pandas的数据联级
一.索引的堆(stack)
1.行列的转化:
Stack():列转行
Unstack():行转列
Stack对应行,
使用小技巧:使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
使用UNstack的时候,level等于哪一个,哪一个就消失,出现在列里。
如:
原来:A:
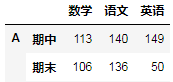
现在:A.stack(level=0).unstack(level=0).unstack(level=0)执行后
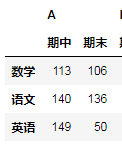
二.多层索引的聚合操作
所谓的操作是指:平均数mean()、方差std()、最大数max()、最小值min()等.....
注意:需要指定axis
小技巧:和unstack()相反,聚合操作的时候,axis等于哪一个,哪一个就保留
求平均值:
重点是axis和level的组合
A.mean(axis=0,level=1)
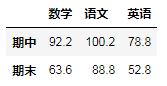
求方差:
df.std(asis=x,level=y)
方差是衡量随随机变量或一组数据时离散程度的度量。
A.std(axis=0,level=0)

Pandas的拼接操作
1.联级:pd.concal,pd.append
(1)使用pd.concat()级联
Pandas使用pd.concat()函数,与np.concatenate函数类似,只是多了一些参数
dp.concat(['objs', 'axis=0', "join='outer'", 'join_axes=None', 'ignore_index=False', 'keys=None', 'levels=None', 'names=None', 'verify_integrity=False', 'sort=None', 'copy=True'])
Concat()此方法默认增加行数,即样本。通过设置axis进行行方向或是列方向的级联。
如:
行方向级联:
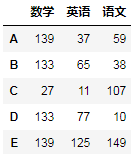
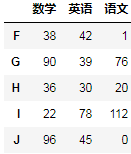
pd.concat([df1,df2],axis=0)
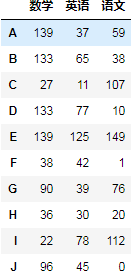
进行列方向级联
df3: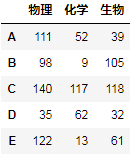
pd.concat([df1,df3],axis=1)
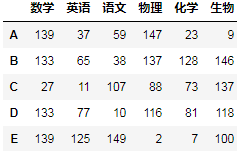
Pandas中的参数:
['objs', 'axis=0', "join='outer'", 'join_axes=None', 'ignore_index=False', 'keys=None', 'levels=None', 'names=None', 'verify_integrity=False', 'sort=None', 'copy=True']
Jgnore_index:
默认:False
如果为T,忽视给定的索引值,用1,2,3,4,.....代替,当然在操作时,以前给定的索引值失效。
如:pd.concat([df1,df2],ignore_index=True)
Keys:
序列,默认没有
如果传递了多个级别,则应该包含元组。构造使用传递的键作为最外层的分层索引
如:pd.concat([df1,df1],keys=["期中","期末"])
Join:
默认join=”outer”
Outer指合并除了公有列还合并非共有列
Inner指只合公有列
如:
pd.concat([df1,df5],join="outer")
pd.concat([df1,df5],join="inner")
Join_axes
当两张表中数据有部分列不同时,可以设置join_axes根据那个表中的列进行合并
如:pd.concat([df1,df5],join_axes=[df5.columns])
(2)使用append()追加
如:df1.append(df2)
- 合并:pd.merge,pd.join
(1)Merge:融合
A.参数:
['right', "how='inner'", 'on=None', 'left_on=None', 'right_on=None', 'left_index=False', 'right_index=False', 'sort=False', "suffixes=('_x', '_y')", 'copy=True', 'indicator=False', 'validate=None']
根据表中的属性值相同进行融合
Merge与concat的区别
merge需要依据某一共同的行或者列进行合并,使用pd.merge()合并时,会自动根据两者形同的column名称的那一列,作为key来进行合并。注意每一列元素的顺序不要求一致。
B.一对一合并
如:
df6 = DataFrame({"省":["北京","山东","河北"],"大学":["清华","山大","河大"],"人口":[1200,200,1000]})
df7 = DataFrame({"省":["北京","上海","河北"],"大学":["清华","复旦","河大"],"人口":[1200,1220,1000]})
df6.merge(df7)
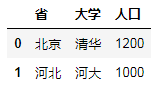
C.多对一合并
Df8 = DataFrame({"省":["北京","山东","北京"],"大学":["清华","山大","北大"]})
Df9 = DataFrame({"省":["北京","上海","河北"],"人口":[1200,1220,1000]})
Df8.merge(df9)
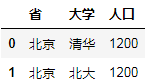
D.多对多合并
df6 = DataFrame({"省":["北京","山东","北京"],"大学":["清华","山大","北大"]})
df7 = DataFrame({"省":["北京","上海","北京"],"人口":[1200,1220,1000]})
df6.merge(df7)

E.Key的规范化
使用on=显示指定那一列为key,当有多个key相同时使用
如:
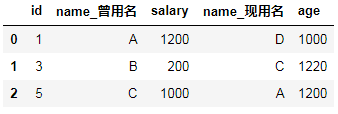
df6 = DataFrame({"id":[1,3,5],"name":["A","B","C"],"salary":[1200,200,1000]})
df7 = DataFrame({"id":[5,3,1],"name":["A","C","D"],"age":[1200,1220,1000]})
df6.merge(df7,on="id",suffixes=["_曾用名","_现用名"]) #指定根据id进行合并
使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不相等时使用
如:
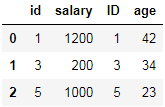
df6 = DataFrame({"id":[1,3,5],"salary":[1200,200,1000]})
df7 = DataFrame({"ID":[5,3,1],"age":[23,34,42]})
df6.merge(df7,left_on = "id",right_on = "ID")
内合并与外合并
内合并:只保留两者都有的key(默认模式)
How = “inner”
外合并:how = “outer”,补nan
左合并,右合并:how=”left”,how=”right”
G.列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个作为key,配合suffixes指定冲突列名,可以使用suffixes=自己指定的列名
Left_index=,right_index=,是否使用索引
如:将总分列添加到总表中
s = df1.sum(axis=1)
df0 = DataFrame(s,columns=["总分"])
df1.merge(df0,left_index=True,right_index=True)
pandas的数据联级的更多相关文章
- FreeSql 导航属性的联级保存功能
写在前面 FreeSql 一个款 .net 平台下支持 .net framework 4.5+..net core 2.1+ 的开源 ORM.单元测试超过3100+,正在不断吸引新的开发者,生命不息开 ...
- Blazor和Vue对比学习(基础1.6):祖孙传值,联级和注入
前面章节,我们实现了父子组件之间的数据传递.大多数时候,我们以组件形式来构建页面的区块,会涉及到组件嵌套的问题,一层套一层.这种情况,很大概率需要将祖先的数据,传递给子孙后代去使用.我们当然可以使用父 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 【转载】使用Pandas对数据进行筛选和排序
使用Pandas对数据进行筛选和排序 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas对数据进行筛选和排序 目录: sort() 对单列数据进行排序 对多列数据进行排序 获取金额最小前10项 ...
- 【转载】使用Pandas进行数据提取
使用Pandas进行数据提取 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据提取 目录 set_index() ix 按行提取信息 按列提取信息 按行与列提取信息 提取特定日期的信 ...
- 【转载】使用Pandas进行数据匹配
使用Pandas进行数据匹配 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas进行数据匹配 目录 merge()介绍 inner模式匹配 lefg模式匹配 right模式匹配 outer模式 ...
- 【转载】使用Pandas创建数据透视表
使用Pandas创建数据透视表 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas创建数据透视表 目录 pandas.pivot_table() 创建简单的数据透视表 增加一个行维度(inde ...
- Pandas 把数据写入csv
Pandas 把数据写入csv from sklearn import datasets import pandas as pd iris = datasets.load_iris() iris_X ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
随机推荐
- 黑马学习SpringMVC 基本开发步骤
- Linux —— ps命令
Ps命令 作用 显示瞬间进程的状态,并不动态连续: 如果想对进程进行实时监控应该用top命令: 对进程的管理,可以使用kill命令发送信号 Ps PID : 运行着的命令的进程编号 TTY : 命令所 ...
- 【bzoj1503】[NOI2004]郁闷的出纳员
1503: [NOI2004]郁闷的出纳员 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 13890 Solved: 5086[Submit][Stat ...
- python入门2(补发a)
一.流程控制-while循环,结构如下: while 条件: 结果 如果条件是真,则直接执行结果,然后再次判断条件,直到条件是假,停止循环 那么我们如何终止循环呢? 1,改变循环条件 2,break ...
- 批量插入,update
#####setting 1create table t as select * from all_objects where 1 =2; ###.模拟逐行提交的情况,注意观察执行时间DECLAREB ...
- airodump-ng 界面参数比较详细的解释
BSSID: AP(access point)的MAC地址,,如果在client section中BSSID显示为"not associated" ,那么意味着该客户端没有和AP连 ...
- replcation set (复制集)配置过程 --mongodb
一,配置规划 复制集原理(基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB) Paxos(mysql MGR 用的是变种))如果发生主库宕机,复制集内部会进行投票选举,选择一 ...
- windows 2008 r2或win7安装SP1补丁,安装sqlserver 2012
说明:安装sql server 2012时,win7和win2008r2系统都需要打sp1补丁. 1.SP1补丁下载地址(建议用迅雷下载): http://download.microsoft.com ...
- java lombok包在maven已经配置,但是注解没用
如果你是用eclipse作为开发环境,配置了maven依赖以后,还需要在eclipse/myeclipse中手动安装lombok. 其实就是加一个jar包,添加2行代码 1. 将 lombok.jar ...
- nodejs 实践:express 最佳实践(八) egg.js 框架的优缺点
nodejs 实践:express 最佳实践(八) egg.js 框架的优缺点 优点 所有的 web开发的点都考虑到了 agent 很有特色 文件夹规划到位 扩展能力优秀 缺点 最大的问题在于: 使用 ...