hibernate(八) Hibernate检索策略(类级别,关联级别,批量检索)详解
序言
很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要想想,你花费的也就那么一点时间,别人花你这么多时间也能够学到你所学到的东西,所以还是要继续努力。既然不是天才,唯有靠勤奋来弥补。
--WZY
一、概述
检索策略分三大块,类级别检索策略和关联级别检测策略。
类级别检索策略:get、load、
关联级别检索策略:order.getCustomer().getName()
上面这两种应该是看得懂的。很容易去理解,现在就具体来说说这两种其中的细节。
批量检索解决n+1问题。
二、类级别检索策略
2.1、立即检索 get
直接发送sql语句,到数据库中去查询数据。
例如
Staff staff = (Staff)session.get(Staff.class, 3);//执行完这句,就会发送sql语句,到数据库表中查询相应的数据加入一级缓存中 //结果
Hibernate:
select
staff0_.id as id1_0_,
staff0_.name as name1_0_,
staff0_.deptId as deptId1_0_
from
staff staff0_
where
staff0_.id=?
2.2、延迟检索 load
不会直接发送sql语句,而是等到用的时候在发送sql语句,如果一直没用,就永远不会发送sql语句。
Staff staff = (Staff)session.load(Staff.class, 3);//执行完这句,不会发送sql语句
System.out.println("load后还没发送sql语句,等用到的时候才会发送。");
System.out.println(staff.getName());//现在需要用staff。则会发送sql语句。 //结果 load后还没发送sql语句,等用到的时候才会发送。
Hibernate:
select
staff0_.id as id1_0_,
staff0_.name as name1_0_,
staff0_.deptId as deptId1_0_
from
staff staff0_
where
staff0_.id=?
qqq2
2.3、深入讲解get和load
上面两个只是简单讲解一下立即加载和延迟加载两个概念。现在来讲点深入的东西。
1、load检索返回的代理对象,而不是一个pojo对象,get返回的是pojo对象,这个的前提是一级缓存中没有我们要查询的对象。

2、get和load都是先从一级缓存中拿数据,而不是每次都从数据库中拿,也就是说如果一级缓存有我们需要的数据,就不会在发送sql语句了。并且返回就是一级缓存对象中对象的状态,也就是说如果在一级缓存中该对象的状态是pojo对象,那么就算是用load加载的,返回的也就是pojo对象,如果该对象是代理对象,那么就算get加载的,返回的也就是代理对象,不过会将代理对象的数据初始化。也就是会向数据库中发送sql语句查询数据。 解释:代理对象数据初始化:代理对象中包含了我们想要的pojo对象的所有信息。
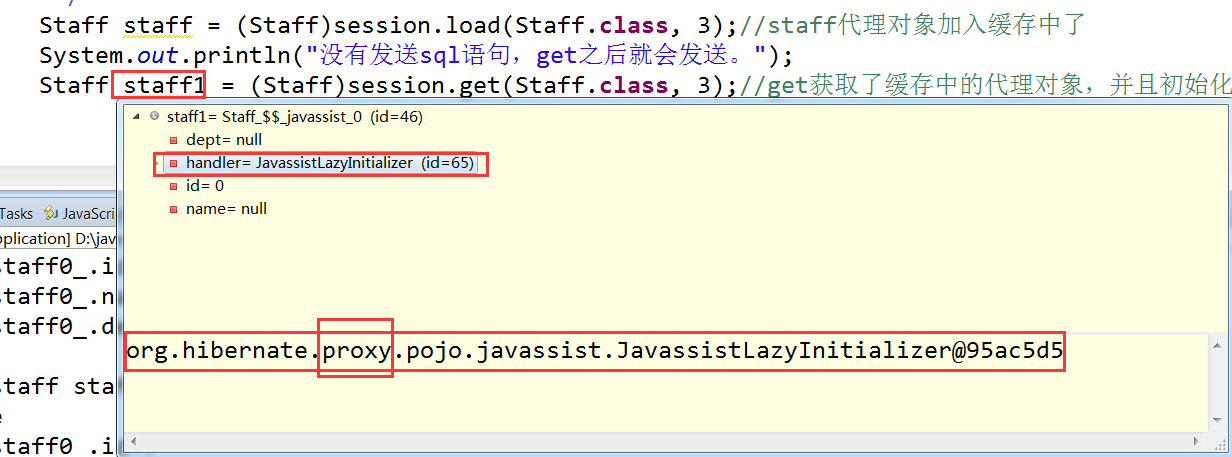
例子:一级缓存中的是代理对象,使用get获得
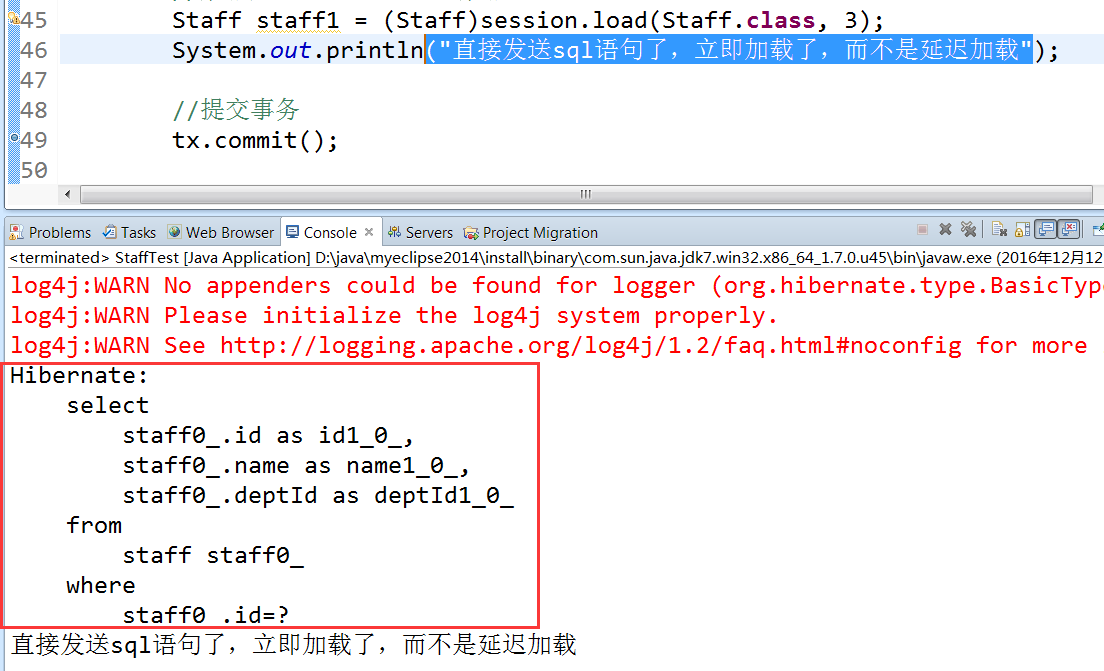
Staff staff = (Staff)session.load(Staff.class, 3);//staff代理对象加入缓存中了
System.out.println("没有发送sql语句,get之后就会发送。");
Staff staff1 = (Staff)session.get(Staff.class, 3);//get获取了缓存中的代理对象,并且初始化 //结果
没有发送sql语句,get之后就会发送。
Hibernate:
select
staff0_.id as id1_0_,
staff0_.name as name1_0_,
staff0_.deptId as deptId1_0_
from
staff staff0_
where
staff0_.id=?
例子: 一级缓存中是pojo对象,通过load获得
Staff staff = (Staff)session.get(Staff.class, 3);//staff pojo对象加入缓存中了
System.out.println("get后发送sql语句,并且该pojo对象在一级缓存中了。");
Staff staff1 = (Staff)session.load(Staff.class, 3);//load获取了缓存中的pojo对象 //结果
Hibernate:
select
staff0_.id as id1_0_,
staff0_.name as name1_0_,
staff0_.deptId as deptId1_0_
from
staff staff0_
where
staff0_.id=?
get后发送sql语句,并且该pojo对象在一级缓存中了。

3、只有在使用时,代理对象才会初始化,其实还有一种方式可以不使用代理对象而初始化数据,
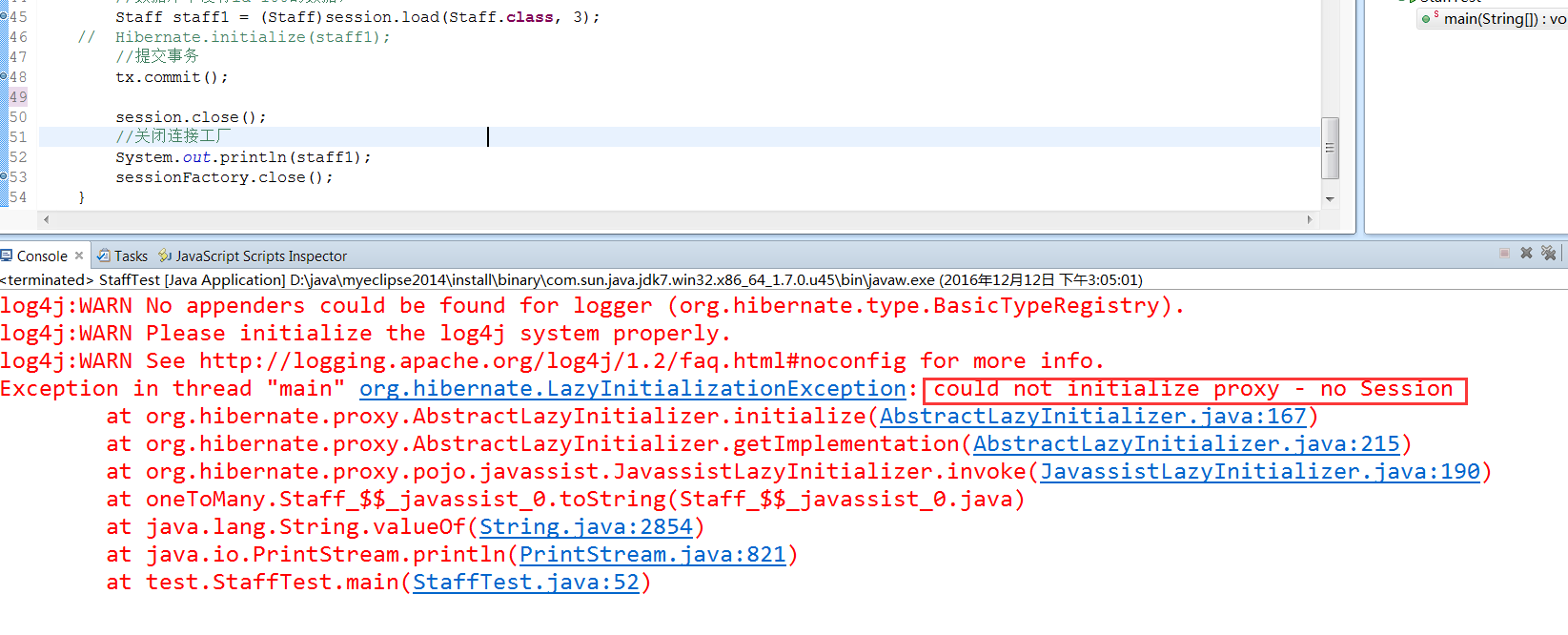 、
、
因为没有初始化代理对象,在关闭session后,在使用staff1,就会报错,报错内容为不能够初始化代码对象,没有session,
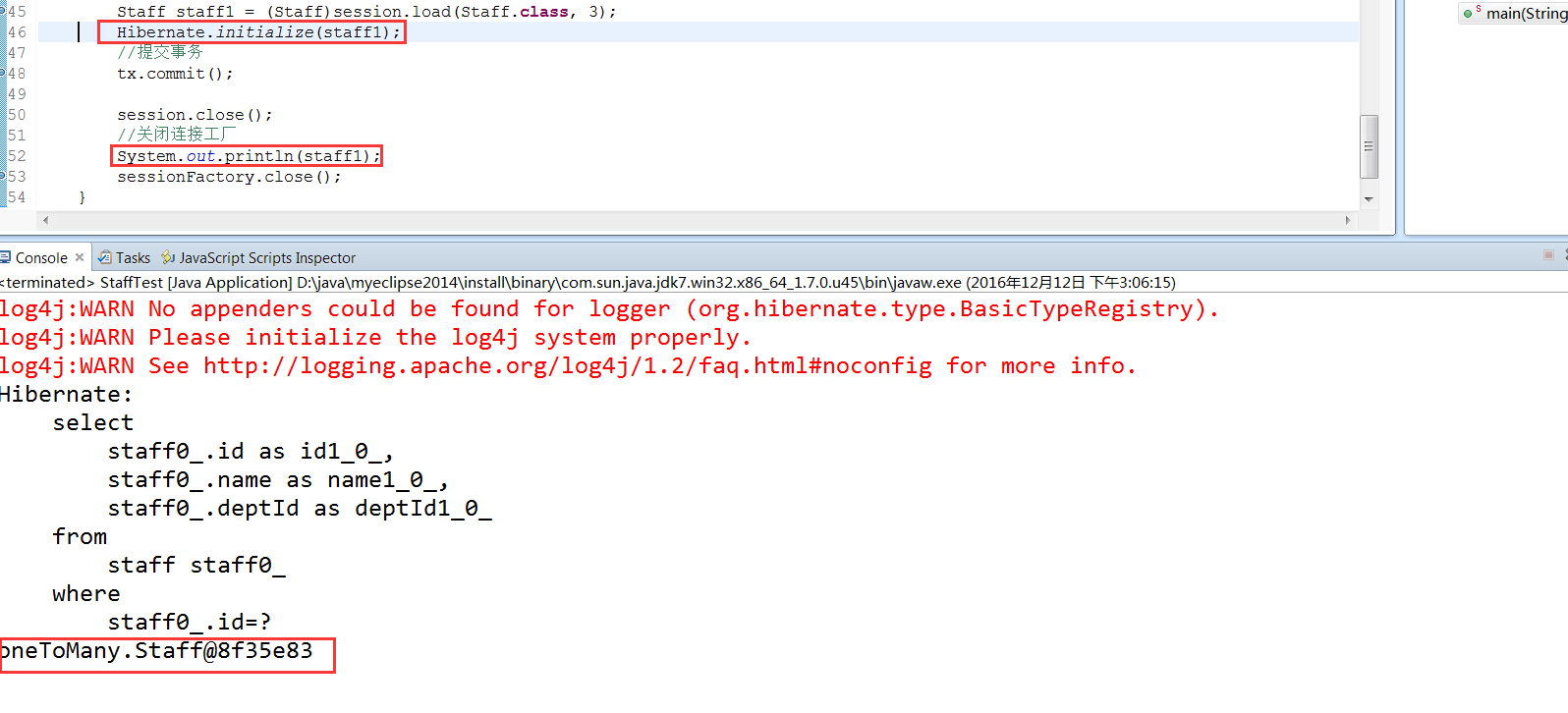
使用Hibernate.initialize(proxy);来对代理对象进行初始化,这个的效果和使用代理对象是一样的,但是会使代码看起来更好,如果你在这里system.out.println(代理对象),也有也可以,但是看起来总觉得乖乖的,所以hibernate就有了这个方法来对代理对象进行初始化。
4、可以通过lazy属性来设置让load不延迟加载,而跟get一样立即加载,因为是类级别检索,所以在hbm映射文件中的class位置进行属性设置。

在staff.hbm.xml中设置了lazy=false。意思是让其延迟加载失效,所以在对staff进行查询时,使用load也是立即检索
5、我们常说的,get如果查询数据库中没有的记录的话,返回是null,而load将会报错。这句话是正确的,但是概念很模糊,来看下面的路子看会不会报错。
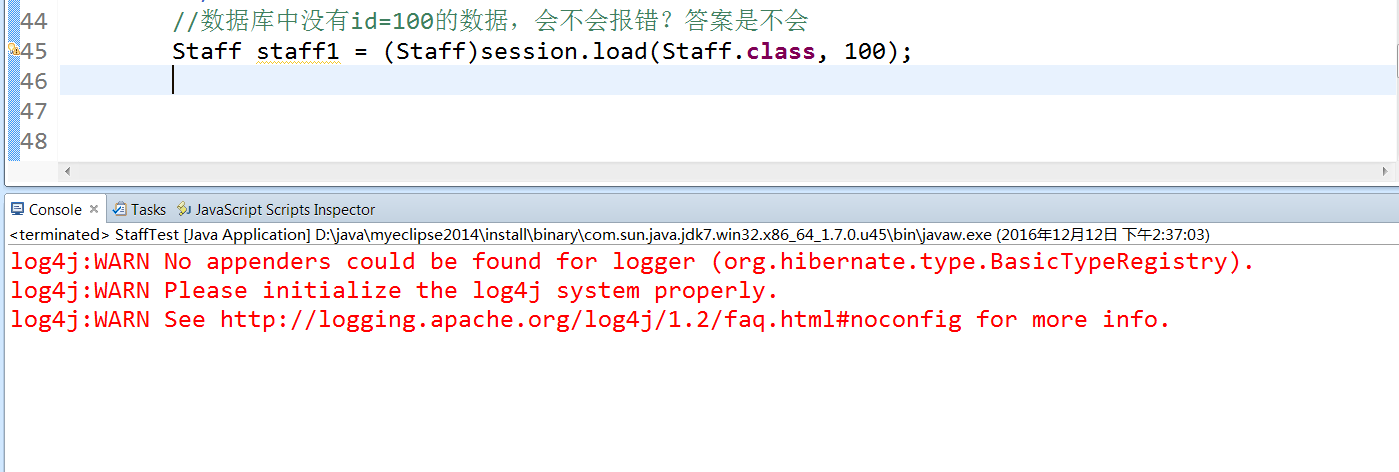
例子一:查询数据库中没有的数据,id=100,load的时候会不会报错? 报错
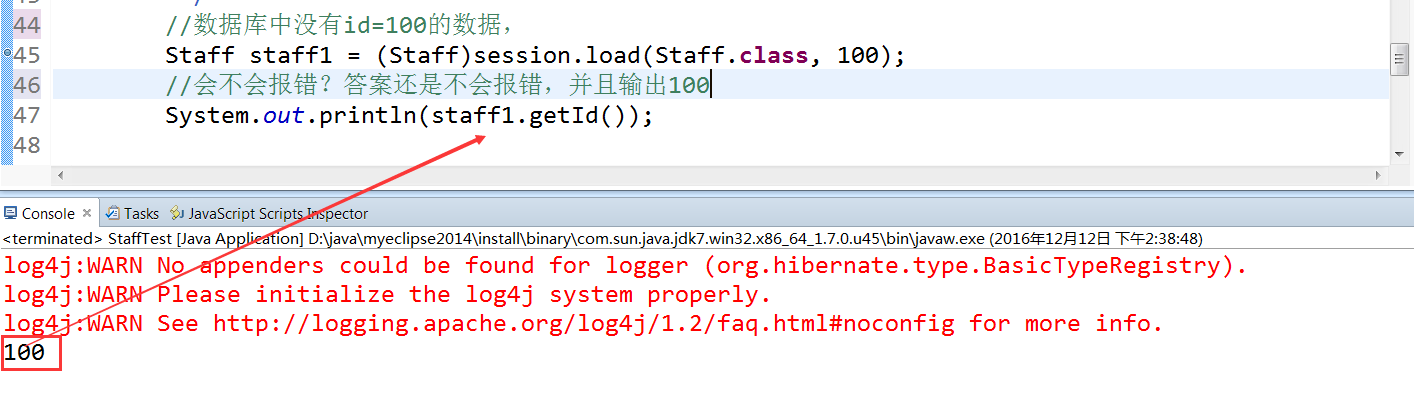
例子二:查询数据库中没有的数据,id=100,并且将其取出id 不抱错
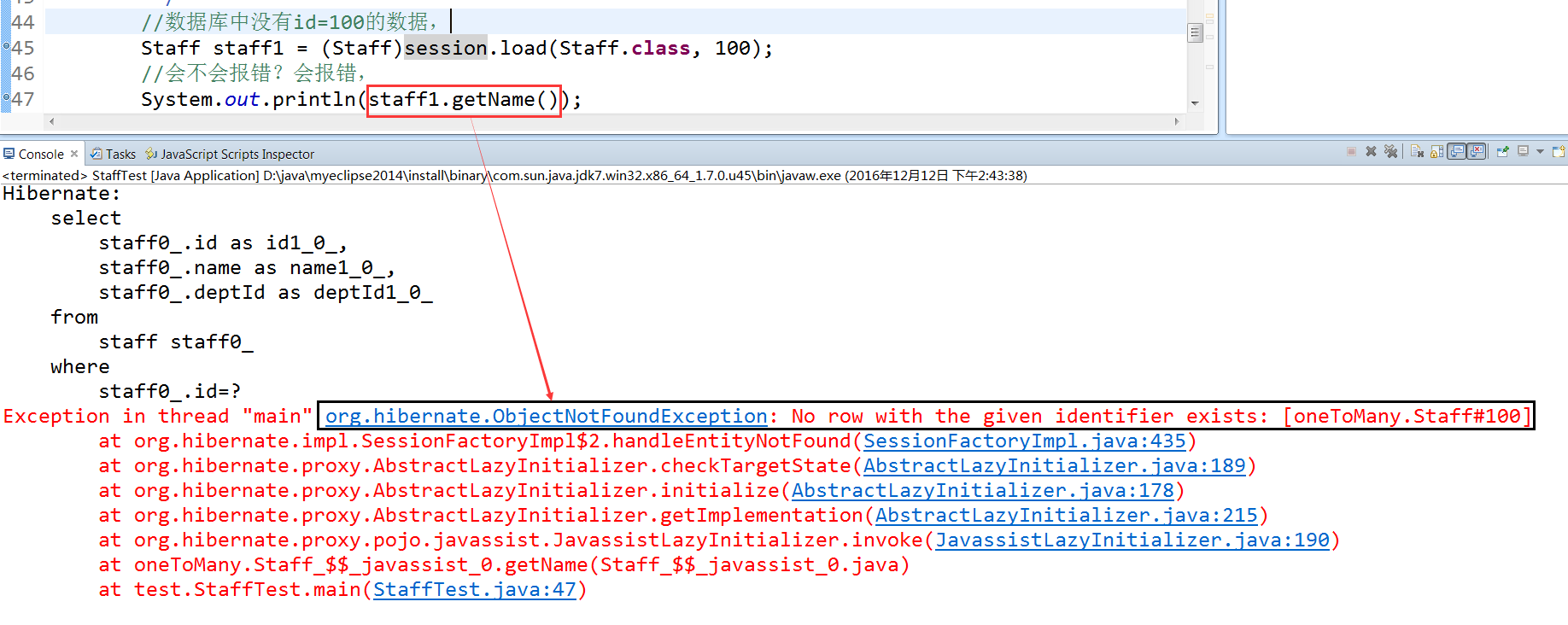
例子三:查询数据库中没有的数据,id=100,并且取出name 报错
总结load:load加载返回的是一个代理对象,并且我们说的用load查询一个数据库中没有的数据,并不是load这条语句报异常,而是在使用时,代理对象在数据库表中找不到数据而报的异常,所以单纯只写load语句,是不会报错的,并且代理对象的id是我们手动输入进去的,不用往数据库中查也知道,所以在代理对象.getId()时也不会发送sql语句,而是拿到我们一开始的id值。
2.4、load和get的区别(面试题)
1、get是立即加载、load是延迟加载
2、get和load都是先从缓存中查找对象,如果有该对象的缓存,则不向数据库中查询,并且返回的是缓存中对象的状态(是代理对象就返回代理对象,是pojo对象就返回pojo对象)
3、在缓存中没有对象时,get返回的是pojo对象,load返回的是代理对象
三、关联级别检索策略
在<set>标签上或者在<many-to-one>上设置两个属性值来控制其检索策略, fetch、lazy
fetch:代表检索时的语句的方式,比如左外连接等。
fetch:join、select 、subselect
lazy:是否延迟加载。
lazy:true、false、extra
分两种情况
3.1、一对多或多对多时
<set fetch="",lazy="">
fetch = join时,采取迫切左外连接查询
lazy不管取什么值都失效,就是取默认值为false。
fetch=select时,生成多条简单sql查询语句
lazy=false:立即检索
lazy=true:延迟检索
lazy=extra:加强延迟检索,非常懒惰,比延迟检索更加延迟
fetch=subselect时,生成子查询
lazy=false:立即检索
lazy=true;延迟检索
lazy=extra:加强延迟检索,非常懒惰,比延迟检索更加延迟
实验一:fetch=join 发送左外迫切连接
一、hql的query查询

使用hql的query查询,会让fetch=join失效,lazy重新启用。如果生成结果是延迟检索,那么就说明我们说的这个是正确的。
//使用hql查询,fetch=join是无效的,并且lazy重新启用,本来lazy失效的话,
//则使用默认的,就是立即加载,现在因为重新启用了,所以会是延迟加载
Query query = session.createQuery("from Dept where id = 2");
Dept dept = (Dept) query.uniqueResult();
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
dept.getStaffSet().size(); //结果 Hibernate:
select
dept0_.id as id0_,
dept0_.name as name0_
from
dept dept0_
where
dept0_.id=2
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
二、使用get查询。fetch=join生效,lazy就会失效,并且会发送左外迫切连接。这里要注意,要看set中存放的东西是什么,而不是看发送的语句是不是含有fetch来判断是不是左外迫切连接,因为hibernate中,左外迫切连接发送的语句跟左外连接发送的语句是一样的,从这里是区分不出来了。如果不信的话,自己可以去尝试一下,手动写一个左外迫切连接,然后看发送的语句是什么样的,我试过了,跟我说的一样
Dept dept = (Dept) session.get(Dept.class, 2);
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
Set<Staff> set = dept.getStaffSet();
System.out.println(set); //结果
Hibernate:
select
dept0_.id as id0_1_,
dept0_.name as name0_1_,
staffset1_.deptId as deptId0_3_,
staffset1_.id as id3_,
staffset1_.id as id1_0_,
staffset1_.name as name1_0_,
staffset1_.deptId as deptId1_0_
from
dept dept0_
left outer join
staff staffset1_
on dept0_.id=staffset1_.deptId
where
dept0_.id=?
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
[oneToMany.Staff@367e4144, oneToMany.Staff@20a709f3, oneToMany.Staff@1dc39acc, oneToMany.Staff@1aeef34f, oneToMany.Staff@1d82e71, oneToMany.Staff@55a7e5ae, oneToMany.Staff@3da7d559, oneToMany.Staff@782d5c85, oneToMany.Staff@6a155d66]
总结第一种情况fetch=join。
1、注意我们这里讨论的是关联级别的检索方式,所以重点是看关联的时候发送的sql语句,重心不在get和load上面了
2、fetch=join让lazy失效的前提是使用的不是hql的query查询。
实验二:fetch=select时 发送简单sql语句
lazy=false;也就是立即检索,发送简单sql语句

Dept dept = (Dept) session.get(Dept.class, 2);
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
Set<Staff> set = dept.getStaffSet();
System.out.println(set); //结果
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
[oneToMany.Staff@5091be16, oneToMany.Staff@5c1a555, oneToMany.Staff@753f827a, oneToMany.Staff@6c4d7266, oneToMany.Staff@58e83637, oneToMany.Staff@15dbd461, oneToMany.Staff@1056bfad, oneToMany.Staff@2f41ff3c, oneToMany.Staff@1c8f53b9]
lazy=true;延迟检索,发送简单sql语句

Dept dept = (Dept) session.get(Dept.class, 2);
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
Set<Staff> set = dept.getStaffSet();
System.out.println(set); //结果
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
[oneToMany.Staff@5091be16, oneToMany.Staff@5c1a555, oneToMany.Staff@753f827a, oneToMany.Staff@6c4d7266, oneToMany.Staff@58e83637, oneToMany.Staff@1056bfad, oneToMany.Staff@2f41ff3c, oneToMany.Staff@1c8f53b9, oneToMany.Staff@645c1312]
lazy=extra;超级懒惰,能尽量少查就绝对不会多查,比如,size(),就会使用count()函数,而不会全部查表中的字段,就是这个意思

Dept dept = (Dept) session.get(Dept.class, 2);
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
Set<Staff> set = dept.getStaffSet();
System.out.println(set.size()); //结果
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
Hibernate:
select
count(id)
from
staff
where
deptId =?
9
实验三、fetch=subselect 生成子查询,注意使用get方式不生成子查询,使用query().list().get(),并且数据库表中还得不止一条记录才会生成子查询,如果只有一条记录,hibernate也很聪明,就没必要用子查询了。
lazy=false:立即检索
Dept dept = (Dept) session.createQuery("from Dept").list().get(0);
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
Set<Staff> set = dept.getStaffSet();
System.out.println(set);
//结果
Hibernate:
select
dept0_.id as id0_,
dept0_.name as name0_
from
dept dept0_
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId in (
select
dept0_.id
from
dept dept0_
)
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
[oneToMany.Staff@62c2bff3, oneToMany.Staff@583c72d7, oneToMany.Staff@6897ae82, oneToMany.Staff@19d5f3ea, oneToMany.Staff@3160c0bd, oneToMany.Staff@4af364d4, oneToMany.Staff@4afbc8ce, oneToMany.Staff@5fc81d2c, oneToMany.Staff@3e420e73]
lazy=true:延迟检索
lazy=extra;超级懒惰,比延迟检索还延迟
这两个其实也就差不多了,自己可以试试
3.2、多对一或一对一时
fetch可以取值为:join,select
lazy:false,proxy,no-proxy
当fetch=join,lazy会失效,生成的sql是迫切左外连接
如果我们使用query时,hql是我们自己指定的,那么fetch=join是无效的,不会生成迫切左外连接,这时lazy重新启用
当fetch=select,lazy不失效,生成简单sql语句,
lazy=false:立即检索
lazy=proxy:这时关联对象采用什么样的检索策略取决于关联对象的类级别检索策略.就是说参考<class>上的lazy的值
其实跟上面一样,我们是测试一个fetch=select,lazy=proxy的把。
staff,也就是多方,

dept,也就是一方

按照我们所配置的,关联级别检索应该是延迟检索,结果正如我们所想的。
Staff staff = (Staff) session.createQuery("from Staff").list().get(0);
System.out.println("如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载");
Dept dept = staff.getDept();
System.out.println(dept);
//结果
Hibernate:
select
staff0_.id as id1_,
staff0_.name as name1_,
staff0_.deptId as deptId1_
from
staff staff0_
如果sql语句在这句话之上说明是立即加载,如果在之下就是延迟加载
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
Dept [id=2, name=1部门]
总结:
1、为什么需要分(一对多,多对多)和(多对一,一对一)两组情况呢?
注意:这里说的一对多,那么就是单向一对多,也就是占在一的角度去考虑东西,上面说的四种都是从左边往右边看。
因为一对多和多对多,所拿到的关联对象度是一个集合,查询的记录就有很多个,也就多了一个fetch=subselect这个特性,查询方式的变化也就多一点,
而多对一,一对一,所拿到的关联对象就是一个对象,也就是一条记录,查询的方式比较单一和简单
因为上面的原因就把他们两个给分开来以处理不同的情况。达到更高的效率。
2、为什么需要搞这样的检索方式,不很麻烦吗?
根据不同的业务需求,来让开发者自己控制用什么样的检索方式,这样让程序的性能更好
四、批量检索
什么叫批量检索,就是多条sql语句才能完成的查询,现在一条sql语句就能解决多条sql语句才能完成的事情,看下面例子就明白了,
例子:n+1问题,什么叫n+1问题?
就拿我们上面这个例子来说,Dept和Staff,现在有5个部门,每个部门中的人数可能一样,也可能不一样,要求,查询每个部门中的员工。那么我们写的话就需要发送6条sql语句,哪6条呢?第一条查询部门表中所有的部门,剩下5条,拿到每一个部门的ID,去员工表中查找每个部门中的员工,要查5次,因为有5个部门。本来只有5个部门,现在需要发送6条sql语句,这就是n+1问题,看下面代码
总之就发送了6条sql语句,我已经数过了。
List<Dept> list = session.createQuery("from Dept").list();
for(Dept dept : list){
System.out.println(dept.getStaffSet());
}
//结果
Hibernate:
select
dept0_.id as id0_,
dept0_.name as name0_
from
dept dept0_
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
[oneToMany.Staff@ffdde88, oneToMany.Staff@1a33cda6, oneToMany.Staff@3160c0bd, oneToMany.Staff@48860e29, oneToMany.Staff@1538c1e3, oneToMany.Staff@339289a7, oneToMany.Staff@3f025aba, oneToMany.Staff@598b4d64, oneToMany.Staff@641cbaeb, oneToMany.Staff@590bcaf1]
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
[oneToMany.Staff@650e7ac9, oneToMany.Staff@456ffab9, oneToMany.Staff@3ab5ab4c, oneToMany.Staff@5456df43, oneToMany.Staff@718bc0c4, oneToMany.Staff@7fde1684, oneToMany.Staff@6d0128b0, oneToMany.Staff@157f068f, oneToMany.Staff@55cfffa2, oneToMany.Staff@46e1d5d9, oneToMany.Staff@4d9875b1, oneToMany.Staff@104628c, oneToMany.Staff@4687a14f, oneToMany.Staff@135bd2f7, oneToMany.Staff@149ebdea, oneToMany.Staff@726f6db5, oneToMany.Staff@4a9810b1, oneToMany.Staff@72c5c2e7, oneToMany.Staff@e1cbe19, oneToMany.Staff@671672b8]
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
[oneToMany.Staff@5ce4c86b, oneToMany.Staff@23081b81, oneToMany.Staff@132ff4b6, oneToMany.Staff@316ae291, oneToMany.Staff@480955df, oneToMany.Staff@30221872, oneToMany.Staff@6945c41e, oneToMany.Staff@1f43a98b, oneToMany.Staff@634ec390, oneToMany.Staff@e72fd0e]
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
[oneToMany.Staff@269c2a55, oneToMany.Staff@4d45222c, oneToMany.Staff@1a66421c, oneToMany.Staff@2f7e49ce, oneToMany.Staff@42c51adb, oneToMany.Staff@5103c049, oneToMany.Staff@c1f8bbe, oneToMany.Staff@75c69e55, oneToMany.Staff@41c7d5a8, oneToMany.Staff@6b0f6d29]
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId=?
[oneToMany.Staff@1cf8338b, oneToMany.Staff@7beca583, oneToMany.Staff@5fb369e2, oneToMany.Staff@532cb84e, oneToMany.Staff@6afff988, oneToMany.Staff@1d8df66a, oneToMany.Staff@52ae002e, oneToMany.Staff@6b8dce4, oneToMany.Staff@5f45cd73, oneToMany.Staff@4b578699]
解决:使用一个属性,batch-size。
1、从部门查员工。也就是从单向一对多,从一方查多方,查询每个部门中的员工有哪些这样的问题?,那么就在映射文件中的set中设置batch-size。有多少个部门,就至少设置多少,意思就是一次性查询多少个。从上面的例子中可以看出,发送了5条对staff的查询语句,所以这里batch-size至少为5,大于5可以,浪费了,小于5的话,又会多发sql语句。所以如果能够确定查询多少个,那么就写确定值,如果不能确定,那么就写稍微大一点;

可以看结果,只发送两条sql语句,第一条是查询部门的,第二条是一看,使用关键字 IN 来将所有的部门ID含括在内,我们应该就知道了,原来原理是这样,这样就只需要发送一条sql语句,来达到发送5条sql语句才能完成的功能。 这就是批量检索,其实原理很简单
List<Dept> list = session.createQuery("from Dept").list();
for(Dept dept : list){
System.out.println(dept.getStaffSet());
}
//结果,只发送两条sql语句
Hibernate:
select
dept0_.id as id0_,
dept0_.name as name0_
from
dept dept0_
Hibernate:
select
staffset0_.deptId as deptId0_1_,
staffset0_.id as id1_,
staffset0_.id as id1_0_,
staffset0_.name as name1_0_,
staffset0_.deptId as deptId1_0_
from
staff staffset0_
where
staffset0_.deptId in (
?, ?, ?, ?, ?
)
[oneToMany.Staff@4d9875b1, oneToMany.Staff@3ab5ab4c, oneToMany.Staff@456ffab9, oneToMany.Staff@5456df43, oneToMany.Staff@135bd2f7, oneToMany.Staff@6d0128b0, oneToMany.Staff@7177600e, oneToMany.Staff@199f55f4, oneToMany.Staff@4a9810b1, oneToMany.Staff@671672b8]
[oneToMany.Staff@4d6a54b0, oneToMany.Staff@41c65839, oneToMany.Staff@718bc0c4, oneToMany.Staff@7fde1684, oneToMany.Staff@1538c1e3, oneToMany.Staff@4d2d1f6d, oneToMany.Staff@157f068f, oneToMany.Staff@1ce89199, oneToMany.Staff@46e1d5d9, oneToMany.Staff@414128f7, oneToMany.Staff@104628c, oneToMany.Staff@4687a14f, oneToMany.Staff@149ebdea, oneToMany.Staff@68aee2a2, oneToMany.Staff@726f6db5, oneToMany.Staff@72c5c2e7, oneToMany.Staff@e1cbe19, oneToMany.Staff@88f2363, oneToMany.Staff@31a12f5f, oneToMany.Staff@590bcaf1]
[oneToMany.Staff@59bd770a, oneToMany.Staff@3402d895, oneToMany.Staff@23081b81, oneToMany.Staff@79897ed0, oneToMany.Staff@26d938e0, oneToMany.Staff@7f250e0c, oneToMany.Staff@31e4c806, oneToMany.Staff@25d25f8d, oneToMany.Staff@44ca27eb, oneToMany.Staff@167f3561]
[oneToMany.Staff@5ce4c86b, oneToMany.Staff@132ff4b6, oneToMany.Staff@316ae291, oneToMany.Staff@480955df, oneToMany.Staff@30221872, oneToMany.Staff@6945c41e, oneToMany.Staff@6040b6ef, oneToMany.Staff@1f43a98b, oneToMany.Staff@634ec390, oneToMany.Staff@e72fd0e]
[oneToMany.Staff@3f574c4a, oneToMany.Staff@56a88251, oneToMany.Staff@7c51aec2, oneToMany.Staff@4d45222c, oneToMany.Staff@38aa3647, oneToMany.Staff@1a66421c, oneToMany.Staff@42c51adb, oneToMany.Staff@5103c049, oneToMany.Staff@2ed18c61, oneToMany.Staff@75c69e55]
2、上面是从一查多,batch-size放在set中。从多查一呢,在many-to-one中并没有batch-size这个属性。注意了,此时batch-size放在一方的class中。看下图

先不着急看批量检索后的结果,先来看看如果没有该属性,会怎么发送sql语句。发送多少条。
查询每个员工所属的部门信息。一想,如果每个员工都到部门表中查一次,包括开始查询自己员工的信息,也是n+1问题,比如有10个员工,那么就会发送11个sql语句,如果你这样想,就误解了这个n+1的意思。这个n+1的意思跟上面从部门查询员工的n+1的意思是一样的,因为不管有多少个员工,其中总会有一些员工是在同一个部门,既然在同一个部门,那么就不用一直发送重复的sql语句了,而是相同部门的员工,就只查询一次就足够了。所以,不管有多少员工,发送的sql语句还是部门的数量加1.也就是n+1,这才是真正的n+1问题。来看不用批量检索时,员工查询部门是不是发送6条sql语句

List<Staff> list = session.createQuery("from Staff").list();
for(Staff staff : list){
System.out.println(staff.getName()+","+staff.getDept());
}
//结果
Hibernate:
select
staff0_.id as id1_,
staff0_.name as name1_,
staff0_.deptId as deptId1_
from
staff staff0_
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
qqq,Dept [id=2, name=2部门]
qqq1,Dept [id=2, name=2部门]
qqq2,Dept [id=2, name=2部门]
qqq3,Dept [id=2, name=2部门]
qqq4,Dept [id=2, name=2部门]
qqq5,Dept [id=2, name=2部门]
qqq6,Dept [id=2, name=2部门]
qqq7,Dept [id=2, name=2部门]
qqq8,Dept [id=2, name=2部门]
qqq9,Dept [id=2, name=2部门]
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
yyy0,Dept [id=1, name=1部门]
yyy1,Dept [id=1, name=1部门]
yyy2,Dept [id=1, name=1部门]
yyy3,Dept [id=1, name=1部门]
yyy4,Dept [id=1, name=1部门]
yyy5,Dept [id=1, name=1部门]
yyy6,Dept [id=1, name=1部门]
yyy7,Dept [id=1, name=1部门]
yyy8,Dept [id=1, name=1部门]
yyy9,Dept [id=1, name=1部门]
yyy0,Dept [id=2, name=2部门]
yyy1,Dept [id=2, name=2部门]
yyy2,Dept [id=2, name=2部门]
yyy3,Dept [id=2, name=2部门]
yyy4,Dept [id=2, name=2部门]
yyy5,Dept [id=2, name=2部门]
yyy6,Dept [id=2, name=2部门]
yyy7,Dept [id=2, name=2部门]
yyy8,Dept [id=2, name=2部门]
yyy9,Dept [id=2, name=2部门]
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
yyy0,Dept [id=3, name=3部门]
yyy1,Dept [id=3, name=3部门]
yyy2,Dept [id=3, name=3部门]
yyy3,Dept [id=3, name=3部门]
yyy4,Dept [id=3, name=3部门]
yyy5,Dept [id=3, name=3部门]
yyy6,Dept [id=3, name=3部门]
yyy7,Dept [id=3, name=3部门]
yyy8,Dept [id=3, name=3部门]
yyy9,Dept [id=3, name=3部门]
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
yyy0,Dept [id=4, name=4部门]
yyy1,Dept [id=4, name=4部门]
yyy2,Dept [id=4, name=4部门]
yyy3,Dept [id=4, name=4部门]
yyy4,Dept [id=4, name=4部门]
yyy5,Dept [id=4, name=4部门]
yyy6,Dept [id=4, name=4部门]
yyy7,Dept [id=4, name=4部门]
yyy8,Dept [id=4, name=4部门]
yyy9,Dept [id=4, name=4部门]
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id=?
yyy0,Dept [id=5, name=5部门]
yyy1,Dept [id=5, name=5部门]
yyy2,Dept [id=5, name=5部门]
yyy3,Dept [id=5, name=5部门]
yyy4,Dept [id=5, name=5部门]
yyy5,Dept [id=5, name=5部门]
yyy6,Dept [id=5, name=5部门]
yyy7,Dept [id=5, name=5部门]
yyy8,Dept [id=5, name=5部门]
yyy9,Dept [id=5, name=5部门]
自己数一下,确实是发送的6条sql语句,然后在Dept的class中加上batch-size属性。
结果就发送两条sql语句。
List<Staff> list = session.createQuery("from Staff").list();
for(Staff staff : list){
System.out.println(staff.getName()+","+staff.getDept());
}
//结果
Hibernate:
select
staff0_.id as id1_,
staff0_.name as name1_,
staff0_.deptId as deptId1_
from
staff staff0_
Hibernate:
select
dept0_.id as id0_0_,
dept0_.name as name0_0_
from
dept dept0_
where
dept0_.id in (
?, ?, ?, ?, ?
)
qqq,Dept [id=2, name=2部门]
qqq1,Dept [id=2, name=2部门]
qqq2,Dept [id=2, name=2部门]
qqq3,Dept [id=2, name=2部门]
qqq4,Dept [id=2, name=2部门]
qqq5,Dept [id=2, name=2部门]
qqq6,Dept [id=2, name=2部门]
qqq7,Dept [id=2, name=2部门]
qqq8,Dept [id=2, name=2部门]
qqq9,Dept [id=2, name=2部门]
yyy0,Dept [id=1, name=1部门]
yyy1,Dept [id=1, name=1部门]
yyy2,Dept [id=1, name=1部门]
yyy3,Dept [id=1, name=1部门]
yyy4,Dept [id=1, name=1部门]
yyy5,Dept [id=1, name=1部门]
yyy6,Dept [id=1, name=1部门]
yyy7,Dept [id=1, name=1部门]
yyy8,Dept [id=1, name=1部门]
yyy9,Dept [id=1, name=1部门]
yyy0,Dept [id=2, name=2部门]
yyy1,Dept [id=2, name=2部门]
yyy2,Dept [id=2, name=2部门]
yyy3,Dept [id=2, name=2部门]
yyy4,Dept [id=2, name=2部门]
yyy5,Dept [id=2, name=2部门]
yyy6,Dept [id=2, name=2部门]
yyy7,Dept [id=2, name=2部门]
yyy8,Dept [id=2, name=2部门]
yyy9,Dept [id=2, name=2部门]
yyy0,Dept [id=3, name=3部门]
yyy1,Dept [id=3, name=3部门]
yyy2,Dept [id=3, name=3部门]
yyy3,Dept [id=3, name=3部门]
yyy4,Dept [id=3, name=3部门]
yyy5,Dept [id=3, name=3部门]
yyy6,Dept [id=3, name=3部门]
yyy7,Dept [id=3, name=3部门]
yyy8,Dept [id=3, name=3部门]
yyy9,Dept [id=3, name=3部门]
yyy0,Dept [id=4, name=4部门]
yyy1,Dept [id=4, name=4部门]
yyy2,Dept [id=4, name=4部门]
yyy3,Dept [id=4, name=4部门]
yyy4,Dept [id=4, name=4部门]
yyy5,Dept [id=4, name=4部门]
yyy6,Dept [id=4, name=4部门]
yyy7,Dept [id=4, name=4部门]
yyy8,Dept [id=4, name=4部门]
yyy9,Dept [id=4, name=4部门]
yyy0,Dept [id=5, name=5部门]
yyy1,Dept [id=5, name=5部门]
yyy2,Dept [id=5, name=5部门]
yyy3,Dept [id=5, name=5部门]
yyy4,Dept [id=5, name=5部门]
yyy5,Dept [id=5, name=5部门]
yyy6,Dept [id=5, name=5部门]
yyy7,Dept [id=5, name=5部门]
yyy8,Dept [id=5, name=5部门]
yyy9,Dept [id=5, name=5部门]
疑问一:为什么从一到多,batch-size就放在set中,而从多到一,batch-size也是放在一方的class中?
这样去想:一方查多方,在一方的set中就代表着多方的对象,将batch-size放在set中,就可以理解查多方的时候,就使用批量检索了。
多方查一方,在一方的class中设置batch-size。可以理解,当多方查到一方时,在一方的映射文件中的class部分遇到了batch-size就知道查询一方时需要批量检索了
这样应该更好理解和记忆。
五、总结
这一章节分析的是三大检索方式。其目的是让开发者自己能够调节性能,就三大块内容
1、类级别检索
get和load的区别,和原理。
2、关联级别检索
fetch和lazy属性的用法。 这里面要理解的前提是对sql语句比较了解,要知道什么是左外连接,才能进一步讨论迫切左外连接是什么。
一对多和多对多一组讨论其用法
多对一和一对一为一组讨论其用法
3、批量检索
解决n+1问题,要知道n+1描述的是什么问题。
差不多就到这里了,一定不要因为学了这章导致基本的hibernate查询度不会了,这个只是为了调节性能而深入讨论的东西。平常该怎么用就怎么用,该怎么用hql或者qbc查询就怎么查询。只是在get、load查询或者关联级别查询时留个心眼就足够了。
hibernate(八) Hibernate检索策略(类级别,关联级别,批量检索)详解的更多相关文章
- Hibernate缓存简介和对比、一级缓存、二级缓存详解
一.hibernate缓存简介 缓存的范围分为3类: 1.事务范围(单Session即一级缓存) 事务范围的缓存只能被当前事务访问,每个事务都有各自的缓存,缓存内的数据通常采用相互关联的对象 ...
- 并发编程(六)Object类中线程相关的方法详解
一.notify() 作用:唤醒一个正在等待该线程的锁的线程 PS : 唤醒的线程不会立即执行,它会与其他线程一起,争夺资源 /** * Object类的notify()和notifyAll()方法详 ...
- moviepy音视频剪辑:视频剪辑基类VideoClip的属性及方法详解
☞ ░ 前往老猿Python博文目录 ░ 一.概述 在<moviepy音视频剪辑:moviepy中的剪辑基类Clip详解>和<moviepy音视频剪辑:moviepy中的剪辑基类Cl ...
- 《手把手教你》系列技巧篇(二十八)-java+ selenium自动化测试-处理模态对话框弹窗(详解教程)
1.简介 在前边的文章中窗口句柄切换宏哥介绍了switchTo方法,这篇继续介绍switchTo中关于处理alert弹窗的问题.很多时候,我们进入一个网站,就会弹窗一个alert框,有些我们直接关闭, ...
- 《手把手教你》系列技巧篇(四十八)-java+ selenium自动化测试-判断元素是否可操作(详解教程)
1.简介 webdriver有三种判断元素状态的方法,分别是isEnabled,isSelected 和 isDisplayed,其中isSelected在前面的内容中已经简单的介绍了,isSelec ...
- 《手把手教你》系列技巧篇(七十一)-java+ selenium自动化测试-自定义类解决元素同步问题(详解教程)
1.简介 前面宏哥介绍了几种关于时间等待的方法,也提到了,在实际自动化测试脚本开发过程,百分之90的报错是和元素因为时间不同步而发生报错.本文介绍如何新建一个自定义的类库来解决这个元素同步问题.这样, ...
- Hibernate学习(八)———— Hibernate检索策略(类级别,关联级别,批量检索)详解
序言 很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要 ...
- moviepy音视频剪辑:moviepy中的剪辑基类Clip的属性和方法详解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt+moviepy音视频剪辑实战 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一. ...
- Java基础进阶:多态与接口重点摘要,类和接口,接口特点,接口详解,多态详解,多态中的成员访问特点,多态的好处和弊端,多态的转型,多态存在的问题,附重难点,代码实现源码,课堂笔记,课后扩展及答案
多态与接口重点摘要 接口特点: 接口用interface修饰 interface 接口名{} 类实现接口用implements表示 class 类名 implements接口名{} 接口不能实例化,可 ...
随机推荐
- 51单片机对无线模块nRF24L01简单的控制收发程序
它的一些物理特性如工作频段.供电电压.数据传输速率就不详细介绍了,直接上代码. 1.首先是发送端: // Define SPI pins #include <reg51.h> #defin ...
- MATLAB不运行也不报错
今天本来挺激动找到能运行的好几个程序 MATLAB忙到busy也是停不下来 本来不以为然 结果呢 吃了个水果 一杯水都喝下去了 还没结果(⊙o⊙) 这时候解决办法只有一个 Ctrl+c
- JBoss CLI
转自http://www.cnblogs.com/inteliot/archive/2012/08/05/2623719.html 为 了便于维护和管理, JBoss AS 7 提供了命令行接口( ...
- H 1022 Train Problem Ⅰ
题意:给我们两个序列,看能否通过压栈,出栈将第一个序列转换成第二个. 思路:将序列 1 依次压栈,同时看是否和序列 2 当前元素相同 代码如下: #include<iostream> #i ...
- Android中的IntentService
首先说下,其他概念:Android中的本地服务与远程服务是什么? 本地服务:LocalService 应用程序内部------startService远程服务:RemoteService androi ...
- [转]WinForms GridListEditor - How to restore values in the auto filter row
http://dennisgaravsky.blogspot.hk/2016/05/winforms-gridlisteditor-how-to-restore.html using System; ...
- php CLI 模式下的传参方法
在CLI模式(命令行界面 Command Line Interface)下,传入参数有如下3种方法: 一. getopt函数(PHP 4 >= 4.3.0, PHP 5) getopt - 从命 ...
- MVVM和MVC的区别
MVVM(Model-View-ViewModel) 优点:低耦合:可重用:独立开发:可测试 即,将页面与数据分离的模式:将数据绑定工作放到javaScript文件中实现,javaScript文件的主 ...
- linux指令之文件的创建、查询、修改
mkdir(make directory) 功能:创建目录 案例: mkdir test 点评:将创建一个目录名为test的目录 rmdir(remove directory) 功能:删除目录 案例: ...
- 终于解决:升级至.NET 4.6.1后VS2015生成WCF客户端代理类的问题
在Visual Studio 2015中将一个包含WCF引用的项目的targetFramework从4.5改为4.6.1的时候,VS2015会重新生成WCF客户端代理类.如果WCF引用配置中选中了&q ...