr=null;
JSONArray PubBatchBankCustomDataStr=null;
if("dspayfinancialupdatewordfir.docx".equals(templateName.split(",")[0])&&productListJsonArray.size()>0){
JSONObject job = productListJsonArray.getJSONObject(0); // 遍历 jsonarray 数组,把每一个对象转成 json 对象
if(job.containsKey("PriSinBillCustomDataStr")&&job.getString("PriSinBillCustomDataStr")!=null&&xpath.indexOf("PriSinBillCustomDataStr")>-1){
String PriBill =job.get("PriSinBillCustomDataStr").toString()==null?"":String.valueOf(job.get("PriSinBillCustomDataStr"));
PriSinBillCustomDataStr = JSONArray.fromObject(PriBill);
}else if(job.containsKey("PubSinBankCustomDataStr")&&job.getString("PubSinBankCustomDataStr")!=null&&xpath.indexOf("PubSinBankCustomDataStr")>-1){
String PubBank =job.get("PubSinBankCustomDataStr").toString()==null?"":String.valueOf(job.get("PubSinBankCustomDataStr"));
PubSinBankCustomDataStr = JSONArray.fromObject(PubBank);
}else if(job.containsKey("PriBatchBankCustomDataStr")&&job.getString("PriBatchBankCustomDataStr")!=null&&xpath.indexOf("PriBatchBankCustomDataStr")>-1){
String PriBatch =job.get("PriBatchBankCustomDataStr").toString()==null?"":String.valueOf(job.get("PriBatchBankCustomDataStr"));
PriBatchBankCustomDataStr = JSONArray.fromObject(PriBatch);
}else if(job.containsKey("PubBatchBankCustomDataStr")&&job.getString("PubBatchBankCustomDataStr")!=null&&xpath.indexOf("PubBatchBankCustomDataStr")>-1){
String PubBatch =job.get("PubBatchBankCustomDataStr").toString()==null?"":String.valueOf(job.get("PubBatchBankCustomDataStr"));
PubBatchBankCustomDataStr = JSONArray.fromObject(PubBatch);
}
}
JSONArray terminalArray =new JSONArray();
JSONObject merchantFinanceObject = new JSONObject();//只有主协议需要这个
String checkTemplateNameValue = checkTemplateName(templateName);
// 如果产品涉及到终端直接去terminobjects中取值
if("1".equals(checkTemplateNameValue)){//去terminobjects中取值
JSONObject terminalObject = (JSONObject)productListJsonArray.get(0);
if((JSONArray)terminalObject.get("terminalObjects")!= null){//防止空指针
terminalArray =(JSONArray)terminalObject.get("terminalObjects");
}
/*}
// 非终端相关的直接去productList中取值
else{
terminalArray=productListJsonArray;*/
}else if("2".equals(checkTemplateNameValue)){//去merchantFinance取值
if(obj.containsKey("merchantFinance")){
merchantFinanceObject = obj.getJSONObject("merchantFinance");//主协议的时候需要用到
}
}
if(productListJsonArray==null){
rsMap.put(paramAdvancde.getFieldName(),"");
}else{
String methodParam =paramAdvancde.getMethodParam();
// String[] methodParamArray = methodParam.split(",");
String[] methodParamArray = null;
if(!StringUtils.isEmpty(xpath)&&xpath.indexOf("@&&@")!=-1){//@&&@,前提条件中存在特殊符号
methodParamArray = methodParam.split(";");
}else{
methodParamArray = methodParam.split(",");//tina623
}
Object[] args = null;
if("1".equals(checkTemplateNameValue)){//如果产品涉及到终端直接去terminobjects中取值
if(paramAdvancde.getCallMethod().startsWith("get")){
args = new Object[methodParamArray.length+2];
args[0]=productListJsonArray;
args[1]=terminalArray;//主协议的时候,merchantFinance取的arraylist封装在这里
for(int i=2;i<methodParamArray.length+2;i++){
args[i]=methodParamArray[i-2];
}
}else if(paramAdvancde.getCallMethod().startsWith("set")){
args = new Object[methodParamArray.length+1];
args[0]=templateName.split(",")[1];
for(int i=1;i<methodParamArray.length+1;i++){
args[i]=methodParamArray[i-1];
}
}
}else if("2".equals(checkTemplateNameValue)){//主协议---主协议的时候,merchantFinance取的arraylist封装在这里
if(paramAdvancde.getCallMethod().startsWith("get")){
args = new Object[methodParamArray.length+2];
args[0]=productListJsonArray;
args[1]=merchantFinanceObject;//主协议的时候,merchantFinance取的arraylist封装在这里
for(int i=2;i<methodParamArray.length+2;i++){
args[i]=methodParamArray[i-2];
}
}else if(paramAdvancde.getCallMethod().startsWith("set")){
args = new Object[methodParamArray.length+1];
args[0]=templateName.split(",")[1];
for(int i=1;i<methodParamArray.length+1;i++){
args[i]=methodParamArray[i-1];
}
}
}else{
args = new Object[methodParamArray.length+1];
// 约定取值方法以get起始的话
if(paramAdvancde.getCallMethod().startsWith("get")){
args[0]=productListJsonArray;
}else if(paramAdvancde.getCallMethod().startsWith("set")){
args[0]=templateName.split(",")[1];
}else if("dspayfinancialupdatewordfir.docx".equals(templateName.split(",")[0])&¶mAdvancde.getCallMethod().startsWith("twoGet")){
if(xpath.indexOf("PriSinBillCustomDataStr")>-1){
args[0]=PriSinBillCustomDataStr;
}else if(xpath.indexOf("PubSinBankCustomDataStr")>-1){
args[0]=PubSinBankCustomDataStr;
}else if(xpath.indexOf("PriBatchBankCustomDataStr")>-1){
args[0]=PriBatchBankCustomDataStr;
}else if(xpath.indexOf("PubBatchBankCustomDataStr")>-1){
args[0]=PubBatchBankCustomDataStr;
}
}
for(int i=1;i<methodParamArray.length+1;i++){
args[i]=methodParamArray[i-1];
}
}
Class[] argsClass = new Class[args.length];
for (int i = 0, j = args.length; i < j; i++) {
if(args[i]!=null){//避免空指针
argsClass[i] = args[i].getClass();
}
}
try{
Method method = crmContractUtil.getClass().getMethod(paramAdvancde.getCallMethod(),argsClass);
rsMap.put(paramAdvancde.getFieldName(),method.invoke(crmContractUtil, args));
}catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
else{
if(res.get(paramAdvancde.getFieldName())!=null && !StringUtils.isEmpty(res.get(paramAdvancde.getFieldName()).toString())){
rsMap.put(paramAdvancde.getFieldName(), res.get(paramAdvancde.getFieldName()));
}else{
rsMap.put(paramAdvancde.getFieldName(), "/");//如果获取的值为空,自动赋值/
}
}
}
rsMap.put("templateName", templateName.split(",")[0]);
rsMap = converMap(rsMap,contractNum,merchantCode,isMainFlag,res);//封装一些需要计算的数据
aTemplateParamList.add(rsMap);
}
log.info("获取模板原始参数成功..aTemplateParamList===="+aTemplateParamList.toString()+"===========");
return aTemplateParamList;
}
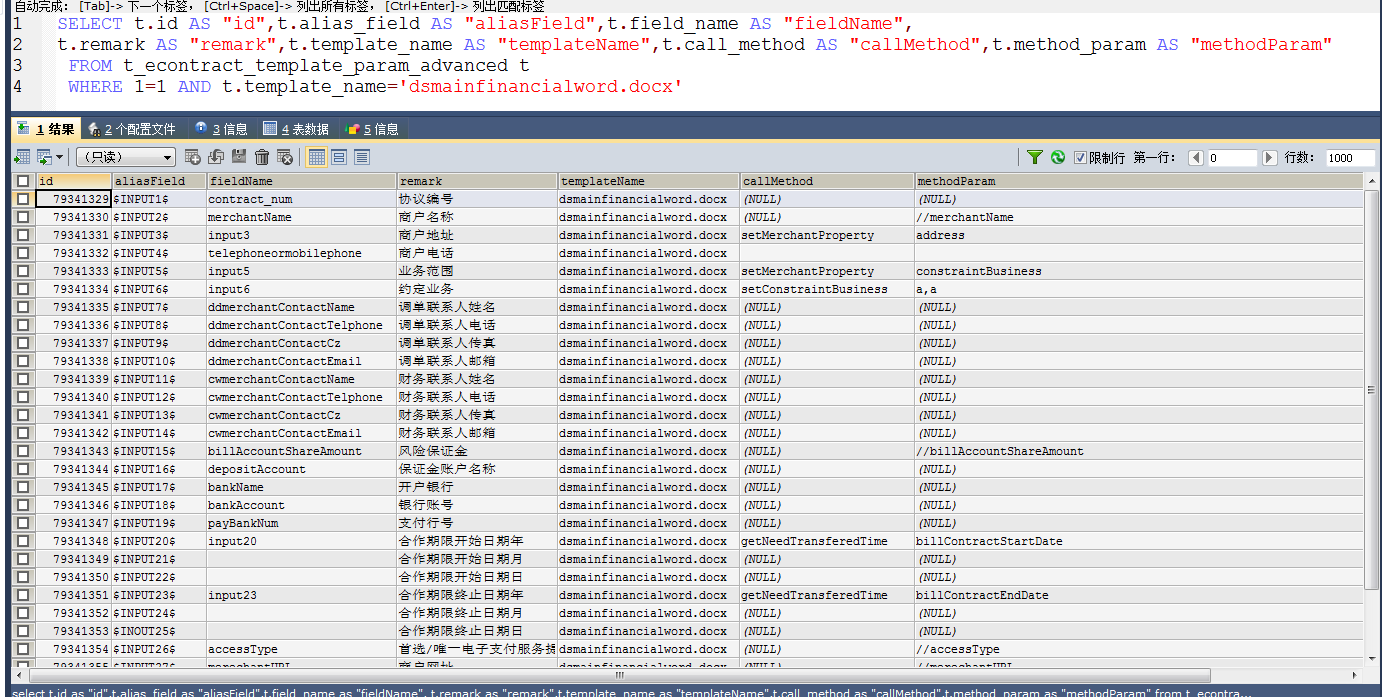
@SuppressWarnings("finally")
private String getXpathValue(String json,String xpathRule){
String xpathValue = "/";
try {
JSONObject obj = getGoodJson(json, json.replaceAll("\n", "").replaceAll("\"null\"", "\"\"").replaceAll(":null,", ":\"\",").replaceAll(" \"", "\""));
XMLSerializer serializer = new XMLSerializer();
String xml = serializer.write(obj,"UTF-8");
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setValidating(false);
DocumentBuilder db;
db = dbf.newDocumentBuilder();
StringReader stringReader = new StringReader(xml);
InputSource inputSource = new InputSource(stringReader);
Document doc;
doc = db.parse(inputSource);
XPathFactory factory = XPathFactory.newInstance();
XPath xpath = factory.newXPath();
Node node = (Node)xpath.evaluate(xpathRule, doc,XPathConstants.NODE);
if(node==null){
return "/";
}
else{
if(StringUtils.isEmpty(node.getTextContent())){
return "/";
}else{
xpathValue = node.getTextContent();
return node.getTextContent();
}
}
} catch (Exception e) {
log.info("合同解析生成XML报错,xpathRule==="+xpathRule);
return "/";
}finally{
return xpathValue;
}
// return "/";
}
划红线的是和一开始的是不一样的,这里是获取json转化过来的xml的文档的node节点的值的。
而
isTrue = (Boolean) xpath.evaluate(xpathRule, doc,XPathConstants.BOOLEAN);
是通过xpath判断
xpathRule有没有在经过封装的xml文件的document里面的。
orginParamList = econtractTemplateParamAdvancedService.queryEcontractTemplateParamAdvancedByMap(queryOriginParam);
--根据模板名称获取
res里面装的是json转化成的map数据,根据数据库查出来的key值,去取map中的value值。并全部放在map中来。
根据数据库中参数的设置来看取值的逻辑
取值逻辑1:
callmethod 空 methodparam 空
则什么都不往map中放
取值逻辑2:
callmethod 空 methodparam 有值:比如//merchantName
它的取值逻辑主要也是用到了上面的xpath的取值逻辑。
则去json转化的map中查找,找到数值后则放进map中来
取值逻辑3:
callmethod 空 methodparam 有值:比如//isApiPayToBank=1 or //isApiPayToBill=1 or //isBatchApiPayToBank=1
其实它和2的取值逻辑是一样的,只不过xpath的表单式不一样而已。
取值逻辑4:
callmethod 有值,方法名比如setMerchantProperty methodparam 有值:比如参数address或者IpAddress_sin_99bill/IpAddress_sin_ban/IpAddress_bat_ban 可以放值多个参数
这个一般是在json格式的数据中没有这个值,但是还要获取这个数据,通过反射找到setMerchantProperty 这个方法从数据库中其它表中来获取。
address它是参数,需要根据它往反射类中的反射方法中传递的参数。
而存在map中的key值则是word文档中的命名规则,比如input。value值则是从数据库中获取的。
则会通过反射的方法来获取数值。
可以看出来只要是input开头都是通过这个方法获取的。这个主要是为了给替换做准备的。
反射的逻辑详见
反射的一个案例分析
取值逻辑5:
假如上面的4套规则还不能解决一些问题的话,则通过代码直接来设置map的key和value值,放到map中来,比如说当前的时间等等。
rsMap.put(paramAdvancde.getFieldName(), res.get(paramAdvancde.getFieldName()));
最后通过得到的数据就是
[{payBankNum=/, cwmerchantContactEmail=222@qq.com, masterDay=11, masterContractNum=K18-2000-801-03, depositAccount=/, masterYear=2018, cwmerchantContactCz=/, masterMonth=2, billAccountShareAmount=/, merchantName=还有几天就要放假了呀, year=2018, telephoneormobilephone=18068334025, legalName=222, input28=名字, ddmerchantContactTelphone=18068334025, ddmerchantContactEmail=222@qq.com, bankName=/, cwmerchantContactName=名字, cwmerchantContactTelphone=18068334025, input3=广西壮族自治区贵港市, input5=3333, ddmerchantContactName=名字, input6=3333, input20=2018年 02月 11日, month=2, ddmerchantContactCz=/, merechantURL=/, input23=2019年 02月 10日, day=11, contract_num=K18-2000-801-03, templateName=dsmainfinancialword.docx, accessType=首选, bankAccount=/}, {perMinimum=, perMinimum_pri_bat_ban=, payToCompayKqAcccountRatio=/, payBankNum=/, input69=3333, perMinimum_pub_bat_99bill=, input19=/, payToCompayAcccount=□, input18=□, autoDiectPayOpenFee=/, perMaximum_pub_bat_99bill=/, masterDay=11, input13=□, masterYear=2018, masterMonth=2, holidayPayOpenFee=/, year=2018, holidayPayTechnologyFee=/, memberCode=10012401604, telephoneormobilephone=18068334025, accumulateQuota=/, groupPayCompayKqAccountRatio=/, perMinimum_pri_sin_ban=, perMaximum=/, apiZdPayOpenFee=/, KqPayXinShi=■, bankName=/, perMinimum_pri_bat_99bill=, cwmerchantContactTelphone=18068334025, perMaximum_pri_bat_99bill=/, ddmerchantContactName=名字, BankName_bat_ban_hidden=/, AccountNum_bat_ban=/, month=2, day=11, idContent=234324fds432@qq.com, contract_num=K18-2000-801-03, apiZdPayTechnologyFee=/, perMaximum_pub_bat_ban=/, cwmerchantContactEmail=222@qq.com, holidayPay=□, perMaximum_pri_sin_99bill=/, perMinimum_pub_sin_99bill=, masterContractNum=K18-2000-801-03, groupPayCompayBankAccountRatio=/, depositAccount=/, groupPayToPersonKqAccountRatio=/, cwmerchantContactCz=/, groupPayToPersonBankAccountRatio=/, merchantName=还有几天就要放假了呀, AccountName_bat_ban=/, isBatchApiPayToBank=□, perMaximum_pri_bat_ban=/, perMinimum_pri_sin_99bill=, perMaximum_pub_sin_ban=/, input28=□, ddmerchantContactEmail=222@qq.com, ddmerchantContactTelphone=18068334025, perMinimum_pub_sin_ban=, payToCompayBankAcccountRatio=/, payPersonBankAccountRatio=/, KqPayXinShiFeeRatio=0, payPersonAccountRatio=/, cwmerchantContactName=名字, input3=□, input7=□, input6=/, input9=□, perMaximum_pub_sin_99bill=/, autoDiectPay=□, input22=□, ddmerchantContactCz=/, input24=□, input26=□, perMinimum_pub_bat_ban=, bankAccount=/, templateName=dspayfinancialaddwordfir.docx, perMaximum_pri_sin_ban=/}, {telephoneormobilephone=18068334025, ddmerchantContactEmail=222@qq.com, ddmerchantContactTelphone=18068334025, bankName=/, payBankNum=/, cwmerchantContactEmail=222@qq.com, cwmerchantContactName=名字, cwmerchantContactTelphone=18068334025, masterDay=11, masterContractNum=K18-2000-801-03, ddmerchantContactName=名字, depositAccount=/, masterYear=2018, cwmerchantContactCz=/, masterMonth=2, month=2, merchantName=还有几天就要放假了呀, year=2018, ddmerchantContactCz=/, day=11, contract_num=K18-2000-801-03, templateName=quickSubjectSeal.docx, bankAccount=/}]
至于上面的KqPayXinShi=■
则是按照上面的判断规则直接获取就行了
if(getXpathRes(json,xpath)){
rsMap.put(paramAdvancde.getFieldName(),"■");
}else{
rsMap.put(paramAdvancde.getFieldName(),"□");
}
2.3,替换模板参数
private List<Map<String,Object>> replaceParam(List<Map<String,Object>> templatParamList,String contractNum,long contractType)
{
List<Map<String,Object>> originParamList = new ArrayList<Map<String,Object>>();
if(!templatParamList.isEmpty())
{
String templateName = "";
Map<String,Object> resultMap = null;
Map<String,Object> queryOriginParam = new HashMap<String,Object>();
List<EcontractTemplateParamAdvanced> aTemplateParamList = new ArrayList<EcontractTemplateParamAdvanced>();
for(Map<String,Object> originParam : templatParamList)
{
templateName = (String) originParam.get("templateName");
queryOriginParam.put("templateName", templateName);
//获取每个模板需要替换的参数
aTemplateParamList = econtractTemplateParamAdvancedService.queryEcontractTemplateParamAdvancedByMap(queryOriginParam);
if(!aTemplateParamList.isEmpty())
{
resultMap = new HashMap<String,Object>();
for(EcontractTemplateParamAdvanced replaceParams : aTemplateParamList)
{
if(originParam.containsKey(replaceParams.getFieldName()))
{
//TODO 调用参数替换规则脚本 未完待续....
resultMap.put(replaceParams.getAliasField(), originParam.get(replaceParams.getFieldName()));
}
}
resultMap.put("templateName", templateName);
resultMap.put("contract_num", contractNum);
resultMap.put("contract_type", contractType);
originParamList.add(resultMap);
}
}
}
log.info("替换模板参数成功..");
return originParamList;
}
if(originParam.containsKey(replaceParams.getFieldName()))
originParam:
{payBankNum=/, cwmerchantContactEmail=222@qq.com, masterDay=11, masterContractNum=K18-2000-801-03, depositAccount=/, masterYear=2018, cwmerchantContactCz=/, masterMonth=2, billAccountShareAmount=/, merchantName=还有几天就要放假了呀, year=2018, telephoneormobilephone=18068334025, legalName=222, input28=名字, ddmerchantContactTelphone=18068334025, ddmerchantContactEmail=222@qq.com, bankName=/, cwmerchantContactName=名字, cwmerchantContactTelphone=18068334025, input3=广西壮族自治区贵港市, input5=3333, ddmerchantContactName=名字, input6=3333, input20=2018年 02月 11日, month=2, ddmerchantContactCz=/, merechantURL=/, input23=2019年 02月 10日, day=11, contract_num=K18-2000-801-03, templateName=dsmainfinancialword.docx, accessType=首选, bankAccount=/}
{$INPUT19$=/, $INPUT1$=K18-2000-801-03, $INPUT3$=广西壮族自治区贵港市, $INPUT7$=名字, $INPUT17$=/, $INPUT23$=2019年 02月 10日, $INPUT5$=3333, contract_type=0, $INPUT15$=/, $INPUT29$=222, $INPUT11$=名字, $INPUT13$=/, $INPUT27$=/, $INPUT9$=/, $INPUT18$=/, $INPUT2$=还有几天就要放假了呀, $INPUT4$=18068334025, $INPUT6$=3333, $INPUT8$=18068334025, $INPUT16$=/, $INPUT14$=222@qq.com, $INPUT20$=2018年 02月 11日, $INPUT10$=222@qq.com, $INPUT28$=名字, $INPUT26$=首选, contract_num=K18-2000-801-03, $INPUT12$=18068334025, templateName=dsmainfinancialword.docx}
替换的原理就是把上面获取到的所有的值,根据数据库中的配置,全部提花成$input$开头的,因为word文档的每个参数就是这样设置的。
if(originParam.containsKey(replaceParams.getFieldName()))
originParam:
{payBankNum=/, cwmerchantContactEmail=222@qq.com, masterDay=11, masterContractNum=K18-2000-801-03, depositAccount=/, masterYear=2018, cwmerchantContactCz=/, masterMonth=2, billAccountShareAmount=/, merchantName=还有几天就要放假了呀, year=2018, telephoneormobilephone=18068334025, legalName=222, input28=名字, ddmerchantContactTelphone=18068334025, ddmerchantContactEmail=222@qq.com, bankName=/, cwmerchantContactName=名字, cwmerchantContactTelphone=18068334025, input3=广西壮族自治区贵港市, input5=3333, ddmerchantContactName=名字, input6=3333, input20=2018年 02月 11日, month=2, ddmerchantContactCz=/, merechantURL=/, input23=2019年 02月 10日, day=11, contract_num=K18-2000-801-03, templateName=dsmainfinancialword.docx, accessType=首选, bankAccount=/}
{$INPUT19$=/, $INPUT1$=K18-2000-801-03, $INPUT3$=广西壮族自治区贵港市, $INPUT7$=名字, $INPUT17$=/, $INPUT23$=2019年 02月 10日, $INPUT5$=3333, contract_type=0, $INPUT15$=/, $INPUT29$=222, $INPUT11$=名字, $INPUT13$=/, $INPUT27$=/, $INPUT9$=/, $INPUT18$=/, $INPUT2$=还有几天就要放假了呀, $INPUT4$=18068334025, $INPUT6$=3333, $INPUT8$=18068334025, $INPUT16$=/, $INPUT14$=222@qq.com, $INPUT20$=2018年 02月 11日, $INPUT10$=222@qq.com, $INPUT28$=名字, $INPUT26$=首选, contract_num=K18-2000-801-03, $INPUT12$=18068334025, templateName=dsmainfinancialword.docx}
替换的原理就是把上面获取到的所有的值,根据数据库中的配置,全部提花成$input$开头的,因为word文档的每个参数就是这样设置的。
2.4,替换word文档中的各个参数并合并word文档
fileName = dealWordHelperService.replaceWordText(finalOriginParamList,templeteFilePath,outFilePath);
templeteFilePath:模板存放的地方
outFilePath:替换掉参数临时的路径
templateName = (String)templateParam.get("templateName");
log.info("======开始替换模板参数=replaceWordText中==templateName==="+templateName+"=====");
OPCPackage pack = POIXMLDocument.openPackage(templeteFile + File.separator + templateName);
document = new XWPFDocument(pack);
OPCPackage pack = POIXMLDocument.openPackage(templeteFile + File.separator + templateName);
document = new XWPFDocument(pack);
获取document对象
2.4.1,替换页脚
templateParam:
{payBankNum=/, cwmerchantContactEmail=222@qq.com, masterDay=11, masterContractNum=K18-2000-801-03, depositAccount=/, masterYear=2018, cwmerchantContactCz=/, masterMonth=2, billAccountShareAmount=/, merchantName=还有几天就要放假了呀, year=2018, telephoneormobilephone=18068334025, legalName=222, input28=名字, ddmerchantContactTelphone=18068334025, ddmerchantContactEmail=222@qq.com, bankName=/, cwmerchantContactName=名字, cwmerchantContactTelphone=18068334025, input3=广西壮族自治区贵港市, input5=3333, ddmerchantContactName=名字, input6=3333, input20=2018年 02月 11日, month=2, ddmerchantContactCz=/, merechantURL=/, input23=2019年 02月 10日, day=11, contract_num=K18-2000-801-03, templateName=dsmainfinancialword.docx, accessType=首选, bankAccount=/}
OperatorWordUtil.replaceInFoot(document,templateParam);
public static void replaceInFoot(XWPFDocument doc, Map<String, Object> params)
{
List<XWPFFooter> footerList = doc.getFooterList();
if (footerList != null && footerList.size() > 0)
{
for (XWPFFooter xWPFFooter : footerList)
{
String text = xWPFFooter.getText();
LOGGER.info("记得删除,遍历的text"+text);
System.out.println("控制台记得删除,遍历的text"+text);
List<XWPFParagraph> xWPFParagraphs = xWPFFooter.getParagraphs();
if (xWPFParagraphs != null && xWPFParagraphs.size() > 0)
{
for (XWPFParagraph xWPFParagraph : xWPFParagraphs)
{
replaceInPara(xWPFParagraph, params);
}
}
}
}
}
public static void replaceInPara(XWPFParagraph paragraph, Map<String, Object> replaceMap)
{
List<XWPFRun> runs = paragraph.getRuns();
for (int i = 0; i < runs.size(); i++)
{
if (null == runs.get(i))
{
continue;
}
String oneparaString = runs.get(i).getText(runs.get(i).getTextPosition());
if (StringUtils.isEmpty(oneparaString))
{
continue;
}
for (Map.Entry<String, Object> entry : replaceMap.entrySet())
{
if(null != entry.getValue())
{
oneparaString = oneparaString.replace(entry.getKey().trim(), (String.valueOf(entry.getValue())!=null? String.valueOf(entry.getValue()): ""));
}
else
{
oneparaString = oneparaString.replace(entry.getKey().trim(), "");
}
}
if(oneparaString!=null && oneparaString.indexOf(breakFlag)>-1){//需要换行
LOGGER.info("----->需要手动换行的"+oneparaString);
String[] breaks = oneparaString.split(breakFlag);
int index = 0;
for(String breakinfo:breaks){
runs.get(i).setText(breakinfo, index);
runs.get(i).addBreak();//换行
index++;
}
}else{//不用换行,根据模板正常显示,原来的逻辑
runs.get(i).setText(oneparaString, 0);
}
}
}

2.4.2,替换字段里的参数
public static void replaceInPara(XWPFDocument doc, Map<String, Object> params)
{
Iterator<XWPFParagraph> iterator = doc.getParagraphsIterator();
XWPFParagraph para;
while (iterator.hasNext())
{
para = iterator.next();
replaceInPara(para, params);
}
}
replaceInPara还是上面的方法
2.4.3,替换表格里面的变量
public static void replaceInTable(XWPFDocument doc, Map<String, Object> params)
{
Iterator<XWPFTable> iterator = doc.getTablesIterator();
XWPFTable table;
List<XWPFTableRow> rows;
List<XWPFTableCell> cells;
List<XWPFParagraph> paras;
while (iterator.hasNext())
{
table = iterator.next();
rows = table.getRows();
for (XWPFTableRow row : rows)
{
cells = row.getTableCells();
for (XWPFTableCell cell : cells)
{
paras = cell.getParagraphs();
for (XWPFParagraph para : paras)
{
replaceInPara(para, params);
}
}
}
}
}
replaceInPara还是上面的方法
一段XWPFParagraph一段的去读
读到每一段之后他会在吧这一段进行按照word文档当初设置的格式,假如是黏贴复制的话不会换行String oneparaString = runs.get(i).getText(runs.get(i).getTextPosition()),假如是手写的的话就会换行,所以要想把自己的变量单独的取出来必须手动的输入这个变量才会遍历的时候单独的把这个字段取出来。
一个段落就是一个XWPFParagraph,注意这个段落就是我们传统意义上的段落比如

一行就是String oneparaString = runs.get(i).getText(runs.get(i).getTextPosition()),但是行就不是我们传统意义上的行了,请见下图关于oneparaString的解释。它就是一行行的读的。眼睛看上去应该是一行,其实是三行,因为在写好的基础上,我们手动的添加了一个$INPUT6$,一定注意是手动,而不是黏贴复制的。
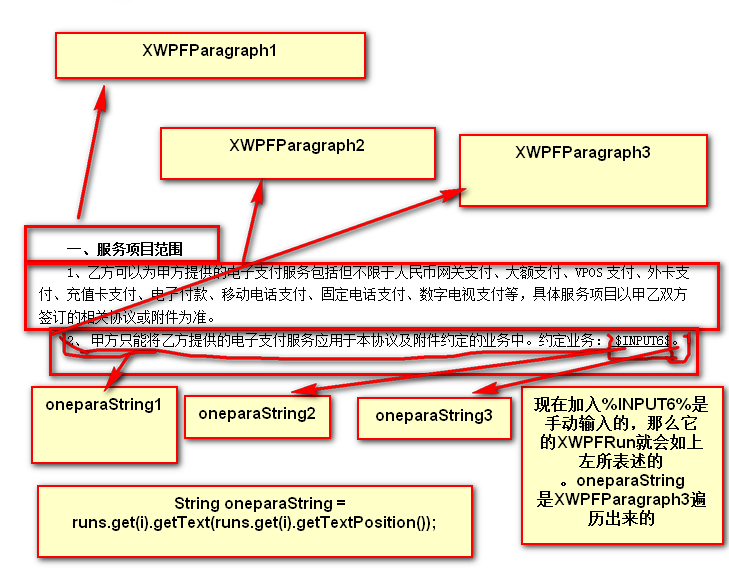
假如是表格的话,就会在每个单元格算一个段落,word文档中有时候表格是设置的,我们眼睛有时候看不到的,比如每个单元格就是一个cell,其实就是一个段落。
paras = cell.getParagraphs(); cell

在在单元格的基础上进行一行行的读,读的规则和上面的oneparaString 规则是一样的。
2.5,输出(生成临时的word文档,记得上传服务器之后在删除,否则会积累好多的垃圾数据的)
//生成临时word文件
fileName = newTemWord(outFilePath, templateName, document);
fileNames.append(fileName).append(",");
private String newTemWord(String outFilePath, String templateName,
XWPFDocument document) throws FileNotFoundException, IOException
{
String outTempFilePath = wordFile + File.separator + outFilePath;
FileOutputStream outStream = null;
String fileName = System.currentTimeMillis() + templateName;
String filePath = outTempFilePath+ File.separator + fileName;
outStream = new FileOutputStream(filePath);
document.write(outStream);
outStream.close();
return fileName;
}
2.6,把多个word文档合并成一个word文档
finalWordName = getFinalWordDoc(fileNames.toString(),outFilePath);
log.info("合同生成成功1!合同名称:"+finalWordName);
private String getFinalWordDoc(String fileNames,String outFilePath)
{
String outTempFilePath = wordFile + File.separator + outFilePath;
String finalWordName = OperatorWordUtil.mergeWordDocx(outTempFilePath, fileNames);
return finalWordName;
}
public static String mergeWordDocx(String outTempFilePath,String fileNames)
{
String finalWordName = "";
if(fileNames.length() > 0 && fileNames != null)
{
FileInputStream InStream = null;
String filePath = "";
List<InputStream> InputStreams = new ArrayList<InputStream>();
String[] fileNameArray = fileNames.toString().split(",");
InputStream InputStream = null;
OutputStream outputStream = null;
try
{
for(String fileName : fileNameArray)
{
filePath = outTempFilePath + File.separator + fileName;
InStream = new FileInputStream(filePath);
InputStreams.add(InStream);
}
//合并word
InputStream = mergeDocx(InputStreams,outTempFilePath);
finalWordName = System.currentTimeMillis()+".docx";
outputStream = new FileOutputStream(outTempFilePath+File.separator+finalWordName);
int bytesWritten = 0;
int byteCount = 0;
byte[] bytes = new byte[100000000];
while ((byteCount = InputStream.read(bytes)) != -1)
{
outputStream.write(bytes, bytesWritten, byteCount);
bytesWritten += byteCount;
}
}
catch (Exception e)
{
e.printStackTrace();
}
finally {
try {
if (null != outputStream) {
outputStream.close();
}
if (null != InputStream) {
InputStream.close();
}
if (null != InStream) {
InStream.close();
}
} catch (Exception e2) {
LOGGER.error("OperatorWordUtil close stream failed!", e2);
}
}
}
return finalWordName;
}
public static InputStream mergeDocx(final List<InputStream> streams,String outTempFilePath) throws Docx4JException, IOException
{
WordprocessingMLPackage target = null;
File tmpdir = new File(outTempFilePath);
final File generated = File.createTempFile("generated", ".docx",tmpdir);
int chunkId = 0;
Iterator<InputStream> it = streams.iterator();
while (it.hasNext())
{
InputStream is = it.next();
if (is != null)
{
if (target == null)
{
// Copy first (master) document
OutputStream os = new FileOutputStream(generated);
os.write(IOUtils.toByteArray(is));
os.close();
target = WordprocessingMLPackage.load(generated);
}
else
{
// Attach the others (Alternative input parts)
insertDocx(target.getMainDocumentPart(), IOUtils.toByteArray(is), chunkId++);
}
}
}
if (target != null)
{
target.save(generated);
return new FileInputStream(generated);
}
else
{
return null;
}
}
private static void insertDocx(MainDocumentPart main, byte[] bytes, int chunkId)
{
try
{
AlternativeFormatInputPart afiPart = new AlternativeFormatInputPart(new PartName("/part" + chunkId + ".docx"));
afiPart.setContentType(new ContentType(ContentTypes.WORDPROCESSINGML_DOCUMENT));
afiPart.setBinaryData(bytes);
Relationship altChunkRel = main.addTargetPart(afiPart);
CTAltChunk chunk = Context.getWmlObjectFactory().createCTAltChunk();
chunk.setId(altChunkRel.getId());
main.addObject(chunk);
}
catch (Exception e)
{
e.printStackTrace();
}
}
public final static String WORDPROCESSINGML_DOCUMENT = "application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml";
POI生成word文档完整案例及讲解的更多相关文章
- POI生成WORD文档
h2:first-child, body>h1:first-child, body>h1:first-child+h2, body>h3:first-child, body>h ...
- POI 生成 word 文档 简单版(包括文字、表格、图片、字体样式设置等)
POI 生成word 文档 一般有两种方法: ① word模板 生成word 文档 : ② 写代码直接生成 word 文档: 我这里演示的是第二种方法,即写代码生成 word文档,不多说废话,直接 ...
- POI加dom4j将数据库的数据按一定格式生成word文档
一:需求:将从数据库查处来的数据,生成word文档,并有固定的格式.(dom4j的jar包+poi的jar包) 二:解决:(1)先建立固定格式的word文档(2007版本以上),另存成为xml文件,作 ...
- PoiDocxDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0),目前只能java生成】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 这个是<PoiDemo[Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)]>的扩展,上一篇是根 ...
- PoiDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 使用Poi实现android中根据模板文件生成Word文档的功能.这里的模板文件是doc文件.如果模板文件是docx文件的话,请阅读 ...
- Java Web项目中使用Freemarker生成Word文档
Web项目中生成Word文档的操作屡见不鲜.基于Java的解决方式也是非常多的,包含使用Jacob.Apache POI.Java2Word.iText等各种方式,事实上在从Office 2003開始 ...
- Java生成 Word文档的并打印解决方案
户要求用程序生成标准的word文档,要能打印,而且不能变形,以前用过很多解决方案,都在客户严格要求下牺牲的无比惨烈. POI读word文档还行,写文档实在不敢恭维,复杂的样式很难控制不提,想象一下一个 ...
- Poi之Word文档结构介绍
1.poi之word文档结构介绍之正文段落 一个文档包含多个段落,一个段落包含多个Runs,一个Runs包含多个Run,Run是文档的最小单元 获取所有段落:List<XWPFParagraph ...
- 将HTML导出生成word文档
前言: 项目开发中遇到了需要将HTML页面的内容导出为一个word文档,所以有了这边随笔. 当然,项目开发又时间有点紧迫,第一时间想到的是用插件,所以百度了下.下面就介绍两个导出word文档的方法. ...
随机推荐
- BZOJ 3879: SvT [虚树 后缀树]
传送门 题意: 多次询问,给出一些后缀,求两两之间$LCP$之和 哈哈哈哈哈哈哈竟然$1A$了,刚才还在想如果写不好这道题下节数学就不上了,看来是上天让我上数学课啊 $Suffix\ Virtual\ ...
- Windows Azure Virtual Network (11) 虚拟网络之间点对点连接VNet Peering
<Windows Azure Platform 系列文章目录> 在有些时候,我们需要通过VNet Peering,把两个虚拟网络通过内网互通互联.比如: 1.在订阅A里的Virtual N ...
- python数据分析工具包(1)——Numpy(一)
在本科阶段,我们常用的科学计算工具是MATLAB.下面介绍python的一个非常好用而且功能强大的科学计算库--Numpy. a powerful N-dimensional array object ...
- vue 路由懒加载 使用,优化对比
vue这种单页面应用,如果没有应用懒加载,运用webpack打包后的文件将会异常的大,造成进入首页时,需要加载的内容过多,时间过长,会出啊先长时间的白屏,即使做了loading也是不利于用户体验,而运 ...
- ZK客户端脚本的简单使用
sh zkCli.sh [-server ip:port] :连接节点zk客户端[-server ip:port 用于连接集群中指定节点的客户端] 1.创建节点 create [-s] [-e] pa ...
- sphinx初识
sphinx(SQL Phrase Index),查询词组索引. 定义:Sphinx是一个全文检索引擎. 特性: 1.高速索引 (在新款CPU上,近10 MB/秒); 2.高速搜索 (2-4G的文本量 ...
- 如何使用 VS生成动态库?
如何使用 VS生成动态库? //.cpp 文件默认定义了 __cplusplus 宏 #ifdef __cplusplus extern "C"{ #endif xxx #ifde ...
- Shiro登录成功之后跳到指定URL
通常我们使用shiro,登录之后就会跳到我们上一次访问的URL,如果我们是直接访问登录页面的话,shiro就会根据我们配置的successUrl去重定向,如果我们没有配置successUrl的话,那么 ...
- yaf代码生成工具的使用
具体步骤如下: 1.下载php-yaf源码: git clone https://github.com/laruence/php-yaf/ 2.运行代码生成工具: /Users/helloxiaozh ...
- nginx笔记5-双机热备原理
1动静分离演示: 将笔记3的Demo改造一下,如图所示: 改造完成后,其实就是在网页上显示一张图片 现在启动Tomcat运行起来,如图: 可以看到图片的请求是请求Tomcat下的图片. 现在,通过把静 ...