《利用python进行数据分析》读书笔记--第四章 numpy基础:数组和矢量计算
http://www.cnblogs.com/batteryhp/p/5000104.html
第四章 Numpy基础:数组和矢量计算
第一部分:numpy的ndarray:一种多维数组对象
实话说,用numpy的主要目的在于应用矢量化运算。Numpy并没有多么高级的数据分析功能,理解Numpy和面向数组的计算能有助于理解后面的pandas.按照课本的说法,作者关心的功能主要集中于:
- 用于数据整理和清理、子集构造和过滤、转换等快速的矢量化运算
- 常用的数组解法,如排序、唯一化、集合运算等
- 高效的描述统计和数据聚合/摘要运算
- 用于异构数据集的合并/连接运算的数据对齐和关系型数据运算
- 将条件逻辑表述为数组表达式(而不是带有if-elif-else分支的循环)
- 数据的分组运算(聚合、转换、函数应用等)。
作者说了,可能还是pandas更好一些,我感觉显然pandas更高级,其中的函数真是太方便了,数据框才是最好的数据结构。只是,Numpy中的函数之类的是基础,需要熟悉。
NumPy的ndarray:一种多维数组对象
ndarray对象是NumPy最重要的对象,特点是矢量化。ndarray每个元素的数据类型必须相同,每个数组有两个属性:shape和dtype.

#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt data = [[1,2,5.6],[21,4,2]]
data = np.array(data)
print data.shape
print data.dtype
print data.ndim
>>>
(2, 3)
float64
2
array函数接受一切序列型的对象(包括其他数组),然后产生新的含有传入数据的NumPy数组,array会自动推断出一个合适的数据类型。还有一个方法是ndim:这个翻译过来叫维度,标明数据的维度。上面的例子是两维的。zeros和ones可以创建指定长度或形状全为0或1的数组。empty可以创建一个没有任何具体值的数组,arange函数是python内置函数range的数组版本。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt data = [[1,2,5.6],[21,4,2],[2,5,3]]
data1 = [[2,3,4],[5,6,7,3]]
data = np.array(data)
data1 = np.array(data1) arr1 = np.zeros(10)
arr2 = np.ones((2,3))
arr3 = np.empty((2,3,4)) print arr1
print arr2
print arr3
print arr3.ndim
>>>
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[ 1. 1. 1.]
[ 1. 1. 1.]]
[[[ 3.83889007e-321 0.00000000e+000 0.00000000e+000 0.00000000e+000]
[ 0.00000000e+000 0.00000000e+000 0.00000000e+000 0.00000000e+000]
[ 0.00000000e+000 0.00000000e+000 0.00000000e+000 0.00000000e+000]]
[[ 0.00000000e+000 0.00000000e+000 0.00000000e+000 0.00000000e+000]
[ 0.00000000e+000 0.00000000e+000 0.00000000e+000 0.00000000e+000]
[ 0.00000000e+000 0.00000000e+000 0.00000000e+000 0.00000000e+000]]]
3

上面是常用的生成数组的函数。
ndarray的数据类型
dtype(数据类型)是一个特殊的对象。它含有ndarray将一块内存解释为指定数据类型所需的信息。他是NumPy如此灵活和强大的原因之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码(C\Fortran)”等工作变得更加简单。dtype命名方式为,类型名+表示元素位长的数字。标准双精度浮点型数据需要占用8字节(64位)。记作float64.常见的数据类型为:


我终于找到了f4,f8的含义了……布尔型数据的代码倒是很有个性。函数astype可以强制转换数据类型。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt arr = np.array([1,2,3,4,5])
print arr.dtype
float_arr = arr.astype(np.float64)
print float_arr.dtype arr1 = np.array([2.3,4.2,32.3,4.5])
#浮点型会被整型截断
print arr1.astype(np.int32)
#一个全是数字的字符串也可以转换为数值类型
arr2 = np.array(['2323.2','23'])
print arr2.astype(float) #数组的dtype还有一个用法
int_array = np.arange(10)
calibers = np.array([.22,.270,.357,.44,.50],dtype = np.float64)
print int_array.astype(calibers.dtype)
print np.empty(10,'u4')
调用astype总会创建一个新的数组(原始数组的一个拷贝),即使和原来的数据类型相同。警告:浮点数只能表示近似数,比较小数的时候要注意。
数组与标量之间的运算
矢量化(vectorization)是数组最重要的特点了。可以避免(显示)循环。注意加减乘除的向量化运算。不同大小的数组之间的运算叫广播(broadcasting)。
索引和切片,不再赘述,注意的是 广播的存在使得数组即使只赋一个值也会被广播到所有数组元素上,其实和R语言中自动补齐功能相同。下面的性质有点蛋疼:跟列表最重要的区别在于,数组切片是原始数组的视图,对视图的任何修改都会反映到源数据上。即使是下面的情况:
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt arr = np.array([1,2,3,4,5,6,7,8,9])
arr1 = arr[1:2]
arr1[0] = 10
print arr
#如果想得到拷贝,需要显示地复制一份
arr2 = arr[3:4].copy()
arr2[0] = 10
print arr arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
#下面两种索引方式等价
print arr2d[0][2]
print arr2d[0,2]
print arr2d[:,1] #注意这里的方式和下面的方式
print arr2d[:,:1] arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[[10,11,12]]]])
print arr3d[(1,0)]
>>>
[ 1 10 3 4 5 6 7 8 9]
[ 1 10 3 4 5 6 7 8 9]
3
3
[2 5 8] #注意这里的方式和下面的方式
[[1]
[4]
[7]]
[7, 8, 9]
布尔型索引
这里的布尔型索引就是TRUE or FALSE索引。==、!=、-(表示否定)、&(并且)、|(或者)。注意布尔型索引选取数组中的数据,将创建数据的副本。python关键字and、or无效。
花式索引(Fancy indexing)
花式索引指的是利用整数数组进行索引。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt arr = np.arange(32).reshape(8,4) print arr
#注意这里的向量式方式
print arr[[1,5,7,2],[0,3,1,2]]
print arr[[1,5,7,2]][:,[0,3,1,2]]
#也可以使用np.ix_函数,将两个一维整数数组组成选取方形区域的索引器
print arr[np.ix_([1,5,7,2],[0,3,1,2])]
>>>
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
[ 4 23 29 10]
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
花式索引总是将数据复制到新数组中,跟切片不同,一定要注意下面的区别:
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt arr = np.arange(32).reshape(8,4)
arr1 = np.arange(32).reshape(8,4)
#注意下面得到的结果是一样的
arr3 = arr[[1,2,3]][:,[0,1,2,3]]
arr3_1 = arr1[1:4][:] #注意下面是区别了
arr3[0,1] = 100 #花式索引得到的是复制品,重新赋值以后arr不变化
arr3_1[0,1] = 100 #切片方式得到的是一个视图,重新赋值后arr1会变化 print arr3
print arr3_1
print arr
print arr1
>>>
[[ 4 100 6 7]
[ 8 9 10 11]
[ 12 13 14 15]]
[[ 4 100 6 7]
[ 8 9 10 11]
[ 12 13 14 15]]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
[[ 0 1 2 3]
[ 4 100 6 7]
[ 8 9 10 11]
[ 12 13 14 15]
[ 16 17 18 19]
[ 20 21 22 23]
[ 24 25 26 27]
[ 28 29 30 31]]
数组转置和轴转换
转置transpose,是一种对源数据的视图,不会进行复制。调用T就可以。np中的矩阵乘积函数为np.dot。
比较复杂的是高维数组:
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt arr = np.arange(24).reshape((2,3,4))
#下面解释一下transpose:
#(1,0,2) 是将reshape中的参数 (2,3,4) 进行变化 ,变为(3,2,4)
#但是由于是转置,所以是将所有元素的下标都进行了上述变化,比如 12这个元素,原来索引为 (1,0,0) ,现在为 (0,1,0)
arr1 = arr.transpose((1,0,2))
arr2 = arr.T #直接用T是变为了(4,3,2)的形式 #arr3 = np.arange(120).reshape((2,3,4,5))
#arr4 = arr3.T #直接用T就是将形式变为 (5,4,3,2)
#ndarray还有swapaxes方法,接受一对轴编号
arr5 = arr.swapaxes(1,2) #print arr
#print arr1
#print arr2
#print arr3
#print arr4
print arr5 >>>
[[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]] [[12 16 20]
[13 17 21]
[14 18 22]
[15 19 23]]]
第二部分是关于一些元素级函数:即作用于数组每个元素上的函数,用过R语言之后就觉得其实没什么了。
下面是一些常见的矢量化函数(姑且这么叫吧)。


下面是几个例子:
#-*- encoding:utf-8 -*- import numpy as np
import numpy.random as npr
import pandas as pd #接收两个数组的函数,对应值取最大值
x = npr.randn(8)
y = npr.randn(8)
#注意不是max函数
z = np.maximum(x,y)
print x,y,z #虽然并不常见,但是一些ufunc函数的确可以返回多个数组。modf函数就是一例,用来分隔小数的整数部分和小数部分,是python中divmod的矢量化版本
arr = npr.randn(8)
print np.modf(arr)
#ceil函数取天花板,不小于这个数的最小整数
print np.ceil(arr)
#concatenate函数是将两个numpy数组连接,注意要组成元组方式再连接
#arr = np.concatenate((arr,np.array([0,0])))
#logical_not函数, 非 函数
#print np.logical_not(arr)
print np.greater(x,y)
print np.multiply(x,y)
第三部分:利用数组进行数据处理
作者说矢量化数组运算比纯pyhton方式快1-2个数量级(or more),又一次强调了broadcasting作用很强大。
#-*- encoding:utf-8 -*- import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #假设想在一个二维网格上计算一个 sqrt(x^2 + y^2)
#生成-5到5的网格,间隔0.01
points = np.arange(-5,5,0.01)
#meshgrid返回两个二维矩阵,描述出所有(-5,5)* (-5,5)的点对
xs,ys = np.meshgrid(points,points) z = np.sqrt(xs ** 2 + ys ** 2)
#print xs
#print ys
#不做个图都对不起观众
#imshow函数,展示z是一个矩阵,cmap就是colormap,用的时候值得研究
plt.imshow(z,cmap=plt.cm.gray)
plt.colorbar()
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
plt.show()
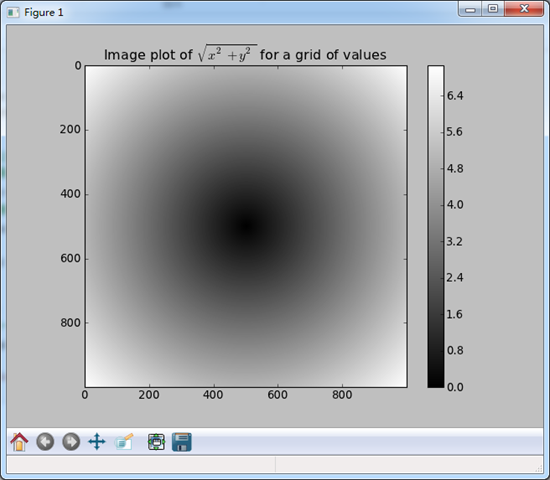
上面的画图语句在用的时候还需要好好研究一下。
下面的一个例子是np.where函数,简洁版本的if-else。
'''
#np.where函数通常用于利用已有的数组生产新的数组
arr = npr.randn(4,4)
#正值赋成2,负值为-2
print np.where(arr > 0,2,-2)
#注意这里的用法
print np.where(arr > 0,2,arr)
#可以用where表示更为复杂的逻辑表达
#两个布尔型数组cond1和cond2,4种不同的组合赋值不同
#注意:按照课本上的说法,下面的语句是从左向右运算的,不是从做内层括号计算起的;这貌似与python的语法不符
np.where(cond1 & cond2,0,np.where(cond1,1,np.where(cond2,2,3)))
#不过感觉没有更好的写法了。
#书上“投机取巧”的式子,前提是True = 1,False = 0
result = 1 * (cond1 - cond2) + 2 * (cond2 & -cond1) + 3 * -(cond1 | cond2)
'''
#-*- encoding:utf-8 -*- import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr
#值得注意的是,mean、sum这样的函数,会有一个参数axis表示对哪个维度求值
arr = np.array([[0,1,2],[3,4,5],[6,7,8]])
#cumsum不是聚合函数,维度不会减少
print arr.cumsum(0)
下面是常用的数学函数:


用于布尔型数组的方法
sum经常用于True的加和;any和all分别判断是否存在和是否全部为True。
排序及唯一化
#-*- encoding:utf-8 -*- import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr #sort函数是就地排序
arr = npr.randn(10)
print arr
arr.sort()
print arr
#多维数组可以按照维度排序,把轴编号传递给sort即可
arr = npr.randn(5,3)
print arr
#sort传入1,就是把第1轴排好序,即按列
arr.sort(1)
print arr
#np.sort返回的是排序副本,不是就地排序
#输出5%分位数
arr_npr = npr.randn(1000)
arr_npr.sort()
print arr_npr[int(0.05 * len(arr_npr))]
#pandas中有更多排序、分位数之类的函数,直接可以取分位数的,第二章的例子中就有
#numpy中有unique函数,唯一化函数,R语言中也有
names = np.array(['Bob','Joe','Will','Bob','Will'])
print sorted(set(names))
print np.unique(names)
values = np.array([6,0,0,3,2,5,6])
#in1d函数用来查看一个数组中的元素是否在另一个数组中,名字挺好玩,注意返回的长度与第一个数组相同
print np.in1d(values,[6,2,3])
下面是常用集合运算

用于数组的文件输入输出
NumPy能够读写磁盘上的文本数据或二进制数据。后面的章节将会给出一些pandas中用于将表格型数据读取到内存的工具。
np.save 和 np.load是读写磁盘数据的两个主要函数。默认情况下,数组是以未压缩的原始二进制文件格式保存在扩展名为.npy的文件中。
#-*- encoding:utf-8 -*- import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr
'''
arr = np.arange(10)
np.save('some_array',arr)
np.savez('array_archive.npz',a = arr,b = arr)
arr1 = np.load('some_array.npy')
arch = np.load('array_archive.npz')
print arr1
print arch['a']
'''
#下面是存取文本文件,pandas中的read_csv和read_table是最好的了
#有时需要用np.loadtxt或者np.genfromtxt将数据加载到普通的NumPy数组中
#这些函数有许多选项使用:指定各种分隔符,针对特定列的转换器函数,需要跳过的行数等
#np.savetxt执行的是相反的操作:将数组写到以某种分隔符隔开的文本文件中
#genfromtxt跟loadtxt差不多,只不过它面向的是结构化数组和缺失数据处理
线性代数
关于线性代数的一些函数,NumPy的linalg中有很多关于矩阵的函数,与MATLAB、R使用的是相同的行业标准级Fortran库。

随机数生成
NumPy.random模块对Python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值的函数。
#-*- encoding:utf-8 -*-
import numpy as np
import numpy.random as npr
from random import normalvariate
#生成标准正态4*4样本数组
samples = npr.normal(size = (4,4))
print samples
#从下面的例子中看出,如果产生大量样本值,numpy.random快了不止一个数量级
N = 1000000
#xrange()虽然也是内置函数,但是它被定义成了Python里一种类型(type),这种类型就叫做xrange.
#下面的循环中,for _ in xrange(N) 非常good啊,查了一下和range的关系,两者都用于循环,但是在大型循环时,xrange好得多
%timeit samples = [normalvariate(0,1) for _ in xrange(N)]
%timeit npr.normal(size = N)


范例:随机漫步
#-*- encoding:utf-8 -*-
import numpy as np
import random #这里的random是python内置的模块
import matplotlib.pyplot as plt position = 0
walk = [position]
steps = 1000
for i in xrange(steps):
step = 1 if random.randint(0,1) else -1
position += step
walk.append(position)
plt.plot(walk)
plt.show() #下面看看简单的写法
nsteps = 1000
draws = np.random.randint(0,2,size = nsteps)
steps = np.where(draws > 0,1,-1)
walk = steps.cumsum()
plt.plot(walk)
plt.show()
#argmax函数返回数组第一个最大值的索引,但是在这argmax不高效,因为它会扫描整个数组
print (np.abs(walk) >= 10).argmax() nwalks = 5000
nsteps = 1000
draws = np.random.randint(0,2,size = (nwalks,nsteps))
steps = np.where(draws > 0,1,-1)
walks = steps.cumsum(1)
print walks.max()
print walks.min()
#这里的any后面的参数1表示每行(轴为1)是否存在true
hist30 = (np.abs(walks) >= 30).any(1)
print hist30
print hist30.sum() #这就是有多少行超过了30
#这里argmax的参数1就是
crossing_time = (np.abs(walks[hist30]) >= 30).argmax(1)
print crossing_time.mean()
X = range(1000)
plt.plot(X,walks.T)
plt.show()
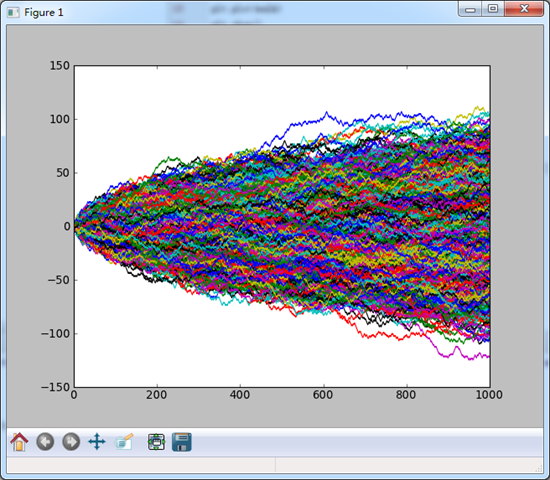
NumPy写完了,接下来写pandas.NumPy写的还好,比较顺利。
《利用python进行数据分析》读书笔记--第四章 numpy基础:数组和矢量计算的更多相关文章
- 《利用Python进行数据分析》笔记---第4章NumPy基础:数组和矢量计算
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- python numpy基础 数组和矢量计算
在python 中有时候我们用数组操作数据可以极大的提升数据的处理效率, 类似于R的向量化操作,是的数据的操作趋于简单化,在python 中是使用numpy模块可以进行数组和矢量计算. 下面来看下简单 ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- 《利用Python进行数据分析》笔记---第6章数据加载、存储与文件格式
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第5章pandas入门
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--1880-2010年间全美婴儿姓名
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--MovieLens 1M数据集
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--来自bit.ly的1.usa.gov数据
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数 通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数. 1)一元(unary)ufunc,如,sqrt和exp函数 2)二元(unary) ...
随机推荐
- JavaScript:编程改变文本样式
<!DOCTYPE HTML><html><head><meta http-equiv="Content-Type" Content=&q ...
- javaScript的简单学习
JavaScript介绍 JavaScript跟java没半毛钱关系 JavaScript有三部分组成:ECMAScript,document object model,broswer object ...
- 《Linux内核设计与实现》CHAPTER17阅读梳理
<Linux内核设计与实现>CHAPTER17阅读梳理 [学习时间:3.5hours] [学习内容:设备类型,模块,内核对象,sysfs] 个人思考部分见[]标出的部分 一.课堂讲解整理& ...
- Java 多线程之单例设计模式
转载:https://segmentfault.com/a/1190000007504892 概念: Java中单例模式是一种常见的设计模式,单例模式的写法有好几种,这里主要介绍两种:懒汉式单例.饿汉 ...
- DWR实现扫一扫登录功能
前言 <DWR实现后台推送消息到Web页面>一文中已对DWR作了简介,并列出了集成步骤.本文中再一次使用到DWR,用以实现扫一扫登录功能. 业务场景 web端首页点击"登陆&qu ...
- Sass与Web组件化相关的功能
Sass https://en.wikipedia.org/wiki/Sass_(stylesheet_language) Sass (Syntactically Awesome Stylesheet ...
- python3爬取网页
爬虫 python3爬取网页资源方式(1.最简单: import'http://www.baidu.com/'print2.通过request import'http://www.baidu.com' ...
- java随笔
java与c++的几点区别 (1)Java比C++程序可靠性更高.有人曾估计每50行C++程序中至少有一个BUG.姑且不去讨论这个数字是否夸张,但是任何一个C++程序员都不得不承认C++语言在提供强大 ...
- Fiddler的一些坑: !SecureClientPipeDirect failed: System.IO.IOException
手机的请求Fiddler可以捕捉,但是手机一直无法上网,在logs中看到的日志如下: !SecureClientPipeDirect failed: System.IO.IOException 由于远 ...
- CSS中position小解
我们先来看看CSS3 Api中对position属性的相关定义: static:无特殊定位,对象遵循正常文档流.top,right,bottom,left等属性不会被应用. relative:对象遵循 ...