UNDO及MVCC、崩溃恢复
0、undo物理存储研究
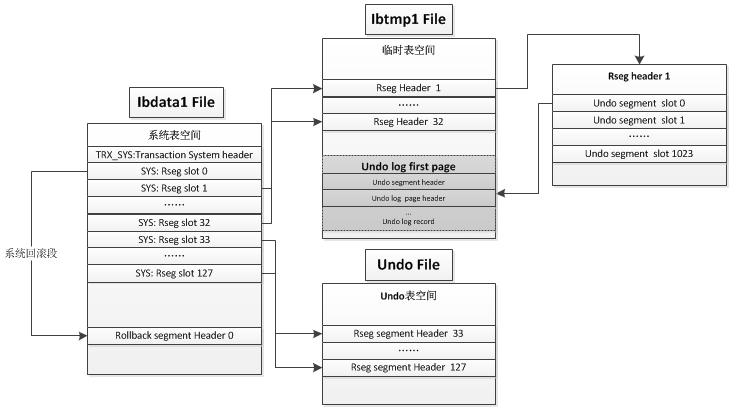
1>ibdata第五个数据块(系统事务表)中存储着128个undo段的段头块的地址
2>每一个undo段头块有1024行,两行记录一个事务,一共可以记录512个事务
3>一个数据行中存放XID、rollpointr
4>一个数据行被修改
1.新的事务ID
2.新的rollpointr
3.修改后数据
上面三部分数据都会进入到回滚块中。详细见:事务工作流程……
一、UNDO特性
1、避免脏读
1>在操作任何数据之前,首先将数据备份到undo页中,然后再进行数据的修改;
2>不能看到其他会话未提交的数据;
3>当要读取被修改数据页数据行时,会指向备份在undo页中的数据,而避免脏读。
2、事务的回滚
undo最基本的作用是rollback,旧数据先放到undo里面存放,等rollback时候再将undo里面的数据回滚回来。
3、DML不阻塞读
提高并发,如果别的用户正在修改某数据页,事务没有提交,现需要读该数据页,发现事务没有提交,就根据数据行上的rollpointer找到原来的数据(在undo页上),结合该数据页将数据返给用户。
4、MVCC(一致性读)
多版本控制Multiversion Concurrency Control
5、崩溃恢复(回滚)
自动回滚未提交事务;
redo前滚,undo回滚,未提交事务主动回滚,未提交事务信息在事务槽里写着。数据库在运行期间,突然崩了,数据库启动之后,需要redo前滚,就会有很多未提交的事务(事务的会话断了,不可能继续完成了,就需要对未提交事务回滚了 )也滚回来了:读取未提交事务事务槽信息,把未提交事务回滚。
二、事务工作流程:存储结构
1、分配一个事务ID,事务ID依次递增
2、分配一个事务槽,将事务信息写入事务槽中
3、开始修改数据行,数据行中存储事务ID、修改前数据所使用的回滚块地址
4、回滚块中存放修改前的数据
5、属于一个事务的各个回滚块链接起来
6、回滚段段头块中的地址指向回滚块链表中的最后一个回滚块
7、一个回滚块只能存放一个事务的数据
8、事务提交就是在事务槽中将事务状态改成已提交

三、MVCC原理机制
理解不深(转自:http://www.cnblogs.com/chenpingzhao/p/5065316.html)
1、MVCC的几个特点:
1>每行数据都存在一个版本,每次数据更新时都更新该版本
2>修改时Copy出当前版本随意修改,各个事务之间无干扰
3>保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
也就是每行都有版本号,保存时根据版本号决定是否成功,听起来含有乐观锁的味道;
2、非阻塞读Innodb的实现方式:
4>事务以排他锁的形式修改原始数据
5>把修改前的数据存放于undo log,通过回滚指针与主数据关联
6>修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
3、区别理解
二者最本质的区别是,当修改数据时是否要排他锁定;
Innodb的实现真算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据时,理想的MVCC据无能为力了。
比如,如果Transaciton1执行理想的MVCC,修改Row1成功,而修改Row2失败,此时需要回滚Row1,但因为Row1没有被锁定,其数据可能又被Transaction2所修改,如果此时回滚Row1的内容,则会破坏Transaction2的修改结果,导致Transaction2违反ACID。
理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
四、崩溃恢复
redo前滚、undo回滚……
1、两个保证
1>数据库保证所有已提交事务的redolog都写入到了redo logfile中
2>数据库保证所有脏块的redolog都早redo logfile中,只有脏块写入磁盘以后,redo log才能被覆盖
结论:redo log有足够的能力将该有的脏块都构造出来
2、redo log如何确定使用哪些日志来构造脏块
1>起点:checkpoint开始
1.innodb buffer pool中存在一条flush list链表
2.这个链表最旧的那一端对应的redo log就是将来数据库崩溃恢复redolog前滚的起点
3.clean线程周期性的将需要flush list最旧的那一个脏块对应的redo log地址写入到ibdata中
2>终点:redo log current最后一条日志
3、崩溃恢复的过程
第一个阶段是前滚:
前滚对应的redo log的启动和终点已经确定:redolog不害怕多跑,因为redolog有版本,数据块有版本,如果redolog比数据块还要旧,就采用空跑的方式
第二个阶段是回滚:
崩溃时没有提交的事务也会被回滚回来,这些事务都属于死事务,因为这些事务对应的用户会话已经结束,后续读到对应的数据块,发现数据块上有未提交事务,读取未提交事务对应的事务信息,发现已经是死事务,主动回滚这个数据块;
碰到死事务对应的数据块,谁使用谁回滚。
五、大事务、长事务
1、长事务的危害
开始一个事务,长时间不提交,所有的数据都需要undo去保存,可能产生很多undo数据,而且还不能被清空覆盖,一直保存到该事务提交。很严重。
2、大事务的危害
修改批量的数据,占用过多的undo页(产生undo数据主要是delete产生的,但MySQL对delete做了优化,添加deleted_flag标志位,减少delete对undo的使用),所以危害不是很大,而且正常的事务场景也不会出现大事务。
3、如何判断大事务和长事务
mysql> desc information_schema.INNODB_TRX;
关键参数:
1.trx_started:事务开始的时间,如果时间较当前差很远说明是长事务
2.trx_rows_modified:事务修改的行数量,如果值很大说明是大事务
3.trx_mysql_thread_id:该事务所对应的线程id(kill线程清理事务)
4、解决棘手的大事务、长事务
处理大事务:kill -9 mysql_process_id:处理大事务,就直接干掉mysql实例,不会主动去回滚所以速度块,然后重启。(除非迫不得已,否则不那么干,生产环境重启服务器是天大的事情)
处理长事务:如果开始的时间不是很长,并且行数不是很多,直接kill掉该事务所在的线程。(在数据库里kill,可能反应慢)
六、UNDO的优化处理
1、实现undo分离
在MySQL5.5以及之前,除了数据量自然增长之外,一旦出现大事务,其所使用的undo log占用的空间就会一直在ibdata1里面存在,即使这个事务已经关闭。随着数据库上线时间越来越长,ibdata1文件会越来越大,物理备份文件越来越大……
MySQL 5.6增加了如下参数,可以把undo log从ibdata1移出来单独存放。
mysql> show variables like '%undo%';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | ON |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 3 |
+--------------------------+------------+
5 rows in set, 1 warning (0.00 sec)
1> innodb_undo_directory:
指定单独存放undo表空间的目录,默认为.(即datadir),可以设置相对路径或者绝对路径。该参数实例初始化之后虽然不可直接改动,但是可以通过先停库,修改配置文件,然后移动undo表空间文件的方式去修改该参数;
2> innodb_undo_tablespaces:
指定单独存放的undo表空间个数,例如如果设置为3,则undo表空间为undo001、undo002、undo003,每个文件初始大小默认为10M。该参数实例初始化之后不可改动;
3> innodb_undo_logs:
指定回滚段的个数(早期版本该参数名字是innodb_rollback_segments),默认128个。每个回滚段可同时支持1024个在线事务。这些回滚段会平均分布到各个undo表空间中。该变量可以动态调整,但是物理上的回滚段不会减少,只是会控制用到的回滚段的个数。
操作undo分离:实际使用方面,在初始化实例之前,我们只需要设置innodb_undo_tablespaces参数(建议大于等于3)即可将undo log设置到单独的undo表空间中。
2、在线收缩undo表空间
MySQL 5.7引入了新的参数,innodb_undo_log_truncate,开启后可在线收缩拆分出来的undo表空间,支持动态设置。
1>实现在线收缩undo的条件
1.innodb_undo_tablespaces>=2:因为truncate undo表空间时,该文件处于inactive状态,如果只有1个undo表空间,那么整个系统在此过程中将处于不可用状态;
2.innodb_undo_logs>=35(默认128):因为在MySQL 5.7中,第一个undo log永远在共享表空间中,另外32个undo log分配给了临时表空间(即ibtmp1),至少还有2个undo log才能保证2个undo表空间中每个里面至少有1个undo log;
2>满足以上2个条件后
innodb_undo_log_truncate=ON,即可开启undo表空间的自动truncate
1.innodb_max_undo_log_size:undo表空间文件超过此值即标记为可收缩,默认1G,truncate之后空间缩小到10M;
2.innodb_purge_rseg_truncate_frequency:指定purge操作被唤起多少次之后才释放rollback segments。当undo表空间里面的rollback segments被释放时,undo表空间才会被truncate。(最大是128,最小是1,默认为128)该参数越小,undo表空间被尝试truncate的频率越高。
UNDO及MVCC、崩溃恢复的更多相关文章
- MySQL之UNDO及MVCC、崩溃恢复
UNDO特性:避免脏读.事务回滚.非阻塞读.MVCC.崩溃恢复 事务工作流程(图2) MVCC原理机制 崩溃恢复:redo前滚.undo回滚 长事务.大事务:危害.判断.处理 UNDO优化:实现u ...
- 基于Redo Log和Undo Log的MySQL崩溃恢复流程
在之前的文章「简单了解InnoDB底层原理」聊了一下MySQL的Buffer Pool.这里再简单提一嘴,Buffer Pool是MySQL内存结构中十分核心的一个组成,你可以先把它想象成一个黑盒子. ...
- MySQL · 引擎特性 · InnoDB崩溃恢复
前言 数据库系统与文件系统最大的区别在于数据库能保证操作的原子性,一个操作要么不做要么都做,即使在数据库宕机的情况下,也不会出现操作一半的情况,这个就需要数据库的日志和一套完善的崩溃恢复机制来保证.本 ...
- 一起看下MySQL的崩溃恢复到底是怎么回事
目录 回顾 思考一个问题 checkponit机制 Checkpoint的种类及触发条件 LSN 推荐阅读 本文稍微有点晦涩.但是看过之后你就能Get到MySQL的崩溃恢复到底是怎么做的! 文章公号 ...
- MySQL · 引擎特性 · InnoDB 崩溃恢复过程
MySQL · 引擎特性 · InnoDB 崩溃恢复过程 在前面两期月报中,我们详细介绍了 InnoDB redo log 和 undo log 的相关知识,本文将介绍 InnoDB 在崩溃恢复时的主 ...
- [转] IIS配置文件的XML格式不正确 applicationHost.config崩溃 恢复解决办法
IIS配置文件的XML格式不正确 applicationHost.config崩溃 恢复解决办法 源文件:http://www.cnblogs.com/yuejin/p/3385584.html ...
- 崩溃恢复(crash recovery)与 AUTORESTART参数
关于这个参数设置的影响,在生产系统中经历过两次: 第一次是有套不太重要的系统安装在虚拟机,这套系统所有应用(DB2 WAS IHS)都配置到/etc/rc.local中,每次启动机器会自 ...
- Zookeeper崩溃恢复过程(Leader选举)
1. 崩溃恢复 a). leader选择过程可以保证新leader是ZXID最大的节点 b). ZAB协议确保丢弃那些只在leader上被提出的事务,场景 leader发出PROPOSAL收到ACK, ...
- MySQL崩溃恢复与组提交
Ⅰ.binlog与redo的一致性(原子) 由内部分布式事务保证 我们先来了解下,当一个commit敲下后,内部会发生什么? 步骤 操作 step1 InnoDB做prepare redo log ...
随机推荐
- Maven文件配置
Maven文件路径的配置 默认设置 修改之后的设置 Maven文件内容的配置 对于Maven 的 settings.xml 文件,需要注意. <mirror>镜像元素之间是互斥的,优先级是 ...
- TKCPP
volume one: http://book.huihoo.com/thinking-in-cpp-2nd-ed-vol-one/ volume2 : http://book.huihoo.com/ ...
- css里面如何设置body背景图片满屏
@{ Layout = null; ViewBag.Title = "Login Page";} <!DOCTYPE html> <html>& ...
- TensorFlow 实战之实现卷积神经网络
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过. 一.相关性概念 1.卷积神经网络(ConvolutionNeu ...
- 解决java.lang.IllegalArgumentException: No converter found for return value of type: class java.util.ArrayList这个问题
今天使用SSM框架,用@ResponseBody注解,出现了这个问题 java.lang.IllegalArgumentException: No converter found for return ...
- vim学习、各类插件配置与安装
vim学习.各类插件配置与安装 vim 插件 配置 1. vim学习 vim基础学习:根据网上流行基础文章<简明Vim练级攻略>,进阶书籍<vim实用技巧>.注:进阶书籍可以在 ...
- maven中的传递依赖和传递依赖的解除
例如创建三个maven工程A B C pom文件分别为 A <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns: ...
- 常见JedisConnectionException异常分析
异常内容:我看了很多人的博客,千篇一律都是说redis.conf文件的配置问题,发现并不能解决我的问题,今天写这个博客讲解一下我的解决办法: 遇到这个问题第一步:查看虚拟机的防火墙是否关闭,测试方法就 ...
- js在工作中遇到的一些问题
前言 js这种语言没有太多封装好的模式或者统一的编程方式,所以一些细节的问题很容易导致bug,那下面就写为:一份坚固的代码是什么样的. 持续更新一下,记一些good case和bug. 事件绑定的选择 ...
- Java中子类能继承父类的私有属性吗?
前段时间去听老师讲课的时候,老师告诉我子类是可以继承父类所有的属性和方法的.当时我是极其疑惑的,因为之前学校考试时这个考点我记得很清楚:子类只能继承父类的非私有属性和方法.老师给我的解释是这样的--先 ...